
揭露内核黑科技 - 热补丁技术真容原创
内核热补丁是一种无需重启操作系统,动态为内核打补丁的技术。系统管理员基于该技术,可以在不重启系统的情况下,修复内核BUG或安全漏洞,可以在最大程度上减少系统宕机时间,增加系统的可用性。
一直很好奇内核热补丁这个黑科技,今天终于可以揭露它的真容了。当然这章的内容强烈依赖于前一章探秘ftrace[1]。有需要的小伙伴请自取。
从一个例子开始
作为一个小白,当然是从一个例子开始入手会比较简单。感谢内核社区开发着贴心的服务,在内核代码中,就有热补丁的例子在samples/livepatch目录下。
我们来看一个非常简单的例子,因为太简单了,我干脆就把整个代码都贴上来了。

我想,有一些内核开发经验的小伙伴,从这个例子中就可以猜出这个代码的作用。
将函数cmdline_proc_show替换成livepatch_cmdline_proc_show
怎么样,是不是炒鸡简单?
来点难的
上面的代码实在是太没有难度了,让我们来点挑战。看看这个klp_enable_patch究竟做了点什么。

怎么样,是不是有点傻眼了?这么多调用都是点啥?别急,其实这么多调用大多是花架子。如果你了解了klp_patch这个数据结构,我想一切都迎刃而解了。
klp_patch的数据结构
所以说大学时候学习算法和数据结构是非常有道理的,只可惜当年我压根就没有好好学习,以至于工作后不得不拼命补课。瞧,这时候又能用上了。
想要了解上面列出的klp_enable_patch这个函数的逻辑,还是要从klp_patch这个结构体入手。
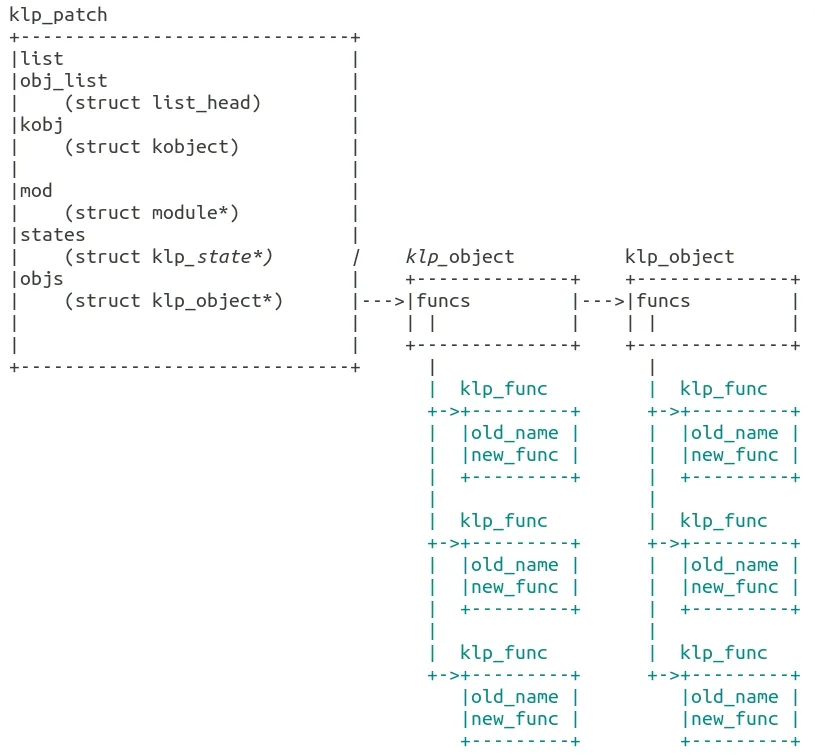
大家可以对照这例子代码中的klp_patch和这个图来帮助理解。
这个klp_patch就好像是一个二维数组
-
第一维是klp_object
-
第二维是klp_func
最后落实到klp_func标注了要替换的目标函数和替换成的新的函数。
知道了这个后,再回过去看刚才那一坨初始化的代码是不是会简单点?其实就是做了几个循环,把这个二维数组上所有的klp_object和klp_patch都初始化好。所有的初始化,大部分是创建对应的kobj,这样在/sys/kernel/livepatch/目录下就能控制每个热补丁点了。
真正的干货
到此为止,看了半天其实都没有看到热不定究竟是怎么打到内核代码上的。别急,小编这就给您娓娓道来。
在前面初始化的代码中,大家有没有看到一个函数–klp_patch_func?这个函数会对每个klp_func数据执行一遍。对了,魔鬼就在这里。
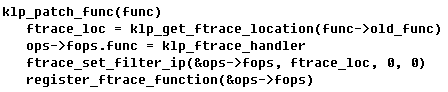
这几个可以说都是重量级的选手,让我慢慢给您一一讲解。
klp_get_ftrace_location
这个函数呢,就是要给出被替换的函数地址。首先我们在定义中并没有给出这个old_func的地址,所以第一步是要算出这个old_func。这部分工作在函数klp_init_object_loaded中通过klp_find_object_symbol查找symbol来得到。
ops->fops.func = klp_ftrace_handler
这是什么呢?对了,如果你对ftrace还有印象,这就是我们会替换掉ftrace探针的那个函数。也就是说,当我们的想要修改的函数被执行到时,这个klp_ftrace_handler就会被调用起来干活了。
ftrace_set_filter_ip
在探秘ftrace中,我们并没有展开这个ftrace_ops结构体。那这里我们就来展开看一下。

每个ftrace_ops上都有两个哈希表,还记得我们操作ftrace时候有两个文件 set_ftrace_filter / set_ftrace_notrace么?这两个文件分别用来控制我们想跟踪那个函数和不想跟踪那个函数。这两个集合在代码中就对应了ftrace_ops中的两个哈希表 filter_hash / notrace_hash。
所以 ftrace_set_filter_ip 就是用来将我们想要补丁的函数加到这个哈希表上的。
register_ftrace_function
这个函数的功效在探秘ftrace中已经描述过了一部分,这里我们将从另一个角度再次阐述。
register_ftrace_function函数的功效之一是将ftrace_ops结构体添加到全局链表ftrace_ops_list上,这么做有什么用呢?我们来看一下被ftrace插入到代码中的函数ftrace_ops_list_func。
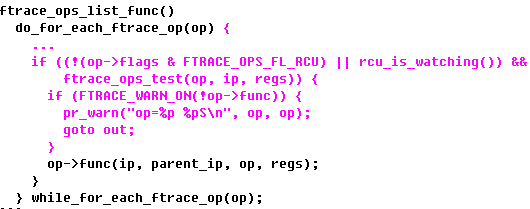
可以看到,每一个被ftrace改变的函数,如果在有多个ftrace_ops的情况下,会通过ftrace_ops_test()来判断当前函数是否符合这个ftrace_ops。如果符合才会执行op->func。(注意,这个func就是刚才设置的klp_ftrace_handler了。
而这个ftrace_ops_test()是怎么做判断的呢?对了,我想你已经猜到了,咱不是有两个哈希表么?
惊人一跃
到此为止,我们还是围绕着热补丁怎么利用ftrace的框架,让自己在特定的探针上执行,还没有真正看到所谓的补丁是怎么打上去的。是时候来揭开这层面纱了。
通过上述的操作,klp成功的在某个探针上嵌入了函数klp_ftrace_handler。那就看看这个函数吧。
klp_ftrace_handler(ip, parent_ip, fops, regs)
klp_arch_set_pc(regs, func->new_func)
regs->ip = ip;
怎么样,是不是有点吃惊,所谓的热补丁就是这么一个语句?理论上讲到这里,意思上也明白了,但是我依然想要弄清楚这个究竟是怎么一回事儿。
这一切还是要从ftrace的探针开始说起。
因为klp在设置ftrace_ops时添加了FTRACE_OPS_FL_SAVE_REGS,所以对应的探针是ftrace_reg_caller。经过一番刨根问底,终于发现了秘密。
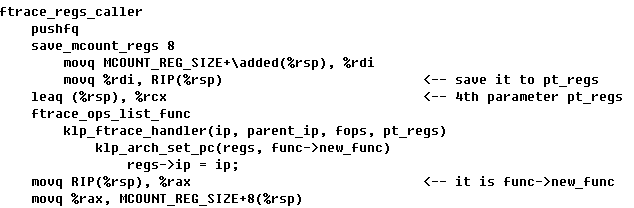
在探针执行ftrace_ops_list_func的前,会将调用探针的rip保存到堆栈上的regs参数中。然后在返回探针前,将rges->ip上的内容再恢复到函数返回地址上。此时如果有klp的探针函数,那么这个值就改变为了我们想改变成的函数了。
怎么样,原来黑科技是这么玩的!
这事儿有点抽象,让我画一个简易的堆栈示意一下。

一切的秘密都在这个堆栈上的return address里了。
到这里我才反应过来,原来黑科技就是黑客用的科技啊 :)
补充知识 – 函数返回地址
上面的这个黑科技运用到了一个x86架构下,如何保存函数返回是运行的地址的原理。也就是指令callq/retq是如何改变堆栈的。
那先说一下原理:
callq指令在跳转到目标代码前,会将自身的下一条指令的地址放到堆栈上。retq执行返回时,会从堆栈上取出目标地址然后跳转到那里。
这么说有点抽象了,咱们可以用gdb做一个简单的实验。
实验代码
一个再简单不过的add函数。
#include <stdio.h>
int add(int a, int b)
{
return a + b;
}
int main()
{
int a = 3;
a = a + 3;
add(a, 2);
return 0;
}
验证返回地址在堆栈上
使用gdb在add返回前停住,然后用下面的指令查看状态。
(gdb) disassemble
Dump of assembler code for function add:
0x00000000004004ed <+0>: push %rbp
0x00000000004004ee <+1>: mov %rsp,%rbp
0x00000000004004f1 <+4>: mov %edi,-0x4(%rbp)
0x00000000004004f4 <+7>: mov %esi,-0x8(%rbp)
0x00000000004004f7 <+10>: mov -0x8(%rbp),%eax
0x00000000004004fa <+13>: mov -0x4(%rbp),%edx
0x00000000004004fd <+16>: add %edx,%eax
0x00000000004004ff <+18>: pop %rbp
=> 0x0000000000400500 <+19>: retq
End of assembler dump.
(gdb) info registers rsp
rsp 0x7fffffffe2e8 0x7fffffffe2e8
(gdb) x/1xw 0x7fffffffe2e8
0x7fffffffe2e8: 0x00400523
首先我们看到在执行retq前,堆栈上的内容是0x00400523。
接着我们再执行一次stepi。
(gdb) stepi
main () at main.c:13
13 return 0;
(gdb) info registers rsp
rsp 0x7fffffffe2f0 0x7fffffffe2f0
(gdb) info registers rip
rip 0x400523 0x400523 <main+34>
此时我们看到堆栈变化了,而且rip的值和刚才堆栈上的值是一样的。
然后再反汇编一下,看到此时正要执行的指令就是callq后面的一条指令。
(gdb) disassemble
Dump of assembler code for function main:
0x0000000000400501 <+0>: push %rbp
0x0000000000400502 <+1>: mov %rsp,%rbp
0x0000000000400505 <+4>: sub $0x10,%rsp
0x0000000000400509 <+8>: movl $0x3,-0x4(%rbp)
0x0000000000400510 <+15>: addl $0x3,-0x4(%rbp)
0x0000000000400514 <+19>: mov -0x4(%rbp),%eax
0x0000000000400517 <+22>: mov $0x2,%esi
0x000000000040051c <+27>: mov %eax,%edi
0x000000000040051e <+29>: callq 0x4004ed <add>
=> 0x0000000000400523 <+34>: mov $0x0,%eax
0x0000000000400528 <+39>: leaveq
0x0000000000400529 <+40>: retq
End of assembler dump.
修改返回地址
接下来我们还能模拟热补丁,来修改这个返回值。(当然比较简陋些。)
我们在add函数执行retq前停住,用gdb改变堆栈上的值,让他指向mov的下一条指令leaveq。
(gdb) disassemble
Dump of assembler code for function add:
0x00000000004004ed <+0>: push %rbp
0x00000000004004ee <+1>: mov %rsp,%rbp
0x00000000004004f1 <+4>: mov %edi,-0x4(%rbp)
0x00000000004004f4 <+7>: mov %esi,-0x8(%rbp)
0x00000000004004f7 <+10>: mov -0x8(%rbp),%eax
0x00000000004004fa <+13>: mov -0x4(%rbp),%edx
0x00000000004004fd <+16>: add %edx,%eax
0x00000000004004ff <+18>: pop %rbp
=> 0x0000000000400500 <+19>: retq
End of assembler dump.
(gdb) info registers rsp
rsp 0x7fffffffe2e8 0x7fffffffe2e8
(gdb) x/1xw 0x7fffffffe2e8
0x7fffffffe2e8: 0x00400523
(gdb) set *((int *) 0x7fffffffe2e8) = 0x00400528
(gdb) x/1xw 0x7fffffffe2e8
0x7fffffffe2e8: 0x00400528
然后我们再执行stepi
(gdb) stepi
main () at main.c:14
14 }
(gdb) info registers rip
rip 0x400528 0x400528 <main+39>
(gdb) disassemble
Dump of assembler code for function main:
0x0000000000400501 <+0>: push %rbp
0x0000000000400502 <+1>: mov %rsp,%rbp
0x0000000000400505 <+4>: sub $0x10,%rsp
0x0000000000400509 <+8>: movl $0x3,-0x4(%rbp)
0x0000000000400510 <+15>: addl $0x3,-0x4(%rbp)
0x0000000000400514 <+19>: mov -0x4(%rbp),%eax
0x0000000000400517 <+22>: mov $0x2,%esi
0x000000000040051c <+27>: mov %eax,%edi
0x000000000040051e <+29>: callq 0x4004ed <add>
0x0000000000400523 <+34>: mov $0x0,%eax
=> 0x0000000000400528 <+39>: leaveq
0x0000000000400529 <+40>: retq
End of assembler dump.
瞧,这下是不是直接走到了leaveq,而不是刚才的mov?我们轻松的黑了一把。
好了,到这里就真的结束了,希望大家有所收获。
本文来自:Linux阅码场公众号,作者:理查德。



