
大纲
第一篇:JVM是如何创建对象的?了解 JDK8 下 Java 对象的内存分配和创建过程
第二篇:你真的了解垃圾回收吗:引用计数法和可达性分析举例、垃圾收集算法介绍
第三篇:聊一聊Java异常:JVM是如何捕获异常原理和实例分析
第四篇:聊聊Java的数据类型:基础数据类型、引用数据类型和存储结构
正文
在我刚接触 Java 学习时,第一个上手的程序就是关于 int 类型变量的计算,然后输出执行结果。后来慢慢地又接触到其他类型的变量,比如 long、double、char 等等,看起来都挺简单的。但是我们都听过 Java 是一门面向对象的开发语言,绝不可能仅限于这些基本的数据类型,于是又认识了 Integer、Double、Long 等数据类型,我们称之为基本数据类型的包装类。
上述基本数据类型和对应的包装类(也称为引用类型),构成了 Java 虚拟机的数据类型。后续我们面对对象开发,构建的一个个类对象,都是基于这些数据类型实现的。与数据类型一样,Java 中存在原始值和引用值两种类型的数值,它们可用于变量赋值、参数传递、方法返回和运算操作。
除了 Java 语言,我当初因为想学习数据分析,花了一段时间来学习 Python,就我个人而言,Python 比 Java 更容易入门,比如说给变量赋值时不需要声明变量类型,代码更加简洁等等。回归正题,我主要想说 Python 只有五个标准的数据类型:Numbers(数字)、String(字符串)、List(列表)、Tuple(元组)和Dictionary(字典),不像 Java 的数据类型那么复杂。
我们思考这样一个问题,Java 是面向对象的,为什么要设计这些基本数据类型,只要引用类型不可以吗?
基本数据类型肯定有其优势,总结如下:
1、基本数据类型因为简单易学,使用比较频繁;
2、存在栈中,占用存储空间小,可以快速创建;
3、栈上执行逻辑操作效率更高。
即便基本数据类型那么方便,也不能不引入引用类型,Java 是面向对象的,而基本数据类型不具备面向对象的属性。
Java 数据类型的结构如下图所示:
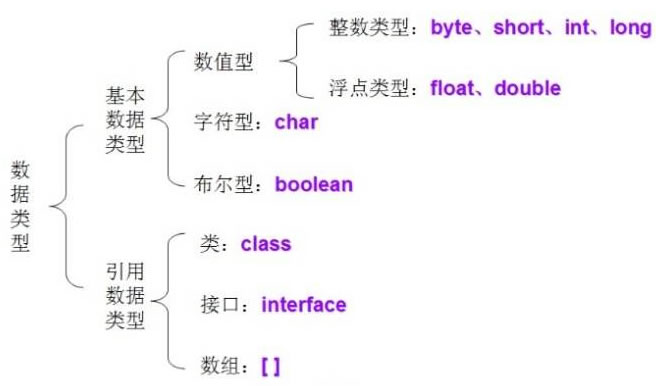
接下来我们就更深入地学习一番这些数据类型,了解它们在 JVM 中的定义和存储等。
基本数据类型
Java 有八大基本数据类型,如下图所示:
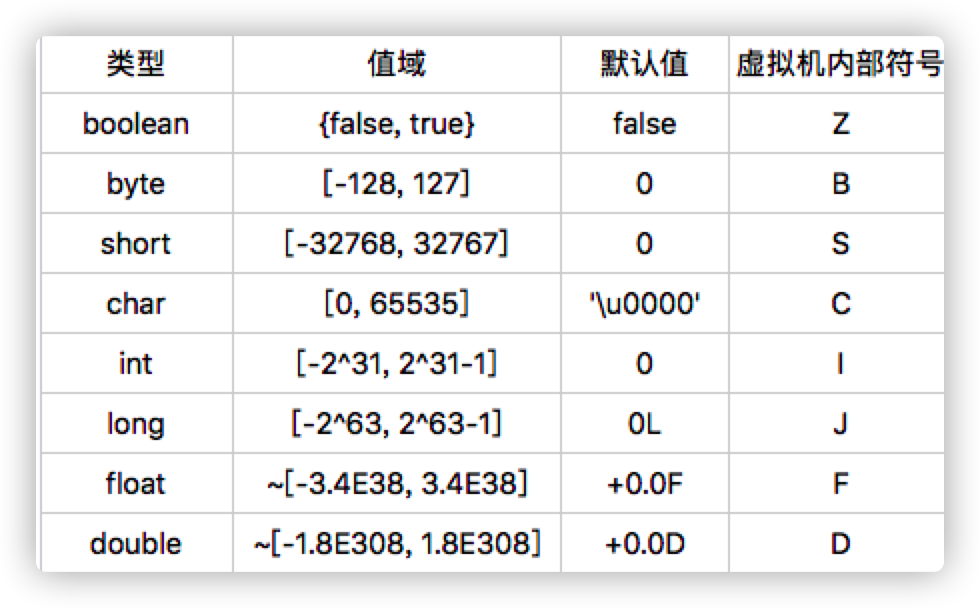
- byte 类型:值为8位有符号二进制补码整数;
- short 类型:值为16位有符号二进制补码整数;
- int 类型:值为32位有符号二进制补码整数;
- long 类型:值为64位有符号二进制补码整数;
- char 类型:值为16位无符号二进制补码整数;
- float 类型:值为单精度浮点数集合中的元素;
- double 类型:值为双精度浮点数集合中的元素;
- boolean 类型:值为 true 和 false。
boolean 和 char 是唯二的无符号类型。在不考虑违反规范的情况下,boolean 类型的取值范围是 0 或者 1。char 类型的取值范围则是[0, 65535]。
NaN 有一个有趣的特性:除了“!=”始终返回 true 之外,所有其他比较结果都会返回 false。
举例来说,“NaN<1.0F”返回 false,而“NaN>=1.0F”同样返回 false。对于任意浮点数 f,不管它是 0 还是 NaN,“f!=NaN”始终会返回 true,而“f==NaN”始终会返回 false。
整数类型
Java 定义了 4 种整数类型变量:字节型(byte)、短整型(short)、整型(int)和长整型(long),分别表示8位、16位、32位、64位的有符号补码整数。
上面提到的二进制补码整数,是怎么一回事呢?
整数在计算机中使用补码表示,在 Java 虚拟机中也不例外。学习补码之前,我们必须理解原码和反码。
原码,就是符号位加上数字的二进制表示,以 int 为例,第1位表示符号位(0表示整数,1表示负数),其余 31位表示该数字的二进制值。
10的原码为:00000000 00000000 00000000 00001010
-10的原码为:10000000 00000000 00000000 00001010反码是在原码的基础上,符号位不变,其余位取反,以 -10为例,其反码为:
11111111 11111111 11111111 11110101说完原码和反码,现在来看一下补码,正数的补码就是原码本身,负数的补码就是反码加1。
10的补码为:00000000 00000000 00000000 00001010
-10的补码为:11111111 11111111 11111111 11110110通过代码来查看补码:
int a = -10;
for (int i = 0; i < 32; i++) {
int t = (a & 0x80000000 >>> i) >>> (31 - i);
System.out.print(t);
}
//执行结果为:
11111111111111111111111111110110为什么计算机使用补码来存储整数呢?至少有以下两个好处:
1、上面我们只说了正数和负数的补码表示,没有提到0,由于0既非正数,也非负数,所以使用原码表示符号位难以确定,把0归入正数或负数得到的原码结果是不同的。但是用补码表示,无论把0归入正数或负数结果是一致的。
假设0为正数,则0的补码结果为:
00000000 00000000 00000000 00000000假设0为负数,
0的原码:10000000 00000000 00000000 00000000
0的反码:11111111 11111111 11111111 11111111
0的补码:00000000 00000000 00000000 00000000可以看到,使用补码作为整数编码,可以解决数字0的存储问题。
2、使用补码可以简化整数的加减法计算,即减法计算可以视为加法计算,虽然我们做的是减法,计算机可以当作加法来处理。
比如说 10-5,可以看作为 -5+10。
-5的补码为:11111111 11111111 11111111 11111011
10的补码为:00000000 00000000 00000000 00001010
相加结果为:00000000 00000000 00000000 00000101所以最后结果为 5。
对于补码有了一个大概的了解后,我们继续来学习整数类型在 Java 虚拟机中的使用。
我们来演示一个示例:
public static void addTest() {
byte a = 20;
short b = 12;
int i = 14;
long l = 30;
long sum = a + b + i + l;
}查看其字节码内容如下:
0: bipush 20
2: istore_0 //将int型数值存入第一个本地变量
3: bipush 12
5: istore_1
6: bipush 14
8: istore_2
9: ldc2_w #2 // long 30l,将long型数值推送至栈顶
12: lstore_3
13: iload_0
14: iload_1
15: iadd
16: iload_2
17: iadd
18: i2l // 将int型数值强制转换为 long并将结果压入栈顶
19: lload_3
20: ladd
21: lstore 5
23: return可以看到,byte 和 short 转换为 int 型(隐式转换),使用的都是 istore 和 iload 指令。加法计算最后得到的数值类型为 long 型,范围更大,其中发生了一次强制类型转换。
再看下面这个问题:
对于 short s1 = 1; s1 = s1 + 1;由于 1 是 int 类型,因此 s1+1 运算结果也是 int 型,需要强制转换类型才能赋值给 short 型。而 short s1 = 1; s1 += 1;可以正确编译,因为 s1+= 1;相当于 s1 = (short)(s1 + 1);其中有隐含的强制类型转换。
最终我们得到如下结论,byte 和 short 在计算时会隐式转换为 int 型,int 型需要强制转换才能变为 long 型。
浮点类型
浮点类型是带有小数部分的数据类型。浮点型数据包括单精度浮点型(float)和双精度浮点型(double),代表有小数精度要求的数字。
单精度浮点型(float)和双精度浮点型(double)之间的区别主要是所占用的内存大小不同,float 类型占用 4 字节的内存空间,double 类型占用 8 字节的内存空间。双精度类型 double 比单精度类型 float 具有更高的精度和更大的表示范围。
一个浮点数由3部分组成,分别是:符号位、指数位和尾数位。以 32 位 float 为例,符号位占1位,表示正负数,指数位占8位,尾数位占剩余的 23 位,如下图所示:

其中 sflag 表示符号,当 s为0时,sflag 为1,当 s为1时,sflag 为-1。e为指数位,8位表示。m 为尾数值,实际占用空间为 23位,但是根据 e的取值,有 24位精度。当 e全为0时,尾数位附加为0,否则,尾数位附加为1,附加是指在最左侧加一位,值为0或1。
以浮点数 -5f 为例,其内部表示为:
1 10000001 01000000000000000000000符号位 1表示负数,指数位为 10000001,表示 129。因为 e不全为0,尾数位附加1,即为 101000000000000000000000。
尾数计算如下图所示:

该浮点数计算公式如下:
-1*2^(129-127)*(1*2^0+0*2^(-1)+1*2^(-2)+0*2^(-3)...) = -1*4*1.25 = -5通过 Java 代码也可以查看浮点数的表示:
float t = -5f;
System.out.println(Integer.toBinaryString(Float.floatToRawIntBits(t)));
//结果
11000000101000000000000000000000好了,回归正题,我们继续学习 Java 虚拟机。
Java 默认的浮点型为 double,例如,11.11 和 1.2345 都是 double 型数值。如果要说明一个 float 类型数值,就需要在其后追加字母 f 或 F,如 11.11f 和 1.2345F 都是 float 类型的常数。
如下示例:
public static void addTest() {
float f = 12.5f;
int i = 3;
float res = f / i;
double ss = f / i;
double dd = 12.5;
float sd = (float) (dd /i);
}截取部分字节码文件如下:
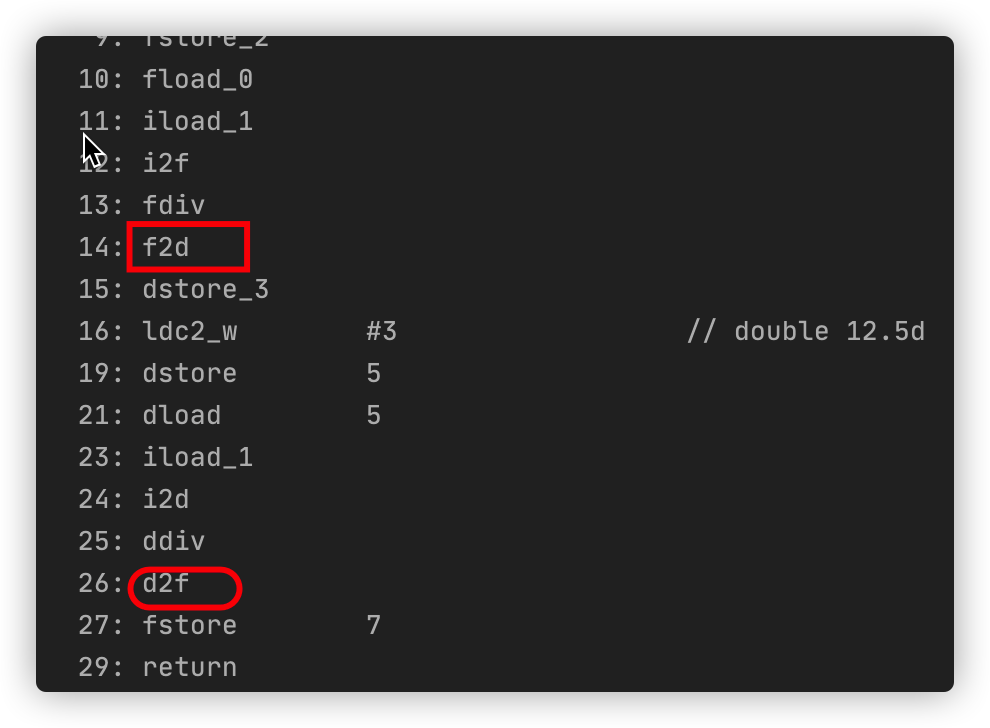
其中 f2d 指令是将 float 型数值强制转换为 double 型并推入栈顶,d2f 将 double 数值强制转换为 float 型并推入栈顶。
字符型
Java 语言中的字符类型(char)使用两个字节的 Unicode 编码表示,它支持世界上所有语言,可以使用单引号字符或者整数对 char 型赋值。
一般计算机语言使用 ASCII 编码,用一个字节表示一个字符。ASCII 码是 Unicode 码的一个子集,用 Unicode 表示 ASCII 码时,其高字节为 0,它是其前 255 个字符。
字符型变量的类型为 char,用来表示单个的字符,例如:
char c1 = 'D';
char c2 = 5;
char c3 = (char) (c1 + c2);对应字节码内容为:
0: bipush 68
2: istore_0
3: iconst_5
4: istore_1
5: iload_0
6: iload_1
7: iadd
8: i2c
9: istore_2可以看出,字母 D在 ASCII(和 Unicode)中对应的值为 68,最后两个 int 数值相加后又强制转换为 char 型。
布尔类型
布尔类型(boolean)用于对两个数值通过逻辑运算,判断结果是“真”还是“假”。true 和 false不是关键字,而是布尔文字。Java 中用 true 和 false 来代表逻辑运算中的“真”和“假”。因此,一个 boolean 类型的变量或表达式只能是取 true 和 false 这两个值中的一个。
接下来玩点有意思的,看看 boolean 的神奇操作。
public class AwkCommandLearn {
public static void main(String[] args) {
boolean flag = true;
if (flag) {
System.out.println("Hello Java");
}
if(flag == true){
System.out.println("Hello JVM");
}
}
}
// 执行结果:
Hello Java
Hello JVM大家可能对 flag == true 语句有些疑惑,好奇 Java 虚拟机是怎么比较的,我们来看一下字节码文件:
% javap -c AwkCommand
Compiled from "AwkCommand.jasm"
public class AwkCommand {
public AwkCommand();
Code:
0: aload_0
1: invokespecial #4 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: iconst_1
1: istore_1
2: iload_1
3: ifeq 14
6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
9: ldc #2 // String Hello Java
11: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: iload_1
15: iconst_1
16: if_icmpne 27
19: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
22: ldc #1 // String Hello JVM
24: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
27: return
}可以看到 flag == true 语句包含三条指令,首先获取 flag 的值并推上栈顶,然后又将一个新的 int 型 1推上栈顶,最后两个 int 型数值做比较,如果结果等于0则比较成功。
我们可以通过第三方工具包来修改字节码文件,查看新的执行结果。
首先下载 asmtools.jar [2] ,然后按照下述命令执行:
% javac AwkCommand.java
% java AwkCommand
Hello Java
Hello JVM
% java -cp /Users/ankanghao/Downloads/asmtools-7.0/lib/asmtools.jar org.openjdk.asmtools.jdis.Main AwkCommand.class > AwkCommand.jasm.1
% awk 'NR==1,/iconst_1/{sub(/iconst_1/, "iconst_2")} 1' AwkCommand.jasm.1 > AwkCommand.jasm
% java -cp /Users/ankanghao/Downloads/asmtools-7.0/lib/asmtools.jar org.openjdk.asmtools.jasm.Main AwkCommand.jasm
% java AwkCommand
Hello Java按照要求执行其他命令后(注意,操作上述步骤时删掉包名),结果将出现变化。我们知道 true 对应数值1,false 对应0。所以要想改变 flag 对应的数值,只能通过 awk 命令来修改局部变量。
我们来看一下修改后的字节码文件:
0: iconst_2
1: istore_1
2: iload_1
3: ifeq 14
6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
9: ldc #2 // String Hello Java
11: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: iload_1
15: iconst_1
16: if_icmpne 27
19: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
22: ldc #1 // String Hello JVM
24: invokevirtual #5 // Method java/io/PrintStream.println:(Ljava/lang/String;)Vawk 那条命令的含义:将第一行的 iconst_1 替换为 iconst_2。
- if(flag)比较时 ifeq 指令做是否为零判断,常数2仍为true,打印输出
- if(true == flag)比较时 if_cmpne 做整数比较,iconst_1 是否等于flag,比较失败,不再打印输出
那么现在有个疑问,为什么 iconst_2 仍为 true,如果再将 flag 的值改为 3,结果又会如何呢?
我们先测试一下将 iconst_2 替换为 iconst_3 的情况,然后执行上述命令,最终得到的输出结果也是 Hello Java。那么看起来当布尔型变量数值大于0时,输出结果都是 Hello Java。
那么这样就完事了吗?想要了解的更深入,就要从 JVM 的层面进行分析,聊聊这些基本数据类型是如何被加载的。
数据的加载
Java 虚拟机的算数运算几乎全部依赖于操作数栈。也就是说,如果数据在堆上存储,我们需要将堆中的 boolean、byte、char 以及 short 加载到操作数栈上,而后将栈上的值当成 int 类型来运算。
boolean 字段和 boolean 数组则比较特殊。在 HotSpot 中,boolean 字段占用一字节,而 boolean 数组则直接用 byte 数组来实现。为了保证堆中的 boolean 值是合法的,HotSpot 在存储时显式地进行掩码操作,也就是说,只取最后一位的值存入 boolean 字段或数组中。
对于 byte、short 这两个类型来说,加载伴随着符号扩展。举个例子,short 的大小为两个字节。在加载时 short 的值同样会被复制到 int 类型的低二字节。如果该 short 值为非负数,即最高位为 0,那么该 int 类型的值的高二字节会用 0 来填充,否则用 1 来填充。这点我们在上述代码示例中通过字节码有所体现。
回到上述 boolean 类型的测试案例,boolean 字段是在栈上存储的,没法做掩码处理,那么我们修改一下代码,在堆上存储 boolean 型字段,然后使用 Unsafe 类进行测试:
public class Foo {
boolean flag = false;
public boolean getFlag() {
return this.flag;
}
public static void main(String[] args) throws InvocationTargetException,
NoSuchMethodException,
InstantiationException,
IllegalAccessException,
NoSuchFieldException {
Foo foo = new Foo();
Field field = Foo.class.getDeclaredField("flag");
Unsafe unsafe = foo.getUnsafeByConstructor();
long addr = unsafe.objectFieldOffset(field);
for (byte b = 2; b < 4; b++) {
System.out.println("Unsafe.putByte: " + b);
unsafe.putByte(foo, addr, b);
System.out.println("Unsafe.getByte: " + unsafe.getByte(foo, addr)); // 总是会打印出put的值
System.out.println(
"Unsafe.getBoolean: " + unsafe.getBoolean(foo, addr)); // 打印出的值,像是ifeq, flag != 0即true
// ifeq,flag != 0即true
if (foo.flag) {
System.out.println("foo.flag,");
}
// if_cmpne 做整数比较,1 == flag,则为true
if (true == foo.flag) {
System.out.println("true == foo.flag,");
}
// ifeq,(flag) & 1 !=0 即true
if (foo.getFlag()) {
System.out.println("foo.getFlag(),");
}
// if_cmpne 做整数比较,,getFlag方法会对 boolean内容进行掩码操作,1 == (flag) & 1,则为true
if (true == foo.getFlag()) {
System.out.println("true == foo.getFlag(),");
}
System.out.println("-----------------------------------------------------------");
}
}
private static Unsafe getUnsafeByConstructor()
throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
Constructor<Unsafe> unsafeConstructor = Unsafe.class.getDeclaredConstructor();
unsafeConstructor.setAccessible(true);
Unsafe unsafe = unsafeConstructor.newInstance();
return unsafe;
}
}执行结果如下:
Unsafe.putByte: 2
Unsafe.getByte: 2
Unsafe.getBoolean: true
foo.flag,
-----------------------------------------------------------
Unsafe.putByte: 3
Unsafe.getByte: 3
Unsafe.getBoolean: true
foo.flag,
foo.getFlag(),
true == foo.getFlag(),从结果中可知调用 getFlag 方法可以进行掩码操作,所以赋值 (byte)3 给 flag 最后数值等于1。
网上查阅资料得知如下结论:Unsafe.putBoolean 会做掩码,另外方法返回也会对 boolean byte char short 进行掩码。但是因为对这方面研究不够,暂时无法深入解答。
引用数据类型
引用数据类型建立在基本数据类型的基础上,包括数组、类和接口。引用数据类型是由用户自定义,用来限制其他数据的类型。另外,Java 语言中不支持 C++ 中的指针类型、结构类型、联合类型和枚举类型。
引用数据类型就是对一个对象的引用,对象包括实例和数组两种。实际上,引用类型变量就是一个指针,只是 Java 语言里不再使用指针这个说法。
引用类型还有一种特殊的 null 类型,空类型(null type)就是 null 值的类型,这种类型没有名称。因为 null 类型没有名称,所以不可能声明一个 null 类型的变量或者强制转换到 null 类型。
空引用(null)是 null 类型变量唯一的值。空引用(null)可以转换为任何引用类型。
在实践中,程序员可以忽略 null 类型,只是假装它null只是一个可以是任何引用类型的特殊文字。
数据存储
Java 虚拟机每调用一个 Java 方法,便会创建一个栈帧。如下图所示:
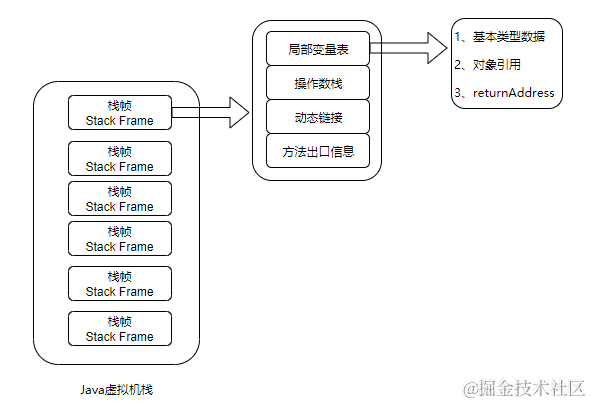
这种栈帧有两个主要的组成部分,分别是局部变量表,以及字节码的操作数栈。这里的局部变量是广义的,除了普遍意义下的局部变量之外,它还包含实例方法的“this 指针”以及方法所接收的参数。
在 Java 虚拟机规范中,局部变量表等价于一个数组,并且可以用正整数来索引。除了 long、double 值需要用两个数组单元来存储之外,其他基本类型以及引用类型的值均占用一个数组单元。
关于这个数组单元,这个很多 JVM 的实现都是指针大小(8 bytes for 64-bits, 4 bytes for 32-bits)。所以这个地方,引用也只用占一个数组单元(64-bits平台引用要8 bytes,32-bits要4bits)。 其他的不大于4bits(即除了long和double)的数据类型,用一个数组单元就能搞定,long和double在64-bits机器上一个数组单元也能搞定,但是 Java 在编译的时候并不知道是会运行在一个64-bits机器上还是32-bits,基于java设计原则(write once, run everywhere),所以就分配两个数组单元了。
首先查看 mac 是多少位的操作系统,由此可知本机是 64 位的。
% uname -a
Darwin xxx-MacBook-Pro.local 20.5.0 Darwin Kernel Version 20.5.0: Sat May 8 05:10:33 PDT 2021; root:xnu-7195.121.3~9/RELEASE_X86_64 x86_64然后编译并解析下述代码:
public class BasicDataType {
public static void add(){
int i = 10;
boolean flag = true;
short tt = 10;
long sum = 100L;
double avg = 25.5;
int ii = 12;
}
}执行下述两个命令:
% javac -g:vars BasicDataType.java
% javap -v BasicDataType我们截取部分解析结果,内容如下:
Code:
stack=2, locals=8, args_size=0
......
LocalVariableTable:
Start Length Slot Name Signature
3 15 0 i I
5 13 1 flag Z
8 10 2 tt S
12 6 3 sum J
17 1 5 avg D
21 1 7 ii I由 LocalVariableTable 中的内容可知,int、boolean、short 类型的数据在栈上占用 1 个 slot,long、double 类型占 2 个 slot。所以 locals =8 指的是总共占用了 8个 slot。
有没有发现上文中提到的数组单元其实就是 slot,接下来我们学习了解一下 slot。
Slot变量槽
关于 Slot 的描述,分为以下几点:
- Slot 是局部变量表中最基本的存储单元。
- 参数值的存放总是从局部变量表数组的 index 0开始,到数组的-1的索引结束。
- 局部变量表中存放的是局部变量,包括8种基本数据类型,引用数据类型,returnAddress 类型的变量。
- 32位以内的数据占用一个Slot(包括returnAddress类型,引用数据类型),64位类型的(long, double)占用两个Slot。
- JVM会为局部变量表中的每一个 Slot 分配一个访问索引,通过这个索引来访问局部变量。
- 当一个实例方法(非静态方法)被调用的时候,它的方法参数和方法体内部定义的局部变量将会按照顺序被复制到局部变量的每一个 Slot 上。
- 如果需要访问局部变量表中的一个64位的局部变量值时,只需要使用前一个索引即可。(例如:访问long或double 类型的变量)
- 如果当前栈帧是由构造方法或者实例方法创建的,那么该对象引用 this 将会存放在 index 为0的 slot 处,其余的参数按照参数表的顺序继续进行存储。
下述图片是上述代码的索引分配情况:
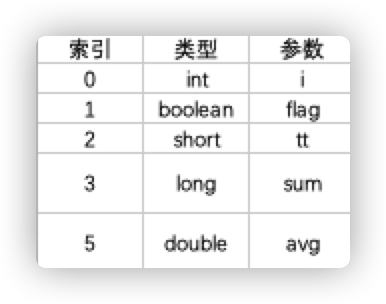
关于 slot 的详细讲解推荐阅读本文
综上,boolean、byte、char、short 这四种类型,在栈上占用的空间和 int 是一样的,和引用类型也是一样的。因此,在 32 位的 HotSpot 中,这些类型在栈上将占用 4 个字节;而在 64 位的 HotSpot 中,他们将占 8 个字节。
当然,上述情况仅存在于局部变量,而并不会出现在存储于堆中的字段或者数组元素上。对于 byte、char 以及 short 这三种类型的字段或者数组单元,它们在堆上占用的空间分别为一字节、两字节,以及两字节。




