
虽然是我遇到的一个棘手的生产问题,但是我写出来之后,就是你的了。原创
你好呀,是歪歪。
前几天,就在大家还沉浸在等待春节到来的喜悦氛围的时候,在一个核心链路上的核心系统中,我踩到一个坑的一比的坑,要不是我沉着冷静,解决思路忙中有序,处理手段雷厉风行,把它给扼杀在萌芽阶段了,那这玩意肯定得引发一个比较严重的生产问题。
从问题出现到定位到这个问题的根本原因,我大概是花了两天半的时间。
所以写篇文章给大家复盘一下啊,这个案例就是一个纯技术的问题导致的,和业务的相关度其实并不大,所以你拿过去直接添油加醋,稍微改改,往自己的服务上套一下,那就是你的了。
我再说一次:虽然现在不是你的,但是你看完之后就是你的了,你明白我意思吧?
表象
事情是这样的,我这边有一个服务,你可以把这个服务粗暴的理解为是一个商城一样的服务。有商城肯定就有下单嘛。
然后接到上游服务反馈,说调用下单接口偶尔有调用超时的情况出现,断断续续的出现好几次了,给了几笔流水号,让我看一下啥情况。当时我的第一反应是不可能是我这边服务的问题,因为这个服务上次上线都至少是一个多月前的事情了,所以不可能是由于近期服务投产导致的。
但是下单接口,你听名字就知道了,核心链接上的核心功能,不能有一点麻痹大意。
每一个请求都很重要,客户下单体验不好,可能就不买了,造成交易损失。
交易上不去营业额就上不去,营业额上不去利润就上不去,利润上不去年终就上不去。
想到这一层关系之后,我立马就登陆到服务器上,开始定位问题。
一看日志,确实是我这边接口请求处理慢了,导致的调用方超时。
为什么会慢呢?

于是按照常规思路先根据日志判断了一下下单接口中调用其他服务的接口相应是否正常,从数据库获取数据的时间是否正常。
这些判断没问题之后,我转而把目光放到了 gc 上,通过监控发现那个时间点触发了一次耗时接近 1s 的 full gc,导致响应慢了。
由于我们监控只采集服务近一周的 gc 数据,所以我把时间拉长后发现 full gc 在这一周的时间内出现的频率还有点高,虽然我还没定位到问题的根本原因,但是我定位到了问题的表面原因,就是触发了 full gc。
因为是核心链路,核心流程,所以此时不应该急着去定位根本原因,而是先缓解问题。
好在我们提前准备了各种原因的应急预案,其中就包含这个场景。预案的内容就是扩大应用堆内存,延缓 full gc 的出现。
所以我当即进行操作报备并联系运维,按照紧急预案执行,把服务的堆内存由 8G 扩大一倍,提升到 16G。
虽然这个方法简单粗暴,但是既解决了当前的调用超时的问题,也给了我足够的排查问题的时间。

定位原因
当时我其实一点都不慌的,因为问题在萌芽阶段的时候我就把它给干掉了。

不就是 full gc 吗,哦,我的老朋友。
先大胆假设一波:程序里面某个逻辑不小心搞出了大对象,触发了 full gc。
所以我先是双手插兜,带着监控图和日志请求,闲庭信步的走进项目代码里面,想要凭借肉眼找出一点蛛丝马迹......

没有任何收获,因为下单服务涉及到的逻辑真的是太多了,服务里面 List 和 Map 随处可见,我很难找到到底哪里是大对象。
但是我还是一点都不慌,因为这半天都没有再次发生 Full GC,说明此时留给我的时间还是比较充足的,
所以我请求了场外援助,让 DBA 帮我导出一下服务的慢查询 SQL,因为我想可能是从数据库里面一次性取的数据太多了,而程序里面也没有做控制导致的。
我之前就踩过类似的坑。
一个根据客户号查询客户有多少订单的内部使用接口,接口的返回是 List<订单>,看起来没啥毛病,对不对?
一般来说一个个人客户就几十上百,多一点的上千,顶天了的上万个订单,一次性拿出来也不是不可以。
但是有一个客户不知道咋回事,特别钟爱我们的平台,也是我们平台的老客户了,一个人居然有接近 10w 的订单。
然后这么多订单对象搞到到项目里面,本来响应就有点慢,上游再发起几次重试,直接触发 Full gc,降低了服务响应时间。
所以,经过这个事件,我们定了一个规矩:用 List、Map 来作为返回对象的时候,必须要考虑一下极端情况下会返回多少数据回去。即使是内部使用,也最好是进行分页查询。
好了,话说回来,我拿到慢查询 SQL 之后,根据几个 Full gc 时间点,对比之后提取出了几条看起来有点问题的 SQL。
然后拿到数据库执行了一下,发现返回的数据量其实也都不大。
此刻我还是一点都不慌,反正内存够用,而且针对这类问题,我还有一个场外援助没有使用呢。
第二天我开始找运维同事帮我每隔 8 小时 Dump 一次内存文件,然后第三天我开始拿着内存文件慢慢分析。
但是第二天我也没闲着,根据现有的线索反复分析、推理可能的原因。
然后在观看 GC 回收内存大小监控的时候,发现了一点点端倪。因为触发 Full GC 之后,发现被回收的堆内存也不是特别多。
当时就想到了除了大对象之外,还有一个现象有可能会导致这个现象:内存泄露。
巧的是在第二天又发生了一次 Full gc,这样我拿到的 Dump 文件就更有分析的价值了。基于前面的猜想,我分析的时候直接就冲着内存泄漏的方向去查了。
我拿着 5 个 Dump 文件,分析了在 5 个 Dump 文件中对象数量一直在增加的对象,这样的对象也不少,但是最终定位到了 FutureTask 对象,就是它:
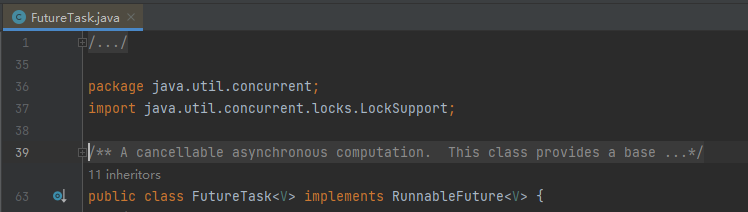
找到这玩意了再回去定位对应部分的代码就比较容易。
但是你以为定位了代码就完事了吗?
不是的,到这里才刚刚开始,朋友。
因为我发现这个代码对应的 Bug 隐藏的还是比较深的,而且也不是我最开始假象的内存泄露,就是一个纯粹的内存溢出。
所以值得拿出来仔细嗦一嗦。
示例代码
为了让你沉浸式体验找 BUG 的过程,我高低得给你整一个可复现的 Demo 出来,你拿过去就可以跑的那种。
首先,我们得搞一个线程池:
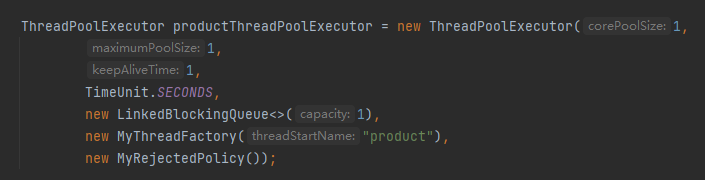
需要说明一下的是,上面这个线程池的核心线程数、最大线程数和队列长度我都取的 1,只是为了方便演示问题,在实际项目中是一个比较合理的值。
然后重点看一下线程池里面有一个自定义的叫做 MyThreadFactory 的线程工厂类和一个自定义的叫做 MyRejectedPolicy 的拒绝策略。
在我的服务里面就是有这样一个叫做 product 的线程池,用的也是这个自定义拒绝策略。
其中 MyThreadFactory 的代码是这样的:
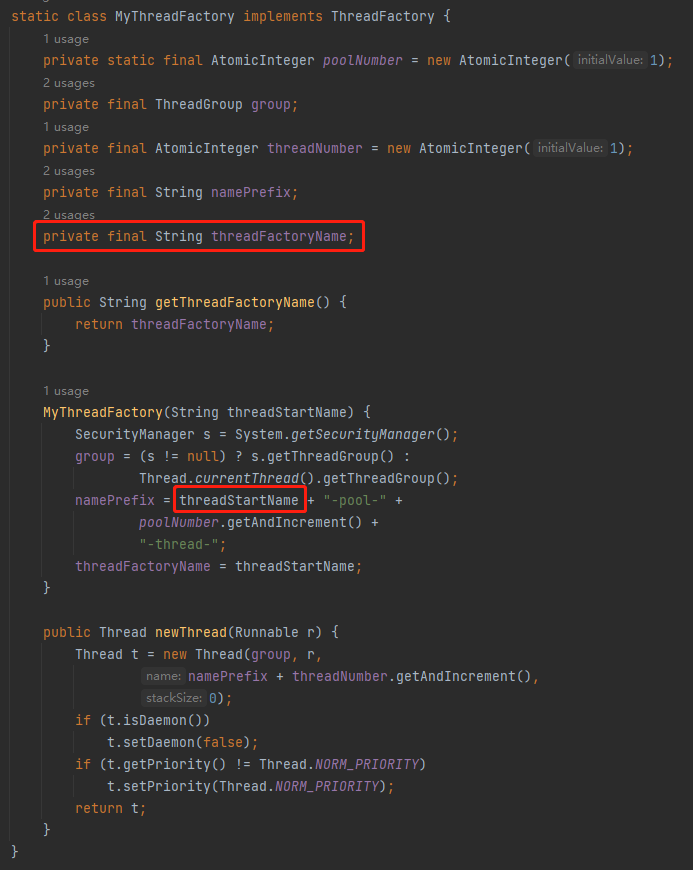
它和默认的线程工厂之间唯一的区别就是我加了一个 threadFactoryName 字段,方便给线程池里面的线程取一个合适的名字。
更直观的表示一下区别就是下面这个玩意:
原生:pool-1-thread-1
自定义:product-pool-1-thread-1
接下来看自定义的拒绝策略:
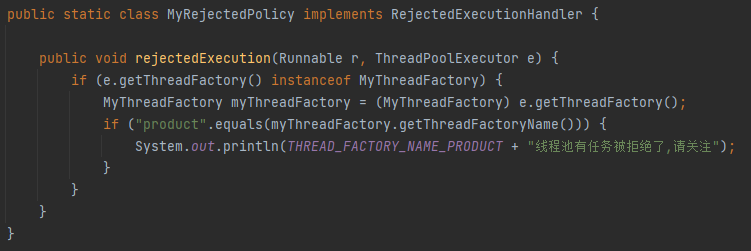
这里的逻辑很简单,就是当 product 线程池满了,触发了拒绝策略的时候打印一行日志,方便后续定位。
然后接着看其他部分的代码:

标号为 ① 的地方是线程池里面运行的任务,我这里只是一个示意,所以逻辑非常简单,就是把 i 扩大 10 倍。实际项目中运行的任务业务逻辑,会复杂一点,但是也是有一个 Future 返回。
标号为 ② 的地方就是把返回的 Future 放到 list 集合中,在标号为 ③ 的地方循环处理这个 list 对象里面的 Future。
需要注意的是因为实例中的线程池最多容纳两个任务,但是这里却有五个任务。我这样写的目的就是为了方便触发拒绝策略。
然后在实际的项目里面刚刚提到的这一坨逻辑是通过定时任务触发的,所以我这里用一个死循环加手动开启线程来示意:
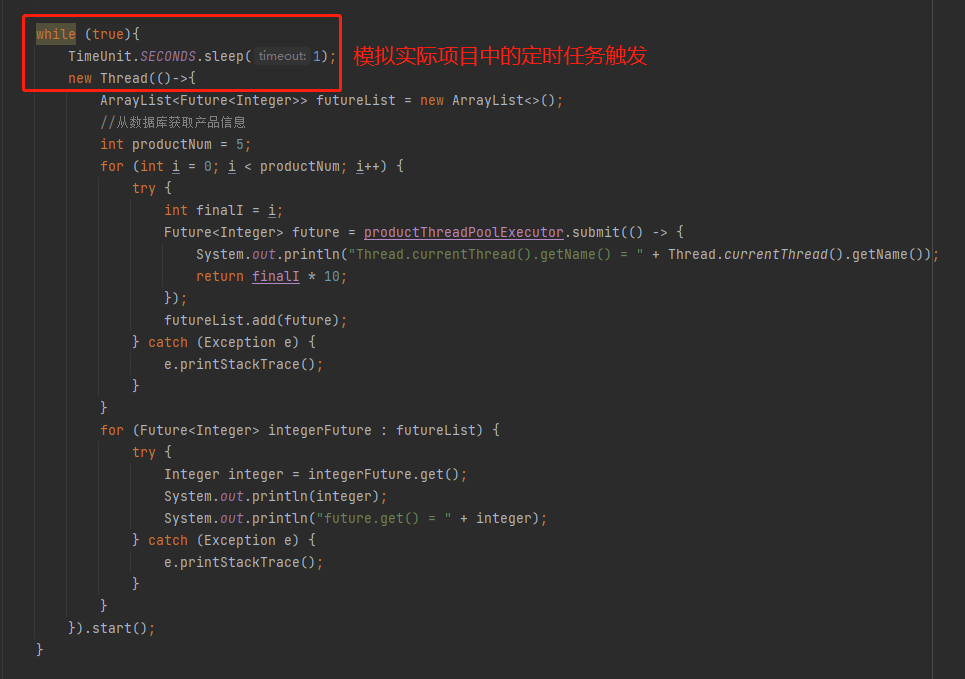
整个完整的代码就是这样的,你直接粘过去就可以跑,这个案例就可以完全复现我在生产上遇到的问题:
public class MainTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor productThreadPoolExecutor = new ThreadPoolExecutor(1,
1,
1,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1),
new MyThreadFactory("product"),
new MyRejectedPolicy());
while (true){
TimeUnit.SECONDS.sleep(1);
new Thread(()->{
ArrayList<Future<Integer>> futureList = new ArrayList<>();
//从数据库获取产品信息
int productNum = 5;
for (int i = 0; i < productNum; i++) {
try {
int finalI = i;
Future<Integer> future = productThreadPoolExecutor.submit(() -> {
System.out.println("Thread.currentThread().getName() = " + Thread.currentThread().getName());
return finalI * 10;
});
futureList.add(future);
} catch (Exception e) {
e.printStackTrace();
}
}
for (Future<Integer> integerFuture : futureList) {
try {
Integer integer = integerFuture.get();
System.out.println(integer);
System.out.println("future.get() = " + integer);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
static class MyThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
private final String threadFactoryName;
public String getThreadFactoryName() {
return threadFactoryName;
}
MyThreadFactory(String threadStartName) {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = threadStartName + "-pool-" +
poolNumber.getAndIncrement() +
"-thread-";
threadFactoryName = threadStartName;
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
public static class MyRejectedPolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (e.getThreadFactory() instanceof MyThreadFactory) {
MyThreadFactory myThreadFactory = (MyThreadFactory) e.getThreadFactory();
if ("product".equals(myThreadFactory.getThreadFactoryName())) {
System.out.println(THREAD_FACTORY_NAME_PRODUCT + "线程池有任务被拒绝了,请关注");
}
}
}
}
}
你跑的时候可以把堆内存设置的小一点,比如我设置为 10m:
-Xmx10m -Xms10m
然后用 jconsole 监控,你会发现内存走势图是这样的:

哦,我的老天爷啊,这个该死的图,也是我的老伙计了,一个缓慢的持续上升的内存趋势图, 最后疯狂的触发 gc,但是并没有内存被回收,最后程序直接崩掉:
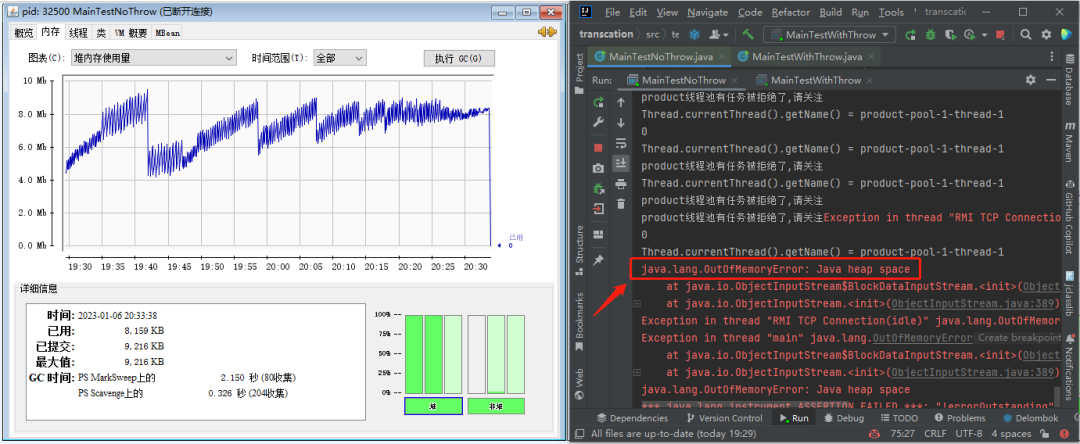
这绝大概率就是内存泄漏了啊。
但是在生产上的内存走势图完全看不出来这个趋势,我前面说了,主要因为 GC 情况的数据只会保留一周时间,所以就算把整个图放出来也不是那么直观。
其次不是因为我牛逼嘛,萌芽阶段就干掉了这个问题,所以没有遇到最后频繁触发 gc,但是没啥回收的,导致 OOM 的情况。
所以我再带着你看看另外一个视角,这是我真正定位到问题的视角。就是分析内存 Dump 文件。
分析内存 Dump 文件的工具以及相关的文章非常的多,我就不赘述了,你随便找个工具玩一玩就行。我这里主要是分享一个思路,所以就直接使用 idea 里面的 Profiler 插件了,方便。
我用上面的代码,启动起来之后在四个时间点分别 Dump 之后,观察内存文件。内存泄露的思路就是找文件里面哪个对象的个数和占用空间是在持续上升嘛,特别是中间还发生过 full gc,这个过程其实是一个比较枯燥且复杂的过程,在生产项目中可能会分析出很多个这样的对象,然后都要到代码里面去定位相关逻辑。
但是我这里极大的简化了程序,所以很容易就会发现这个 FutureTask 对象特别的抢眼,数量在持续增加,而且还是名列前茅的:

然后这个工具还可以看对象占用大小,大概是这个意思:

所以我还可以看看在这几个文件中 FutureTask 对象大小的变化,也是持续增加:

就它了,准没错。
好,问题已经能复现了,GC 图和内存 Dump 的图也都给你看了。
到这里,如果有人已经看出来问题的原因了,可以直接拉到文末点个赞,感谢大佬阅读我的文章。
如果你还没看出端倪来,那么我先给你说问题的根本原因:
问题的根本原因就出在 MyRejectedPolicy 这个自定义拒绝策略上。
在带你细嗦这个问题之前,我先问一个问题:
JDK 自带的线程池拒绝策略有哪些?
这玩意,老八股文了,存在的时间比我从业的时间都长,得张口就来:
-
AbortPolicy:丢弃任务并抛出 RejectedExecutionException 异常,这是默认的策略。 -
DiscardOldestPolicy:丢弃队列最前面的任务,执行后面的任务 -
CallerRunsPolicy:由调用线程处理该任务 -
DiscardPolicy:也是丢弃任务,但是不抛出异常,相当于静默处理。
然后你再回头看看我的自定义拒绝策略,是不是和 DiscardPolicy 非常像,也没有抛出异常。只是比它更高级一点,打印了一点日志。
当我们使用默认的策略的时候:

或者我们把框起来这行代码粘到我们的 MyRejectedPolicy 策略里面:

再次运行,不管是观察 gc 情况,还是 Dump 内存,你会发现程序正常了,没毛病了。
下面这个走势图就是在拒绝策略中是否抛出异常对应的内存走势对比图:
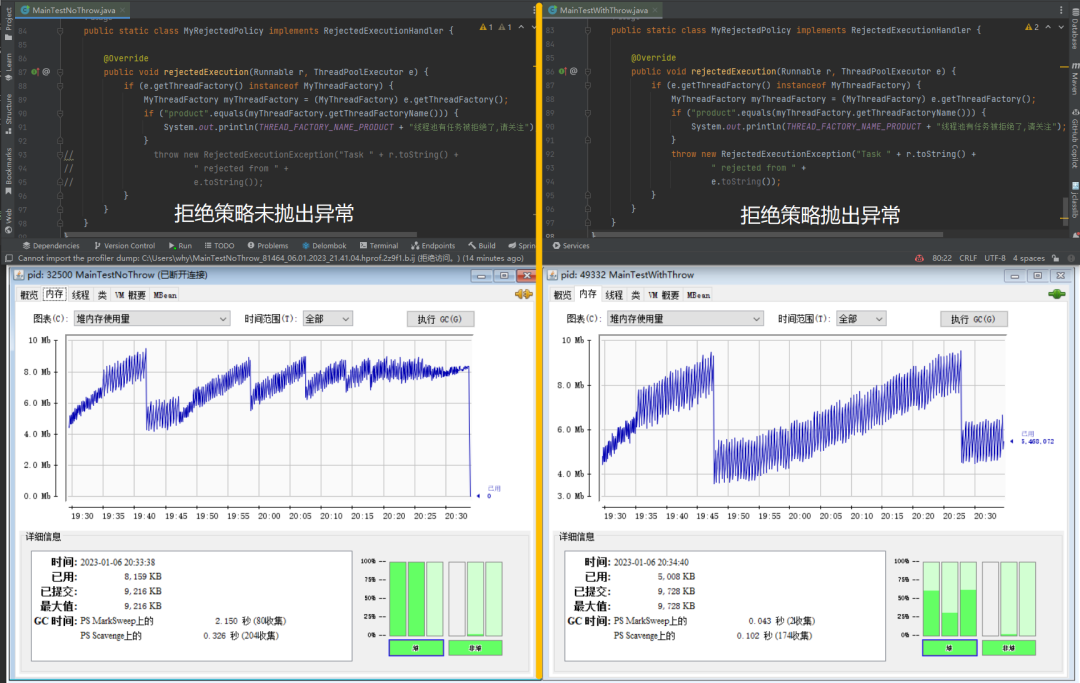
在拒绝策略中抛出异常就没毛病了,为啥?

探索
首先,我们来看一下没有抛出异常的时候,发生了什么事情。
没有抛出异常时,我们前面分析了,出现了非常多的 FutureTask 对象,所以我们就找程序里面这个对象是哪里出来的,定位到这个地方:

future 没有被回收,说明 futureList 对象没有被回收,而这两个对象对应的 GC Root 都是new 出来的这个线程,因为一个活跃线程是 GC Root。
进一步说明对应 new 出来的线程没有被回收。
所以我给你看一下前面两个案例对应的线程数对比图:
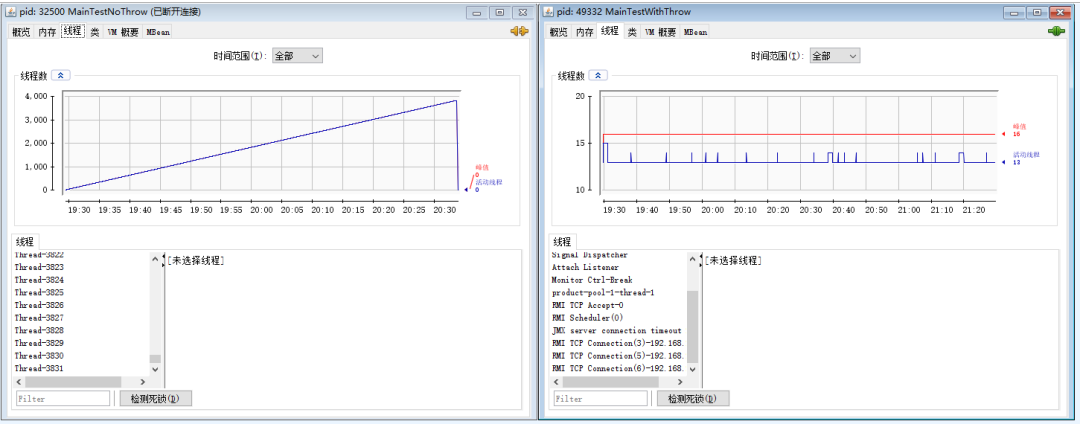
没有在拒绝策略中抛出异常的线程非常的多,看起来每一个都没有被回收,这个地方肯定就是有问题的。
然后随机选一个查看详情,可以看到线程在第 39 行卡着的:
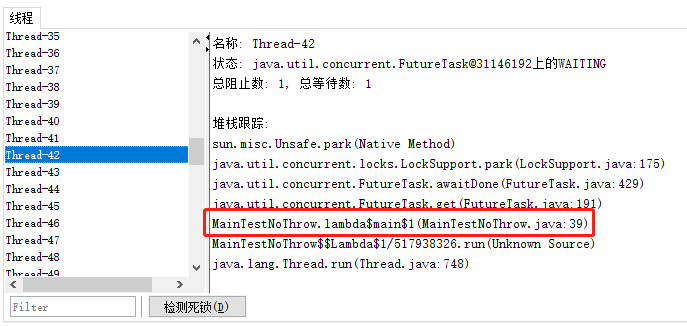
也就是这样一行代码:

这个方法大家应该熟悉,因为也没有给等待时间嘛,所以如果等不到 Future 的结果,线程就会在这里死等。
也就导致线程不会运行结束,所以不会被回收。
对应着源码说就是有 Future 的 state 字段,即状态不正确,导致线程阻塞在这个 if 里面:
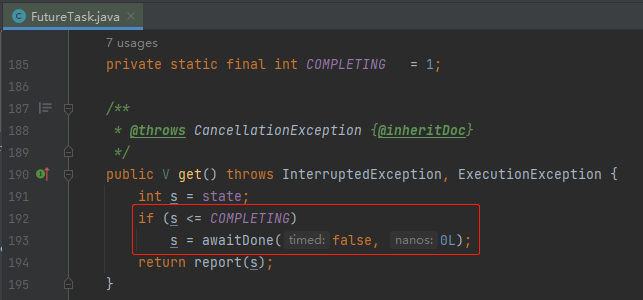
if 里面的 awaitDone 逻辑稍微有一点点复杂,这个地方其实还有一个 BUG,在 JDK 9 进行了修复,这一点我在之前的文章中写过,所以就不赘述了,你有兴趣可以去看看:《Doug Lea在J.U.C包里面写的BUG又被网友发现了。》
总之,在我们的案例下,最终会走到我框起来的代码:
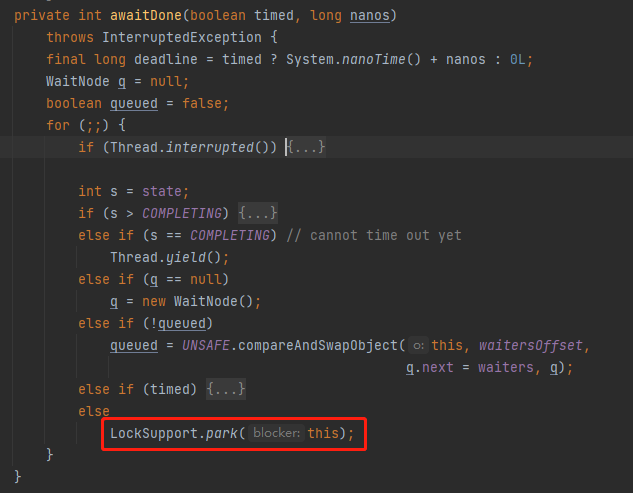
也就是当前线程会在这里阻塞住,等到唤醒。
那么问题就来了,谁来唤醒它呢?
巧了,这个问题我之前也写过,在这篇文章中,有这样一句话:《关于多线程中抛异常的这个面试题我再说最后一次!》
如果子线程捕获了异常,该异常不会被封装到 Future 里面。是通过 FutureTask 的 run 方法里面的 setException 和 set 方法实现的。在这两个方法里面完成了 FutureTask 里面的 outcome 变量的设置,同时完成了从 NEW 到 NORMAL 或者 EXCEPTIONAL 状态的流转。
带你看一眼 FutureTask 的 run 方法:
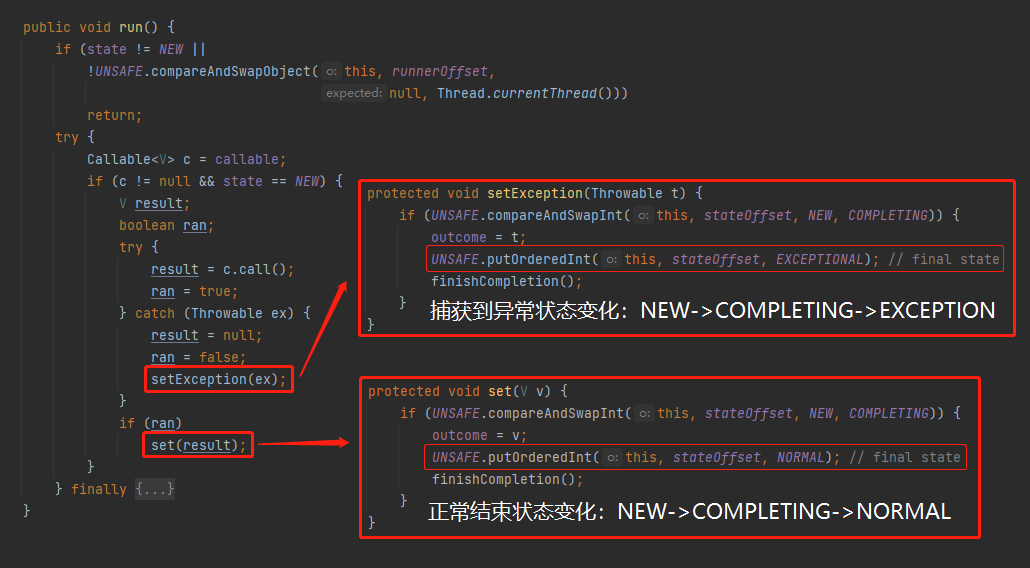
也就是说 FutureTask 状态变化的逻辑是被封装到它的 run 方法里面的。
知道了它在哪里等待,在哪里唤醒,揭晓答案之前,还得带你去看一下它在哪里诞生。
它的出生地,就是线程池的 submit 方法:
java.util.concurrent.AbstractExecutorService#submit
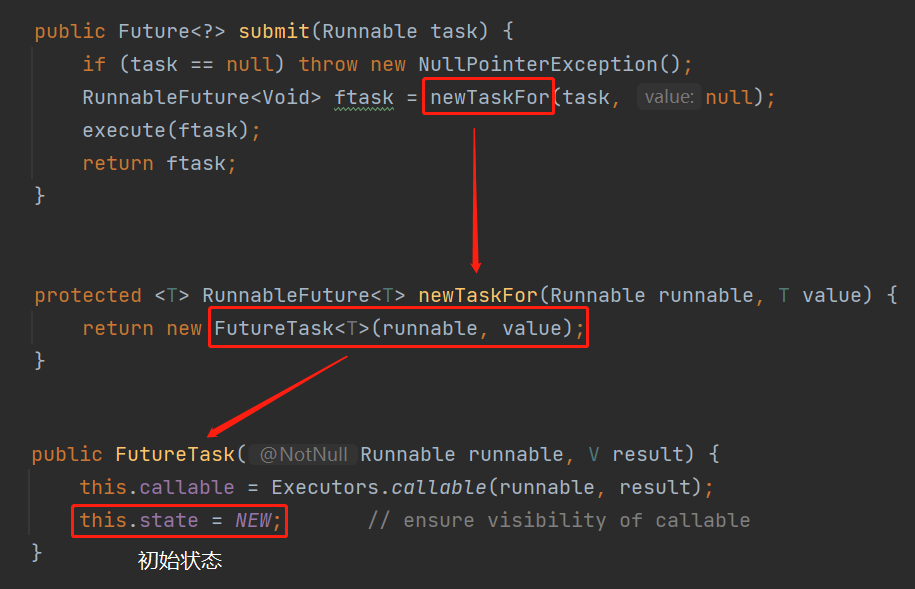
但是,朋友,注意,我要说但是了。
首先,我们看一下当线程池的 execute 方法,当线程池满了之后,再次提交任务会触发 reject 方法,而当前的任务并不会被放到队列里面去:

也就是说当 submit 方法不抛出异常就会把正常返回的这个状态为 NEW 的 future 放到 futureList 里面去,即下面编号为 ① 的地方。然后被标号为 ② 的循环方法处理:
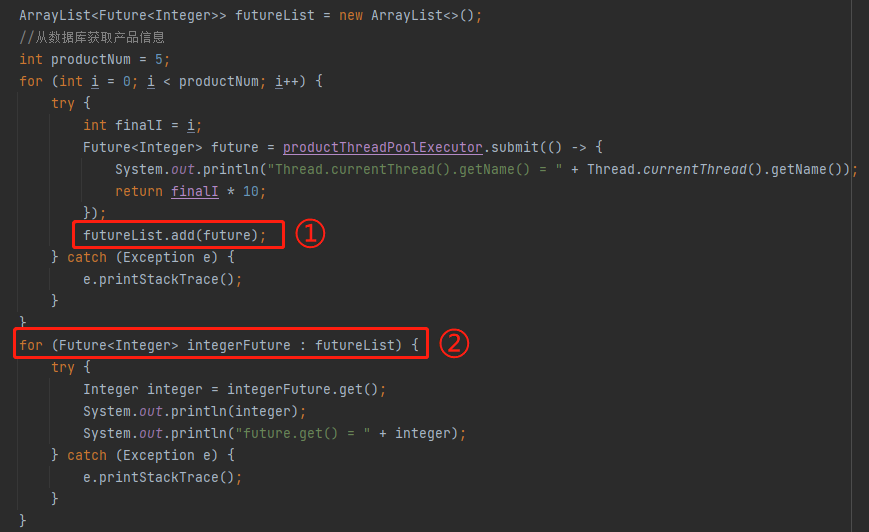
那么问题就来了:被拒绝了的任务,还会被线程池触发 run 方法吗?
肯定是不会的,都被拒绝了,还触发个毛线啊。
不会被触发 run 方法,那么这个 future 的状态就不会从 NEW 变化到 EXCEPTION 或者 NORMAL。
所以调用 Future.get() 方法就一定一直阻塞。又因为是定时任务触发的逻辑,所以导致 Future 对象越来越多,形成一种内存泄露。
submit 方法如果抛出异常则会被标号为 ② 的地方捕获到异常。
不会执行标号为 ① 的地方,也就不会导致内存泄露:

道理就是这么一个道理。
解决方案
知道问题的根本原因了,解决方案也很简单。
定位到这个问题之后,我发现项目中的线程池参数配置的并不合理,每次定时任务触发之后,因为数据库里面的数据较多,所以都会触发拒绝策略。
所以首先是调整了线程池的参数,让它更加的合理。当时如果你要用这个案例,这个地方你也可以包装一下,动态线程池,高大上,对吧,以前讲过。
然后是调用 Future.get() 方法的时候,给一个超时时间,这样至少能帮我们兜个底。资源能及时释放,比死等好。
最后就是一个教训:自定义线程池拒绝策略的时候,一定一定记得要考虑到这个场景。
比如我前面抛出异常的自定义拒绝策略其实还是有问题的,我故意留下了一个坑:
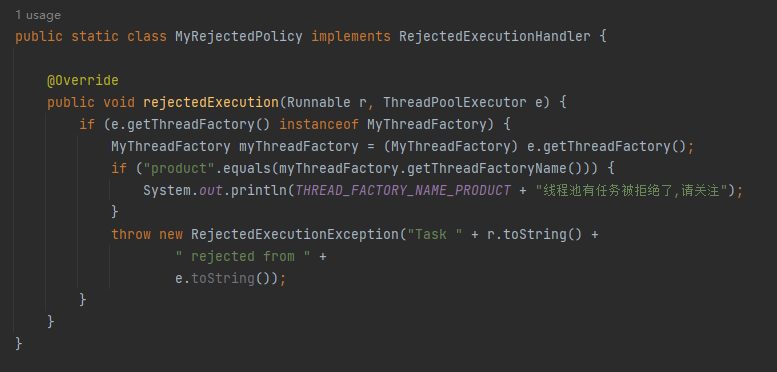
抛出异常的前提是要满足最开始的 if 条件:
e.getThreadFactory() instanceof MyThreadFactory
如果别人误用了这个拒绝策略,导致这个 if 条件不成立的话,那么这个拒绝策略还是有问题。
所以,应该把抛出异常的逻辑移到 if 之外。
同时在排查问题的过程中,在项目里面看到了类似这样的写法:

不要这样写,好吗?
一个是因为 submit 是有返回值的,你要是不用返回值,直接用 execute 方法不香吗?
另外一个是因为你这样写,如果线程池里面的任务执行的时候出异常了,会把异常封装到 Future 里面去,而你又不关心 Future,相当于把异常给吞了,排查问题的时候你就哭去吧。
这些都是编码过程中的一些小坑和小注意点。

反转
这一小节的题目为什么要叫反转?
因为以上的内容,除了技术原理是真的,我铺垫的所有和背景相关的东西,全部都是假的。

整篇文章从第二句开始就是假的,我根本就没有遇到过这样的一个生产问题,也谈不上扼杀在摇篮里,更谈不上是我去解决的了。
但是我在开始的时候说了这样一句话,也是全文唯一一句加粗的话:
虽然现在不是你的,但是你看完之后就是你的了,你明白我意思吧?
所以,这个背景其实我前几天看到了“严选技术”发布的这篇文章《严选库存稳定性治理系列:一个线程池拒绝策略引发的血案》。
他们的这篇文章确实是一个真实的生产问题,当时虽然不是我的,但是我看完之后理解了,消化了,四舍五入就相当于是我遇到的生产问题了。
这个不过分吧?
其实看完他们的这篇文章之后,我立马想起了我之前写过的这篇文章:《看起来是线程池的BUG,但是我认为是源码设计不合理。》
这两篇文章遇到的问题的核心原因其实是一模一样的。
我写的这篇就是单纯从技术角度去解析的这个问题,而“严选技术”则是从真实场景出发,层层剥茧,抵达了问题的核心。
我在我的文章中的最后就有这样一段话:

巧了,这不是和“严选技术”里面这句话遥相呼应起来了吗:

在我反复阅读了他们的文章,了解到了背景和原因之后,我润色了一下,写了这篇文章来“骗”你。
如果你有那么几个瞬间被我“骗”到了,那么我问你一个问题:假设你是面试官,你问我工作中有没有遇到过比较棘手的问题?
而我是一个只有三年工作经验的求职者。
我用这篇文章中我假想出来的生产问题处理过程,并辅以技术细节,你能看出来这是我“包装”的吗?
然后在描述完事件之后,再体现一下对于事件的复盘,可以说一下基于这个事情,后面自己对监控层面进行了丰富,比如接口超时率监控、GC 导致的 STW 时间监控啥的。然后也在公司内形成了“经验教训”文档,主动同步给了其他的同事,以防反复踩坑,巴拉巴拉巴拉...
反正吧,以后看到自己觉得好的案例,不要看完之后就完了,多想想怎么学一学,包装成自己的东西。
这波包装,属于手摸手教学了吧?
求个赞,不过分吧?

你好呀,我是歪歪。我没进过一线大厂,没创过业,也没写过书,更不是技术专家,所以也没有什么亮眼的title。
当年高考,随缘调剂到了某二本院校计算机专业。纯属误打误撞,进入程序员的行列,之后开始了运气爆棚的程序员之路。
说起程序员之路还是有点意思,可以点击蓝字,查看我的程序员之路。



