
介绍 HashMap
Map 是一种存储键值对的集合。Map 集合可以根据 key 快速查找对应的 value 值。HashMap 是 Map 类型的一中。
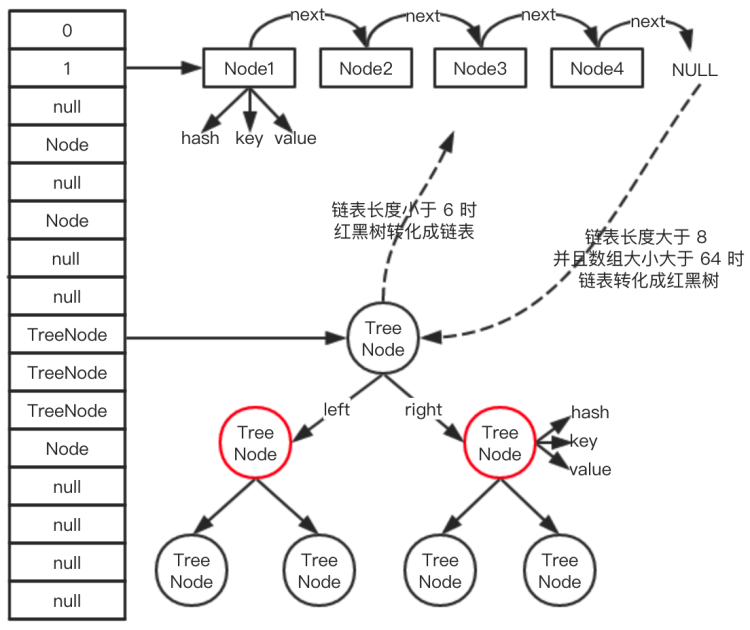
HashMap 的底层存储结构是:数组 + 链表 + 红黑树。
下面我们通过 HashMap 的新增操作、查找操作来看 HashMap 的底层存储结构。
HashMap 的新增操作
当调用 HashMap 的 put() 方法时,put() 方法的处理逻辑如下:
-
首先,它会调用 hash() 方法根据 key 计算出 hash 值,然后根据计算出的 hash 值计算出 key 对应的数组索引 i:
-
计算出 key 对应的数组索引 i 之后,它根据数组在索引 i 上的值进行处理:
- 如果数组在索引 i 上的值为 null,则直接生成一个新的节点,并让 tab[i] 指向该节点;
- 如果数组在索引 i 上的值不为 null,则意味着需要解决 hash 冲突问题。
-
接上一步骤,如果数组在索引 i 上的值不为 null。
- 如果索引 i 上的结构是普通链表,则把新生成的节点加到链表的末尾
- 如果索引 i 上的结构是红黑树,则使用红黑树方式新增
-
接上一步骤,如果索引 i 上的结构是普通链表,则把新生成的节点加到链表的末尾之后,需要判断是否需要将链表转为红黑树:
- 如果链表的长度大于等于 8,并且数组的长度大于等于 64,则调用 treeifyBin() 将链表转为红黑树;
- 如果链表的长度大于等于 8,但是数组的长度小于 64,则调用 resize() 方法执行扩容操作;
- 当红黑树中的节点个数小于等于 6 时,红黑树会转为链表。
-
将节点加入 HashMap 集合之后,put() 方法的最后一步,如果 HashMap 中元素的数量超过了扩容的阈值(threshold),那么它会调用 resize() 方法执行扩容操作。
当调用 HashMap 的 put() 方法时,如果 HashMap 中已经存在要新增的 key,并且方法的入参 onlyIfAbsent 为 false,则替换旧值,并返回旧值。
HashMap 中调用 hash() 方法根据 key 计算出 hash 值的规则是:
- 如果 key 为 null,则计算出的 hash 值为 0
- 如果 key 不为 null,则 hash 值的计算公式为 hash = key.hashCode() ^ (key.hashCode() >>> 16)。先将 key 的 hashCode 值无符号右移 16 位,然后再和 key 的 hashCode 值做 异或 运算,使 key 的 hashCode 值高 16 位的变化映射到低 16 位中,使 hashCode 值高 16 位也参与后续索引 i 的计算(
i = hash & (n - 1))。减少了碰撞的可能性。
// 向 HashMap 集合中新增键值对
// 如果 HashMap 集合中已经存在该键,那么旧的值将被替换
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashMap 的扩容机制
当调用 HashMap 的 put() 方法时,将节点加入 HashMap 集合之后,如果 HashMap 中元素的数量超过了扩容的阈值(threshold),那么它会调用 resize() 方法执行扩容操作。
HashMap 的扩容机制是扩容为原来容量的 2 倍。resize() 方法会重新计算每个元素的 hash 值,将元素重新放入新的位置,并更新下次扩容的阈值(threshold 成员变量)为原来阈值的 2 倍。初始扩容阈值 threshold = loadFactor * 数组的长度。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// 将节点加入 HashMap 集合
++modCount;
if (++size > threshold) {
// 执行扩容操作
resize();
}
afterNodeInsertion(evict);
return null;
}
HashMap 的查找操作
当调用 HashMap 的 get() 方法时,get() 方法的处理逻辑如下:
- 首先,它会根据传入的 key 计算出 hash 值;然后根据计算出的 hash 值计算出 key 对应的数组索引 i
- 计算出 key 对应的数组索引 i 之后,根据存储位置,从数组中取出对应的 Entry,然后通过 key 对象的 equals() 方法判断传入的 key 和 Entry 中的 key 是否相等:
- 如果传入的 key 和 Entry 中的 key 相等,则查找操作完成,返回 Entry 中的 value;
- 如果传入的 key 和 Entry 中的 key 不相等,判断数组在索引 i 上的结构是链表 还是 红黑树,然后调用相应的查找数据的方法。直到找到相等的 Entry 或者没有下一个 Entry 为止。
自定义类型作为 Map 的 key,注意事项
面试中如何通过 HashMap 展示你在数据结构方面的功底?-极客时间 (geekbang.org)
当 HashMap 的 key 为自定义类型时,我们需要重写(Override)该类的 equals() 方法和 hashCode() 方法。因为:
- 重写 equals() 方法的原因:HashMap 的查找操作需要使用 key 对象的 equals() 方法判断传入的 key 和 Entry 中的 key 是否相等。我们需要保证逻辑上相同的对象,使用 equals() 方法判断时结果为 true。
- 重写 hashCode() 方法的原因:HashMap 在使用哈希函数计算 key 的 hash 值时,需要使用 key 对象的 hashCode() 方法。我们需要保证逻辑上相同的对象,hashCode() 方法的返回值也相同。
HashMap 的容量大小问题
HashMap 的数组长度总是为 2 的幂次方。不论传入的初始容量是否为 2 的幂次方,最终都会转化为 2 的幂次方。
HashMap 中根据 key 计算出 hash 值,然后根据计算出的 hash 值计算出 key 对应的数组索引 i 时,通过 hash 值 和 数组的长度 - 1 做与运算获得 key 对应的数组索引 i ,即 i = hash & (n - 1)。
HashMap 设计的非常巧妙:
- 在计算 hash 值时,它先将 key 的 hashCode 值无符号右移 16 位,然后再和 key 的 hashCode 值做 异或 运算,使 key 的 hashCode 值高 16 位的变化映射到低 16 位中,使 hashCode 值高 16 位也参与后续索引 i 的计算(
i = hash & (n - 1))。减少了碰撞的可能性。 - 在根据 hash 值计算 key 对应的数组索引 i 时,它将 hash 值 和 数组的长度 - 1 做与运算获得 key 对应的数组索引 i,即
i = hash & (n - 1)。由于数组的长度 n 是 2 的幂次方,n - 1 可以保证它的二进制的后几位都是 1,n 的这一位及之前的位都是 0。因此,计算出的数组索引 i 和 hash 值的二进制表示中后几位有关,而与前面的二进制位无关 - 当 b 是 2 的幂次方时,
a % b == a & (b - 1)。CPU 处理位运算比处理数**算的速度更快,效率更高。
HashMap 的死循环问题
HashMap 的死循环问题说的是,多个线程同时操作一个 HashMap,当 HashMap 中的键值对数量达到一定程度需要进行扩容操作时,HashMap 有可能会进入一个无限循环,导致程序无法正常执行。
这是因为多个线程同时操作一个 HashMap,多个线程调用 HashMap 的 resize() 执行扩容操作,HashMap 中的链表有可能成环,程序无法从遍历链表中退出,从而导致程序进入死循环。



