
如何降低young gc时间原创
基础知识
young gc 主要采用的是copying GC算法;copying GC算法主要有以下两个步骤:
-
Root Scanning
-
Object Copy
copying Gc的执行过程大概是从 Gc roots开始扫描其引用,扫描到的就是认为是存活的对象,其他的就是不需要的对象,然后把存放对象进行移动就OK了。
young gc 的耗时也基本上都在这两个步骤上。要想减少一次young gc的时间,必须想办法减少上面两步耗时。
根据官方文档可以知道,GC roots 包含以下引用:
-
所有java线程以及线程栈帧里指向GC堆里的对象的引用
-
JNI Local & Global
-
由系统类加载器(system class loader)加载的对象,这些类是不能够被回收的
-
stack local Java方法的local变量或参数
-
其他,包含monitor & finalizable & native stack 等吧
Copying GC算法最主要的特征就是它的gc 时间只跟活对象的多少有关系,而跟它所管理的堆空间的大小没关系。
如何降低每次young gc 的时间呢
从上面的分析可以知道只要减少GC roots集合大小以及降低每次gc 之后的存活对象就可以了。
在GC roots中 跟业务方最相关的就是java线程,那要是把线程数减少是不是能降低 Root Scanning,进而降低整个young gc 时间呢。
笔者负责的项目大部分项目都是采用Hystrix线程池作为超时熔断降级,因为依赖的下游接口很多很多并且很多时候需要分批,导致线程数特别多,高达4000+,young gc 时root scanning 占用了 15ms左右,young gc 日志如下:
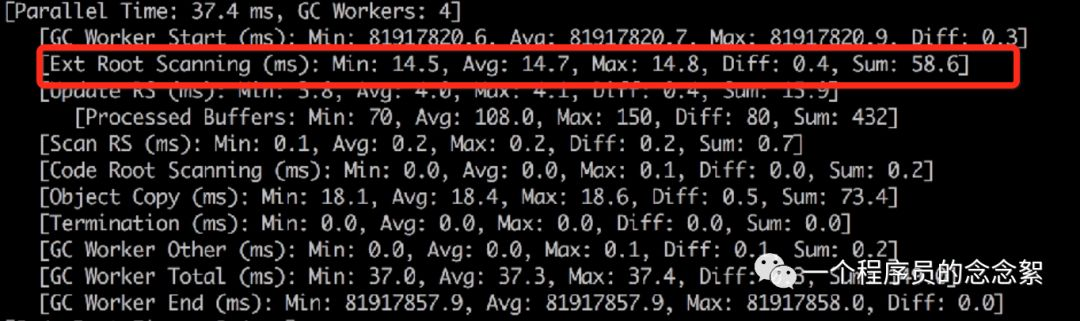
我采用了Hystrix信号量+RPC异步化去改造项目,减少线程池数目。改造之后线程数在700左右,young gc时root scanning 占用的的时间 < 5ms。
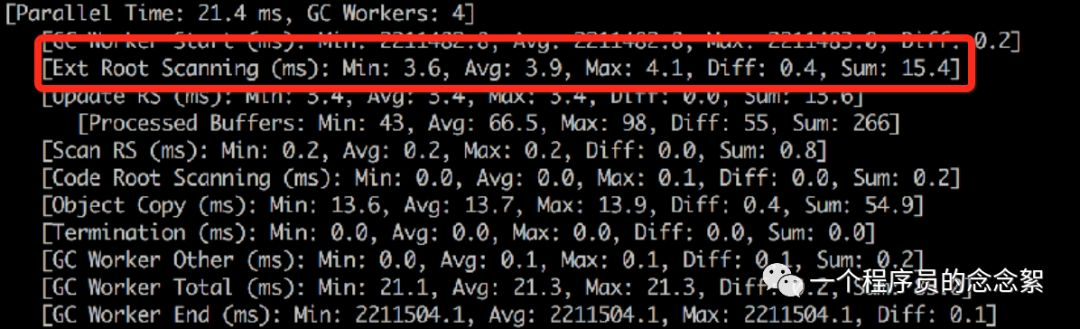
降低young gc的总时间
调整Eden区域大小对应用产生的可能影响分析
相同的应用一般来说 gc roots 应该是保持不变的,可以简单认为Root Scanning相等(其实live object会影响到扫描时间,但是影响和object copy相比很小)
我们来看看Object Copy可能受到的影响(假设Survivor区域足够大,不会因为copy过程中Survivor不够大直接晋升到old区域)。
先看第一部分,Eden移动到Survivor情况
假设机器2 Eden区域是 机器1 的两倍大,其他条件都保持不变;
就一般情况来说(Survivor区域中存活的对象比Eden少很多,比如1%),那么机器1 young gc的频率是 机器2 young gc 频率的2倍;那么假设机器1在T时间内GC一次,在GC之后由Eden区域晋升到Survivor的大小为10M(即age=1),那么机器2在2T时间之后发生GC,1T-2T之间生成的对象和机器1类似,GC之后有10M进入Survivor区域,但是0T-1T内最多会剩余10M内存可能会进入到Survivor,但是在经历1T-2T时间之后也有可能导致object已经不存活,如何判断这部分对象有没有存活呢,在机器1在2T的时间点要又要进行一次young gc,那么在0T-1T之前存活的对象也就是age=1的对象将会再次会经历一次young gc,便是了age=2,所有看age=2的年龄段剩余多少就可以了。机器2一次GC之后,由Eden区域进入到Survivor区域中的大约等于10M+机器1中Survivor中(age=2)也就是机器1:age1+age2中的object对象。
总结 机器2由Eden区域移动到Survivor的量就是机器1 age1 + age2的量。
第二部分的分析逻辑和第一部分的差不多,逻辑自己推。
结论:如果age1 远大于 age2中的值,那么调大Eden区域对减少young gc 次数会很明显,并且每次young gc time时间变化不大,能明显降低young gc总体时间。
为了验证上面的理论分析,笔者找了一个young gc 之后age1>>>age2的项目,young gc 日志如下:
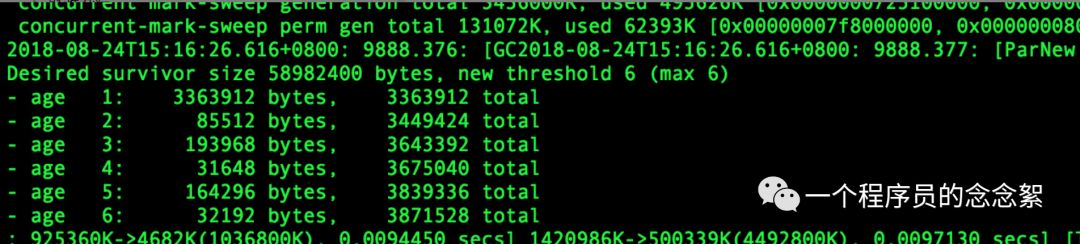
笔者把dx17的young 区域调大 (调整之后Eden为1677824K),dx14的Eden为921600K,调整前后的gc 时间如下:
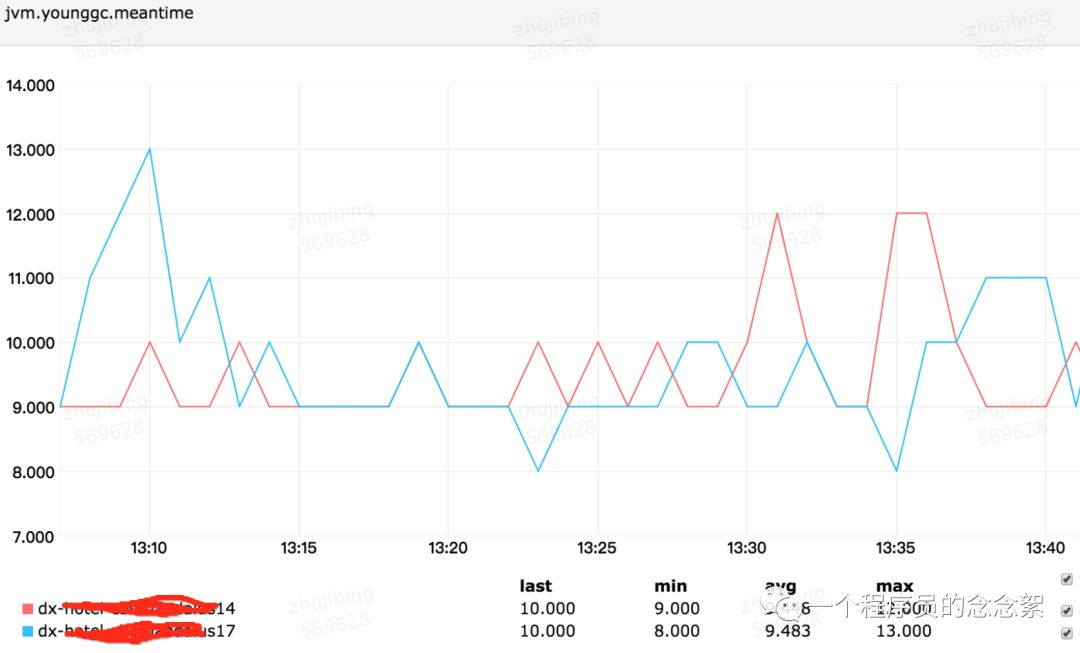
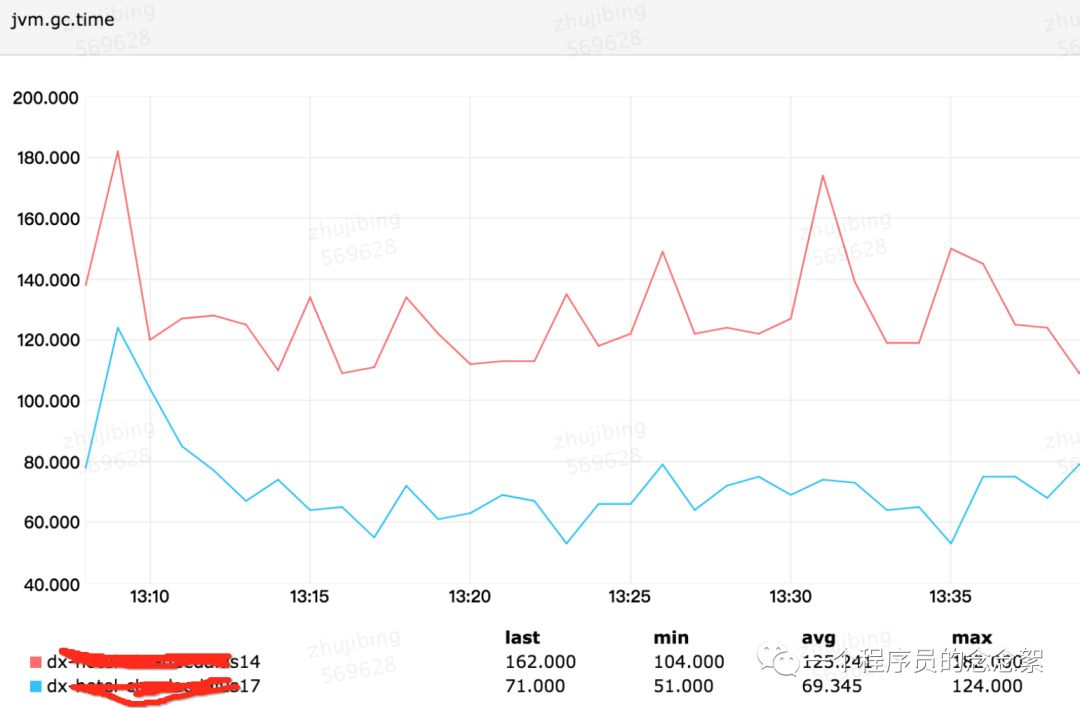
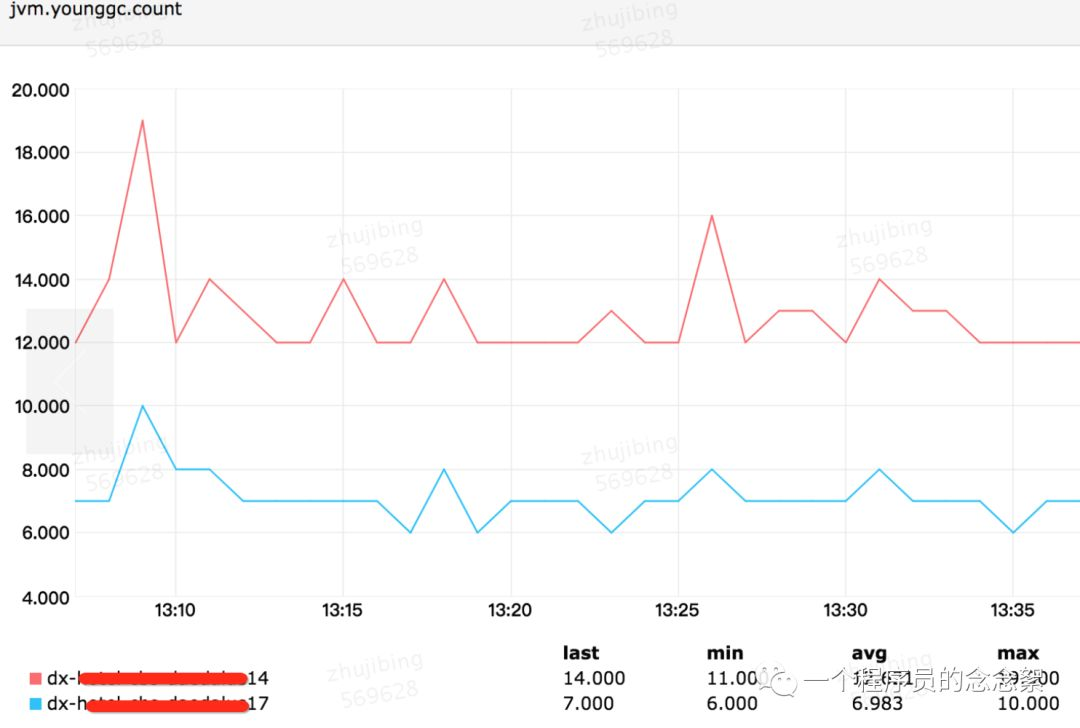
从上面3张图可以看出 整体每分钟 young gc 时间由 125ms —>70ms,young gc 次数由 每分钟12.7 —> 7,每次young gc的时间仍旧是9.4左右。用awk做了一下统计发现每次young gc 之后的live object的大小由2.85M增加到了3.3M。
减少对象生成 以到达降低young gc 次数
尽量使用小对象,并且在方法内和线程内分配对象,利用JIT在优化时对象在栈上分配,减少在堆上分配内存,可以参考浅谈HotSpot逃逸分析,但是笔者在关闭逃逸分析的时候(-XX:-DoEscapeAnalysis),对线上机器,对GC请求没啥影响,但是自己写测试确实有比较大的影响,没有明白为什么。
使用对象池,减少对象产生。



