
【译】Java HashMap的内部实现原理转载
HashMap 是Java 中用于存储键值对的数据结构,其中get()和put()操作的平均检索时间是恒定的,即O(1)。
java如何实现它,下面详细讨论:
transient HashMapEntry<K,V>[] tableHashmap 使用节点数组(命名为table),其中 Node 具有键、值等字段(等等)。这里节点由类 HashMapEntry 表示。基本上,HashMap 有一个存储键值数据的数组。它计算可以放置节点的数组中的索引,并将其放置在那里。现在在从 HashMap 中获取元素时,它再次计算要检索的元素的索引并转到数组索引并返回元素/节点的值(如果存在)。
这就是Hashmap的基本功能。
但这并不那么简单,因为也可能存在碰撞的情况。冲突是当 2 个元素具有相同的索引时。可能吗?
是的,任何 2 个元素都可以具有表数组的相同索引。
例如,Hashmap 的初始大小 = 16(默认大小)
现在假设我们插入一个元素(让它命名为 elementOne)并假设索引计算为 2,因此它将放置在表数组的索引 2 处。
如果我们再插入一个(命名为 elementTwo)并假设它的索引也是 2,那么在这种情况下会发生什么?
这是碰撞场景。
即在hashmap 中,多个元素在hashmap 表中获得相同的索引是很常见的。这里大小为 4,可能是在插入时所有元素都放在所有不同的索引中,或者在最坏的情况下,所有元素都可能指向相同的索引(碰撞),因此可能会发生碰撞情况。
为了让 hashmap 即使在发生冲突的情况下也能正常工作,我们在数组索引处设置了 LinkedList,即在索引 2 处的上述示例中,我们将使用
elementTwo -> elementOne,即这两个元素位于相同的索引处但在 LinkedList 数据结构中。因此,在取回元素时,我们首先计算索引,然后在该索引处遍历LinkedList以获取项目。
所以你一定已经猜到了 Node 结构必须至少有这些东西
a. key
b. value
c. next
这里的 next 是 LinkedList 中的下一个元素。
除了这 3 个之外,它还具有其他字段,即hash。哈希用于比较 2 个节点和计算节点的索引。
所以节点看起来像:
class HashMapEntry<K,V> {
final K key;
V value;
HashMapEntry<K,V> next;
int hash;
// Some utility methods
}所以它有一个 HashMapEntry 数组,每个 HashMapEntry 在发生冲突时都指向下一个,如下所示,灰色框代表对应索引处的节点:

放置操作:
最初,表被初始化为EMPTY_TABLE,如:
final HashMapEntry<?,?>[] EMPTY_TABLE = {};
HashMapEntry<K,V>[] table = (HashMapEntry<K,V>[]) EMPTY_TABLE;因此,在放置一个元素时,它会检查表是否为空,如果它为空,则表会膨胀,它的完成方式如下:
if (table == EMPTY_TABLE) {
table = new HashMapEntry[capacity];
}这里的容量(HashMap 的最大大小)的计算方式始终是 2 的幂。
现在在插入键值对时会增加 2 种情况。
案例1,(要插入的节点的)键为空
如果键为空,则表迭代第一个表索引(空节点始终插入索引 0)以查找是否已经存在任何空键。如果已经存在空值,则将其值替换为新值,并返回旧值。
for (HashMapEntry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) { // Found the null key
V oldValue = e.value;
e.value = value;
return oldValue;
}
}如果没有插入空键的节点,则在 0 索引处插入此节点。
由于要插入到第 0 个 Index,所以 hash 为 0,index = 0。
注意:我们无法计算 null Node 的 hash,所以 null Node 的 hashcode 取为 0
。第一次,返回 null,表示之前没有插入任何 Node 将 null 键。
注意: put() 方法插入节点,如果之前已经存在具有相同 Key 的节点,则返回之前的值。如果是第一次插入,则返回 null。
后面会讨论如何添加节点。
案例2,(要插入的节点的)键不为空
如果要插入的节点的键不为空,则计算如下:
a.
密钥b的哈希码。将节点放置在
的索引 索引是根据哈希码和表的当前长度计算的,因此索引始终在数组长度内。
现在迭代 table[index] 以检查是否已经存在具有相同键的节点。
for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// Means there is already the Node with same key present.
V oldValue = e.value;
e.value = value;
return oldValue;
}
}因此它在 table[i] 处迭代(i= 在步骤 b 计算的索引)并检查是否已经存在节点。
如果 Node 存在,它的值被替换并返回旧值,就像 null 情况下所做的那样(当已经存在带有 null 键的 Node 时)。
注意:要检查 2 个节点是否相等,哈希码和等号都会出现,从上面的代码可以看出。
为了比较这 2 个节点,它检查它们的哈希码是否相等,以及它们的相等是否也返回 true。
因此,对于任何被视为 hashmap 键的对象,我们必须覆盖该对象中的 hashcode 和 equals 方法,以便可以有效地检查它们是否相等。
如果没有找到这样的键,则将新节点添加到哈希图中。
将节点添加到哈希图中:
要添加节点,我们需要它的哈希码、索引、键和值。
对于 Node 来说,key、hash、index 都是 0和提供的值。
对于非空key节点,计算hash和index,提供key和value。
在添加新节点时,我们检查 Hashmap 的当前大小是否大于阈值。
Threshold的值是loadfactor*capacity
Capacity 是 HashMap 的最大大小在表格膨胀时设置阈值,如下所示:
浮动阈值浮动=容量*负载因子;
if (thresholdFloat > MAXIMUM_CAPACITY + 1) {
thresholdFloat = MAXIMUM_CAPACITY + 1;
}
阈值 = (int) 阈值浮动;所以阈值的意思是如果当前大小超过这个值,那么HashMap就需要resize。
现在阈值是 0.75*容量,即如果哈希图的当前值大于总大小集的 0.75,则调整它的大小。
我们也可以设置 loadFactor,但它的默认值为 0.75
因此,如果大小超过阈值,则调整哈希图的大小。
在调整它的大小时,计算新容量并将所有节点复制到新容量哈希图中。
注意: HashMap 的新大小是之前大小的两倍。
为什么我们需要调整HashMap 的大小?
这是因为如果大小是固定的,并且随着越来越多的元素添加到 hashmap,那么将会有越来越多的冲突,因此会维护更长的链表,因此对它们的迭代将不再是恒定的时间,但可能会上升到 O( n)。因此,为了更均匀地分布节点,一旦其中的节点总数超过某个阈值,请调整哈希图的大小。
所以要调整大小:
HashMapEntry[] newTable = new HashMapEntry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);创建具有新容量(= 先前容量的两倍)的新 Hashmap,表现在指向它,并创建新阈值。
最后,旧元素被转移到这个新的 Hashmap 中:
void transfer(HashMapEntry[] newTable) {
int newCapacity = newTable.length;
for (HashMapEntry<K,V> e : table) {
while(null != e) {
HashMapEntry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}我们遍历每个表索引,在每个索引处我们遍历 LinkedList 的所有元素。
在每个数组索引处,找到的元素为“e”。
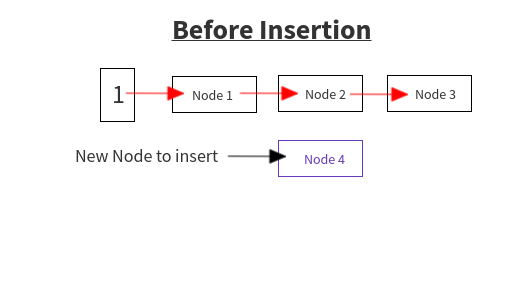
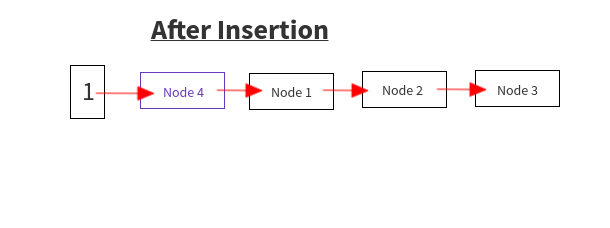
现在,让我们假设在索引“i”处我们有插入前的状态,如图所示。
在遍历旧的 HashMap 时,我们得到了节点(节点 4)。计算索引以将其插入新的 HashMap。设索引为“i”
所以插入如上代码:
设e即要插入的 Node 即Node 4
e.next = null (Node4 不指向任何 Node)
计算新的索引来插入它,即i(如上所述)
e.next = newtable[i]
即Node4 -> Node1因为 newTable[i] 具有节点 1
newTable[i] = e
即新表现在指向新插入的节点,即Node4而不是 Node1。
newtable[i] = Node1 -> Node2 -> Node 3
改为
newtable[i] = Node 4 -> Node1 -> Node2 -> Node 3
因此节点被插入到新表中。
同样,所有节点都插入到新的 Hashmap 中。
最后,在Hashmap调整大小后,即所有旧数据都被复制到新的Hashmap并增加了大小(如果大小超过阈值,只有在调整大小时才会完成),可以插入新节点。
到目前为止,只有旧数据被添加到大小增加的新 hashmap 中。
createEntry() 阶段:
在这个方法中,条目最终被添加到一个 hashmap 中。
所以新节点计算哈希,索引插入方式如上图类似。
让插入它的索引为 i。
让索引 i 的状态为
table[i] -> Node1 -> Node2
现在将 Node3 插入其中,
插入后 table[i] 将是:
table[i] -> Node 3 -> Node1 -> Node2
所以新节点被插入到索引处所有节点的顶部。
HashMapEntry<K,V> e = table[bucketIndex];
table[bucketIndex] = new HashMapEntry<>(hash, key, value, e);这里的e 指向我们示例中的Node1,即插入前表[index] 处的节点。
现在 table[index] 指向 new HashMapEntry<>(hash, key, value, e); 现在创建了指向 Node3 的方法,并且 table[index] 指向它。
不是 Node3 也必须指向 Node1,否则 Node1 LinkedList 将丢失。
它是通过在创建节点 3 时将节点 1 指向下一个来完成的。
HashMapEntry<K,V> e = table[bucketIndex]; // points to Node1
table[bucketIndex] = new HashMapEntry<>(hash, key, value, e); // i.e. Node1 is passedHashMapEntry<>(hash, key, value, e) 的签名是:
HashMapEntry(int h, K k, V v, HashMapEntry<K,V> n) {
value = v;
key = k;
hash = h;
next = n; // new Node i.e. Node3 is created with its next pointing to n which is Node1 passed.
}因此值被插入。
所以完整的 put() 方法是:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
int i = indexFor(hash, table.length);
for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}获取操作:
Get 匹配 hashcode 和 equals 后找到 Node 的值。
如果没有找到这样的节点,则返回 null。
它检查作为输入提供的键是否为空。
情况 1:(要搜索的节点的)
键为空 如果键为空,它会遍历表 [0],即第 0 个索引以在那里找到任何空键。如果找到,则返回键的值,如果空键不存在,则返回 null。
for (HashMapEntry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;情况 2:(要搜索的节点的)键不为空
如果键不为空,它会计算哈希码,然后计算要搜索的索引。
然后它遍历 table[index],检查 hashcode 和 equals,如果键匹配则返回值,否则返回 null。
for (HashMapEntry<K,V> e = table[index]; e != null; e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e.value;
}
return null;所以完整的 get() 方法是:
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}


