
【译】一个提升并发队列性能的专用算法转载
使用专用算法,对于多个写入线程和单个读取线程,可以实现比java.util.concurrent.BlockingQueue高四倍的性能。
如果你必须从多个线程访问单个资源,这种支持多个写入器但只有一个读取器的阻塞队列非常有用。与其直接写入资源,不如将数据放入队列中,并让单个线程异步将数据写入资源。
在vmlens中,一个在测试期间检测竞争条件和死锁的工具,此队列用于将跟踪事件写入文件系统。
队列
主要想法不是使用一个队列,而是使用多个队列。我们使用存储在线程本地字段中的每个写入线程一个队列。然后,线程本地队列是一个简单的链接列表,使用下一个元素的波动字段和值的最终字段。读取迭代所有写入线程以收集书面数据。这里更详细地解释了该算法。
你可以从GitHub下载队列的源代码。
基准
以下是基准的源代码:
@State(Scope.Group)
public class BlockingQueueBenchmark {
private static final int WRITING_THREAD_COUNT = 5;
private static final int VMLENS_QUEUE_LENGTH = 1000;
private static final int JDK_QUEUE_LENGTH = 4000;
EventBusImpl eventBus;
Consumer consumer;
ProzessAllListsRunnable prozess;
TLongObjectHashMap<ProzessOneList> threadId2ProzessOneRing;
LinkedBlockingQueue jdkQueue;
private long jdkCount = 0;
private long vmlensCount = 0;
@Setup()
public void setup() {
eventBus = new EventBusImpl(VMLENS_QUEUE_LENGTH);
consumer = eventBus.newConsumer();
prozess = new ProzessAllListsRunnable(new EventSink() {
public void execute(Object event) {
vmlensCount++;
}
public void close() {
}
public void onWait() {
}
}, eventBus);
threadId2ProzessOneRing = new TLongObjectHashMap<ProzessOneList>();
jdkQueue = new LinkedBlockingQueue(JDK_QUEUE_LENGTH);
}
@Benchmark
@Group("vmlens")
@GroupThreads(WRITING_THREAD_COUNT)
public void offerVMLens() {
consumer.accept("event");
}
@Benchmark
@Group("vmlens")
@GroupThreads(1)
public void takeVMLens() {
prozess.oneIteration(threadId2ProzessOneRing);
}
@Benchmark
@Group("jdk")
@GroupThreads(WRITING_THREAD_COUNT)
public void offerJDK() {
try {
jdkQueue.put("event");
} catch (Exception e) {
e.printStackTrace();
}
}
@Benchmark
@Group("jdk")
@GroupThreads(1)
public void takeJDK() {
try {
jdkQueue.poll(100, TimeUnit.SECONDS);
jdkCount++;
} catch (Exception e) {
e.printStackTrace();
}
}
@TearDown(Level.Trial)
public void printCounts() {
System.out.println("jdkCount " + jdkCount);
System.out.println("vmlensCount " + vmlensCount);
}
}该基准使用jmh,这是一个用于微基准的OpenJDK框架。
该基准包括使用 WRITING_THREAD_COUNT 线程向队列发布事件——vmlens 队列为 35 行,JDK 队列为 48 行。vmlens在第41行,JDK使用一个线程读取事件。vmlens队列在一个调用中读取所有当前可用的事件,并为每个事件调用回调函数执行第20行。
你可以在此处从GitHub下载基准的源代码。
结果
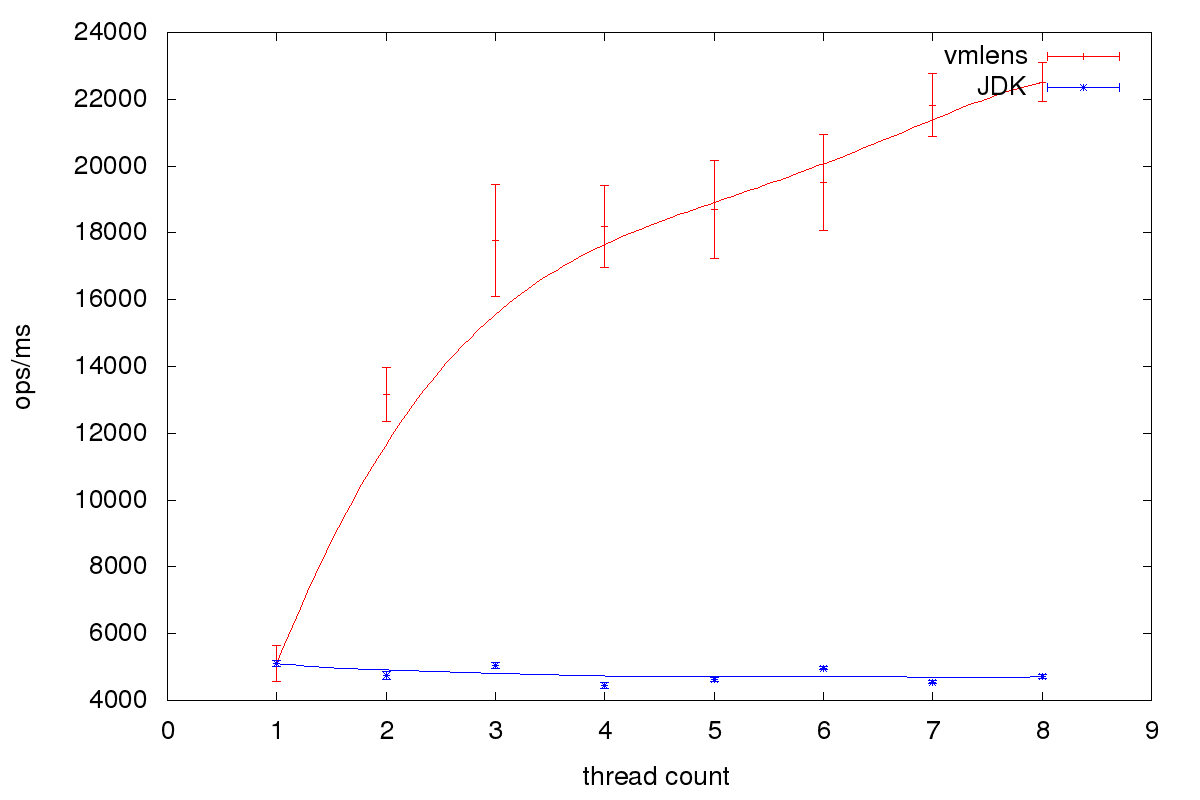
该基准是在英特尔i5 4核CPU上运行的。所有测试都使用以下jmh参数运行:-wi 10 -i 50 -f 5 -tu ms。下图显示了1到8个写入线程每毫秒的运行吞吐量:
结论和后续步骤
正如我们所看到的,对于阻止、多个写入器、单个读取器队列,使用与通用java.util.concurrent.BlockingQueue相比,可以使用专用队列实现更好的吞吐量。当我们使用此队列写入文件系统时,限制因素是读取线程。此线程不仅需要收集所有数据,还需要将其写入文件系统。因此,为了进一步提高性能,我计划收集数据,并可能将其压缩到被阻止的写入线程中。
我很高兴听到你关于你用于写入文件系统的技巧的消息。
原文作者:



