
FullGC没及时处理,差点造成P0事故原创
背景
上线新功能后,要多观察。如果出现不稳定性的情况,需要高优先级查清原因,避免出现更大的问题。
问题描述
部分应用出现重启
过程
- 11:58,接到报警,一个pod1三分钟内存在重启
- 12:02,pod1已经5分钟没有报警,数据已经正常恢复【有耗内存的功能,多人同时触发时,偶尔也会重启】
- 12:06,JVM监控 节点机IP: 10.10.48.116 JVM_FullGC次数,最近2分钟求平均 >= 5.0 次, 当前值5.0000 次
- 12:07,JVM监控 节点机IP: 10.10.48.116 JVM_FullGC,数据已经正常恢复
- 12:15,接到报警,pod2三分钟内存在重启告警
- 12:18,pod2和pod3三分钟内存在重启告警
- 12:20,pod2和pod3和pod4三分钟内存在重启告警
- 12:24,查看重启pod日志,发现一直在刷查询tableStore异常的日志:2022-09-01 12:24:41[16-d ][I/O dispatcher 36] WARN c.a.o.tablestore.core.utils.LogUtil - TraceId:8-1 Failed RetriedCount:1 [ErrorCode]:OTSServerBusy, [Message]:Service is busy., [RequestId]:00-e1, [TraceId]:81db-cd, [HttpStatus:]503
- 12:25,JVM监控 节点机IP: 10.10.48.117 JVM_FullGC次数最近2分钟求平均 >= 5.0 次, 当前值5.5000 次
- 12:25,从 2022-09-01 12:22:00 开始,在 0 天, 3 分钟内发生 3 次 JVM监控 节点机IP: 10.10.48.117 JVM_FullGC次数最近2分钟求平均 >= 5.0 次, 当前值5.5000 次 JVM监控 节点机IP: 10.10.48.116 JVM_FullGC次数最近2分钟求平均 >= 5.0 次, 当前值5.0000 次
- 12:28,其它业务check过,没有明显异常。除个别业务在查询tableStore时也会出现503的报错
- 12:41,申请运维同学再加两个pod。增加可用pod数
- 12:50,添加pod后,重启没有停止。
- 13:07,查看是否有OOM。没有
- 13:22,收到阿里tableStore的同学反馈,503的原因是索引查询用的索引不是覆盖索引, 反查主表压力过大引起的5XX错误
- 13:23,把涉及的查询的定时任务都停掉
- 13:30, JVM_FullGC和pod重启告警 没有停止
- 13:40,看到是full GC告警,增加Pod和JVM堆内存各4G,并重新发版
- 13:42,重新发版完成。JVM_FullGC和pod重启告警都消失
- 14:00,把之前停止的定时任务启动
服务不稳定状态时堆内存及GC情况
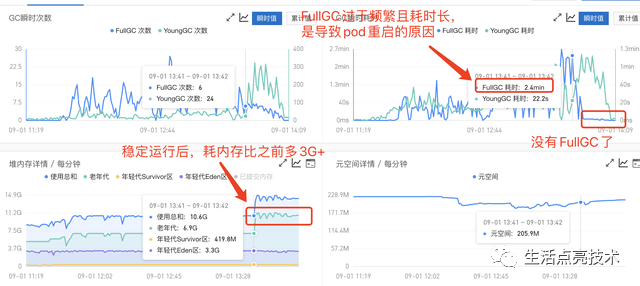
故障原因
出现占用大内存的操作,导致FullGC频繁。
原因分析
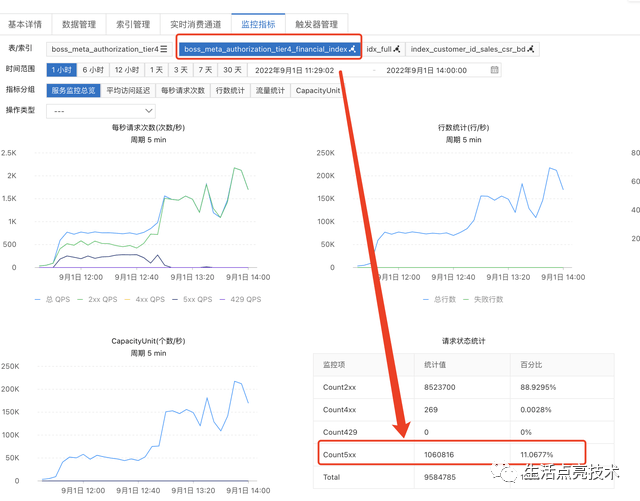
- 是不是TableStore的异常导致服务异常
- 不是。看查询报错的请求低于12%
ots的报错情况
pod为什么会重启
Full GC耗时过长,导致容器判定pod异常,并将其重启。
异常期间,pod存活探测的规则如下:
livenessProbe: # 存活探测的相关配置如下
httpGet:
path: /ready
port: http
initialDelaySeconds: 180
periodSeconds: 10 # 每隔10s探测一次
timeoutSeconds: 1 # 如果/ready接口1s内没有返回,则判断失败
successThreshold: 1
failureThreshold: 3 # 连续失败3次,则判断pod异常。容器重启pod
FullGC时会STW,此时所有请求都会阻塞。
FullGC耗时超过30s,pod就会重启。异常期间FullGC耗时都超过120s了。按配置的规则,容器会重启该pod
FullGC超过30s,则容器会将pod重启

- 为什么会触发FullGC
出现了耗内存的操作。
TableStore服务器返回的数据,占用大量内存
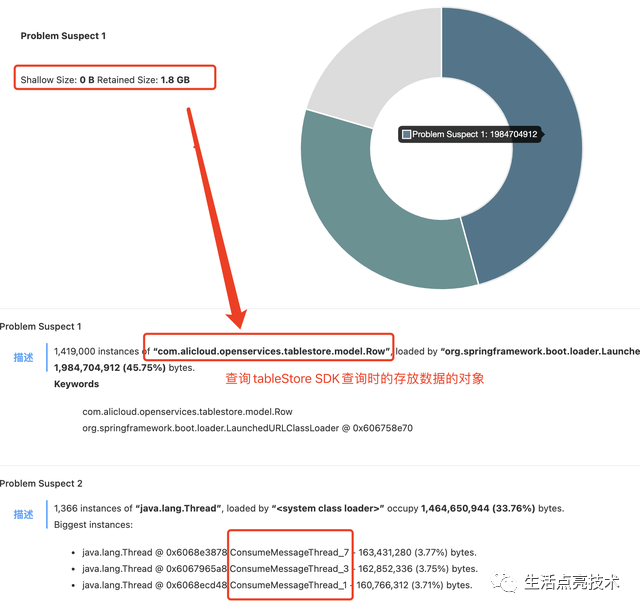
新加的查询TableStore的业务线程
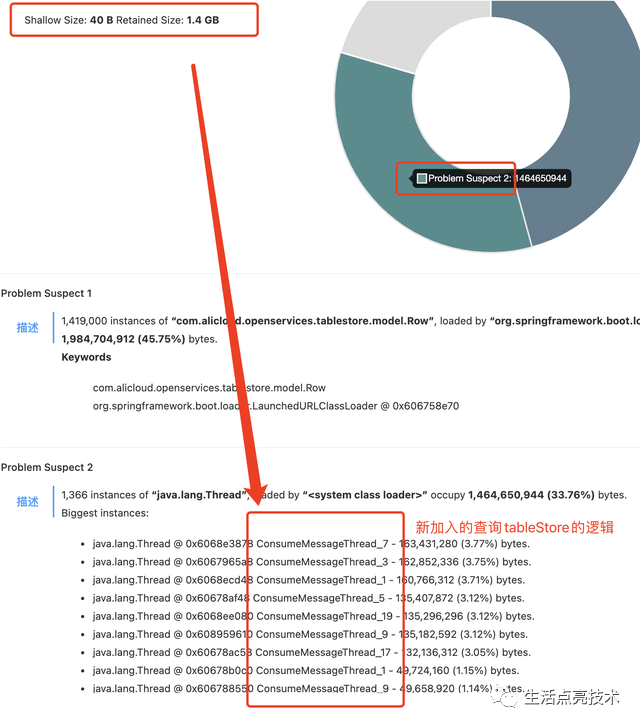
- 上述业务占用内存是否合理
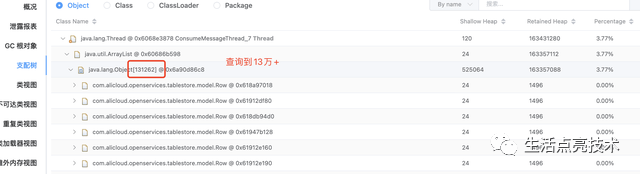
不合理。从业务上看,每次查询符合条件的记录最多不会超过100条。但现在返回了131262条
返回的数据量过多,核对过代码,发现查询条件错误。查询tableStore的三个条件应该是and的关系,但现在是or。
- 这么严重的逻辑错误,为什么会出现?
存在错误逻辑是2020年上线的老代码。写新功能的同学,直接copy过去。想着是两年前的线上代码,code reivew就没有作为重点,具体过程,相关的同学都不记得了。
- 这么严重的逻辑错误,为什么之前服务没有出现这种问题?
之前的服务也是有问题的。老代码由一个定时任务触发。只是串行查询TableStore,虽然会耗内存,但如果正在执行的pod没有其它在执行的耗内存操作,是不会触发FullGC的。这也可能是当前应用偶发出现重启的原因。
新业务场景是接收到mq消息然后根据条件去触发这段老代码,当同时接收n个消息,则占用的内存*n ,则很容易触发FullGC
-
新功能上线快1周了,为什么今天才触发此异常
在查询TableStore,需要满足条件才会触发有异常的老代码。异常时,触发异常逻辑的的业务数据较多。 -
测试环节为什么没有发现
case没有全部覆盖业务场景。当三个and的筛选条件被错写成or,查到的数据会变多。目前的这个场景所涉及到的查询结果数据,被用于数据权限控制,返回的数据变多时造成的问题是,该看到该数据的人可以看到,不该看到该数据的也可以看到。
如果测试case只有一个:该查看数据的人是否可以查看。那么,测试是通过的。
小结
- 异常出现时,一象限的操作
- 如果pod重启时,是qps增高,则优先增加Pod
- 如果pod重启时,识别到FullGC耗时过长,则优先考虑增加内存来解决
- 出现异常时,要把jvm堆内的数据dump出来。在没有找到异常原因时,要把dump出来的堆数据都查看一下,因为dump时,有的pod中的jvm可能刚启动不久,异常操作还没有被触发。
- 异常出现后,二象限的操作
- 已经在线的代码,如果新功能涉及到,尽量不要copy
- 已经在线的代码,如果新功能涉及到,也要CodeReview
- 待上线的代码,要测试充分
- 待上线的功能,关键路径,测试Case要全面
- 增加jvm堆内存的告警,如果超过80%时就告警,然后dump出Heap内的数据进行分析
- 每个迭代确保用于技术优化的时间。目前这部分有一个bug需要解决:当前的规则中,需求的优先级是由产品决定,一个技术需求如果产品把优先级降低,如果引发故障,产品却不需要承担责任。需要推动这个事情解决,保持权责利一致,做多大的决定,就需要负多大的责任,也享受多大的利好。
- 待解决的问题
- FullGC耗时过长的原因及解决办法


