
刺激,线程池的一个BUG直接把CPU干到100%了。原创
你好呀,我是歪歪。
给大家分享一个关于 ScheduledExecutorService 线程池的 BUG 啊,这个 BUG 能直接把 CPU 给飚到 100%,希望大家永远踩不到。
但是,u1s1,一般来说也很难踩到。
到底咋回事呢,让我给你细细嗦嗦。
Demo
老规矩,按照惯例,先搞个 Demo 出来玩玩:
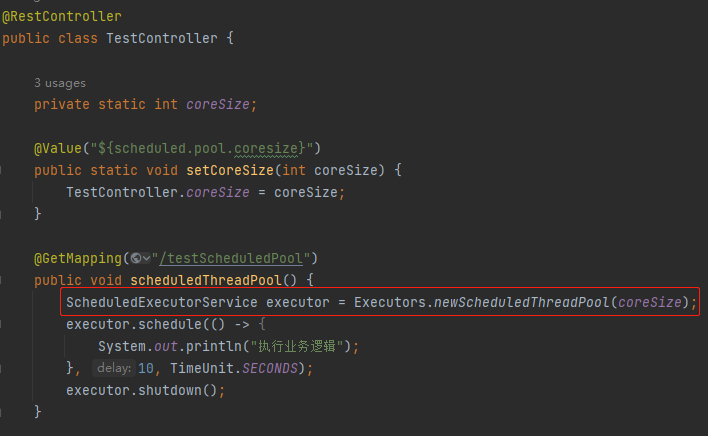
项目里面使用到了 ScheduledThreadPoolExecutor 线程池,该线程池对应的核心线程数放在配置文件里面,通过 @Value 注解来读取配置文件。
然后通过接口触发这个线程池里面的任务。
具体来说就是在上面的示例代码中,在调用 testScheduledPool 接口之后,程序会在 60 秒之后输出“执行业务逻辑”。
这个代码的逻辑还是非常简单清晰的,但是上面的代码有一个问题,不知道你看出来没有?

没看出来也没关系,我这里都是鼓励式教学的,不打击同学的积极性。
所以,别着急,我先给你跑起来,你瞅一眼立马就能看出问题是啥:
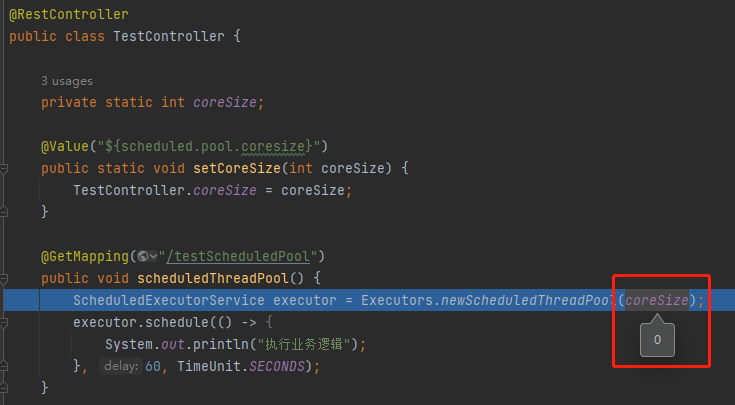
为什么 coreSize 是 0 呢,我们配置文件里面明明写的是 2 啊?
因为 setCoreSize 方法是 static 的,导致 @Value 注解失效。
如果去掉 static 那么就能正确读取到配置文件中的配置:
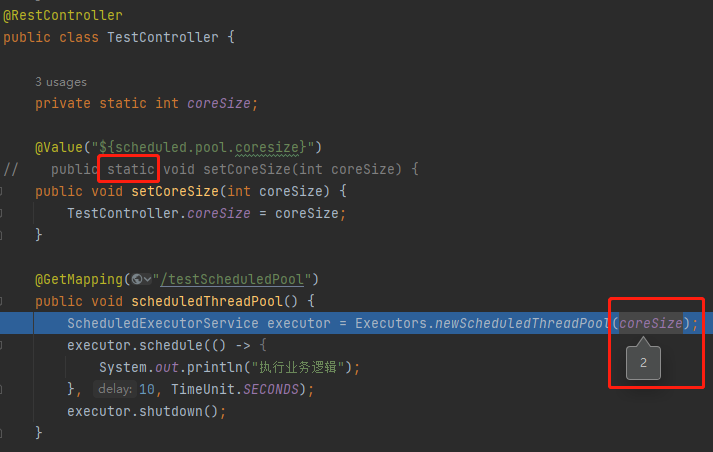
虽然这里面也大有学问,但是这并不是本文的重点,这只是一个引子,
为的是引出为什么会在项目里面出现下面这种 coreSize 等于 0 的奇怪的代码:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(0);
如果我直接给出上面的代码,一点有人说只有小(大)可(傻)爱(逼)才会这样写。
但是铺垫一个背景之后,就容易接受的多了。
你永远可以相信我的行文结构,老司开车稳得很,你放心。
好,经过前面的铺垫,其实我们的 Demo 能直接简化到这个样子:
public static void main(String[] args){
ScheduledExecutorService e = Executors.newScheduledThreadPool(0);
e.schedule(() -> {
System.out.println("业务逻辑");
}, 60, TimeUnit.SECONDS);
e.shutdown();
}
这个代码是可以正常运行的,你粘过去直接就能跑,60 秒后是会正常输出的。
如果你觉得 60 秒太长了,那么你可以改成 3 秒运行一下,看看程序是不是正常运行并结束了。
但是就这个看起来问题不大的代码,会导致 CPU 飚到 100% 去。
真的,儿豁嘛。

咋回事呢
到底咋回事呢?
这个其实就是 JDK 的 BUG 导致的,我带你瞅瞅:
https://bugs.openjdk.org/browse/JDK-8065320
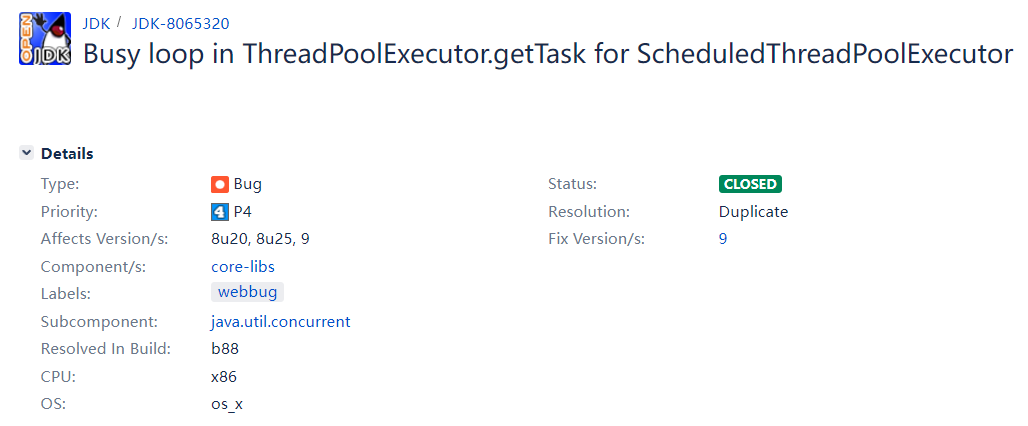
首先,你看 Fix Version 那个地方是 9,也就是说明这个 BUG 是在 JDK 9 里面修复了。JDK 8 里面是可以复现的。
其次,这个标题其实就包含了非常多的信息了,它说对于 ScheduledExecutorService 来说 getTask 方法里面存在频繁的循环。
那么问题就来了:频繁的循环,比如 for(;;) ,while(true) 这样的代码,长时间从循环里面走不出来,会导致什么现象?
那不就是导致 CPU 飙高吗。
注意,这里我说的是“长时间从循环里面走不出来”,而不是死循环,这两者之间的差异还是很大的。
我代码里面的示例就是使用的提出 BUG 的哥们给出的实例:

他说,在这个示例下,如果你在一个只有单核的服务器上跑,然后使用 TOP 命令,会看到持续 60 秒的 CPU 使用率为 100%。
为什么呢?
答案就藏在前面提到的 getTask 方法中:
java.util.concurrent.ThreadPoolExecutor#getTask
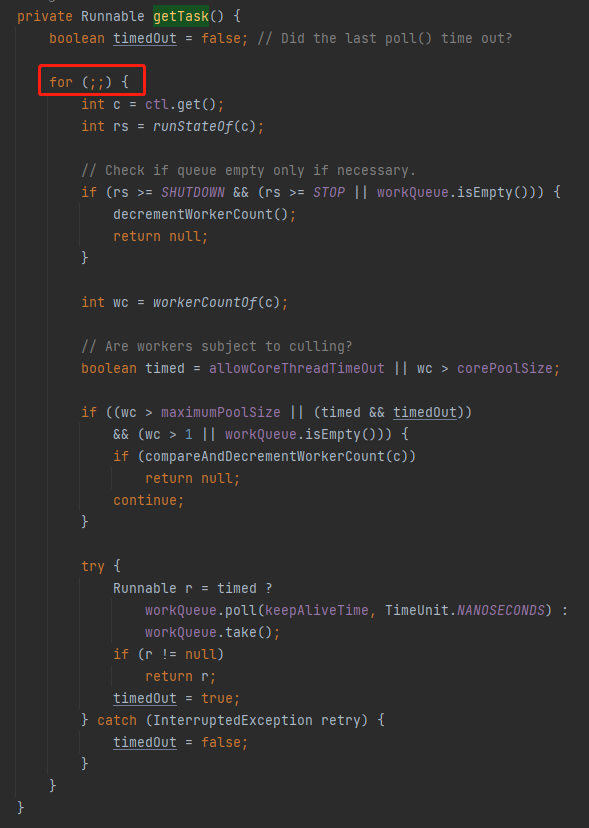
这个方法里面果然是有一个类似于无线循环的代码,但是它为什么不停的执行呢?
现在赶紧想一想线程池的基本运行原理。当没有任务处理的时候,核心线程在干啥?

是不是就阻塞在这个地方,等着任务过来进行处理的,这个能理解吧:
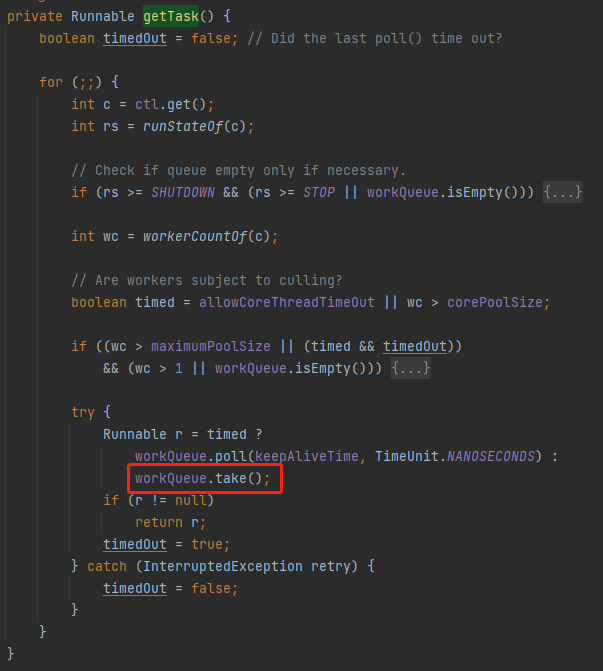
那我再问你一个问题,这行代码的作用是干啥:
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)
是不是在指定时间内如果没有从队列里面拉取到任务,则抛出 InterruptedException。
那么它什么时候会被触发呢?
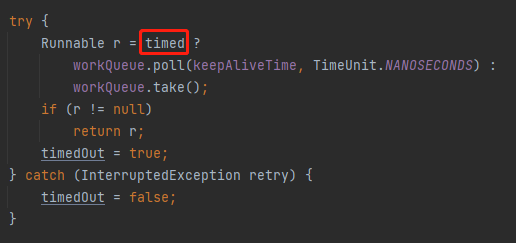
在 timed 参数为 true 的时候。
timed 参数什么时候会为 true 呢?

当 allowCoreThreadTimeOut 为 true 或者当前工作的线程大于核心线程数的时候。
而 allowCoreThreadTimeOut 默认为 false:
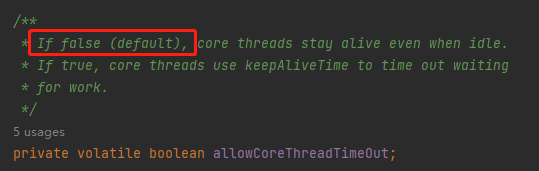
那么也就是在这个案例下满足了当前工作的线程大于核心线程数这个条件:
wc > corePoolSize
通过 Debug 知道,wc 是 1,corePoolSize 为 0:
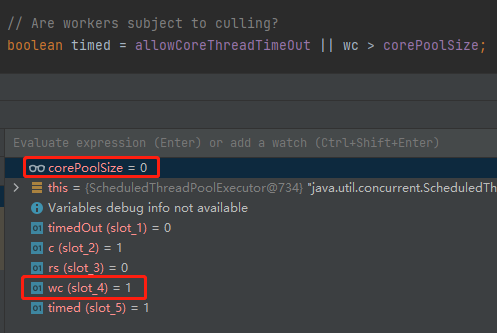
所以 timed 变成了 true。
好,这里要注意了,朋友。

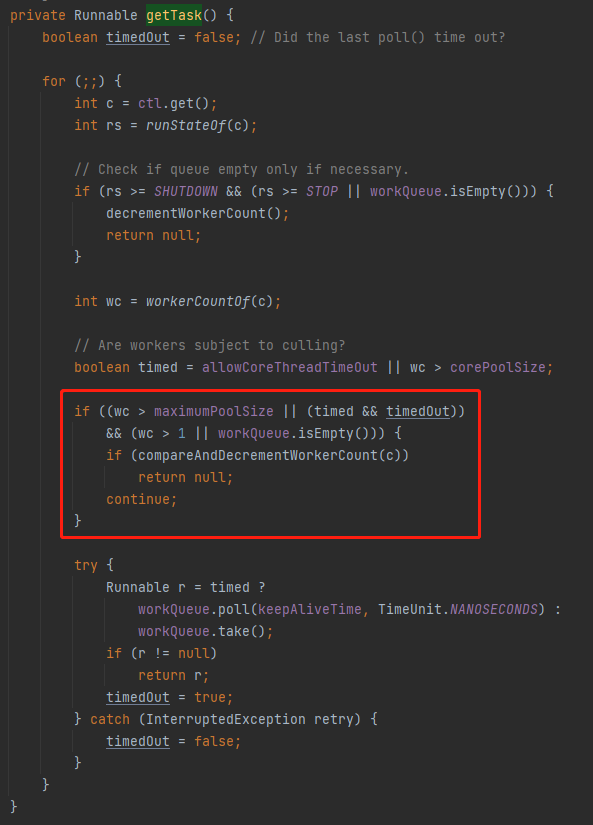
经过前面的分析,我们已经知道了在当前的案例下,会触发 for(;;)这个逻辑:
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)
那么这个 keepAliveTime 到底是多少呢?
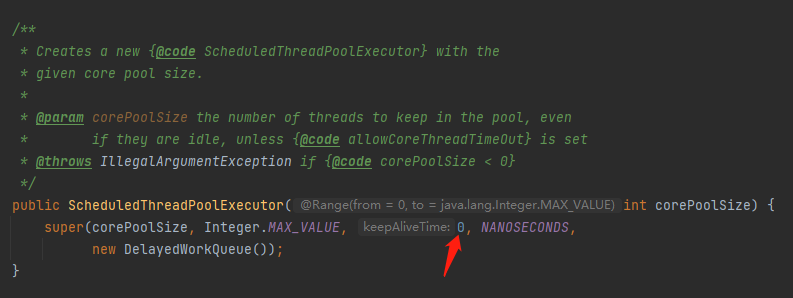
来,大声的喊出这个数字:0,这是一个意想不到的、诡计多端的 0。

所以,这个地方中的 r 每次都会返回一个 null,然后再次开启循环。
对于正常的线程池来说,触发了这个逻辑,代表没有任务要执行了,可以把对应线程进行回收了。
回收,对应的就是这部分代码会返回一个 null:
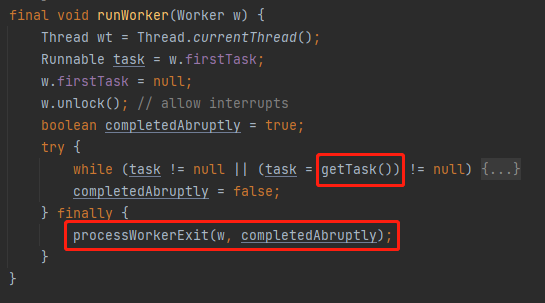
然后在外面 runWorker 方法中的,由于 getTask 返回了 null,从而执行了 finally 代码里面的逻辑,也就是从当前线程池移除线程的逻辑:
但是,朋友,我要说但是了。
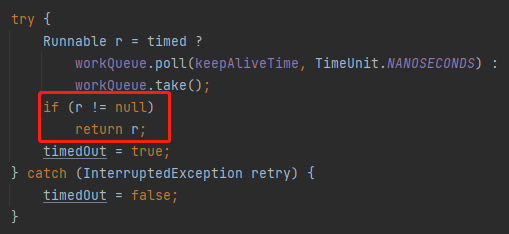
在我们的案例下,你看 if 判断的条件:
.jpg)
这里面的 wc > 1 || workQueue.isEmpty()) 是 false
所以这个 if 条件不成立,那么它又走到了 poll 这里:
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)
由于这里的 keepAliveTime 是 0,所以马不停蹄的的开启下一轮循环。
那么这个循环什么时候结束呢?
就是在从队列里面获取到任务的时候。
那么队列里面什么时候才会有任务呢?
在我们的案例里面,是 60 秒之后。
所以,在这 60 秒内,这部分代码相当于是一个“死循环”,导致 CPU 持续飙高到 100%。
这就是 BUG,这就是根本原因。
但是看到这里是不是觉得还差点意思?
我说 100% 就 100% 吗?
得拿出石锤来才行啊。
所以,为了拿出实锤,眼见为实,我把核心流程拿出来,然后稍微改动一点点代码:
public static void main(String[] args) {
ArrayBlockingQueue<Runnable> workQueue =
new ArrayBlockingQueue<>(100);
//绑定到 5 号 CPU 上执行
try (AffinityLock affinityLock = AffinityLock.acquireLock(5)) {
for (; ; ) {
try {
Runnable r = workQueue.poll(0, TimeUnit.NANOSECONDS);
if (r != null)
break;
} catch (InterruptedException retry) {
}
}
}
}
AffinityLock 这个类在之前的文章里面出现过:《面试官:Java如何绑定线程到指定CPU上执行?》
就是把线程绑定到指定 CPU 上去执行,减少 CPU 抖动带来的损耗, 具体我就不介绍了,有兴趣去看我之前的文章。
把这个程序跑起来之后,打开资源监视器,你可以看到 5 号 CPU 立马就飚到 100% 了,停止运行之后,立马就下来了:
这就是眼见为实,这真是 JDK 的 BUG,我真没骗你。
怎么修复
在 JDK 9 里面是怎么修复这个 BUG 的呢?
在前面提到的 BUG 的链接中,有这样的一个链接,里面就是 JDK 9 版本里面针对上述的 BUG 进行的修复:
http://hg.openjdk.java.net/jdk9/jdk9/jdk/rev/6dd59c01f011
点开这个链接之后,你可以找到这个地方:
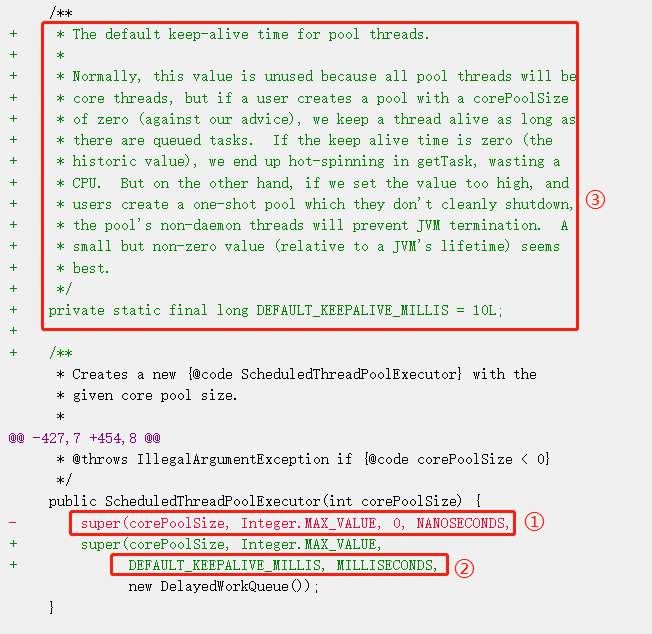
首先对比一下标号为 ① 和 ② 的地方,默认值从 0 纳秒修改为了 DEFAULT_KEEPALIVE_MILLIS 毫秒。
而 DEFAULT_KEEPALIVE_MILLIS 的值为在标号为 ③ 的地方, 10L。
也就是默认从 0 纳秒修改为了 10 毫秒。而这一处的改动,就是为了防止出现 coreSize 为 0 的情况。
我们重点关注一下 DEFAULT_KEEPALIVE_MILLIS 上面的那一坨注释。
我给你翻译一下,大概是这样的:
这个值呢一般来说是用不上的,因为在 ScheduledThreadPoolExecutor 线程池里面的线程都是核心线程。
但是,如果用户创建的线程池的时候,不听劝,头铁,要把 corePoolSize 设置为 0 会发生什么呢?

因为 keepAlive 参数设置的为 0,那么就会导致线程在 getTask 方法里面非常频繁的循环,从而导致 CPU 飙高。
那怎么办呢?
很简单,设置一个小而非零的值就可以,而这个小是相对于 JVM 的运行时间而言的。
所以这个 10 毫秒就是这样来的。
再来一个
在研究前面提到的编号为 8065320 的 BUG 的时候,我还发现一个意外收获,编号为 8051859 的 BUG,它们是挨着的,排排坐。
有点意思,也很简单,所以分享一波:
https://bugs.openjdk.org/browse/JDK-8051859

这个 BUG 又说的是啥事儿呢:
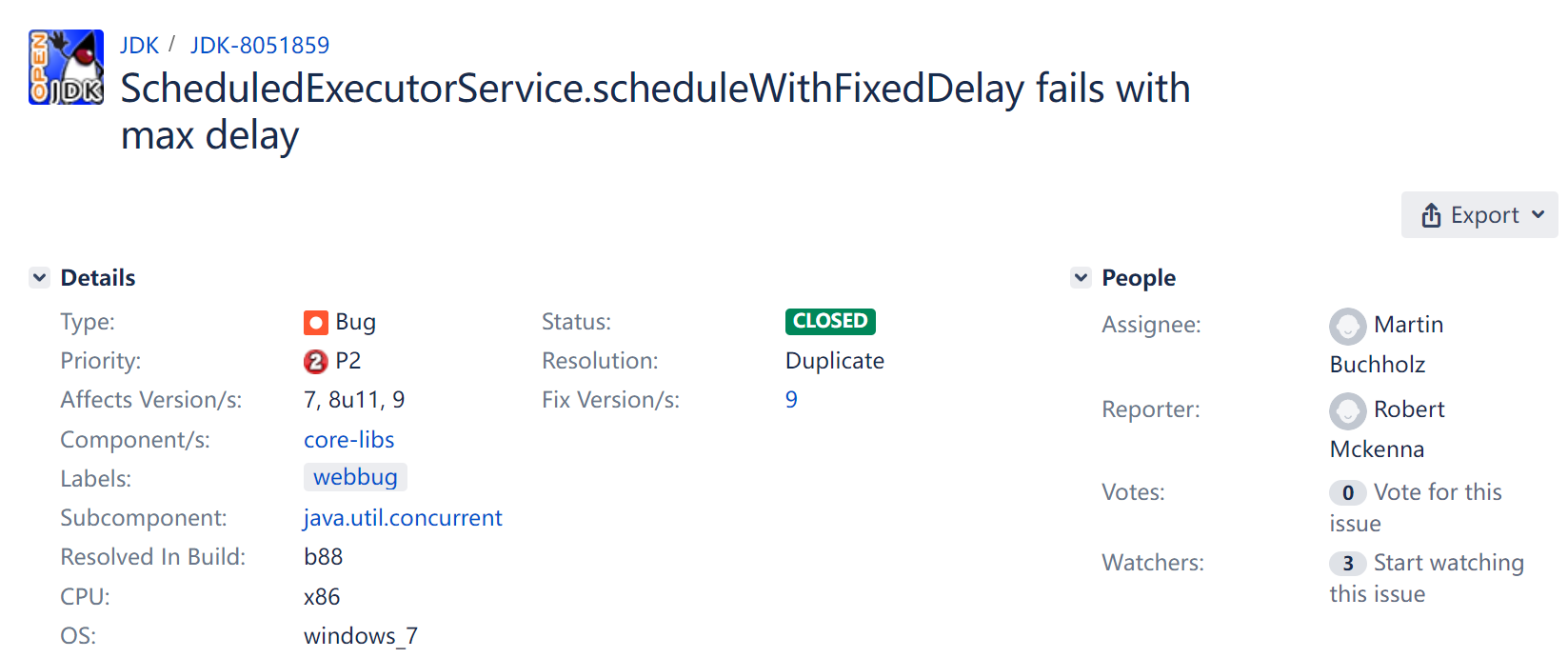
看截图这个 BUG 也是在 JDK 9 版本之后修复的。
这个 BUG 的标题说的是 ScheduledExecutorService 线程池的 scheduleWithFixedDelay 方法,遇到大延迟时会执行失败。
具体啥意思呢?
我们还是先拿着 Demo 说:
public class ScheduledTaskBug {
static public void main(String[] args) throws InterruptedException {
ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();
//第一个任务
executor.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
System.out.println("running scheduled task with delay: " + new Date());
}
}, 0, Long.MAX_VALUE, TimeUnit.MICROSECONDS);
//第二个任务
executor.submit(new Runnable() {
@Override
public void run() {
System.out.println("running immediate task: " + new Date());
}
});
Thread.sleep(5000);
executor.shutdownNow();
}
}
你把这个代码粘过去之后,发现输出是这样的:
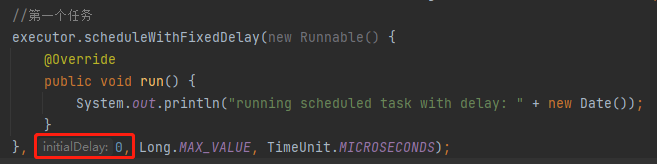
只有第一个任务执行了,第二个任务没有输出结果。
正常来说,第一个任务的延迟时间,也就是 initialDelay 参数是 0,所以第一次执行的时候是立即执行:
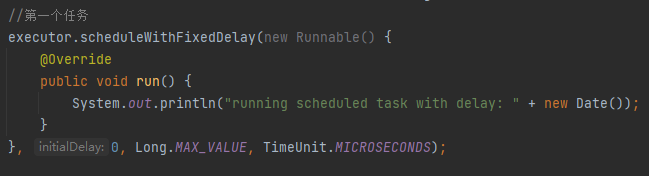
比如我改成这样,把周期执行的时间单位,由微秒修改为纳秒,就正常了:

神奇不神奇?你说这不是 BUG 这是啥?
提出 BUG 的这个哥们在描述里面介绍了 BUG 的原因,主要是提到了一个字段和两个方法:

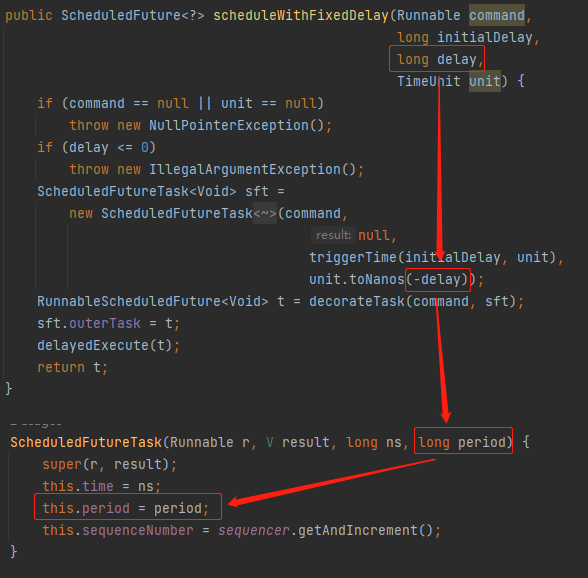
一个字段是指 period,两个方法分别是 TimeUnit.toNanos(-delay) 和 ScheduledFutureTask.setNextRunTime()。
首先,在 ScheduledThreadPoolExecutor 里面 period 字段有三个取值范围:
-
正数,代表的是按照固定速率执行(scheduleAtFixedRate)。 -
负数,代表的是按照固定延时执行(scheduleWithFixedDelay)。 -
0,代表的是非重复性任务。
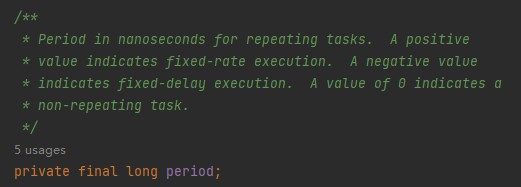
比如我们的示例代码中调用的是 scheduleWithFixedDelay 方法,它里面就会在调用 TimeUnit.toNanos 方法的时候取反,让 period 字段为负数:
好,此时我们开始 Debug 我们的 Demo,先来一个正常的。
比如我们来一个每 30ms 执行一次的周期任务,请仔细看:
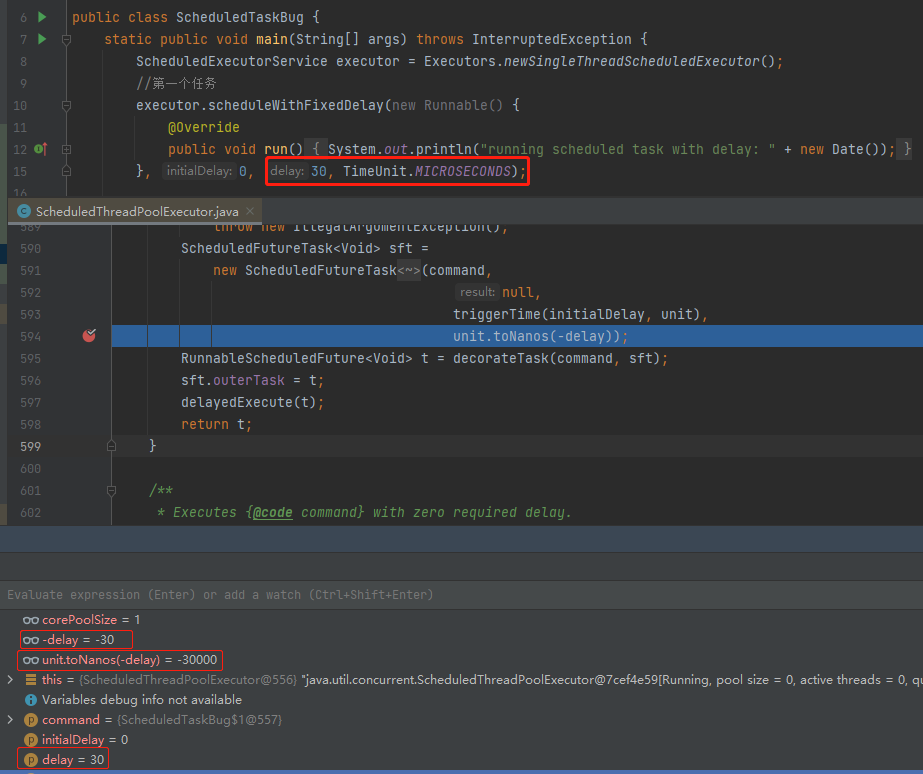
在执行 TimeUnit.toNanos(-delay) 这一行代码的时候,把 30 微秒转化为了 -30000 纳秒,也就是把 period 设置为 -30000。
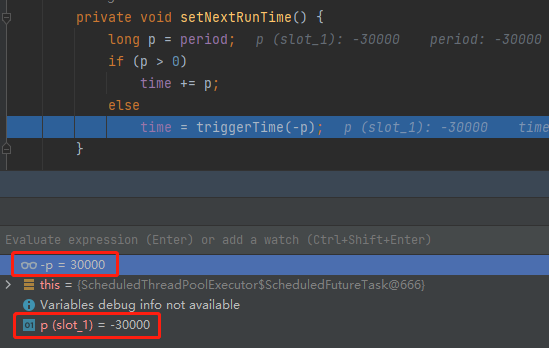
然后来到 setNextRunTime 方法的时候,计算任务下一次触发时间的时候,又把 period 转为正数,没有任何毛病:
但是,当我们把 30 修改为 Long.MAX_VALUE 的时候,有意思的事情就出现了:
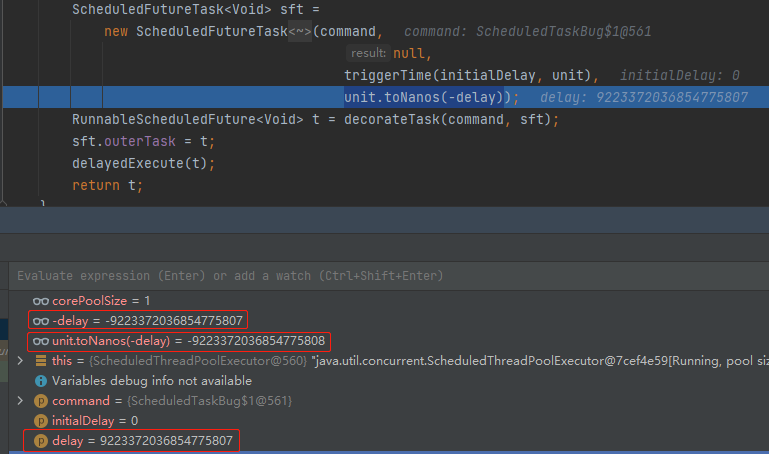
delay=9223372036854775807
-delay=-9223372036854775807
unit.toNanos(-delay)=-9223372036854775808
直接给干溢出了,变成了 Long.MIN_VALUE:
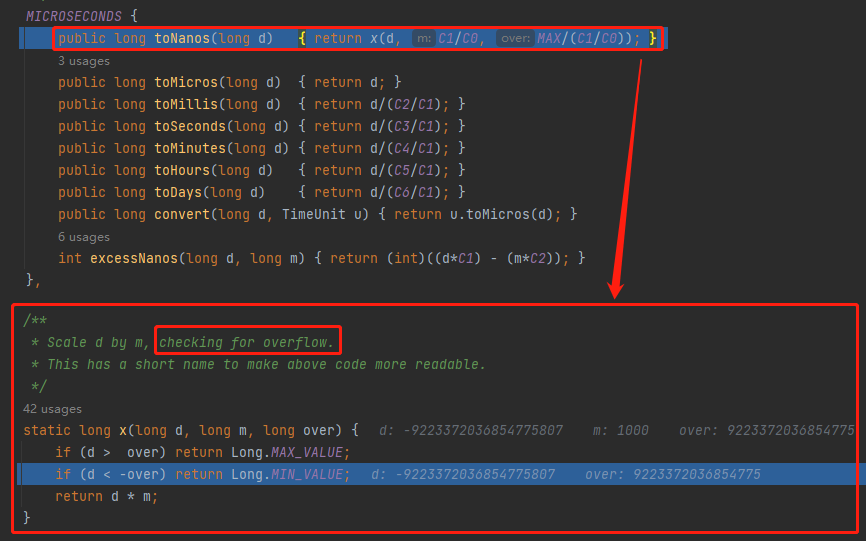
当来到 setNextRunTime 方法的时候,你会发现由于我们的 p 已经是 Long.MIN_VALUE 了。
那么 -p 是多少呢?
给你跑一下:
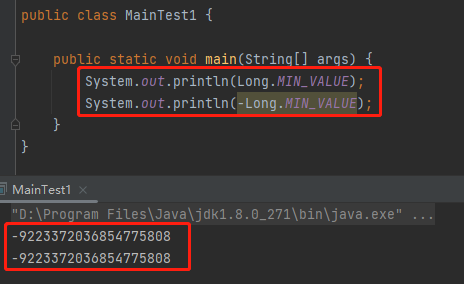
Long.MIN_VALUE 的绝对值,还是 Long.MIN_VALUE。一个神奇的小知识点送给你,不客气。
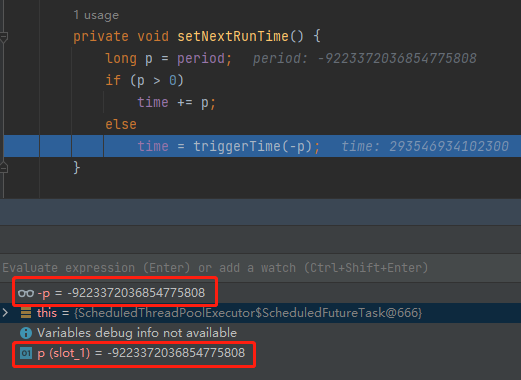
所以 -p 还是 Long.MIN_VALUE:
我们来算一下啊,一秒等于 10 亿纳秒:
那么下一次触发时间就变成了这样:
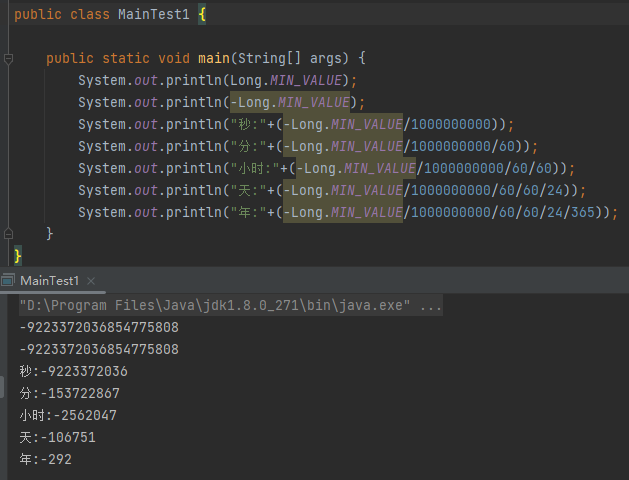
292 年之前。
这就是在 BUG 描述中提到的:
This results in triggerTime returning a time in the distant past.

the distant past,就是 long long ago,就是 292 年之前。就是 1731 年,雍正九年,那个时候的皇帝还是九子夺嫡中一顿乱杀,冲出重围的胤禛大佬。
确实是很久很久以前了。
那么这个 BUG 怎么修复呢?
其实很简单:

把 unit.toNanos(-delay) 修改为 -unit.toNanos(delay),搞定。
我给你盘一下:
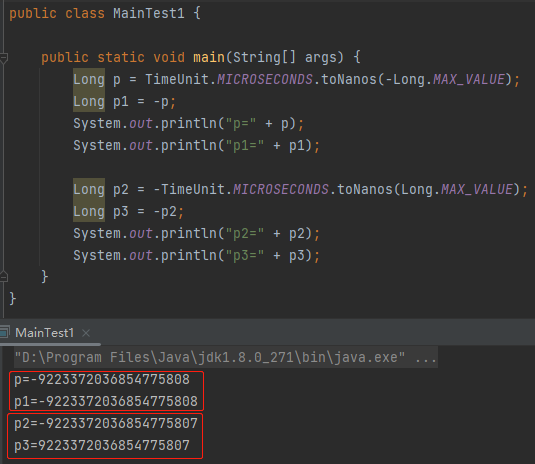
这样就不会溢出,时间就变成了 292 年之后。
那么问题就来了,谁特么会设置一个每 292 年执行一次的 Java 定时任务呢?
好,你看到这里了,本文就算结束了,我来问你一个问题:你知道了这两个 BUG 之后,对你来说有什么收获吗?

没有,是的,除了浪费了几分钟时间外,没有任何收获。
那么恭喜你,又在我这里学到了两个没有卵用的知识点。

汇总
这个小节为什么叫做汇总呢?
因为我发现这里出现的一串 BUG,除了本文提到的 2 个外,还有 3 个我都写过了,所以在这里汇个总,充点字数,凑个篇幅:

8054446: Repeated offer and remove on ConcurrentLinkedQueue lead to an OutOfMemoryError
《我的程序跑了60多小时,就是为了让你看一眼JDK的BUG导致的内存泄漏。》
这篇文章就是从 ConcurrentLinkedQueue 队列的一个 BUG 讲起。jetty 框架里面的线程池用到了这个队列,导致了内存泄漏。
同时通过 jconsole、VisualVM、jmc 这三个可视化监控工具,让你看见“内存泄漏”的发生。
8062841: ConcurrentHashMap.computeIfAbsent stuck in an endless loop
《震惊!ConcurrentHashMap里面也有死循环,作者留下的“彩蛋”了解一下?》
这个 BUG 在 Dubbo 和 Seata 里面都有提到过,也被 Seata 官方的一篇博客中被引用过:
https://seata.io/zh-cn/blog/seata-dsproxy-deadlock.html
8073704: FutureTask.isDone returns true when task has not yet completed
《Doug Lea在J.U.C包里面写的BUG又被网友发现了。》
这个 BUG 也是在 JDK 9 版本里面修复的,逻辑弯弯绕绕的,但是理解之后,对于 FutureTask 状态流转就能有一个比较深刻的认知了。有兴趣可以看看。



