
系统崩溃了?别惊慌!这里有快速恢复的方法!原创
-
网站挂了
-
系统当前的状态
-
根因分析:并发量高,资源不够用了
-
小结:梳理健康检查失败的原因及此类问题的排查方向
-
总结:解决慢SQL、GC频繁加内存、并发量高水平扩展加Pod
-
灵魂6问:压测做了没?

背景:为什么写这篇?
简单讲,系统不能提供服务,大多是 资源不够用了 。
这篇咱们就拉上ChatGPT一块探讨下如何快速识别哪类资源是瓶颈?
加那些资源能快速让服务恢复 ?
是加内存,还是加机器?
网站挂了

复现一下:
ERR_HTTP2_PROTOCOL_ERROR是指HTTP/2协议错误。
HTTP/2是一种新的协议,用于客户端浏览器和服务器之间的通信。这种协议允许更快地加载网页和提高安全性。
但是,在使用HTTP/2协议时,有时会遇到错误,其中之一就是ERR_HTTP2_PROTOCOL_ERROR。这个错误可能会发生在客户端浏览器和服务器之间的通信过程中,可能是由于协议本身的问题、网络问题、浏览器问题或服务器问题导致。通常,当出现这个错误时,浏览器会显示一个错误页面。ChatGPT-3
再刷新:
有点懵
到处都是报错,乱糟糟的,都错哪了?
谁来告诉我哪个地方改一改就能好了呀
系统现状
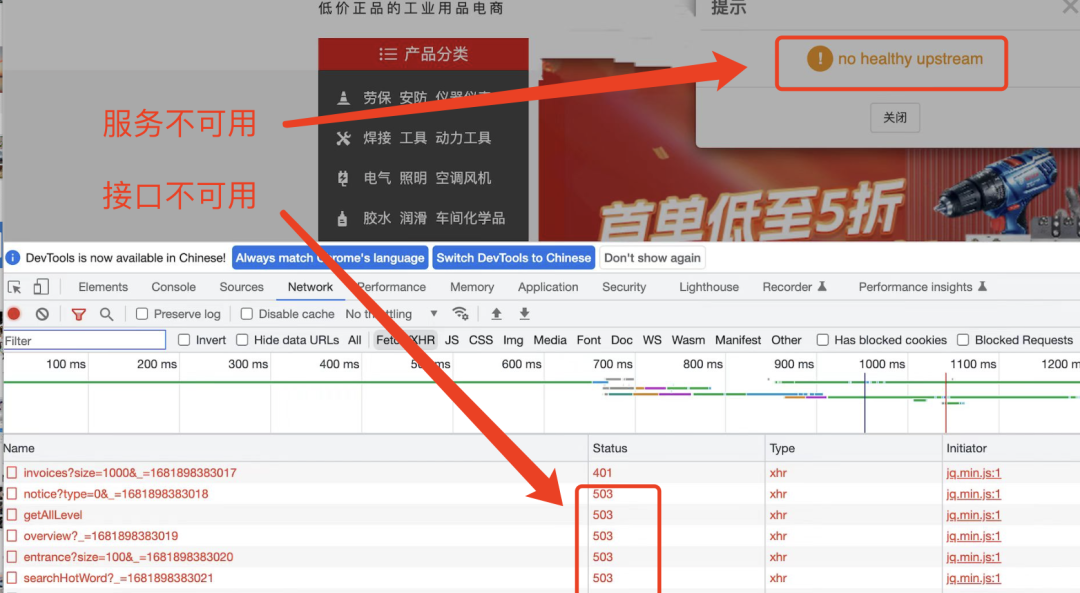
看到“no healthy upstream”,有同学已经猜到,报错的是k8s应用。
是的。报错的应用是部署在K8s集群中的

先看当前系统的状态
整体状态:
Kubernetes Dashboard查看pod状态,Pod down后又up,前赴后继。。。
应用的各项监控指标:
在ARMS平台中可以看到
应用实时监控服务ARMS(Application Real-Time Monitoring Service)是一款阿里云应用性能管理(APM)类监控产品。
借助本产品,您可以基于前端、应用、业务自定义等维度,迅速便捷地为企业构建秒级响应的应用监控能力。https://help.aliyun.com/document_detail/42781.html
“应用总览”标红

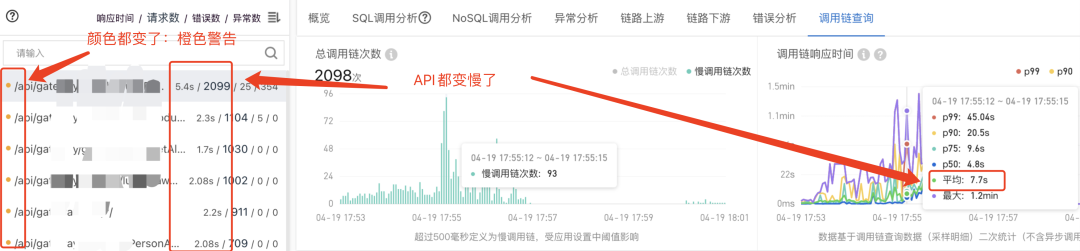
总请求量、接口响应时间、异常、慢调用比平时多
“应用详情”中,也是乱糟糟的
“接口调用”页面也是警灯闪烁,哀鸿遍野
再看数据库:
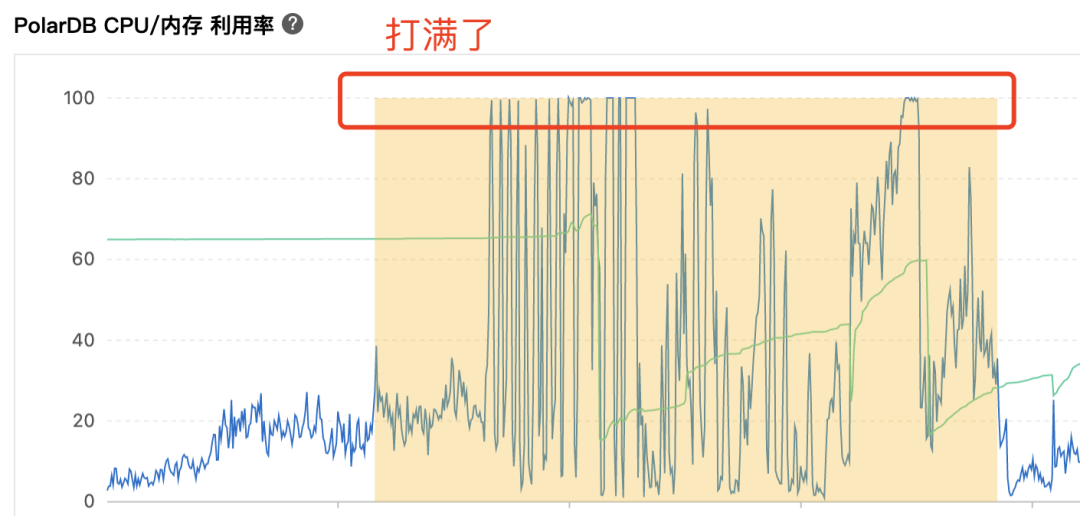
面对这牵一发而动全身的分布式系统,如何快速找到解决问题的关键点呢?
根因分析
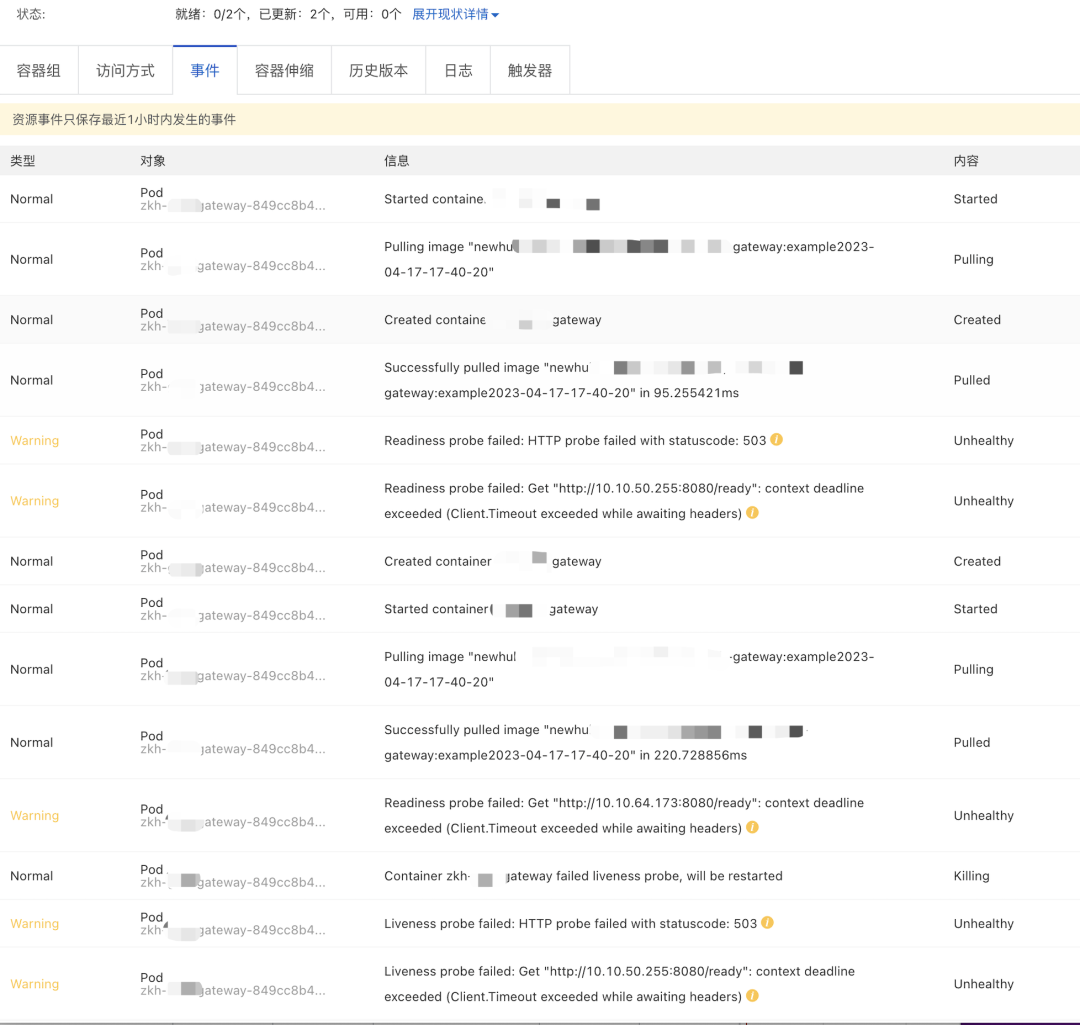
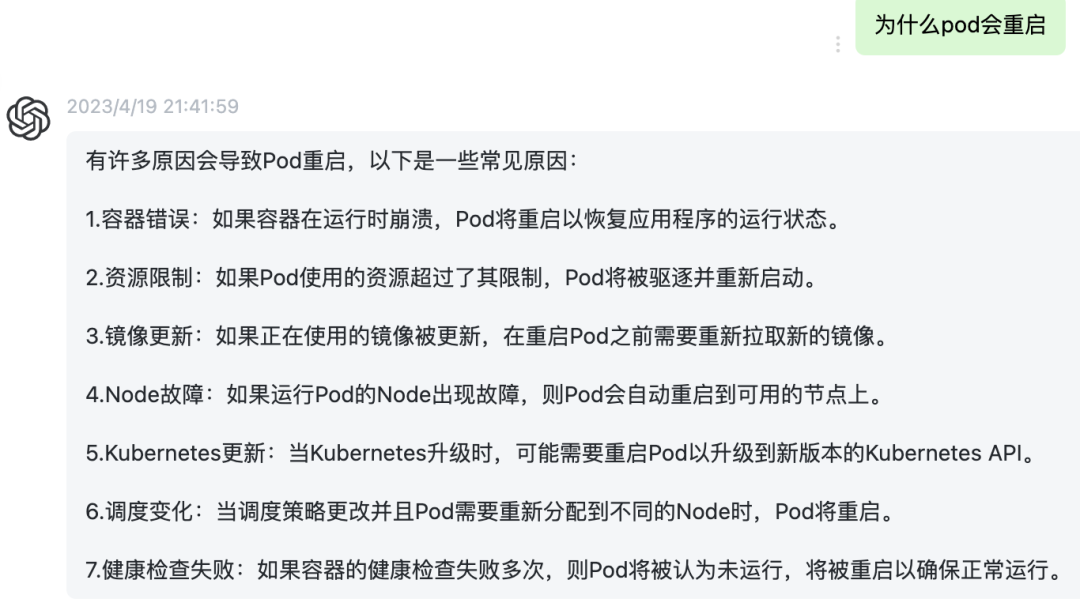
Pod为什么重启了?
健康检查为什么失败了?
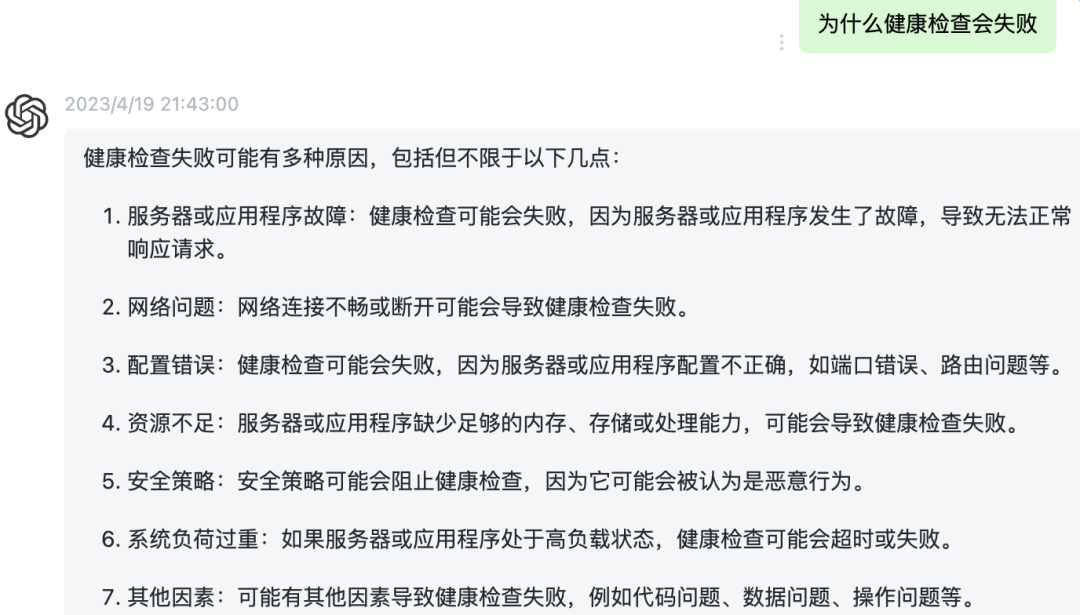
根据异常期间的数据和排查问题的经验,Pod重启是因为没有通过健康检查。
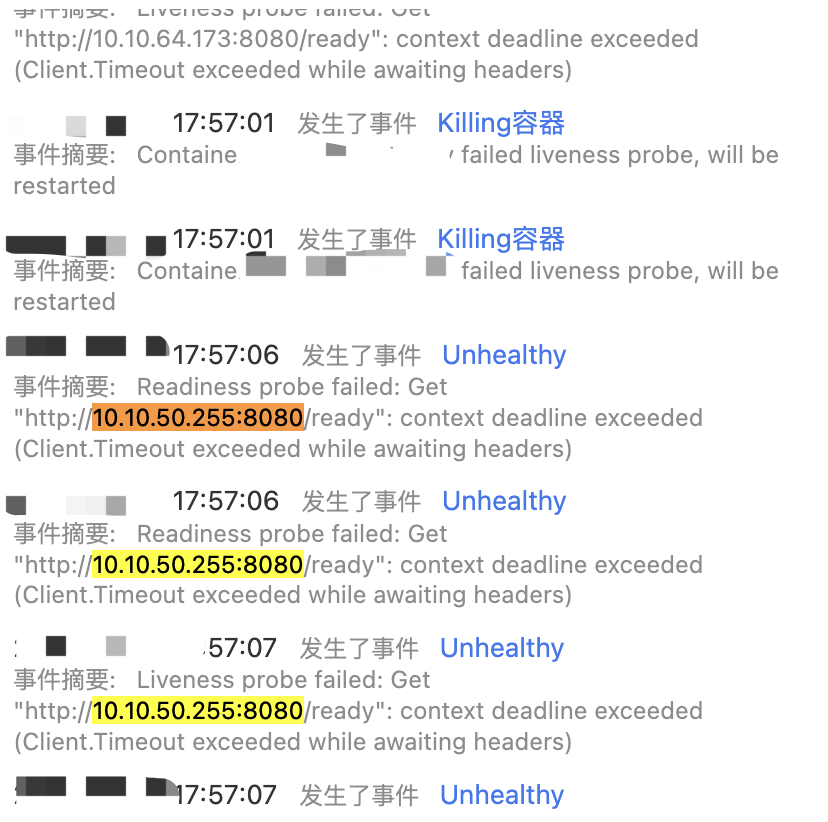
什么是健康检查?
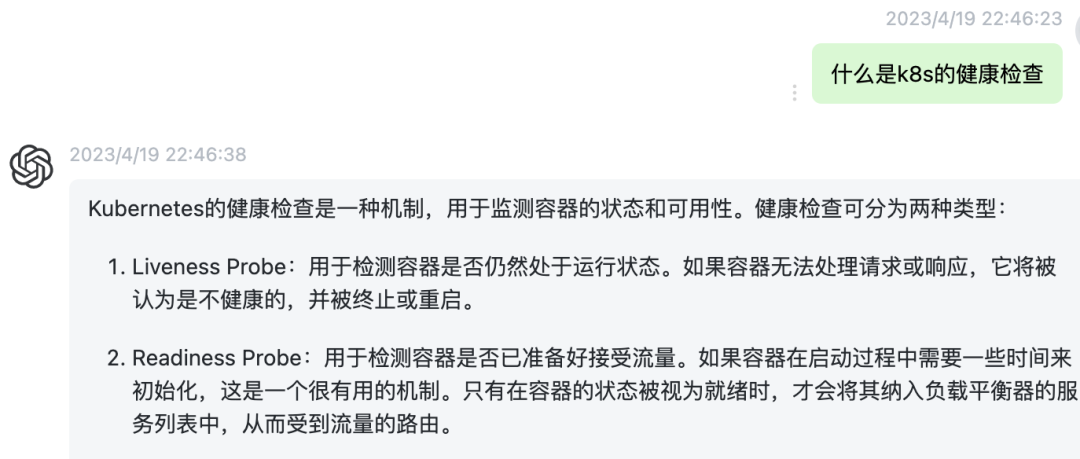
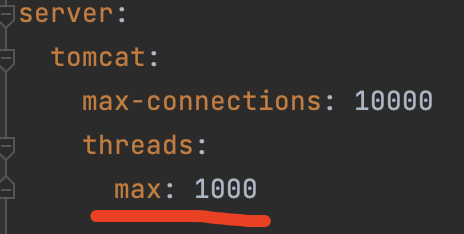
当前配置健康检查的规则:

重点:超过1s没有响应就判定健康检查失败,连接失败3次就判定服务不可用
为什么用于健康检查的/ready接口会没有及时响应?

小结:梳理健康检查失败的原因及此类问题的排查方向
本次主要是复盘应用方面的问题及改进事项,ChatGTP给的解释再结合排查问题的经验,
本次导致/ready接口没有响应的原因有两个大的排查方向:
1、查看异常期间JVM的GC情况
2、查看并发的请求量是否超过Tomcat的处理能力。重点是请求量、慢接口数量
健康检查用的接口/ready实现如下:
@GetMapping("/ready")
public String ready() {
return "";
}如果不是,建议改一下。
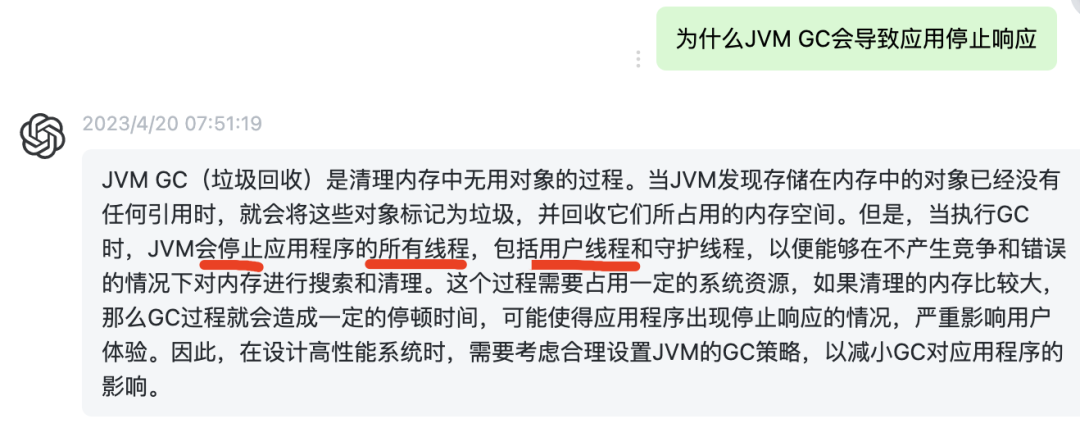
为什么JVM GC会导致/ready接口无法及时响应?
为什么请求量过大会导致/ready接口无法及时响应?
请求量增加且慢调用也增加,请求数大于tomcat的处理能力,提供给k8s进行健康检查用的/ready接口,会一直阻塞在tomcat的等待队列中没有办法响应给调用方。
为什么最高峰不就2000多请求,为啥Pod就挂了呢?
这个问题实际是:为啥请求数超过2000,K8s健康检查用的/ready接口为啥就超时了?

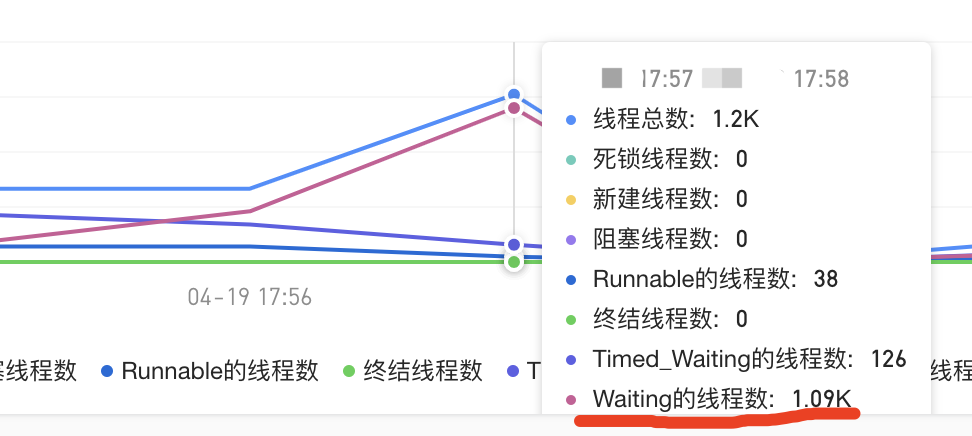
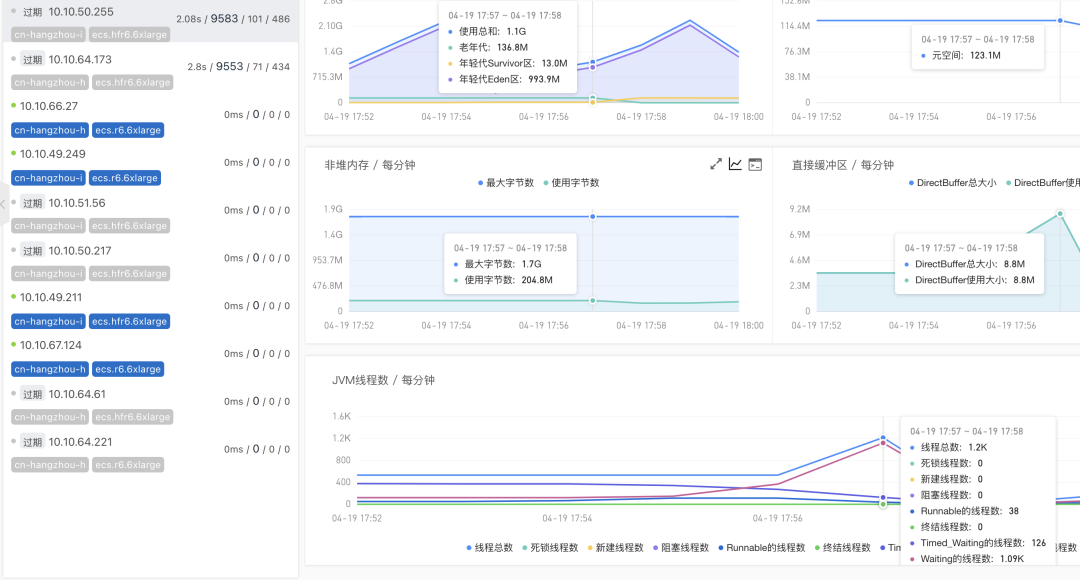
Waiting的线程数已经大于tomcat的最大线程1000了。
当使用接口/ready进行K8s健康检查时,如果Tomcat中没有可用的线程来处理新的请求,那么这些请求将会被阻塞,并放置在等待队列中等待处理。如果任务过多,而处理线程一直忙碌不空闲,那么 接口响应时间会超过1s,这会导致健康检查失败 。如果健康检查连续失败3次,K8s将判定该Pod不可用,并重启该Pod。
在JVM中,除了Tomcat自身的线程池,项目依赖的其它框架也会引入一些线程池。
流量增大且慢调用也增大,健康检查很容易就失败了:

总结
K8s中pod重启,应用层面的原因两个方面:
1、GC
2、并发量超过了Web容器的处理能力
第一象限的解决方案:
如果是GC异常显著:增加pod的内存和CPU,增大Pod中应用JVM的堆内存。
2022稳定性建设检查项说明书【事前篇】
如果是并发量增大且数据库无异常:增加POD数量
如果是慢接口量增大且数据库无异常:增加POD数量
如果期间数据库负载也上升,可以根据建议优化数据库,再增加POD
譬如:千丈之堤,以蝼蚁之穴溃:一个慢SQL引发的雪崩
有条件的话做个dump,方便后续的优化
经验分享:
如果是由于数据问题导致JVM FGC,增加POD数并不能解决问题,因为新起的POD也会因为FGC而重启。譬如:FullGC没及时处理,差点造成P0事故
第二象限:
优化慢SQL
优化慢接口
根据dump数据找到耗内存服务并优化
进行活动前,评估系统容量并更新相关服务的配置
架构升级,譬如一个业务点出现异常而影响整个服务
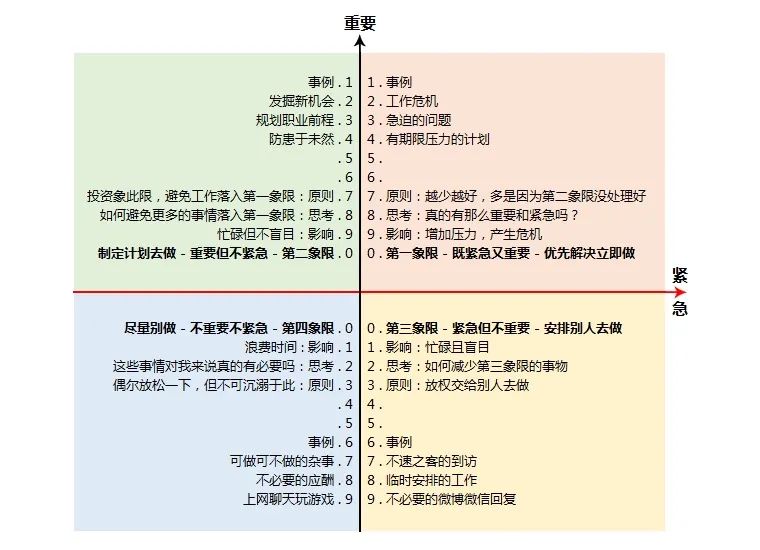
拉通第一象限、第二象限
灵魂6问:
上线前有没有做压测?
做了也没用。事后发现uat和线上数据量是不同的
慢SQL涉及到的表,uat是51823条,线上是1055816
说明:压测还是必要的,不过压测这件事涉及到的变量及准备工作较多,想做得有用,需要相关的知识储备和资源投入
为什么没有发现这个慢SQL?
uat环境数据量小且并发小,这个SQL并不慢。
uat执行一次
SQL模板:

SELECT
tiered_id,
count(tiered_id) AS count
FROM
tiered_detail
WHERE
tiered_id IN (
筛选的ID
)
GROUP BY
tiered_id从执行计划上看,也没有找到优化的空间。
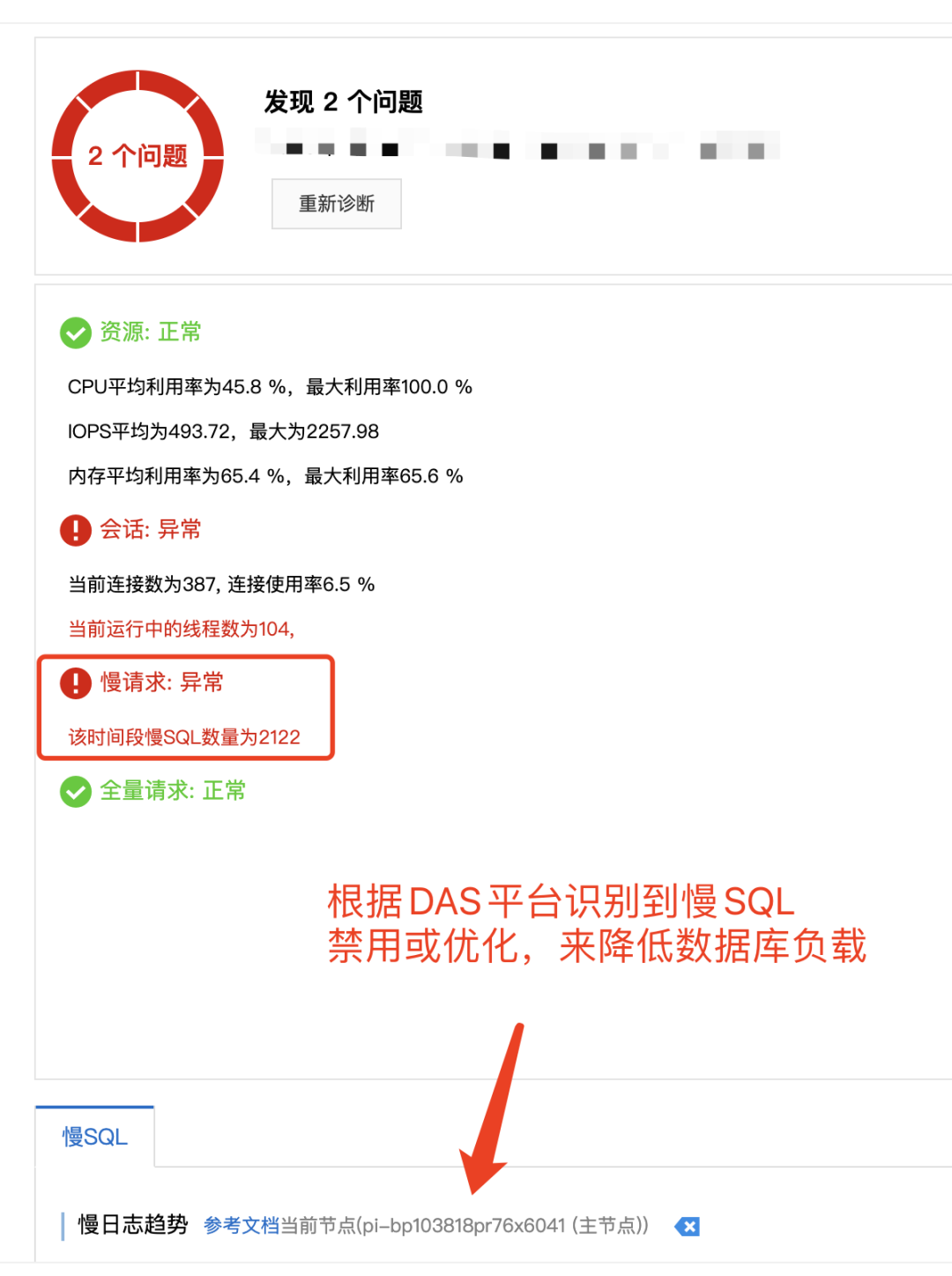
看看阿里DAS服务的表现:

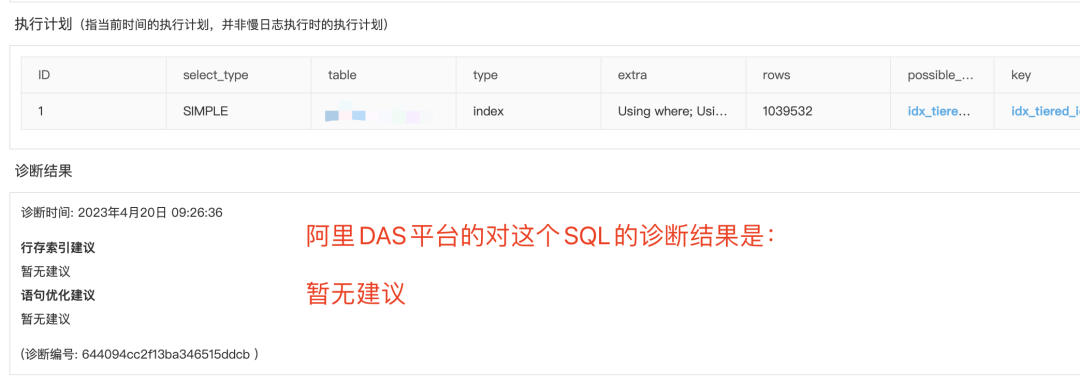
为什么没有做降级?
没有识别到有这么一个慢SQL。如果各个环节都做降级,就有很大的风险无法按时交付。
为什么没有做限流?
报告,没时间
为什么没有做熔断?
同上
上线营销活动,为什么没有针对性地处理好系统的“热点数据”?
没资源,干不了

参考
http://gk.link/a/10zjK


