
手写本地缓存实战1——各个击破,按需应对实际使用场景原创

大家好,又见面了。
通过《深入理解缓存原理与实战设计》系列专栏的前两篇内容,我们介绍了缓存的整体架构、设计规范,也阐述了缓存的常见典型问题及其使用策略。作为该系列的第三篇文章,本篇我们将一起探讨下项目中本地缓存的各种使用场景与应对实现策略 —— 也通过本篇介绍的几个本地缓存的实现策略与关键特性的支持,体会到本地缓存使用与构建的关注要点,也作为我们下一篇文章要介绍的手写本地缓存通用框架的铺垫。
本地缓存的递进史
从本质上来说,缓存其实就是一堆数据的集合(甚至有的时候,这个集合中只有1个元素,比如一些缓存计数器)。再直白点,它就是一个容器而已。在各个编程语言中,容器类的对象类型都有很多不同种类,这就需要开发人员根据业务场景不同的诉求,选择不同的缓存承载容器,并进行二次加工封装以契合自己的意愿。
下面我们就一起看下我们实现本地缓存的时候,可能会涉及到的一些常见的选型类型。
小众诉求 —— 最简化的集合缓存
List或者Array算是比较简单的一种缓存承载形式,常用于一些黑白名单类数据的缓存,业务层面上用于判断某个值是否存在于集合中,然后作出对应的业务处理。

比如有这么个场景:
在一个论坛系统中,管理员会将一些违反规定的用户拉入黑名单中禁止其发帖,这些黑名单用户ID列表是存储在数据库中一个独立的表中。
当用户发帖的时候,后台需要判断此用户是否在被禁言的黑名单列表里。如果在,则禁止其发帖操作。
因为黑名单ID的数量不会很多,为了避免每次用户发帖操作都查询一次DB,可以选择将黑名单用户ID加载到内存中进行缓存,然后每次发帖的时候判断下是否在黑名单中即可。实现时,可以简单的用List去承载:
public class UserBlackListCache {
private List<String> blackList;
public boolean inBlackList(String userId) {
return blackList.contains(userId);
}
public void addIntoBlackList(String userId) {
blackList.add(userId);
}
public void removeFromBlackList(String userId) {
blackList.remove(userId);
}
}
作为一个基于List实现的黑名单缓存,一共对外提供了三个API方法:
| 接口名称 | 功能说明 |
|---|---|
| inBlackList | 判断某个用户是否在黑名单 |
| addIntoBlackList | 将某个用户添加到黑名单中 |
| removeFromBlackList | 将某个用户从黑名单中移除 |
List或者Array形式,由于数据结构比较简单,无冗余数据,缓存存储的时候内存占用量相对会比较经济些。当然,受限于List和Array自身的数据结构特点,实现按条件查询操作的时候时间复杂度会比较高,所以使用场景相对有限。
众生形态 —— 常规键值对缓存
相比List这种线性集合容器而言,在实际项目中,更多的场景会选择使用一些key-value格式的映射集(比如HashMap)来作为容器 —— 这也是大部分缓存的最基础的数据结构形态。业务上可以将查询条件作为key值,然后将实际内容作为value值进行存储,可以实现高效的单条数据条件查询匹配。
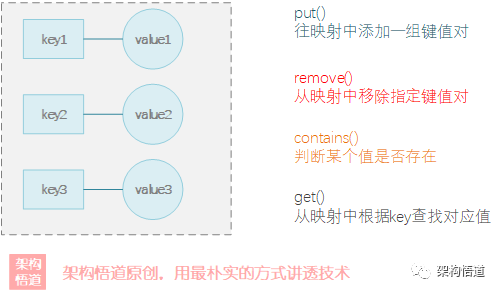
还是上述的发帖论坛系统的一个场景:
用户登录论坛系统,查看帖子列表的时候,界面需调用后端提供的帖子列表查询请求。在帖子列表中,会显示每个帖子的发帖人信息。
由于帖子的发帖人只存储了个UID信息,而需要给到界面的是这个UID对应用户的简要信息,比如头像、昵称、注册年限等等,所以在帖子列表返回前,还需要根据UID查询到对应的用户信息,最后一并返回给前端。
按照上述的要求,如果每次查询到帖子列表之后,再去DB中根据UID逐个去查询每个帖子对应的用户信息,势必会导致每个列表接口都需要调用很多次DB查询用户的操作。所以如果我们将用户的简要信息映射缓存起来,然后每次直接从缓存里面根据UID查询即可,这样可以大大简化每次查询操作与DB的交互次数。
使用HashMap来构建缓存,我们可以将UID作为key,而UserInfo作为value,代码如下:
public class UserCache {
private Map<String, UserInfo> userCache = new HashMap<>();
public void putUser(UserInfo user) {
userCache.put(user.getUid(), user);
}
public UserInfo getUser(String uid) {
if (!userCache.containsKey(uid)) {
throw new RuntimeException("user not found");
}
return userCache.get(uid);
}
public void removeUser(String uid) {
userCache.remove(uid);
}
public boolean hasUser(String uid) {
return userCache.containsKey(uid);
}
}
为了满足业务场景需要,上述代码实现的缓存对外提供几个功能接口:
| 接口名称 | 功能说明 |
|---|---|
| putUser | 将指定的用户信息存储到缓存中 |
| getUser | 根据UID获取对应的用户信息数据 |
| removeUser | 删除指定UID对应的用户缓存数据 |
| hasUser | 判断指定的用户是否存在 |
使用HashMap构建缓存,可以轻松的实现O(1)复杂度的数据操作,执行性能可以得到有效保障。这也是为什么HashMap被广泛使用在缓存场景中的原因。
容量约束 —— 支持数据淘汰与容量限制的缓存
通过类似HashMap的结构来缓存数据是一种简单的缓存实现策略,可以解决很多查询场景的实际诉求,但是在使用中,有些问题也会慢慢浮现。
在线上问题定位过程中,经常会遇到一些内存溢出的问题,而这些问题的原因,很大一部分都是由于对容器类的使用不加约束导致的。
所以很多情况下,出于可靠性或者业务自身诉求考量,会要求缓存的HashMap需要有最大容量限制,如支持LRU策略,保证最多仅缓存指定数量的数据。
比如在上一节中,为了提升根据UID查询用户信息的效率,决定将用户信息缓存在内存中。但是这样一来:
-
论坛的用户量是在一直增加的,这样就会导致加载到内存中的用户数据量也会越来越大,内存占用就会
无限制增加,万一用户出现井喷式增长,很容易会把内存撑满,造成内存溢出问题; -
论坛内的用户,其实有很多用户注册之后就是个僵尸号,或者是最近几年都没有再使用系统了,这些数据加载到内存中,业务几乎不会使用到,白白占用内存而已。
这种情况,就会涉及到我们在前面文章中提到的一个缓存的基础特性了 —— 缓存淘汰机制!也即支持热点数据存储而非全量数据存储。我们可以对上一节实现的缓存进行一个改造,使其支持限制缓存的最大容量条数,如果超过此条数,则基于LRU策略来淘汰最不常用的数据。
我们可以基于LinkedHashMap来实现。比如我们可以先实现一个支持LRU的缓存容器LruHashMap,代码示例如下:
public class LruHashMap<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = 1287190405215174569L;
private int maxEntries;
public LruHashMap(int maxEntries, boolean accessOrder) {
super(16, 0.75f, accessOrder);
this.maxEntries = maxEntries;
}
/**
* 自定义数据淘汰触发条件,在每次put操作的时候会调用此方法来判断下
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxEntries;
}
}
如上面实现的缓存容器,提供了一个构造方法,允许传入两个参数:
-
maxEntities :此缓存容器允许存储的最大记录条数。
-
accessOrder :决定数据淘汰排序策略。传入
true则表示基于LRU策略进行排序,false则表示基于数据写入先后进行排序。
往缓存里面写入新数据的时候,会判断缓存容器中的数据量是否超过maxEntities,如果超过就会基于accessOrder所指定的排序规则进行数据排序,然后将排在最前面的元素给删除,挪出位置给新的待插入数据。
我们使用此改进后的缓存容器,改写下前面的缓存实现:
public class UserCache {
private Map<String, UserInfo> userCache = new LruHashMap<>(10000, true);
public void putUser(UserInfo user) {
userCache.put(user.getUid(), user);
}
public UserInfo getUser(String uid) {
// 因为是热点缓存,非全量,所以缓存中没有数据,则尝试去DB查询并加载到内存中(演示代码,忽略异常判断逻辑)
if (!userCache.containsKey(uid)) {
UserInfo user = queryFromDb(uid);
putUser(user);
return user;
}
return userCache.get(uid);
}
}
相比于直接使用HashMap来构建的缓存,改造后的缓存增加了基于LRU策略进行数据淘汰的能力,可以限制缓存的最大记录数,既可以满足业务上对缓存数据有要求的场景使用,又可以规避因为调用方的原因导致的缓存无限增长然后导致内存溢出的风险,还可以减少无用冷数据对内存数据的占用浪费。
线程并发场景
为了减少内存浪费、以及防止内存溢出,我们上面基于LinkedHashMap定制打造了个支持LRU策略的限容缓存器,具备了更高级别的可靠性。但是作为缓存,很多时候是需要进程内整个系统全局共享共用的,势必会涉及到在并发场景下去调用缓存。
而前面我们实现的几种策略,都是非线程安全的,适合局部缓存或者单线程场景使用。多线程使用的时候,我们就需要对前面实现进行改造,使其变成线程安全的缓存容器。
对于简单的不需要淘汰策略的场景,我们可以使用ConcurrentHashMap来替代HashMap作为缓存的容器存储对象,以获取线程安全保障。
而对于我们基于LinkedHashMap实现的限容缓存容器,要使其支持线程安全,可以使用最简单粗暴的一种方式来实现 —— 基于同步锁。比如下面的实现,就是在原有的LruHashMap基础上嵌套了一层保护壳,实现了线程安全的访问:
public class ConcurrentLruHashMap<K, V> {
private LruHashMap<K, V> lruHashMap;
public ConcurrentLruHashMap(int maxEntities) {
lruHashMap = new LruHashMap<>(maxEntities);
}
public synchronized V get(Object key) {
return lruHashMap.get(key);
}
public synchronized void put(K key, V value) {
lruHashMap.put(key, value);
}
private static class LruHashMap<K, V> extends LinkedHashMap<K, V> {
private int maxEntities;
public LruHashMap(int maxEntities) {
super(16, 0.75f, true);
this.maxEntities = maxEntities;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxEntities;
}
}
}
为了尽量降低锁对缓存操作性能的影响,我们也可以对同步锁的策略进行一些优化,比如可以基于分段锁来降低同步锁的粒度,减少锁的竞争,提升性能。
另外,Google Guava开源库中也有提供一个ConcurrentLinkedHashMap,同样支持LRU的策略,并且在保障线程安全方面的锁机制进行了优化,如果项目中有需要的话,也可以考虑直接引入对应的开源库进行使用。
曲终人散 —— TTL缓存过期机制
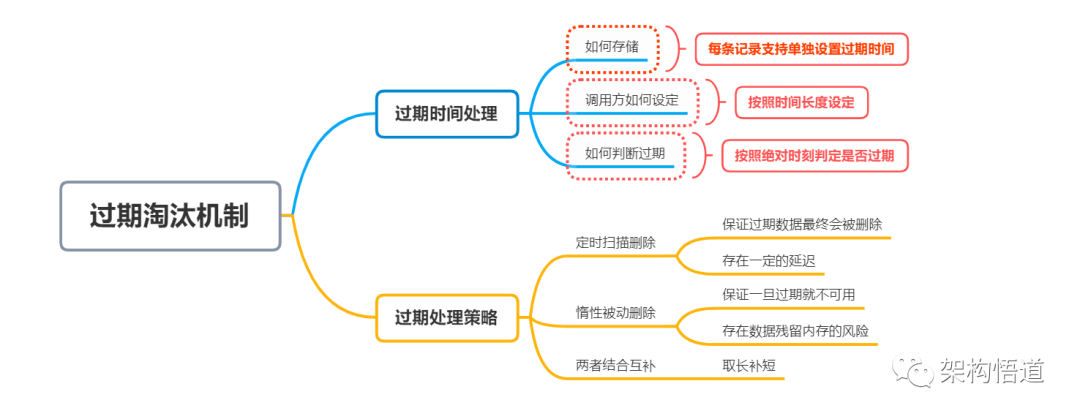
使用缓存的时候,经常会需要设置缓存记录对应的有效期,支持将过期的缓存数据删除。要实现此能力,需要确定两点处理策略:
-
如何存储每条数据的过期时间
-
何种机制去删除已经过期的数据
下面展开聊一聊。
过期时间存储与设定
既然要支持设定过期时间,也即需要将过期时间一并存储在每条记录里。对于常规的key-value类型的缓存架构,我们可以对value结构进行扩展,包裹一层公共的缓存对象外壳,用来存储一些缓存管理需要使用到的信息。比如下面这种实现:
@Data
public class CacheItem<V> {
private V value;
private long expireAt;
// 后续有其它扩展,在此补充。。。
}
其中value用来存储真实的缓存数据,而其他的一些辅助参数则可以一并随value存储起来,比如用来记录过期时间的expireAt参数。
对于过期时间的设定,一般有两种时间表述形式:
-
使用绝对时刻,比如指定2022-10-13 12:00:00过期
-
使用时间间隔,比如指定5分钟过期
对于使用方而言,显然第2种形式设置起来更加方便、也更符合业务的实际使用场景。而对于缓存实现而言,显然使用第1种方式,管理每条数据是否过期的时候会更可行(如果用时间间隔,还需要额外存储时间间隔的计时起点,或者不停的去扣减剩余时长,比较麻烦)。作为应对之策,我们可以在缓存过期时间设置的时候进行一次转换,将调用方设定的过期时间间隔,转换为实际存储的绝对时刻,这样就可以满足两者的诉求。
结合上面的结论,我们可有写出如下代码:
public class DemoCache<K, V> {
private Map<K, CacheItem<V>> cache = new HashMap<>();
/**
* 单独设置某个key对应过期时间
* @param key 唯一标识
* @param timeIntvl 过期时间
* @param timeUnit 时间单位
*/
public void expireAfter(K key, int timeIntvl, TimeUnit timeUnit) {
CacheItem<V> item = cache.get(key);
if (item == null) {
return;
}
long expireAt = System.currentTimeMillis() + timeUnit.toMillis(timeIntvl);
item.setExpireAt(expireAt);
}
/**
* 写入指定过期时间的缓存信息
* @param key 唯一标识
* @param value 缓存实际值
* @param timeIntvl 过期时间
* @param timeUnit 时间单位
*/
public void put(K key, V value, int timeIntvl, TimeUnit timeUnit) {
long expireAt = System.currentTimeMillis() + timeUnit.toMillis(timeIntvl);
CacheItem<V> item = new CacheItem<>();
item.setValue(value);
item.setExpireAt(expireAt);
cache.put(key, item);
}
// 省略其他方法
}
上面代码中,支持设定不同的时长单位,比如是Second、Minute、Hour、Day等,这样可以省去业务方自行换算时间长度的操作。并且,提供了一个2个途径设定超时时间:
-
独立接口指定某个数据的过期时长
-
写入或者更新缓存的时候直接设置对应的过期时长
而最终存储的时候,也是在缓存内部将调用方设定的超时时长信息,转换为了一个绝对时间戳值,这样后续的缓存过期判断与数据清理的时候就可以直接使用。
具体业务调用的时候,可以根据不同的场景,灵活的进行过期时间的设定。比如当我们登录的时候会生成一个token,我们可以将token信息缓存起来,使其保持一定时间内有效:
public void afterLogin(String token, User user) {
// ... 省略业务逻辑细节
// 将新创建的帖子加入缓存中,缓存30分钟
cache.put(token, user, 30, TimeUnit.MINUTES);
}
而对于一个已有的记录我们也可以单独去设置,这种经常使用于在缓存续期的场景中。比如上面说的登录成功后会将token信息缓存30分钟,而这个时候我们希望用户如果一直在操作的话,就不要使其token失效,否则使用到一半就要求用户重新登录,这种体验就会很差。我们可以这样:
public PostInfo afterAuth(String token) {
// 每次使用后,都重新设置过期时间为30分钟后(续期)
cache.expireAfter(token, 30, TimeUnit.MINUTES);
}
这样一来,只要用户登录后并且一直在做操作,token就一直不会失效,直到用户连续30分钟未做任何操作的时候,token才会从缓存中被过期删除。
过期数据删除机制
上面一节中,我们已经确定了缓存过期时间的存储策略,也给定了调用方设定缓存时间的操作接口。这里还剩一个最关键的问题需要解决:对于设定了过期时间的数据,如何在其过期的时候使其不可用?下面给出三种处理的思路。
定时清理
这是最容易想到的一种实现,我们可以搞个定时任务,定时的扫描所有的记录,判断是否有过期,如果过期则将对应记录删除。因为涉及到多个线程对缓存的数据进行处理操作,出于并发安全性考虑,我们的缓存可以采用一些线程安全的容器(比如前面提过的ConcurrentHashMap)来实现,如下所示:
public class DemoCache<K, V> {
private Map<K, CacheItem<V>> cache = new ConcurrentHashMap<>();
public DemoCache() {
timelyCleanExpiredItems();
}
private void timelyCleanExpiredItems() {
new Timer().schedule(new TimerTask() {
@Override
public void run() {
cache.entrySet().removeIf(entry -> entry.getValue().hasExpired());
}
}, 1000L, 1000L * 10);
}
// 省略其它方法
}
这样,我们就可以根据缓存的总体数据量以及缓存对数据过期时间的精度要求,来设定一个合理的定时执行策略,比如我们设定每隔10s执行一次过期数据清理任务。那么当一个任务过期之后,最坏情况可能会在过期10s后才会被删除(所以过期时间精度控制上会存在一定的误差范围)。
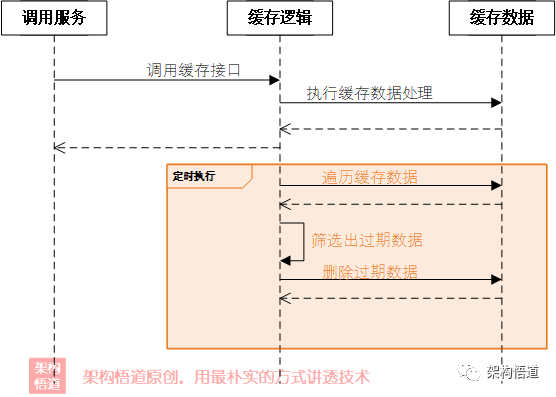
此外,为了尽可能保证控制的精度,我们就需要将定时清理间隔尽可能的缩短,但是当缓存数据量较大时,频繁的全量扫描操作,也会对系统性能造成一定的影响。
惰性删除
这是另一种数据过期的处理策略,与定时清理这种主动出击的激进型策略相反,惰性删除不会主动去判断缓存是否失效,而是在使用的时候进行判断。每次读取缓存的时候,先判断对应记录是否已经过期,如果过期则直接删除并且告知调用方没有此缓存数据。
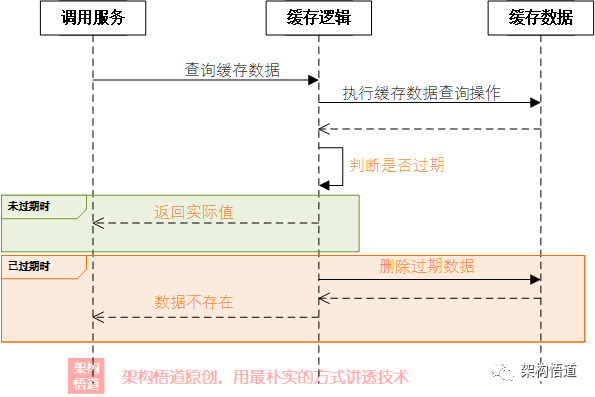
代码如下所示:
public class DemoCache<K, V> {
private Map<K, CacheItem<V>> cache = new HashMap<>();
/**
* 从缓存中查询对应值
* @param key 缓存key
* @return 缓存值
*/
public V get(K key) {
CacheItem<V> item = cache.get(key);
if (item == null) {
return null;
}
// 如果已过期,则删除,并返回null
if (item.hasExpired()) {
cache.remove(key);
return null;
}
return item.getValue();
}
// 省略其它方法
}
相比于定时清理机制,基于惰性删除的策略,在代码实现上无需额外的独立清理服务,且可以保证数据一旦过期后立刻就不可用。但是惰性删除也存在一个很大的问题,这种依靠外部调用来触发自身数据清理的机制不可控因素太多,如果一个记录已经过期但是没有请求来查询它,那这条已过期的记录就会一直驻留在缓存中,造成内存的浪费。
两者结合
如前所述,不管是主动出击的定时清理策略,还是躺平应付的惰性删除,都不是一个完美的解决方案:
-
定时清理可以保证内存中过期数据都被删除,但是频繁执行易造成性能影响、且过期时间存在精度问题
-
惰性删除可以保证过期时间控制精准,且可以解决性能问题,但是易造成内存中残留过期数据无法删除的问题
但是上述两种方案的优缺点恰好又是可以相互弥补的,所以我们可以将其结合起来使用,取长补短。
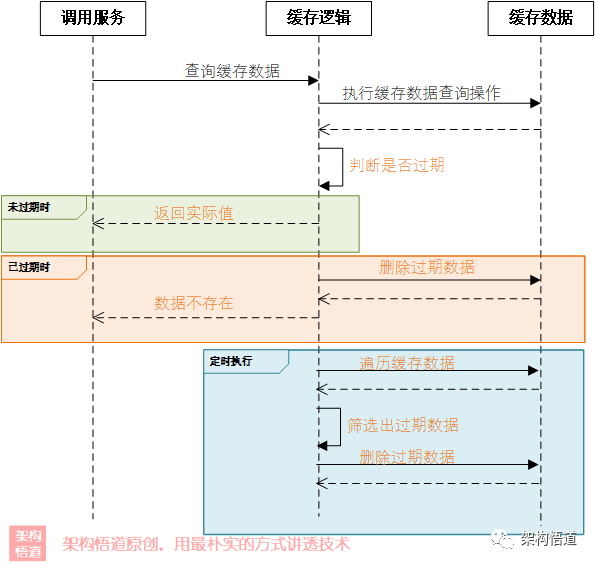
看下面的实现:
public class DemoCache<K, V> {
private Map<K, CacheItem<V>> cache = new ConcurrentHashMap<>();
public DemoCache() {
timelyCleanExpiredItems();
}
private void timelyCleanExpiredItems() {
new Timer().schedule(new TimerTask() {
@Override
public void run() {
cache.entrySet().removeIf(entry -> entry.getValue().hasExpired());
}
}, 1000L, 1000L * 60 * 60 *24);
}
public V get(K key) {
CacheItem<V> item = cache.get(key);
if (item == null) {
return null;
}
// 如果已过期,则删除,并返回null
if (item.hasExpired()) {
cache.remove(key);
return null;
}
return item.getValue();
}
}
上面的实现中:
1.使用惰性删除策略,每次使用的时候判断是否过期并执行删除策略,保证过期数据不会被继续使用。
-
配合一个
低频定时任务作为兜底(比如24小时执行一次),用于清理已过期但是始终未被访问到的缓存数据,保证已过期数据不会长久残留内存中。由于执行频率较低,也不会对性能造成太大影响。
小结回顾
回顾下本篇的内容,作为手写本地缓存框架的前菜,我们先介绍了一些项目中本地缓存实现的几种情况,一起一些诸如淘汰策略、过期失效等能力的开发初体验。
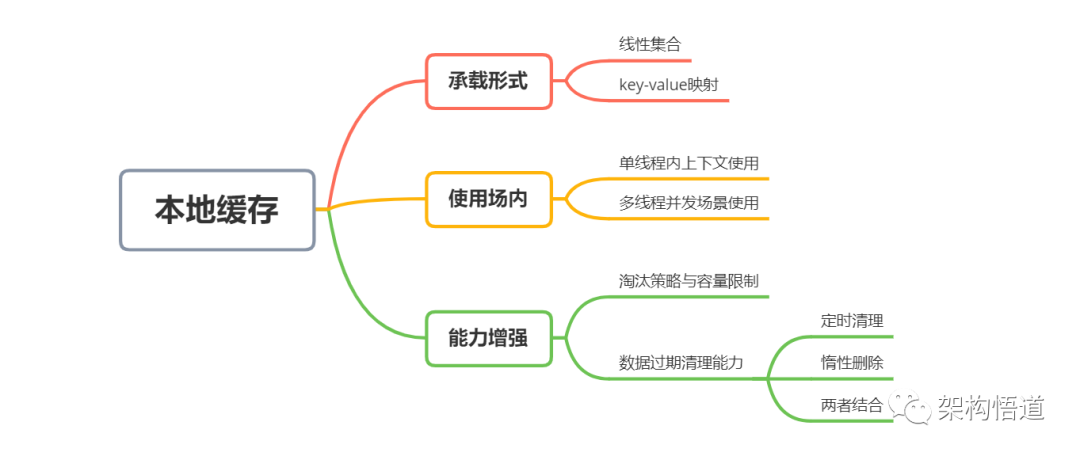
这些内容在项目开发中出现的频率极高,几乎在任何有点规模的项目中都会或多或少使用到。我们将其称之为手写本地缓存的“前菜”,是因为这些都是一些零散的独立场景应对策略,就像一个个游击队,分散出击,各自撑起自己的一小块根据地。在本篇内容的基础上,我们下一篇文章将会一起聊一聊如何在游击队经验的基础上,打造一支正规军 —— 构建一个通用化、系统化的完整本地缓存框架。
那么,关于本篇前面提到的各种“游击队”式的本地缓存,你在编码中是否有涉及过呢?你是如何实现的呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。
📣 补充说明 :
本文属于《深入理解缓存原理与实战设计》系列专栏的内容之一。该专栏围绕缓存这个宏大命题进行展开阐述,全方位、系统性地深度剖析各种缓存实现策略与原理、以及缓存的各种用法、各种问题应对策略,并一起探讨下缓存设计的哲学。
如果有兴趣,也欢迎关注此专栏。
我是悟道,聊技术、又不仅仅聊技术~
期待与你一起探讨,一起成长为更好的自己。





