
JVM是如何创建对象的?了解 JDK8 下 Java 对象的内存分配和创建过程原创
正文
快要讲解 Java 垃圾回收机制了,在此之前我们有必要了解一下 Java 对象的内存分配和创建过程。
JDK8内存区域
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。如下图所示:
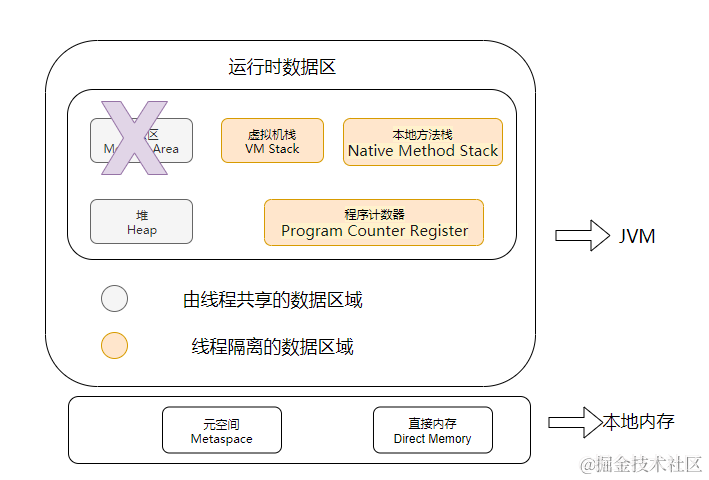
Java 对象分配内存主要与堆有关,所以此处只介绍一下堆内存。
堆是 JVM 内存管理的最大的一块区域,此内存区域的唯一目的就是存放对象的实例,所有对象实例与数组都要在堆上分配内存。它也是垃圾收集器的主要管理区域。java 堆可以处于物理上不连续的空间,只要逻辑上是连续的即可。线程共享的区域。如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将抛出 OutOfMemoryError 异常。
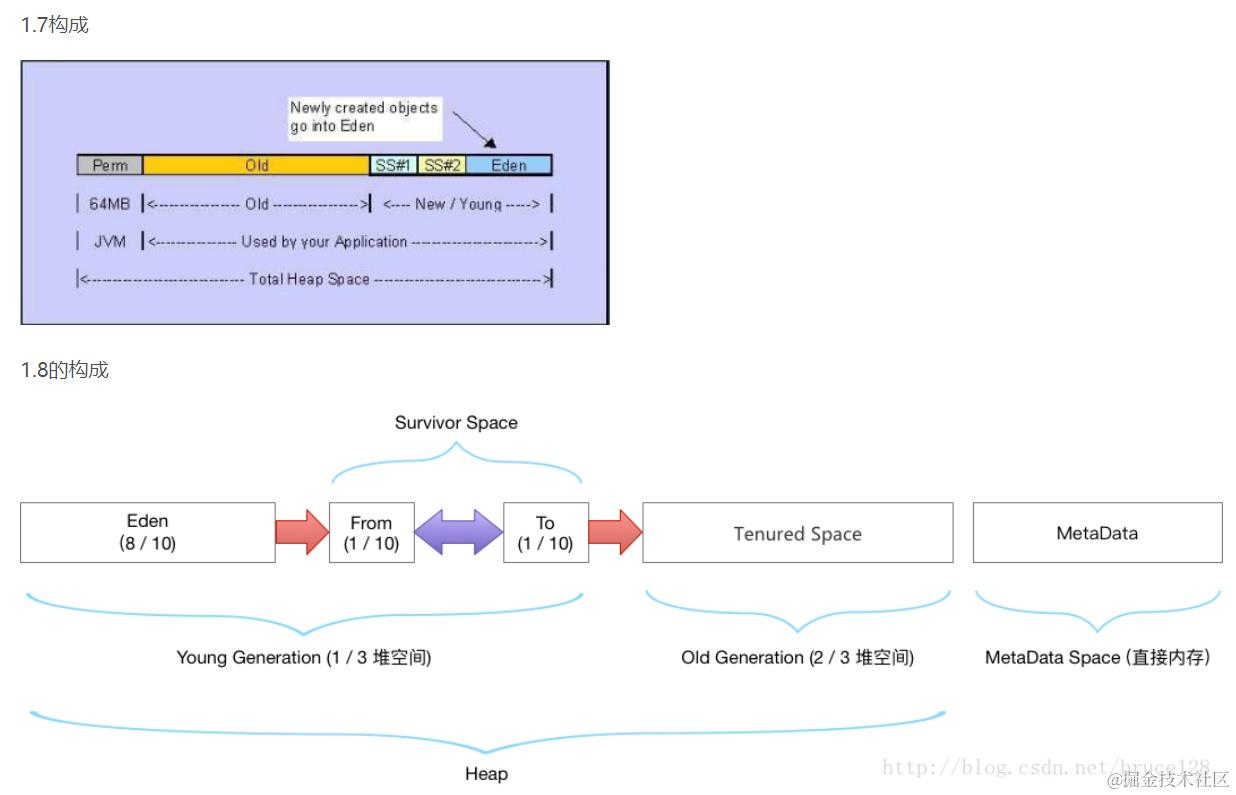
为了支持垃圾收集,堆被分为三个部分:
- 年轻代 : 常常又被划分为Eden区和Survivor(From Survivor To Survivor)区(Eden空间、From Survivor空间、To Survivor空间(空间分配比例是8:1:1)
- 老年代
- 永久代 (jdk 8已移除永久代)
(1)、堆是 JVM 中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了 new 对象的开销是比较大的。
(2)、Sun Hotspot JVM 为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间 TLAB(Thread Local Allocation Buffer),其大小由 JVM 根据运行的情况计算而得,在 TLAB 上分配对象时不需要加锁,因此 JVM 在给线程的对象分配内存时会尽量的在 TLAB 上分配,在这种情况下 JVM 中分配对象内存的性能和 C 基本是一样高效的,但如果对象过大的话则仍然是直接使用堆空间分配。
(3)、TLAB 仅作用于新生代的 Eden Space,因此在编写 Java 程序时,通常多个小的对象比大的对象分配起来更加高效。
(4)、所有新创建的 Object 都将会存储在新生代 Yong Generation 中。如果 Young Generation 的数据在一次或多次 GC 后存活下来,那么将被转移到 OldGeneration。新的 Object 总是创建在 Eden Space。
值得注意的是,我们说 TLAB 是线程独享的,但是只是在“分配”这个动作上是线程独占的,至于在读取、垃圾回收等动作上都是线程共享的。而且在使用上也没有什么区别。
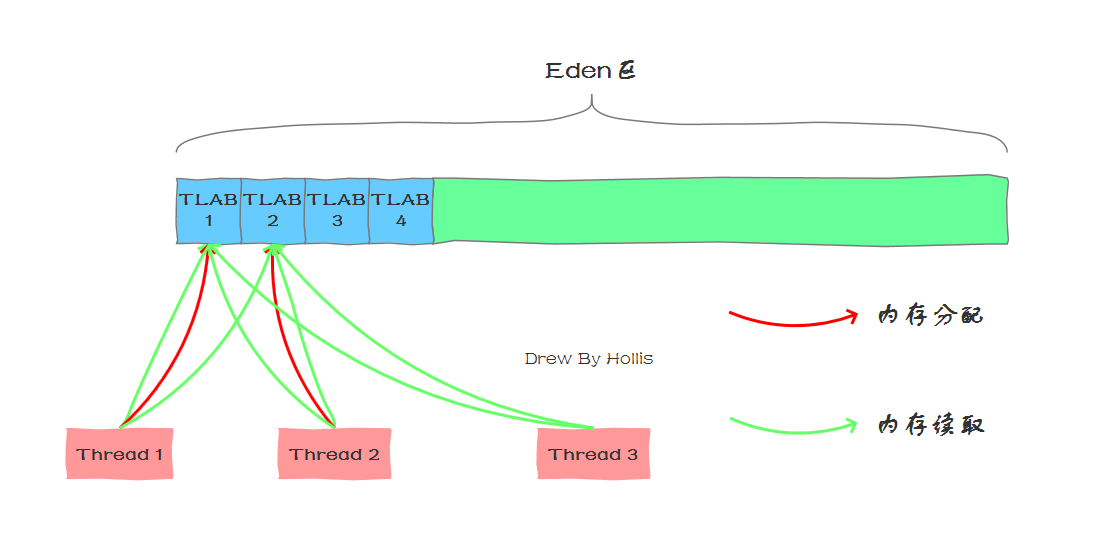
换言之,虽然每个线程在初始化时都会去堆内存中申请一块 TLAB,并不是说这个 TLAB 区域的内存其他线程就完全无法访问了,其他线程的读取还是可以的,只不过无法在这个区域中分配内存而已。
Java对象创建方式
在 Java 程序中,我们拥有多种新建对象的方式。
最简单的方式就是使用new关键字。
User user = new User();
除此以外,还可以使用反射机制创建对象:
User user = User.class.newInstance();
或者使用 Constructor 类的 newInstance:
Constructor<User> constructor = User.class.getConstructor();
User user = constructor.newInstance();
除此之外还可以使用 clone 方法、反序列化以及 Unsafe 类的方式,Object.clone 方法和反序列化通过直接复制已有的数据,来初始化新建对象的实例字段。Unsafe.allocateInstance 方法则没有初始化实例字段,而 new 语句和反射机制,则是通过调用构造器来初始化实例字段。想深入这三种方式的朋友,推荐阅读 java创建对象的五种方式
new关键字
以 new 语句为例,它编译而成的字节码将包含用来请求内存的 new 指令,以及用来调用构造器的 invokespecial 指令。
public class SubUser {
public static void main(String[] args) {
SubUser subUser = new SubUser();
}
}
// 解析字节码文件
public com.msdn.java.hotspot.object.SubUser();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 8: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=1
0: new #2 // class com/msdn/java/hotspot/object/SubUser
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: return
提到构造器,就不得不提到 Java 对构造器的诸多约束。首先,如果一个类没有定义任何构造器的话, Java 编译器会自动添加一个无参数的构造器。
Object 类是一切 Java 类的父类,对于普通的 Java 类,即便不声明,也是默认继承了Object 类。正如上面案例所示,SubUser 没有显式声明构造方法,Java 编译器会自动添加对父类构造器的调用。但是,如果父类没有无参数构造器,那么子类的构造器则需要显式地调用父类带参数的构造器。
显式调用又可分为两种,一是直接使用“super”关键字调用父类构造器,二是使用“this”关键字调用同一个类中的其他构造器,具体可查看下述示例代码。无论是直接的显式调用,还是间接的显式调用,都需要作为构造器的第一条语句,以便优先初始化继承而来的父类字段。(不过这可以通过字节码注入来绕开,我们之前讲重载时有介绍到)
public class Cutomer {
private String name;
private int age;
public Cutomer(String name, int age) {
this.name = name;
this.age = age;
}
}
public class SubUser extends Cutomer {
private long id;
public SubUser(String name, int age) {
super(name, age);
}
public SubUser(String name, int age, long id) {
// super(name, age);
this(name, age);
this.id = id;
}
}
总而言之,当我们调用一个构造器时,它将优先调用父类的构造器,直至 Object 类。这些构造器的调用者皆为同一对象,也就是通过 new 指令新建而来的对象。
我们查看一下 SubUser 类中的第一个构造器对应的字节码内容:
0: aload_0
1: aload_1
2: iload_2
3: invokespecial #1 // Method com/msdn/java/hotspot/object/Cutomer."<init>":(Ljava/lang/String;I)V
6: return
相较于没有继承 Customer 时的默认构造器,多了两条指令,分别是 aload_1 和 iload_2,对应 Customer 中的 name 和 age 字段,即子类分配内存时涵盖了所有父类中的实例字段。也就是说,虽然子类无法访问父类的私有实例字段,或者子类的实例字段隐藏了父类的同名实例字段,但是子类的实例还是会为这些父类实例字段分配内存的。
Java对象创建过程
关于对象的创建,用图解的形式展示:
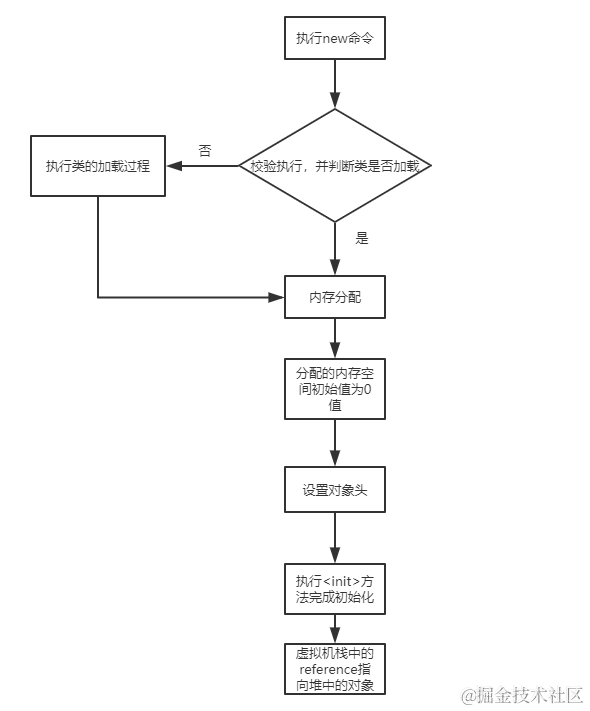
从图中我们可以发现对象创建的步骤如下:
-
类加载检查: 虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
-
内存分配: 在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。
-
初始化零值: 内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
-
设置对象头: 初始化零值完成之后,虚拟机要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希吗、对象的 GC 分代年龄等信息。 这些信息存放在对象头中。 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
-
执行 init 方法: 在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始, 方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行 方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
-
Java 虚拟机栈中的 Reference 指向我们刚刚创建的对象。
那么关于内存分配到底是怎么进行的呢?
内存分配方式
分配方式有 “指针碰撞” 和 “空闲列表” 两种,选择哪种分配方式由 Java 堆是否规整决定,而Java堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。
选择以上两种方式中的哪一种,取决于 Java 堆内存是否规整。而 Java 堆内存是否规整,取决于 GC 收集器的算法是"标记-清除",还是"标记-整理"(也称作"标记-压缩"),值得注意的是,复制算法内存也是规整的。

JDK8 默认垃圾收集器为 ParallelGC,可通过下述命令得知:
% java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=268435456 -XX:MaxHeapSize=4294967296 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
java version "1.8.0_301"
Java(TM) SE Runtime Environment (build 1.8.0_301-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)
UseParallelGC 即 Parallel Scavenge + Parallel Old。
% java -XX:+PrintGCDetails -version
java version "1.8.0_301"
Java(TM) SE Runtime Environment (build 1.8.0_301-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)
Heap
PSYoungGen total 76288K, used 2621K [0x000000076ab00000, 0x0000000770000000, 0x00000007c0000000)
eden space 65536K, 4% used [0x000000076ab00000,0x000000076ad8f748,0x000000076eb00000)
from space 10752K, 0% used [0x000000076f580000,0x000000076f580000,0x0000000770000000)
to space 10752K, 0% used [0x000000076eb00000,0x000000076eb00000,0x000000076f580000)
ParOldGen total 175104K, used 0K [0x00000006c0000000, 0x00000006cab00000, 0x000000076ab00000)
object space 175104K, 0% used [0x00000006c0000000,0x00000006c0000000,0x00000006cab00000)
Metaspace used 2247K, capacity 4480K, committed 4480K, reserved 1056768K
class space used 243K, capacity 384K, committed 384K, reserved 1048576K
Parallel 收集器类似于 ParNew 收集器,而ParNew 收集器新生代采用复制算法,老年代采用标记-整理算法。所以 Parallel 收集器的堆内存是规整的,综上可知 JDK8 默认的内存分配方式为指针碰撞。
Java 对象创建过程中还有一个比较重要的过程——设置对象头,那么这些字段在内存中的具体分布是怎么样的呢?今天我们就来看看对象的内存布局。
内存布局
在 JVM 中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。
对象头
对象头包括两部分信息:标记字段和类型指针,如果对象是一个数组,还需要一块用于记录数组长度的数据。
标记字段包括哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向锁ID和偏向时间戳等,这部分数据在32位和64位虚拟机中的长度分别为32bit和64bit,官方称为"Mark Word"。Mark Word被设计成非固定的数据结构,以实现在有限空间内保存尽可能多的数据。
如32位 JVM 下,除了上述列出的 Mark Word 默认存储结构外,还有如下可能变化的结构:
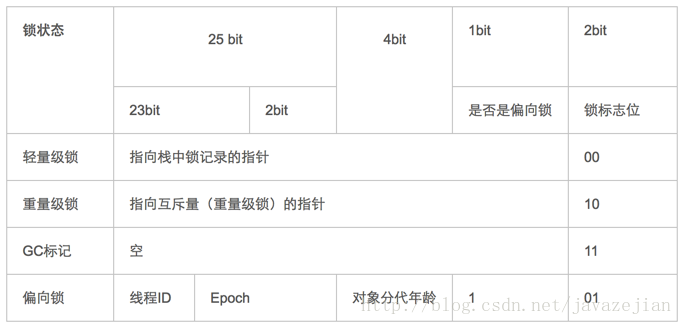
我们可以在 JVM 源码 (hotspot/share/oops/markOop.hpp) 中看到对象头中存储内容的定义
public:
// Constants
enum {
age_bits = 4,
lock_bits = 2,
biased_lock_bits = 1,
max_hash_bits = BitsPerWord - age_bits - lock_bits - biased_lock_bits,
hash_bits = max_hash_bits > 31 ? 31 : max_hash_bits,
cms_bits = LP64_ONLY(1) NOT_LP64(0),
epoch_bits = 2
};
在该文件中关于标记字段的结构有如下示例:
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
字段含义如下:
- hash: 对象的哈希码
- age: 对象的分代年龄
- biased_lock : 偏向锁标识位
- lock: 锁状态标识位
- JavaThread* : 持有偏向锁的线程 ID
- epoch: 偏向时间戳
类型指针指向该对象的类元数据,虚拟机通过这个指针可以确定该对象是哪个类的实例。该指针的位长度为JVM的一个字大小,即32位的JVM为32位,64位的JVM为64位。
在 64 位的 Java 虚拟机中,对象头的标记字段占 64 位,而类型指针又占了 64 位。也就是说,每一个 Java 对象在内存中的开销就是 16 个字节。
为了尽量较少对象的内存使用量,64 位 Java 虚拟机引入了压缩指针的概念(对应虚拟机选项 -XX:+UseCompressedOops,默认开启,32位HotSpot VM是不支持UseCompressedOops参数的),将堆中原本 64 位的 Java 对象指针压缩成 32 位的。
比如说 Integer 对象,如果不开启压缩指针,查看其内存分配情况。
//-XX:-UseCompressedOops
Integer i = Integer.valueOf(5);
System.out.println(ClassLayout.parseInstance(i).toPrintable());
//输出
java.lang.Integer object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) a0 72 7d 0d (10100000 01110010 01111101 00001101) (226325152)
12 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
16 4 int Integer.value 5
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
先解释下各个字段的含义
OFFSET是偏移量,也就是到这个字段位置所占用的byte数,SIZE是后面类型的大小,TYPE是Class中定义的类型,DESCRIPTION是类型的描述,object header 指的是对象头VALUE是TYPE在内存中的值。
分析上述结果,Integer 对象占用空间的有三部分,第一部分是对象头,占16个字节,第二部分是 int 表示的是具体的值,占 4个字节,总共 20个字节,但是JVM中对象内存的分配必须是8字节的整数倍,所以要补全4字节(即下文讲到的对齐填充),最后 Integer 类的总大小是 24字节。
开启了压缩指针,输出结果为:
//-XX:+UseCompressedOops
java.lang.Integer object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) bf 22 00 f8 (10111111 00100010 00000000 11111000) (-134208833)
12 4 int Integer.value 5
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
可以看到,对象头中的类型指针也会被压缩成 32 位,使得对象头的大小从 16 字节降至 12 字节。当然,压缩指针不仅可以作用于对象头的类型指针,还可以作用于引用类型的字段,以及引用类型数组。
在默认情况下,Java 虚拟机中的 32 位压缩指针可以寻址到 2 的 35 次方个字节,也就是 32GB 的地址空间(超过 32GB 则会关闭压缩指针)。
在对压缩指针解引用时,即引用被存入64位的寄存器时,我们需要将其左移 3 位,再加上一个固定偏移量,便可以得到能够寻址 32GB 地址空间的伪 64 位指针了。
实例数据
实例数据就是在程序代码中所定义的各种类型的字段,包括从父类继承的,这部分的存储顺序会受到虚拟机分配策略和字段在源码中定义顺序的影响。
对齐填充
在JVM中(不管是32位还是64位),对象已经按8字节边界对齐了。对于大部分处理器,这种对齐方案都是最优的。
由于 HotSpot 的自动内存管理要求对象的起始地址必须是8字节的整数倍,即对象的大小必须是8字节的整数倍,对象头的数据正好是8的整数倍,所以当实例数据不够8字节整数倍时,需要通过对齐填充进行补全。
内存对齐不仅存在于对象与对象之间,也存在于对象中的字段之间。比如说,Java 虚拟机要求 long 字段、double 字段,以及非压缩指针状态下的引用字段地址为 8 的倍数。
对象中字段也存在对齐填充,可以查看如下示例:
//-XX:-UseCompressedOops
class Stud{
private long num;
private int age;
}
Stud stud = new Stud();
System.out.println(ClassLayout.parseInstance(stud).toPrintable());
输出:
com.msdn.java.hotspot.object.Stud object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 48 dc 4d 05 (01001000 11011100 01001101 00000101) (88988744)
12 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
16 8 long Stud.num 0
24 4 int Stud.age 0
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
可以看到 int 类型的字段会进行对齐填充。
**字段内存对齐的其中一个原因,是让字段只出现在同一 CPU 的缓存行中。**如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。这两种情况对程序的执行效率而言都是不利的。比如 long和double在32位虚拟机中,并发出现高32位和低32位不在同一缓存行而导致的读写不一致的问题。
在上文 Stud 对象的内存布局,可以看到一个有意思的现象,int 类型字段在 String 类型前面,为什么会按照这种方式排列呢?这就涉及到另一个特性:字段重排列。
字段重排列
字段重排列,顾名思义,就是 Java 虚拟机重新分配字段的先后顺序,以达到内存对齐的目的。Java 虚拟机中有三种排列方法(对应 Java 虚拟机选项 -XX:FieldsAllocationStyle,默认值为 1),但都会遵循如下两个规则。
其一,如果一个字段占据 C 个字节,那么该字段的偏移量需要对齐至 NC。这里偏移量指的是字段地址与对象的起始地址差值。
以 Long 类为例,它仅有一个 long 类型的实例字段。在使用了压缩指针的 64 位虚拟机中,尽管对象头的大小为 12 个字节,该 long 类型字段的偏移量也只能是 16,而中间空着的 4 个字节便会被浪费掉。
//默认开启压缩指针
System.out.println(ClassLayout.parseClass(Long.class).toPrintable());
//输出
java.lang.Long object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 (alignment/padding gap)
16 8 long Long.value N/A
Instance size: 24 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
根据规则1,这个 long实例内存偏移量(就是起始地址)必须是8N,例如8、16、24等等;由于Long类型的对象头大小占据了12字节(好比说是011),那么根据规则1,long实例只能从地址16开始存储(1624)。
其二,子类所继承字段的偏移量,需要与父类对应字段的偏移量保持一致。
在具体实现中,Java 虚拟机还会对齐子类字段的起始位置。对于使用了压缩指针的 64 位虚拟机,子类第一个字段需要对齐至 4N;而对于关闭了压缩指针的 64 位虚拟机,子类第一个字段则需要对齐至 8N。
下面我们通过一个案例进行分析:
class A {
long l;
int i;
}
class B extends A {
long l;
int i;
}
B b= new B();
System.out.println(ClassLayout.parseInstance(b).toPrintable());
下面分别打印了 B 类在启用压缩指针和未启用压缩指针时,各个字段的偏移量。
//-XX:+UseCompressedOops
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 81 c1 00 f8 (10000001 11000001 00000000 11111000) (-134168191)
12 4 int A.i 0
16 8 long A.l 0
24 8 long B.l 0
32 4 int B.i 0
36 4 (loss due to the next object alignment)
Instance size: 40 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
根据规则1,long 字段内存偏移量(就是起始地址)必须是8N,例如8、16、24等等,所以 A类的int 字段放置于 long 字段之前,同理,B 类的 long 字段放置于 int 字段之前。最后由于对象整体大小需要对齐至 8N,因此对象的最后会有 4 字节的空白填充。
//-XX:-UseCompressedOops
com.msdn.java.hotspot.object.B object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 18 12 f6 16 (00011000 00010010 11110110 00010110) (385225240)
12 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
16 8 long A.l 0
24 4 int A.i 0
28 4 (alignment/padding gap)
32 8 long B.l 0
40 4 int B.i 0
44 4 (loss due to the next object alignment)
Instance size: 48 bytes
Space losses: 4 bytes internal + 4 bytes external = 8 bytes total
根据规则2,A类的 long 字段放置于 int 字段之前,B类也是如此,紧跟着 long 字段是 int 字段,所以 int 字段后都有一段空白。
扩展
字节序
字节序是指占用内存多于一个字节类型的数据在内存中的存放顺序,有小端和大端两种顺序。
字节序分为两种:大段(Big-Endian)和小段(Little-Endian)
- 大段:高字节数据存放在低地址处,低字节数据存放在高地址处。
- 小段:高字节数据存放在高地址处,低字节数据存放在低地址处。
比如说有一个十六进制数 0x12345678 共占4个字节,分别是0x12、0x34、0x56、0x78,因此在该数字中0x12属于高位数据,0x78属于低位数据。
可以把内存看作是一个很大的数组,数组的索引就是内存地址,对应索引存储的元素即为真实值。
第一种顺序:低地址存放高位数据,叫大端模式

第二种顺序:低地址存放低位数据,叫小端模式

可以看出,大端模式比较符合人类的阅读习惯;小端模式更符合计算机的处理方式,因为计算机从低位开始处理。
Java 如何查看字节序属于哪种?
JOL的全称是Java Object Layout。是一个用来分析JVM中Object布局的小工具。包括Object在内存中的占用情况,实例对象的引用情况等等。
1、首先引入依赖
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.14</version>
</dependency>
2、通过JOL查看jvm信息
public class ObjectHeadTest {
public static void main(String[] args) {
//查看字节序
System.out.println(ByteOrder.nativeOrder());
//打印当前jvm信息
System.out.println("======================================");
System.out.println(VM.current().details());
}
}
输出:
LITTLE_ENDIAN
======================================
# WARNING: Unable to attach Serviceability Agent. You can try again with escalated privileges. Two options: a) use -Djol.tryWithSudo=true to try with sudo; b) echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# WARNING | Compressed references base/shifts are guessed by the experiment!
# WARNING | Therefore, computed addresses are just guesses, and ARE NOT RELIABLE.
# WARNING | Make sure to attach Serviceability Agent to get the reliable addresses.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
可以发现,Java 在内存中字节序使用的是小端模式。
💥看到这里的你,如果对于我写的内容很感兴趣,有任何疑问,欢迎在下面留言📥,会第一次时间给大家解答,谢谢!


