
深入理解Linux系统调用与API原创
作者简介:
程磊,一线码农,在某手机公司担任系统开发工程师,阅码场荣誉总编辑,日常喜欢研究内核基本原理。
目录:
一、基本概念解析
1.1 系统调用的来源与作用
1.2 API的来源与作用
1.3 API与系统调用的关系
1.4 系统调用机制的基本原理
二、API的制定与实现
2.1 POSIX API
2.2 Windows API
2.3 API的实现
三、系统调用的实现
3.1 x86平台的实现
3.2 指令基本原理
3.3系统调用编号
3.4系统调用入口函数
3.5汇编程序演示
3.6vsyscall与vdso
四、总结回顾
一、基本概念解析
我们在很多书籍上、博客上都学过或者听说过系统调用与API这两个概念,那么这两个概念究竟是什么意思,它们之间是什么关系呢?如果我们阅读过《操作系统导论》,就会明白操作系统的目的与作用,就会知道内核是要向进程提供服务的,那么内核是如何向进程提供服务的呢?下面我们就来一探究竟。
1.1 系统调用的来源与作用
我们先来看一下进程的虚拟内存空间布局,我们以32位为例,64位的逻辑也是一样的。
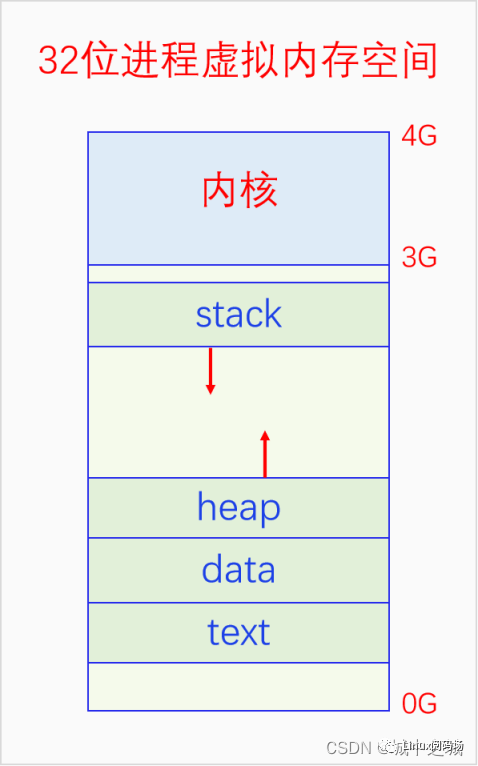
可以看到一个进程的内存空间分为用户空间和内核空间两部分。每个进程都有自己独立的用户空间,但是所有进程都共享同一个内核空间,所以所有进程都可以请求内核的服务。不过内核空间运行在特权级,用户空间运行在非特权级,所以用户空间是不能直接访问内核空间的。为此,内核向用户空间提供了有限制的访问,系统调用。用户空间可以通过系统调用来调用内核里一些特定的函数。这样的话,进程就可以通过系统调用来请求内核的服务了。系统调用是如何实现的呢?这是需要硬件的特殊支持的,第三章节会讲。
1.2 API的来源与作用
既然有了系统调用,进程可以通过系统调用来请求内核的服务,那么为什么还会有API呢?因为系统调用是偏底层的,有很多细节要处理,而且不同的平台其系统调用并不相同;就算是同一个平台,其提供的系统调用功能以及系统调用的实现方法都有可能会发生变化。因此为了屏蔽系统调用的各种细节,增加通用性和跨平台性,操作系统又向用户进程提供了API。API,Application Programming Interface,应用程序编程接口,它的意思就是它的字面意思,就是指操作系统向应用程序提供的编程接口。现实中有很多人把API当做I(Interface)接口的意思来用,本文所说的API都是指它的本意。有了API你就不用考虑系统调用了,无论在任何平台、任何OS,你只管使用API,只要它们的API是相同的,你的源码就是兼容的、跨平台的。
1.3 API与系统调用的关系
API和系统调用具体是什么关系呢?系统调用是偏底层、偏实现的,API是偏上层、偏接口的。系统调用是实现在内核里的,它的修改只要符合内核的规范、只要内核的主要管理者同意就可以。API它首先是行业标准或者业内标准,是不能随意改变的,一般都有相应的标准委员会来制定和发展API。API的实现是在用户空间库里面,一般都是在libc中实现。API的底层实现一般使用的是系统调用,很多API和系统调用是一对一关系。但也有特殊情况,比如有的API并不使用系统调用,有的系统调用没有对应的API,有的API可能调用了多个系统调用,有的系统调用可能被多个API使用。也就是说大部分情况下API和系统调用是1:1的关系,但有些情况下是1:0、0:1、1:n、n:1、m:n的关系。当API和系统调用的关系是1:1,而且它们的名字也相同时,我们不能把它们看做是同一个事物,而应当把它们看做不同的事物,只不过是名字相同而已,是同名的API使用了同名的系统调用。就好比有两种情况,第一种情况是,有两个人都叫张伟,一个是副市长,一个是公安局局长,张伟副市长安排张伟局长去做某件事情。第二种情况是,有一个人叫张伟,他是副市长兼任公安局局长,张伟副市长兼局长去做某件事情。这两种情况是不一样的,同名的API与系统调用的关系类似于前者。
下面我们举例来说明一下API与系统调用的关系。我们来写一个最简单的hello world程序,代码如下。
#include <unistd.h>
#include <string.h>
int main(int argc, char *argv[])
{
char str[] = "hello, world\n";
write(1, str, strlen(str));
}
编译:gcc -o hello hello.c
运行:./hello
会在屏幕上输出 hello, world。
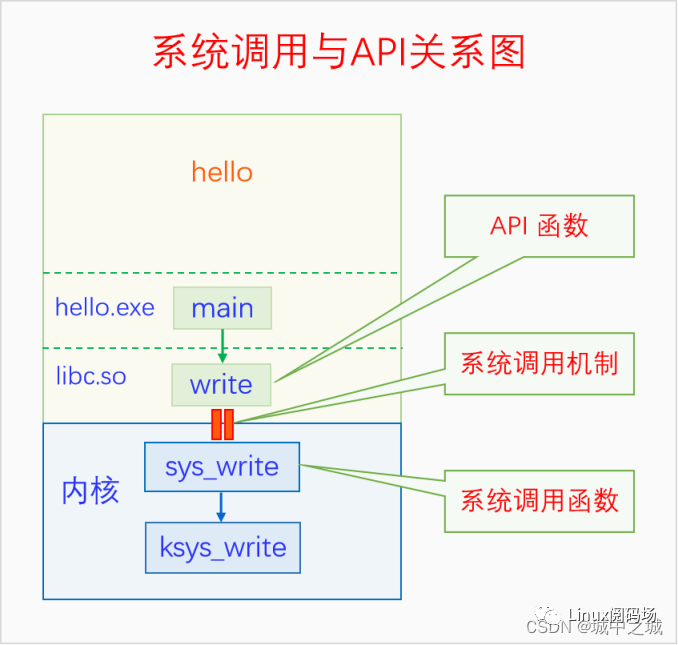
这个程序非常简单,我们调用了两个API(strlen 和 write),在屏幕上输出了一行文字。同样是API,strlen没有使用系统调用,自己直接在用户空间就把功能实现了,而write API则使用了write系统调用。有些API的功能比较简单,自己在用户空间就能实现,没必要麻烦内核。但是有些API的功能在用户空间是不可能实现或者很难实现的,必须要求助于内核。我们把write API与write系统调用画成图,如下所示:
API函数通过系统调用机制调用系统调用函数。那么系统调用机制要做的事情有哪些呢?有两件事,一是实现CPU特权级的转变,把CPU设置为特权模式之后才能执行内核的代码。二是传递系统调用的编号和函数参数,系统调用函数有很多,怎么知道你想调用的是哪个系统调用函数呢,通过编号来区分。系统调用函数大部分都是有参数的,所以还需要传递参数,参数怎么传递是和具体硬件相关的,由相应的ABI来规定。
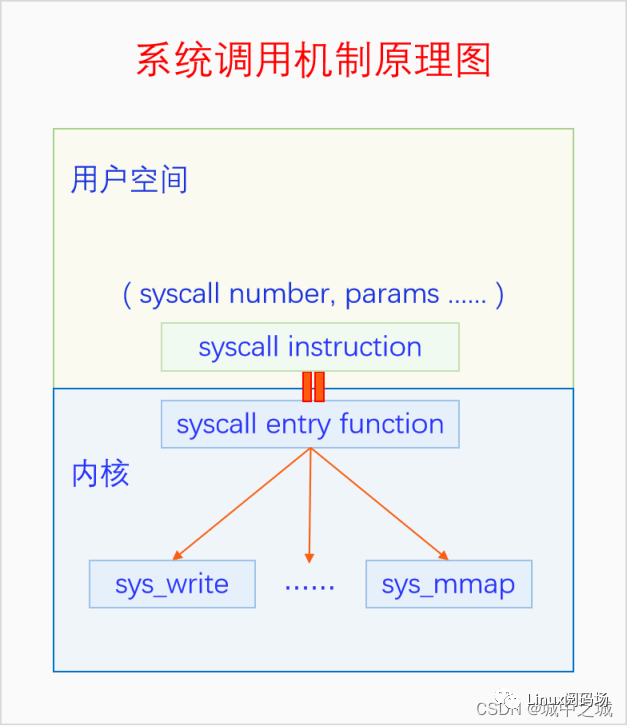
1.4 系统调用机制的基本原理
那么系统调用机制该怎么实现呢?答案是要靠CPU提供的特殊指令(系统调用指令)来实现,虽然不同架构的CPU实现不尽相同,但是大概模式都是一样的,都是往某个寄存器写入系统调用编号,在约定的寄存器或者栈上写入参数,然后调用特殊指令(系统调用指令),此时CPU就会切换到特权模式并进入内核执行一段预先设定的代码(系统调用入口函数),这段代码会根据系统调用编号调用相应的系统调用函数。画成图如下所示:
可以看出完成一个系统调用有两个关键点,一是系统调用编号要能对应上,二是系统调用入口函数要提前设置好。这样系统调用入口函数才能根据系统调用编号找到正确的系统调用函数。
需要说明的是,一个平台提供的系统调用指令不一定只有一个,不同系统调用指令对应的系统调用入口函数也不相同,这个第三章会详细讲解。
二、API的制定和实现
最开始的时候是没有操作系统的,后来逐渐产生了操作系统。操作系统对应用程序提供的用户空间接口就叫做API(应用程序编程接口)。API刚开始是看着缺啥就添啥,没有一定的标准。后来随着操作系统的发展,再野蛮生长就不行了,于是就有了操作系统API标准规范。不同的操作系统,它们的API并不相同,API的制定与维护方法也不相同。
2.1 POSIX API
UNIX操作系统家族的API叫做POSIX(Portable Operating System Interface)。POSIX是IEEE制定的规范,POSIX这个名字是GNU的倡导者Richard Stallman建议的,按照当时的命名习惯在最后加了个X。UNIX还有另外一个规范叫做Single UNIX Specification,简称SUS,是由Open Group发布的。后来POSIX和SUS合并开发,内容一样,但是对外还是用两个名字。想要了解POSIX S最新的标准,请查看网站https://unix.org/online.html。
Linux本身仅仅是个内核,并不是个操作系统。GNU/Linux或者Linux发行版才是个完整的操作系统。Linux发行版都遵循POSIX API。网站https://man7.org 和书籍《The Linux Programming Interface》非常全面详细地介绍了POSIX API的语义以及它在Linux上的一些实现情况,非常值得大家认真学习或者经常查阅。
2.2 Windows API
Windows的API在16位的时候叫做Windows API。后来到了32位的时候,重新设计了API,由于16的API和32位的API差别非常大,所以就重新命名为Win32 API。到了64位的时候,API基本没啥变化,就是把有些参数从32位提升到了64位,所以64位的Windows的API也依然被人们叫做Win32 API。当然64位的API也被Windows命名为Windows API,因为16位Windows早已成为历史,这么命名也不会引起歧义。现在Windows API和Win32 API几乎是同义词,区别不大。
由于Windows操作系统是微软一家的闭源产品,所以它的API规范是由公司制定的。这和POSIX是由标准委员会制定的是不一样的。
2.3 API的实现
API本身仅仅是个规范,是个概念性的东西,它具体是怎么实现的呢?目前业界都是把API放在libc里面来实现的。所以libc里面不仅有C标准库的实现,还有操作系统API的实现。所以大家不能认为libc就是一个普通的lib,它的作用是非常重要的,没有libc,几乎所有的进程都无法运行,libc是进程通向内核的必经之路。几乎所有的进程都链接了libc,大部分都是动态链接的,通过ldd命令可以查到,通过/proc/$pid/maps也可以查到;少部分是静态链接libc的,是查不到libc.so的,但是程序本身还是包含libc的代码的。当然你也可以自己调用系统调用就不用libc,一般只有演示程序会这么做。
Libc在不同操作系统上的实现是不同的,在同一个操作系统也可能有多个不同的实现。Linux发行版上最流行的libc实现是Glibc,Android上的libc实现是bionic。
三、系统调用的实现
系统调用机制的实现原理都是相同的,但是不同操作系统、不同硬件平台上的实现细节又不尽相同。下面我们分别来讲一下Linux在x86平台和arm平台上实现细节。
3.1 x86平台的实现
X86平台的系统调用的实现方法经历了三代的变迁,每次改变都提高了系统调用的执行效率。第一代系统调用指令,借用了中断机制的指令,int 0x80、iret。第二代系统调用指令sysenter、sysexit。第三代系统调用指令syscall、sysret。三代指令在内核中的使用情况如下图所示:
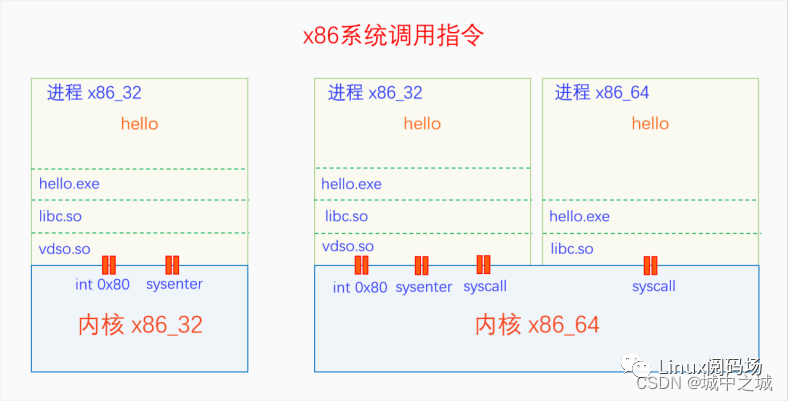
下面我们分别讲一下这三代指令的基本原理。
3.2 指令基本原理
第一代系统调用指令使用的是中断指令,基本原理如下。中断发生时,CPU会切换到特权模式并跳到内核执行预先指定的一段程序。执行哪段程序呢,要根据中断源来决定,不同的中断源执行不同的程序,每个中断源都对应一个整数来标识自己,这个整数就叫做中断向量。中断源有三类,外设中断、CPU异常、指令中断,前两种都有自己的方法来指定中断向量,指令中断是在指令的操作数里面指定中断向量号的。我们的系统调用就是利用指令中断,用向量号0x80,也就是十进制的128当做自己的中断向量,来执行系统调用的。我们在用户空间,先把系统调用编号赋值给寄存器EAX,然后执行int 0x80,CPU就会跳转到内核执行内核预先设定的中断处理程序(也就是系统调用入口函数)。系统调用入口函数根据EAX的值调用对应的系统调用函数。系统调用函数执行完成之后返回系统调用入口函数,入口函数再执行iret返回到用户空间,一个系统调用就完成了。
第二代系统调用指令sysenter/sysexit,由于通过中断流程进行系统调用开销太大了,很多操作对系统调用来说又是没有意义的,因此Intel专门开发了只用于系统调用的指令。由于sysenter是专用指令,它可以把很多中断相关的操作都省略掉,具体来说有以下几点,1.不再自动把寄存器信息保存到内核栈上,2.不再自动从内核栈上加载esp的值,3.不再走中断处理流程。
使用sysenter指令需要提前设置一些MSR寄存器,具体来说要做以下一些设置。把内核代码段的选择符写入MSR IA32_SYSENTER_CS,把系统调用入口函数写入MSR IA32_SYSENTER_EIP,内核栈段的选择符要放在紧挨着内核栈段的后面,把内核栈的地址写入MSR IA32_SYSENTER_ESP,这样sysenter执行时CPU就会切换到特权模式,然后执行系统调用入口函数。在执行sysexit之前把要返回到的用户空间指令的地址写入EDX,用户空间栈的值写入ECX。
sysenter/sysexit指令也可以用于64位模式,但是Linux选择在64位上只使用syscall/sysret。
第三代系统调用指令syscall/sysret,是AMD开发的,它只能用于64位模式,比sysenter/sysexit还要快一些,因为1.它不再保存和恢复用户空间RSP,2.它只能用于平坦内存,因此省略了分段单元的开销。
使用syscall/sysret前要提前设置一些MSR。要在MSR IA32_STAR中设置内核空间和用户空间的代码段,其中内核空间CS、SS在47:32位,用户空间CS、SS在63:48位。系统调用入口函数的地址要写人MSR IA32_LSTR。syscall执行的时候会把MSR IA32_STAR的47:32位加载到CS和SS,把MSR IA32_LSTR的值加载到RIP。在执行sysret之前把要返回到的用户空间指令的地址写入RCX,sysret执行时会把MSR IA32_STAR的63:48位加载到CS和SS,把RCX加载到RIP。
3.3 系统调用编号
我们先来解决第一个问题,系统调用编号是怎么确定的。不同架构不同位数的系统,系统调用编号是不一样的。如果用户空间传递的系统调用编号和内核里的系统调用编号对不上,那问题就严重了。Linux内核在编译时会生成一个文件,arch/x86/include/generated/uapi/asm/unistd_64.h,这个文件是生成的,不是本来就有的,这个文件里面有所有系统调用的编号。在安装操作系统时或者单独安装内核和内核头文件时,这个文件会被安装在/usr/include/asm/unistd_64.h,libc会使用这个文件,这样用户空间传递的编号和内核里面的系统调用编号就是一致的了。
3.4 系统调用入口函数
下面我们来说说系统调用入口函数是怎么设置的。X86_64对于64位的进程来说只有一个系统调用指令,就是syscall,它的入口函数在linux-src/arch/x86/entry/entry_64.S, 函数名叫entry_SYSCALL_64。对于32位的进程来说有三个系统调用指令 int 0x80、sysenter、syscall,它们的入口函数都在 linux-src/arch/x86/entry/entry_64_compat.S,函数名分别叫做entry_INT80_compat、entry_SYSENTER_compat、entry_SYSCALL_compat。设置它们的代码在两个地方,syscall(64)、syscall(32)、sysenter 这三个设置在一个地方,在文件linux-src/arch/x86/kernel/cpu/common.c中的函数 syscall_init
#ifdef CONFIG_X86_64
void syscall_init(void)
{
wrmsr(MSR_STAR, 0, (__USER32_CS << 16) | __KERNEL_CS);
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);
#ifdef CONFIG_IA32_EMULATION
wrmsrl(MSR_CSTAR, (unsigned long)entry_SYSCALL_compat);
/*
* This only works on Intel CPUs.
* On AMD CPUs these MSRs are 32-bit, CPU truncates MSR_IA32_SYSENTER_EIP.
* This does not cause SYSENTER to jump to the wrong location, because
* AMD doesn't allow SYSENTER in long mode (either 32- or 64-bit).
*/
wrmsrl_safe(MSR_IA32_SYSENTER_CS, (u64)__KERNEL_CS);
wrmsrl_safe(MSR_IA32_SYSENTER_ESP,
(unsigned long)(cpu_entry_stack(smp_processor_id()) + 1));
wrmsrl_safe(MSR_IA32_SYSENTER_EIP, (u64)entry_SYSENTER_compat);
#else
wrmsrl(MSR_CSTAR, (unsigned long)ignore_sysret);
wrmsrl_safe(MSR_IA32_SYSENTER_CS, (u64)GDT_ENTRY_INVALID_SEG);
wrmsrl_safe(MSR_IA32_SYSENTER_ESP, 0ULL);
wrmsrl_safe(MSR_IA32_SYSENTER_EIP, 0ULL);
#endif
/*
* Flags to clear on syscall; clear as much as possible
* to minimize user space-kernel interference.
*/
wrmsrl(MSR_SYSCALL_MASK,
X86_EFLAGS_CF|X86_EFLAGS_PF|X86_EFLAGS_AF|
X86_EFLAGS_ZF|X86_EFLAGS_SF|X86_EFLAGS_TF|
X86_EFLAGS_IF|X86_EFLAGS_DF|X86_EFLAGS_OF|
X86_EFLAGS_IOPL|X86_EFLAGS_NT|X86_EFLAGS_RF|
X86_EFLAGS_AC|X86_EFLAGS_ID);
}
#else /* CONFIG_X86_64 */
......
#endif /* CONFIG_X86_64 */
从代码中可以看出只有在64位的情况下才会设置syscall指令的入口函数,只有在系统兼容32位进程(CONFIG_IA32_EMULATION)的情况下才会设置syscall(32)、sysenter的兼容入口函数。大部分linux发行版都支持32位进程兼容。
兼容int 0x80的代码设置在另外一个地方,因为int 0x80是中断指令,所以它是在设置中断的地方设置的,具体位置是linux-src/arch/x86/kernel/idt.c中的函数idt_setup_traps。
tatic const __initconst struct idt_data def_idts[] = {
INTG(X86_TRAP_DE, asm_exc_divide_error),
ISTG(X86_TRAP_NMI, asm_exc_nmi, IST_INDEX_NMI),
INTG(X86_TRAP_BR, asm_exc_bounds),
INTG(X86_TRAP_UD, asm_exc_invalid_op),
INTG(X86_TRAP_NM, asm_exc_device_not_available),
INTG(X86_TRAP_OLD_MF, asm_exc_coproc_segment_overrun),
INTG(X86_TRAP_TS, asm_exc_invalid_tss),
INTG(X86_TRAP_NP, asm_exc_segment_not_present),
INTG(X86_TRAP_SS, asm_exc_stack_segment),
INTG(X86_TRAP_GP, asm_exc_general_protection),
INTG(X86_TRAP_SPURIOUS, asm_exc_spurious_interrupt_bug),
INTG(X86_TRAP_MF, asm_exc_coprocessor_error),
INTG(X86_TRAP_AC, asm_exc_alignment_check),
INTG(X86_TRAP_XF, asm_exc_simd_coprocessor_error),
#ifdef CONFIG_X86_32
TSKG(X86_TRAP_DF, GDT_ENTRY_DOUBLEFAULT_TSS),
#else
ISTG(X86_TRAP_DF, asm_exc_double_fault, IST_INDEX_DF),
#endif
ISTG(X86_TRAP_DB, asm_exc_debug, IST_INDEX_DB),
#ifdef CONFIG_X86_MCE
ISTG(X86_TRAP_MC, asm_exc_machine_check, IST_INDEX_MCE),
#endif
#ifdef CONFIG_AMD_MEM_ENCRYPT
ISTG(X86_TRAP_VC, asm_exc_vmm_communication, IST_INDEX_VC),
#endif
SYSG(X86_TRAP_OF, asm_exc_overflow),
#if defined(CONFIG_IA32_EMULATION)
SYSG(IA32_SYSCALL_VECTOR, entry_INT80_compat),
#elif defined(CONFIG_X86_32)
SYSG(IA32_SYSCALL_VECTOR, entry_INT80_32),
#endif
};
void __init idt_setup_traps(void)
{
idt_setup_from_table(idt_table, def_idts, ARRAY_SIZE(def_idts), true);
}
从代码中可以看出,只有系统支持32位进程兼容(CONFIG_IA32_EMULATION)才会去设置entry_INT80_compat。
我们设置好了这些系统调用指令的入口函数之后,当用户空间调用这些指令的时候就会调用这些函数。那么这些函数又是怎样去调用具体对应的系统调用函数呢?我们以64位进程的syscall指令为例来看一看。先看它的入口函数,linux-src/arch/x86/entry/entry_64.S:entry_SYSCALL_64
SYM_CODE_START(entry_SYSCALL_64)
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(cpu_tss_rw + TSS_sp2) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
pushq %rax /* pt_regs->orig_ax */
call do_syscall_64 /* returns with IRQs disabled */
sysretq
SYM_CODE_END(entry_SYSCALL_64)
我们对代码做了精简只留下最关键的。可以看到函数先把__USER_DS和__USER_CS都push到了栈上,这是为了执行最后面的那条sysretq时可以返回用户空间把特权级也转为用户级。函数的主体就是调用函数do_syscall_64,我们再来看一个这个函数,linux-src/arch/x86/entry/common.c
static __always_inline bool do_syscall_x64(struct pt_regs *regs, int nr)
{
/*
* Convert negative numbers to very high and thus out of range
* numbers for comparisons.
*/
unsigned int unr = nr;
if (likely(unr < NR_syscalls)) {
unr = array_index_nospec(unr, NR_syscalls);
regs->ax = sys_call_table[unr](regs);
return true;
}
return false;
}
__visible noinstr void do_syscall_64(struct pt_regs *regs, int nr)
{
add_random_kstack_offset();
nr = syscall_enter_from_user_mode(regs, nr);
instrumentation_begin();
if (!do_syscall_x64(regs, nr) && !do_syscall_x32(regs, nr) && nr != -1) {
/* Invalid system call, but still a system call. */
regs->ax = __x64_sys_ni_syscall(regs);
}
instrumentation_end();
syscall_exit_to_user_mode(regs);
}
可以看到do_syscall_64就是调用do_syscall_x64,do_syscall_x64就是根据用户空间传来的系统调用编号在sys_call_table数组中调用相应的函数。那么这个sys_call_table数组是怎么来的呢?它是在文件linux-5.15.28/arch/x86/entry/syscall_64.c中定义的,如下:
#include <linux/linkage.h>
#include <linux/sys.h>
#include <linux/cache.h>
#include <linux/syscalls.h>
#include <asm/syscall.h>
#define __SYSCALL(nr, sym) extern long __x64_##sym(const struct pt_regs *);
#include <asm/syscalls_64.h>
#undef __SYSCALL
#define __SYSCALL(nr, sym) __x64_##sym,
asmlinkage const sys_call_ptr_t sys_call_table[] = {
#include <asm/syscalls_64.h>
};
那么syscalls_64.h的内容是什么,它是怎么来的呢?这个文件并不是手写的,而是在编译时由脚本生成的,它是根据文件linux-src/arch/x86/entry/syscalls/syscall_64.tbl 生成的。我们截取一段syscalls_64.h的内容如下:
__SYSCALL(0, sys_read)
__SYSCALL(1, sys_write)
__SYSCALL(2, sys_open)
__SYSCALL(3, sys_close)
__SYSCALL(4, sys_newstat)
__SYSCALL(5, sys_newfstat)
__SYSCALL(6, sys_newlstat)
__SYSCALL(7, sys_poll)
__SYSCALL(8, sys_lseek)
__SYSCALL(9, sys_mmap)
......
__SYSCALL(442, sys_mount_setattr)
__SYSCALL(443, sys_quotactl_fd)
__SYSCALL(444, sys_landlock_create_ruleset)
__SYSCALL(445, sys_landlock_add_rule)
__SYSCALL(446, sys_landlock_restrict_self)
__SYSCALL(447, sys_memfd_secret)
__SYSCALL(448, sys_process_mrelease)
对syscall_64.c进行预编译之后我们可以发现sys_call_table数组的内容如下:
const sys_call_ptr_t sys_call_table[] = {
__x64_sys_read,
__x64_sys_write,
__x64_sys_open,
__x64_sys_close,
__x64_sys_newstat,
__x64_sys_newfstat,
__x64_sys_newlstat,
__x64_sys_poll,
__x64_sys_lseek,
__x64_sys_mmap,
__x64_sys_mprotect,
__x64_sys_munmap,
__x64_sys_brk,
......
__x64_sys_openat2,
__x64_sys_pidfd_getfd,
__x64_sys_faccessat2,
__x64_sys_process_madvise,
__x64_sys_epoll_pwait2,
__x64_sys_mount_setattr,
__x64_sys_quotactl_fd,
__x64_sys_landlock_create_ruleset,
__x64_sys_landlock_add_rule,
__x64_sys_landlock_restrict_self,
__x64_sys_memfd_secret,
__x64_sys_process_mrelease,
};
也就是说这是由一堆函数名构成的函数指针数组,那么这些函数名是怎么生成的呢?它是由一系列的SYSCALL_DEFINEx宏生成的,x代表函数的参数个数。我们以open系统调用来讲解一下,open系统调用的实现是在文件linux-src/fs/open.c
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_how how = build_open_how(flags, mode);
return do_sys_openat2(dfd, filename, &how);
}
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
我们把宏SYSCALL_DEFINE3展开之后大致可以得到如下的代码:
long __x64_sys_open(const struct pt_regs *regs)
{ return __se_sys_open(regs->di, regs->si, regs->dx); }
long __ia32_sys_open(const struct pt_regs *regs)
{ return __se_sys_open((unsigned int)regs->bx, (unsigned int)regs->cx, (unsigned int)regs->dx); }
static long __se_sys_open(__typeof(filename), __typeof(flags), __typeof(mode) )
{
long ret = __do_sys_open(( const char *) filename, ( int) flags, ( umode_t) mode);
return ret;
}
long __do_sys_open(const char * filename, int flags, umode_t mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
可以看出这个宏会生成函数__x64_sys_open,这个函数正好是sys_call_table数组里面的函数名。__x64_sys_open接受的参数是一个寄存器集的指针,然后提取寄存器中的值再调用函数__se_sys_open,函数__se_sys_open对参数进行强转再调用__do_sys_open,这个函数是最终的函数。我们可以看到这里面还生成了函数__ia32_sys_open,这个函数是32位进程兼容的系统调用所使用的数组ia32_sys_call_table的成员。
3.5 汇编程序演示
下面我们用汇编语言来试一试执行系统调用,一般情况下我们都不会直接使用系统调用指令,下面的例子仅仅是为了演示,标准编程中请使用API。
.data
msg:
.ascii "Hello from syscall !\n"
len = . - msg
.text
.global _start
_start:
movq $1, %rax
movq $1, %rdi
movq $msg, %rsi
movq $len, %rdx
syscall
movq $60, %rax
xorq %rdi, %rdi
syscall
执行如下命令,先汇编后链接
gcc -c -o hello-syscall64.o hello-syscall64.S
ld -entry _start hello-syscall64.o -o hello-syscall64
然后运行程序
./hello-syscall64
可以看到运行成功,命令行输出了 Hello from syscall !
下面我们再来演示一下32位进程兼容模式的系统调用,汇编代码如下:
.data
msg1:
.ascii "Hello from int 0x80 !\n"
len1 = . - msg1
msg2:
.ascii "Hello from sysenter !\n"
len2 = . - msg2
.text
.globl _start
_start:
movl $4, %eax
movl $1, %ebx
movl $msg1, %ecx
movl $len1, %edx
int $0x80
movl $4, %eax
movl $1, %ebx
movl $msg2, %ecx
movl $len2, %edx
call sys
movl $1, %eax
movl $0, %ebx
int $0x80
sys:
pushl %ecx
pushl %edx
pushl %ebp
movl %esp, %ebp
sysenter
popl %ebp
popl %edx
popl %ecx
ret
执行如下命令,先汇编后链接
gcc -m32 -c -o hello-syscall32.o hello-syscall32.S
ld -melf_i386 -entry _start hello-syscall32.o -o hello-syscall32
然后运行程序
./hello-syscall32
可以看到运行成功,命令行输出了
Hello from int 0x80 !
Hello from sysenter !
从上面的汇编代码示例中我们看到了用户空间是如何调用系统调用的,这也正是libc中的做法。我们前面有个内容没有讲,那就是执行了系统调用指令,CPU是如何切换到特权模式的。其实前面的系统调用入口函数设置里面也在相应的寄存器里面设置了__KERNEL_CS,这个会导致CPU切到特权模式来执行。
上述代码放到了github上:https://github.com/orangeboyye/hello-syscall
3.6 vsyscall与vdso
最刚开始的时候只有一种系统调用方式int 0x80,这时候libc都是直接使用这个指令。后来有个sysenter系统调用指令,libc就要考虑系统有没有sysenter指令,有的话就用sysenter,没有的话就用int 0x80。但是这对libc来说太难了,因此内核想了一个办法,把内核的一个page设置为用户空间可访问的,叫做vsyscall,libc通过这个vsyscall来进行系统调用,就不用有那么复杂的考虑了。对于内核来说,如果CPU支持sysenter并且内核自己也支持sysenter,就把vsyscall设置为sysenter,否则就设置为int 0x80。这对内核来说是一件非常简单的事。后来人们发现可以把一些系统调用的函数放到vsyscall里面,如果获取系统时间,这是一个只读的操作,而且对系统没有啥影响,放到vsyscall之后,libc就可以直接调用了,没有额外的开销。后来人们又觉得vsyscall的地址在内核空间,而且vsyscall没有一定的格式,这不太好。于是又开发了vdso,它是so的格式,在进程创建的时候映射到进程的地址空间,这样进程就可以像使用so一样使用vdso。再后来,64位的进程下只有一个系统调用指令,vsyscall的最初的作用就没有了意义,所以64位进程下的vsyscall和vdso就没有了系统调用指令兼容层的功能,就只剩下了可以直接调用一些系统调用函数的功能。
四、总结回顾
内核为了向用户空间提供服务,设计出了系统调用机制,系统调用机制可以让用户空间调用内核里的某些特定的函数。要实现系统调用机制需要有CPU提供的特殊指令才行。由于历史原因,系统调用指令在x86平台上不止有一个。系统调用指令的作用是把CPU模式切换到特权模式、让CPU跳到指定的入口函数来执行,并把用户空间提供的系统调用编号和参数传递进内核。入口函数根据系统调用编号调用相应的函数并传递参数,执行完毕后再返回用户空间。
我们一般情况下并不会直接使用系统调用,操作系统为我们提供了非常丰富的API,用起来更方便。
参考文献:
《Linux Kernel Development》
《Understanding the Linux Kernel》
《Professional Linux Kernel Architecture》
《Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 2》
https://man7.org/linux/man-pages/man2/intro.2.html
https://man7.org/linux/man-pages/man2/syscalls.2.html
https://man7.org/linux/man-pages/man2/_syscall.2.html
https://man7.org/linux/man-pages/man2/syscall.2.html
https://man7.org/linux/man-pages/man7/vdso.7.html



