
全面吃透JAVA Stream流操作,让代码更加的优雅原创
在JAVA中,涉及到对数组、Collection等集合类中的元素进行操作的时候,通常会通过循环的方式进行逐个处理,或者使用Stream的方式进行处理。
例如,现在有这么一个需求:
从给定句子中返回单词长度大于5的单词列表,按长度倒序输出,最多返回3个
在JAVA7及之前的代码中,我们会可以照如下的方式进行实现:
/**
* 【常规方式】
* 从给定句子中返回单词长度大于5的单词列表,按长度倒序输出,最多返回3个
*
* @param sentence 给定的句子,约定非空,且单词之间仅由一个空格分隔
* @return 倒序输出符合条件的单词列表
*/
public List<String> sortGetTop3LongWords(@NotNull String sentence) {
// 先切割句子,获取具体的单词信息
String[] words = sentence.split(" ");
List<String> wordList = new ArrayList<>();
// 循环判断单词的长度,先过滤出符合长度要求的单词
for (String word : words) {
if (word.length() > 5) {
wordList.add(word);
}
}
// 对符合条件的列表按照长度进行排序
wordList.sort((o1, o2) -> o2.length() - o1.length());
// 判断list结果长度,如果大于3则截取前三个数据的子list返回
if (wordList.size() > 3) {
wordList = wordList.subList(0, 3);
}
return wordList;
}
在JAVA8及之后的版本中,借助Stream流,我们可以更加优雅的写出如下代码:
/**
* 【Stream方式】
* 从给定句子中返回单词长度大于5的单词列表,按长度倒序输出,最多返回3个
*
* @param sentence 给定的句子,约定非空,且单词之间仅由一个空格分隔
* @return 倒序输出符合条件的单词列表
*/
public List<String> sortGetTop3LongWordsByStream(@NotNull String sentence) {
return Arrays.stream(sentence.split(" "))
.filter(word -> word.length() > 5)
.sorted((o1, o2) -> o2.length() - o1.length())
.limit(3)
.collect(Collectors.toList());
}
直观感受上,Stream的实现方式代码更加简洁、一气呵成。很多的同学在代码中也经常使用Stream流,但是对Stream流的认知往往也是仅限于会一些简单的filter、map、collect等操作,但JAVA的Stream可以适用的场景与能力远不止这些。
那么问题来了:Stream相较于传统的foreach的方式处理stream,到底有啥优势?
这里我们可以先搁置这个问题,先整体全面的了解下Stream,然后再来讨论下这个问题。
笔者结合在团队中多年的代码检视遇到的情况,结合平时项目编码实践经验,对Stream的核心要点与易混淆用法、典型使用场景等进行了详细的梳理总结,希望可以帮助大家对Stream有个更全面的认知,也可以更加高效的应用到项目开发中去。
Stream初相识
概括讲,可以将Stream流操作分为3种类型:
-
创建Stream
-
Stream中间处理
-
终止Steam
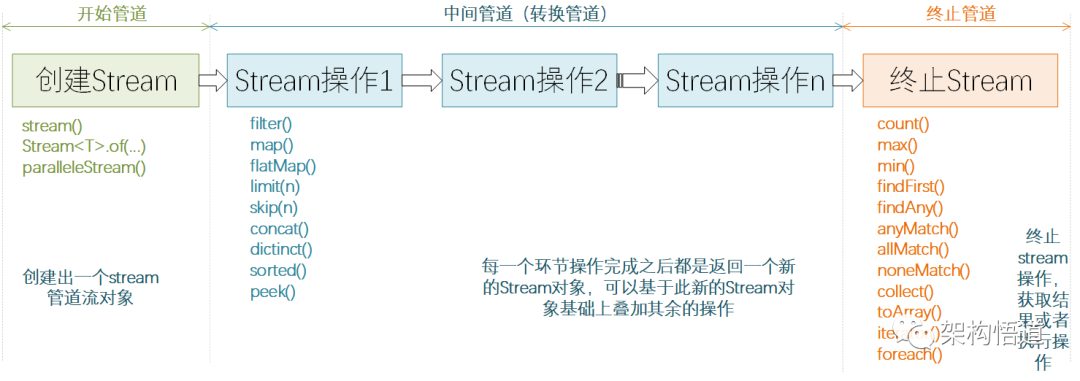
每个Stream管道操作类型都包含若干API方法,先列举下各个API方法的功能介绍。
-
开始管道
主要负责新建一个Stream流,或者基于现有的数组、List、Set、Map等集合类型对象创建出新的Stream流。
|
API |
功能说明 |
|
stream() |
创建出一个新的stream串行流对象 |
|
parallelStream() |
创建出一个可并行执行的stream流对象 |
|
Stream.of() |
通过给定的一系列元素创建一个新的Stream串行流对象 |
-
中间管道
负责对Stream进行处理操作,并返回一个新的Stream对象,中间管道操作可以进行叠加。
|
API |
功能说明 |
|
filter() |
按照条件过滤符合要求的元素, 返回新的stream流 |
|
map() |
将已有元素转换为另一个对象类型,一对一逻辑,返回新的stream流 |
|
flatMap() |
将已有元素转换为另一个对象类型,一对多逻辑,即原来一个元素对象可能会转换为1个或者多个新类型的元素,返回新的stream流 |
|
limit() |
仅保留集合前面指定个数的元素,返回新的stream流 |
|
skip() |
跳过集合前面指定个数的元素,返回新的stream流 |
|
concat() |
将两个流的数据合并起来为1个新的流,返回新的stream流 |
|
distinct() |
对Stream中所有元素进行去重,返回新的stream流 |
|
sorted() |
对stream中所有的元素按照指定规则进行排序,返回新的stream流 |
|
peek() |
对stream流中的每个元素进行逐个遍历处理,返回处理后的stream流 |
-
终止管道
顾名思义,通过终止管道操作之后,Stream流将会结束,最后可能会执行某些逻辑处理,或者是按照要求返回某些执行后的结果数据。
|
API |
功能说明 |
|
count() |
返回stream处理后最终的元素个数 |
|
max() |
返回stream处理后的元素最大值 |
|
min() |
返回stream处理后的元素最小值 |
|
findFirst() |
找到第一个符合条件的元素时则终止流处理 |
|
findAny() |
找到任何一个符合条件的元素时则退出流处理,这个对于串行流时与findFirst相同,对于并行流时比较高效,任何分片中找到都会终止后续计算逻辑 |
|
anyMatch() |
返回一个boolean值,类似于isContains(),用于判断是否有符合条件的元素 |
|
allMatch() |
返回一个boolean值,用于判断是否所有元素都符合条件 |
|
noneMatch() |
安徽一个boolean值, 用于判断是否所有元素都不符合条件 |
|
collect() |
将流转换为指定的类型,通过Collectors进行指定 |
|
toArray() |
将流转换为数组 |
|
iterator() |
将流转换为Iterator对象 |
|
foreach() |
无返回值,对元素进行逐个遍历,然后执行给定的处理逻辑 |
map与flatMap
map与flatMap都是用于转换已有的元素为其它元素,区别点在于:
-
map 必须是一对一的,即每个元素都只能转换为1个新的元素
-
flatMap 可以是一对多的,即每个元素都可以转换为1个或者多个新的元素
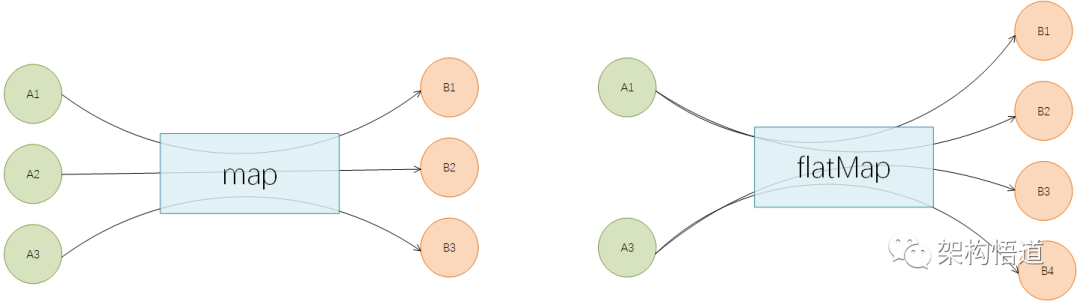
比如:有一个字符串ID列表,现在需要将其转为User对象列表。可以使用map来实现:
/**
* 演示map的用途:一对一转换
*/
public void stringToIntMap() {
List<String> ids = Arrays.asList("205","105","308","469","627","193","111");
// 使用流操作
List<Integer> results = ids.stream()
.map(s -> Integer.valueOf(s))
.collect(Collectors.toList());
System.out.println(results);
}
执行之后,会发现每一个元素都被转换为对应新的元素,但是前后总元素个数是一致的:
[User{id='205'},
User{id='105'},
User{id='308'},
User{id='469'},
User{id='627'},
User{id='193'},
User{id='111'}]
再比如:现有一个句子列表,需要将句子中每个单词都提取出来得到一个所有单词列表。这种情况用map就搞不定了,需要flatMap上场了:
public void stringToIntFlatmap() {
List<String> sentences = Arrays.asList("hello world","Jia Gou Wu Dao");
// 使用流操作
List<String> results = sentences.stream()
.flatMap(sentence -> Arrays.stream(sentence.split(" ")))
.collect(Collectors.toList());
System.out.println(results);
}
执行结果如下,可以看到结果列表中元素个数是比原始列表元素个数要多的:
[hello, world, Jia, Gou, Wu, Dao]
这里需要补充一句,flatMap操作的时候其实是先每个元素处理并返回一个新的Stream,然后将多个Stream展开合并为了一个完整的新的Stream,如下:
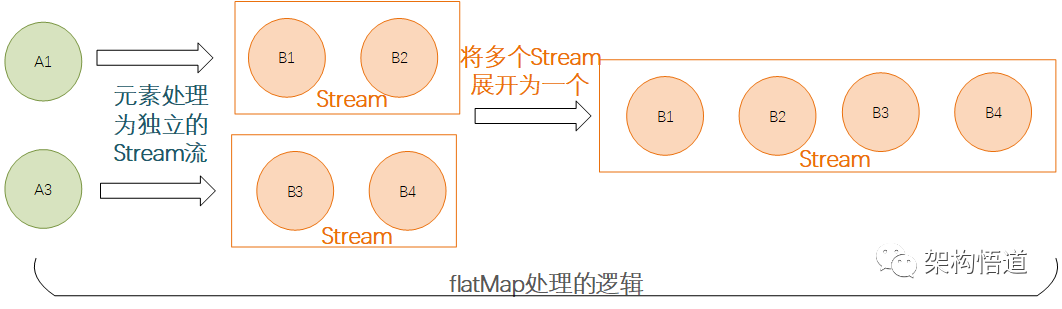
peek和foreach方法
peek和foreach,都可以用于对元素进行遍历然后逐个的进行处理。
但根据前面的介绍,peek属于中间方法,而foreach属于终止方法。这也就意味着peek只能作为管道中途的一个处理步骤,而没法直接执行得到结果,其后面必须还要有其它终止操作的时候才会被执行;而foreach作为无返回值的终止方法,则可以直接执行相关操作。
public void testPeekAndforeach() {
List<String> sentences = Arrays.asList("hello world","Jia Gou Wu Dao");
// 演示点1: 仅peek操作,最终不会执行
System.out.println("----before peek----");
sentences.stream().peek(sentence -> System.out.println(sentence));
System.out.println("----after peek----");
// 演示点2: 仅foreach操作,最终会执行
System.out.println("----before foreach----");
sentences.stream().forEach(sentence -> System.out.println(sentence));
System.out.println("----after foreach----");
// 演示点3:peek操作后面增加终止操作,peek会执行
System.out.println("----before peek and count----");
sentences.stream().peek(sentence -> System.out.println(sentence)).count();
System.out.println("----after peek and count----");
}
输出结果可以看出,peek独自调用时并没有被执行、但peek后面加上终止操作之后便可以被执行,而foreach可以直接被执行:
----before peek----
----after peek----
----before foreach----
hello world
Jia Gou Wu Dao
----after foreach----
----before peek and count----
hello world
Jia Gou Wu Dao
----after peek and count----
filter、sorted、distinct、limit
这几个都是常用的Stream的中间操作方法,具体的方法的含义在上面的表格里面有说明。具体使用的时候,可以根据需要选择一个或者多个进行组合使用,或者同时使用多个相同方法的组合:
public void testGetTargetUsers() {
List<String> ids = Arrays.asList("205","10","308","49","627","193","111", "193");
// 使用流操作
List<Dept> results = ids.stream()
.filter(s -> s.length() > 2)
.distinct()
.map(Integer::valueOf)
.sorted(Comparator.comparingInt(o -> o))
.limit(3)
.map(id -> new Dept(id))
.collect(Collectors.toList());
System.out.println(results);
}
上面的代码片段的处理逻辑很清晰:
-
使用filter过滤掉不符合条件的数据
-
通过distinct对存量元素进行去重操作
-
通过map操作将字符串转成整数类型
-
借助sorted指定按照数字大小正序排列
-
使用limit截取排在前3位的元素
-
又一次使用map将id转为Dept对象类型
-
使用collect终止操作将最终处理后的数据收集到list中
输出结果:
[Dept{id=111}, Dept{id=193}, Dept{id=205}]
简单结果终止方法
按照前面介绍的,终止方法里面像count、max、min、findAny、findFirst、anyMatch、allMatch、nonneMatch等方法,均属于这里说的简单结果终止方法。所谓简单,指的是其结果形式是数字、布尔值或者Optional对象值等。
public void testSimpleStopOptions() {
List<String> ids = Arrays.asList("205", "10", "308", "49", "627", "193", "111", "193");
// 统计stream操作后剩余的元素个数
System.out.println(ids.stream().filter(s -> s.length() > 2).count());
// 判断是否有元素值等于205
System.out.println(ids.stream().filter(s -> s.length() > 2).anyMatch("205"::equals));
// findFirst操作
ids.stream().filter(s -> s.length() > 2)
.findFirst()
.ifPresent(s -> System.out.println("findFirst:" + s));
}
执行后结果为:
6
true
findFirst:205
避坑提醒
这里需要补充提醒下,一旦一个Stream被执行了终止操作之后,后续便不可以再读这个流执行其他的操作了,否则会报错,看下面示例:
public void testHandleStreamAfterClosed() {
List<String> ids = Arrays.asList("205", "10", "308", "49", "627", "193", "111", "193");
Stream<String> stream = ids.stream().filter(s -> s.length() > 2);
// 统计stream操作后剩余的元素个数
System.out.println(stream.count());
System.out.println("-----下面会报错-----");
// 判断是否有元素值等于205
try {
System.out.println(stream.anyMatch("205"::equals));
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("-----上面会报错-----");
}
执行的时候,结果如下:
6
-----下面会报错-----
java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)
at java.util.stream.ReferencePipeline.anyMatch(ReferencePipeline.java:449)
at com.veezean.skills.stream.StreamService.testHandleStreamAfterClosed(StreamService.java:153)
at com.veezean.skills.stream.StreamService.main(StreamService.java:176)
-----上面会报错-----
因为stream已经被执行count()终止方法了,所以对stream再执行anyMatch方法的时候,就会报错stream has already been operated upon or closed,这一点在使用的时候需要特别注意。
结果收集终止方法
因为Stream主要用于对集合数据的处理场景,所以除了上面几种获取简单结果的终止方法之外,更多的场景是获取一个集合类的结果对象,比如List、Set或者HashMap等。
这里就需要collect方法出场了,它可以支持生成如下类型的结果数据:
-
一个
集合类,比如List、Set或者HashMap等 -
StringBuilder对象,支持将多个
字符串进行拼接处理并输出拼接后结果 -
一个可以记录个数或者计算总和的对象(
数据批量运算统计)
生成集合
应该算是collect最常被使用到的一个场景了:
public void testCollectStopOptions() {
List<Dept> ids = Arrays.asList(new Dept(17), new Dept(22), new Dept(23));
// collect成list
List<Dept> collectList = ids.stream().filter(dept -> dept.getId() > 20)
.collect(Collectors.toList());
System.out.println("collectList:" + collectList);
// collect成Set
Set<Dept> collectSet = ids.stream().filter(dept -> dept.getId() > 20)
.collect(Collectors.toSet());
System.out.println("collectSet:" + collectSet);
// collect成HashMap,key为id,value为Dept对象
Map<Integer, Dept> collectMap = ids.stream().filter(dept -> dept.getId() > 20)
.collect(Collectors.toMap(Dept::getId, dept -> dept));
System.out.println("collectMap:" + collectMap);
}
结果如下:
collectList:[Dept{id=22}, Dept{id=23}]
collectSet:[Dept{id=23}, Dept{id=22}]
collectMap:{22=Dept{id=22}, 23=Dept{id=23}}
生成拼接字符串
将一个List或者数组中的值拼接到一个字符串里并以逗号分隔开,这个场景相信大家都不陌生吧?
如果通过for循环和StringBuilder去循环拼接,还得考虑下最后一个逗号如何处理的问题,很繁琐:
public void testForJoinStrings() {
List<String> ids = Arrays.asList("205", "10", "308", "49", "627", "193", "111", "193");
StringBuilder builder = new StringBuilder();
for (String id : ids) {
builder.append(id).append(',');
}
// 去掉末尾多拼接的逗号
builder.deleteCharAt(builder.length() - 1);
System.out.println("拼接后:" + builder.toString());
}
但是现在有了Stream,使用collect可以轻而易举的实现:
public void testCollectJoinStrings() {
List<String> ids = Arrays.asList("205", "10", "308", "49", "627", "193", "111", "193");
String joinResult = ids.stream().collect(Collectors.joining(","));
System.out.println("拼接后:" + joinResult);
}
两种方式都可以得到完全相同的结果,但Stream的方式更优雅:
拼接后:205,10,308,49,627,193,111,193
数据批量数**算
还有一种场景,实际使用的时候可能会比较少,就是使用collect生成数字数据的总和信息,也可以了解下实现方式:
public void testNumberCalculate() {
List<Integer> ids = Arrays.asList(10, 20, 30, 40, 50);
// 计算平均值
Double average = ids.stream().collect(Collectors.averagingInt(value -> value));
System.out.println("平均值:" + average);
// 数据统计信息
IntSummaryStatistics summary = ids.stream().collect(Collectors.summarizingInt(value -> value));
System.out.println("数据统计信息: " + summary);
}
上面的例子中,使用collect方法来对list中元素值进行数**算,结果如下:
平均值:30.0
总和:IntSummaryStatistics{count=5, sum=150, min=10, average=30.000000, max=50}
并行Stream
机制说明
使用并行流,可以有效利用计算机的多CPU硬件,提升逻辑的执行速度。并行流通过将一整个stream划分为多个片段,然后对各个分片流并行执行处理逻辑,最后将各个分片流的执行结果汇总为一个整体流。
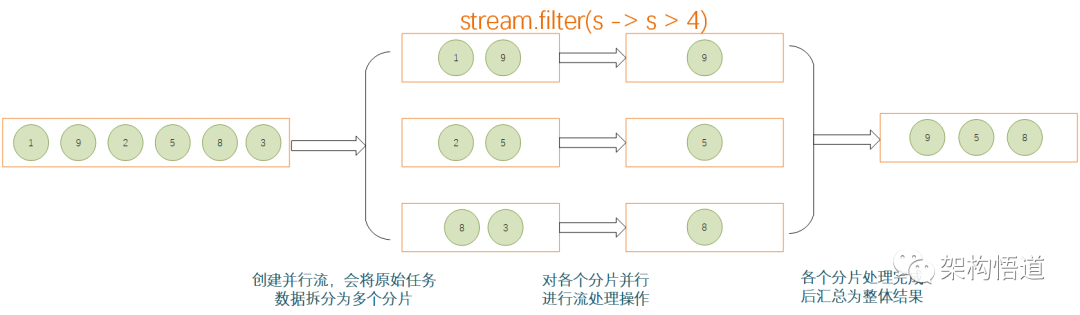
约束与限制
并行流类似于多线程在并行处理,所以与多线程场景相关的一些问题同样会存在,比如死锁等问题,所以在并行流终止执行的函数逻辑,必须要保证线程安全。
回答最初的问题
到这里,关于JAVA Stream的相关概念与用法介绍,基本就讲完了。我们再把焦点切回本文刚开始时提及的一个问题:
Stream相较于传统的foreach的方式处理stream,到底有啥优势?
根据前面的介绍,我们应该可以得出如下几点答案:
-
代码更简洁、偏声明式的编码风格,更容易体现出代码的逻辑意图
-
逻辑间解耦,一个stream中间处理逻辑,无需关注上游与下游的内容,只需要按约定实现自身逻辑即可
-
并行流场景效率会比迭代器逐个循环更高
-
函数式接口,延迟执行的特性,中间管道操作不管有多少步骤都不会立即执行,只有遇到终止操作的时候才会开始执行,可以避免一些中间不必要的操作消耗
当然了,Stream也不全是优点,在有些方面也有其弊端:
-
代码调测debug不便
-
程序员从历史写法切换到Stream时,需要一定的适应时间
总结
好啦,关于JAVA Stream的理解要点与使用技能的阐述就先到这里啦。那通过上面的介绍,各位小伙伴们是否已经跃跃欲试了呢?快去项目中使用体验下吧!当然啦,如果有疑问,也欢迎找我一起探讨探讨咯。
此外:
-
关于Stream中collect的分组、分片等进阶操作,以及对并行流的深入探讨,因为涉及内容比较多且相对独立,我会在后续的文档中展开专门介绍下,如果有兴趣的话,可以点个关注、避免迷路。
-
关于本文中涉及的演示代码的完整示例,我已经整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技术、又不仅仅聊技术~
期待与你一起探讨,一起成长为更好的自己。





