
Java注解与原理分析原创
使用的太多,被忽略的理所当然;
一、注解基础
注解即标注与解析,在Java的代码工程中,注解的使用几乎是无处不在,甚至多到被忽视;
无论是在JDK源码或者框架组件,都在使用注解能力完成各种识别和解析动作;在对系统功能封装时,也会依赖注解能力简化各种逻辑的重复实现;
基础接口
在Annotation的源码注释中有说明:所有的注解类型都需要继承该公共接口,本质上看注解是接口,但是代码并没有显式声明继承关系,可以直接查看字节码文件;
-- 1、声明注解
public @interface SystemLog {}
-- 2、查看指令
javap -v SystemLog.class
-- 3、打印结果
Compiled from "SystemLog.java"
public interface com.base.test.SystemLog extends java.lang.annotation.Annotation
元注解
声明注解时使用,用来定义注解的作用目标,保留策略等;
@Documented
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface SystemLog { String model () default "" ; }
- Documented:是否被javadoc或类似工具记录在文档中;
- Inherited:标识注解是否可以被子类继承;
- Target:作用目标,在ElementType枚举中可以看到取值包括类、方法、属性等;
- Retention:保留策略,比如编译阶段是否丢弃,运行时保留;
此处声明一个SystemLog注解,作用范围是在方法上,并且在运行时保留,该注解通常用在服务运行时,结合AOP切面编程实现方法的日志采集;
二、注解原理
先来看一个简单的注解使用案例,再细致的分析其中原理,案例并不复杂,就是常见的标注与解析两个关键动作;
public class LogInfo {
@SystemLog(model = "日志模块")
public static void main(String[] args) {
// 生成代理文件
System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");
// 反射机制
Method[] methods = LogInfo.class.getMethods();
for (Method method:methods){
SystemLog systemLog = method.getAnnotation(SystemLog.class) ;
if (systemLog != null){
// 动态代理:com.sun.proxy.$Proxy2
System.out.println(systemLog.getClass().getName());
System.out.println(systemLog.model());
}
}
}
}
这里涉及到两个核心概念:反射机制、动态代理;反射机制可以在程序运行时获取类的完整结构信息,代理模式给目标对象提供一个代理对象,由代理对象持有目标对象的引用;
案例中通过反射机制,在程序运行时进行注解的获取和解析,值得关注的是systemLog对象的类名,输出的是代理类信息;
案例执行完毕后,会在代码工程的目录下生成代理类,可以查看$Proxy2文件;
public final class $Proxy2 extends Proxy implements SystemLog {
public final String model() throws {
try {
return (String)super.h.invoke(this, m3, (Object[])null);
} catch (RuntimeException | Error var2) {
throw var2;
} catch (Throwable var3) {
throw new UndeclaredThrowableException(var3);
}
}
}
在对SystemLog解析的过程中,实际上是在使用注解的代理类,$Proxy2继承了Proxy类并实现了SystemLog接口,并且重写了相关方法;有关反射和代理的逻辑,在之前的内容中有详说,此处不赘述;
值得一看是代理类中invoke方法调用,具体的处理逻辑在AnnotationInvocationHandler类的invoke方法中,会对注解原生方法和自定义方法做判断,并对原生方法提供实现;
三、常用注解
1、JDK注解
在JDK中有多个注解是经常使用的,例如Override、Deprecated、SuppressWarnings等;
- Override:判断方法是否为重写方法;
- Deprecated:标记过时的API,继续使用会警告;
- FunctionalInterface:检验是否为函数式接口;
- SuppressWarnings:代码的警告会静默处理;
这里注意FunctionalInterface注解,从1.8开始引入,检验是否为函数式接口,即接口只能有一个抽象方法,否则编译报错;
2、Lombok注解
在具体的看Lombok组件之前,需要先了解一个概念:代码编译;在open-jdk的描述文档中大致分为三个核心阶段;

- 第一步:读取命令行上指定的所有源文件,解析为语法树,进行符号表填充;
- 第二步:调用注解处理器,如果处理器生成任何新的源文件或类文件,编译会重新启动;
- 第三步:分析器创建的语法树被分析并转换为类文件;
更多细节说明可以参考openjdk文档中Compiler模块的内容,下面再回到Lombok组件上;
Lombok组件在代码工程中的使用非常频繁,通过注解的方式极大的简化Java中Bean对象的编写,提高了效率并且让源码显得简洁;
这里用一段简单的代码演示其效果,在IdKey的类中通过三个常用的Lombok注解,替代了类中很多基础方法的显式生成,查看编译后的文件实际是存在相关方法的;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class IdKey {
private Integer id ;
private String key ;
public static void main(String[] args) {
IdKey idKey01 = new IdKey(1,"cicada") ;
System.out.println(idKey01);
idKey01.setId(2);
idKey01.setKey("smile");
System.out.println(idKey01);
}
}
这里需要了解JDK中注解处理器的相关源码,AbstractProcessor作为超类,编译器在编译时会去检查该类的子类,子类中最核心的是process方法;

-- 1、Lombok处理器
@SupportedAnnotationTypes("*")
public class LombokProcessor extends AbstractProcessor {
private JavacTransformer transformer;
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
transformer.transform(prio, javacProcessingEnv.getContext(), cusForThisRound, cleanup);
}
}
-- 2、AST抽象树
public class JavacTransformer {
public void transform(long priority, Context context, List<JCTree.JCCompilationUnit> compilationUnits,
CleanupRegistry cleanup) {
JavacAST ast = new JavacAST(messager, context, unit, cleanup);
ast.traverse(new AnnotationVisitor(priority));
handlers.callASTVisitors(ast, priority);
}
}
-- 3、注解处理抽象类
public abstract class JavacAnnotationHandler<T extends Annotation> {
public abstract void handle(AnnotationValues<T> annotation, JCAnnotation ast, JavacNode annotationNode);
}
-- 4、Getter注解处理
public class HandleGetter extends JavacAnnotationHandler<Getter> {
@Override
public void handle(AnnotationValues<Getter> annotation, JCTree.JCAnnotation ast, JavacNode annotationNode) {
JavacNode node = annotationNode.up();
List<JCTree.JCAnnotation> onMethod = unboxAndRemoveAnnotationParameter(ast, "onMethod", "@Getter(onMethod", annotationNode);
switch (node.getKind()) {
case FIELD:
createGetterForFields(level, fields, annotationNode, true, lazy, onMethod);
break;
}
}
}
IdKey类从简洁的源码编译为复杂的字节码文件,通过注解对结构处理时关联一个核心概念,叫AST抽象树,会涉及到很多语法、词法的解析逻辑;
四、自定义注解
在系统开发中通过自定义注解可以处理各种麻烦的重复逻辑,其最明显的好处就是可以大量的消除冗余的代码块;
1、同步控制
代码中可能存在很多方法是限制重复请求的,加锁处理是很常用的手段,此时完全可以通过注解结合AOP切面编程简化代码的复杂程度;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface SyncLock {
String lockKey(); // 锁的Key
int time () default 3000 ; // 有效时间
int retryNum () default 3 ; // 重试次数
}
通过注解标记在方法上,可以极大简化同步锁的编码步骤,只是在读取KEY的时候需要设计好解析规则,结合反射原理进行获取即可;
基于相同的原理,也适应与日志采集、系统告警等功能,在之前的内容中都有详细的总结;
2、类型引擎
在数据处理的逻辑中,经常有这样一种场景,同一份数据要动态推送到多种数据源中存储,比如常见的MySQL表和ES索引双写模式,这就需要对实体对象做不同的解析逻辑;
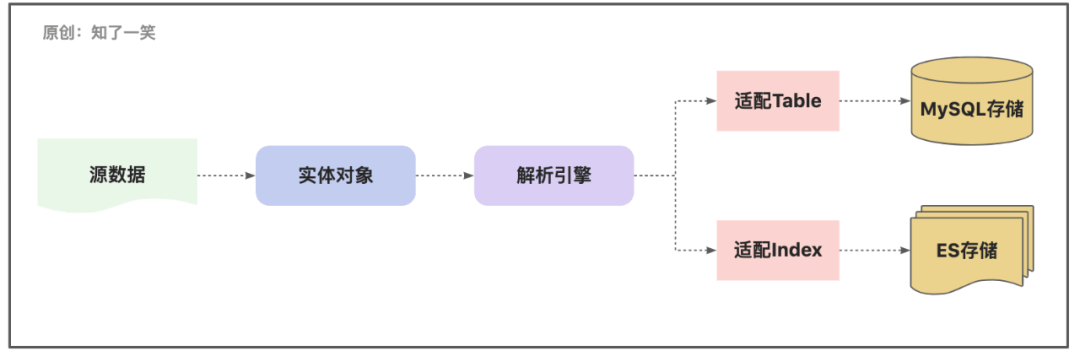
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface BizType {
EsIndexEnum esIndexEnum () ; // ES索引解析适配
MySqlTableEnum mySqlTableEnum () ; // MySQL表解析适配
ExcelEnum excelEnum () ; // Excel解析适配
}
首先声明一个类型解析的注解,可以标记在实体对象的字段属性上,然后根据各种数据源的类型枚举,去适配不同解析工厂的执行逻辑,比如常用数据类型、格式、或者完全自定义。



