
一个慢SQL引发的雪崩原创
每一次犯错都是成长的机会
-
服务出问题了?这个SQL能把MySQL打满?
-
错哪了?雪崩时,没有一片雪花是无辜的。
-
复盘。Anything that can go wrong will go wrong.
-
改进。升级架构,不能把鸡蛋放在一个篮子里
-
小结。稳定性无小事
服务出问题了?这个SQL能让MySQL CPU 100%?
早上8:40左右,地铁上,在跟小伙伴聊天,接到电话“是不是服务出问题了?”
第一个反应,不可能吧。昨天又没有上线,前天刚优化过,并且又没有收到告警。

这个电话刚挂,又有一个电话打来,说“XXX系统有异常,看看你这边有没有问题”。
可能有问题了!!
不一定是我们服务的问题,但要澄清一下,给出解决问题的方向。
刷群,看到一个报错信息:
xxx业务异常访问customers接口异常:status 503 reading ICustomerServiceApi#customers(CustomerReq); content: up
503 Service Unavailable
这种报错在上线发版时会出现,原因是由于请求被强行中断,即常说的“断流”。因为OpenApi服务最近一天没有任何改动,这种情况下,外部原因的可能性比较大,譬如网络问题。
打电话找到离电脑最近的同学,通报情况并开始排查。发现是数据库连接不够用了
### Error querying database. Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 60000, active 150, maxActive 150, creating 0, runningSqlCount 150 : SELECT
奇怪,前天才将应用中数据库连接池的maxActive从100升级到150。
出现这种错误,在严重耦合DB的服务面前,除了重启应用来重新初始化数据库连接池外,没有其它更好的办法了。
确定开始重新部署后,继续刷群,收集对锁定问题有帮忙的信息。
公司其它团队的小伙伴真是给力:
-
运维同学在确定不是发版原因造成服务不可用时,给pod扩容.相当于增加新可以连接池,这样可以提升服务的可用率,譬如有8个pod,如果有1个应用的数据库连接池被打满,那么有服务的整体可用性为87.5%,如果扩到10个Pod,那么可用性就提升到90%。 -
DBA同学在对慢SQL进行限流,并持续kill掉已经识别到的可能引发MySql CPU利用率过高的执行任务。 -
在将疑似有异常的接口发到群里后,相关的前台系统也将相应的流量熔断
应用重启完成后。服务恢复正常
pod:Pod是Kubernetes调度的最小单元。简单理解,一个Pod相当于一个逻辑主机,每个pod都有自己的ip地址,pod内的容器共享相同的ip和端口空间。在实际的使用中,一个应用的进程是运行在Pod的容器中。
生产环境,一个Pod只运行一个业务进程是最佳实践。
一个Pod可以包含一个或多个容器。容器是基于镜像创建的,即容器中的进程依赖于镜像中的文件,这里的文件包括进程运行所需要的可执行文件,依赖软件,库文件,配置文件等。镜像是文件, 容器是进程。
如何停止MySql上正在运行的任务
解决方案(类似于linux服务器杀进程):
查看最近所有sql进程 bash KILL [CONNECTION | QUERY] thread_id或select concat( ' KILL ' ,id, ' ; ' ) from information>_schema.processlist where user = ' root ' ;
+------------------------+
| concat('KILL ',id,';')
+------------------------+
| KILL 3101;
| KILL 2946;
+------------------------+
2 rows in set (0.00 sec)目前有数据库中间件把上面的过程封装起来,提供了更高效的工具。譬如将没有绑定变量的SQL作为模板,生成唯一的指纹,然后设置规则则,阻止指定指纹的SQL语句执行。这个机制只能处理新的异常SQL。历史的,只能手动kill了
错哪了?雪崩时,没有一片雪花是无辜的。
-
为什么没有告警
1.1 为什么慢SQL没有告警:有规则,但没有触发。更改后的规则:
1.2 为什么周例会上没有通报这个系统有慢SQL
这个数据库有3个系统在用。然后就不知道写谁,然后就... -
为什么会有503
发现Pod重启过一次。
重启时,相关调用会被中断,即“断流”,调用方会收到503 -
应用的数据库连接池为什么会被打满
MySql CPU利用率100%,会影响执行Sql的TPS/QPS。
在流量不变的情况下,数据库连接池中的连接,申请一个占用5分钟,那么在随后的1s内,如果新请求数大于连接池中的最大值150,那么数据库池就被打满了。
后面来进来的请求,等待指定的时间仍然没有获取到连接时,就报错。 -
为什么MySql的CPU利用率会100%
这个慢SQL之前已经识别到,并排期准备改了。
关联的接口流量并不大,不可能。即使流量变大了,涉及到的表数据量并不大,即使全表扫描,也不可能导致MySql cpu 100%吧!
后来翻了代码,这个慢SQL是2018年的一位同学写的。老的没问题,是因为的老的是高配
4.1 流量是否变大
变大了。
有一个前台系统将流量切过来了。12.14 19:00切过来,19:00到23:00共1484次请求,12.13号同时段共2次请求
12.15 8:10到8:40共3510次请求,12.13号同时段共1次请求
迁移原因:记一次中台建设的过程及心得

4.2 扫描的数据行多不多
不多。SQL执行的情况如下:

4.3 为什么CPU会100%
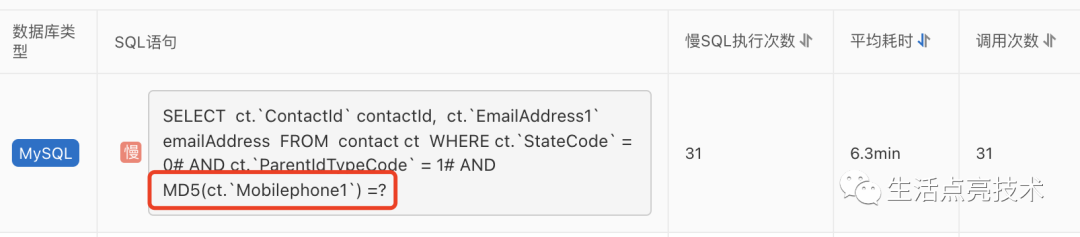
没有走索引是一个待优化点,真正的问题是:当前的数据库实例的cpu对md5函数比较敏感,抽一个慢Sql连接执行3次,CPU利用率直接上升到6.57%:
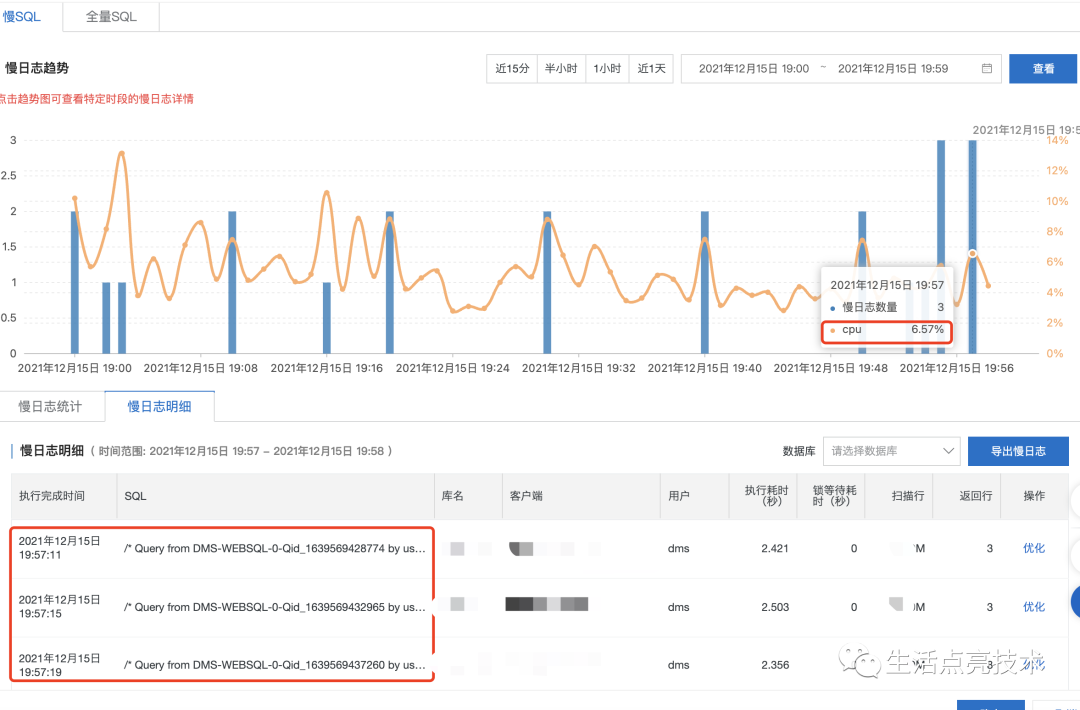
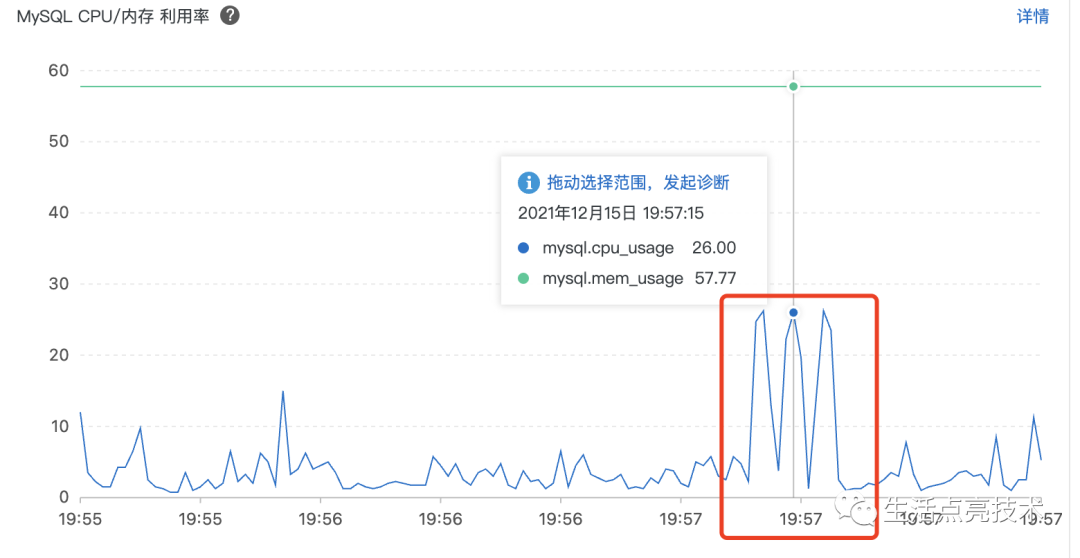
4.4 12.14 19:00-12.15 08:00期间CPU为什么没有100%
19:50已经出现尖刺了,期间出现瞬时峰值100%: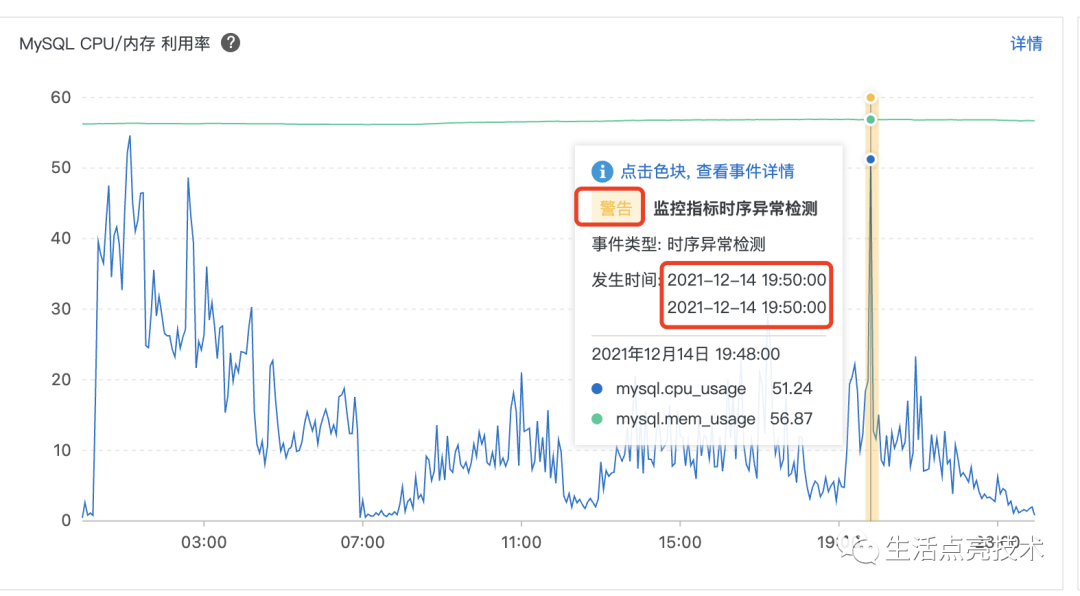
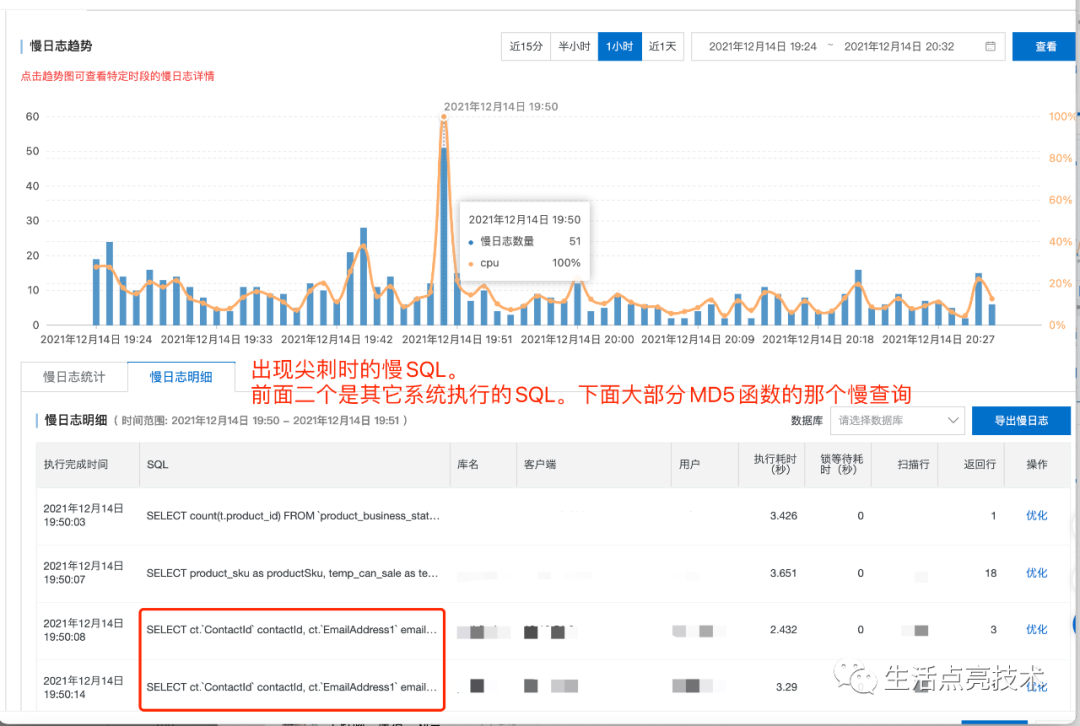
4.5 为什么早上8点期间有持续的100%
流量持续增多。新接入流量的并发数增加了2倍,并且持续一段时间。
12.14 19:50 出现尖刺时的并发数是4。当然也不能忽视前面几秒积累的慢查询:
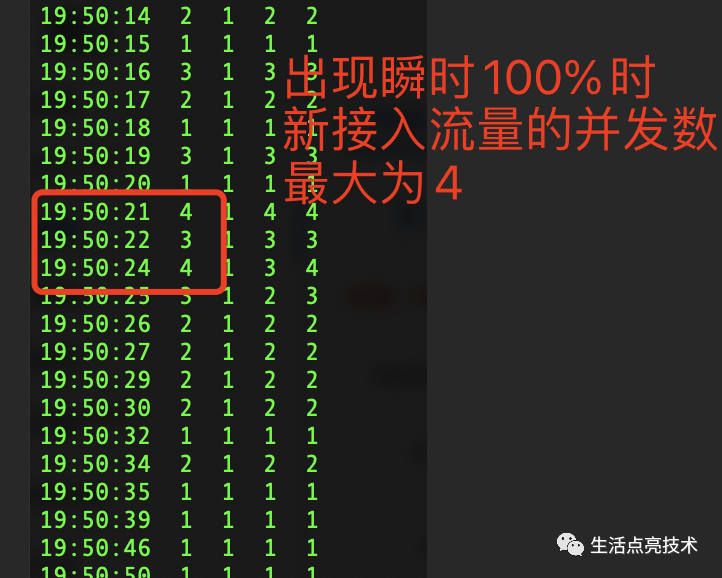
12.15 08:22左右 MySql cpu利用率100%时的新增流量的并发最大值为8。当然加上其它两个系统在这个时间点也是使用高峰期,还有之前积累的慢查询:
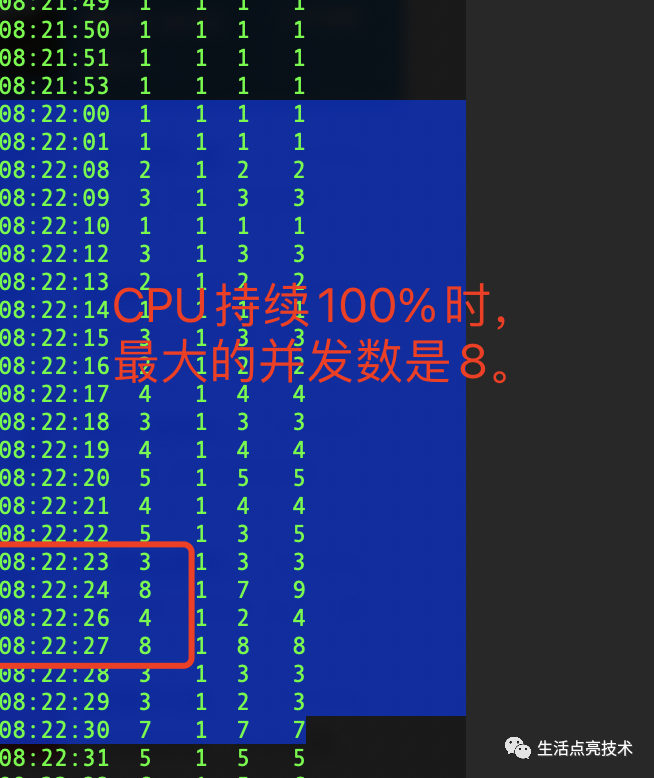
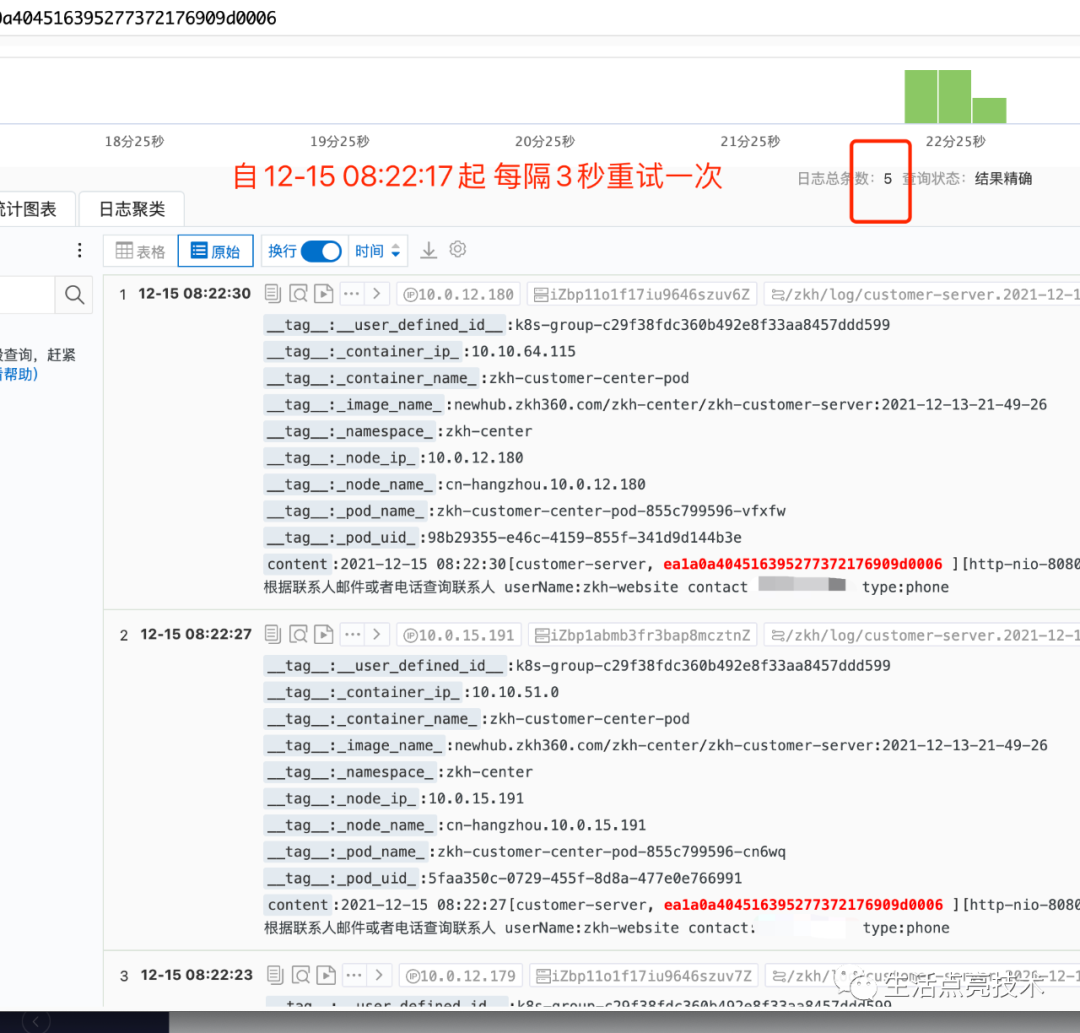
4.6 为什么相同的调用频繁出现
调用方进行了超时重试
复盘。Anything that can go wrong will go wrong.
存在一个消耗CPU资源且有一个关键字段不能走索引的慢SQL。因为之前流量比较低,消耗的资源不足以让MySql CPU持续100%。
12.14 19:00 前台一个系统将流量切过来,晚上用的人较少,其它两个系统用的人也少,虽在12.14 19:50出现瞬时100%,但MySql整体稳定。
12.15 08:22开始新切入的流量从1增加到8,并持续稳定在并发数8左右。使用这个数据库的其它两个系统,也有慢SQL进来,导致慢SQL执行更加慢。还有一个不能忽视:前台请求时的超时重试。如果一个接口耗时超过的一定的时间,譬如3s,调用端就会再次发起相同的请求。
这种场景,相当于把流量放大几倍,会进一步加剧服务提供方的资源紧张的情况。
改进。升级架构,不能把鸡蛋放在一个篮子里
短期:
-
再出现此类问题,要借助K8s高效的 删除Pod 机制和扩容机制,快速删除已经停止服务的Pod,并扩容。本次是通过云效的流水线部署,耗时12分22秒,有点慢。 -
解决眼前的问题:fix这个坚挺了三年的技术债 -
增加数据库池的maxActive,从150调整到1000 -
完善监控
3.1 增加数据库cpu利用率的监控告警
3.2 完善服务器的监控告警 -
fix项目中其它慢SQL -
增加限流、限流特性。 -
数据库层引入Kill 慢SQL规则。规则:如果一个SQL执行时间超过1min,则直接Kill掉。
长期:
-
升级系统架构。使用合适的介质存放合适的数据。譬如根据id查信息的接口,就可以引入Redis来提升QPS,也增加了系统的可用性,当MySql出现异常时,这个接口仍然是可用的。
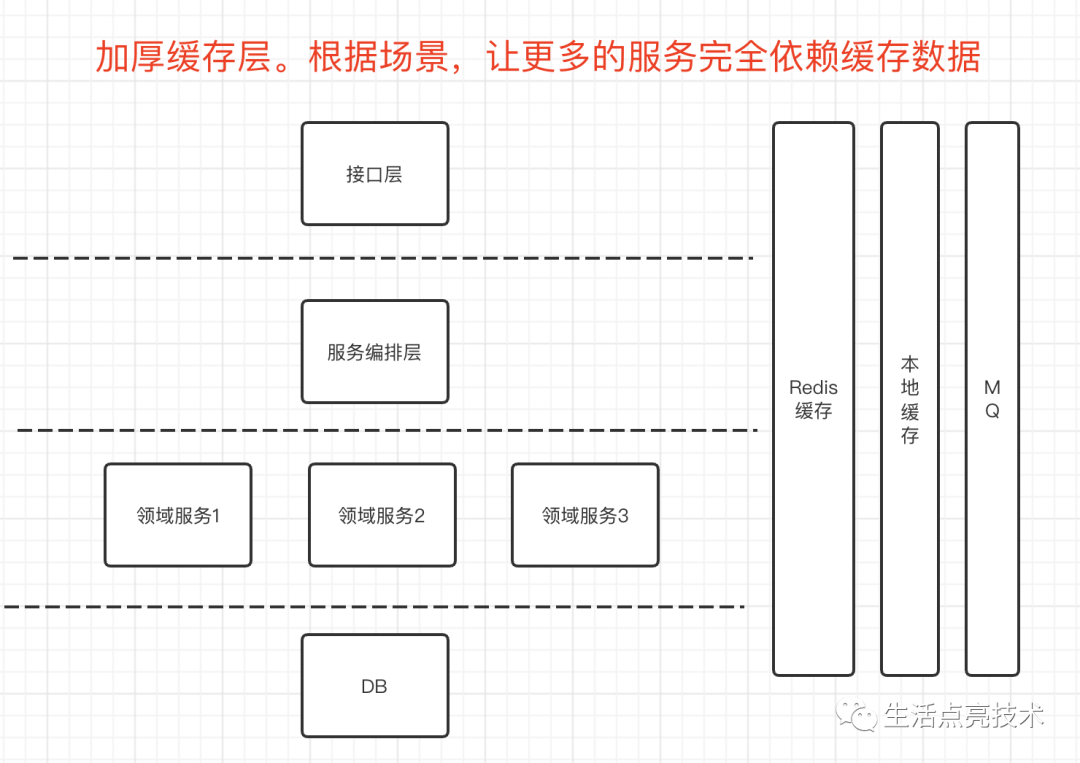
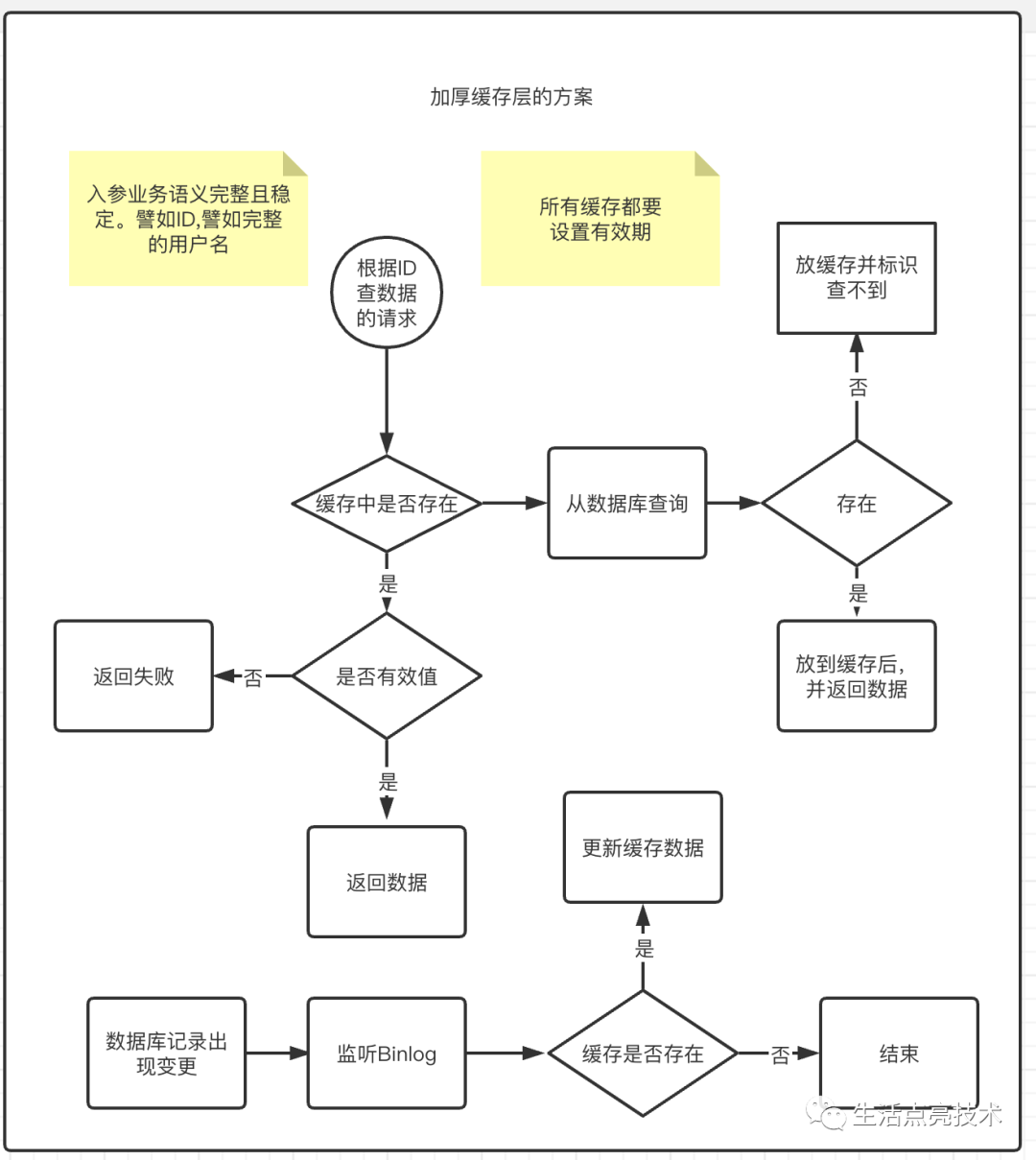
-
优化整个链路的调用效率。看到前台系统有部分请求存在调用浪费的情况,譬如一个完整的请求过程中会使用相同的参数多次调用。如果把第一次调用返回的结果在JVM内传给后面的逻辑,一方面会提升QPS,节省服务器资源,也可以降低服务提供方的压力。 -
优化调用端调接口时超时重试的频次、触发重试的阈值。 -
增加值班机制。产研的上班时间是9点,业务同学上班的时间是8:30。团队同学轮流保持业务同学的考勤时间一致 -
持续Review代码机制。从一点一滴做起
小结。以不变应万变
系统稳定性无小事,一出问题就是大事。


