
进程物理内存远大于Xmx的问题分析原创
问题描述
最近经常被问到一个问题,”为什么我们系统进程占用的物理内存(Res/Rss)会远远大于设置的Xmx值”,比如Xmx设置1.7G,但是top看到的Res的值却达到了3.0G,随着进程的运行,Res的值还在递增,直到达到某个值,被OS当做bad process直接被kill掉了。
- top - 16:57:47 up 73 days, 4:12, 8 users, load average: 6.78, 9.68, 13.31
- Tasks: 130 total, 1 running, 123 sleeping, 6 stopped, 0 zombie
- Cpu(s): 89.9%us, 5.6%sy, 0.0%ni, 2.0%id, 0.7%wa, 0.7%hi, 1.2%si, 0.0%st
- ...
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 22753 admin 20 0 4252m 3.0g 17m S 192.8 52.7 151:47.59 /opt/app/java/bin/java -server -Xms1700m -Xmx1700m -Xmn680m -Xss256k -XX:PermSize=128m -XX:MaxPermSize=128m -XX:+UseStringCache -XX:+
- 40 root 20 0 0 0 0 D 0.3 0.0 5:53.07 [kswapd0]
物理内存大于Xmx可能吗
先说下Xmx,这个vm配置只包括我们熟悉的新生代和老生代的最大值,不包括持久代,也不包括CodeCache,还有我们常听说的堆外内存从名字上一看也知道没有包括在内,当然还有其他内存也不会算在内等,因此理论上我们看到物理内存大于Xmx也是可能的,不过超过太多估计就可能有问题了。
物理内存和虚拟内存间的映射关系
我们知道os在内存上面的设计是花了心思的,为了让资源得到最大合理利用,在物理内存之上搞一层虚拟地址,同一台机器上每个进程可访问的虚拟地址空间大小都是一样的,为了屏蔽掉复杂的到物理内存的映射,该工作os直接做了,当需要物理内存的时候,当前虚拟地址又没有映射到物理内存上的时候,就会发生缺页中断,由内核去为之准备一块物理内存,所以即使我们分配了一块1G的虚拟内存,物理内存上不一定有一块1G的空间与之对应,那到底这块虚拟内存块到底映射了多少物理内存呢,这个我们在linux下可以通过/proc/<pid>/smaps这个文件看到,其中的Size表示虚拟内存大小,而Rss表示的是物理内存,所以从这层意义上来说和虚拟内存块对应的物理内存块不应该超过此虚拟内存块的空间范围
- 8dc00000-100000000 rwxp 00000000 00:00 0
- Size: 1871872 kB
- Rss: 1798444 kB
- Pss: 1798444 kB
- Shared_Clean: 0 kB
- Shared_Dirty: 0 kB
- Private_Clean: 0 kB
- Private_Dirty: 1798444 kB
- Referenced: 1798392 kB
- Anonymous: 1798444 kB
- AnonHugePages: 0 kB
- Swap: 0 kB
- KernelPageSize: 4 kB
- MMUPageSize: 4 kB
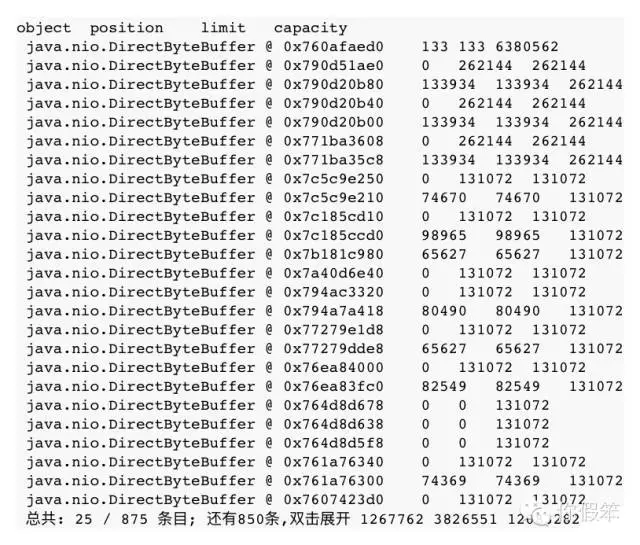
一般来说连续分配的内存块还是有一定关系的,当然也不能完全肯定这种关系,此次为了排查这个问题,我特地写了个简单的分析工具来分析这个问题,得到的效果大致如下:

当然这只是一个简单的分析,后面我们会挖掘更多的点出来,比如每个内存块是属于哪块memory pool,到底是什么地方分配的等(注:上面的第一条,其实就是new+old+perm对应的虚拟内存及其物理内存映射情况)。
进程满足什么条件会被os因为oom而被kill
当一个进程无故消失的时候,我们一般看/var/log/message里是否有Out of memory: Kill process关键字(如果是java进程我们先看是否有crash日志),如果有就说明是被os因为oom而被kill了:

从上面我们看到了一个堆栈,也就是内核里选择被kill进程的过程,这个过程会对进程进行一系列的计算,每个进程都会给它们计算一个score,这个分数会记录在/proc/<pid>/oom_score里,通常这个分数越高,就越危险,被kill的可能性就越大,下面将内核相关的代码贴出来,有兴趣的可以看看,其中代码注释上也写了挺多相关的东西了:

物理内存到底去哪了?
DirectByteBuffer冰山对象?
这是我们查这个问题首先要想到的一个地方,是否是因为什么地方不断创建DirectByteBuffer对象,但是由于没有被回收导致了内存泄露呢,之前有篇文章已经详细介绍了这种特殊对象,可以看我之前发的文章《JVM源码分析之堆外内存完全解读》,知道后台到底绑定了多少堆外内存还没有被回收:
某个动态库里频繁分配?
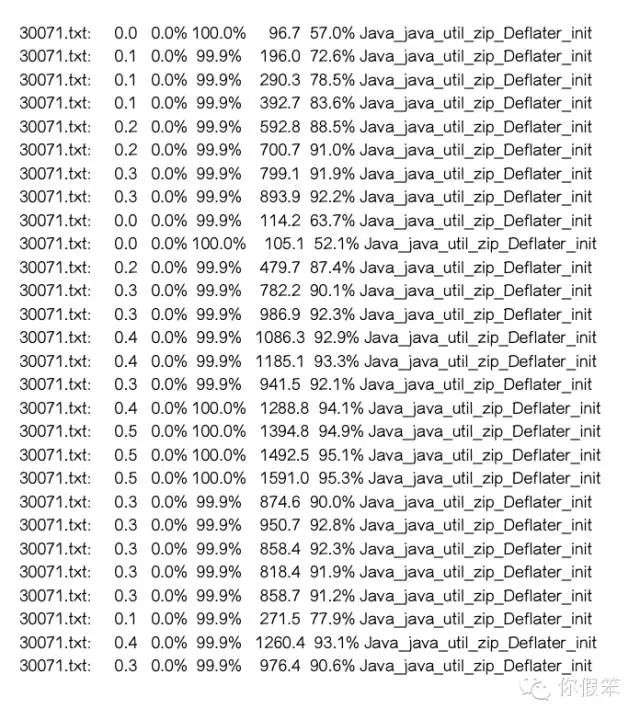
对于动态库里频繁分配的问题,主要得使用google的perftools工具了,该工具网上介绍挺多的,就不对其用法做详细介绍了,通过该工具我们能得到native方法分配内存的情况,该工具主要利用了unix的一个环境变量LD_PRELOAD,它允许你要加载的动态库优先加载起来,相当于一个Hook了,于是可以针对同一个函数可以选择不同的动态库里的实现了,比如googleperftools就是将malloc方法替换成了tcmalloc的实现,这样就可以跟踪内存分配路径了,得到的效果类似如下:

从上面的输出中我们看到了zcalloc函数总共分配了1616.3M的内存,还有Java_java_util_zip_Deflater_init分配了1591.0M内存,deflateInit2_分配了1590.5M,然而总共才分配了1670.0M内存,所以这几个函数肯定是调用者和被调用者的关系:
上述代码也验证了他们这种关系。
那现在的问题就是找出哪里调用Java_java_util_zip_Deflater_init了,从这方法的命名上知道它是一个java的native方法实现,对应的是java.util.zip.Deflater这个类的init方法,所以要知道init方法哪里被调用了,跟踪调用栈我们会想到btrace工具,但是btrace是通过插桩的方式来实现的,对于native方法是无法插桩的,于是我们看调用它的地方,找到对应的方法,然后进行btrace脚本编写:
- import com.sun.btrace.annotations.*;
- import static com.sun.btrace.BTraceUtils.*;
- public class Test {
- (
- clazz="java.util.zip.Deflater",
- method="<init>"
- )
- public static void onnewThread(int i,boolean b) {
- jstack();
- }
- }
于是跟踪对应的进程,我们能抓到调用Deflater构造函数的堆栈

从上面的堆栈我们找出了调用java.util.zip.Deflate.init()的地方
问题解决
上面已经定位了具体的代码了,于是再细致跟踪了下对应的代码,其实并不是代码实现上的问题,而是代码设计上没有考虑到流量很大的场景,当流量很大的时候,不管自己系统是否能承受这么大的压力,都来者不拒,拿到数据就做deflate,而这个过程是需要分配堆外内存的,当量达到一定程度的时候此时会发生oom killer,另外我们在分析过程中发现其实物理内存是有下降的
这也就说明了其实代码使用上并没有错,因此建议将deflate放到队列里去做,比如限制队列大小是100,每次最多100个数据可以被deflate,处理一个放进一个,以至于不会被活活撑死。



