
【全网首发】内核是如何给容器中的进程分配CPU资源的?原创
大家好,我是飞哥!现在很多公司的服务都是跑在容器下,我来问几个容器 CPU 相关的问题,看大家对天天在用的技术是否熟悉。
-
容器中的核是真的逻辑核吗? -
Linux 是如何对容器下的进程进行 CPU 限制的,底层是如何工作的? -
容器中的 throttle 是什么意思? -
为什么关注容器 CPU 性能的时候,除了关注使用率,还要关注 throttle 的次数和时间?
和真正使用物理机不同,Linux 容器中所谓的核并不是真正的 CPU 核。所以在理解容器 CPU 性能的时候,必然要有一些特殊的地方需要考虑。
各家公司的容器云上,底层不管使用的是 docker 引擎,还是 containerd 引擎,都是依赖 Linux 的 cgroup 的 cpu 子系统来工作的,所以今天我们就来深入地学习一下 cgroup cpu 子系统 。理解了这个,你将会对容器进程的 CPU 性能有更深入的把握。
一、cgroup 的 cpu 子系统
在 Linux 下, cgroup 提供了对 CPU、内存等资源实现精细化控制的能力。它的全称是 control groups。允许对某一个进程,或者一组进程所用到的资源进行控制。现在流行的 Docker 就是在这个底层机制上成长起来的。
在你的机器执行执行下面的命令可以查看当前 cgroup 都支持对哪些资源进行控制。
$ lssubsys -a
cpuset
cpu,cpuacct
...
其中 cpu 和 cpuset 都是对 CPU 资源进行控制的子系统。cpu 是通过执行时间来控制进程对 cpu 的使用,cpuset 是通过分配逻辑核的方式来分配 cpu。其它可控制的资源还包括 memory(内存)、net_cls(网络带宽)等等。
cgroup 提供了一个原生接口并通过 cgroupfs 提供控制。类似于 procfs 和 sysfs,是一种虚拟文件系统。默认情况下 cgroupfs 挂载在 /sys/fs/cgroup 目录下,我们可以通过修改 /sys/fs/cgroup 下的文件和文件内容来控制进程对资源的使用。
比如,想实现让某个进程只使用两个核,我们可以通过 cgroupfs 接口这样来实现,如下:
# cd /sys/fs/cgroup/cpu,cpuacct
# mkdir test
# cd test
# echo 100000 > cpu.cfs_period_us // 100ms
# echo 100000 > cpu.cfs_quota_us //200ms
# echo {$pid} > cgroup.procs
其中 cfs_period_us 用来配置时间周期长度,cfs_quota_us 用来配置当前 cgroup 在设置的周期长度内所能使用的 CPU 时间。这两个文件配合起来就可以设置 CPU 的使用上限。
上面的配置就是设置改 cgroup 下的进程每 100 ms 内只能使用 200 ms 的 CPU 周期,也就是说限制使用最多两个“核”。
要注意的是这种方式只限制的是 CPU 使用时间,具体调度的时候是可能会调度到任意 CPU 上执行的。如果想限制进程使用的 CPU 核,可以使用 cpuset 子系统;
docker 默认情况下使用的就是 cgroupfs 接口,可以通过如下的命令来确认。
# docker info | grep cgroup
Cgroup Driver: cgroupfs
二、内核中进程和 cgroup 的关系
在上一节中,我们在 /sys/fs/cgroup/cpu,cpuacct 创建了一个目录 test,这其实是创建了一个 cgroup 对象。当我们把某个进程的 pid 添加到 cgroup 后,又是建立了进程结构体和 cgroup 之间的关系。
所以要想理解清 cgroup 的工作过程,就得先来了解一下 cgroup 和 task_struct 结构体之间的关系。
2.1 cgroup 内核对象
一个 cgroup 对象中可以指定对 cpu、cpuset、memory 等一种或多种资源的限制。我们先来找到 cgroup 的定义。
//file:include/linux/cgroup-defs.h
struct cgroup {
...
struct cgroup_subsys_state __rcu *subsys[CGROUP_SUBSYS_COUNT];
...
}
每个 cgroup 都有一个 cgroup_subsys_state 类型的数组 subsys,其中的每一个元素代表的是一种资源控制,如 cpu、cpuset、memory 等等。
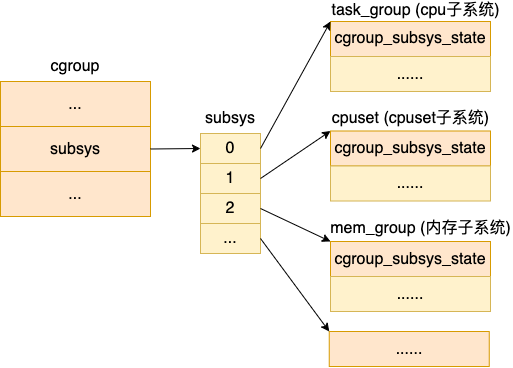
这里要注意的是,其实 cgroup_subsys_state 并不是真实的资源控制统计信息结构,对于 CPU 子系统真正的资源控制结构是 task_group。它是 cgroup_subsys_state 结构的扩展,类似父类和子类的概念。
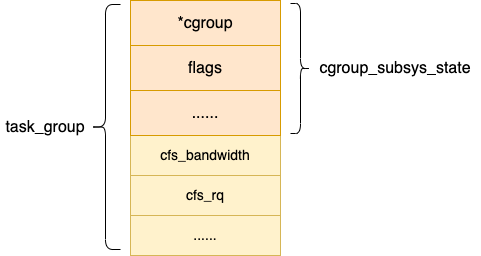
当 task_group 需要被当成 cgroup_subsys_state 类型使用的时候,只需要强制类型转换就可以。
对于内存子系统控制统计信息结构是 mem_cgroup,其它子系统也类似。
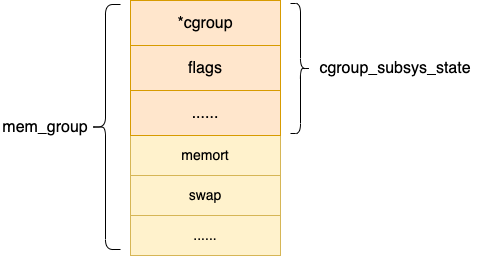
之所以要这么设计,目的是各个 cgroup 子系统都统一对外暴露 cgroup_subsys_state,其余部分不对外暴露,在自己的子系统内部维护和使用。
2.2 进程和 cgroup 子系统
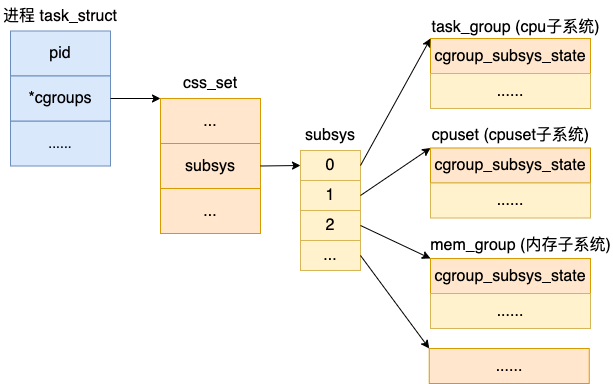
一个 Linux 进程既可以对它的 cpu 使用进行限制,也可以对它的内存进行限制。所以,一个进程 task_struct 是可以和多种子系统有关联关系的。
和 cgroup 和多个子系统关联定义类似,task_struct 中也定义了一个 cgroup_subsys_state 类型的数组 subsys,来表达这种一对多的关系。
我们来简单看下源码的定义。
//file:include/linux/sched.h
struct task_struct {
...
struct css_set __rcu *cgroups;
...
}
//file:include/linux/cgroup-defs.h
struct css_set {
...
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
}
其中subsys是一个指针数组,存储一组指向 cgroup_subsys_state 的指针。一个 cgroup_subsys_state 就是进程与一个特定的子系统相关的信息。
通过这个指针,进程就可以获得相关联的 cgroups 控制信息了。能查到限制该进程对资源使用的 task_group、cpuset、mem_group 等子系统对象。
2.3 内核对象关系图汇总
我们把上面的内核对象关系图汇总起来看一下。
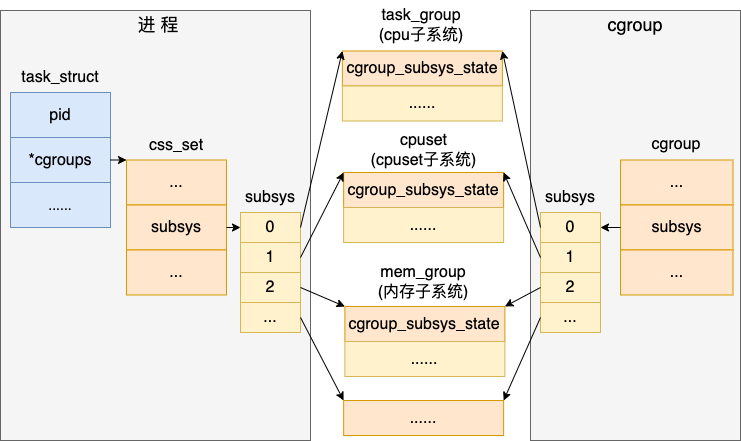
可以看到无论是进程、还是 cgroup 对象,最后都能找到和其关联的具体的 cpu、内存等资源控制自系统的对象。
2.4 cpu 子系统
因为今天我们重点是介绍进程的 cpu 限制,所以我们把 cpu 子系统相关的对象 task_group 专门拿出来理解理解。
//file:kernel/sched/sched.h
struct task_group {
struct cgroup_subsys_state css;
...
// task_group 树结构
struct task_group *parent;
struct list_head siblings;
struct list_head children;
//task_group 持有的 N 个调度实体(N = CPU 核数)
struct sched_entity **se;
//task_group 自己的 N 个公平调度队列(N = CPU 核数)
struct cfs_rq **cfs_rq;
//公平调度带宽限制
struct cfs_bandwidth cfs_bandwidth;
...
}
第一个 cgroup_subsys_state css 成员我们在前面说过了,这相当于它的“父类”。再来看 parent、siblings、children 等几个对象。这些成员是树相关的数据结构。在整个系统中有一个 root_task_group。
//file:kernel/sched/core.c
struct task_group root_task_group;
所有的 task_group 都是以 root_task_group 为根节点组成了一棵树。
接下来的 se 和 cfs_rq 是完全公平调度的两个对象。它们两都是数组,元素个数等于当前系统的 CPU 核数。每个 task_group 都会在上一级 task_group(比如 root_task_group)的 N 个调度队列中有一个调度实体。
cfs_rq 是 task_group 自己所持有的完全公平调度队列。是的,你没看错。每一个 task_group 内部都有自己的一组调度队列,其数量和 CPU 的核数一致。
假如当前系统有两个逻辑核,那么一个 task_group 树和 cfs_rq 的简单示意图大概是下面这个样子。
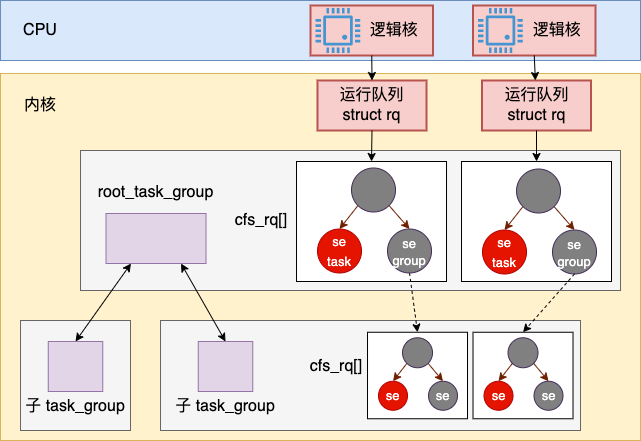
Linux 中的进程调度是一个层级的结构。对于容器来讲,宿主机中进行进程调度的时候,先调度到的实际上不是容器中的具体某个进程,而是一个 task_group。然后接下来再进入容器 task_group 的调度队列 cfs_rq 中进行调度,才能最终确定具体的进程 pid。
还有就是 cpu 带宽限制 cfs_bandwidth, cpu 分配的管控相关的字段都是在 cfs_bandwidth 中定义维护的。
cgroup 相关的内核对象我们就先介绍到这里,接下来我们看一下 cpu 子系统到底是如何实现的。
三、CPU 子系统的实现
在第一节中我们展示通过 cgroupfs 对 cpu 子系统使用,使用过程大概可以分成三步:
-
第一步:通过创建目录来创建 cgroup -
第二步:在目录中设置 cpu 的限制情况 -
第三步:将进程添加到 cgroup 中进行资源管控
那本小节我们就从上面三步展开,看看在每一步中,内核都具体做了哪些事情。限于篇幅所限,我们只讲 cpu 子系统,对于其他的子系统也是类似的分析过程。
3.1 创建 cgroup 对象
内核定义了对 cgroupfs 操作的具体处理函数。在 /sys/fs/cgroup/ 下的目录创建操作都将由下面 cgroup_kf_syscall_ops 定义的方法来执行。
//file:kernel/cgroup/cgroup.c
static struct kernfs_syscall_ops cgroup_kf_syscall_ops = {
.mkdir = cgroup_mkdir,
.rmdir = cgroup_rmdir,
...
};
创建目录执行整个过程链条如下
vfs_mkdir
->kernfs_iop_mkdir
->cgroup_mkdir
->cgroup_apply_control_enable
->css_create
->cpu_cgroup_css_alloc
其中关键的创建过程有:
-
cgroup_mkdir:在这里创建了 cgroup 内核对象 -
css_create:创建每一个子系统资源管理对象,对于 cpu 子系统会创建 task_group
cgroup 内核对象是在 cgroup_mkdir 中创建的。除了 cgroup 内核对象,这里还创建了文件系统重要展示的目录。
//file:kernel/cgroup/cgroup.c
int cgroup_mkdir(struct kernfs_node *parent_kn, const char *name, umode_t mode)
{
...
//查找父 cgroup
parent = cgroup_kn_lock_live(parent_kn, false);
//创建cgroup对象出来
cgrp = cgroup_create(parent);
//创建文件系统节点
kn = kernfs_create_dir(parent->kn, name, mode, cgrp);
cgrp->kn = kn;
...
}
在 cgroup 中,是有层次的概念的,这个层次结构和 cgroupfs 中的目录层次结构一样。所以在创建 cgroup 对象之前的第一步就是先找到其父 cgroup, 然后创建自己,并创建文件系统中的目录以及文件。
在 cgroup_apply_control_enable 中,执行子系统对象的创建。
//file:kernel/cgroup/cgroup.c
static int cgroup_apply_control_enable(struct cgroup *cgrp)
{
...
cgroup_for_each_live_descendant_pre(dsct, d_css, cgrp) {
for_each_subsys(ss, ssid) {
struct cgroup_subsys_state *css = cgroup_css(dsct, ss);
css = css_create(dsct, ss);
...
}
}
return 0;
}
通过 for_each_subsys 遍历每一种 cgroup 子系统,并调用其 css_alloc 来创建相应的对象。
//file:kernel/cgroup/cgroup.c
static struct cgroup_subsys_state *css_create(struct cgroup *cgrp,
struct cgroup_subsys *ss)
{
css = ss->css_alloc(parent_css);
...
}
上面的 css_alloc 是一个函数指针,对于 cpu 子系统来说,它指向的是 cpu_cgroup_css_alloc。这个对应关系在 kernel/sched/core.c 文件仲可以找到
//file:kernel/sched/core.c
struct cgroup_subsys cpu_cgrp_subsys = {
.css_alloc = cpu_cgroup_css_alloc,
.css_online = cpu_cgroup_css_online,
...
};
通过 cpu_cgroup_css_alloc => sched_create_group 调用后,创建出了 cpu 子系统的内核对象 task_group。
//file:kernel/sched/core.c
struct task_group *sched_create_group(struct task_group *parent)
{
struct task_group *tg;
tg = kmem_cache_alloc(task_group_cache, GFP_KERNEL | __GFP_ZERO);
...
}
3.2 设置 CPU 子系统限制
第一节中,我们通过对 cpu 子系统目录下的 cfs_period_us 和 cfs_quota_us 值的修改,来完成了 cgroup 中限制的设置。我们这个小节再看看看这个设置过程。
当用户读写这两个文件的时候,内核中也定义了对应的处理函数。
//file:kernel/sched/core.c
static struct cftype cpu_legacy_files[] = {
...
{
.name = "cfs_quota_us",
.read_s64 = cpu_cfs_quota_read_s64,
.write_s64 = cpu_cfs_quota_write_s64,
},
{
.name = "cfs_period_us",
.read_u64 = cpu_cfs_period_read_u64,
.write_u64 = cpu_cfs_period_write_u64,
},
...
}
写处理函数 cpu_cfs_quota_write_s64、cpu_cfs_period_write_u64 最终又都是调用 tg_set_cfs_bandwidth 来完成设置的。
//file:kernel/sched/core.c
static int tg_set_cfs_bandwidth(struct task_group *tg, u64 period, u64 quota)
{
//定位 cfs_bandwidth 对象
struct cfs_bandwidth *cfs_b = &tg->cfs_bandwidth;
...
//对 cfs_bandwidth 进行设置
cfs_b->period = ns_to_ktime(period);
cfs_b->quota = quota;
...
}
在 task_group 中,其带宽管理控制都是由 cfs_bandwidth 来完成的,所以一开始就需要先获取 cfs_bandwidth 对象。接着将用户设置的值都设置到 cfs_bandwidth 类型的对象 cfs_b 上。
3.3 写 proc 进 group
cgroup 创建好了,cpu 限制规则也制定好了,下一步就是将进程添加到这个限制中。在 cgroupfs 下的操作方式就是修改 cgroup.procs 文件。
内核定义了修改 cgroup.procs 文件的处理函数为 cgroup_procs_write。
//file:kernel/cgroup/cgroup.c
static struct cftype cgroup_base_files[] = {
...
{
.name = "cgroup.procs",
...
.write = cgroup_procs_write,
},
}
在 cgroup_procs_write 的处理中,主要做了这么几件事情。
-
第一、逻根据用户输入的 pid 来查找 task_struct 内核对象。 -
第二、从旧的调度组中退出,加入到新的调度组 task_group 中 -
第三、修改进程其 cgroup 相关的指针,让其指向上面创建好的 task_group。
我们来看下加入新调度组的过程,内核的调用链条如下。
cgroup_procs_write
->cgroup_attach_task
->cgroup_migrate
->cgroup_migrate_execute
在 cgroup_migrate_execute 中遍历各个子系统,完成每一个子系统的迁移。
static int cgroup_migrate_execute(struct cgroup_mgctx *mgctx)
{
do_each_subsys_mask(ss, ssid, mgctx->ss_mask) {
if (ss->attach) {
tset->ssid = ssid;
ss->attach(tset);
}
} while_each_subsys_mask();
...
}
对于 cpu 子系统来讲,attach 对应的处理方法是 cpu_cgroup_attach。这也是在 kernel/sched/core.c 下的 cpu_cgrp_subsys 中定义的。
cpu_cgroup_attach 调用 sched_move_task 来完成将进程加入到新调度组的过程。
//file:kernel/sched/core.c
void sched_move_task(struct task_struct *tsk)
{
//找到task所在的runqueue
rq = task_rq_lock(tsk, &rf);
//从runqueue中出来
queued = task_on_rq_queued(tsk);
if (queued)
dequeue_task(rq, tsk, queue_flags);
//修改task的group
//将进程先从旧tg的cfs_rq中移除且更新cfs_rq的负载;再将进程添加入新tg的cfs_rq并更新新cfs_rq的负载
sched_change_group(tsk, TASK_MOVE_GROUP);
//此时进程的调度组已经更新,重新将进程加回runqueue
if (queued)
enqueue_task(rq, tsk, queue_flags);
...
}
这个函数做了三件事。
-
第一、先调用 dequeue_task 从原归属的 queue 中退出来, -
第二、修改进程的 task_group -
第三、重新将进程添加到新 task_group 的 runqueue 中。
//file:kernel/sched/core.c
static void sched_change_group(struct task_struct *tsk, int type)
{
struct task_group *tg;
//查找 task_group
tg = container_of(task_css_check(tsk, cpu_cgrp_id, true),
struct task_group, css);
tg = autogroup_task_group(tsk, tg);
//修改 task_struct 所对应的 task_group
tsk->sched_task_group = tg;
...
}
进程 task_struct 的 sched_task_group 是表示其归属的 task_group, 这里设置到新归属上。
四、进程 CPU 带宽控制过程
在前面的操作完毕之后,我们只是将进程添加到了 cgroup 中进行管理而已。相当于只是初始化,而真正的限制是贯穿在 Linux 运行是的进程调度过程中的。
所添加的进程将会受到 cpu 子系统 task_group 下的 cfs_bandwidth 中记录的 period 和 quota 的限制。
在你的新进程是如何被内核调度执行到的?一文中我们介绍过完全公平调度器在选择进程时的核心方法 pick_next_task_fair。
这个方法的整个执行过程一个自顶向下搜索可执行的 task_struct 的过程。整个系统中有一个 root_task_group。
//file:kernel/sched/core.c
struct task_group root_task_group;
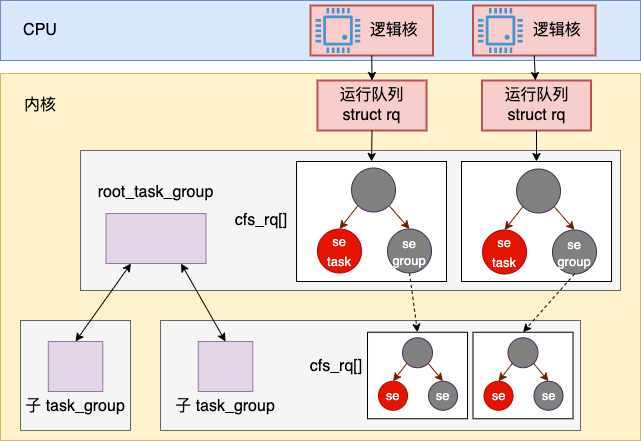
CFS 中调度队列是一颗红黑树, 红黑树的节点是 struct sched_entity, sched_entity 中既可以指向 struct task_struct 也可以指向 struct cfs_rq(可理解为 task_group)
调度 pick_next_task_fair()函数中的 prev 是本次调度时在执行的上一个进程。该函数通过 do {} while 循环,自顶向下搜索到下一步可执行进程。
//file:kernel/sched/fair.c
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
...
//选择下一个调度的进程
do {
...
se = pick_next_entity(cfs_rq, curr);
cfs_rq = group_cfs_rq(se);
}while (cfs_rq)
p = task_of(se);
//如果选出的进程和上一个进程不同
if (prev != p) {
struct sched_entity *pse = &prev->se;
...
//对要放弃 CPU 的进程执行一些处理
put_prev_entity(cfs_rq, pse);
}
}
如果新进程和上一次运行的进程不是同一个,则要调用 put_prev_entity 做两件和 CPU 的带宽控制有关的事情。
//file: kernel/sched/fair.c
static void put_prev_entity(struct cfs_rq *cfs_rq, struct sched_entity *prev)
{
//4.1 运行队列带宽的更新与申请
if (prev->on_rq)
update_curr(cfs_rq);
//4.2 判断是否需要将容器挂起
check_cfs_rq_runtime(cfs_rq);
//更新负载数据
update_load_avg(cfs_rq, prev, 0);
...
}
在上述代码中,和 CPU 带宽控制相关的操作有两个。
-
运行队列带宽的更新与申请 -
判断是否需要进行带宽限制
接下来我们分两个小节详细展开看看这两个操作具体都做了哪些事情。
4.1 运行队列带宽的更新与申请
在这个小节中我们专门来看看 cfs_rq 队列中 runtime_remaining 的更新与申请
在实现上带宽控制是在 task_group 下属的 cfs_rq 队列中进行的。cfs_rq 对带宽时间的操作归总起来就是更新与申请。申请到的时间保存在字段 runtime_remaining 字段中,每当有时间支出需要更新的时候也是从这个字段值从去除。
其实除了上述场景外,系统在很多情况下都会调用 update_curr,包括任务在入队、出队时,调度中断函数也会周期性地调用该方法,以确保任务的各种时间信息随时都是最新的状态。在这里会更新 cfs_rq 队列中的 runtime_remaining 时间。如果 runtime_remaining 不足,会触发时间申请。
//file:kernel/sched/fair.c
static void update_curr(struct cfs_rq *cfs_rq)
{
//计算一下运行了多久
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
delta_exec = now - curr->exec_start;
...
//更新带宽限制
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
在 update_curr 先计算当前执行了多少时间。然后在 cfs_rq 的 runtime_remaining 减去该时间值,具体减的过程是在 account_cfs_rq_runtime 中处理的。
//file:kernel/sched/fair.c
static void __account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec)
{
cfs_rq->runtime_remaining -= delta_exec;
//如果还有剩余时间,则函数返回
if (likely(cfs_rq->runtime_remaining > 0))
return;
...
//调用 assign_cfs_rq_runtime 申请时间余额
if (!assign_cfs_rq_runtime(cfs_rq) && likely(cfs_rq->curr))
resched_curr(rq_of(cfs_rq));
}
更新带宽时间的逻辑比较简单,先从 cfs->runtime_remaining 减去本次执行的物理时间。如果减去之后仍然大于 0 ,那么本次更新就算是结束了。
如果相减后发现是负数,表示当前 cfs_rq 的时间余额已经耗尽,则会立即尝试从任务组中申请。具体的申请函数是 assign_cfs_rq_runtime。如果申请没能成功,调用 resched_curr 标记 cfs_rq->curr 的 TIF_NEED_RESCHED 位,以便随后将其调度出去。
我们展开看下申请过程 assign_cfs_rq_runtime 。
//file:kernel/sched/fair.c
static int assign_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
//获取当前 task_group 的 cfs_bandwidth
struct task_group *tg = cfs_rq->tg;
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(tg);
//申请时间数量为保持下次有 sysctl_sched_cfs_bandwidth_slice 这么多
min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining;
//如果没有限制,则要多少给多少
if (cfs_b->quota == RUNTIME_INF)
amount = min_amount;
else {
//保证定时器是打开的,保证周期性地为任务组重置带宽时间
start_cfs_bandwidth(cfs_b);
//如果本周期内还有时间,则可以分配
if (cfs_b->runtime > 0) {
//确保不要透支
amount = min(cfs_b->runtime, min_amount);
cfs_b->runtime -= amount;
cfs_b->idle = 0;
}
}
cfs_rq->runtime_remaining += amount;
return cfs_rq->runtime_remaining > 0;
}
首先,获取当前 task_group 的 cfs_bandwidth,因为整个任务组的带宽数据都是封装在这里的。接着调用 sched_cfs_bandwidth_slice 来获取后面要留有多长时间,这个函数访问的 sysctl 下的 sched_cfs_bandwidth_slice 参数。
//file:kernel/sched/fair.c
static inline u64 sched_cfs_bandwidth_slice(void)
{
return (u64)sysctl_sched_cfs_bandwidth_slice * NSEC_PER_USEC;
}
这个参数在我的机器上是 5000 us(也就是说每次申请 5 ms)。
$ sysctl -a | grep sched_cfs_bandwidth_slice
kernel.sched_cfs_bandwidth_slice_us = 5000
在计算要申请的时间的时候,还需要考虑现在有多少时间。如果 cfs_rq->runtime_remaining 为正的话,那可以少申请一点,如果已经变为负数的话,需要在 sched_cfs_bandwidth_slice 基础之上再多申请一些。
所以,最终要申请的时间值 min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining
计算出 min_amount 后,直接在向自己所属的 task_group 下的 cfs_bandwidth 把时间申请出来。整个 task_group 下可用的时间是保存在 cfs_b->runtime 中的。
这里你可能会问了,那 task_group 下的 cfs_b->runtime 的时间又是哪儿给分配的呢?我们将在 5.1 节来讨论这个过程。
4.2 带宽限制
check_cfs_rq_runtime 这个函数检测 task group 的带宽是否已经耗尽, 如果是则调用 throttle_cfs_rq 对进程进行限流。
//file: kernel/sched/fair.c
static bool check_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
//判断是不是时间余额已用尽
if (likely(!cfs_rq->runtime_enabled || cfs_rq->runtime_remaining > 0))
return false;
...
throttle_cfs_rq(cfs_rq);
return true;
}
我们再来看看 throttle_cfs_rq 的执行过程。
//file:kernel/sched/fair.c
static void throttle_cfs_rq(struct cfs_rq *cfs_rq)
{
//1.查找到所属的 task_group 下的 se
se = cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))];
...
//2.遍历每一个可调度实体,并从隶属的 cfs_rq 上面删除。
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
if (dequeue)
dequeue_entity(qcfs_rq, se, DEQUEUE_SLEEP);
...
}
//3.设置一些 throttled 信息。
cfs_rq->throttled = 1;
cfs_rq->throttled_clock = rq_clock(rq);
//4.确保unthrottle的高精度定时器处于被激活的状态
start_cfs_bandwidth(cfs_b);
...
}
在 throttle_cfs_rq 中,找到其所属的 task_group 下的调度实体 se 数组,遍历每一个元素,并从其隶属的 cfs_rq 的红黑树上删除。这样下次再调度的时候,就不会再调度到这些进程了。
那么 start_cfs_bandwidth 是干啥的呢?这正好是下一节的引子。
五、进程的可运行时间的分配
在第四小节我们看到,task_group 下的进程的运行时间都是从它的 cfs_b->runtime 中申请的。这个时间是在定时器中分配的。负责给 task_group 分配运行时间的定时器包括两个,一个是 period_timer,另一个是 slack_timer。
struct cfs_bandwidth {
ktime_t period;
u64 quota;
...
struct hrtimer period_timer;
struct hrtimer slack_timer;
...
}
peroid_timer 是周期性给 task_group 添加时间,缺点是 timer 周期比较长,通常是100ms。而 slack_timer 用于有 cfs_rq 处于 throttle 状态且全局时间池有时间供分配但是 period_timer 有还有比较长时间(通常大于7ms)才超时的场景。这个时候我们就可以激活比较短的slack_timer(5ms超时)进行throttle,这样的设计可以提升系统的实时性。
这两个 timer 在 cgroup 下的 cfs_bandwidth 初始化的时候,都设置好了到期回调函数,分别是 sched_cfs_period_timer 和 sched_cfs_slack_timer。
//file:kernel/sched/fair.c
void init_cfs_bandwidth(struct cfs_bandwidth *cfs_b)
{
cfs_b->runtime = 0;
cfs_b->quota = RUNTIME_INF;
cfs_b->period = ns_to_ktime(default_cfs_period());
//初始化 period_timer 并设置回调函数
hrtimer_init(&cfs_b->period_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS_PINNED);
cfs_b->period_timer.function = sched_cfs_period_timer;
//初始化 slack_timer 并设置回调函数
hrtimer_init(&cfs_b->slack_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
cfs_b->slack_timer.function = sched_cfs_slack_timer;
...
}
在上一节最后提到的 start_cfs_bandwidth 就是在打开 period_timer 定时器。
//file:kernel/sched/fair.c
void start_cfs_bandwidth(struct cfs_bandwidth *cfs_b)
{
...
hrtimer_forward_now(&cfs_b->period_timer, cfs_b->period);
hrtimer_start_expires(&cfs_b->period_timer, HRTIMER_MODE_ABS_PINNED);
}
在 hrtimer_forward_now 调用时传入的第二个参数表示是触发的延迟时间。这个就是在 cgroup 是设置的 period,一般为 100 ms。
我们来分别看看这两个 timer 是如何给 task_group 定期发工资(分配时间)的。
5.1 period_timer
在 period_timer 的回调函数 sched_cfs_period_timer 中,周期性地为任务组分配带宽时间,并且解挂当前任务组中所有挂起的队列。
分配带宽时间是在 __refill_cfs_bandwidth_runtime 中执行的,它的调用堆栈如下。
sched_cfs_period_timer
->do_sched_cfs_period_timer
->__refill_cfs_bandwidth_runtime
//file:kernel/sched/fair.c
void __refill_cfs_bandwidth_runtime(struct cfs_bandwidth *cfs_b)
{
if (cfs_b->quota != RUNTIME_INF)
cfs_b->runtime = cfs_b->quota;
}
可见,这里直接给 cfs_b->runtime 增加了 cfs_b->quota 这么多的时间。其中 cfs_b->quota 你就可以认为是在 cgroupfs 目录下,我们配置的那个值。在第一节中,我们配置的是 500 ms。
# echo 500000 > cpu.cfs_period_us // 500ms
5.2 slack_timer
设想一下,假如说某个进程申请了 5 ms 的执行时间,但是当进程刚一启动执行便执行了同步阻塞的逻辑,这时候所申请的时间根本都没有用完。在这种情况下,申请但没用完的时间大部分是要返还给 task_group 中的全局时间池的。
在内核中的调用链如下
dequeue_task_fair
–>dequeue_entity
–>return_cfs_rq_runtime
–>__return_cfs_rq_runtime
具体的返还是在 __return_cfs_rq_runtime 中处理的。
//file:kernel/sched/fair.c
static void __return_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
//给自己留一点
s64 slack_runtime = cfs_rq->runtime_remaining - min_cfs_rq_runtime;
if (slack_runtime <= 0)
return;
//返还到全局时间池中
if (cfs_b->quota != RUNTIME_INF) {
cfs_b->runtime += slack_runtime;
//如果时间又足够多了,并且还有进程被限制的话
//则调用 start_cfs_slack_bandwidth 来开启 slack_timer
if (cfs_b->runtime > sched_cfs_bandwidth_slice() &&
!list_empty(&cfs_b->throttled_cfs_rq))
start_cfs_slack_bandwidth(cfs_b);
}
...
}
这个函数做了这么几件事情。
-
min_cfs_rq_runtime 的值是 1 ms,我们选择至少保留 1ms 时间给自己 -
剩下的时间 slack_runtime 归还给当前的 cfs_b->runtime -
如果时间又足够多了,并且还有进程被限制的话,开启slack_timer,尝试接触进程 CPU 限制
在 start_cfs_slack_bandwidth 中启动了 slack_timer。
//file:kernel/sched/fair.c
static void start_cfs_slack_bandwidth(struct cfs_bandwidth *cfs_b)
{
...
//启动 slack_timer
cfs_b->slack_started = true;
hrtimer_start(&cfs_b->slack_timer,
ns_to_ktime(cfs_bandwidth_slack_period),
HRTIMER_MODE_REL);
...
}
可见 slack_timer 的延迟回调时间是 cfs_bandwidth_slack_period,它的值是 5 ms。这就比 period_timer 要实时多了。
slack_timer 的回调函数 sched_cfs_slack_timer 我们就不展开看了,它主要就是操作对进程解除 CPU 限制
六、总结
今天我们介绍了 Linux cgroup 的 cpu 子系统给容器中的进程分配 cpu 时间的原理。
和真正使用物理机不同,Linux 容器中所谓的核并不是真正的 CPU 核,而是转化成了执行时间的概念。在容器进程调度的时候给其满足一定的 CPU 执行时间,而不是真正的分配逻辑核。
cgroup 提供了的原生接口是通过 cgroupfs 提供控制各个子系统的设置的。默认是在 /sys/fs/cgroup/ 目录下,内核这个文件系统的处理是定义了特殊的处理,和普通的文件完全不一样的。
内核处理 cpu 带宽控制的核心对象就是下面这个 cfs_bandwidth。
//file:kernel/sched/sched.h
struct cfs_bandwidth {
//带宽控制配置
ktime_t period;
u64 quota;
//当前 task_group 的全局可执行时间
u64 runtime;
...
//定时分配
struct hrtimer period_timer;
struct hrtimer slack_timer;
}
用户在创建 cgroup cpu 子系统控制过程主要分成三步:
-
第一步:通过创建目录来创建 cgroup 对象。在 /sys/fs/cgroup/cpu,cpuacct 创建一个目录 test,实际上内核是创建了 cgroup、task_group 等内核对象。 -
第二步:在目录中设置 cpu 的限制情况。在 task_group 下有个核心的 cfs_bandwidth 对象,用户所设置的 cfs_quota_us 和 cfs_period_us 的值最后都存到它下面了。 -
第三步:将进程添加到 cgroup 中进行资源管控。当在 cgroup 的 cgroup.proc 下添加进程 pid 时,实际上是将该进程加入到了这个新的 task_group 调度组了。将使用 task_group 的 runqueue,以及它的时间配额
当创建完成后,内核的 period_timer 会根据 task_group->cfs_bandwidth 下用户设置的 period 定时给可执行时间 runtime 上加上 quota 这么多的时间(相当于按月发工资),以供 task_group 下的进程执行(消费)的时候使用。
struct cfs_rq {
...
int runtime_enabled;
s64 runtime_remaining;
}
在完全公平器调度的时候,每次 pick_next_task_fair 时会做两件事情
-
第一件:将从 cpu 上拿下来的进程所在的运行队列进行执行时间的更新与申请。会将 cfs_rq 的 runtime_remaining 减去已经执行了的时间。如果减为了负数,则从 cfs_rq 所在的 task_group 下的 cfs_bandwidth 去申请一些。 -
第二件:判断 cfs_rq 上是否申请到了可执行时间,如果没有申请到,需要将这个队列上的所有进程都从完全公平调度器的红黑树上取下。这样再次调度的时候,这些进程就不会被调度了。
当 period_timer 再次给 task_group 分配时间的时候,或者是自己有申请时间没用完回收后触发 slack_timer 的时候,被限制调度的进程会被解除调度限制,重新正常参与运行。
这里要注意的是,一般 period_timer 分配时间的周期都是 100 ms 左右。假如说你的进程前 50 ms 就把 cpu 给用光了,那你收到的请求可能在后面的 50 ms 都没有办法处理,对请求处理耗时会有影响。这也是为啥在关注 CPU 性能的时候要关注对容器 throttle 次数和时间的原因了。
最后,求点赞、评论、转发!




