
嵌入式linux-CPU性能优化小记原创
CPU性能优化小记
[TOC]
原文首次发表于https://www.cnblogs.com/wsg1100/p/16614373.html
一、现象
业务线反馈,单板只要一跑我们的通讯软件appA,CPU就变得很高,即使没有任何通讯,空跑时CPU利用率同样的高,难得业务会关注CPU性能,好久没更新博客了,小记一下(又是debug一两天,最后改一行代码解决的问题o(╯□╰)o)。
启动appA 前,top看一下CPU使用情况,如下,9%还算正常(有其他业务应用)。
Mem: 49320K used, 202284K free, 0K shrd, 0K buff, 27420K cached
CPU: 3.0% usr 6.0% sys 0.0% nic 91.0% idle 0.0% io 0.0% irq 0.0% sirq
Load average: 1.79 2.79 2.98 1/86 1721
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1721 1376 root R 2272 0.9 0 1.6 top -d 1
917 1 root S 38936 15.4 0 1.1 ...
908 1 root S 38936 15.4 0 0.5 ...
915 1 root S 38936 15.4 0 0.5 ...
896 1 root S 38936 15.4 0 0.5 ...
914 1 root S 38936 15.4 0 0.5 ...
857 1 root S 4396 1.7 0 0.5 /usr/**in/telnetd
3 2 root SW 0 0.0 0 0.5 [ksoftirqd/0]
1376 857 root S 2272 0.9 0 0.0 -sh
929 1 root S 2272 0.9 0 0.0 /**in/getty -L ttyO2 115200 vt100
1 0 root S 2268 0.9 0 0.0 init
...
我们的应用启动后,CPU使用率很高,65%左右,是什么让CPU占用高?
$top -d1
Mem: 54604K used, 197000K free, 0K shrd, 0K buff, 27220K cached
CPU: 14.6% usr 38.5% sys 0.0% nic 36.2% idle 0.0% io 0.0% irq 10.5% sirq
Load average: 3.26 2.22 1.58 1/107 1470
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1444 1376 root S 28008 11.1 0 5.8 {Thread_start} ./appA
3 2 root SW 0 0.0 0 4.0 [ksoftirqd/0]
1445 1376 root S 28008 11.1 0 2.9 {Task_OS_Timer} ./appA
1470 1376 root R 2272 0.9 0 2.3 top -d 1
917 1 root S 38936 15.4 0 1.7 ...
1450 1376 root S 28008 11.1 0 1.7 ...
896 1 root S 38936 15.4 0 1.1 ...
1449 1376 root S 28008 11.1 0 0.5 {CycleIO} ./appA
857 1 root S 4396 1.7 0 0.5 /usr/**in/telnetd
......
TOP各指标含义
简单介绍下top各指标含义。top 命令显示了 us、sy、nic、idle 、io、hi、si 和 st 这几个指标(不同版本的top显示简写有所不同),各指标含义如下,这几个指标之和为 100。
us, user : time running un-niced user processes
sy, system : time running kernel processes
ni, nice : time running niced user processes
id, idle : time spent in the kernel idle handler
wa, IO-wait : time waiting for I/O completion
hi : time spent servicing hardware interrupts
si : time spent servicing software interrupts
st : time stolen from this vm by the hypervisor
| CPU指标 | 含义 |
|---|---|
| us | CPU执行用户代码消耗的CPU时间比例,这个比例越高,说明CPU的利用率越好,因为我们的目的就是为了让CPU将更多的时间用在执行用户代码上,如果这个指标过高影响了你的业务,那就需要去分析业务代码了。 |
| sy | CPU执行内核代码消耗的CPU时间比例,这个比例要越低越好,因为CPU不应该把时间浪费在执行内核函数上,如内核函数浪费了很多时间,那说明内核可能需要优化了。 |
| ni | Nice值被调大的线程执行用户态代码消耗的CPU百分比。对于非实时任务,通过调整线程的Nice值可以控制它的CPU时间,当我们增大一个线程的Nice值时,我们期望它可以少占用一些CPU时间,CPU利用率里的ni这个值就给我们一个参考指标来观察我们的调整效果。<br />运行一个进程后,它的默认Nice值为0,通过renice来增加该进程的Nice值(正数),该进程的CPU利用率就会在ni中显示,而减少进程的Nice值(负数)则不会在这里面显示。 |
| id | CPU空闲时间,我们通常说的整体CPU利用率就是(100-idl)这个值,也是其他几项的和。为了提升系统的资源利用率,目标就是尽量降低idl。 |
| wa | CPU阻塞在I/O上的时间,比如CPU从磁盘读取文件内容,由于磁盘I/O太慢,导致CPU不得不等待数据就绪,然后才能继续执行下一步操作,这就wai时间,这个值越高,说明I/O处理能力出现了问题。 |
| hi | CPU消耗在硬中断里的时间,正常情况下这个值都很低,因为中断的处理很快,即使有大量的硬件中断,也不会消耗很多的CPU时间。 |
| si | CPU消耗在软中断里的时间,系统中常见的软中断有网络收发包软中断、写文件落盘产生的软中断、高精度定时器软中断等。所以网络吞吐量较高的系统中,这个值也会高一些。 |
在上面这几项中,idle 和 wait 是 CPU 不工作的时间,其余的项都是 CPU 工作的时间。idle 和 wait 的主要区别是,idle 是 CPU 无事可做,而 wait 则是 CPU 想做事却做不了。你也可以将 wait 理解为是一类特殊的 idle,即该 CPU 上有至少一个线程阻塞在 I/O 时的 idle。
二、分析
由CPU: 14.6% usr 38.5% sys 0.0% nic 36.2% idle 0.0% io 0.0% irq 10.5% sirq可以看出,CPU 利用率飙高是由 sys 利用率和sirq利用率变高导致的,也就是说 sys 利用率会忽然飙高一下,比如在 usr 低于 15% 的情况下,sys 会高于 40%,同时sirq会高于10%,持续不到一秒后又恢复正常。
**CPU 的 sys 利用率高,说明内核函数执行花费了太多的时间,同样,CPU 的 sirq利用率高,说明内核处理软中断执行花费了太多的时间,**先对比应用启动前后系统各部分信息,看看能否推断出CPU执行哪部分的的内核函数花费的时间长。
启动应用前
我们先通过pidstat看看appA启动前,系统中每个进程usr、system、guest、wait各部分CPU使用情况:
$ pidstat 1 3 #每秒打印一次 打印3次
Linux 3.12.10 08/22/22 _armv7l_ (1 CPU)
09:45:44 UID PID %usr %system %guest %wait %CPU CPU Command
09:45:44 0 47 0.00 0.96 0.00 0.00 0.96 0 kworker/0:1
09:45:44 0 894 2.88 3.85 0.00 0.00 6.73 0 cpu_mem_task
09:45:44 0 968 0.00 1.92 0.00 0.00 1.92 0 pidstat
09:45:44 UID PID %usr %system %guest %wait %CPU CPU Command
09:45:45 0 857 0.00 1.00 0.00 0.00 1.00 0 telnetd
09:45:45 0 881 0.00 1.00 0.00 0.00 1.00 0 xxxx
09:45:45 0 894 2.00 5.00 0.00 0.00 7.00 0 xxxx
09:45:45 0 968 1.00 2.00 0.00 0.00 3.00 0 pidstat
09:45:45 UID PID %usr %system %guest %wait %CPU CPU Command
09:45:46 0 3 0.00 1.00 0.00 0.00 1.00 0 ksoftirqd/0
09:45:46 0 894 1.00 6.00 0.00 0.00 7.00 0 xxxx
09:45:46 0 968 1.00 2.00 0.00 0.00 3.00 0 pidstat
可以看到,各进程正常,CPU使用率低,接下来通过mpstat 查看内核各部分详细。
]# mpstat --help Usage: mpstat [ options ] [ <interval> [ <count> ] ] Options are: [ -A ] [ -n ] [ -T ] [ -u ] [ -V ] [ -I { SUM | CPU | SCPU | ALL } ] [ -N { <node_list> | ALL } ] [ --dec={ 0 | 1 | 2 } ] [ -o JSON ] [ -P { <cpu_list> | ALL } ]
- -A: 等同于-u -I ALL -P ALL
- -I:指定SUM CPU SCPU ALL四个参数,SUM表示每个处理器的中断总数,CPU表示每个核的每秒中断数量, SCPU表示每个核每秒的软中断数量。
- -P: 统计的CPU编号,一般用ALL
- -u: 输出列的信息
- -V: 查看版本号
- CPU利用率
每秒输出1次, 输出5次:
[root@/tmp]# mpstat 1 5
09:49:51 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
09:49:52 all 1.01 0.00 5.05 0.00 0.00 2.02 0.00 0.00 0.00 91.92
09:49:53 all 2.15 0.00 1.08 0.00 0.00 0.00 0.00 0.00 0.00 96.77
09:49:54 all 0.00 0.00 0.00 0.00 0.00 1.09 0.00 0.00 0.00 98.91
09:49:55 all 2.04 0.00 3.06 0.00 0.00 2.04 0.00 0.00 0.00 92.86
09:49:56 all 0.00 0.00 2.15 0.00 0.00 0.00 0.00 0.00 0.00 97.85
Average: all 1.05 0.00 2.32 0.00 0.00 1.05 0.00 0.00 0.00 95.58
- 软中断
软中断每秒输出1次, 输出6次:
# mpstat -I SCPU 1 6
09:51:22 CPU HI/s TIMER/s NET_TX/s NET_RX/s BLOCK/s BLOCK_IOPOLL/s TASKLET/s SCHED/s HRTIMER/s RCU/s
09:51:23 0 0.00 25.00 1.00 3.00 0.00 0.00 0.00 0.00 200.00 0.00
09:51:24 0 0.00 31.00 0.00 4.00 0.00 0.00 0.00 0.00 200.00 0.00
09:51:25 0 0.00 26.00 0.00 4.00 0.00 0.00 0.00 0.00 199.00 0.00
09:51:26 0 0.00 36.00 0.00 4.00 0.00 0.00 0.00 0.00 200.00 0.00
09:51:27 0 0.00 31.00 0.00 3.00 0.00 0.00 0.00 0.00 199.00 0.00
09:51:28 0 0.00 31.00 1.00 3.00 0.00 0.00 0.00 0.00 200.00 0.00
Average: 0 0.00 30.00 0.33 3.50 0.00 0.00 0.00 0.00 199.67 0.00
对应的软中断信息:
# cat /proc/softirqs
CPU0
HI: 0
TIMER: 7778445
NET_TX: 7244
NET_RX: 293406
BLOCK: 0
BLOCK_IOPOLL: 0
TASKLET: 1
SCHED: 0
HRTIMER: 522165833
RCU: 0
- 硬中断
处理器硬中断总数:
# mpstat -I SUM 1 6
Linux 3.12.10 08/22/22 _armv7l_ (1 CPU)
09:54:50 CPU intr/s
09:54:51 all 3000.00
09:54:52 all 3151.00
09:54:53 all 3229.00
09:54:54 all 3129.00
09:54:55 all 3049.00
09:54:56 all 3210.00
Average: all 3127.79
每个硬中断产生速率:
# mpstat -I CPU 1 6
Linux 3.12.10 08/22/22 _armv7l_ (1 CPU)
09:56:46 CPU 20/s 28/s 30/s 33/s 34/s 35/s 68/s 80/s 84/s 86/s 87/s 90/s 94/s 116/s 125/s 127/s 173/s 230/s 233/s 255/s 261/s Err/s
09:56:47 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3151.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 5.00 0.00 0.00 0.00 0.00 0.00
09:56:48 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3140.00 0.00 4.00 0.00 0.00 0.00 0.00 0.00 7.00 0.00 0.00 0.00 0.00 0.00
09:56:49 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3355.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6.00 0.00 0.00 0.00 0.00 0.00
09:56:50 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3031.00 0.00 4.00 0.00 0.00 0.00 0.00 0.00 4.00 0.00 0.00 0.00 0.00 0.00
09:56:51 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3288.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6.00 0.00 0.00 0.00 0.00 0.00
09:56:52 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3155.00 0.00 4.00 0.00 0.00 0.00 0.00 0.00 6.00 0.00 0.00 0.00 0.00 0.00
Average: 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3186.67 0.00 2.00 0.00 0.00 0.00 0.00 0.00 5.67 0.00 0.00 0.00 0.00 0.00
对应的中断信息:
# cat /proc/interrupts
CPU0
84: 1583852200 INTC 68 gp_timer
86: 108 INTC 70 44e0b000.i2c
87: 483682 INTC 71 4802a000.i2c
90: 59 INTC 74 UART2
173: 701497 GPIO 29 eth0
230: 6 GPIO 22 button_int
233: 0 GPIO 25 fpga_int
255: 0 GPIO 15 mmc0
261: 0 GPIO 21 power_int
Err: 0
......
启动appA应用前,可以看出irq为84的中断gp_timer中断比较高, 3155次/S左右。
启动应用后
先启动应用,然后再看一下这些指标的变化。
# mpstat 1 5
Linux 3.12.10 08/22/22 _armv7l_ (1 CPU)
10:10:45 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:10:46 all 7.95 0.00 18.18 0.00 0.00 3.41 0.00 0.00 0.00 70.45
10:10:47 all 6.17 0.00 16.05 0.00 0.00 1.23 0.00 0.00 0.00 76.54
10:10:48 all 4.94 0.00 17.28 0.00 0.00 2.47 0.00 0.00 0.00 75.31
10:10:49 all 8.05 0.00 17.24 0.00 0.00 4.60 0.00 0.00 0.00 70.11
10:10:50 all 11.76 0.00 12.94 0.00 0.00 2.35 0.00 0.00 0.00 72.94
Average: all 7.82 0.00 16.35 0.00 0.00 2.84 0.00 0.00 0.00 72.99
usr,sys 升高明显,soft有所升高,什么导致的sys升高?下面看硬中断处理信息:
# mpstat -I SUM 1 6
Linux 3.12.10 08/22/22 _armv7l_ (1 CPU)
10:12:11 CPU intr/s
10:12:12 all 6571.00
10:12:13 all 6597.00
10:12:14 all 6574.00
10:12:15 all 6566.00
10:12:16 all 6592.00
10:12:17 all 6583.00
Average: all 6580.50
对比启动应用前3000/s,每秒中断产生次数增长了120%。继续查看哪些中断变高了?
# mpstat -I CPU 1 6
Linux 3.12.10 08/22/22 _armv7l_ (1 CPU)
10:15:04 CPU 20/s 28/s 30/s 33/s 34/s 35/s 68/s 80/s 84/s 86/s 87/s 90/s 94/s 116/s 125/s 127/s 173/s 230/s 233/s 255/s 261/s Err/s
10:15:05 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6552.00 0.00 3.00 0.00 0.00 0.00 0.00 0.00 28.00 0.00 0.00 0.00 0.00 0.00
10:15:06 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6552.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 30.00 0.00 0.00 0.00 0.00 0.00
10:15:07 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6637.00 0.00 4.00 0.00 0.00 0.00 0.00 0.00 27.00 0.00 0.00 0.00 0.00 0.00
10:15:08 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6543.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 28.00 0.00 0.00 0.00 0.00 0.00
10:15:10 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6579.00 0.00 4.00 0.00 0.00 0.00 0.00 0.00 30.00 0.00 0.00 0.00 0.00 0.00
10:15:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6561.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 29.00 0.00 0.00 0.00 0.00 0.00
Average: 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6570.67 0.00 1.83 0.00 0.00 0.00 0.00 0.00 28.67 0.00 0.00 0.00 0.00 0.00
# mpstat -I SCPU 1 6
Linux 3.12.10 08/22/22 _armv7l_ (1 CPU)
10:20:29 CPU HI/s TIMER/s NET_TX/s NET_RX/s BLOCK/s BLOCK_IOPOLL/s TASKLET/s SCHED/s HRTIMER/s RCU/s
10:20:30 0 0.00 41.58 0.00 9.90 0.00 0.00 0.00 0.00 2172.28 0.00
10:20:31 0 0.00 43.00 0.00 12.00 0.00 0.00 0.00 0.00 2187.00 0.00
10:20:32 0 0.00 38.00 0.00 11.00 0.00 0.00 0.00 0.00 2191.00 0.00
10:20:33 0 0.00 34.00 1.00 10.00 0.00 0.00 0.00 0.00 2190.00 0.00
10:20:34 0 0.00 37.00 0.00 11.00 0.00 0.00 0.00 0.00 2190.00 0.00
10:20:35 0 0.00 40.00 0.00 10.00 0.00 0.00 0.00 0.00 2184.00 0.00
Average: 0 0.00 38.94 0.17 10.65 0.00 0.00 0.00 0.00 2185.69 0.00
可以看irq为84的中断gp_timer中断相比应用启动前变为2倍, 3155.00次/S左右。相应的高精度定时器软中断HRTIMER从之前的200/S上升到2100/S,到此基本可以确定应用疯狂定时操作引起的,进一步看内核执行的函数来确认。
采集内核函数的方法
目前基本清楚因为定时器中断变高导致的内核函数执行时间变长,接下来采集 CPU 在 sys 飙高的瞬间所执行的内核函数,同时看看应用执行什么引起的定时器中断,再做相应的优化。采集内核函数的方法有很多,比如:
-
通过 perf( perf 是内核自带的性能剖析工具) 可以采集 CPU 的热点,看看 sys 利用率高时,哪些内核耗时的 CPU 利用率高;
-
通过 perf 的
call-graph功能可以查看具体的调用栈信息,也就是线程是从什么路径上执行下来的; -
通过 perf 的
annotate功能可以追踪到线程是在内核函数的哪些语句上比较耗时; -
通过 ftrace 的
function-graph功能可以查看这些内核函数的具体耗时,以及在哪个路径上耗时最大。 -
针对一些瞬时sys 利用率高问题,还可以通过系统快照sysrq,把当前 CPU 正在做的工作记录下来,然后结合内核源码分析为什么 sys 利用率会高。
sysrq常用来分析内核问题的工具,用它可以观察当前的内存快照、任务快照,可以构造 vmcore 把系统的所有信息都保存下来,甚至还可以在内存紧张的时候用它杀掉内存开销最大的那个进程。
用 sysrq 来分析问题,首先需要使能 sysyrq,使能sysrq后没有任何开销,使能方式如下:
$ sysctl -w kernel.sysrq=1sysrq 的功能被使能后,使用它的 -t 选项来把当前的任务快照保存下来,看看系统中都有哪些任务,以及这些任务都在干什么。使用方式如下:
$ echo t > /proc/sysrq-trigger执行后,任务快照会被打印到内核缓冲区,这些任务快照信息通过
dmesg命令来查看:$ dmesg
内核采集分析
这里使用perf 对appA进程进行采样,输出内核整个调用链上的汇总信息。
# 采样10s后退出
$ perf record -a -g -p `pidof appA` -- sleep 10
采样完成后,继续执行 perf report命令,得到 perf 的汇总报告。
额。。。屏幕太小、ARM 串口来打印,这打印很难看。
火焰图分析
针对 perf 汇总数据的展示问题,Brendan Gragg 发明了火焰图,通过矢量图的形式,更直观展示汇总结果。
(图片来自 Brendan Gregg 博客)
-
横轴表示采样数和采样比例。一个函数占用的横轴越宽,就代表它的执行时间越长。同一层的多个函数,则是按照字母来排序。
-
纵轴表示调用栈,由下往上根据调用关系逐个展开。换句话说,上下相邻的两个函数中,下面的函数,是上面函数的父函数。这样,调用栈越深,纵轴就越高。
另外,要注意图中的颜色,并没有特殊含义,只是用来区分不同的函数。
火焰图是动态的矢量图格式,所以它还支持一些动态特性。比如,鼠标悬停到某个函数上时,就会自动显示这个函数的采样数和采样比例。而当你用鼠标点击函数时,火焰图就会把该层及其上的各层放大,方便你观察这些处于火焰图顶部的调用栈的细节。
如果我们根据性能分析的目标来划分,火焰图可以分为下面这几种。
- on-CPU 火焰图:表示 CPU 的繁忙情况,用在 CPU 使用率比较高的场景中。
- off-CPU 火焰图:表示 CPU 等待 I/O、锁等各种资源的阻塞情况。
- 内存火焰图:表示内存的分配和释放情况。
- 热 / 冷火焰图:表示将 on-CPU 和 off-CPU 结合在一起综合展示。
- 差分火焰图:表示两个火焰图的差分情况,红色表示增长,蓝色表示衰减。差分火焰图常用来比较不同场景和不同时期的火焰图,以便分析系统变化前后对性能的影响情况。
如何生成火焰图?首先,下载几个能从 perf record 记录生成火焰图的工具,这些工具都放在 https://github.com/brendangregg/FlameGraph 。
$ git clone https://github.com/brendangregg/FlameGraph
$ cd FlameGraph
安装好工具后,要生成火焰图,其实主要需要三个步骤:
- 执行
perf script,将perf record的记录转换成可读的采样记录; - 执行
stackcollapse-perf.pl脚本,合并调用栈信息; - 执行
flamegraph.pl脚本,生成火焰图。
如果你的机器安装了完整的系统,通过管道简化这三个步骤的执行如下:
$ perf script -i /root/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > hsys.svg
因为我的目标系统是在ARM busybos上,先在目标机器上执行步骤1,在将中间文件上传到X86系上完成步骤2和3。
$ perf script -i perf.data > perf-temp
$ tftp -p 192.168.1.55 -l perf-temp
X86机器上完成步骤2和3.
$ cat perf-temp| ./stackcollapse-perf.pl --all | ./flamegraph.pl > hsys.svg
使用浏览器打开hsys.svg如下。
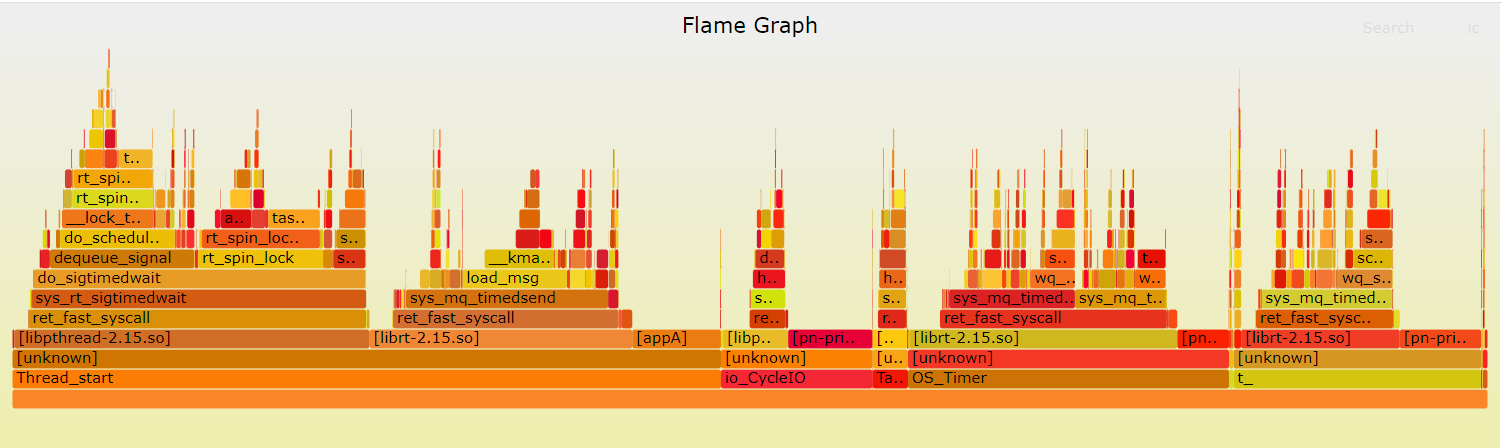
从下往上看,沿着调用栈中最宽的函数来分析执行次数最多的函数。看到的结果跟的 perf report 类似,但直观了很多,这几团系统调用的火焰,就是我们关注的地方。
可以看到,应用发起的几个系统调用后,内核sys_rt_sigtimedwait、sys_mq_timedsend、sys_mq_timedreceive分别占总执行时间的22.69%、(13.71%+6.15%)、(8.53%+8.89%)。
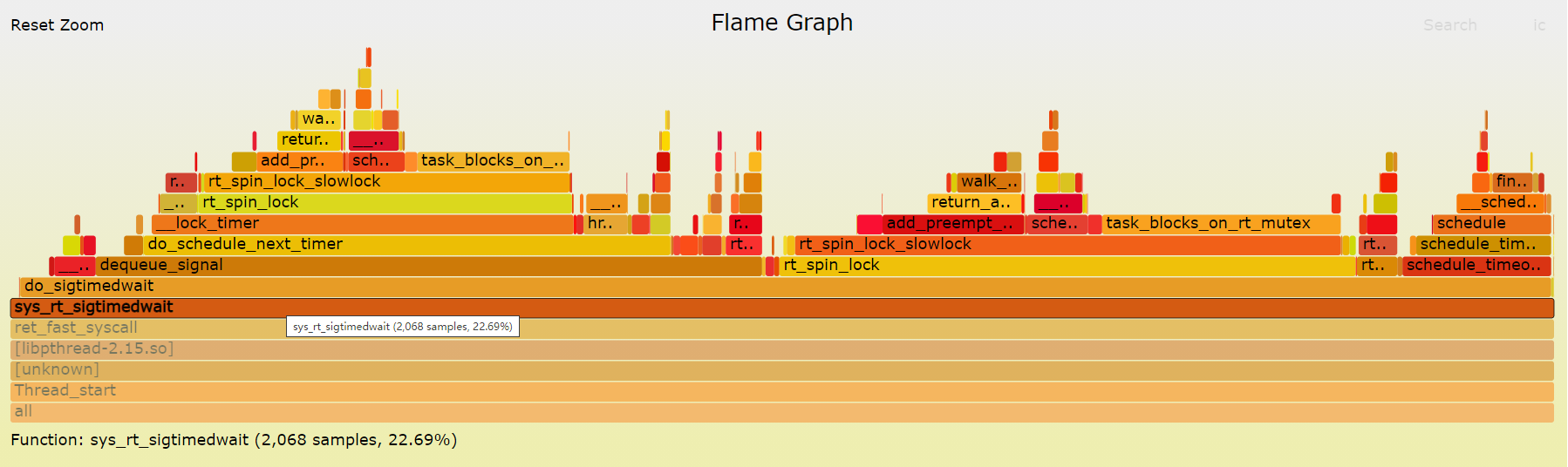
到这里,找出了内核执行最频繁的函数调用堆栈,而这个堆栈中的各层级函数,就是潜在的性能瓶颈来源。对比同一cpu高版本内核,该问题并不明显,如果想深入了解linux时间子系统,请移步时间子系统-蜗窝科技。看来内核是动不了,不好下手,那回到应用看看。
三、解决
既然已经清楚原因是应用定时相关操作引起的,回到应用排查相关代码。
这个应用是一个协议栈,整个协议栈有多个不同优先级的实时线程,每个线程负责各部分通讯处理,其中两个线程为整个协议栈提供timers处理机制,线程Thread_start向操作系统注册一个周期timer,该周期timer的间隔就是协议栈软件timer的基准时间,线程A周期等待操作系统timer超时信号。
当超时信号到达时,线程Thread_start遍历所有上层应用注册的timer,判断时间是否到期,如果该timer到期,通过消息队列mq将该timer发送给另一个线程OS_timer进行timer处理,线程OS_timer接收到该timer后,执行该timer注册的超时回调函数callbalk_timeout。
排查后发现,问题出在线程Thread_start向操作系统注册的这个周期timer,它的触发间隔为500us,由于触发频率太高,导致操作系统处理定时器软硬中断消耗大部分CPU,表现就是系统cpu飙高,但是检索整个协议栈,并没有发现上层应用注册小于1ms的timer,协议栈根本用不到这么小基准的timer。
所以,解决的办法很简单,就修改一行代码,将线程Thread_start向操作系统注册的周期timer间隔500us调整为1ms,问题解决。
优化后,时钟软硬中断降低。系统sys CPU利用率下降,如下:
$ pidstat 1 5 -p `pidof appA` #目标应用指标
Linux 3.12.10 08/22/22 _armv7l_ (1 CPU)
17:32:45 UID PID %usr %system %guest %wait %CPU CPU Command
17:32:46 0 1112 8.91 0.99 0.00 0.00 9.90 0 appA
17:32:47 0 1112 3.00 8.00 0.00 0.00 11.00 0 appA
17:32:48 0 1112 8.00 3.00 0.00 0.00 11.00 0 appA
17:32:49 0 1112 10.00 1.00 0.00 0.00 11.00 0 appA
$mpstat -A 1 1 #系统整体详细指标
Linux 3.12.10 08/22/22 _armv7l_ (1 CPU)
17:35:24 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
17:35:25 all 1.20 0.00 10.84 0.00 0.00 0.00 0.00 0.00 87.95
17:35:25 0 1.20 0.00 10.84 0.00 0.00 0.00 0.00 0.00 87.95
17:35:24 CPU intr/s
17:35:25 all 6821.69
17:35:25 0 6820.48
17:35:24 CPU 20/s 28/s 30/s 33/s 34/s 35/s 68/s 80/s 84/s 86/s 87/s 90/s 94/s 116/s 125/s 127/s 173/s 230/s 233/s 255/s 261/s Err/s
17:35:25 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 6792.77 0.00 3.61 0.00 0.00 0.00 0.00 0.00 24.10 0.00 0.00 0.00 0.00 0.00
17:35:24 CPU HI/s TIMER/s NET_TX/s NET_RX/s BLOCK/s BLOCK_IOPOLL/s TASKLET/s SCHED/s HRTIMER/s RCU/s
17:35:25 0 0.00 30.12 1.20 13.25 0.00 0.00 0.00 0.00 1443.37 0.00
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
Average: all 1.20 0.00 10.84 0.00 0.00 0.00 0.00 0.00 87.95
Average: 0 1.20 0.00 10.84 0.00 0.00 0.00 0.00 0.00 87.95
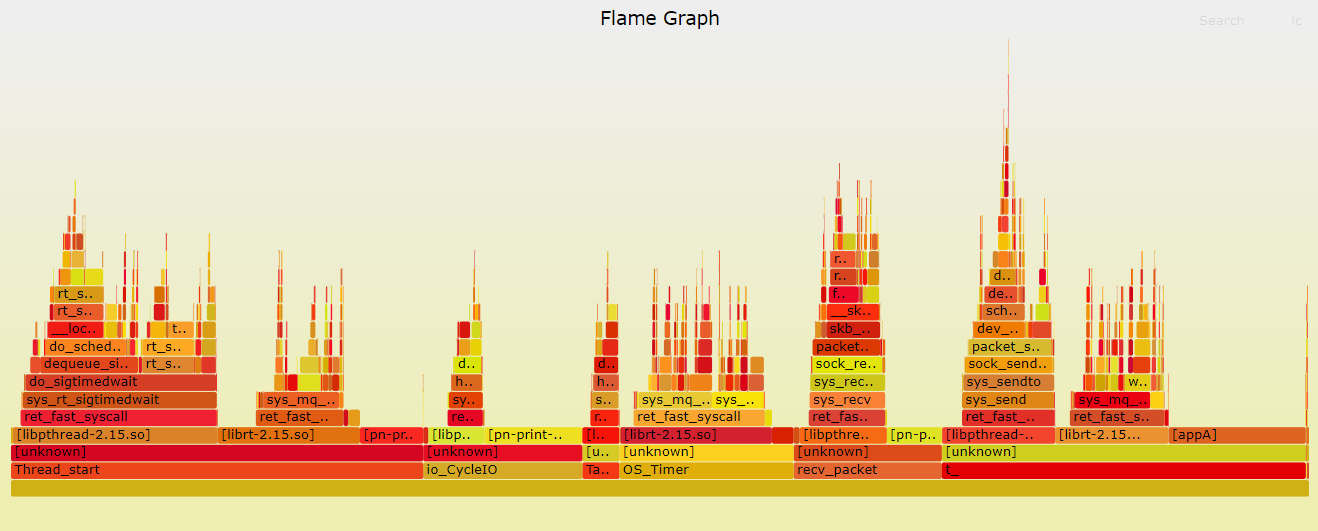
对比上面的火焰图,看到sys_rt_sigtimedwait、sys_mq_timedsend、sys_mq_timedreceive明显降低.
| sys_rt_sigtimedwait | sys_mq_timedsend | sys_mq_timedreceive | |
|---|---|---|---|
| 前 | 22.69% | 19.86%(13.71%+6.15%) | 17.51%(8.53%+8.89%) |
| 后 | 14.94% | 9.84%(5.84%+4%) | 11.47%(5.67%+5.8%) |
真是debug一两天,最后改一行代码解决问题o(╯□╰)o)。。。



