
性能优化:线程资源回收原创
一、问题
模型服务平台的排序请求出现较多超时情况,且不定时伴随空指针异常。
二、问题发生前后的改动
召回引擎扩大了召回量,导致排序请求的item数量增加了。
三、出问题的模型
基于XGBoost预测的全排序模型。
四、项目介绍
web-rec-model:模型服务平台。用于管理排序模型:XGBoost、TensorFlow、pmml…召回模型:item2item,key2item,vec2item…等模型的上下线、测试模型一致性、模型服务等。
五、一次排序请求流程
1、如下图所示,一次排序请求流程包含:特征获取、向量获取、数据处理及预测。以上提到的三个步骤均采用多线程并行处理,均以子任务形式执行。每个阶段中间夹杂这数据处理的流程,由主线程进行处理,且每个阶段的执行任务均为超时返回,主线程等待子线程任务时,也采用超时等待的策略。(同事实现的一个树形任务执行,超时等待的线程框架)
2、特征数据闭环:该步骤为异步执行,将排序计算使用到的特征及分数,模型版本等信息记录。后续作为模型的训练样本,达到特征闭环。
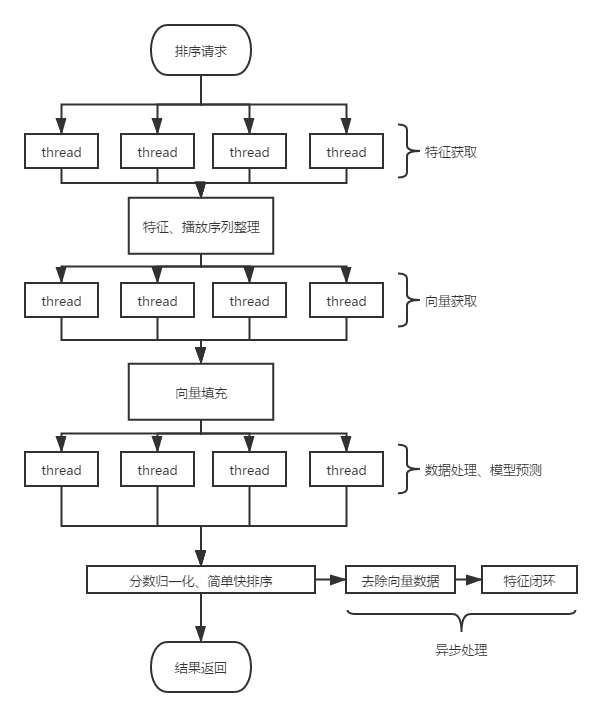
3、一次排序请求中,特征获取及向量获取为网络IO(IO密集型任务),超时可直接响应中断,线程可快速返回。数据处理及模型为计算步骤(CPU密集型任务)。
4、当前请求耗时情况:特征与向量的获取阶段耗时均为5-8ms,数据处理及模型预测阶段耗时平均在10ms左右。
六、问题发生现象
1、首先是调用方:推荐策略平台,监控报警排序请求的超时数量变多(调用方超时时间为300ms),且从监控上看发现排序服务的耗时明显变长:50ms+。正常高峰期的期望值为50ms以下。
2、其次排序服务告警出现大量超时错误。

3、第三根据错误信息定位到该错误信息来自于数据处理及模型预测阶段。
4、除了超时变多以外,服务中会出现偶发性的空指针异常。
七、问题排查
1、首先解决空指针这类低级错误。
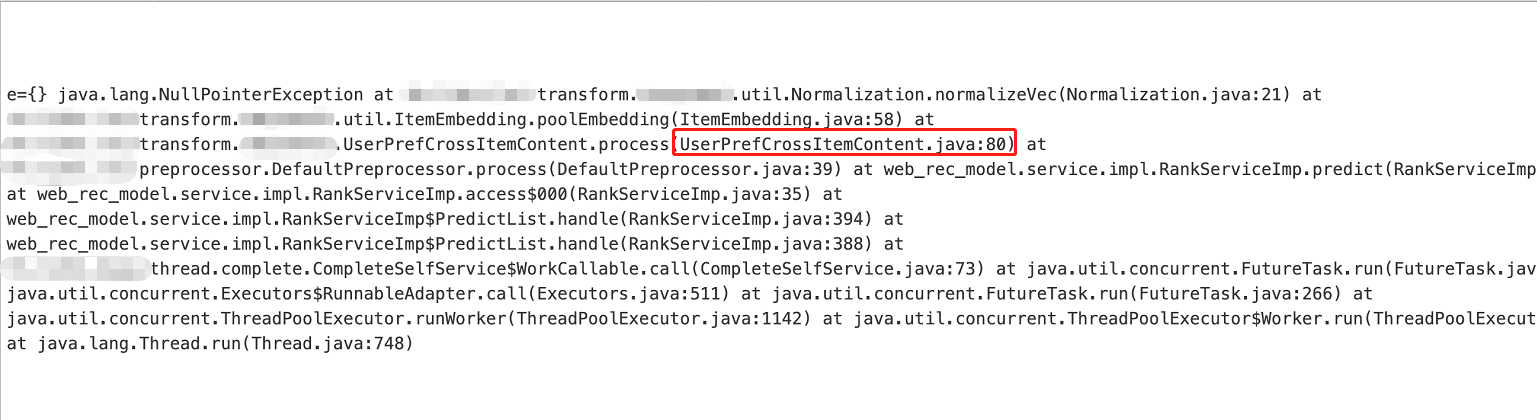
2、根据错误提示找到对应的代码,此处就不粘贴代码了,做一个简单的代码解释。代码逻辑为:从Map<String,Object>中根据特征key获取特征值进行计算。
3、疑惑点出现,首先该Map<String,Object>用于存放特征及向量键值对,且key均做了空值计算兼容。特征或者向量在查询到空值时,会在Map<String,Object>中放入一个对应的默认值。经过反复的代码确认,报错信息对应的代码不可能出现漏放默认值的情况。
4、借助Arthas的watch命令,监控空指针异常的入参。方便后面做模拟请求还原现场。
5、根据报错时的信息进行模拟请求。尝试N次,且使用不同的报错数据进行尝试,均未重现事故。
6、此时怀疑是多线程并发进行数据处理及预测时,发生对Map<String,Object>进行修改的动作,导致部分键值对丢失。
7、反复检查代码,确定数据处理及预测均为只读动作,不会对Map<String,Object>进行任何键值对的删改。
8、线索中断,排查一度搁置。
八、豁然开朗
1、借用Arthas进行报错观察:使用watch命令,依靠-e参数(指定报错触发打印)以及-x n 参数(打印方法入参及返回值数据层数)
2、根据观察,发现Map<String,Object>中丢失的均为向量键值对。
3、找到问题:在排序请求流程图中,在主线程进行分数归一化时,会fork子线程异步做特征数据进行压缩写入kafka。由于Map<String,Object>中存在大量的向量数据,导致保存数据过冗余的情况。此处的做法是先去除所有的向量数据,再进行保存。
4、但是该动作是发生在数据处理及模型预测后的,为何还会因为Map<String,Object>中删除键值对导致空指针异常呢。
5、此时怀疑是数据处理及模型预测阶段,多线程任务还没完成时,主线程已经等候超时返回了。
九、验证想法
1、还是观察超时日志。
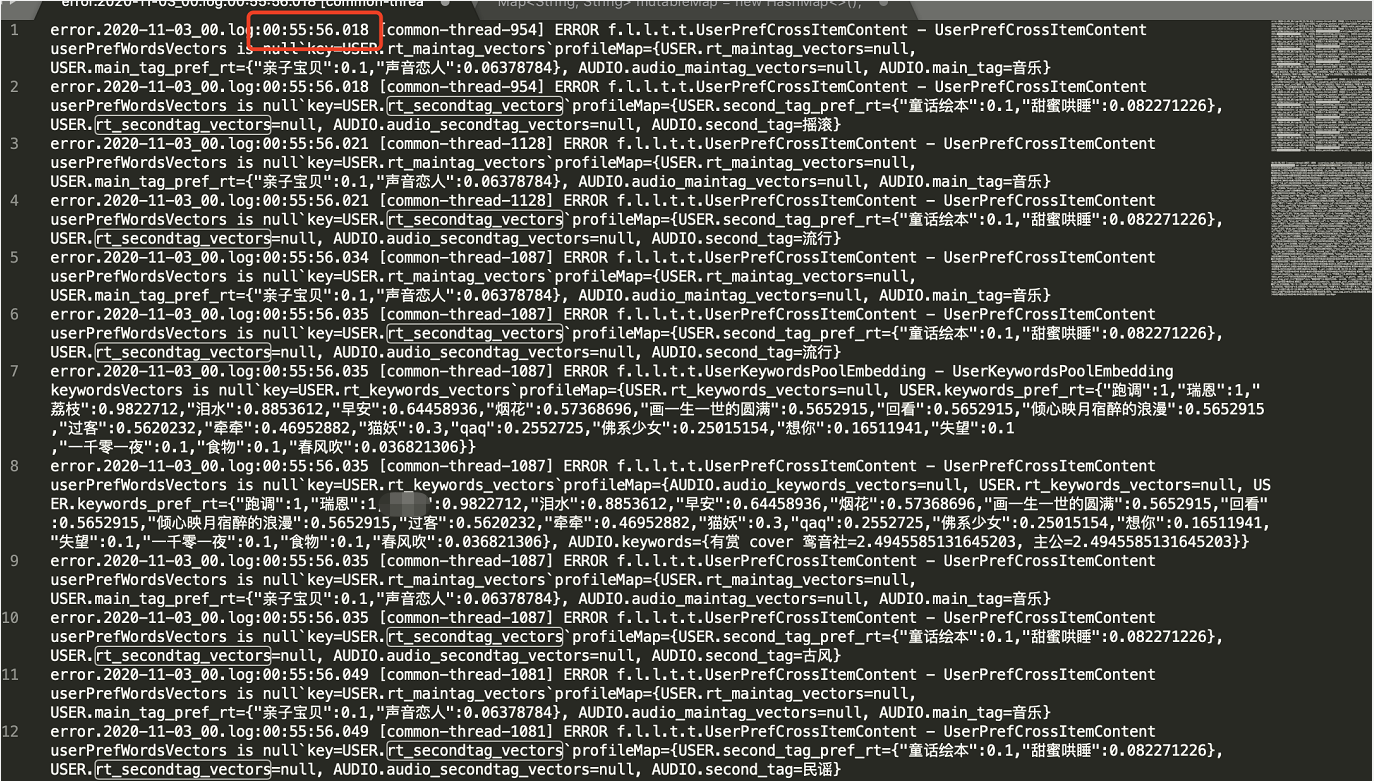
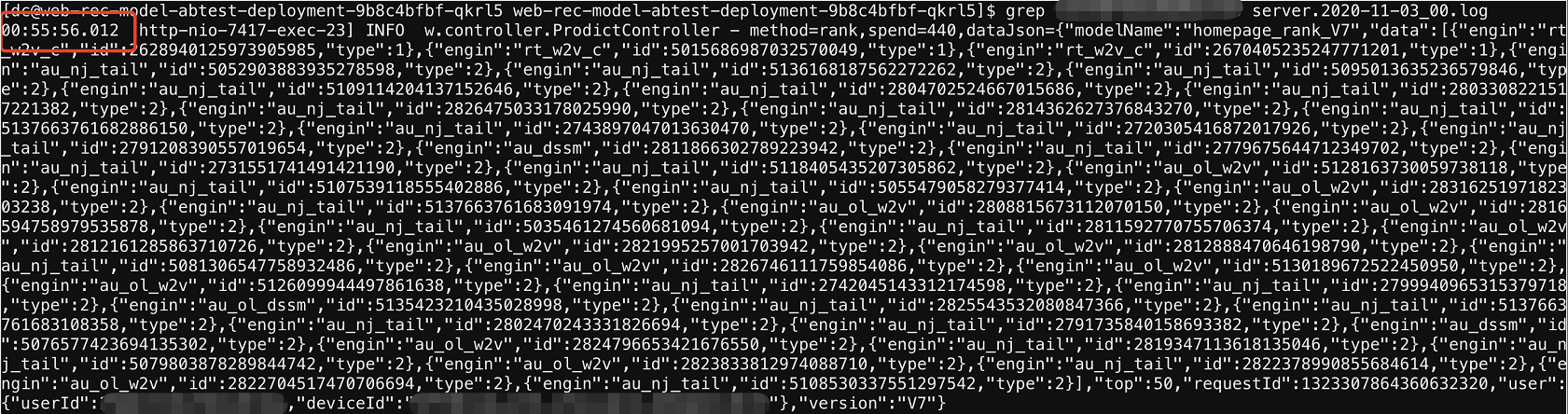
2、发现请求已经返回后,才出现空指针异常。那基本就可以验证以上的想法了。
十、问题解决
1、翻看使用的多线程框架(同事实现),主线程超时等待子线程任务。主线程超时返回后,没有通知子线程任务取消。所以才发生请求已返回,特征数据异步落地后,偶发性出现晚到的空指针异常的情况。如下图,主线程超时返回后,只取消主线程任务。
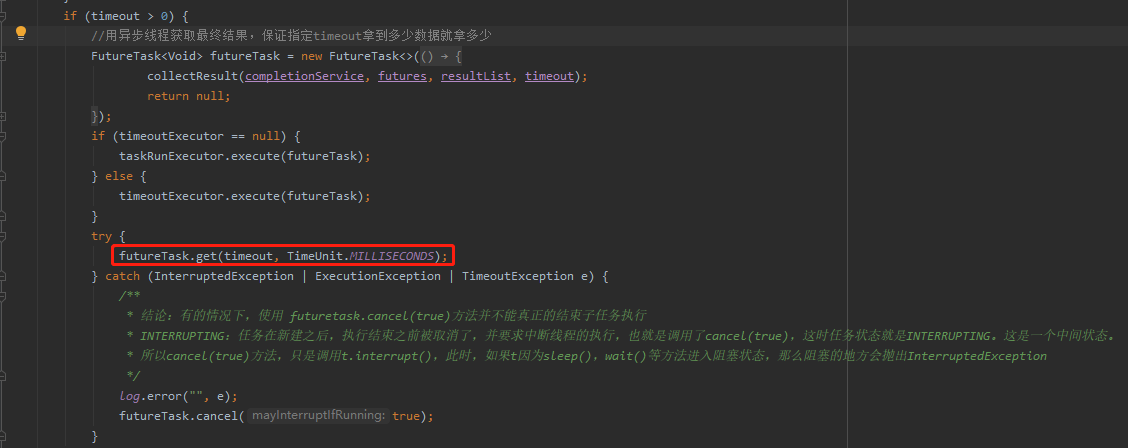
2、解决思路:主线程超时返回后,中断子任务(取消子任务)。由于java的中断机制为软中断,一般是通过中断标志位进行线程中断协作的。当然IO或者sleep的中断由系统帮我们做了中断可以快速返回。对于CPU密集型的任务,是需要使用者在合适的计算点上做标志位判断,确定是否已中断结束任务。以这种协作的方式达到中断。(此处可能有部分理解不当)
3、修改多线程框架,在主线程超时返回后,修改子线程中断标志位。
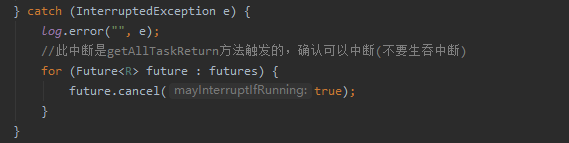
4、在计算流程中加入线程中断检查,如果被中断则提前结束计算。

十一、效果检查
1、修改发版后,空指针没再出现。(其实该空指针是不影响排序结果,因为结果已经是错的,该异常只是附带的虫子而已)
2、超时请求减少,高峰期的超时数据减少三分之一,50ms+的排序请求有明显减少。
十二、复盘
1、主线程等待子任务的场景下,如果主线程超时返回了。需通知子线程结束执行的任务。首先,主线程返回了,表示子任务已被丢弃。继续执行都是在做无用的计算,占用计算机资源。也不是说占着茅坑不拉屎,而是拉了没人要。应该尽量减少服务器资源用在没必要的消耗上。
2、该服务在数据处理及预测阶段使用的线程池队列为SynchronousQueue,如果不了解SynchronousQueue的话可以简单理解为一个0长度的队列。任务进池子时必须要有线程进行对接。与常规的BlockingQueue不同的是,任务在池子中不会堆积,对于任务的快速响应比较友好。但是也因为如果没有空闲的线程,则会不停创建线程直到最高线程数限制而触发丢弃策略。在该项目问题中,由于部分子任务在主线程返回后仍然在执行。新的请求进来后,会出现没有空闲线程的情况,导致池子创建新线程接任务。对于CPU密集型任务来说,过多的线程数对服务来说是另一种负担,毕竟线程切换的代价还是比较大的。这就套入死循环了。(个人理解,如表述有误,还望指正)

