

Java虚拟机
JVM 源码分析之一个 Java 进程究竟能创建多少线程

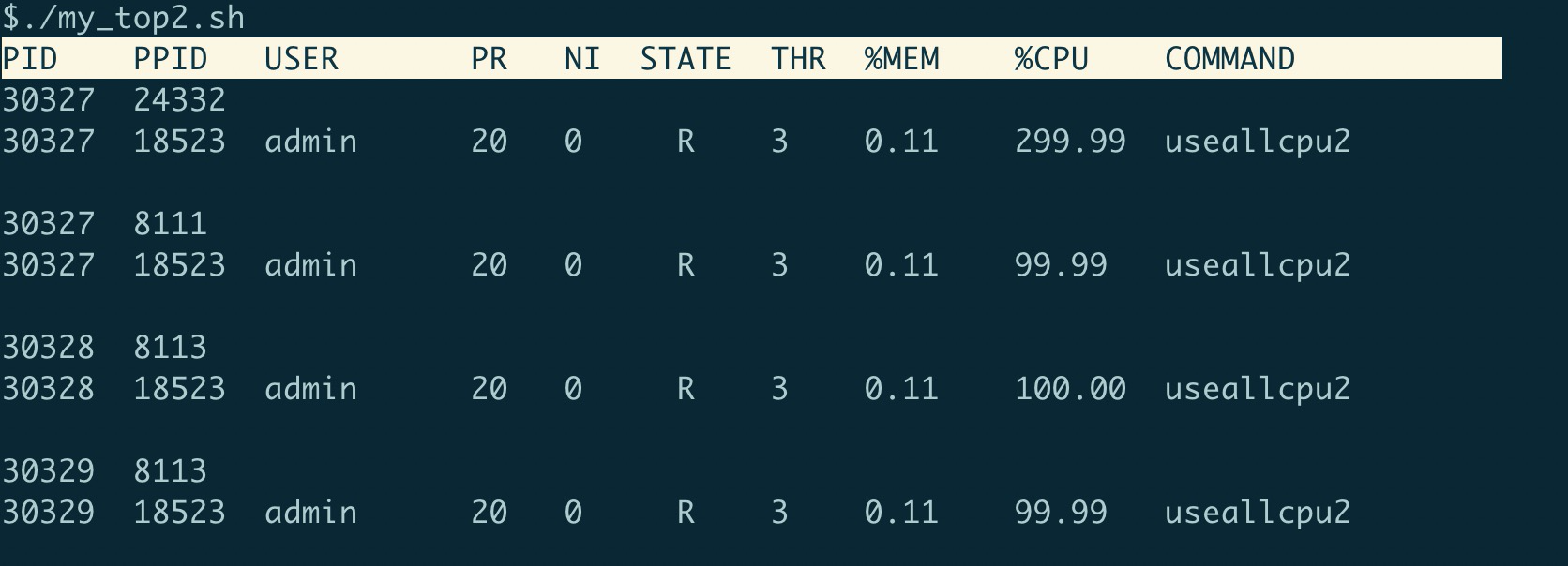
作者:踩刀诗人原文链接:https://www.cnblogs.com/chopper-poet/p/14618391.html 问题背景某日下午有测试人员急匆匆的跑来跟我反馈:“有客户反馈供应商附件

Java虚拟机
进程无故消失的破案历程
Java语言
性能优化:线程资源回收
一、问题模型服务平台的排序请求出现较多超时情况,且不定时伴随空指针异常。 二、问题发生前后的改动召回引擎扩大了召回量,导致排序请求的item数量增加了。 三、出问题的模型基于XGBoost预测的全排序


本文详细介绍了使用EXPORT_SYMBOL宏导出函数或变量、使用kallsyms_lookup_name()查找函数或变量的虚拟地址以及内核模块中直接使用内核函数的虚拟地址等3种方案解决没有被EXPORT_SYMBOL 相关的宏导出的变量或函数不能直接使用的问题

我们先从计算机组成原理的层面介绍DMA,再简单介绍Linux网络子系统的DMA机制是如何的实现的。 计算机组成原理中的DMA 以往的I/O设备和主存交换信息都要经过CPU的操作。不论是最早的轮询方式,

操作系统
Linux多线程应用性能分析
如今CPU的核心数越来越多, 在2019年你可以轻易买到超过50个核心的x86服务器CPU,一个中端台式机拥有8个执行线程也没什么好奇怪的。问题是我们怎样找到工作负载来“喂饱”那些相对饥饿的核。到目前
Java语言
Linux上TCP的几个内核参数调优


Java语言
别再纠结线程池大小/线程数量了,没有固定公式的




Java语言
记一次网络请求连接超时的事故
从HTTP请求超时、重试机制、操作系统网络等层面剖析了事故的原因,最终解决业务问题。这里先抛两个问题:1)你遭遇过由于网络连接或请求超时造成的生产事故吗?2)你知道操作系统默认的网络连接超时是多少秒?
前言到了年底果然都不太平,最近又收到了运维报警:表示有些服务器负载非常高,让我们定位问题。还真是想什么来什么,前些天还故意把某些服务器的负载提高(没错,老板让我写个 BUG!),不过还好是不同的环境互

Linux 内核为了减少命名空间的污染,并做到正确的信息隐藏,内核提供了管理内核符号可见性的方法,没有被 EXPORT_SYMBOL 相关的宏导出的变量或函数是不能直接使用的,为了说明并解决这个问题,

操作系统
从猫蛇之战再看内核戏CPU
Java语言
通过生产者与消费者模型感受死锁
一. 实验目的及实验环境 1.实验目的通过观察、分析实验现象,深入理解产生死锁的原因,学会分析死锁的方法, 并利用 pstack、 gdb 或 core 文件分析( valgrind (DRD+Hel
操作系统
从猫蛇之战看内核戏CPU
操作系统
从猫蛇之战三看内核戏CPU

问题场景在某一时刻,某个微服务的某个实例 CPU 负载突然飚高:同时建立了很多数据库链接:其他实例没有这个现象。 问题定位由于建立了很多数据库链接,猜想可能是数据库比较慢,查看数据库这段时间的 SQL

Java语言
为什么GC 异常,大家喜欢让Swap背锅呢

操作系统
NAT引发的性能瓶颈-完整版

操作系统
理解 Linux 的虚拟内存
操作系统
从应用到内核查接口超时(下)
编译选项和内核编译首先我们都知道,Linux内核如果用O0编译,是无法编译过的,Linux的内核编译,要么是O2,要么是Os,这点从Linux的Makefile里面可以看出:当选择了```CONFIG


当你登陆一台 Linux 服务器之后,因为一个问题要做性能分析时:你会在第 1 分钟内做哪些检测呢?在 Netflix,我们有很多 EC2 的 Linux 机器,并且也需要很多性能分析工具来监控和检查
Java语言
使用虚线程进行同步网络 IO 的不阻塞原理
使用虚线程进行网络 IOProject Loom 主要目标是在 Java 平台上提供一种易于使用、高吞吐量的轻量级并发性和新的编程模型的 JVM 特性和API。这带来了许多有趣和令人兴奋的前景,其中之


内容简介本文主要讨论在高实时要求、高效能计算、DPDK等领域,Linux如何让某一个线程排他性独占CPU;独占CPU涉及的线程、中断隔离原理;以及如何在排他性独占的情况下,甚至让系统的timer tick也不打断独占任务,从而实现最低的延迟抖动。 阅读本文大约需要20分钟。
导语我们在Linux性能方面有哪些优化手段可用呢?我在本章中给出一些开发或者运维中的性能优化建议。注意,我用的字眼是建议,而不是原则之类的。每一种性能优化方法都有它适用或者不适用的应用场景。你应当根据你当前的项目现状灵活来选择用或者不用。 正文1、网络请求优化建议1:尽量减少不必
在本文中,我们将讨论如何解决北美主要交易应用程序中出现的 CPU 峰值问题。突然之间,这个应用程序的 CPU 开始飙升至 100%。事实上,这个团队没有进行任何新的代码部署,没有进行任何环境更改,也没有翻转任何标志设置——但突然间,CPU 开始飙升。我们甚至验证了流量是否增加

1. 前言笔者在 《从 Linux 内核角度看 IO 模型的演变》一文中曾对 Socket 文件在内核中的相关数据结构为大家做了详尽的阐述。又在此基础之上介绍了针对 socket 文件的相关操作及其对应在内核中的处理流程:并与 epoll 的工作机制进行了串联:通过这些内容的串联介绍,

作者简介:程磊,一线码农,在某手机公司担任系统开发工程师,阅码场荣誉总编辑,日常喜欢研究内核基本原理。目录:一、基本概念解析1.1 系统调用的来源与作用1.2 API的来源与作用1.3 API与系统调用的关系1.4 系统调用机制的基本原理二、API的制定与实现2.1 POSIX A
操作系统
聊聊 Linux 中断机制

写在本文开始之前…从本文开始我们就正式开启了 Linux 内核内存管理子系统源码解析系列,笔者还是会秉承之前系列文章的风格,采用一步一图的方式先是详细介绍相关原理,在保证大家清晰理解原理的基础上,我们再来一步一步的解析相关内核源码的实现。有了源码的辅证,这样大家看得也安心,理解起来也放心,最起码可

我们都知道操作系统的一个重要功能就是进行进程管理,而进程管理就是在合适的时机选择合适的进程来执行,在单个cpu运行队列上各个进程宏观并行微观串行执行,多个cpu运行队列上的各个进程之间完全的并行执行。


操作系统
深入理解Linux中断机制
一、中断基本原理中断是计算机中非常重要的功能,其重要性不亚于人的神经系统加脉搏。虽然图灵机和冯诺依曼结构中没有中断,但是计算机如果真的没有中断的话,那么计算机就相当于是半个残疾人。今天我们就来全面详细地讲一讲中断。1.1 中断的定义我们先来看一下中断的定义:中断机制:CPU在执行指令时,收到
操作系统
深入理解Linux进程管理
作者简介:程磊,一线码农,在某手机公司担任系统开发工程师,日常喜欢研究内核基本原理。目录一、进程基本概念1.1 进程与程序1.2 进程与线程1.3 进程与内核1.4 进程与内存1.5 进程运行状态1.6 进程亲缘关系二、进程的实现2.1 基本原理2.2 进程结构体2.3 进
操作系统
为什么我的进程被kill掉了
这篇文章主要整理了一下计算机种的内存结构,以及 CPU 是如何读写内存种的数据的,如何维护 CPU 缓存中的数据一致性。什么是虚拟内存,以及它存在的必要性。如有不对请多多指教。概述目前在计算机中,主要有两大存储器 SRAM 和 DRAM。主存储器是由 DRAM 实现的,也就是我们常说的内存,在

操作系统
一个内核oops问题的分析及解决
问题再现最近在调试设备时,遇到了一个偶发的开机死机问题。通过查看输出日志,发现内核报告了oops错误,如下所示(中间省略了部分日志,以......代替):Unable to handle kernel NULL pointer dereference at virtual address 000
导语:在linux的系统维护中,可能需要经常查看cpu使用率,分析系统整体的运行情况。而监控CPU的性能一般包括以下3点:运行队列、CPU使用率和上下文切换。对于每一个CPU来说运行队列最好不要超过3,例如,如果是双核CPU就不要超过6。如果队列长期保持在3以上,说明任何一个进程运行时都不能马上

slab cache 机制确实比较复杂,涉及到的场景又很多,大家读到这里,我想肯定会好奇或者怀疑笔者在上篇文章中所论述的那些原理的正确性,毕竟 talk is cheap ,所以为了让大家看着安心,理解起来放心,从本文开始,我们将正式进入 show you the code 的阶段
操作系统
谈谈Linux内核的栈回溯与妙用
前言说起linux内核的栈回溯功能,我想这对每个Linux内核或驱动开发人员来说,太常见了。如下演示的是linux内核崩溃的一个栈回溯打印,有了这个崩溃打印我们能很快定位到在内核哪个函数崩溃,大概在函数什么位置,大大简化了问题排查过程。网上或多或少都能找到栈回溯的一些文章,但是讲的都并不完整,
操作系统
三次握手四次挥手性能分析
操作系统
网络编程里的Socket
操作系统
Fork & 写时复制COW原理
本篇文章的内核的代码是 Linux 0.11上一篇文章我们看了计算机系统中的异常和中断是怎么做的,这篇文章我们来看看 fork 是如何利用异常实现进程的创建,以及 COW 实现原理使用fork 函数是一个系统调用函数,它是用来创建一个新的进程,如下:#include <unistd.h
1. 前言本文将通过Node_exporter+Prometheus+Grafana三者结合,快速提取Linux内核数据,数据包括但不限于CPU、内存、磁盘、网络IO等,并进行可视化展示。当然,这一套
操作系统的时钟处理按理来说应该是个早已成熟的技术,不必再费口舌讨论什么。事实也的确如此。然而在虚拟环境下(不仅仅是xen,vmware这些虚拟机),对时钟的处理可绝非轻而易举,如果你耐心看看你虚拟环境
作者介绍:张子恒,西安邮电大学研一在读,导师陈莉君老师,刚刚踏入Linux内核学习的小白一枚。段落引用背景介绍:问题:vmstat只能实时统计进程上下文切换的次数,具有一定的局限性,如果已经发生了高上下文切换的情况,那么该如何找到高上下文切换问题的原因在哪?想法:进程切换最核心的地方就
操作系统
深入理解Linux进程管理
作者简介:程磊,某手机大厂系统开发工程师,阅码场荣誉总编辑,最大的爱好是钻研Linux内核基本原理。目录一、进程基本概念1.1 进程与程序1.2 进程与线程1.3 进程与内核1.4 进程与内存1.5 进程运行状态1.6 进程亲缘关系二、进程的实现2.1 基本原理2.2 进程
容器DNS异常处理问题详情最近公司开发使用的一个 maven 仓库(nexus) 说同步阿里云Maven 源失败,这个仓库是使用容器部署的。排查问题首先就是登陆到容器, ping www.baidu.com 发现网络不可达,确定是容器网络不能访问外网。第二步查看容器的网络模式,使用的桥
操作系统
CPU性能指标提取及源码分析
笔者详细地为大家介绍了 slab cache 进行内存分配的整个链路实现,本文我们就来到了 slab cache 最后的一部分内容了,当申请的内存使用完毕之后,下面就该释放内存了。
哈喽,我是子牙,一个很卷的硬核男人深入研究计算机底层、Windows内核、Linux内核、Hotspot源码……聚焦做那些大家想学没地方学的课程。为了保证课程质量及教学效果,一年磨一剑,三年先后做了三个课程:手写JVM、手写OS及带你用纯汇编写OS、手写64位多核OS及

操作系统
利用可挂载内核模块进行高负载处理
概述本程序在谢宝友老师[1]所提供的高负载处理模块的代码[2]基础上,根据5.15版内核的变化,修改出的。本程序是一个内核模块,用于监控系统负载,在平均负载超过4时,打印所有进程的调用栈。本程序分为三个文件:main.c、load.h、Makefile。其中,main.c是本内核模块的主程序;l
Linux内核之旅社区联合thoughtworks未济实验室在中科院开源之夏和CCF暑期夏令营活动中发布了13个题目,我们也一直在思考如何让大家通过这次暑期活动更好地提升自己。这次分享是通过具体的一个性能指标,利用现有的工具来定位内核代码,从而圈定学习 Kernel 的目标范围,因此这次分享是想给社
与 CPU 管理一样,内存管理也是操作系统的核心功能之一。内存主要用于存储系统和应用程序指令、数据、缓存等。内存映射我们通常所说的内存容量,其实是指物理内存。物理内存也称为主内存,大多数计算机使用的主内存是动态随机存取存储器(DRAM)。只有内核可以直接访问物理内存。那么,进程想要访问内存时应该

2、O(1)调度器的软件功能划分下图是一个O(1)调度器的软件框架:O(n)调度器中只有一个全局的runqueue,严重影响了扩展性,因此在O(1)调度器中引入了per-CPU runqueue的概念




联系我们

