
CPU 优化线上实战篇:Java 生产环境 CPU 跑满 & 大量长耗时的问题排查 & 解决原创
目录
第一篇:CPU性能优化基础篇:一定要了解Linux CPU哪些基本概念
第二篇:CPU 优化高级篇:Linux系统中CPU占用率较高问题排查思路与解决方法
第三篇:CPU 优化高级篇:Java CPU 高的原因和排查方法 :如何定位Java 消耗CPU最多的线程
第四篇:CPU 优化高级篇:Java CPU 高的原因和排查方法 :学会Java死锁和CPU 100% 问题的排查技巧
第五篇:CPU 优化线上实战篇:Java 生产环境 CPU 跑满 & 大量长耗时的问题排查 & 解决
第六篇:CPU 优化线上实战篇:Java JVM 频繁 GC的原因和排查方法
本文正在参加「Java应用线上问题排查经验/工具分享」活动
背景
公司某渠道系统,专门对接三方渠道使用,没有什么业务逻辑,主要是转换报文和参数校验之类的工作,起着一个承上启下的作用。
就在今天早上,突然监控告警了……该系统的所有机器,CPU 利用率达到90%+,并且出现大面积的长耗时请求
排查经过
这种突然长耗时的情况,对于问题排查来说还是挺常见的,所以我还是按照惯例,先分析事件背景:
- 出现问题时,有没有激增的流量?
- 该系统最近有没有什么大的改动?
- 云服务器厂商,有没有什么动作?
和相关负责人沟通后,得知2/3两处并没有问题,但确实有激增流量的情况。
有一个和渠道系统交互的周边系统,最近在早上有批量调用渠道系统的问题,不过并发请求并不多,不太可能把这个系统所在机器 CPU 打满……
但事已至此,光怀疑没有用,得拿出实际的证据来。
虽然 CPU 利用率高 和 慢响应是两个问题,但这俩问题一般是关联的,很可能是 CPU 利用率过高导致的慢响应,所以还是先从 CPU 利用率这个问题出发,看能不能找到一些蛛丝马迹。
于是我们又给该系统新建了一套新的临时测试环境,用于复现问题。场景上尽可能的还原早上的激增流量,不过这里为了排查简单,我们这里做了等比缩小。
比如100并发、10台机器的生产环境,我们用了10+并发,1台机器去模拟,这样监控之类的工作就简单很多了,复现问题也会更简单。
经过测试后发现,等比缩小后的配置仍然会导致 CPU 飙高,直接快 90% 了。
既然能这么稳定的复现问题,那可就好办了。top 命令或者其他监控工具,看一下该进程的哪个线程 CPU 利用率高,然后在查一下该线程的 StactTrace,看看这个线程在搞什么花样(工具啥的这里就不介绍了,命令行的,图形界面的一堆)……
经过分析线程的 stacktrace 发现,占用高的线程基本都在执行 Castor 的相关代码。
Castor 是一个 XML 映射&转换的库,功能非常丰富,可以用配置的方式将 XML 格式转换为异构的 POJO。
渠道系统嘛,拿这玩意转换报文,很正常。
但为什么这个东西 CPU 会占用这么高?这点并发量完全不至于,况且在调用 castor 转换完报文后,后面还有调用核心系统接口的动作,并不是一直在转换报文,这点并发量不可能把 CPU 跑这么高。
一个成熟的开源项目,性能怎么可能这么差呢?要是性能差成这样,那肯定也没人用了。
于是,我开始怀疑……是不是用法不对?
先看看渠道系统代码里的用法:
- public static Object readXML2Bean(Mapping mapping, String xmlString, Class<?> beanClass) throws Exception {
- StringReader reader = new StringReader(xmlString);
- Unmarshaller unmar = new Unmarshaller(beanClass);
- unmar.setMapping(mapping);
- Object ob = unmar.unmarshal(reader);
- reader.close();
- return ob;
- }
一眼看过去,感觉不太对……对于一个序列化的库,每次 New Unmarshaller
可不太正常。
因为报文转 POJO 这个东西,往往会涉及反射,而涉及反射的库往往会将反射的相关类进行缓存,不然性能会很低。
但每次 New 的话,缓存一般就无效了(不绝对,如果用静态变量也不是不行),所以我认为这个用法有点奇怪,可能有问题。
但我并没有证据,因为我也没用过这玩意啊……
没用过,不过可以学。虽然资料较少,但看看官方文档还是可以的。
于是我又翻了翻官方文档,看看官方的教程,有没有啥推荐用法之类的……

找了好一会,终于发现一个可能有用的东西 - Best practise:
来看看文档里的 practise 到底有多 best:
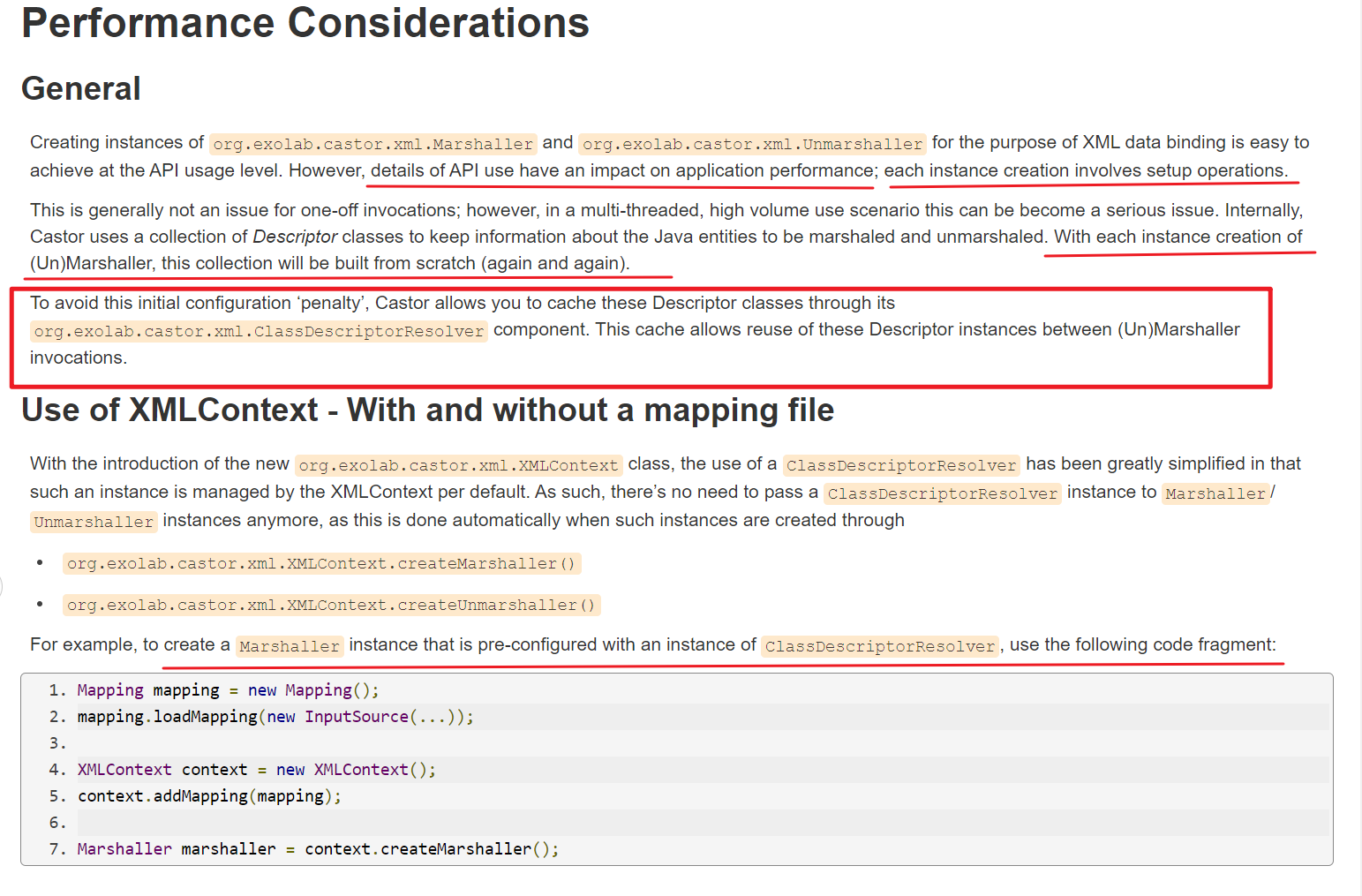
文档上说,Marshaller/UnMarshaller 每次都创建新实例会影响性能,因为 Castor 内部用 Descriptor classes 来保存 Java 类的信息,如果每次 New 的话会导致每次 New 这些信息都要重新生成。
但是这些信息是不变的,每次重新生成效率当然低……至于低多少,那我可就不知道了,得动手测试才行……
Castor 还提供了一个 XMLContext ,可以通过这个类来创建 Marshaller/UnMarshaller 对象,这样的话 Descriptor classes 就可以用已经创建的缓存,无需重复创建(注意XMLContext 这个类要单例):
- Mapping mapping = new Mapping();
- mapping.loadMapping(new InputSource(...));
- XMLContext context = new XMLContext();
- context.addMapping(mapping);
- Marshaller marshaller = context.createMarshaller();
官方资料就是好,看看人家写的多么 best!
于是我给渠道系统调用 Castor 的代码稍加调整,改成了通过 XMLContent 创建 Marshaller/UnMarshaller ,然后重启,重新测试……
相同的并发数下,CPU 的利用率从 90% 左右降到了 10% 还不到……
CPU 利用率下来了,现在再来看看长耗时的问题呢?
经过测试发现,CPU 利用率低下来之后,长耗时的问题也没了。问题就这么“轻松”的解决了
总结
这个问题其实很简单,是由于开发人员对三方库的使用方法不够了解导致,如果在使用前可以多花一些时间看看文档,就完全可以避免这种问题。
有时候快速上手,并不是一件好事。只要多花一点点准备时间,可能会避免以后的很多问题。



