MappedByteBuffer VS FileChannel:从内核层面对比两者的性能差异原创
本文基于 Linux 内核 5.4 版本进行讨论
自上篇文章《从 Linux 内核角度探秘 JDK MappedByteBuffer》 发布之后,很多读者朋友私信我说,文章的信息量太大了,其中很多章节介绍的内容都是大家非常想要了解,并且是频繁被搜索的内容,所以根据读者朋友的建议,笔者决定将一些重要的章节内容独立出来,更好的方便大家检索。
关于 MappedByteBuffer 和 FileChannel 的话题,网上有很多,但大部分都在讨论 MappedByteBuffer 相较于传统 FileChannel 的优势,但好像很少有人来写一写 MappedByteBuffer 的劣势,所以笔者这里想写一点不一样的,来和大家讨论讨论 MappedByteBuffer 的劣势有哪些。
但在开始讨论这个话题之前,笔者想了想还是不能免俗,仍然需要把 MappedByteBuffer 和 FileChannel 放在一起从头到尾对比一下,基于这个思路,我们先来重新简要梳理一下 FileChannel 和 MappedByteBuffer 读写文件的流程。
1. FileChannel 读写文件过程
在之前的文章《从 Linux 内核角度探秘 JDK NIO 文件读写本质》中,由于当时我们还未介绍 DirectByteBuffer 以及 MappedByteBuffer,所以笔者以 HeapByteBuffer 为例来介绍 FileChannel 读写文件的整个源码实现逻辑。
当我们使用 HeapByteBuffer 传入 FileChannel 的 read or write 方法对文件进行读写时,JDK 会首先创建一个临时的 DirectByteBuffer,对于 FileChannel#read 来说,JDK 在 native 层会将 read 系统调用从文件中读取的内容首先存放到这个临时的 DirectByteBuffer 中,然后在拷贝到 HeapByteBuffer 中返回。
对于 FileChannel#write 来说,JDK 会首先将 HeapByteBuffer 中的待写入数据拷贝到临时的 DirectByteBuffer 中,然后在 native 层通过 write 系统调用将 DirectByteBuffer 中的数据写入到文件的 page cache 中。
public class IOUtil {
static int read(FileDescriptor fd, ByteBuffer dst, long position,
NativeDispatcher nd)
throws IOException
{
// 如果我们传入的 dst 是 DirectBuffer,那么直接进行文件的读取
// 将文件内容读取到 dst 中
if (dst instanceof DirectBuffer)
return readIntoNativeBuffer(fd, dst, position, nd);
// 如果我们传入的 dst 是一个 HeapBuffer,那么这里就需要创建一个临时的 DirectBuffer
// 在调用 native 方法底层利用 read or write 系统调用进行文件读写的时候
// 传入的只能是 DirectBuffer
ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining());
try {
// 底层通过 read 系统调用将文件内容拷贝到临时 DirectBuffer 中
int n = readIntoNativeBuffer(fd, bb, position, nd);
if (n > 0)
// 将临时 DirectBuffer 中的文件内容在拷贝到 HeapBuffer 中返回
dst.put(bb);
return n;
}
}
static int write(FileDescriptor fd, ByteBuffer src, long position,
NativeDispatcher nd) throws IOException
{
// 如果传入的 src 是 DirectBuffer,那么直接将 DirectBuffer 中的内容拷贝到文件 page cache 中
if (src instanceof DirectBuffer)
return writeFromNativeBuffer(fd, src, position, nd);
// 如果传入的 src 是 HeapBuffer,那么这里需要首先创建一个临时的 DirectBuffer
ByteBuffer bb = Util.getTemporaryDirectBuffer(rem);
try {
// 首先将 HeapBuffer 中的待写入内容拷贝到临时的 DirectBuffer 中
// 随后通过 write 系统调用将临时 DirectBuffer 中的内容写入到文件 page cache 中
int n = writeFromNativeBuffer(fd, bb, position, nd);
return n;
}
}
}
当时有很多读者朋友给我留言提问说,为什么必须要在 DirectByteBuffer 中做一次中转,直接将 HeapByteBuffer 传给 native 层不行吗 ?
答案是肯定不行的,在本文开头笔者为大家介绍过 JVM 进程的虚拟内存空间布局,如下图所示:
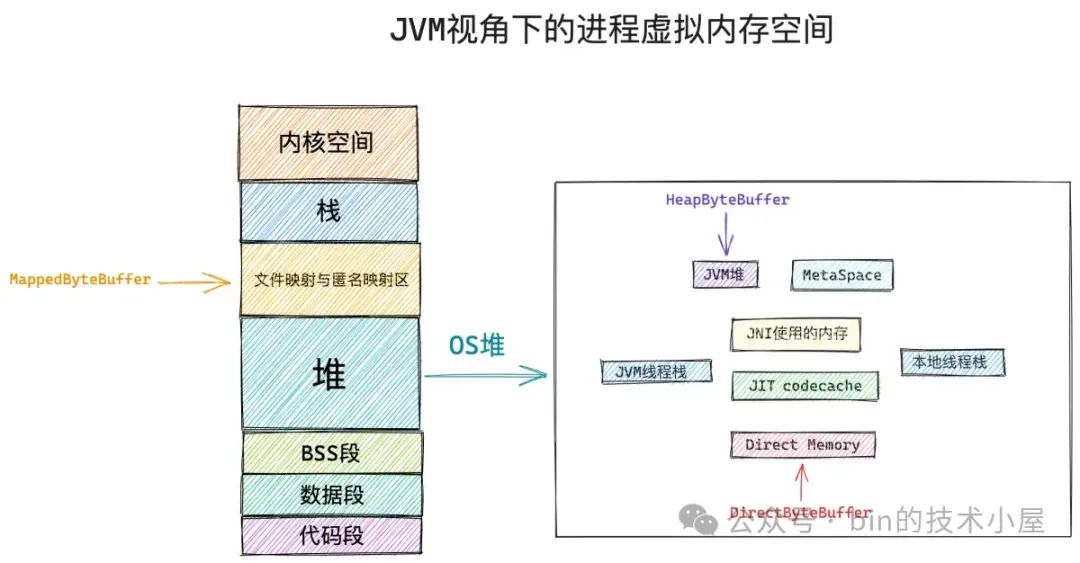
HeapByteBuffer 和 DirectByteBuffer 从本质上来说均是 JVM 进程地址空间内的一段虚拟内存,对于 Java 程序来说 HeapByteBuffer 被用来特定表示 JVM 堆中的内存,而 DirectByteBuffer 就是一个普通的 C++ 程序通过 malloc 系统调用向操作系统申请的一段 Native Memory 位于 JVM 堆之外。
既然 HeapByteBuffer 是位于 JVM 堆中的内存,那么它必然会受到 GC 的管理,当发生 GC 的时候,如果我们选择的垃圾回收器采用的是 Mark-Copy 或者 Mark-Compact 算法的时候(Mark-Swap 除外),GC 会来回移动存活的对象,这就导致了存活的 Java 对象比如这里的 HeapByteBuffer 在 GC 之后它背后的内存地址可能已经发生了变化。
而 JVM 中的这些 native 方法是处于 safepoint 之下的,执行 native 方法的线程由于是处于 safepoint 中,所以在执行 native 方法的过程中可能会有 GC 的发生。
如果我们把一个 HeapByteBuffer 传递给 native 层进行文件读写的时候不巧发生了 GC,那么 HeapByteBuffer 背后的内存地址就会变化,这样一来,如果我们在读取文件的话,内核将会把文件内容拷贝到另一个内存地址中。如果我们在写入文件的话,内核将会把另一个内存地址中的内存写入到文件的 page cache 中。
所以我们在通过 native 方法执行相关系统调用的时候必须要保证传入的内存地址是不会变化的,由于 DirectByteBuffer 背后所依赖的 Native Memory 位于 JVM 堆之外,是不会受到 GC 管理的,因此不管发不发生 GC,DirectByteBuffer 所引用的这些 Native Memory 地址是不会发生变化的。
所以我们在调用 native 方法进行文件读写的时候需要传入 DirectByteBuffer,如果我们用得是 HeapByteBuffer ,那么就需要一个临时的 DirectByteBuffer 作为中转。
这时可能有读者朋友又会问了,我们在使用 HeapByteBuffer 通过 FileChannel#write 对文件进行写入的时候,首先会将 HeapByteBuffer 中的内容拷贝到临时的 DirectByteBuffer 中,那如果在这个拷贝的过程中发生了 GC,HeapByteBuffer 背后引用内存的地址发生了变化,那么拷贝到 DirectByteBuffer 中的内容仍然是错的啊。
事实上在这个拷贝的过程中是不会发生 GC 的,因为 JVM 这里会使用 Unsafe#copyMemory 方法来实现 HeapByteBuffer 到 DirectByteBuffer 的拷贝操作,copyMemory 被 JVM 实现为一个 intrinsic 方法,中间是没有 safepoint 的,执行 copyMemory 的线程由于不在 safepoint 中,所以在拷贝的过程中是不会发生 GC 的。
public final class Unsafe {
// intrinsic 方法
public native void copyMemory(Object srcBase, long srcOffset,
Object destBase, long destOffset,
long bytes);
}
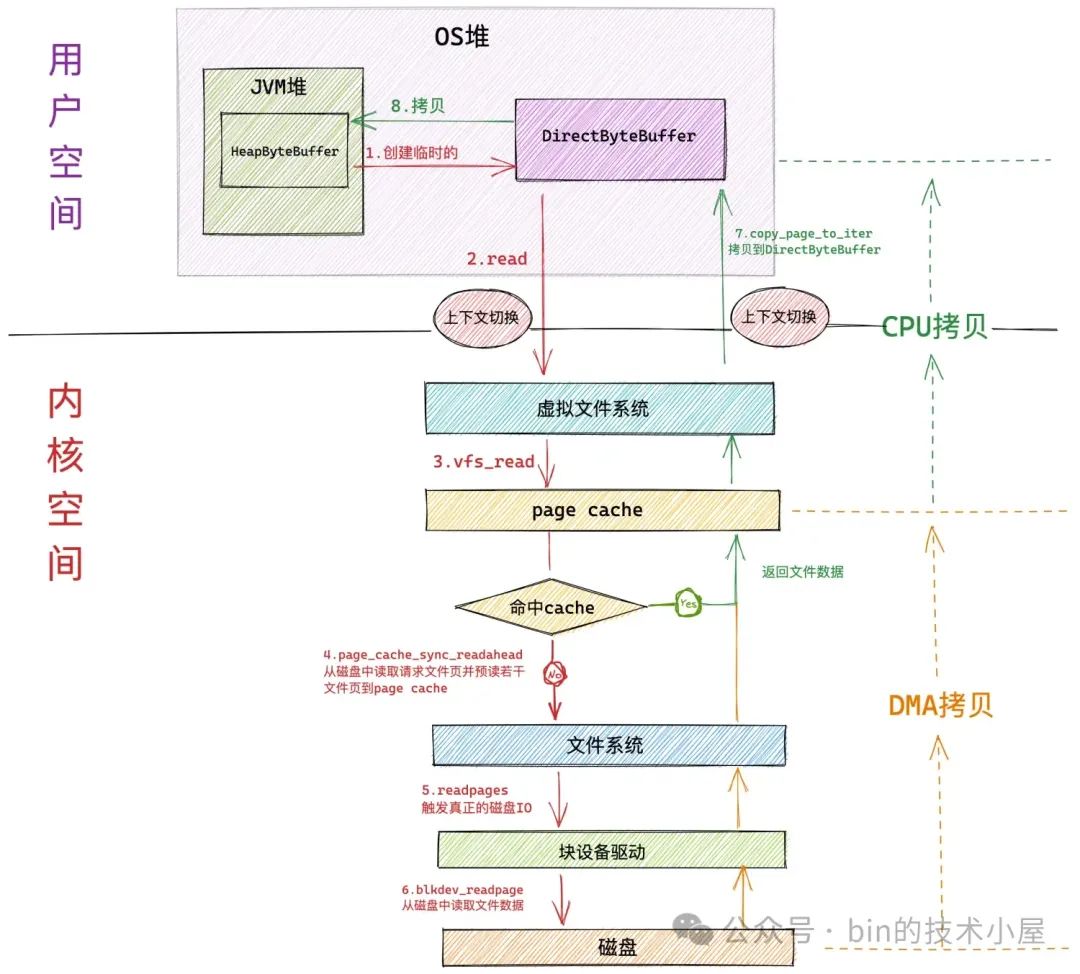
在交代完这个遗留的问题之后,下面我们就以 DirectByteBuffer 为例来重新简要回顾下传统 FileChannel 对文件的读写流程:
-
当 JVM 在 native 层使用 read 系统调用进行文件读取的时候,JVM 进程会发生第一次上下文切换,从用户态转为内核态。
-
随后 JVM 进程进入虚拟文件系统层,在这一层内核首先会查看读取文件对应的 page cache 中是否含有请求的文件数据,如果有,那么直接将文件数据拷贝到 DirectByteBuffer 中返回,避免一次磁盘 IO。并根据内核预读算法从磁盘中异步预读若干文件数据到 page cache 中
-
如果请求的文件数据不在 page cache 中,则会进入具体的文件系统层,在这一层内核会启动磁盘块设备驱动触发真正的磁盘 IO。并根据内核预读算法同步预读若干文件数据。请求的文件数据和预读的文件数据将被一起填充到 page cache 中。
-
磁盘控制器 DMA 将从磁盘中读取的数据拷贝到页高速缓存 page cache 中。发生第一次数据拷贝。
-
由于 page cache 是属于内核空间的,不能被 JVM 进程直接寻址,所以还需要 CPU 将 page cache 中的数据拷贝到位于用户空间的 DirectByteBuffer 中,发生第二次数据拷贝。
-
最后 JVM 进程从系统调用 read 中返回,并从内核态切换回用户态。发生第二次上下文切换。
从以上过程我们可以看到,当使用 FileChannel#read 对文件读取的时候,如果文件数据在 page cache 中,涉及到的性能开销点主要有两次上下文切换,以及一次 CPU 拷贝。其中上下文切换是主要的性能开销点。
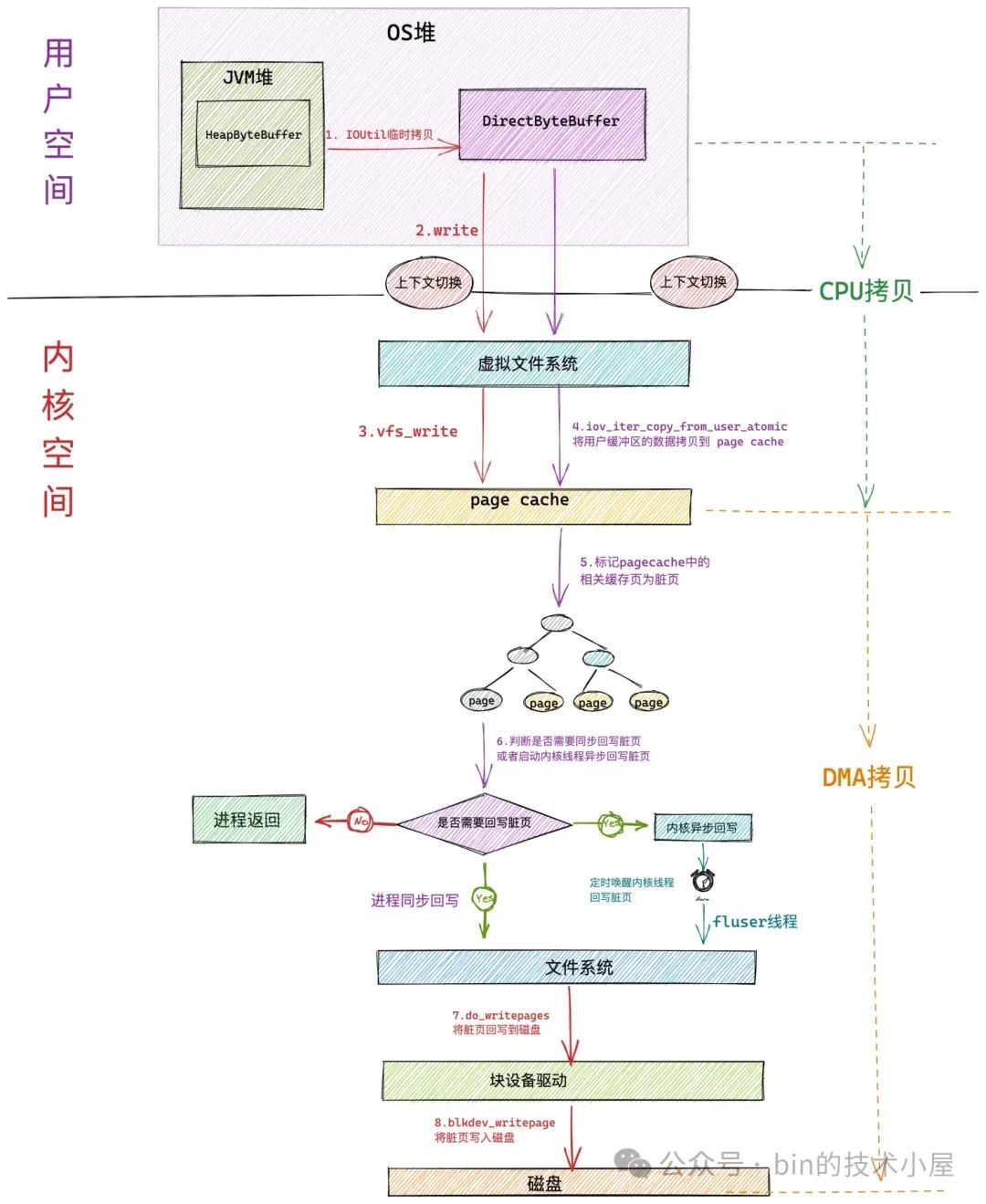
下面是通过 FileChannel#write 写入文件的整个过程:
-
当 JVM 在 native 层使用 write 系统调用进行文件写入的时候,JVM 进程会发生第一次上下文切换,从用户态转为内核态。
-
进入内核态之后,JVM 进程在虚拟文件系统层调用 vfs_write 触发对 page cache 写入的操作。内核调用 iov_iter_copy_from_user_atomic 函数将 DirectByteBuffer 中的待写入数据拷贝到 page cache 中。发生第一次拷贝动作( CPU 拷贝)。
-
当待写入数据拷贝到 page cache 中时,内核会将对应的文件页标记为脏页,内核会根据一定的阈值判断是否要对 page cache 中的脏页进行回写,如果不需要同步回写,进程直接返回。这里发生第二次上下文切换。
-
脏页回写又会根据脏页数量在内存中的占比分为:进程同步回写和内核异步回写。当脏页太多了,进程自己都看不下去的时候,会同步回写内存中的脏页,直到回写完毕才会返回。在回写的过程中会发生第二次拷贝(DMA 拷贝)。
从以上过程我们可以看到,当使用 FileChannel#write 对文件写入的时候,如果不考虑脏页回写的情况,单纯对于 JVM 这个进程来说涉及到的性能开销点主要有两次上下文切换,以及一次 CPU 拷贝。其中上下文切换仍然是主要的性能开销点。
2. MappedByteBuffer 读写文件过程
下面我们来看下通过 MappedByteBuffer 对文件进行读写的过程:
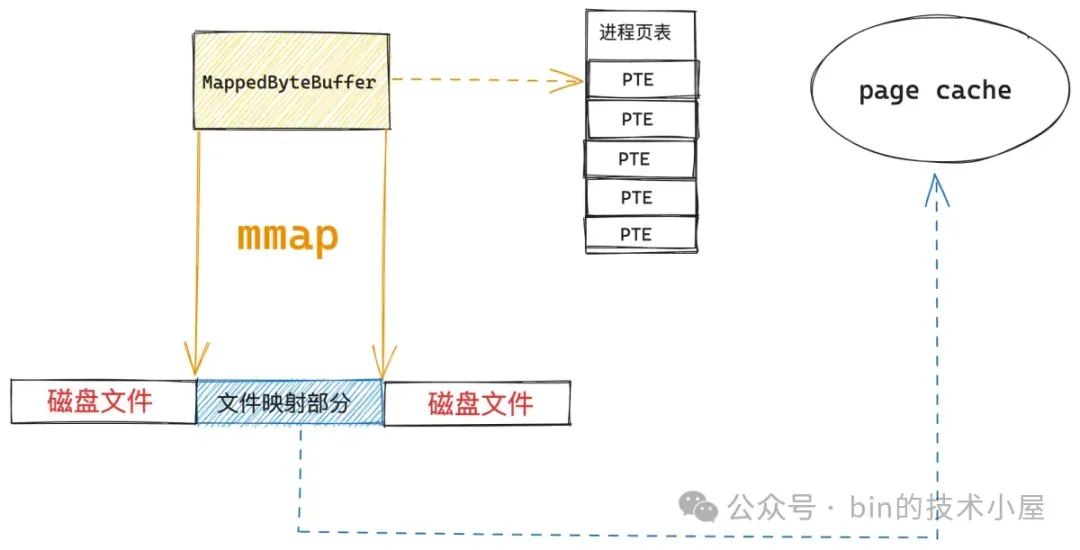
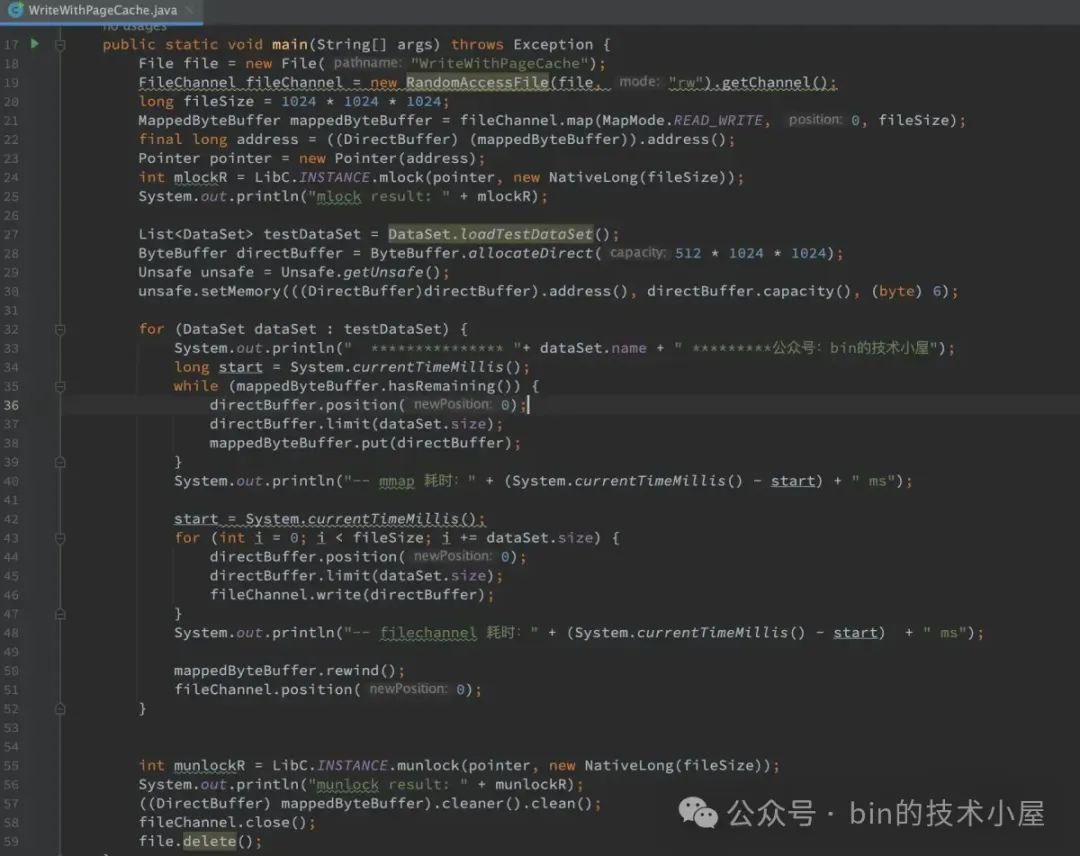
首先我们需要通过 FileChannel#map 将文件的某个区域映射到 JVM 进程的虚拟内存空间中,从而获得一段文件映射的虚拟内存区域 MappedByteBuffer。由于底层使用到了 mmap 系统调用,所以这个过程也涉及到了两次上下文切换。
如上图所示,当 MappedByteBuffer 在刚刚映射出来的时候,它只是进程地址空间中的一段虚拟内存,其对应在进程页表中的页表项还是空的,背后还没有映射物理内存。此时映射文件对应的 page cache 也是空的,我们要映射的文件内容此时还静静地躺在磁盘中。
当 JVM 进程开始对 MappedByteBuffer 进行读写的时候,就会触发缺页中断,内核会将映射的文件内容从磁盘中加载到 page cache 中,然后在进程页表中建立 MappedByteBuffer 与 page cache 的映射关系。由于这里涉及到了缺页中断的处理,因此也会有两次上下文切换的开销。
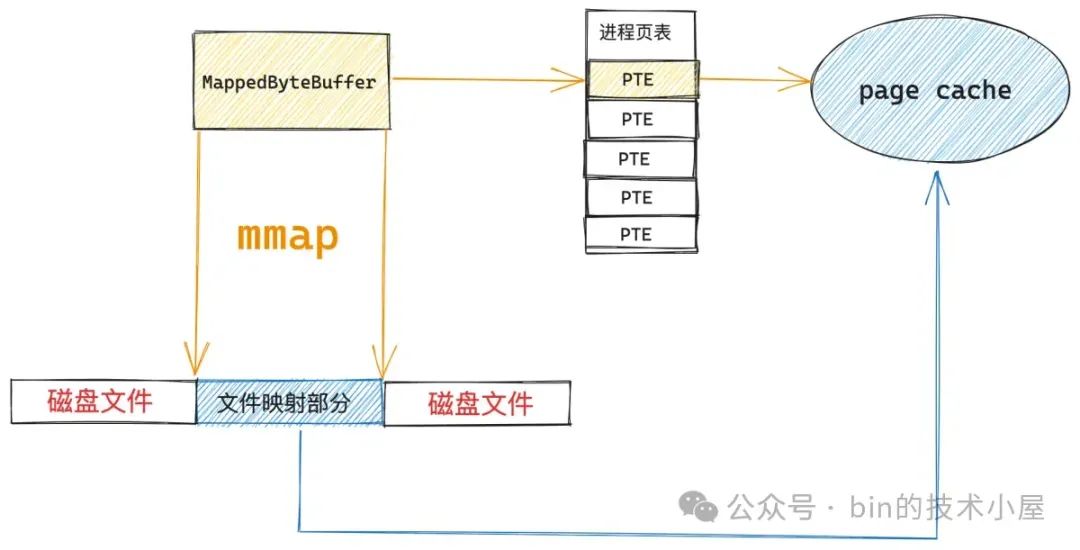
后面 JVM 进程对 MappedByteBuffer 的读写就相当于是直接读写 page cache 了,关于这一点,很多读者朋友会有这样的疑问:page cache 是内核态的部分,为什么我们通过用户态的 MappedByteBuffer 就可以直接访问内核态的东西了?
这里大家不要被内核态这三个字给唬住了,虽然 page cache 是属于内核部分的,但其本质上还是一块普通的物理内存,想想我们是怎么访问内存的 ? 不就是先有一段虚拟内存,然后在申请一段物理内存,最后通过进程页表将虚拟内存和物理内存映射起来么,进程在访问虚拟内存的时候,通过页表找到其映射的物理内存地址,然后直接通过物理内存地址访问物理内存。
回到我们讨论的内容中,这段虚拟内存不就是 MappedByteBuffer 吗,物理内存就是 page cache 啊,在通过页表映射起来之后,进程在通过 MappedByteBuffer 访问 page cache 的过程就和访问普通内存的过程是一模一样的。
也正因为 MappedByteBuffer 背后映射的物理内存是内核空间的 page cache,所以它不会消耗任何用户空间的物理内存(JVM 的堆外内存),因此也不会受到 -XX:MaxDirectMemorySize 参数的限制。
3. MappedByteBuffer VS FileChannel
现在我们已经清楚了 FileChannel 以及 MappedByteBuffer 进行文件读写的整个过程,下面我们就来把两种文件读写方式放在一起来对比一下,但这里有一个对比的前提:
-
对于 MappedByteBuffer 来说,我们对比的是其在缺页处理之后,读写文件的开销。
-
对于 FileChannel 来说,我们对比的是文件数据已经存在于 page cache 中的情况下读写文件的开销。
因为笔者认为只有基于这个前提来对比两者的性能差异才有意义。
-
对于 FileChannel 来说,无论是通过 read 方法对文件的读取,还是通过 write 方法对文件的写入,它们都需要两次上下文切换,以及一次 CPU 拷贝,其中上下文切换是其主要的性能开销点。
-
对于 MappedByteBuffer 来说,由于其背后直接映射的就是 page cache,读写 MappedByteBuffer 本质上就是读写 page cache,整个读写过程和读写普通的内存没有任何区别,因此没有上下文切换的开销,不会切态,更没有任何拷贝。
从上面的对比我们可以看出使用 MappedByteBuffer 来读写文件既没有上下文切换的开销,也没有数据拷贝的开销(可忽略),简直是完爆 FileChannel。
既然 MappedByteBuffer 这么*,那我们何不干脆在所有文件的读写场景中全部使用 MappedByteBuffer,这样岂不省事 ?JDK 为何还保留了 FileChannel 的 read , write 方法呢 ?让我们来带着这个疑问继续下面的内容~~
4. 通过 Benchmark 从内核层面对比两者的性能差异
到现在为止,笔者已经带着大家完整的剖析了 mmap,read,write 这些系统调用在内核中的源码实现,并基于源码对 MappedByteBuffer 和 FileChannel 两者进行了性能开销上的对比。
虽然祭出了源码,但毕竟还是 talk is cheap,本小节我们就来对两者进行一次 Benchmark,来看一下 MappedByteBuffer 与 FileChannel 对文件读写的实际性能表现如何 ? 是否和我们从源码中分析的结果一致。
我们从两个方面来对比 MappedByteBuffer 和 FileChannel 的文件读写性能:
-
文件数据完全加载到 page cache 中,并且将 page cache 锁定在内存中,不允许 swap,MappedByteBuffer 不会有缺页中断,FileChannel 不会触发磁盘 IO 都是直接对 page cache 进行读写。
-
文件数据不在 page cache 中,我们加上了 缺页中断,磁盘IO,以及 swap 对文件读写的影响。
具体的测试思路是,用 MappedByteBuffer 和 FileChannel 分别以 64B ,128B ,512B ,1K ,2K ,4K ,8K ,32K ,64K ,1M ,32M ,64M ,512M 为单位依次对 1G 大小的文件进行读写,从以上两个方面对比两者在不同读写单位下的性能表现。
需要提醒大家的是本小节中得出的读写性能具体数值是没有参考价值的,因为不同软硬件环境下测试得出的具体性能数值都不一样,值得参考的是 MappedByteBuffer 和 FileChannel 在不同数据集大小下的读写性能趋势走向。笔者的软硬件测试环境如下:
-
处理器:2.5 GHz 四核Intel Core i7 -
内存:16 GB 1600 MHz DDR3 -
SSD:APPLE SSD SM0512F -
操作系统:macOS -
JVM:OpenJDK 17
测试代码:https://github.com/huibinliupush/benchmark , 大家也可以在自己的测试环境中运行一下,然后将跑出的结果提交到这个仓库中。这样方便大家在不同的测试环境下对比两者的文件读写性能差异 —— 众人拾柴火焰高。
4.1 文件数据在 page cache 中
由于这里我们要测试 MappedByteBuffer 和 FileChannel 直接对 page cache 的读写性能,所以笔者让 MappedByteBuffer ,FileChannel 只针对同一个文件进行读写测试。
在对文件进行读写之前,首先通过 mlock 系统调用将文件数据提前加载到 page cache 中并主动触发缺页处理,在进程页表中建立好 MappedByteBuffer 和 page cache 的映射关系。最后将 page cache 锁定在内存中不允许 swap。
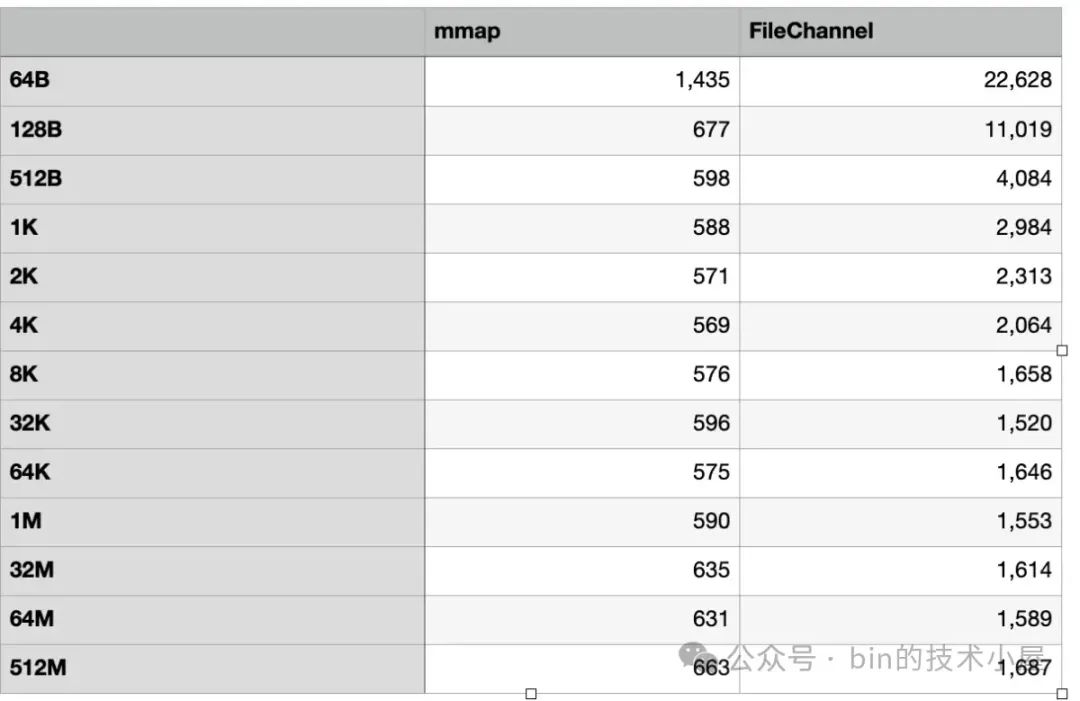
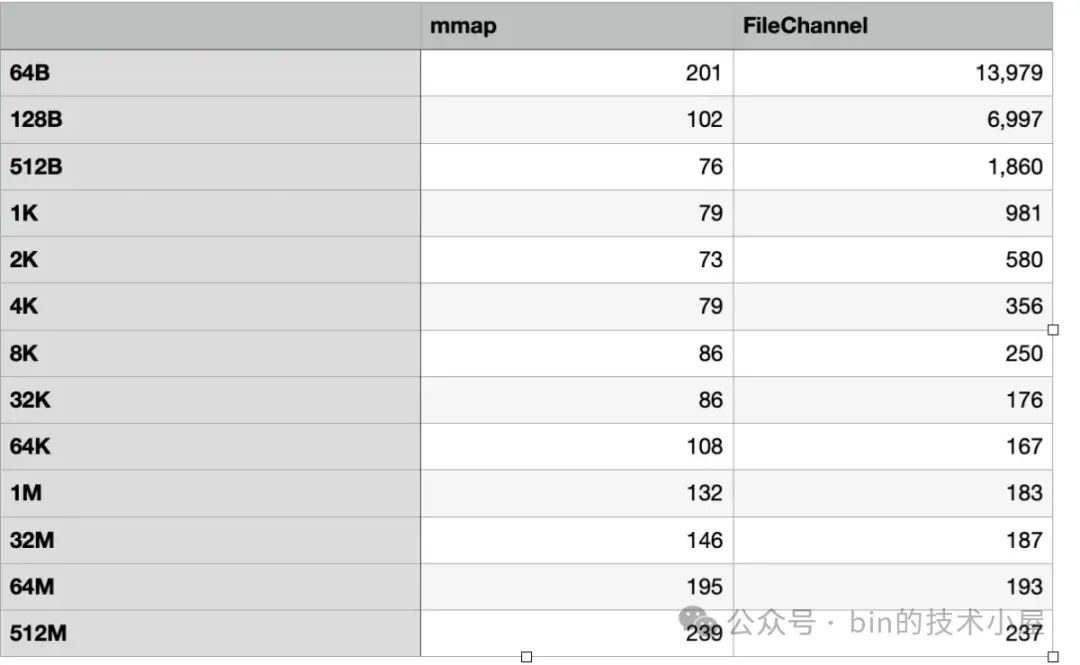
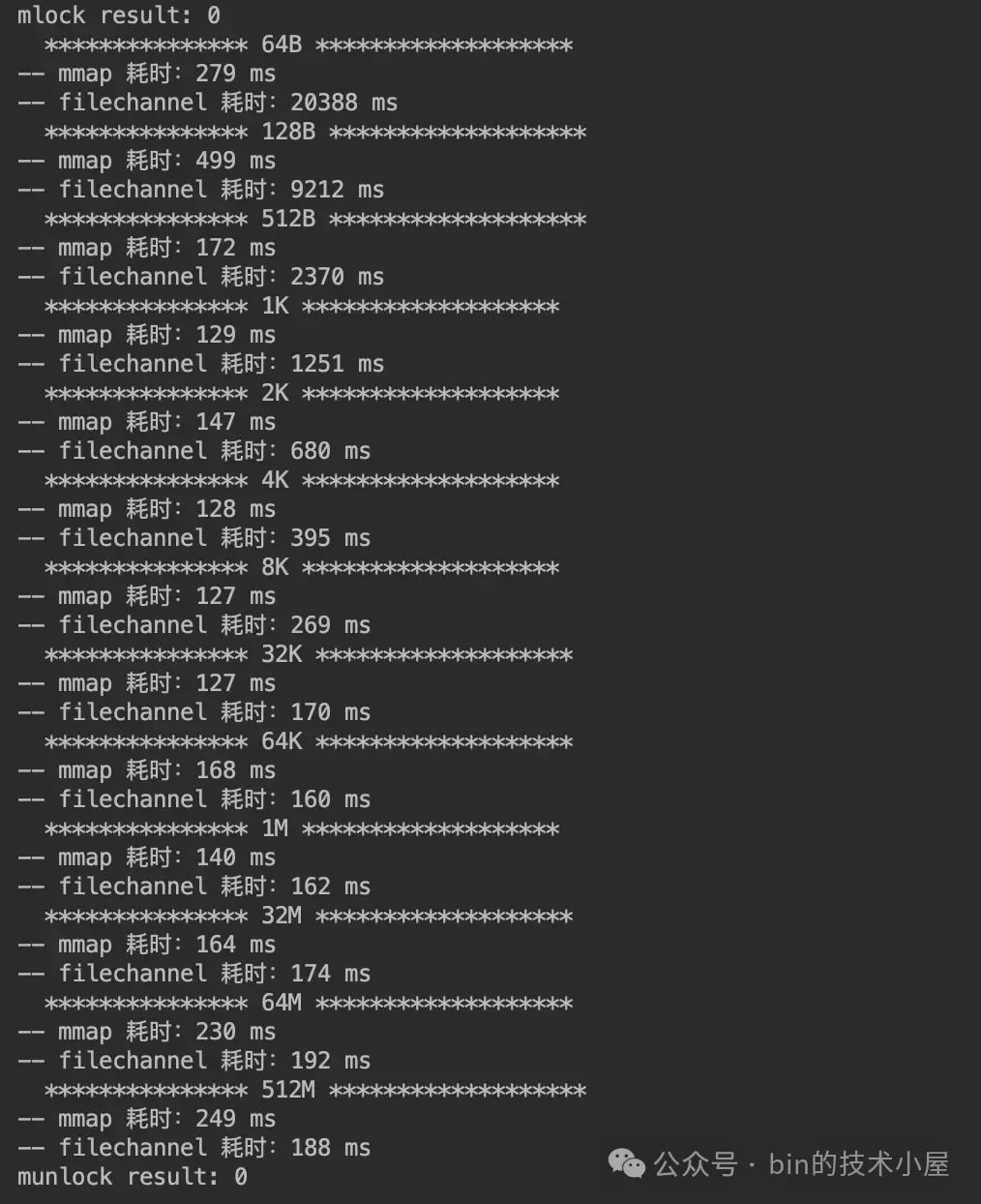
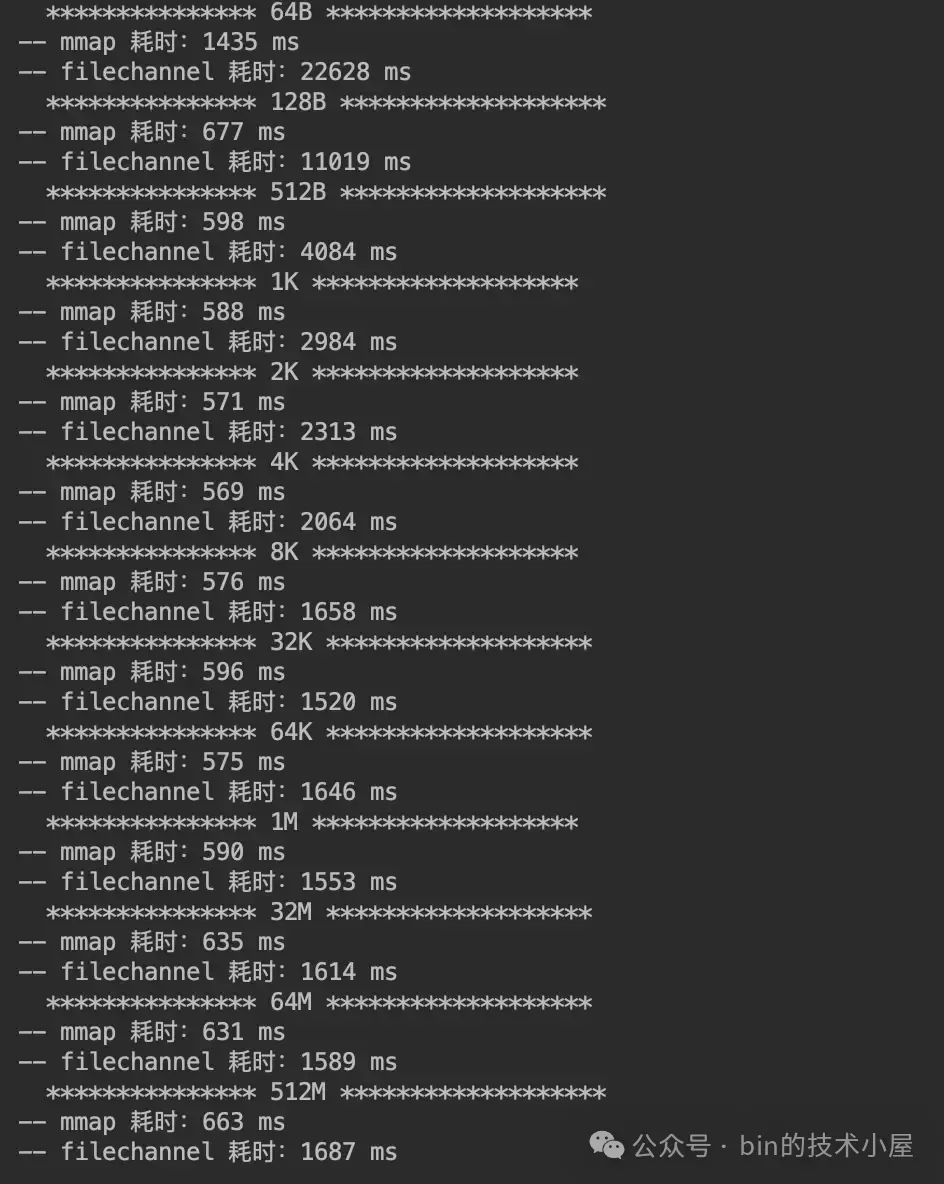
下面是 MappedByteBuffer 和 FileChannel 在不同数据集下对 page cache 的读取性能测试:
运行结果如下:
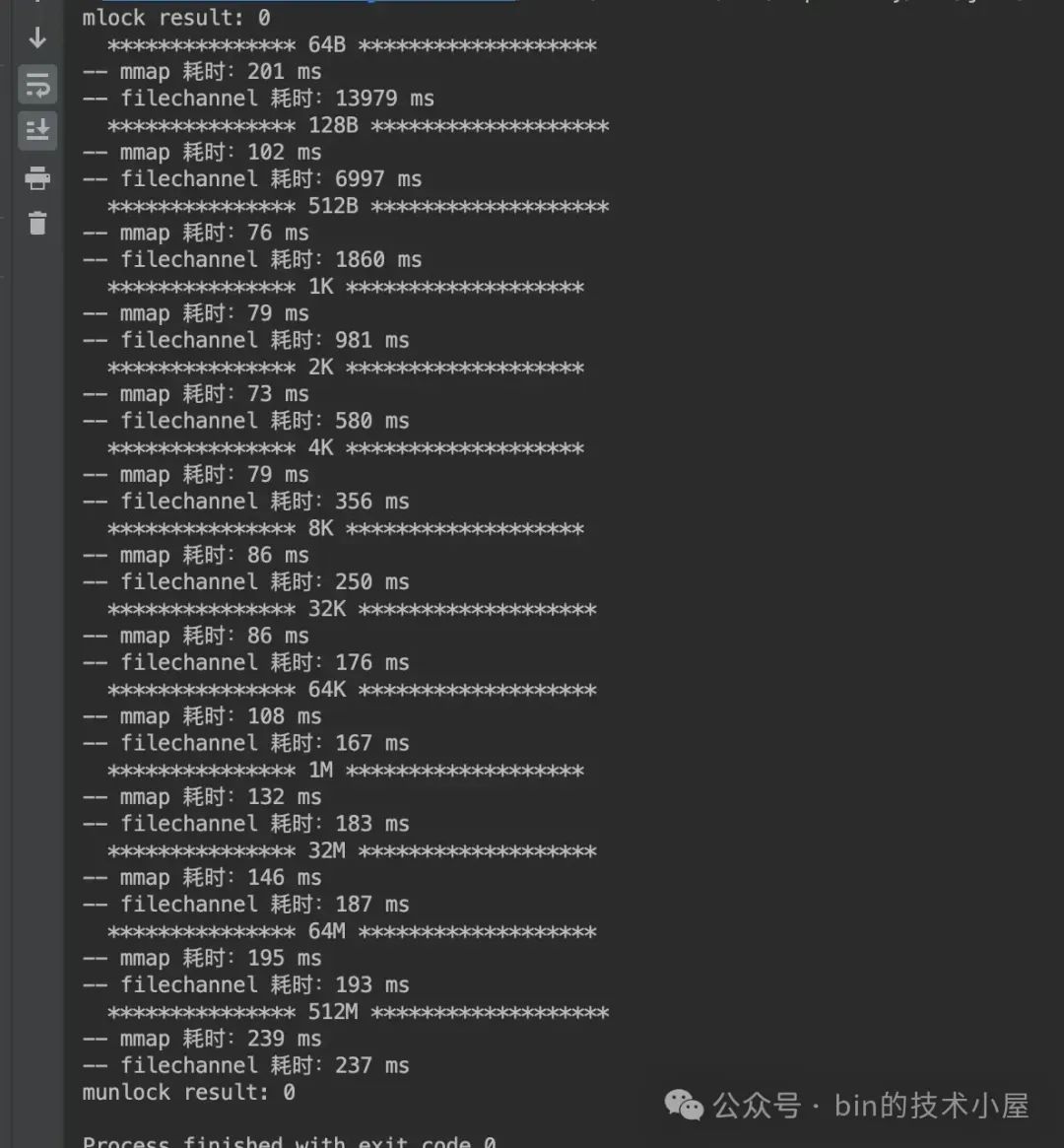
为了直观的让大家一眼看出 MappedByteBuffer 和 FileChannel 在对 page cache 读取的性能差异,笔者根据上面跑出的性能数据绘制成下面这幅柱状图,方便大家观察两者的性能趋势走向。
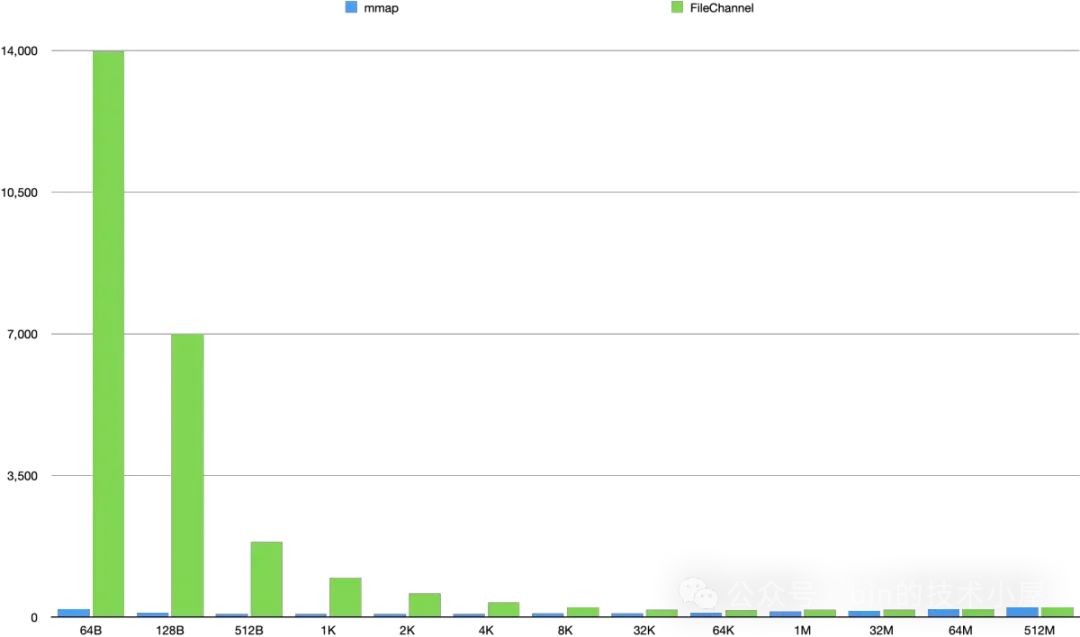
这里我们可以看出,MappedByteBuffer 在 4K 之前具有明显的压倒性优势,在 [8K , 32M] 这个区间内,MappedByteBuffer 依然具有优势但已经不是十分明显了,从 64M 开始 FileChannel 实现了一点点反超。
我们可以得到的性能趋势是,在 [64B, 2K] 这个单次读取数据量级范围内,MappedByteBuffer 读取的性能越来越快,并在 2K 这个数据量级下达到了性能最高值,仅消耗了 73 ms。从 4K 开始读取性能在一点一点的逐渐下降,并在 64M 这个数据量级下被 FileChannel 反超。
而 FileChannel 的读取性能会随着数据量的增大反而越来越好,并在某一个数据量级下性能会反超 MappedByteBuffer。FileChannel 的最佳读取性能点是在 64K 处,消耗了 167ms 。
因此 MappedByteBuffer 适合频繁读取小数据量的场景,具体多小,需要大家根据自己的环境进行测试,本小节我们得出的数据是 4K 以下。
FileChannel 适合大数据量的批量读取场景,具体多大,还是需要大家根据自己的环境进行测试,本小节我们得出的数据是 64M 以上。
下面是 MappedByteBuffer 和 FileChannel 在不同数据集下对 page cache 的写入性能测试:
运行结果如下:
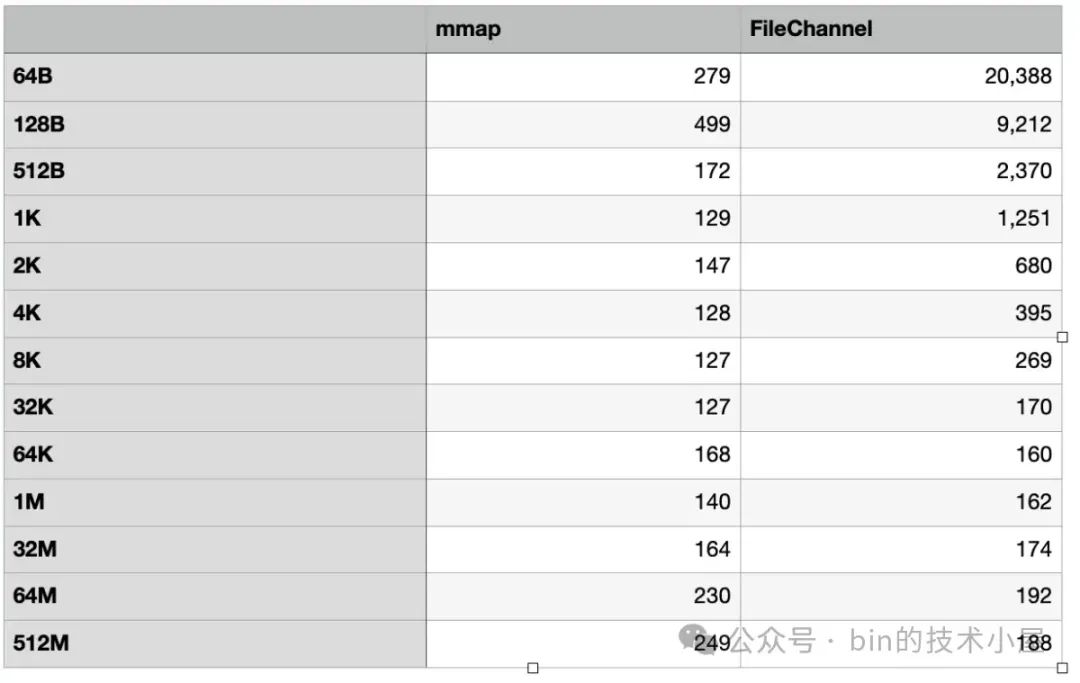
MappedByteBuffer 和 FileChannel 在不同数据集下对 page cache 的写入性能的趋势走向柱状图:
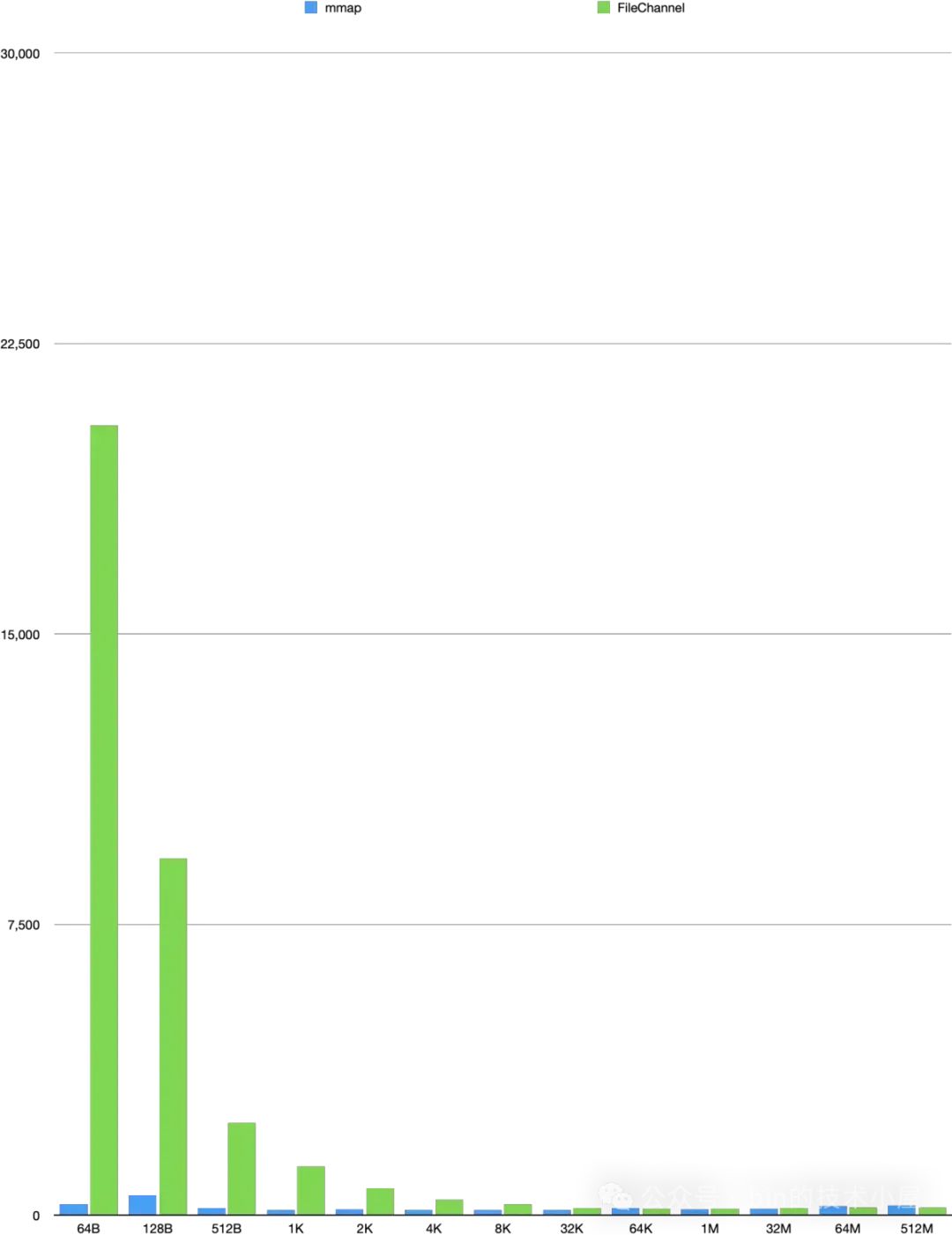
这里我们可以看到 MappedByteBuffer 在 8K 之前具有明显的写入优势,它的写入性能趋势是在 [64B , 8K] 这个数据集方位内,写入性能随着数据量的增大而越来越快,直到在 8K 这个数据集下达到了最佳写入性能。
而在 [32K, 32M] 这个数据集范围内,MappedByteBuffer 仍然具有优势,但已经不是十分明显了,最终在 64M 这个数据集下被 FileChannel 反超。
和前面的读取性能趋势一样,FileChannel 的写入性能也是随着数据量的增大反而越来越好,最佳的写入性能是在 64K 处,仅消耗了 160 ms 。
4.2 文件数据不在 page cache 中
在这一小节中,我们将缺页中断和磁盘 IO 的影响加入进来,不添加任何的优化手段纯粹地测一下 MappedByteBuffer 和 FileChannel 对文件读写的性能。
为了避免被 page cache 影响,所以我们需要在每一个测试数据集下,单独分别为 MappedByteBuffer 和 FileChannel 创建各自的测试文件。
下面是 MappedByteBuffer 和 FileChannel 在不同数据集下对文件的读取性能测试:
运行结果:
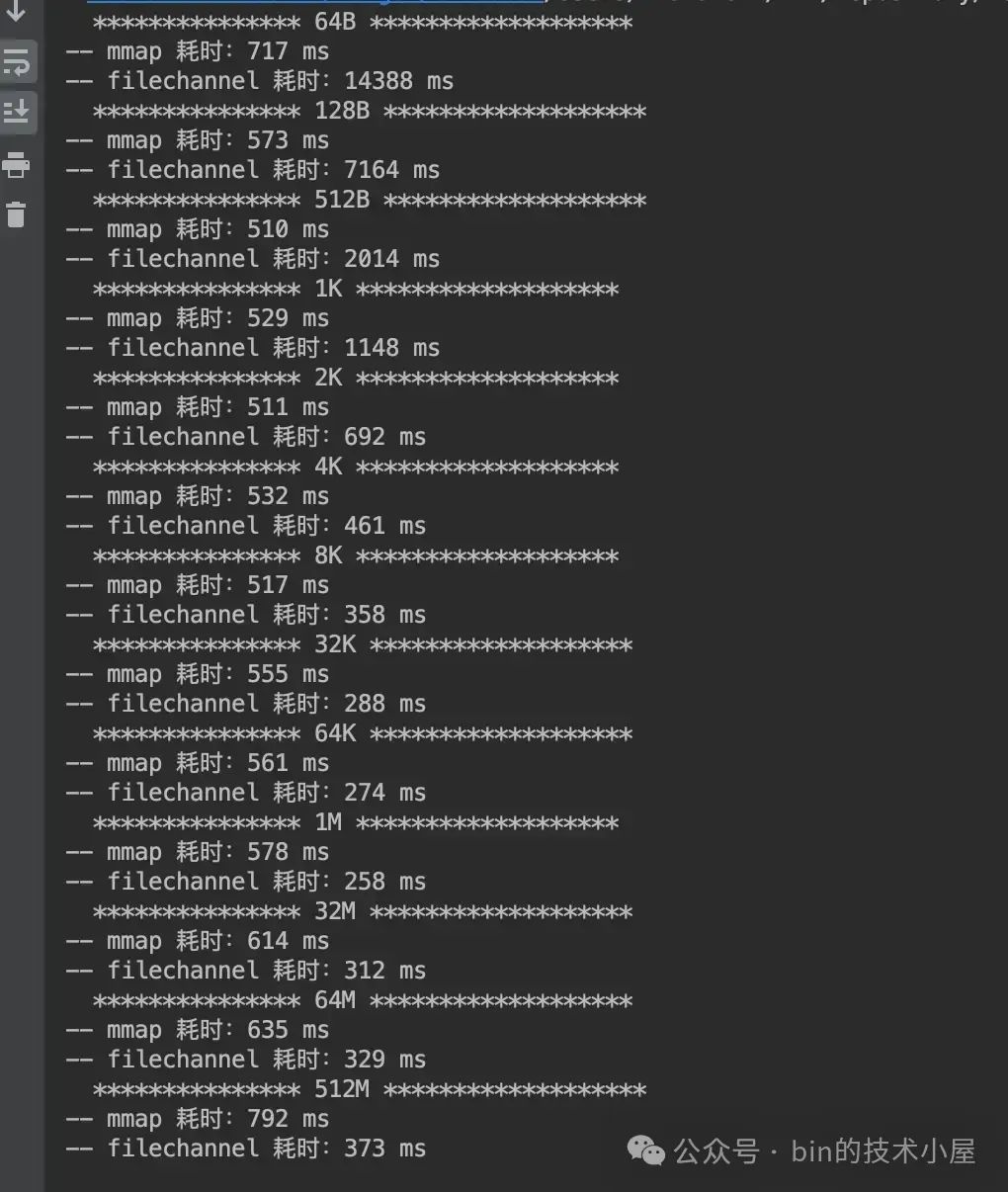
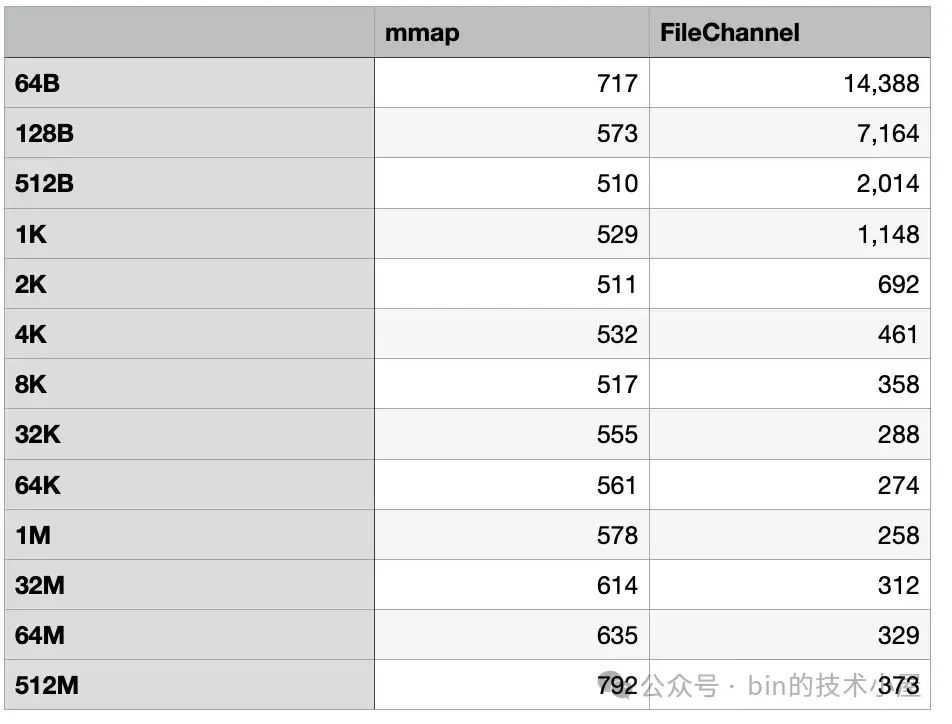
从这里我们可以看到,在加入了缺页中断和磁盘 IO 的影响之后,MappedByteBuffer 在缺页中断的影响下平均比之前多出了 500 ms 的开销。FileChannel 在磁盘 IO 的影响下在 [64B , 512B] 这个数据集范围内比之前平均多出了 1000 ms 的开销,在 [1K, 512M] 这个数据集范围内比之前平均多出了 100 ms 的开销。
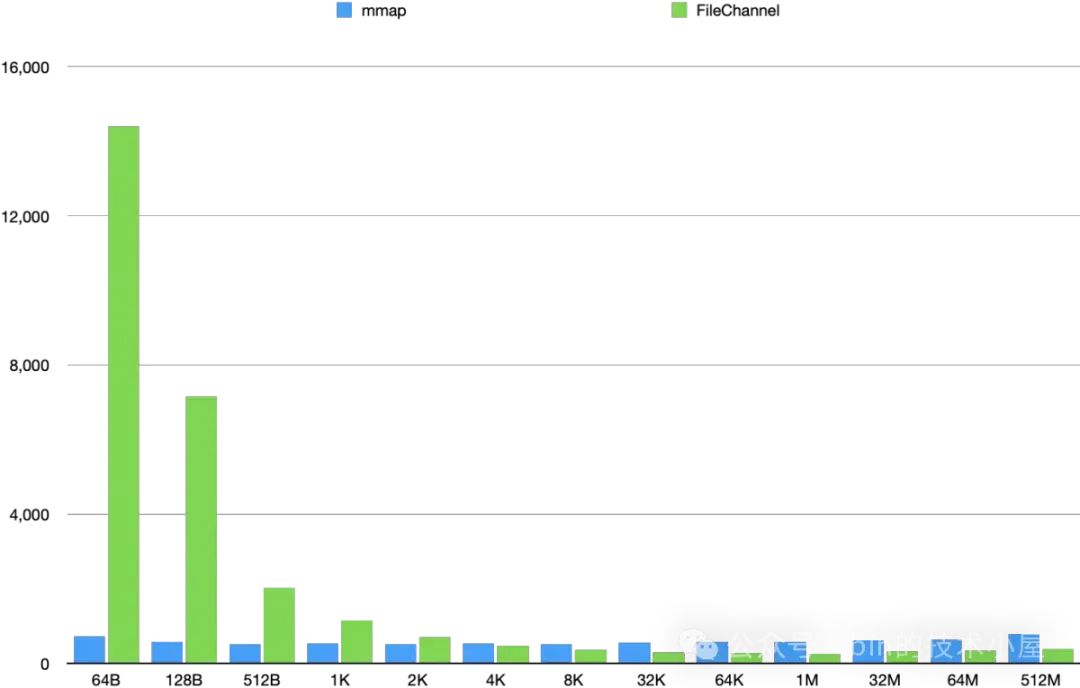
在 2K 之前, MappedByteBuffer 具有明显的读取性能优势,最佳的读取性能出现在 512B 这个数据集下,从 512B 往后,MappedByteBuffer 的读取性能趋势总体成下降趋势,并在 4K 这个地方被 FileChannel 反超。
FileChannel 则是在 [64B, 1M] 这个数据集范围内,读取性能会随着数据集的增大而提高,并在 1M 这个地方达到了 FileChannel 的最佳读取性能,仅消耗了 258 ms,在 [32M , 512M] 这个范围内 FileChannel 的读取性能在逐渐下降,但是比 MappedByteBuffer 的性能高出了一倍。
读到这里大家不禁要问了,理论上来讲 MappedByteBuffer 应该是完爆 FileChannel 才对啊,因为 MappedByteBuffer 没有系统调用的开销,为什么性能在后面反而被 FileChannel 超越了近一倍之多呢 ?
要明白这个问题,我们就需要分别把 MappedByteBuffer 和 FileChannel 在读写文件时候所涉及到的性能开销点一一列举出来,并对这些性能开销点进行详细对比,这样答案就有了。
首先 MappedByteBuffer 的主要性能开销是在缺页中断,而 FileChannel 的主要开销是在系统调用,两者都会涉及上下文的切换。
FileChannel 在读写文件的时候有磁盘IO,有预读。同样 MappedByteBuffer 的缺页中断也有磁盘IO 也有预读。目前来看他俩一比一打平。
但别忘了 MappedByteBuffer 是需要进程页表支持的,在实际访问内存的过程中会遇到页表竞争以及 TLB shootdown 等问题。还有就是 MappedByteBuffer 刚刚被映射出来的时候,其在进程页表中对应的各级页表以及页目录可能都是空的。所以缺页中断这里需要做的一件非常重要的事情就是补齐完善 MappedByteBuffer 在进程页表中对应的各级页目录表和页表,并在页表项中将 page cache 映射起来,最后还要刷新 TLB 等硬件缓存。
想更多了解缺页中断细节的读者可以看下之前的文章——《一文聊透 Linux 缺页异常的处理 —— 图解 Page Faults》
而 FileChannel 并不会涉及上面的这些开销,所以 MappedByteBuffer 的缺页中断要比 FileChannel 的系统调用开销要大,这一点我们可以在上小节和本小节的读写性能对比中看得出来。
文件数据在 page cache 中与不在 page cache 中,MappedByteBuffer 前后的读取性能平均差了 500 ms,而 FileChannel 前后却只平均差了 100 ms。
MappedByteBuffer 的缺页中断是平均每 4K 触发一次,而 FileChannel 的系统调用开销则是每次都会触发。当两者单次按照小数据量读取 1G 文件的时候,MappedByteBuffer 的缺页中断较少触发,而 FileChannel 的系统调用却在频繁触发,所以在这种情况下,FileChannel 的系统调用是主要的性能瓶颈。
这也就解释了当我们在频繁读写小数据量的时候,MappedByteBuffer 的性能具有压倒性优势。当单次读写的数据量越来越大的时候,FileChannel 调用的次数就会越来越少,这时候缺页中断就会成为 MappedByteBuffer 的性能瓶颈,到某一个点之后,FileChannel 就会反超 MappedByteBuffer。因此当我们需要高吞吐量读写文件的时候 FileChannel 反而是最合适的。
除此之外,内核的脏页回写也会对 MappedByteBuffer 以及 FileChannel 的文件写入性能有非常大的影响,无论是我们在用户态中调用 fsync 或者 msync 主动触发脏页回写还是内核通过 pdflush 线程异步脏页回写,当我们使用 MappedByteBuffer 或者 FileChannel 写入 page cache 的时候,如果恰巧遇到文件页的回写,那么写入操作都会有非常大的延迟,这个在 MappedByteBuffer 身上体现的更为明显。
为什么这么说呢 ? 我们还是到内核源码中去探寻原因,先来看脏页回写对 FileChannel 的写入影响。下面是 FileChannel 文件写入在内核中的核心实现:
ssize_t generic_perform_write(struct file *file,
struct iov_iter *i, loff_t pos)
{
// 从 page cache 中获取要写入的文件页并准备记录文件元数据日志工作
status = a_ops->write_begin(file, mapping, pos, bytes, flags,
&page, &fsdata);
// 将用户空间缓冲区 DirectByteBuffer 中的数据拷贝到 page cache 中的文件页中
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
// 将写入的文件页标记为脏页并完成文件元数据日志的写入
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
// 判断是否需要同步回写脏页
balance_dirty_pages_ratelimited(mapping);
}
首先内核会在 write_begin 函数中通过 grab_cache_page_write_begin 从文件 page cache 中获取要写入的文件页。
struct page *grab_cache_page_write_begin(struct address_space *mapping,
pgoff_t index, unsigned flags)
{
struct page *page;
// 在 page cache 中查找写入数据的缓存页
page = pagecache_get_page(mapping, index, fgp_flags,
mapping_gfp_mask(mapping));
if (page)
wait_for_stable_page(page);
return page;
}
在这里会调用一个非常重要的函数 wait_for_stable_page,这个函数的作用就是判断当前 page cache 中的这个文件页是否正在被回写,如果正在回写到磁盘,那么当前进程就会阻塞直到脏页回写完毕。
/**
* wait_for_stable_page() - wait for writeback to finish, if necessary.
* @page: The page to wait on.
*
* This function determines if the given page is related to a backing device
* that requires page contents to be held stable during writeback. If so, then
* it will wait for any pending writeback to complete.
*/
void wait_for_stable_page(struct page *page)
{
if (bdi_cap_stable_pages_required(inode_to_bdi(page->mapping->host)))
wait_on_page_writeback(page);
}
EXPORT_SYMBOL_GPL(wait_for_stable_page);
等到脏页回写完毕之后,进程才会调用 iov_iter_copy_from_user_atomic 将待写入数据拷贝到 page cache 中,最后在 write_end 中调用 mark_buffer_dirty 将写入的文件页标记为脏页。
除了正在回写的脏页会阻塞 FileChannel 的写入过程之外,如果此时系统中的脏页太多了,超过了 dirty_ratio 或者 dirty_bytes 等内核参数配置的脏页比例,那么进程就会同步去回写脏页,这也对写入性能有非常大的影响。
我们接着再来看脏页回写对 MappedByteBuffer 的写入影响,在开始分析之前,笔者先问大家一个问题:通过 MappedByteBuffer 写入 page cache 之后,page cache 中的相应文件页是怎么变脏的 ?
FileChannel 很好理解,因为 FileChannel 走的是系统调用,会进入到文件系统由内核进行处理,如果写入文件页恰好正在回写时,内核会调用 wait_for_stable_page 阻塞当前进程。在将数据写入文件页之后,内核又会调用 mark_buffer_dirty 将页面变脏。
MappedByteBuffer 就很难理解了,因为 MappedByteBuffer 不会走系统调用,直接读写的就是 page cache,而 page cache 也只是内核在软件层面上的定义,它的本质还是物理内存。另外脏页以及脏页的回写都是内核在软件层面上定义的概念和行为。
MappedByteBuffer 直接写入的是硬件层面的物理内存(page cache),硬件哪管你软件上定义的脏页以及脏页回写啊,没有内核的参与,那么在通过 MappedByteBuffer 写入文件页之后,文件页是如何变脏的呢 ?还有就是 MappedByteBuffer 如何探测到对应文件页正在回写并阻塞等待呢 ?
既然我们涉及到了软件的概念和行为,那么一定就会有内核的参与,我们回想一下整个 MappedByteBuffer 的生命周期,唯一一次和内核打交道的机会就是缺页中断,我们看看能不能在缺页中断中发现点什么~
当 MappedByteBuffer 刚刚被 mmap 映射出来的时候它还只是一段普通的虚拟内存,背后什么都没有,其在进程页表中的各级页目录项以及页表项都还是空的。
当我们立即对 MappedByteBuffer 进行写入的时候就会发生缺页中断,在缺页中断的处理中,内核会在进程页表中补齐与 MappedByteBuffer 映射相关的各级页目录并在页表项中与 page cache 进行映射。
static vm_fault_t do_shared_fault(struct vm_fault *vmf)
{
// 从 page cache 中读取文件页
ret = __do_fault(vmf);
if (vma->vm_ops->page_mkwrite) {
unlock_page(vmf->page);
// 将文件页变为可写状态,并设置文件页为脏页
// 如果文件页正在回写,那么阻塞等待
tmp = do_page_mkwrite(vmf);
}
}
除此之外,内核还会调用 do_page_mkwrite 方法将 MappedByteBuffer 对应的页表项变成可写状态,并将与其映射的文件页立即设置位脏页,如果此时文件页正在回写,那么 MappedByteBuffer 在缺页中断中也会阻塞。
int block_page_mkwrite(struct vm_area_struct *vma, struct vm_fault *vmf,
get_block_t get_block)
{
set_page_dirty(page);
wait_for_stable_page(page);
}
这里我们可以看到 MappedByteBuffer 在内核中是先变脏然后在对 page cache 进行写入,而 FileChannel 是先写入 page cache 后在变脏。
从此之后,通过 MappedByteBuffer 对 page cache 的写入就会变得非常丝滑,那么问题来了,当 page cache 中的脏页被内核异步回写之后,内核会把文件页中的脏页标记清除掉,那么这时如果 MappedByteBuffer 对 page cache 写入,由于不会发生缺页中断,那么 page cache 中的文件页如何再次变脏呢 ?
内核这里的设计非常巧妙,当内核回写完脏页之后,会调用 page_mkclean_one 函数清除文件页的脏页标记,在这里会首先通过 page_vma_mapped_walk 判断该文件页是不是被 mmap 映射到进程地址空间的,如果是,那么说明该文件页是被 MappedByteBuffer 映射的。随后内核就会做一些特殊处理:
-
通过 pte_wrprotect 对 MappedByteBuffer 在进程页表中对应的页表项 pte 进行写保护,变为只读权限。
-
通过 pte_mkclean 清除页表项上的脏页标记。
static bool page_mkclean_one(struct page *page, struct vm_area_struct *vma,
unsigned long address, void *arg)
{
while (page_vma_mapped_walk(&pvmw)) {
int ret = 0;
address = pvmw.address;
if (pvmw.pte) {
pte_t entry;
entry = ptep_clear_flush(vma, address, pte);
entry = pte_wrprotect(entry);
entry = pte_mkclean(entry);
set_pte_at(vma->vm_mm, address, pte, entry);
}
return true;
}
这样一来,在脏页回写完毕之后,MappedByteBuffer 在页表中就变成只读的了,这一切对用户态的我们都是透明的,当再次对 MappedByteBuffer 写入的时候就不是那么丝滑了,会触发写保护缺页中断(我们以为不会有缺页中断,其实是有的),在写保护中断的处理中,内核会重新将页表项 pte 变为可写,文件页标记为脏页。如果文件页正在回写,缺页中断会阻塞。如果脏页积累的太多,这里也会同步回写脏页。
static vm_fault_t wp_page_shared(struct vm_fault *vmf)
__releases(vmf->ptl)
{
if (vma->vm_ops && vma->vm_ops->page_mkwrite) {
// 设置页表项为可写
// 标记文件页为脏页
// 如果文件页正在回写则阻塞等待
tmp = do_page_mkwrite(vmf);
}
// 判断是否需要同步回写脏页,
fault_dirty_shared_page(vma, vmf->page);
return VM_FAULT_WRITE;
}
所以并不是对 MappedByteBuffer 调用 mlock 之后就万事大吉了,在遇到脏页回写的时候,MappedByteBuffer 依然会发生写保护类型的缺页中断。在缺页中断处理中会等待脏页的回写,并且还可能会发生脏页的同步回写。这对 MappedByteBuffer 的写入性能会有非常大的影响。
在明白这些问题之后,下面我们继续来看 MappedByteBuffer 和 FileChannel 在不同数据集下对文件的写入性能测试:
运行结果:
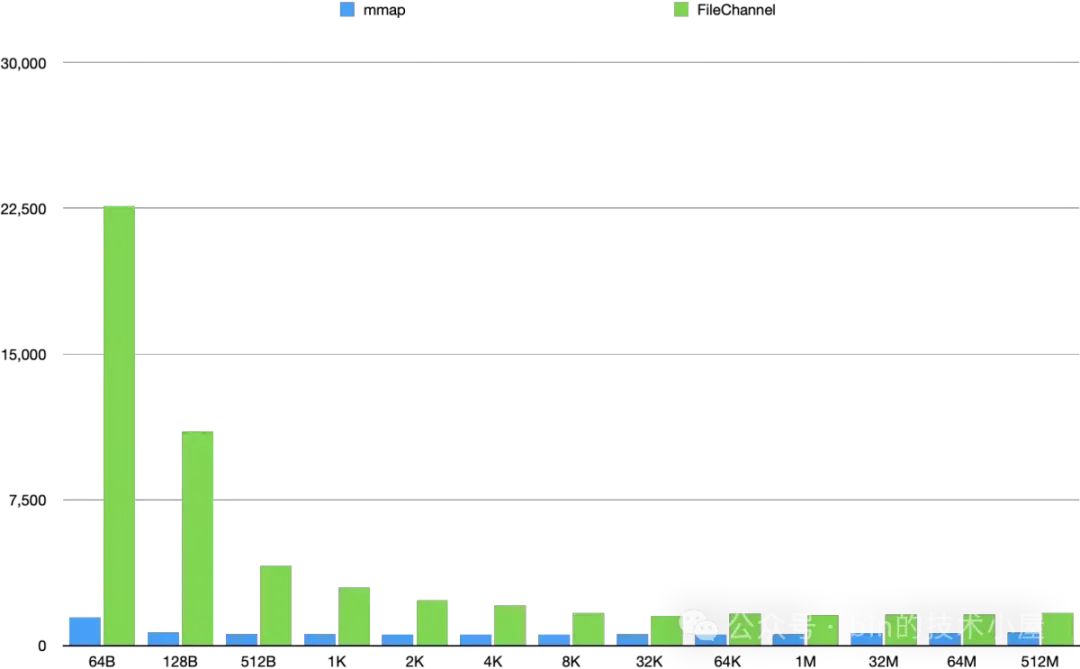
在笔者的测试环境中,我们看到 MappedByteBuffer 在对文件的写入性能一路碾压 FileChannel,并没有出现被 FileChannel 反超的情况。但我们看到 MappedByteBuffer 从 4K 开始写入性能是在逐渐下降的,而 FileChannel 的写入性能却在一路升高。
根据上面的分析,我们可以推断出,后面随着数据量的增大,由于 MappedByteBuffer 缺页中断瓶颈的影响,在 512M 后面某一个数据集下,FileChannel 的写入性能最终是会超过 MappedByteBuffer 的。
在本小节的开头,笔者就强调了,本小节值得参考的是 MappedByteBuffer 和 FileChannel 在不同数据集大小下的读写性能趋势走向,而不是具体的性能数值。