
我是真没想到,这个面试题居然从11年前就开始讨论了,而官方今年才表态。原创
大家好,我是歪歪。
这期给大家盘一个面试题啊,就是下面的第二题。

这个面试题的图片都被弄的有一点“包浆”了。
所以为了你的观感,我还是把第二道题目手打一遍。
啧啧啧,这行为,暖男作者实锤了:
spring 在启动期间会做类扫描,以单例模式放入 ioc。但是 spring 只是一个个类进行处理,如果为了加速,我们取消 spring 自带的类扫描功能,用写代码的多线程方式并行进行处理,这种方案可行吗?为什么?
老实说,我第一次看到这个面试题的时候,人是懵的。

我知道 Spring 在启动期间会把 bean 放到 ioc 容器中,但是到底是单线程还是多线程放,我还真不清楚。
所以我做的第一件事情是去验证题目中这句话:但是 spring 只是一个个类进行处理。
怎么去验证呢?
肯定是找源码啊,源码之下无秘密啊。
怎么去找呢?
这个就需要你个人的经验积累了,抽丝剥茧的去翻 Spring 源码,这个就不是本文重点了,所以我就不细说了。
但是我可以教你一个我一般用的比较多的奇技淫巧。
首先你肯定要搞个 Bean 在项目里面,比如我这里的 Person:
然后把项目日志级别调整为 debug:
logging.level.root=debug
接着启动项目,在项目里面找 Person 的关键字。
原理就是这是一个 Bean,Spring 在操作它的时候一定会打印相关日志,从日志反向去查找代码,要快的多。
所以通过 Debug 日志,我们能定位到这样一行关键日志:
Identified candidate component class: xxxx.Person.class]

然后全局搜索关键字,就能找到这个地方:
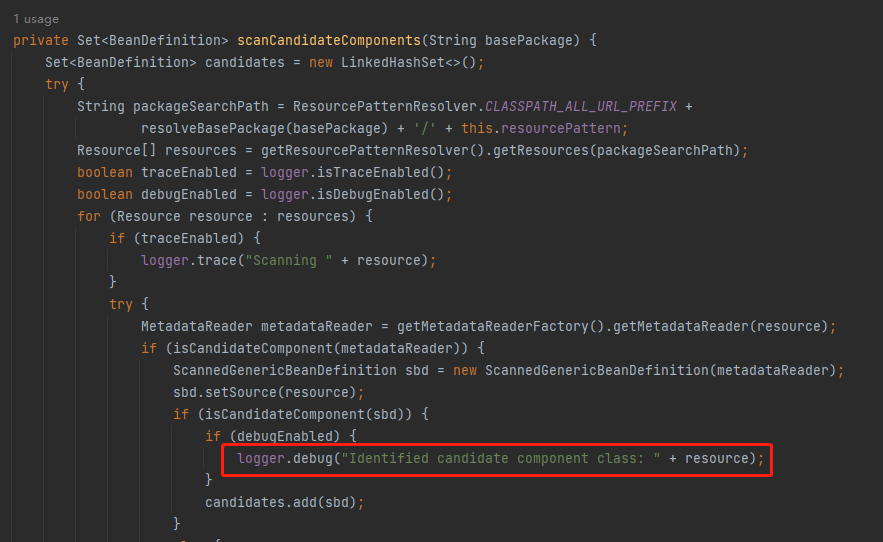
这个地方,就是打第一个断点的地方。
然后启动项目,从调用堆栈往前找,能找到这个地方:

这个类就是我要找的类:
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan
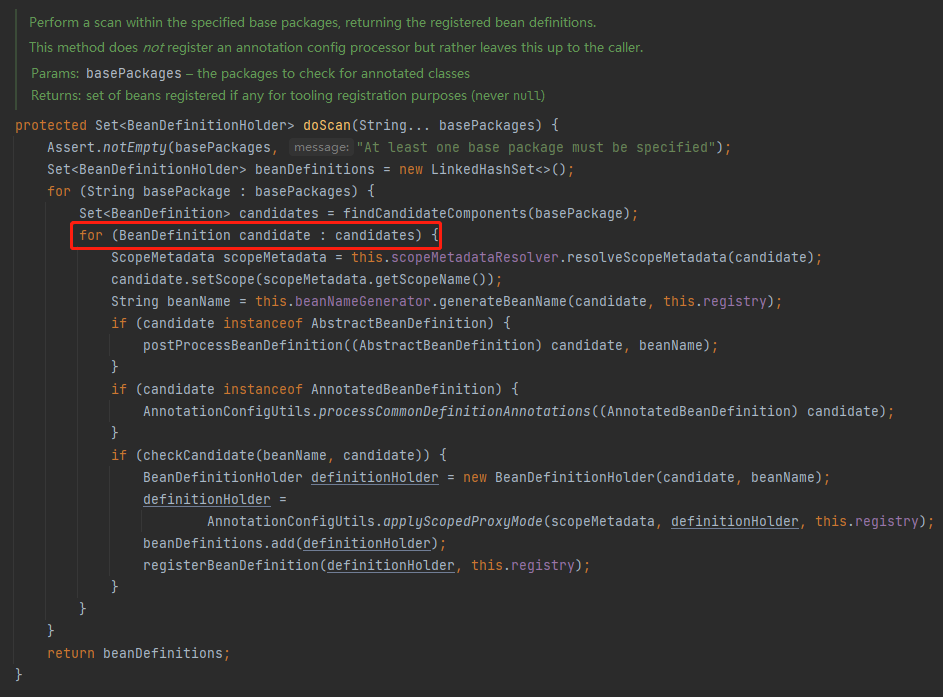
从源码上看,里面确实没有并发相关的操作,看起来确实是在 for 循环里面单线程一个个处理的 Bean 的。
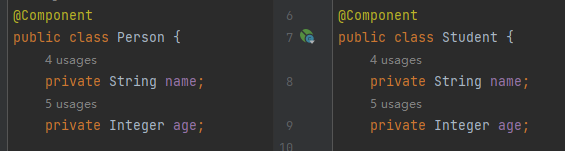
那么从理论上讲,如果是两个没有任何关联关系的 Bean,比如我下面 Person 和 Student 这两个 Bean,它们在交给 Spring 托管,往 ioc 容器里面放的时候,完全可以用两个不同的线程处理嘛:
所以问题就来了:
如果为了加速,我们取消 spring 自带的类扫描功能,用写代码的多线程方式并行进行处理,这样可以吗?
可以吗?
我也不知道啊。
但是我知道去哪里找答案。
但是在找答案之前,我先大胆的猜一个答案:不可以。
为什么?
因为我看的是 Spring 5.x 版本的源码,在这个版本里面还是单线程处理 Bean。
对于 Spring 这种使用规模如此之大的开源框架来说,如果能支持多线程加载的话,肯定老早就支持了。
所以我先盲猜一个:不可以。

找答案
这个问题的答案肯定就藏在 Spring 的 issues 里面。
不要问我为什么知道。这是来自老程序员的直觉。
所以我直接就是来到了这里:
1.2k 个 issue,怎么找到我想要找的呢?
肯定是用关键词搜索一波。基于现在掌握的信息,你说关键词是什么?
肯定是我们前面找到的这个方法、这个类啊,这也是你唯一掌握到的信息:
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan
话不多说,先拿着类名搜一搜,看看啥情况。
从搜索结果上看,真的是一搜就中:
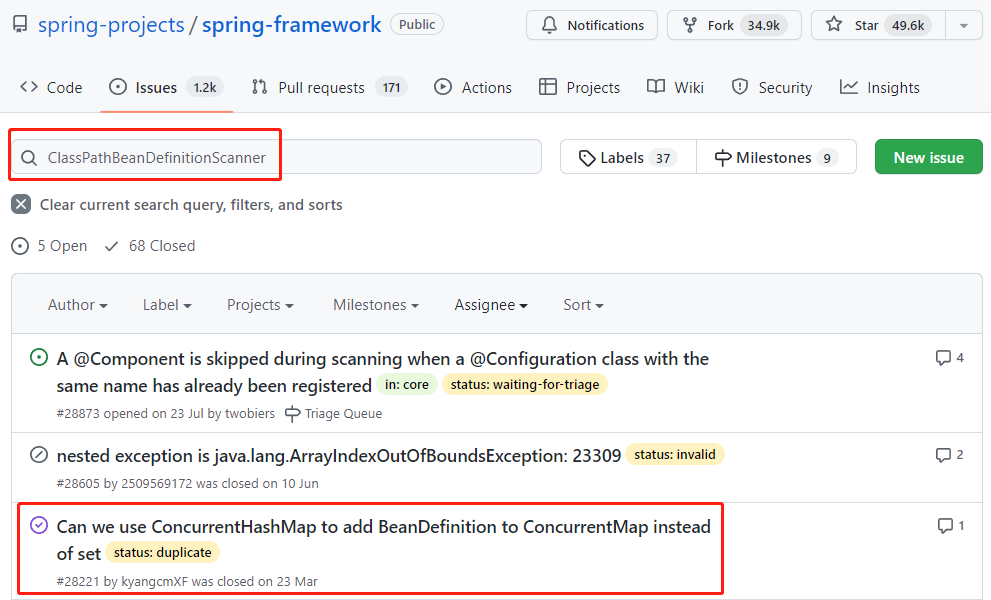
我带你看看这个 issue 的具体内容:
https://github.com/spring-projects/spring-framework/issues/28221
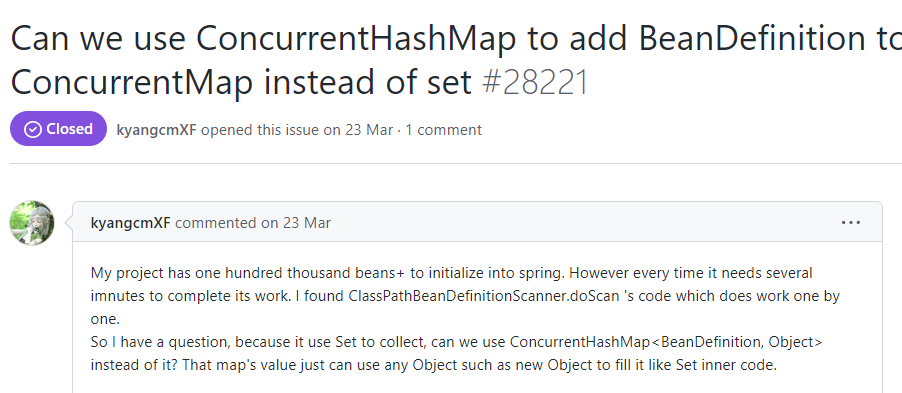
有个叫做 kyangcmXF 的同学...
呃,我第一眼看到他的名字的时候,看到有 F,K 还有 C,第一瞬间想起的是“疯狂星期四”。
那我就叫他“星期四”同学吧。
“星期四”同学说:我的项目有数以万计的 Bean 要被 Spring 初始化。所以每次项目启动的时候需要好几分钟才能完成工作。
然后他发现 doScan 的代码是单线程,一个一个的去处理 Bean 的。
所以他提出了一个问题:我是不是可以用 ConcurrentHashMap 来代替 Set 数据结果,然后并发加载。
他的问题和我们文章开头提出的面试题可以说是一模一样。而他甚至还给出了实现的代码:
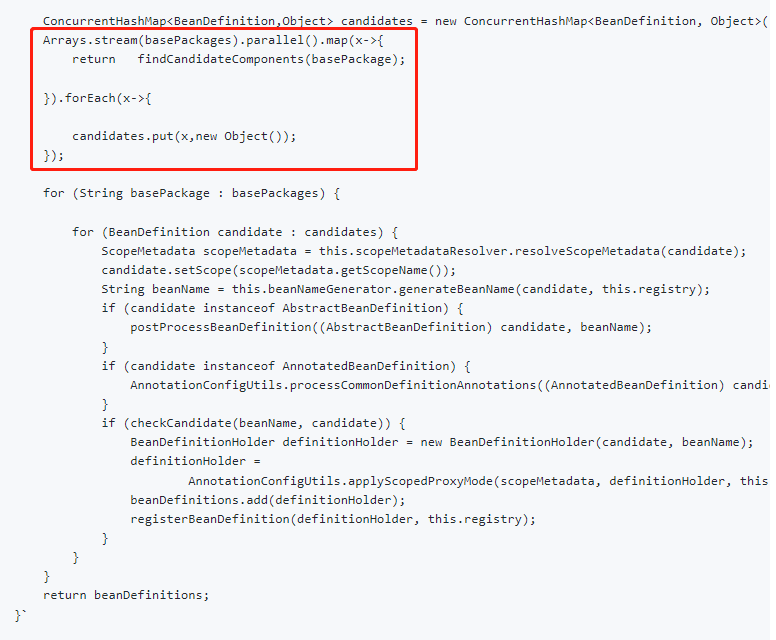
然后这个 issue 下只有一个回复,是这样的:

首先,我们先看看这条回复的人是谁:
他就是 Spring 的 Contributors,他的回答可以说就是官方回答了。
他给“星期四”同学说:thanks 老铁,but not possible。
but post-processing bean definitions asynchronously is not possible at the moment.
目前不可能异步的对 bean 进行后置处理。
到这里,我们至少知道了,想用异步加载的方式确实是在实现上有困难,不仅仅是简单的单线程改多线程。
然后,这个老哥给“星期四”同学指了条路,说如果你想要进一步了解的话,可以看看编号为 13410 的 issue。
虽然我们现在已经有一个答案了,但是既然大佬指路了,那我肯定高低得带你去瞅上一眼。

还得从11年前说起
根据大佬指路的方向,我点开这个 issue 的时候都震惊了:
https://github.com/spring-projects/spring-framework/issues/13410

题目翻译过来是“在启动期间并行的处理 Bean 的初始化”,紧扣我们的面试题。
让我震惊的主要是这个 issue 的创建时间:2011 年 10 月 12 号。
好家伙,原来 11 年前大家就提出了这个问题并进行了讨论。
但是根据我多年在 github 上冲浪的经验,遇到这种“年久失修”的 issue 不能从头到尾的看,得反着来,得先看最后一个回复是什么时候。
所以我直接就是一个拉到最后,没想到最后一个回复还挺新鲜,是三个月前:
回答的这个哥们,也是 Spring 的官方人员,所以可以理解针对这个问题的官方回答:
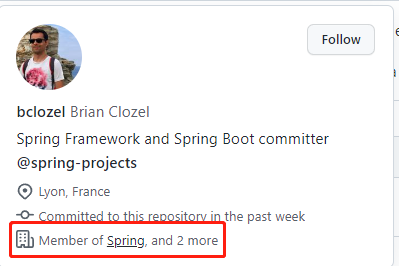
这个哥们说了很长一段,我简单的翻译一下:
他说这个问题在最新的 6.0 版本中也不会被解决,因为它目前的优先级并不是特别高。
在处理真正的启动案例时,我们经常发现,时间都花在少数几个相互依赖的特定 bean 上。在那里引入并行化,在很多情况下并不能节省多少,因为这并不能加快关键路径。这通常与 ORM 设置和数据库迁移有关。
你也可以使用“应用程序启动跟踪功能”(application startup tracking)为自己的应用程序收集更多这方面的信息:可以看到启动时间花在哪里以及是如何花的,以及并行化是否会改善这种情况。
对于 Spring Framework 6.0,我们正专注于本地用例的 Ahead Of Time 功能,以及启动时间的改进。
到这里,就再次证明了官方对于并行化处理 bean 的态度:

但是这个哥们的回答中倒没有说“这个功能做不了”,他说的是“经过调研,这个功能实现后的收益并不大”。
而且他还透露了一个关键的信息,针对 Spring 启动速度,在 6.0 里面的方向是 AOT。
其这也不算透露,早在 2020 年,甚至更早,我记得 Spring 就说过以后的努力方向是 AOT,提前编译(Ahead-of-Time Compilation)。
如果你对于 AOT 很陌生的话,可以去了解一下,不是本文重点,提一下就行。
接下来,关于这个 11 年前的帖子,里面的内容还是比较多,我只能带你简单浏览一下帖子,如果你想要了解细节的话,还得自己去看看。
首先,提出这个问题的人其实已经提出了自己的解决之道:
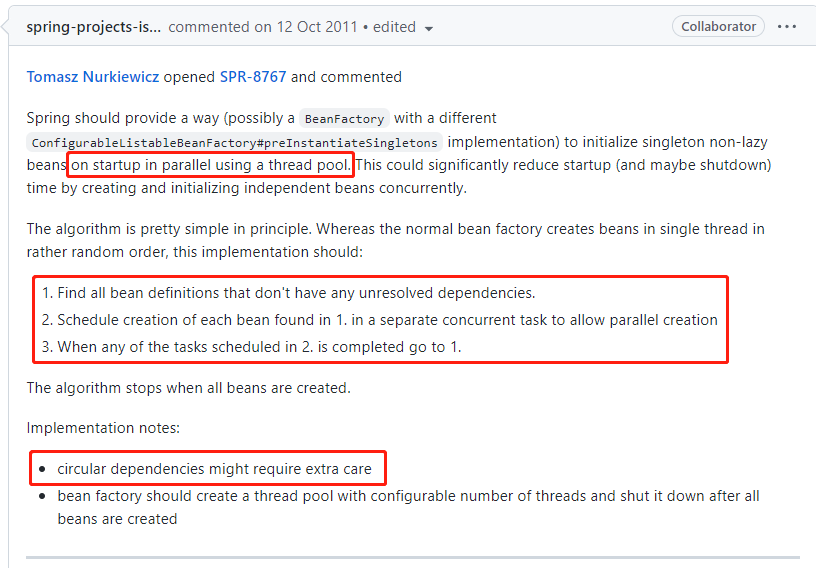
核心想法还是在 Bean 初始化的时候引入线程池,然后并发初始化 Bean。只是需要特别考虑的是存在循环依赖的 Bean。
然后官方立马就站出来对线了:
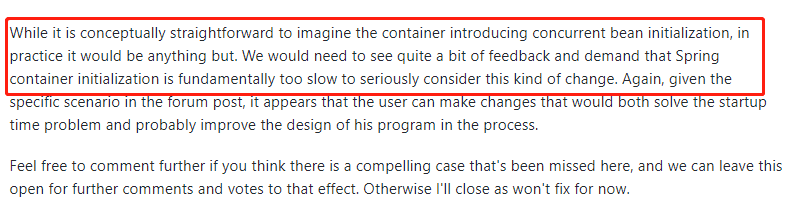
小老弟,虽然从代码上看,在 Spring 容器中引入并发的 Bean 初始化看起来是直截了当的方法,但在实现起来并非看起来这么简单。重要的是我们需要看到更多的反馈和需求,当大家都在说“Spring 容器的初始化从根本上说太慢了”,我们才会认真考虑这种改变。
接着有个老哥跳出来说:我这边有个应用启动花了 2 小时 30 分...

官方针对这个时长也表示很震惊:
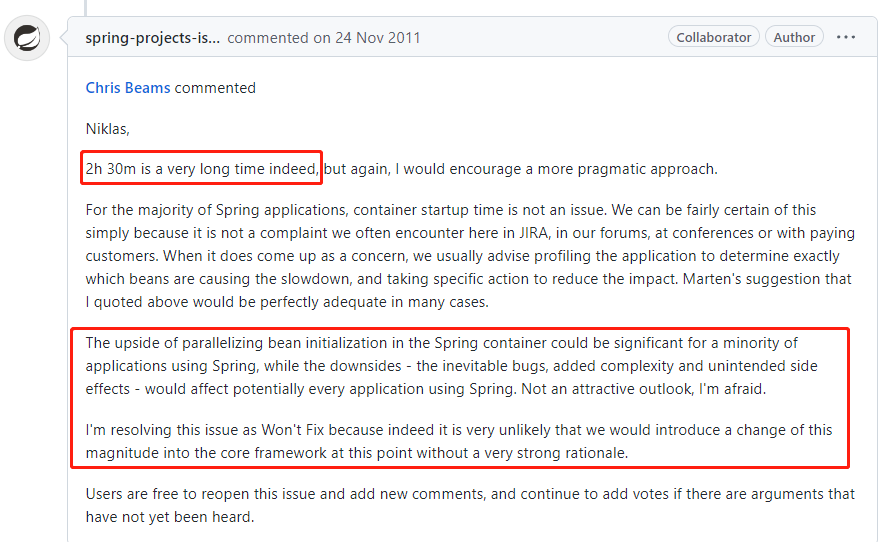
但是他们的核心观点还是:在 Spring 容器中并行化 Bean 初始化的好处对于少数使用 Spring 的应用程序来说是非常重要的,而坏处是不可避免的 Bug、增加的复杂性和意想不到的副作用,这些可能会影响所有使用 Spring 的应用程序,恐怕这不是一个有吸引力的前景。
官方还是把这个问题定义为"不会修复",因为如果没有强有力的理由,官方确实不太可能在核心框架中引入这么大的变化。
这个观点也和他的第一句话很匹配:more pragmatic approach.
more 大家都认识。
approach,也应该是一个比较熟悉的单词:

那么 pragmatic 是什么意思呢?
这个单词不认识很正常,属于生僻词,但是你知道的,我写技术文的时候顺便教单词。
pragmatic,翻译过来是“务实的”的意思:
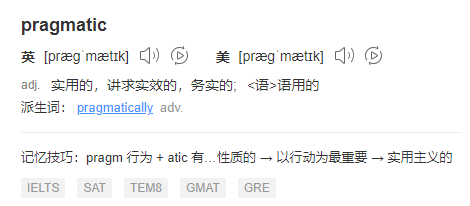
所以“more pragmatic approach”,是啥意思,来跟我大声的读一遍:更务实的方法。
官方的意思是,更务实的方法,就是先找到启动慢的根本原因,而不是把问题甩锅给 Spring,关键是这是核心逻辑,没有强有力的理由,能不动,就别动。
然后期间就是使用者和官方之间的相互扯皮,一直扯到 5 年后,也就是 2016 年 6 月 30 日:
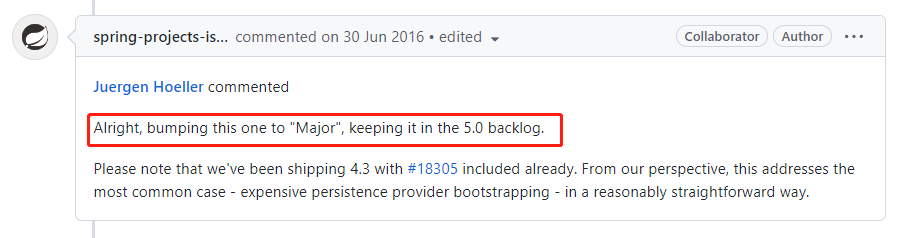
官方重要决定:好吧,把这个问题的优先级提升一下,提升为"Major"任务,保留在 5.0 的积压项目中。
但是...
好像官方这波放了鸽子。
直到 2018 年,网友又忍不住了,这个啥进度了呀?

没有回应。
又到了 2019 年,啥进度了啊,我很期待啊:
还是没有回应。
然后,时间来到了 2020 年。
三年之后又三年,现在都 9 年了,大佬,啥进度了啊?
斗转星移,白驹过隙,白云苍狗,换了人间。时间很快,来到了 2021 年。
让我们共同恭喜这个 issue 已经悬而未决 10 周年了:
最后,就是今年了,7 月 15 日,网友提问:有什么好消息了吗?
官方答:别问了,我鸽了,咋滴吧?

怎么才能快?
在寻找答案的过程中,我找到了这样的一个项目:
https://github.com/dsyer/spring-boot-allocations

这个项目是对于不同版本的 Spring Boot 做了启动时间上的基准测试。
测试的结论最终都被官方采纳了,所以还是很有权威性的。
整个测试方法和测试过程以及火焰图什么都在链接里面贴了,我就不赘述了。
只是把最后的结论搬出来,给大家看看:
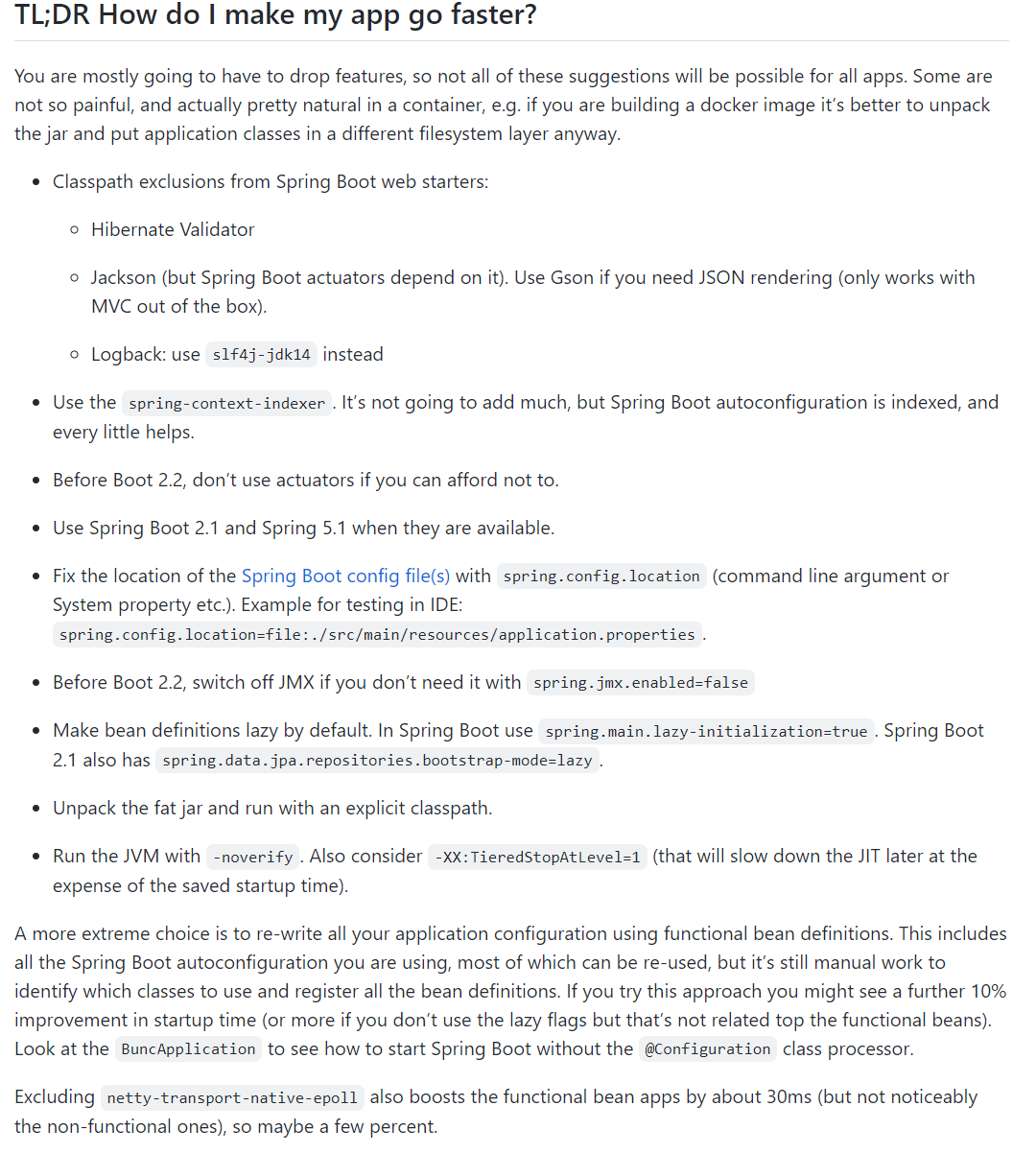
我按照自己的理解翻译一下。
首先,如果你要采用下面的方法,你就要放弃一些功能,所以不是所有的建议都能适用于所有的应用程序。
-
从 Spring Boot web starters 中排除下面这些 Classpath:Hibernate Validator;Jackson(但Spring Boot actuators 依赖于它)。如果你需要JSON渲染,请使用 Gson;Logback:使用slf4j-jdk14代替 -
使用 spring-context-indexer,它不会有很大的帮助,但是有一点点,算一点点。 -
如果可以,别使用 actuators。 -
使用 Spring Boot 2.1 和Spring 5.1 版本。当 2.2 和 5.2 可用时,升级到 2.2 和 5.2 版本 -
用 spring.config.location(命令行参数或 System 属性等)固定 Spring Boot 配置文件的位置。 -
如果你不需要 JMX,就用 spring.jmx.enabled=false 来关闭它(这是 Spring Boot 2.2 的默认值)。 -
把 Bean 设置为 lazy,也就是懒加载。在 Spring Boot 2.2 中有一个配置项 spring.main.lazy-initialization=true 可以用。 -
解压 fat jar 并以明确的 classpath 运行。 -
用 -noverify 运行JVM。也可以考虑 -XX:TieredStopAtLevel=1 。目的是关闭分层编译。
至于每个点背后的原因,答案就藏在前面说到的 issue 里面,感兴趣,自己去翻,我就是指个路,就不细说了,有兴趣自己去翻一翻。
·············· END ··············

你好呀,我是歪歪。我没进过一线大厂,没创过业,也没写过书,更不是技术专家,所以也没有什么亮眼的title。
当年高考,随缘调剂到了某二本院校计算机专业。纯属误打误撞,进入程序员的行列,之后开始了运气爆棚的程序员之路。
说起程序员之路还是有点意思,可以点击蓝字,查看我的程序员之路。



