
Java界的性能优化高手原创

Java代码性能优化谁最在行,那一定是每天从事优化工作的人,目前来看就是Java编译器了。我们本章主要了解下这个性能优化高手平时是怎么工作的,怎么帮我们提高代码效率,以及讨论一下代码效率方面的问题。读完本文,你可以了解到:
1.javac做了什么优化
2.Java后端编译器的发展史
3.JIT是如何工作的
4.效率与质量的平衡
1、编译期优化
1.1、类型擦除
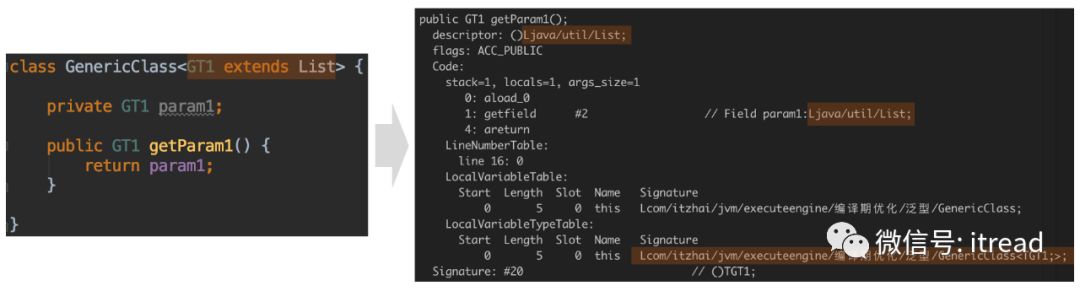
List ,所以擦除后,操作的param1字段变成了 List 类型。GenericClass 类的实例由于并没有指定泛型的具体类型,所以最终Signature中的还是 GenericClass<TGT1;> 类型。1.2、自动装箱、拆箱
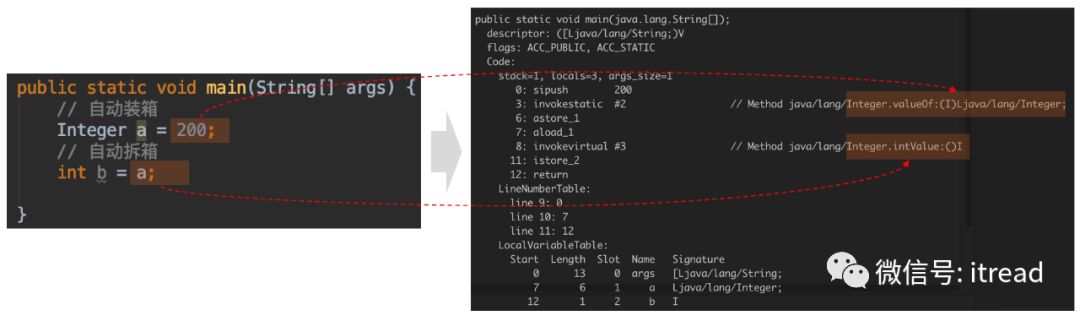
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
Integer i1 = 10; Integer i2 = 10; System.out.println(i1 == i2); // true Integer i3 = 200; Integer i4 = 200; System.out.println(i3 == i4); // false int i5 = 200; System.out.println(i4 == i5); // true Double d1 = 1.0; Double d2 = 1.0; System.out.println(d1 == d2); // false Short s1 = 126; Short s2 = 126; System.out.println(s1 == s2); // true Character c1 = 127; Character c2 = 127; System.out.println(c1 == c2); // true Long l1 = 10L; Long l2 = 10L; System.out.println(l1 == l2); // true System.out.println(i1.equals(l1)); // false } |
-
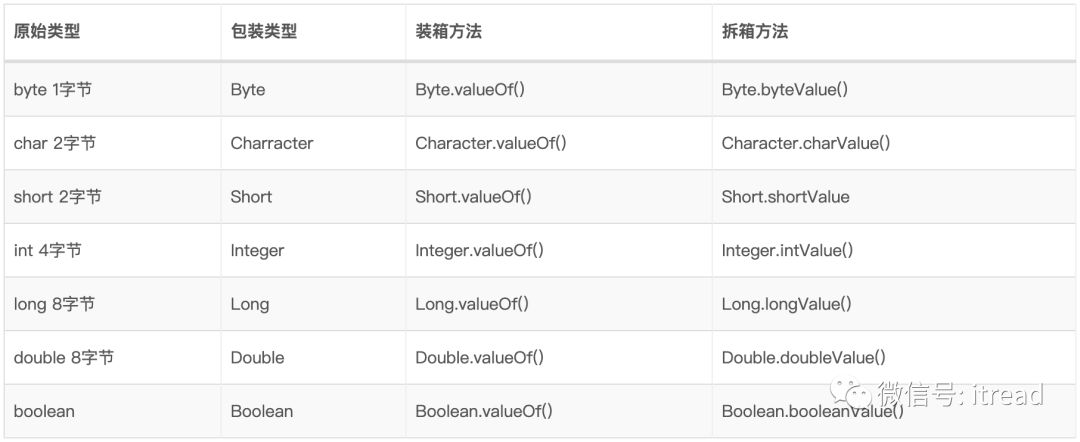
原始类型与包装类型进行
==+-*/等运算时,会进行自动拆箱,对基础数据类型进行运算; -
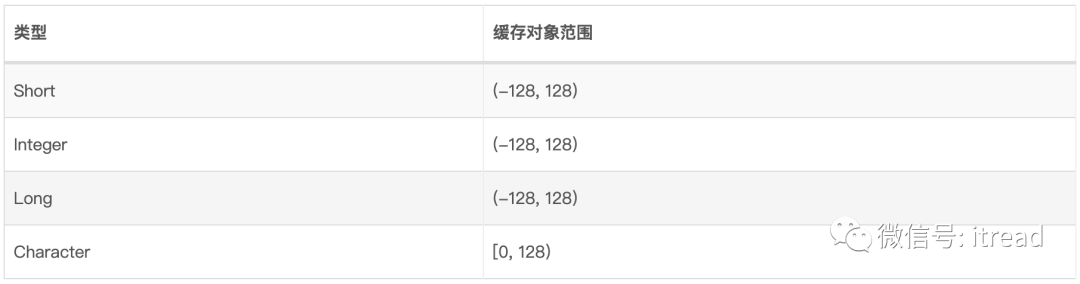
相同的包装类型比较,会把原始类型自动装箱为包装类型比较,注意部分包装类型部分范围对象会缓存到一个cache数组中,每次从数组中取值,如下表所示:
-
( 纠正:(-128需改为[-128 )不同类型比较,只能使用equals方法,该方法会先比较类型信息,然后才是比较具体的值。
1.3、遍历循环和可变参数
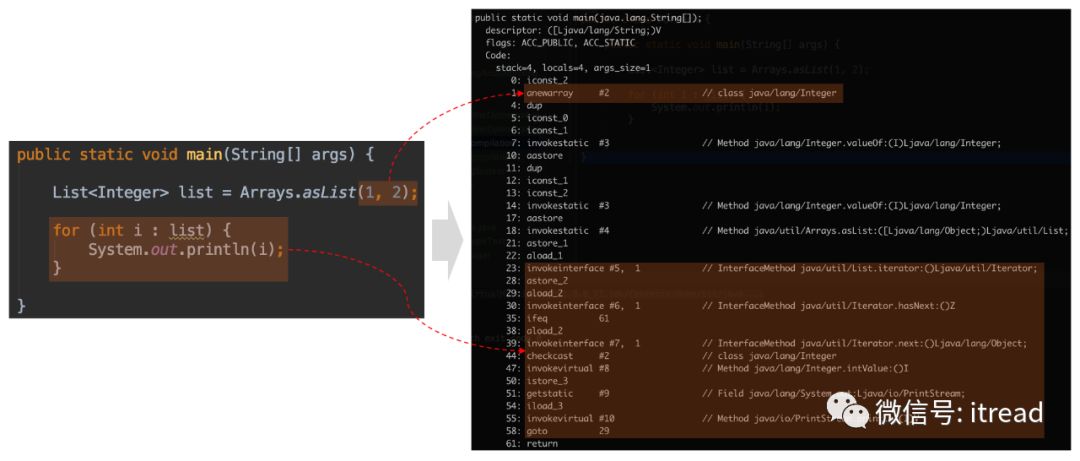
可变参数 最终变为了创建一个固定大小的数组。遍历循环变 成了 迭代器迭 代,所以使用遍历循环语法的类需要实现 Iterable 接口。1.4、条件编译
2、运行期优化
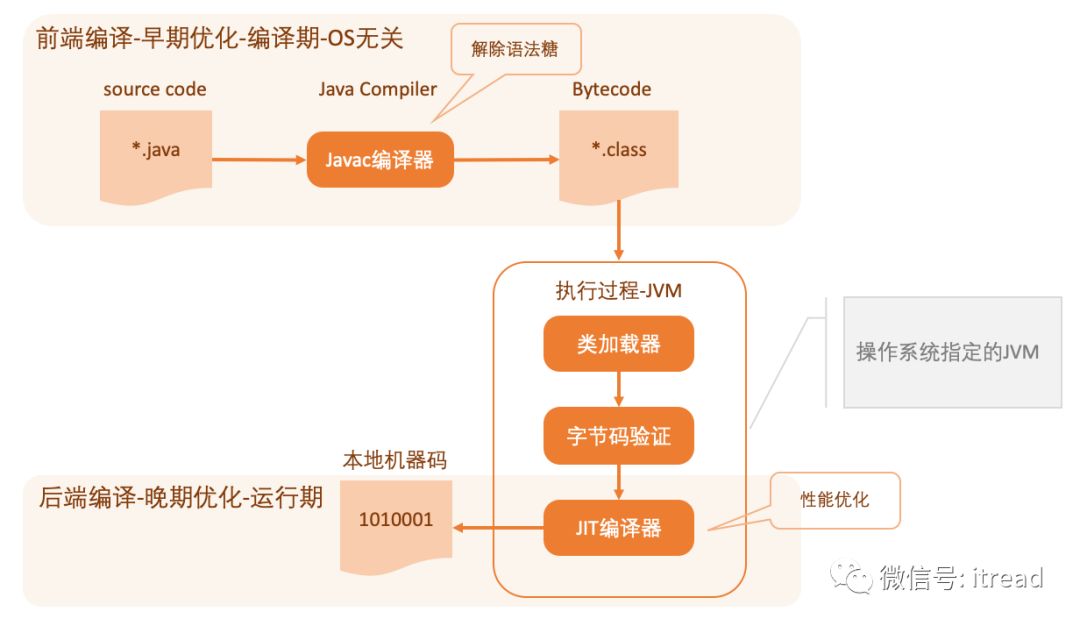
2.1、解释器(Interperter)
2.2、JIT
HotSpot JVM中HotSpot的由来:来自于它用于编译代码的方法,在一般的程序中,有些代码会频繁执行,而这部分代码是影响程序性能的关键代码,这些代码称为热点,代码执行的越频繁,就越是热点代码。
2.2.1、C1编译器(Client Compiler)
2.2.2、C2编译器(Server Compiler)
一般在客户端程序,我们为了达到更快的启动程序,一般会使用C1编译器,而在服务端,为了从长远考虑提供更好的性能,一般会使用C2编译器。
2.3、JVM进化史
2.3.1、早期JVM
The Java HotSpotTM Server Compiler#1. Introduction
https://www.usenix.org/legacy/events/jvm01/full_papers/paleczny/paleczny.pdf

2.3.2、支持JIT的JVM
%JAVA_HOME%/jre/bin 下面有 server 和 client 文件夹,里面分别对应是C2和C1的实现。一次只能使用其中一个编译器,通过 -client 和 -server 参数指定。这个时候引入了三种编译模式:-
解释执行:该模式下表示全部代码均是解释执行,不做任何JIT编译,如果要开启这种模式,请使用-Xint参数; -
编译执行:该模式下不管是否热点代码,对所有的函数,都进行编译执行,如果要开启这种模式,请使用-Xcomp参数; -
混合执行:JVM默认的执行模式,部分函数会解释执行,部分会编译执行。如果函数调用频率高,被反复使用,就会认为是热点代码,该函数就会被编译执行。
https://www.oracle.com/technetwork/java/javase/tech/3198-d1-150056.pdf ,根据这份PPT,我们梳理下引入了JIT之后的JVM结构图:
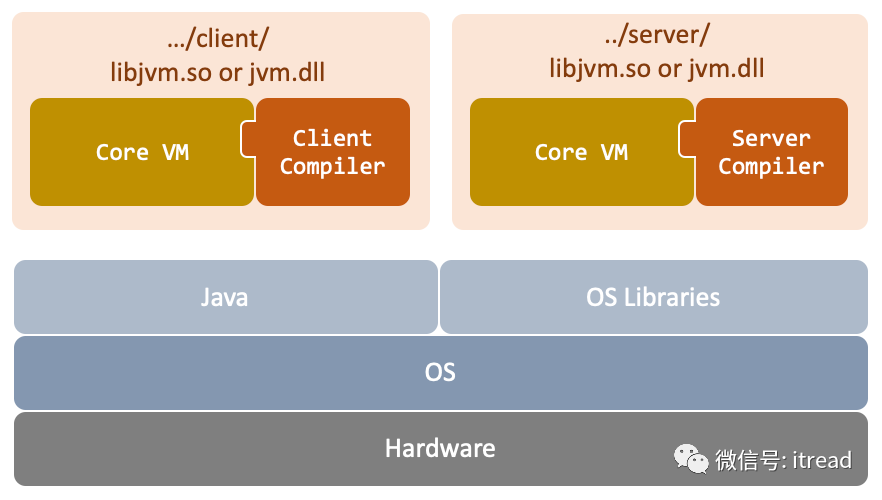
java可执行文件只是一个执行外壳,它会装载jvm.dll(dll为windows下面,Linux下面为so文件,Mac下面为dylib文件)文件,这个动态链接库才是JVM的关键实现。 注意:不同版本的JDK,jvm.so文件目录可能会有所不同。比如Mac系统下 1.8.0_71版本的JDK的server目录:/Contents/Home/jre/lib/server
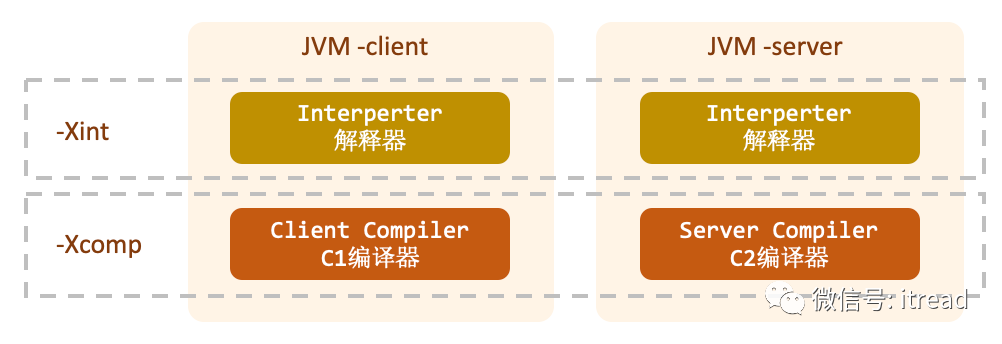
-client 和 -server 参数指定运行模式之后,会选择对应的编译器。为什么我电脑里面的-client参数不生效?
-
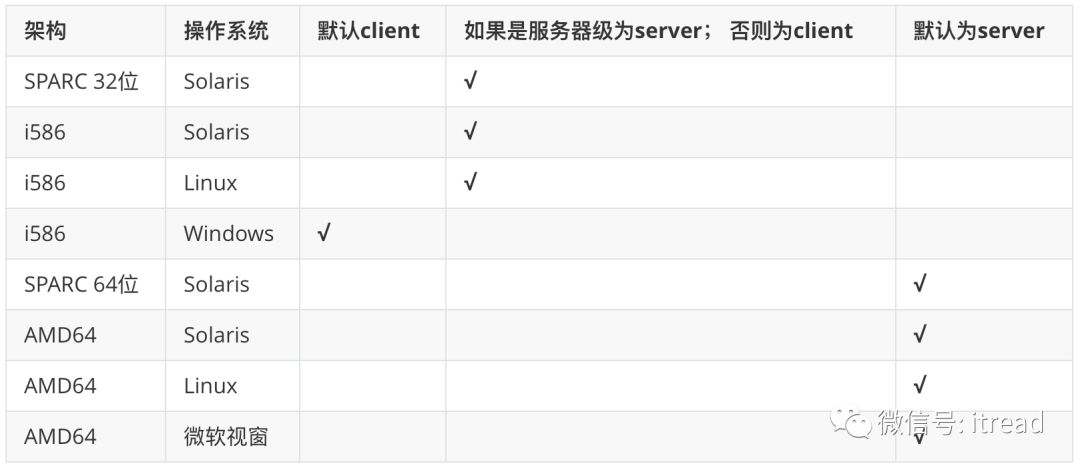
32位客户端版本(
-client) -
32位服务器版本(
-server) -
64位服务器版本(
-d64)
-client 模式就不生效了。可以看看安装目录下面是否有client文件夹,比如MacOS下面64位1.8.0_71JDK,可以发现只有server文件夹:➜ lib ll | grep -E ‘(server|client)’
drwxrwxr-x 5 root wheel 160 Dec 23 2015 server
https://howtodoinjava.com/java/basics/difference-between-32-bit-java-vs-64-bit-java/
2.3.3、支持分层编译的JVM
分层编译 。XX:-TieredCompilation 。如果要使用分层编译,请务必使用Server模式,Client模式不支持,会自动忽略掉。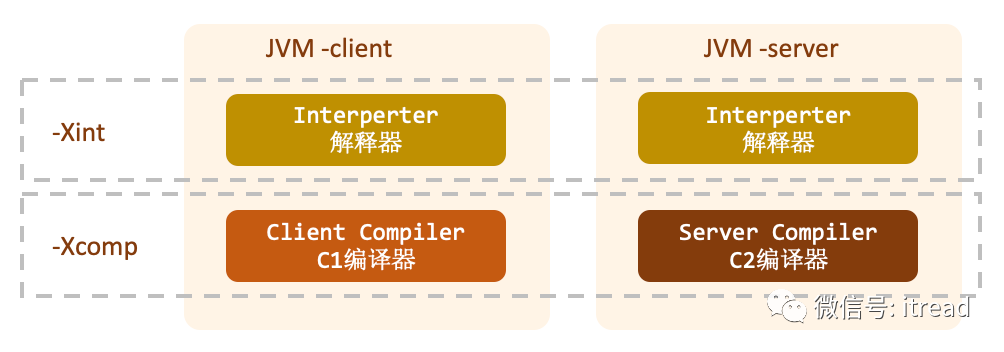
分层编译诞生的小插曲:其实Java 7早期版本中就提供了分层编译的测试版本,但是发现存在许多技术问题,特别是原本两个编译器是在不同体型结构中的,要弄到一起配合工作难度可想而知,该版本性能不佳。不过从Java 7u4版本中得到了解决。这个时候分层编译已经能够为应用程序提供最佳的性能了。
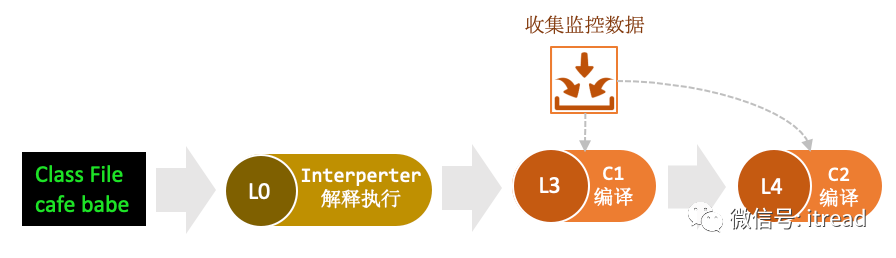
分层编译运行机制

-
方法太简单了:如果要编译的方法很简单,那么仅在1级别下进行编译,因为C2不会使其更快,这个时候进行大量概要分析找出如何使用代码是没有意义的,反而在1级别下面运行更快;
-
C2繁忙中:如果某个时候,C2编译器队列已满,那么会把代码转到2级别进行编译(简单概要分析,可以更快速编译该方法),一段时间后在3级别下编译代码;最后,C2不繁忙的时候,才由C2再次编译;
-
C1繁忙中,但是C2空闲:如果C1队列满了,但是C2未满,则可以有解释器概要分析(0级别),然后直接进入C2。
编译器队列不是标注的FIFO,而是优先级队列。
2.4、何时会逆向优化
2.5、何时触发编译
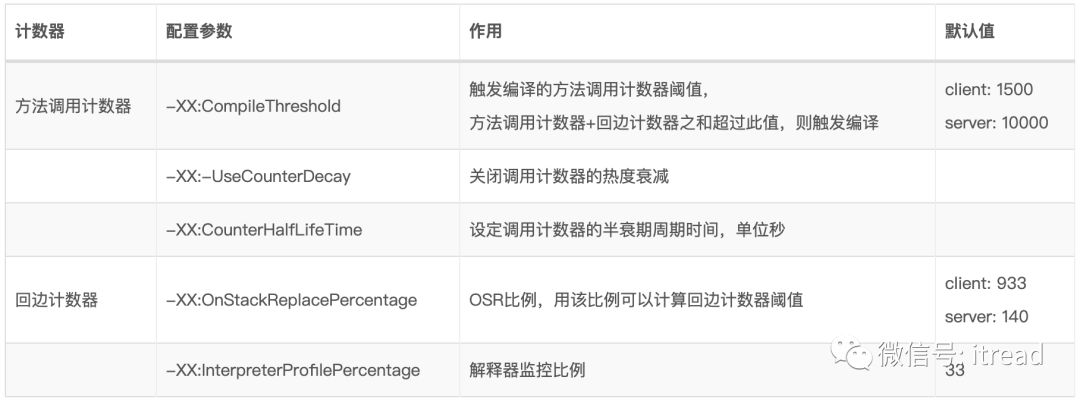
方法调用计数器 + 回边计数器 > 方法调用计数器阈值(CompileThreshold,见 15-1 计数器相关参数 表格)
方法调用计数器 + 回边计数器 > 回边计数器阈值
2.5.1、方法调用计数器
方法计数器 主要用于统计方法调用次数2.5.2、回边计数器
https://www.oracle.com/technetwork/java/javase/tech/3198-d1-150056.pdf):
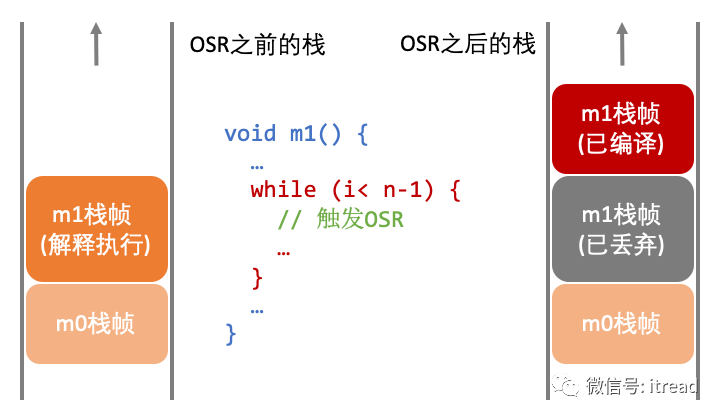
边计数器 统计一个方法中执行循环体代码的次数。当一个循环执行到某位,或者执行到了continue语句的时候,就会触发一个回边指令,这个时候回边计数器值就+1。-
client模式
CompileThreshold * (OnStackReplacePercentage / 100)
-
server模式
CompileThreshold * ((OnStackReplacePercentage - InterpreterProfilePercentage)/100)
-
-XX:-TieredCompilation:
-
禁用中间编译层(1, 2, 3),使得方法要么解释执行,要么进行最大级别的优化(C2);
-
副作用是该参数会更改编译器线程数量,编译策略以及默认代码缓存大小。如果禁用了TieredCompilation:
-
编译器线程数将减少
-
将选择简单的编译策略(基于方法调用和后端计数器),而不是高级的编译策略;
-
默认的保留代码缓存大小将减小5倍
-
如果要禁用C2编译器,只保留C1编译器,请设置-XX:TieredStopAtLevel=1
-
要禁用所有的JIT编译器,只使用解释器运行程序,请使用 -Xint
-
What exactly does -XX:-TieredCompilation do?
https://stackoverflow.com/questions/38721235/what-exactly-does-xx-tieredcompilation-do -
-XX:+PrintCompilation
-
打印即时编译信息,具体输出格式说明可以参考:JDK5u22_client.log
https://gist.github.com/rednaxelafx/1165804或 Working with the JIT Compiler#Inspecting the Compilation Process
https://www.oreilly.com/library/view/java-performance-the/9781449363512/ch04.html -
格式:timestamp compilation_id attributes (tiered_level) method_name size deopt
2.5.3、触发即时编译优化的例子
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
static int addOne(int a) { return a + 1; } public static long calcSum() { long sum = 0; sum += addOne(10); return sum; } public static void main(String[] args) { for (int i = 0; i < 9; i++) { calcSum(); } } } |
-server 启用Server模式
-XX:-TieredCompilation 不启用分层编译
-XX:+PrintCompilation 打印编译日志
-XX:+UnlockDiagnosticVMOptions
-XX:+PrintInlining 打印内联优化信息
-XX:-BackgroundCompilation 不启用后台编译,为了等待编译完成,打印编译日志,然后继续执行
-XX:CompileThreshold=10 触发编译的方法调用计数器阈值
-XX:-UseCounterDecay
|
2 3 |
@ 5 com.itzhai.jvm.executeengine.字节码执行引擎.MonitorCompilation1::addOne (4 bytes) inline (hot) 7722 555 b com.itzhai.jvm.executeengine.字节码执行引擎.MonitorCompilation1::addOne (4 bytes) |
calcSum 方法被调用多次,其内部的 addOne 方法调用触发了内联优化。3、一些关于编译优化的问题
https://wiki.openjdk.java.net/display/HotSpot/PerformanceTacticIndex
3.1、我们能在 Switch 中使用 String 吗?
|
2 3 4 5 6 7 8 9 10 11 12 |
switch (test) { case "abc": System.out.println("case one"); break; case "erw": System.out.println("case two"); break; case "adf": System.out.println("case three"); break; } |
|
2 3 4 5 6 7 |
66: lookupswitch { // 3 96354: 100 96419: 132 100714: 116 default: 145 } |
3.2、提炼更多函数不会影响性能?
https://www.itzhai.com/refactoring/reorganizing-function.html#提炼函数),但是我们知道,每提炼多一个函数,就多一个方法调用,意味着性能更差,事实真的如此吗?
3.2.1、方法内联
|
2 3 4 5 6 7 8 9 10 11 12 13 14 |
System.out.println("inner test..."); } public static void execute() { for (int i = 0; i < 10000; i++) { // 调用多次,成为热点代码之后,该方法会被内联 innerTest(); } } public static void main(String[] args) { execute(); } |
|
2 3 |
@ 9 com.itzhai.jvm.executeengine.字节码执行引擎.MethodInlineOptimization::innerTest (9 bytes) inline (hot) !m @ 5 java.io.PrintStream::println (24 bytes) already compiled into a medium method |
innerTest 方法做了内联优化。3.2.2、虚方法的内联优化
-
如果检查到实际的实现目标版本只有一个,那么就会进行内联优化;后续如果发现执行到了一个新的实现目标版本,那么就取消内联优化,退回解释状态执行;
-
如果存在多个实现版本,JVM也会尝试做内联优化,主要是通过内存缓存实现的。先记录方法接收者缓存,并做内联优化,下次调用的方法接收者变了,那么就取消内联,通过虚方法表进行分派调用。
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
void startUp(); } public class Windows implements OperatingSystem { @Override public void startUp() { System.out.println("windows..."); } } public class Linux implements OperatingSystem { @Override public void startUp() { System.out.println("linux..."); } } public class MethodInlineOptimization2 { static void innerTest(OperatingSystem sys) { // 这里是动态分派,只有运行的时候,才知道具体要调用什么方法 sys.startUp(); } static void execute() { OperatingSystem sys = new Windows(); for (int i = 0; i < 10000; i++) { // 调用多次,成为热点代码之后,该方法会被内联 innerTest(sys); } sys = new Linux(); for (int i = 0; i < 10000; i++) { // 调用多次,成为热点代码之后,该方法会被内联 innerTest(sys); } } public static void main(String[] args) { execute(); } } |
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
windows... 8131 617 % b com.itzhai.jvm.executeengine.字节码执行引擎.MethodInlineOptimization2::execute @ 10 (55 bytes) @ 18 com.itzhai.jvm.executeengine.字节码执行引擎.MethodInlineOptimization2::innerTest (7 bytes) inline (hot) @ 1 com.itzhai.jvm.executeengine.字节码执行引擎.Windows::startUp (9 bytes) already compiled into a medium method ... windows... // 这里准备执行第二个循环的时候,因为准备加载OperatingSystem的第二个自来Linux,会导致重写内联,所以这里有一个 made not entrant linux... 8244 610 com.itzhai.jvm.executeengine.字节码执行引擎.MethodInlineOptimization2::innerTest (7 bytes) made not entrant linux... linux... // 这里重新对innerTest方法做了内联优化,内联了Linux::startUp 8252 623 % b com.itzhai.jvm.executeengine.字节码执行引擎.MethodInlineOptimization2::execute @ 37 (55 bytes) @ 45 com.itzhai.jvm.executeengine.字节码执行引擎.MethodInlineOptimization2::innerTest (7 bytes) inline (hot) @ 1 com.itzhai.jvm.executeengine.字节码执行引擎.Linux::startUp (9 bytes) inline (hot) !m @ 5 java.io.PrintStream::println (24 bytes) already compiled into a medium method |
关于 made not entrant,参考: PrintCompilation JVM flag
https://blog.joda.org/2011/08/printcompilation-jvm-flag.html
-
保证方法尽可能简单,单一职责;为下一步抽象优化做好准备;
-
抽取的方法越小,越容易被JVM做内联优化。
3.3、不用的Java对象究竟需不需要设置为null
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public static void main(String[] args) { for (int i=0; i<10; i++) { test(); } test(); } private static void test() { { byte[] placeholder = new byte[10 * 1024 * 1024]; } // 离开了作用域,栈帧中 placeholder 对应的Slot并没有清掉,GC Roots会继续保持对它的关联 int a = 1; // 新加一个赋值操作,placeholder不再属于GC Roots,可以进行垃圾回收了 System.gc(); } } |
|
2 |
[Full GC (System.gc()) 726K->694K(125952K), 0.0253727 secs] |
int a = 1 注释掉:|
2 3 4 5 6 7 8 9 |
-verbose:gc 打印gc日志 -XX:-TieredCompilation 去掉分层编译,直接使用C2编译器 -XX:+PrintCompilation -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining -XX:-BackgroundCompilation -XX:CompileThreshold=10 方法调用计数器阈值 -XX:-UseCounterDecay |
其实并不用太依赖set null,而是通过严格的作用域来控制对象的回收,其他的交给编译器即可。
3.4、怎么写出更快的Java代码?
-
3.8、尽量指定方法的final修饰符:这个按照实际情况来即可,如果将来可能会扩展,则没必要限制太死,毕竟对于虚方法编译器也会做最大努力的内联优化,您首先要确保使用final是基于清晰的设计以及可读性考虑。
-
动态扩展:Java支持动态扩展,导致编译器即使做了优化,也可能会因为后期动态扩展导致执行目标发生变化,从而导致逆优化; -
动态安全:虚拟机需要频繁的进行动态检查,即使经过了JIT编译,也会消耗不少时间; -
虚方法:Java语言提倡使用面向对象编程,多态会导致很多的虚方法,不可避免的增加了编译器的优化难度。
References
https://stackoverflow.com/questions/38721235/what-exactly-does-xx-tieredcompilation-do
https://dzone.com/articles/client-server-and-tiered-compilation
https://www.oreilly.com/library/view/java-performance-the/9781449363512/ch04.html
https://www.usenix.org/legacy/events/jvm01/full_papers/paleczny/paleczny.pdf
https://www.iteye.com/blog/rednaxelafx-492667
https://www.oracle.com/technetwork/java/javase/tech/3198-d1-150056.pdf
https://www.oracle.com/technetwork/articles/java/vmoptions-jsp-140102.html
https://docs.oracle.com/javase/7/docs/technotes/guides/vm/server-class.html
https://howtodoinjava.com/java/basics/difference-between-32-bit-java-vs-64-bit-java/



