
CPU 优化线上实战篇:Java JVM 频繁 GC的原因和排查方法原创
目录
第一篇:CPU性能优化基础篇:一定要了解Linux CPU哪些基本概念
第二篇:CPU 优化高级篇:Linux系统中CPU占用率较高问题排查思路与解决方法
第三篇:CPU 优化高级篇:Java CPU 高的原因和排查方法 :如何定位Java 消耗CPU最多的线程
第四篇:CPU 优化高级篇:Java CPU 高的原因和排查方法 :学会Java死锁和CPU 100% 问题的排查技巧
第五篇:CPU 优化线上实战篇:Java 生产环境 CPU 跑满 & 大量长耗时的问题排查 & 解决
第六篇:CPU 优化线上实战篇:Java JVM 频繁 GC的原因和排查方法
背景
线上web服务器不时的出现非常卡的情况,登录服务器top命令发现服务器CPU非常的高,重启tomcat之后CPU恢复正常,半天或者一天之后又会偶现同样的问题。解决问题首先要找到问题的爆发点,对于偶现的问题是非常难于定位的。
重启服务器之后只能等待问题再次出现,这时候首先怀疑是否某个定时任务引发大量计算或者某个请求引发了死循环,所以先把代码里面所有怀疑的地方分析了一遍,加了一点日志,结果第二天下午问题再次出现,
这次的策略是首先保护案发现场,因为线上是两个点,把一个点重启恢复之后把另一个点只下线不重启保留犯罪现场。
排查
在问题的服务器上首先看业务日志,没有发现大量重复日志,初步排除死循环的可能,接下来只能分析jvm了。
第一步:top命令查看占用CPU的pid
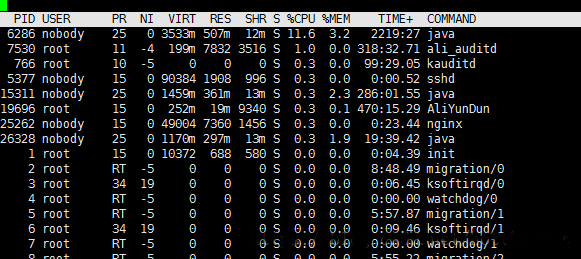
这是事后的截图,当时的cpu飙高到500多,pid是27683
然后ps aux | grep 27683 搜索一下确认一下是不是我们的tomcat占用的cpu,这个基本是可以肯定的,因为tomcat重启之后CPU立马就降下来了。
也可以使用jps显示java的pid
第二步:top -H -p 27683 查找27683下面的线程id,显示线程的cpu的占用时间,占用比例,发现有很多个线程都会CPU占用很高,只能每个排查。
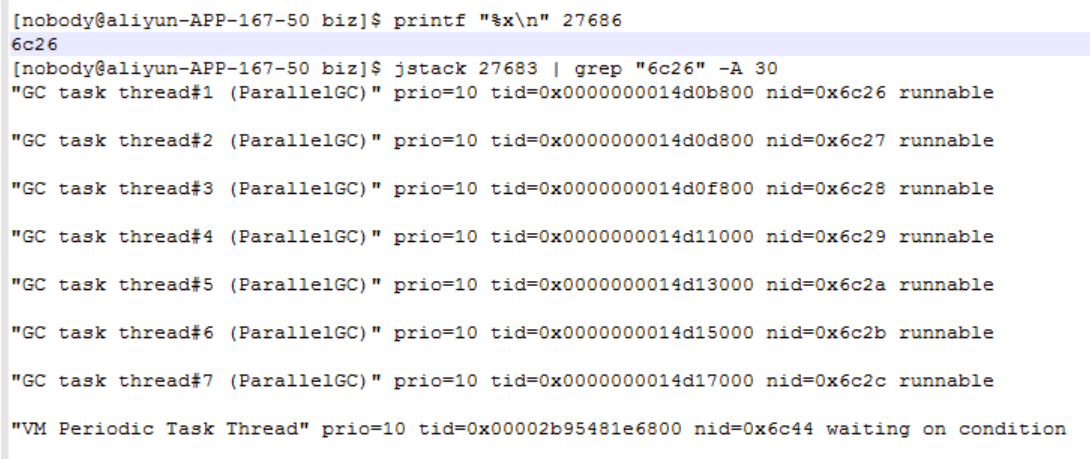
第三步:jstack查看线程信息,命令:jstack 27683 >> aaaa.txt 输出到文本中再搜索,也可以直接管道搜索 jstack 27683 | grep "6c23" 这个线程id是16进制表示,需要转一下,可以用这个命令转 printf "%x\n" tid 也可以自己计算器转一下。
悲剧的是我在排查的时候被引入了一个误区,当时搜索到6c26这个线程的时候,发现是在做gc,疯狂gc导致的线程过高,但是找不到哪里造成的产生这么多对象,一直在找所有可能的死循环和可能的内存泄露。
然后通过命名 jstat -gcutil 【PID】 1000 100 查看每秒钟gc的情况。
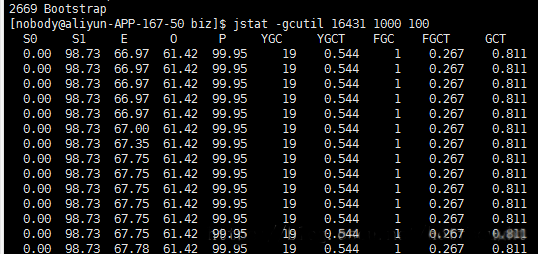
这个是事后复盘的截图,当时的截图已经没有了
发现S0不停的再新建对象,然后gc,不停的反复如此gc,去看堆栈信息,没有什么发现,无非都是String和map对象最多,确定不了死循环的代码,也找不到问题的爆发点,至此陷入彻底的困惑。一番查找之后确认也不是内存泄露,苦苦寻找无果,我陷入了沉思。
CPU还是一直保持在超高,无奈之下,还是jstack 27683 看线程栈,无目的的乱看,但是发现了一个问题,当前的点我是下线的也就是没有用户访问的,CPU还是一直这么高,而且线程栈也在不停的打印,那么也就是说当前还在运行的线程很可能就是元凶,马上分析线程栈信息,有了重大发现。
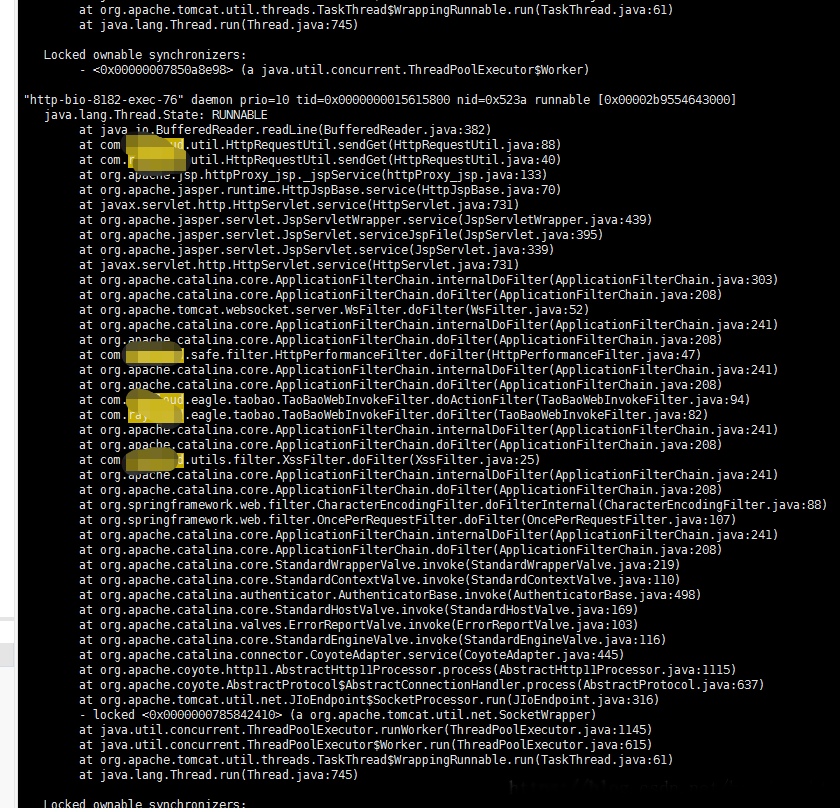
大量的这个线程信息出现,httpProxy_jsp这个jsp的线程在不停的活跃,这个是什么鬼jsp?难道服务器被攻击了?马上去代码里找,发现确实有这个jsp,查看git的提交记录,是几天之前另一个同事提交的代码,时间点和问题第一次出现的时间非常吻合,感觉自己运气好应该是找到问题的点了,把同事叫过来分析他的代码,这个jsp其实非常简单,就是做一个代理请求,发起了一个后端http请求。
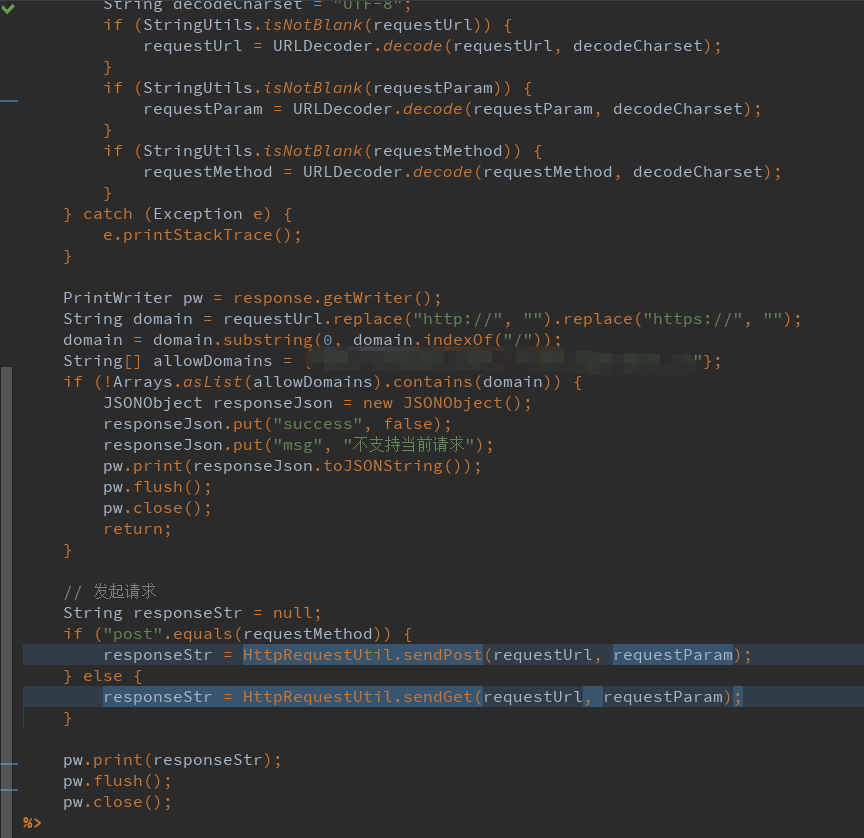
HttpRequestUtil如下,是同事自己写的工具类,没有用公用工具,其中一个post方法里connection没有设置链接超时时间和read超时时间:
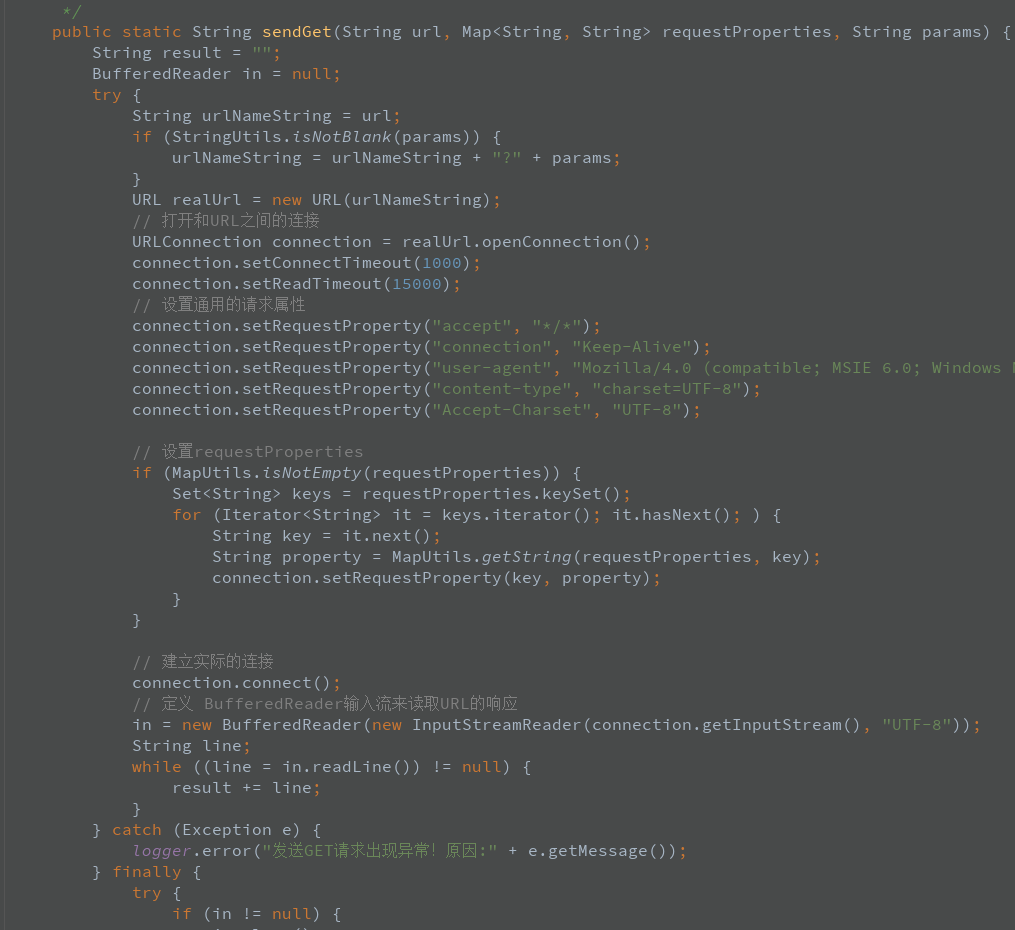
这里面有个致命的问题,他http请求没有设置超时等待时间,connection如果不设置超时时间或者0就认为是无穷大,也就是会一直都不超时,这时候如果被请求的第三方页面如果不响应或者响应非常慢,这个请求就会一直的等待,或者是请求没回来接着又来一次,导致这个线程就卡住了,但是线程堆积在这里又不崩溃还一直的在做某些事情会产生大量的对象,然后触发了jvm不停的疯狂GC把服务器CPU飚到了极限,然后服务器响应变得非常慢,问题终于找到了,而且非常符合问题的特点,果然把这个地方换了一种写法加了2秒钟超时的限制,问题没有再出现。
这次问题的解决过程得出几点心得:
1、jvm的问题是很复杂的,通过日志看到的很可能不是问题的根源,解决问题也有运气成分,分析日志+业务场景+瞎蒙都是解决问题的方法,分析问题不要一条道走到黑,多结合当前的场景加上一些猜测。
2、这个问题的根源是CPU飙高,一开始总想着是代码里有死循环,后来又以为是内存泄露,所以走了很多弯路,最后还是用最笨的方法看线程栈的日志看出了问题,所以问题没有统一的解决方案,具体问题都要具体处理的,不能拘泥于以往的经验。
3、在写代码过程中尽量使用原项目中已经被广泛使用的公共工具类,尽量不要把自己自创的没有经过项目检验的代码引入工程,即使看起来很简单的一段代码可能给项目引入灾难,除非你有充足的把握了解你代码的底层,比如这个超时的设置问题。



