舒服了,踩到一个关于分布式锁的非比寻常的BUG!原创
你好呀,我是歪歪。
提到分布式锁,大家一般都会想到 Redis。
想到 Redis,一部分同学会说到 Redisson。
那么说到 Redisson,就不得不掰扯掰扯一下它的“看门狗”机制了。
所以你以为这篇文章我要给你讲“看门狗”吗?
不是,我主要是想给你汇报一下我最近研究的由于引入“看门狗”之后,给 Redisson 带来的两个看起来就菊花一紧的 bug :
-
看门狗不生效的 BUG。 -
看门狗导致死锁的 BUG。
为了能让你丝滑入戏,我还是先简单的给你铺垫一下,Redisson 的看门狗到底是个啥东西。

看门狗描述
你去看 Redisson 的 wiki 文档,在锁的这一部分,开篇就提到了一个单词:watchdog
https://github.com/redisson/redisson/wiki/8.-distributed-locks-and-synchronizers
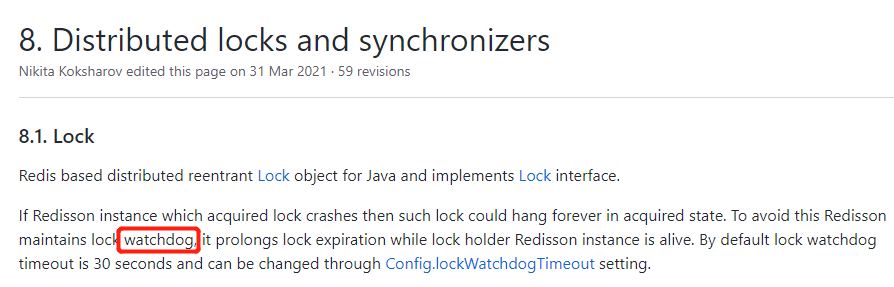
watchdog,就是看门狗的意思。
它是干啥用的呢?
好的,如果你回答不上来这个问题。那当你遇到下面这个面试题的时候肯定懵逼。
面试官:请问你用 Redis 做分布式锁的时候,如果指定过期时间到了,把锁给释放了。但是任务还未执行完成,导致任务再次被执行,这种情况你会怎么处理呢?
这个时候,99% 的面试官想得到的回答都是看门狗,或者一种类似于看门狗的机制。
如果你说:这个问题我遇到过,但是我就是把过期时间设置的长一点。
时间到底设置多长,是你一个非常主观的判断,设置的长一点,能一定程度上解决这个问题,但是不能完全解决。
所以,请回去等通知吧。
或者你回答:这个问题我遇到过,我不设置过期时间,由程序调用 unlock 来保证。
好的,程序保证调用 unlock 方法没毛病,这是在程序层面可控、可保证的。但是如果你程序运行的服务器刚好还没来得及执行 unlock 就宕机了呢,这个你不能打包票吧?
这个锁是不是就死锁了?
所以......

为了解决前面提到的过期时间不好设置,以及一不小心死锁的问题,Redisson 内部基于时间轮,针对每一个锁都搞了一个定时任务,这个定时任务,就是看门狗。
在 Redisson 实例被关闭前,这个狗子可以通过定时任务不断的延长锁的有效期。
因为你根本就不需要设置过期时间,这样就从根本上解决了“过期时间不好设置”的问题。默认情况下,看门狗的检查锁的超时时间是 30 秒钟,也可以通过修改参数来另行指定。
如果很不幸,节点宕机了导致没有执行 unlock,那么在默认的配置下最长 30s 的时间后,这个锁就自动释放了。
那么问题来了,面试官紧接着来一个追问:怎么自动释放呢?
这个时候,你只需要来一个战术后仰:程序都没了,你觉得定时任务还在吗?定时任务都不在了,所以也不会存在死锁的问题。

搞 Demo
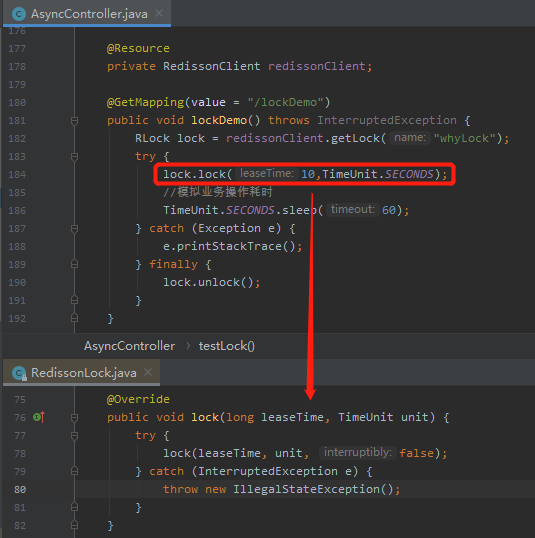
前面简单介绍了原理,我也还是给你搞个简单的 Demo 跑一把,这样更加的直观。
引入依赖,启动 Redis 什么的就不说了,直接看代码。
示例代码非常简单,就这么一点内容,非常常规的使用方法:
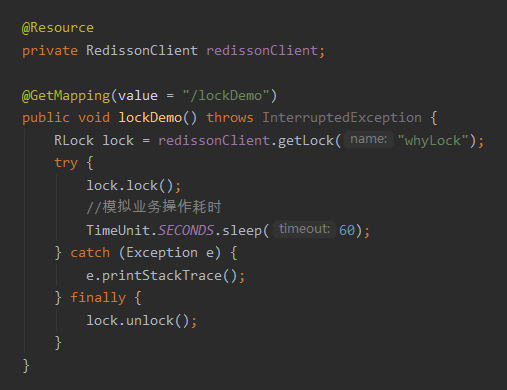
把项目启动起来,触发接口之后,通过工具观察 Redis 里面 whyLock 这个 key 的情况,是这样的:

你可以看到在我的截图里面,是有过期时间的,也就是我打箭头的地方。
然后我给你搞个动图,你仔细看过期时间(TTL)这个地方,有一个从 20s 变回 30s 的过程:
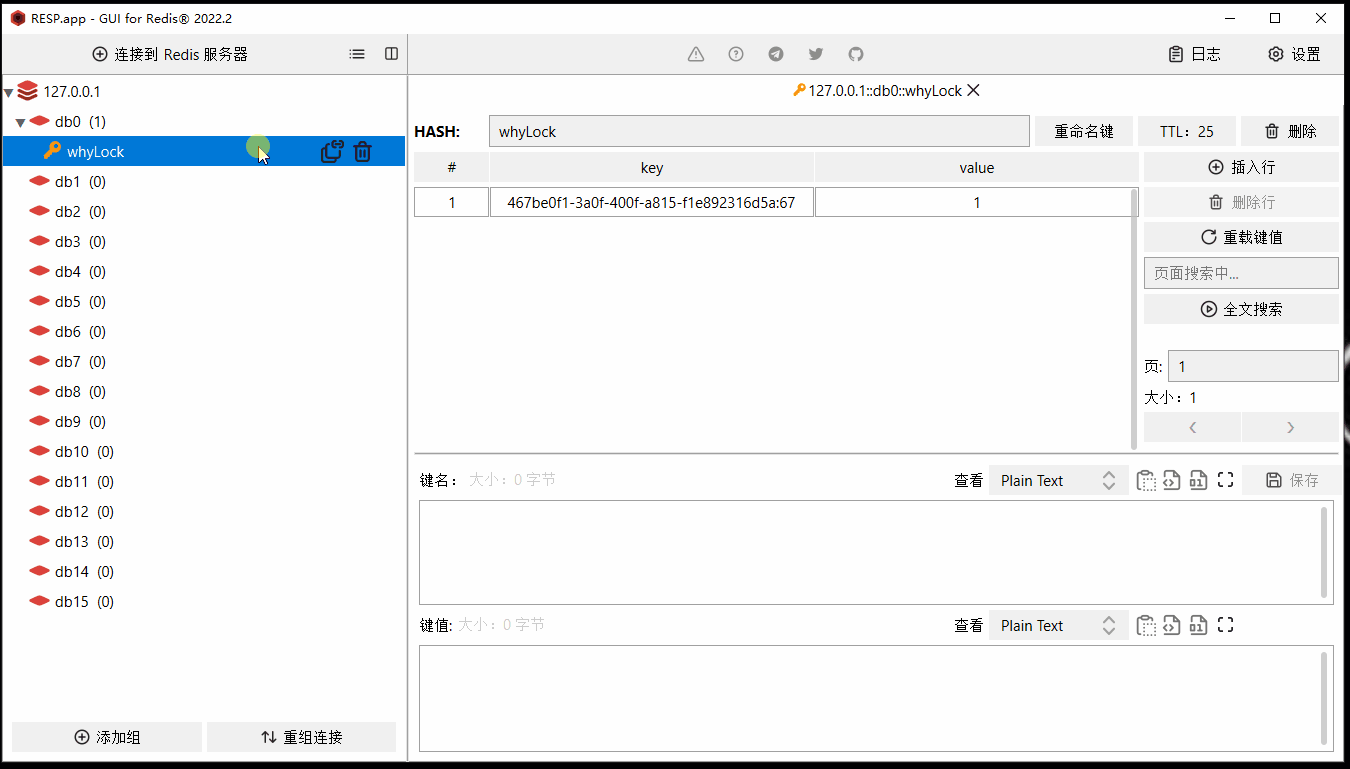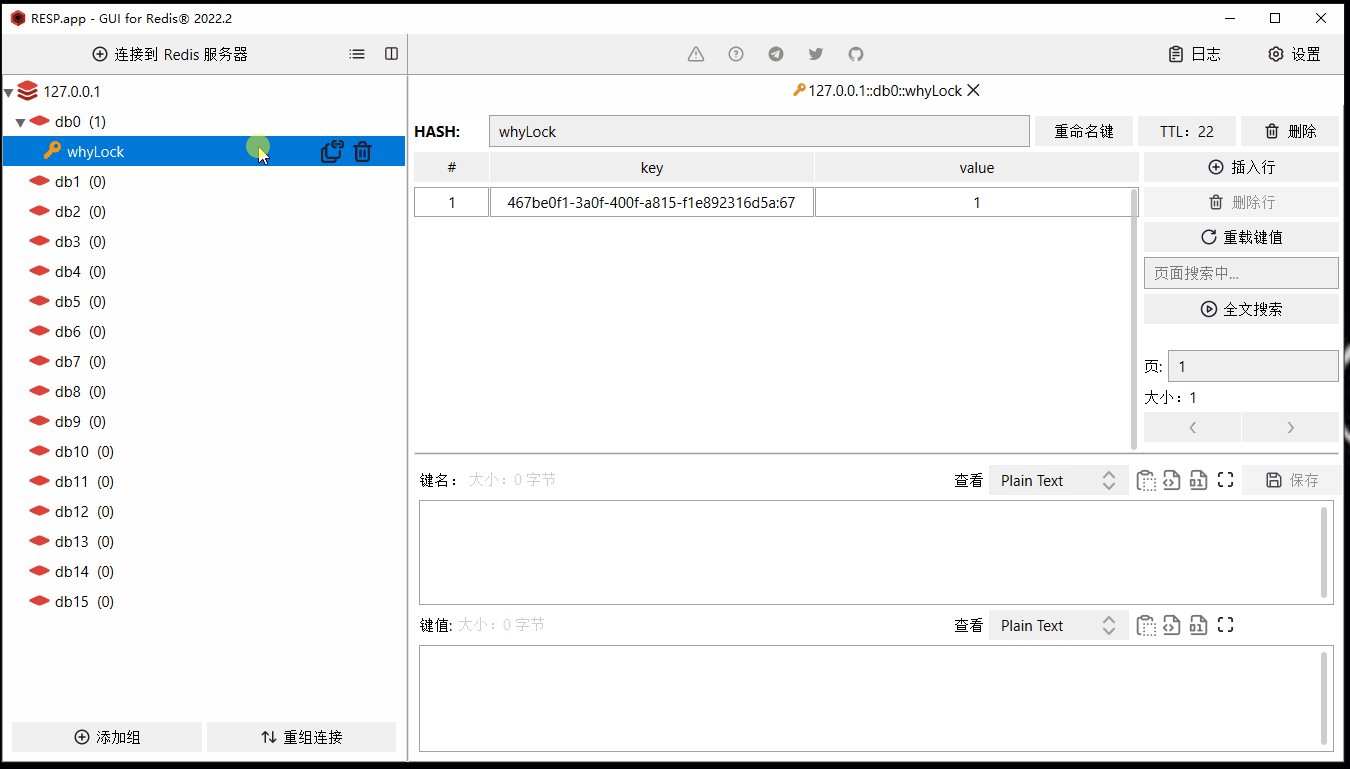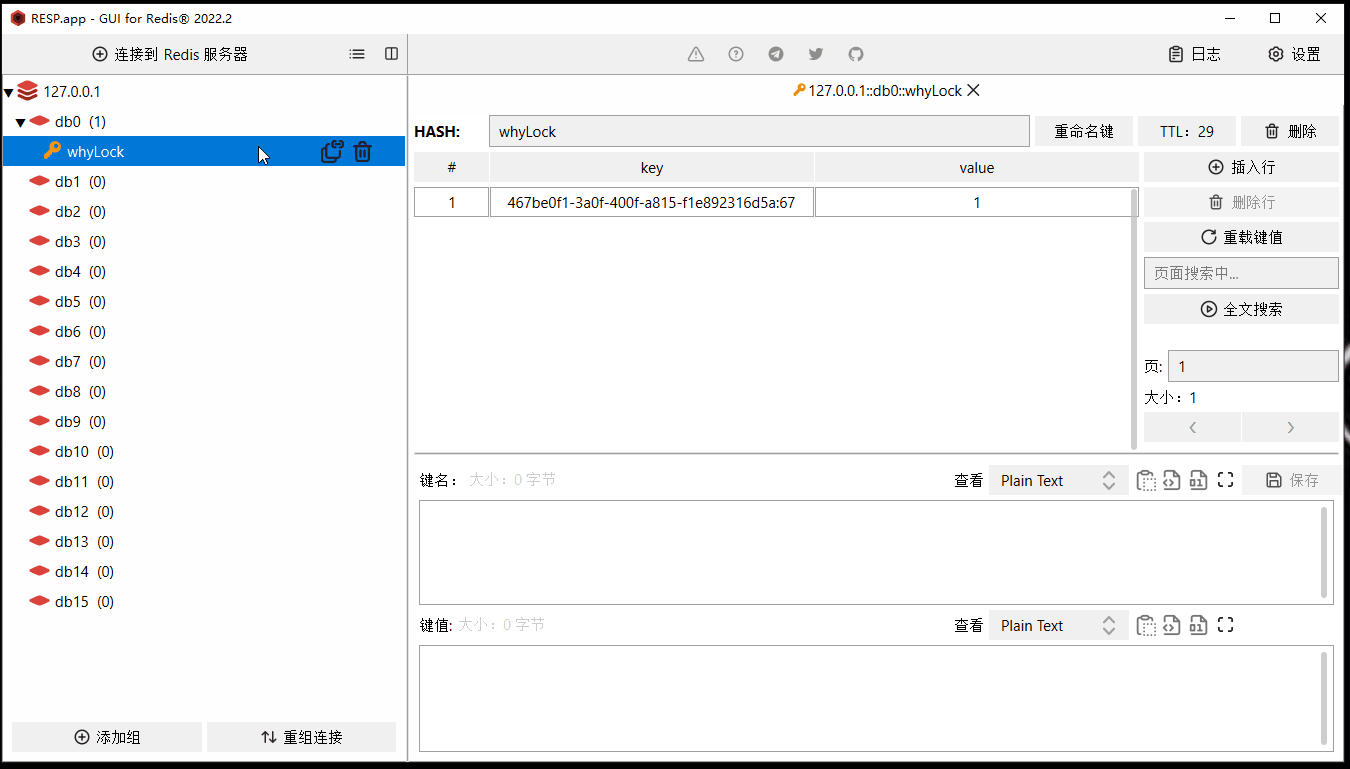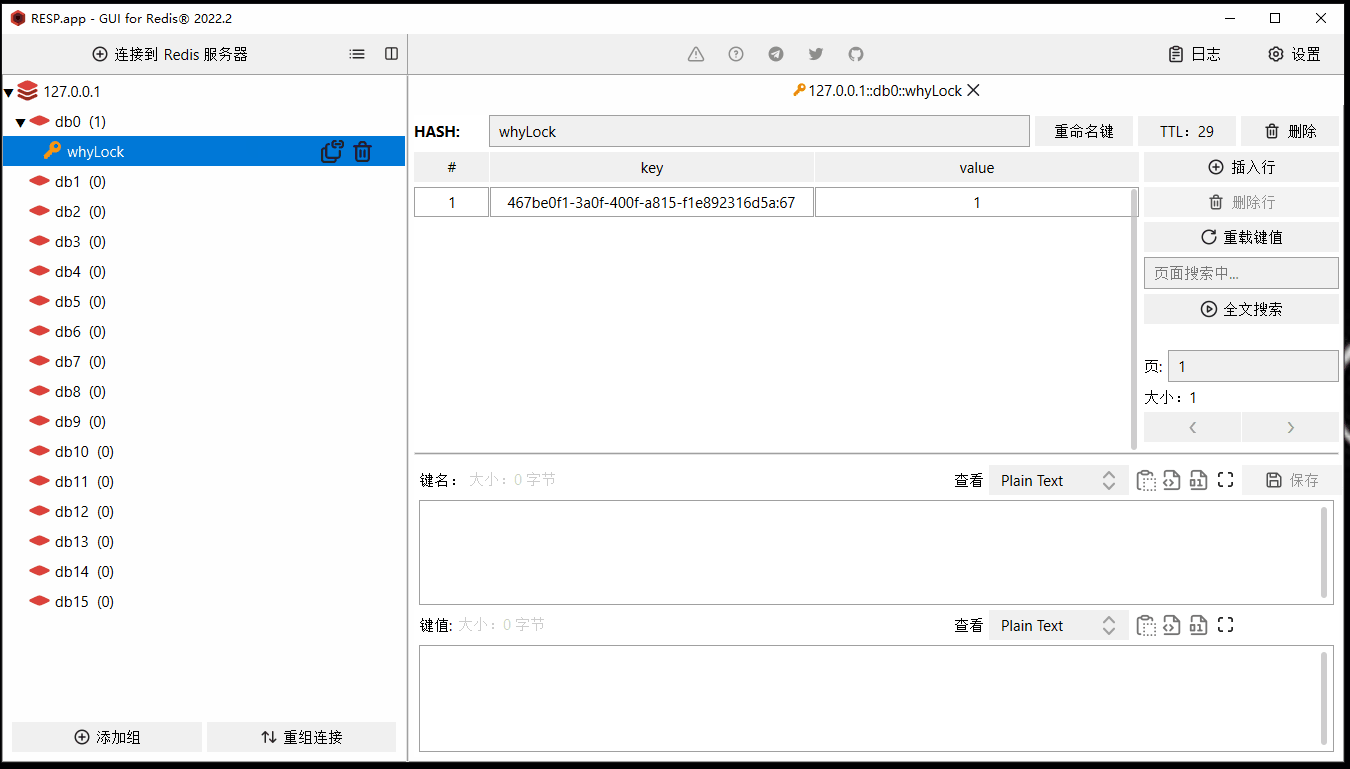
首先,我们的代码里面并没有设置过期时间的动作,也没有去更新过期时间的这个动作。
那么这个东西是怎么回事呢?

很简单,Redisson 帮我们做了这些事情,开箱即用,当个黑盒就完事了。
接下来我就是带你把黑盒变成白盒,然后引出前面提到的两个 bug。
我的测试用例里面用的是 3.16.0 版本的 Redission,我们先找一下它关于设置过期动作的源码。
首先可以看到,我虽然调用的是无参的 lock 方法,但是它其实也只是一层皮而已,里面还是调用了带入参的 lock 方法,只不过给了几个默认值,其中 leaseTime 给的是 -1:
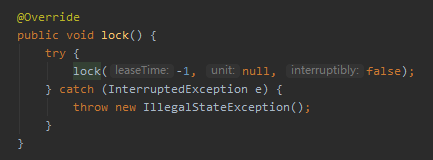
而有参的 lock 的源码是这样的,主要把注意力放到我框起来的这一行代码中:
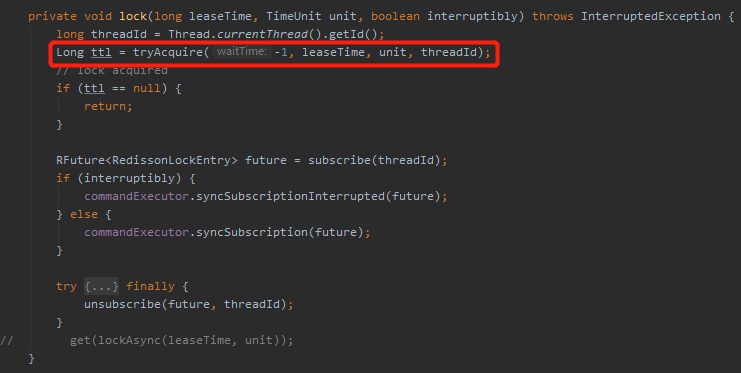
tryAcquire 方法是它的核心逻辑,那么这个方法是在干啥事儿呢?
点进去看看,这部分源码又是这样的:
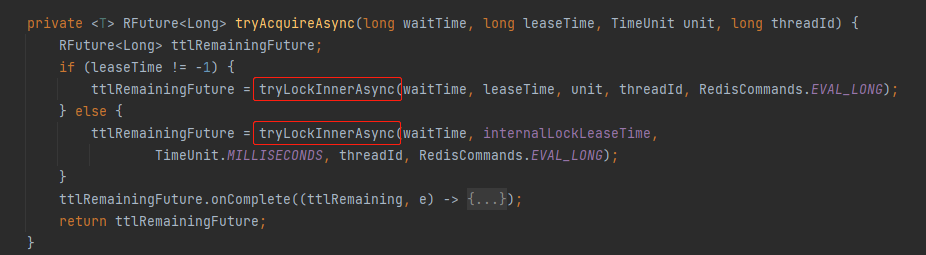
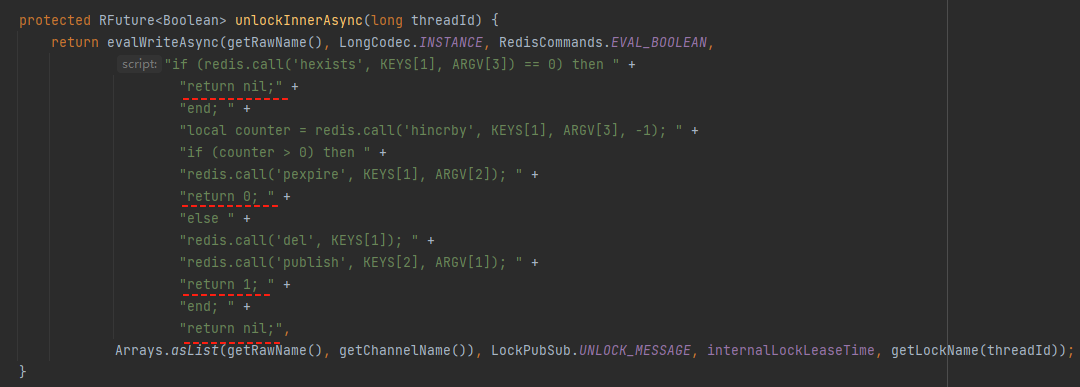
其中 tryLockInnerAsync 方法就是执行 Redis 的 Lua 脚本来加锁。
既然是加锁了,过期时间肯定就是在这里设置的,也就是这里的 leaseTime:
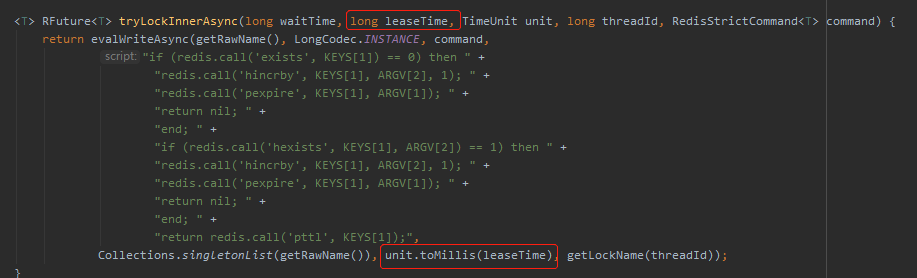
而这里的 leaseTime 是在构造方法里面初始化的,在我的 Demo 里面,用的是配置中的默认值,也就是 30s :

所以,为什么我们的代码里面并没有设置过期时间的动作,但是对应的 key 却有过期时间呢?
这里的源码回答了这个问题。
额外提一句,这个时间是从配置中获取的,所以肯定是可以自定义的,不一定非得是 30s。
另外需要注意的是,到这里,我们出现了两个不同的 leaseTime。
分别是这样的:
-
tryAcquireOnceAsync 方法的入参 leaseTime,我们的示例中是 -1。 -
tryLockInnerAsync 方法的入参 leaseTime,我们的示例中是默认值 30 * 1000。
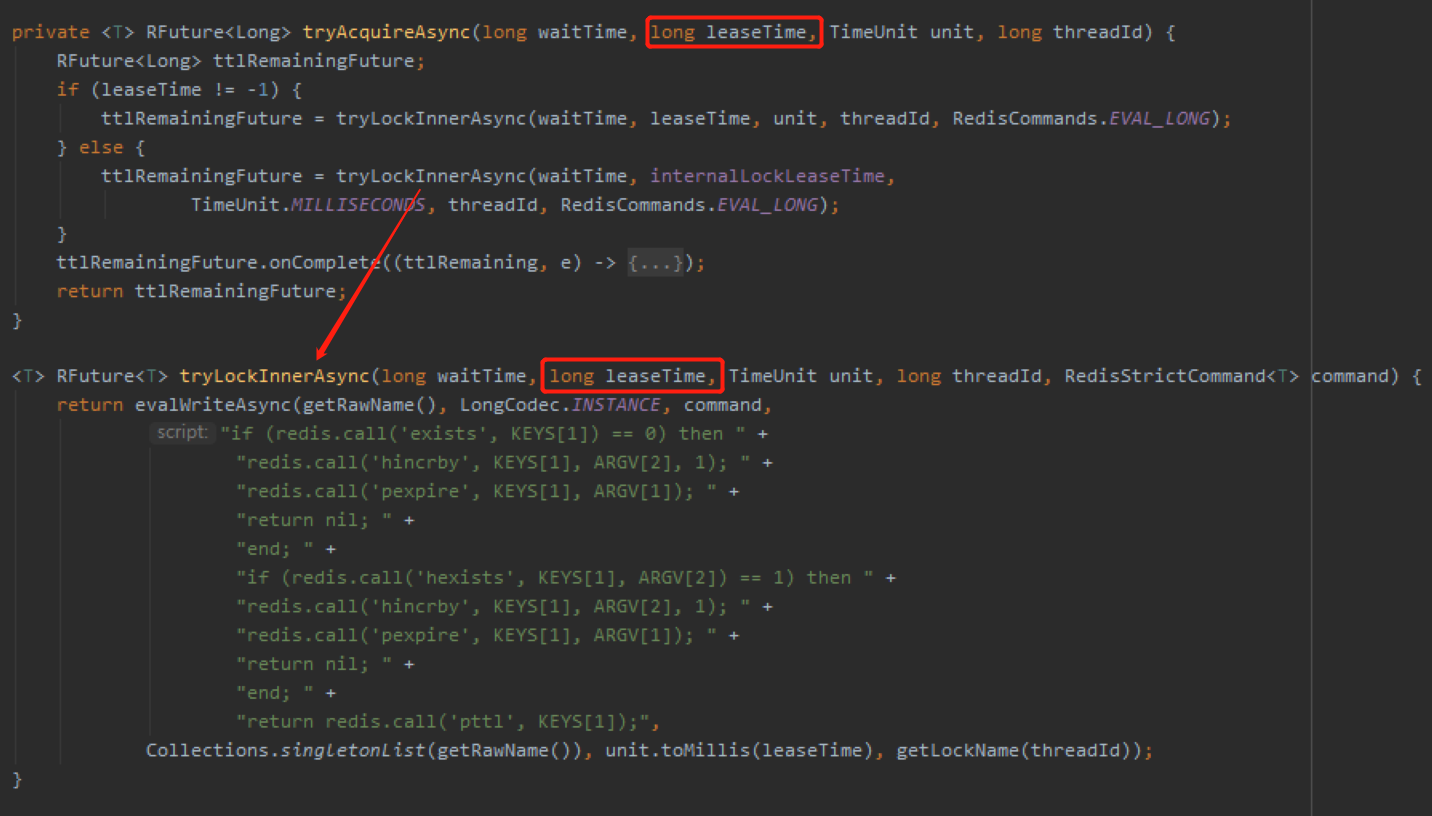
在前面加完锁之后,紧接着就轮到看门狗工作了:
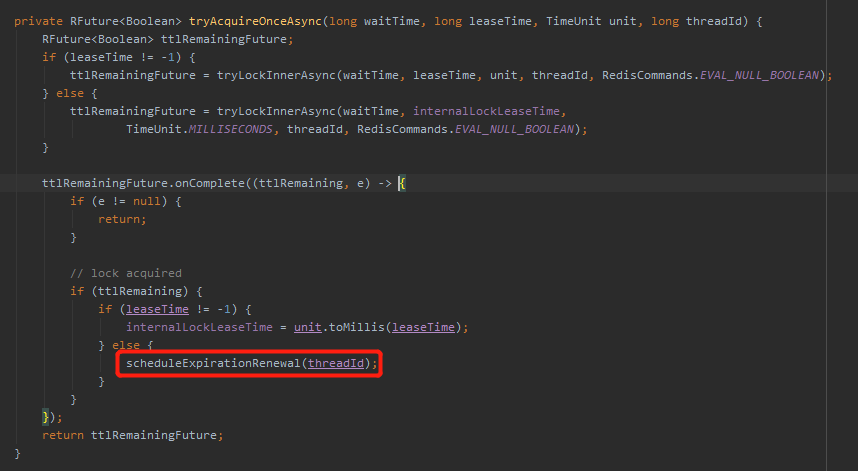
前面我说了,这里的 leaseTime 是 -1,所以触发的是 else 分支中的 scheduleExpirationRenewal 代码。
而这个代码就是启动看门狗的代码。
换句话说,如果这里的 leaseTime 不是 -1,那么就不会启动看门狗。
那么怎么让 leaseTime 不是 -1 呢?
自己指定加锁时间:
说人话就是如果加锁的时候指定了过期时间,那么 Redission 不会给你开启看门狗的机制。
这个点是无数人对看门狗机制不清楚的人都会记错的一个点,我曾经在一个群里面据理力争,后来被别人拿着源码一顿乱捶。

是的,我就是那个以为指定了过期时间之后,看门狗还会继续工作的人。
打脸老疼了,希望你不要步后尘。
接着来看一下 scheduleExpirationRenewal 的代码:
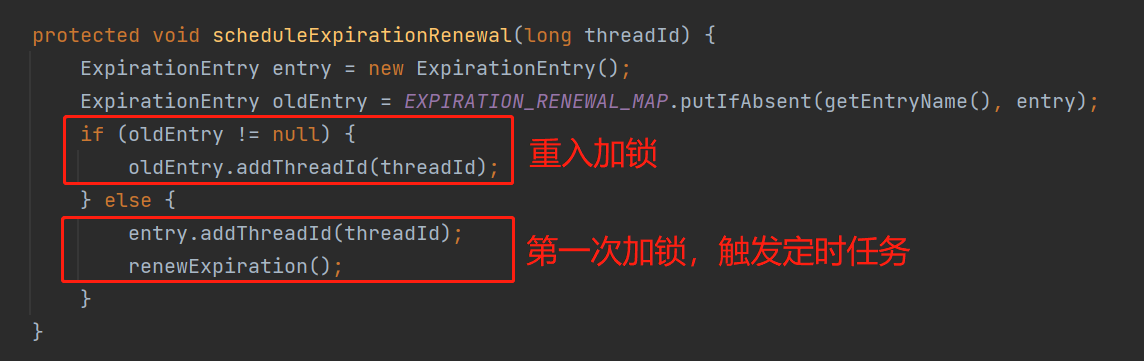
里面就是把当前线程封装成了一个对象,然后维护到一个 MAP 中。
这个 MAP 很重要,我先把它放到这里,混个眼熟,一会再说它:
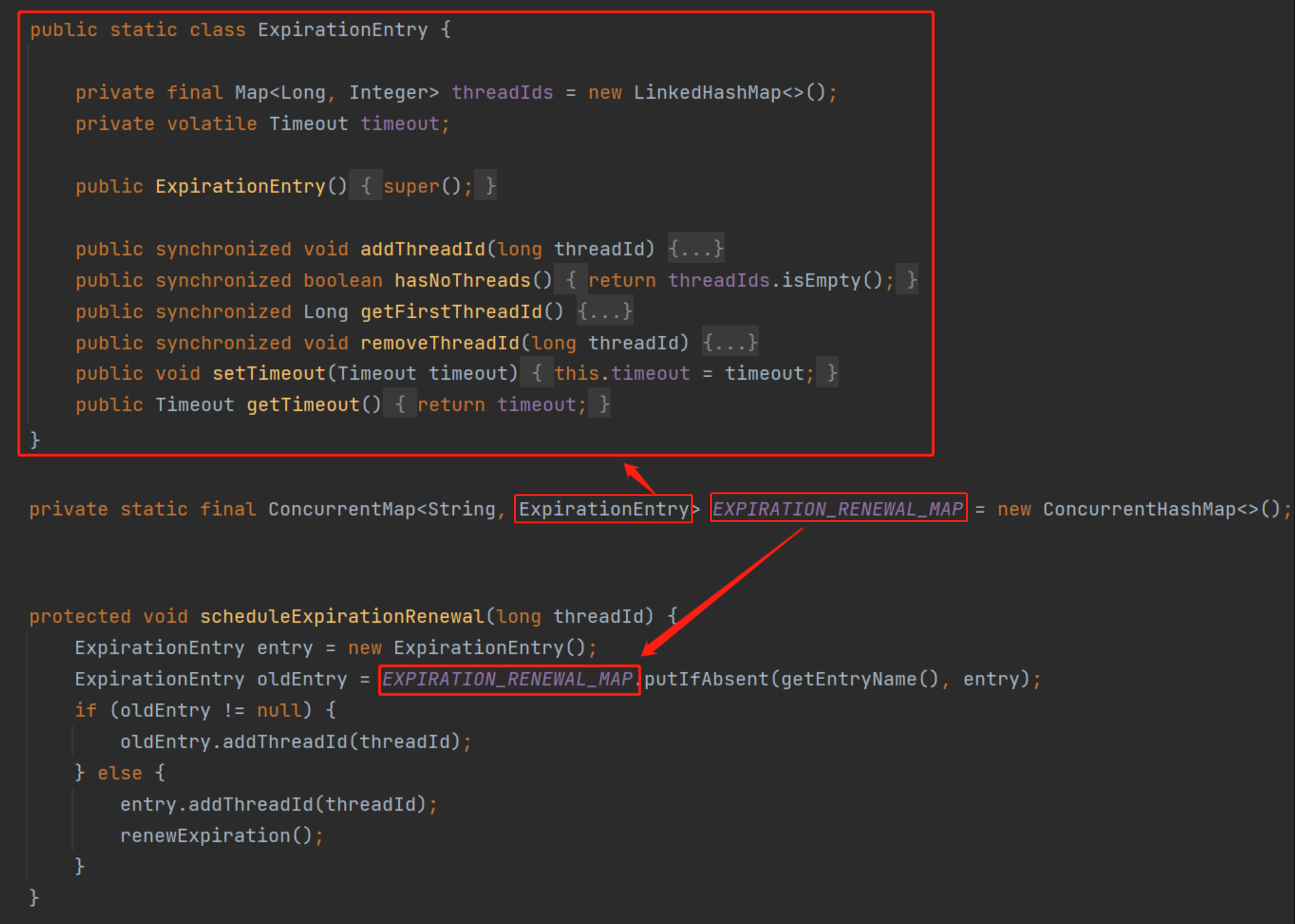
你只要记住这个 MAP 的 key 是当前线程,value 是 ExpirationEntry 对象,这个对象维护的是当前线程的加锁次数。

然后,我们先看 scheduleExpirationRenewal 方法里面,调用 MAP 的 putIfAbsent 方法后,返回的 oldEntry 为空的情况。
这种情况说明是第一次加锁,会触发 renewExpiration 方法,这个方法里面就是看门狗的核心逻辑。
而在 scheduleExpirationRenewal 方法里面,不管前面提到的 oldEntry 是否为空,都会触发 addThreadId 方法:
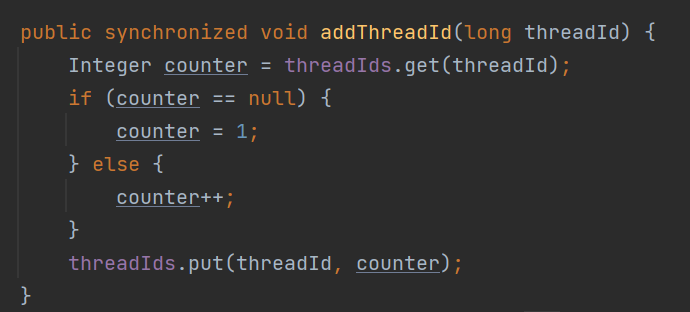
从源码中可以看出来,这里仅仅对当前线程的加锁次数进行一个维护。
这个维护很好理解,因为要支持锁的重入嘛,就得记录到底重入了几次。
加锁一次,次数加一。解锁一次,次数减一。
接着看 renewExpiration 方法,这就是看门狗的真面目了:
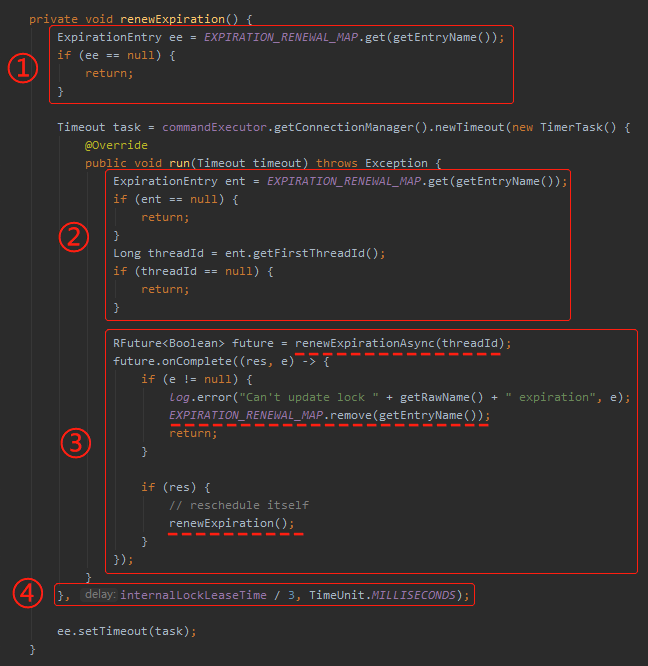
首先这一坨逻辑主要就是一个基于时间轮的定时任务。
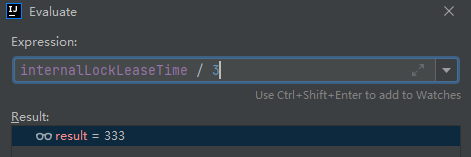
标号为 ④ 的地方,就是这个定时任务触发的时间条件:internalLockLeaseTime / 3。
前面我说了,internalLockLeaseTime 默认情况下是 30* 1000,所以这里默认就是每 10 秒执行一次续命的任务,这个从我前面给到的动态里面也可以看出,ttl 的时间先从 30 变成了 20 ,然后一下又从 20 变成了 30。
标号为 ①、② 的地方干的是同一件事,就是检查当前线程是否还有效。
怎么判断是否有效呢?
就是看前面提到的 MAP 中是否还有当前线程对应的 ExpirationEntry 对象。
没有,就说明是被 remove 了。
那么问题就来了,你看源码的时候非常自然而然的就应该想到这个问题:什么时候调用这个 MAP 的 remove 方法呢?
很快,在接下来讲释放锁的地方,你就可以看到对应的 remove。这里先提一下,后面就能呼应上了。
核心逻辑是标号为 ③ 的地方。我带你仔细看看,主要关注我加了下划线的地方。
能走到 ③ 这里说明当前线程的业务逻辑还未执行完成,还需要继续持有锁。
首先看 renewExpirationAsync 方法,从方法命名上我们也可以看出来,这是在重置过期时间:
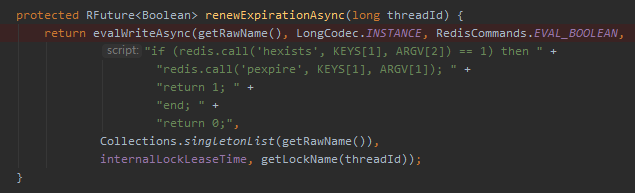
上面的源码主要是一个 lua 脚本,而这个脚本的逻辑非常简单。就是判断锁是否还存在,且持有锁的线程是否是当前线程。如果是当前线程,重置锁的过期时间,并返回 1,即返回 true。
如果锁不存在,或者持有锁的不是当前线程,那么则返回 0,即返回 false。
接着标号为 ③ 的地方,里面首先判断了执行 renewExpirationAsync 方法是否有异常。
那么问题就来了,会有什么异常呢?
这个地方的异常,主要是因为要到 Redis 执行命令嘛,所以如果 Redis 出问题了,比如卡住了,或者掉线了,或者连接池没有连接了等等各种情况,都可能会执行不了命令,导致异常。
如果出现异常了,则执行下面这行代码:
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
然后就 return ,这个定时任务就结束了。
好,记住这个 remove 的操作,非常重要,先混个眼熟,一会会讲。
如果执行 renewExpirationAsync 方法的时候没有异常。这个时候的返回值就是 true 或者 false。
如果是 true,说明续命成功,则再次调用 renewExporation 方法,等待着时间轮触发下一次。
如果是 false,说明这把锁已经没有了,或者易主了。那么也就没有当前线程什么事情了,啥都不用做,默默的结束就行了。
上锁和看门狗的一些基本原理就是前面说到这么多。
接着简单看看 unlock 方法里面是怎么回事儿的。
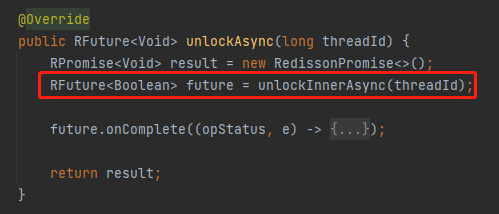
首先是 unlockInnerAsync 方法,这里面就是 lua 脚本释放锁的逻辑:
这个方法返回的是 Boolean,有三种情况。
-
返回为 null,说明锁不存在,或者锁存在,但是 value 不匹配,表示锁已经被其他线程占用。 -
返回为 true,说明锁存在,线程也是对的,重入次数已经减为零,锁可以被释放。 -
返回为 false,说明锁存在,线程也是对的,但是重入次数还不为零,锁还不能被释放。
但是你看 unlockInnerAsync 是怎么处理这个返回值的:
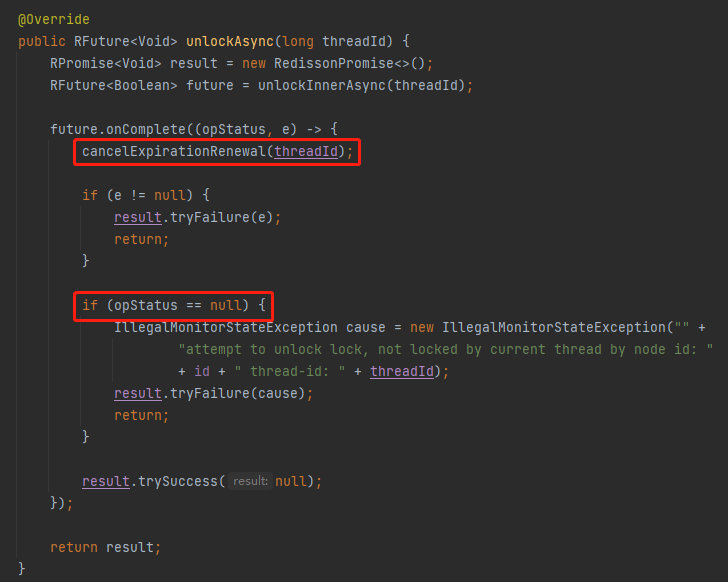
返回值,也就是 opStatus,仅仅是判断了返回为 null 的情况,抛出异常表明这个锁不是被当前线程持有的,完事。
它并不关心返回为 true 或者为 false 的情况。
然后再看我框起来的 cancelExpirationRenewal(threadId); 方法:
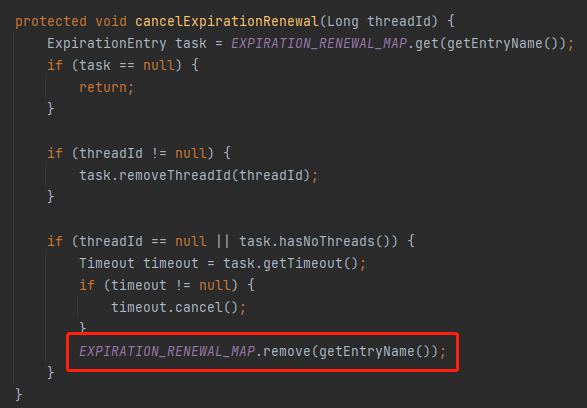
这里面就有 remove 方法。
而前面铺垫了这么多其实就是为了引出这个 cancelExpirationRenewal 方法。
纵观一下加锁和解锁,针对 MAP 的操作,看一下下面的这个图片:
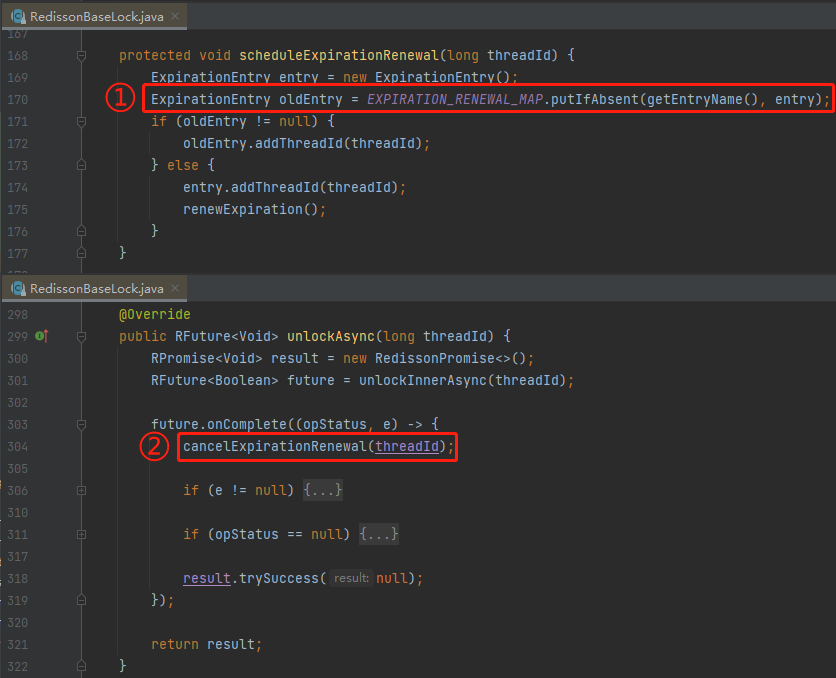
标号为 ① 的地方是加锁,调用 MAP 的 put 方法。
标号为 ② 的地方是放锁,调用 MAP 的 remove 方法。
记住上面这一段分析,和操作这个 MAP 的时机,下面说的 BUG 都是由于对这个 MAP 的操作不恰当导致的。
看门狗不生效的BUG
前面找了一个版本给大家看源码,主要是为了让大家把 Demo 跑起来,毕竟引入 maven 依赖的成本是小很多的。
但是真的要研究源码,还是得把先把源码拉下来,慢慢的啃起来。
直接拉项目源码的好处我在之前的文章里面已经说很多次了,对我而言,无外乎就三个目的:
-
可以保证是最新的源码 -
可以看到代码的提交记录 -
可以找到官方的测试用例
好,话不多说,首先我们看看开篇说的第一个 BUG:看门狗不生效的问题。
从这个 issues 说起:
https://github.com/redisson/redisson/issues/2515
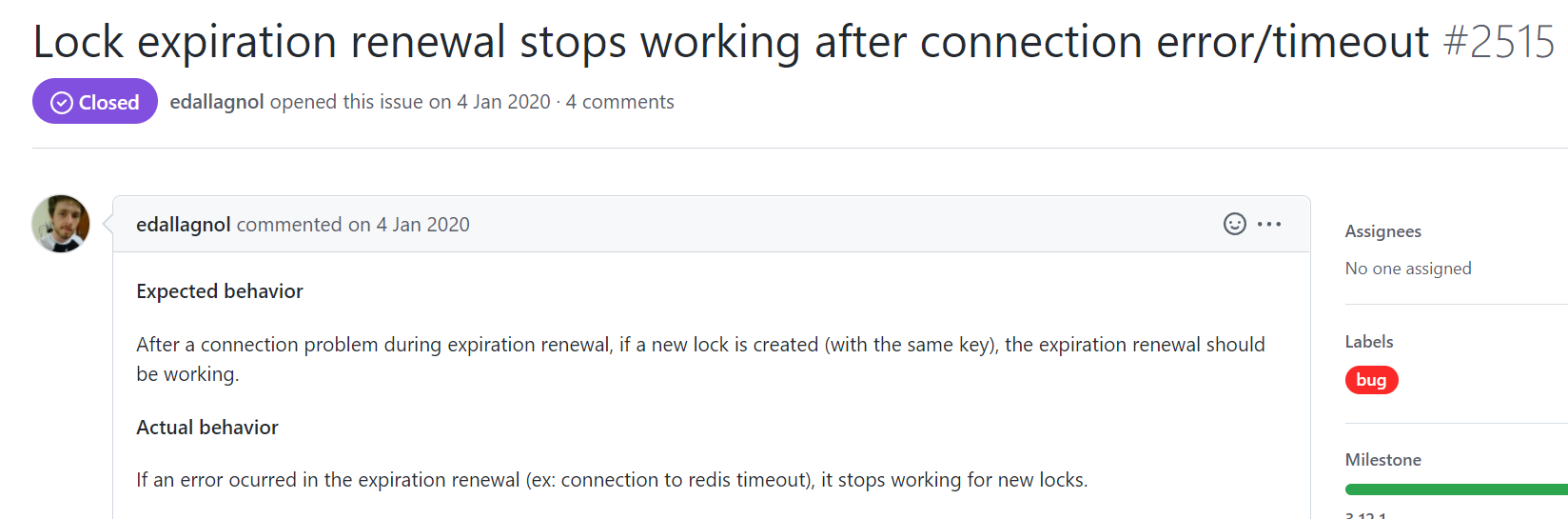
在这个 issues 里面,他给到了一段代码,然后说他预期的结果是在看门狗续命期间,如果出现程序和 Redis 的连接问题,导致锁自动过期了,那么我再次申请同一把锁,应该是让看门狗再次工作才对。
但是实际的情况是,即使前一把锁由于连接异常导致过期了,程序再成功申请到一把新锁,但是这个新的锁,30s 后就自动过期了,即看门狗不会工作。
这个 issues 对应的 pr 是这个:
https://github.com/redisson/redisson/pull/2518

在这个 pr 里面,提供了一个测试用例,我们可以直接在源码里面找到:
org.redisson.RedissonLockExpirationRenewalTest
这就是拉源码的好处。
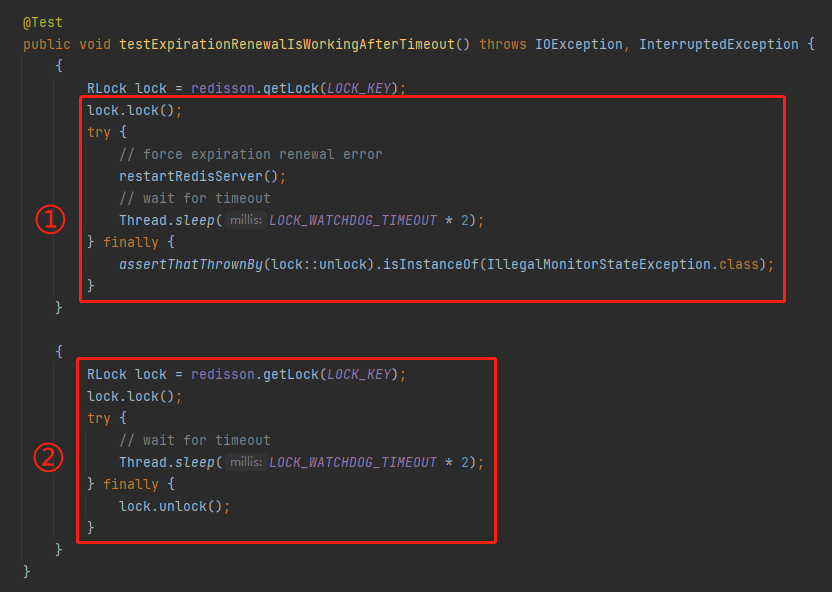
在这个测试用例里面,核心逻辑是这样的:
首先需要说明的是,在这个测试用例里面,把看门狗的 lockWatchdogTimeout 参数修改为 1000 ms:
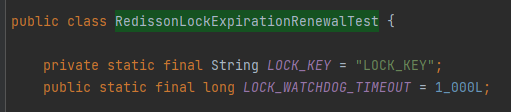
也就是说看门狗这个定时任务,每 333ms 就会触发一次。
然后我们看标号为 ① 的地方,先申请了一把锁,然后 Redis 发生了一次重启,重启导致这把锁失效了,比如还没来得及持久化,或者持久化了,但是重启的时间超过了 1s,这锁就没了。
所以,在调用 unlock 方法的时候,肯定会抛出 IllegalMonitorStateException 异常,表示这把锁没了。
到这里一切正常,还能理解。
但是看标号为 ② 的地方。
加锁之后,业务逻辑会执行 2s,肯定会触发看门狗续命的操作。
在这个 bug 修复之前,在这里调用 unlock 方法也会抛出 IllegalMonitorStateException 异常,表示这把锁没了:
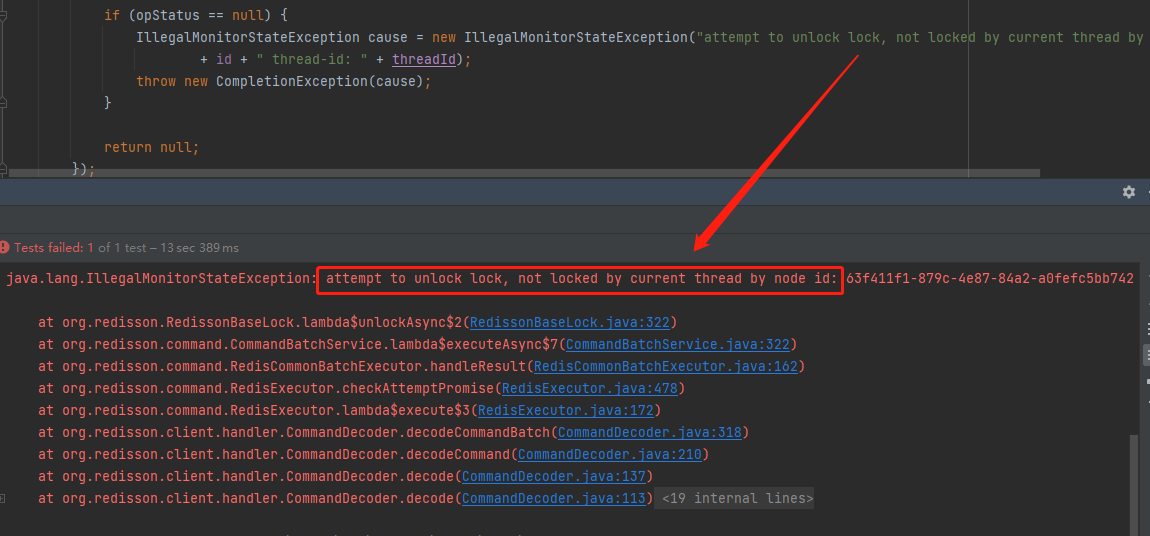
先不说为啥吧,至少这妥妥的是一个 Bug 了。

因为按照正常的逻辑,这个锁应该一直被续命,然后直到调用 unlock 才应该被释放。
好,bug 的演示你也看到了,也可以复现了。你猜是什么原因?
答案其实我在前面应该给你写出来了,就看这波前后呼应你能不能反应过来了。
首先前提是两次加锁的线程是同一个,然后我前面不是特意强调了 oldEntry 这个玩意吗:
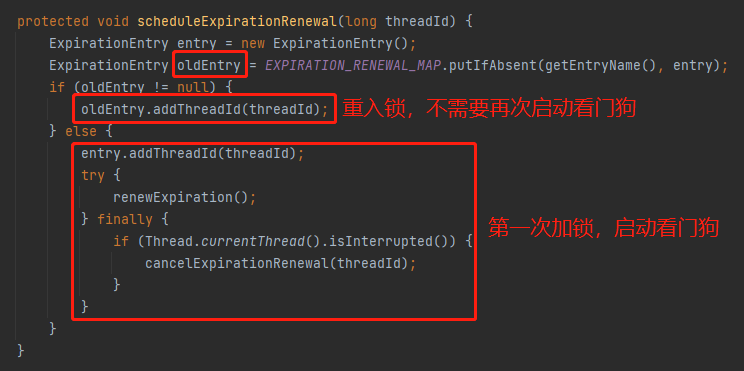
上面这个 bug 能出现,说明第二次 lock 的时候 oldEntry 在 MAP 里面是存在的,因此误以为当前看门狗正在工作,直接进入重入锁的逻辑即可。
为什么第二次 lock 的时候 oldEntry 在 MAP 里面是存在的呢?
因为第一次 unlock 的时候,没有从 MAP 里面把当前线程的 ExpirationEntry 对象移走。
为什么没有移走呢?
看一下这个哥们测试的 Redisson 版本:

在这个版本里面,释放锁的逻辑是这样的:
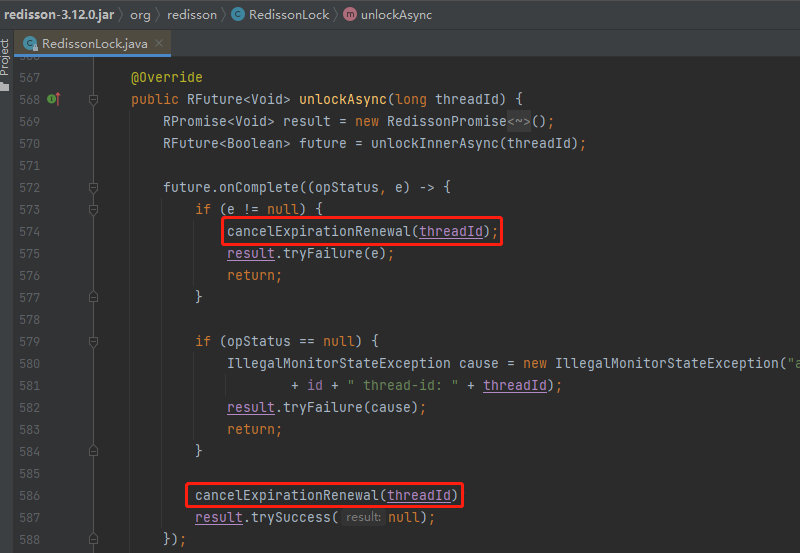
诶,不对呀,这不是有 cancelExpirationRenewal(threadId) 的逻辑吗?
没错,确实有。
但是你看什么情况下会执行这个逻辑。
首先是出现异常的情况,但是在我们的测试用例中,两次调用 unlock 的时候 Redis 是正常的,不会抛出异常。
然后是 opStatus 不为 null 的时候会执行该逻辑。
也就是说 opStatus 为 null 的时候,即当前锁没有了,或者易主了的时候,不会触发 cancelExpirationRenewal(threadId) 的逻辑。
巧了,在我们的场景里面,第一次调用 unlock 方法的时候,就是因为 Redis 重启导致锁没有了,因此这里返回的 opStatus 为 null,没有触发 cancelExpirationRenewal 方法的逻辑。
导致我第二次在当前线程中调用 lock 的时候,走到下面这里的时候,oldEntry 不为空:
所以,走了重入的逻辑,并没有启动看门狗。
由于没有启动看门狗,导致这个锁在 1000ms 之后就自动释放了,可以被别的线程抢走拿去用。
随后当前线程业务逻辑执行完成,第二次调用 unlock,当然就会抛出异常了。
这就是 BUG 的根因。
找到问题就好了,一行代码就能解决:
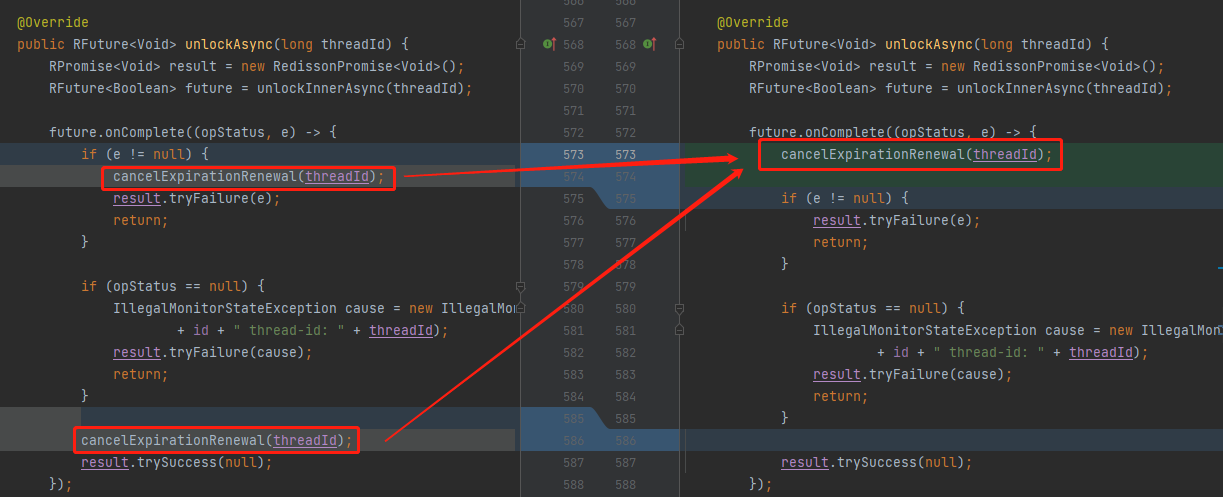
只要调用了 unlock 方法,不管怎么样,先调用 cancelExpirationRenewal(threadId) 方法,准没错。
这就是由于没有及时从 MAP 里面移走当前线程对应的对象,导致的一个 BUG。
再看看另外一个的 issue:
https://github.com/redisson/redisson/issues/3714
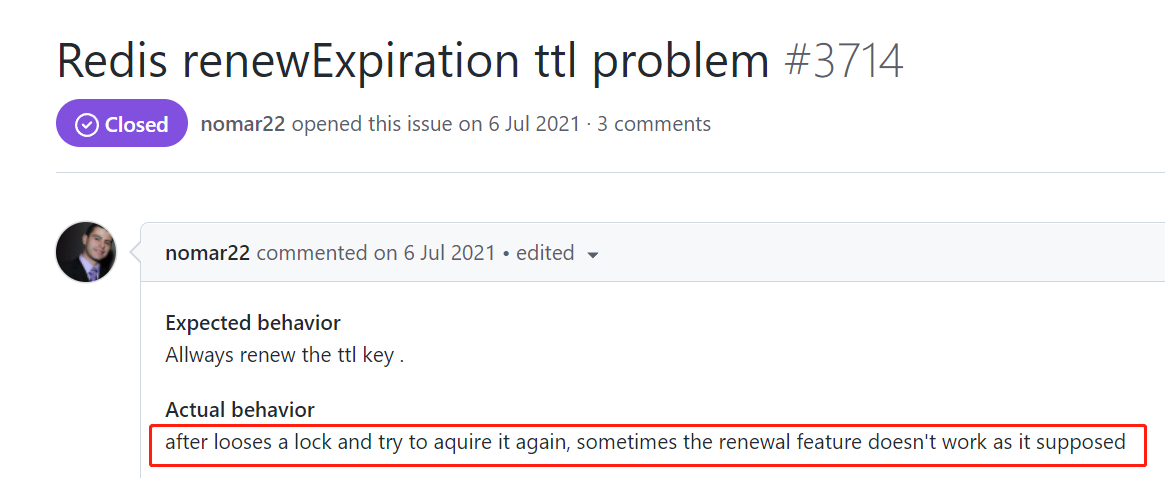
这个问题是说如果我的锁由于某些原因没了,当我在程序里面再次获取到它之后,看门狗应该继续工作。
听起来,说的是同一个问题对不对?
是的,就是说的同一个问题。
但是这个问题,提交的代码是这样的:
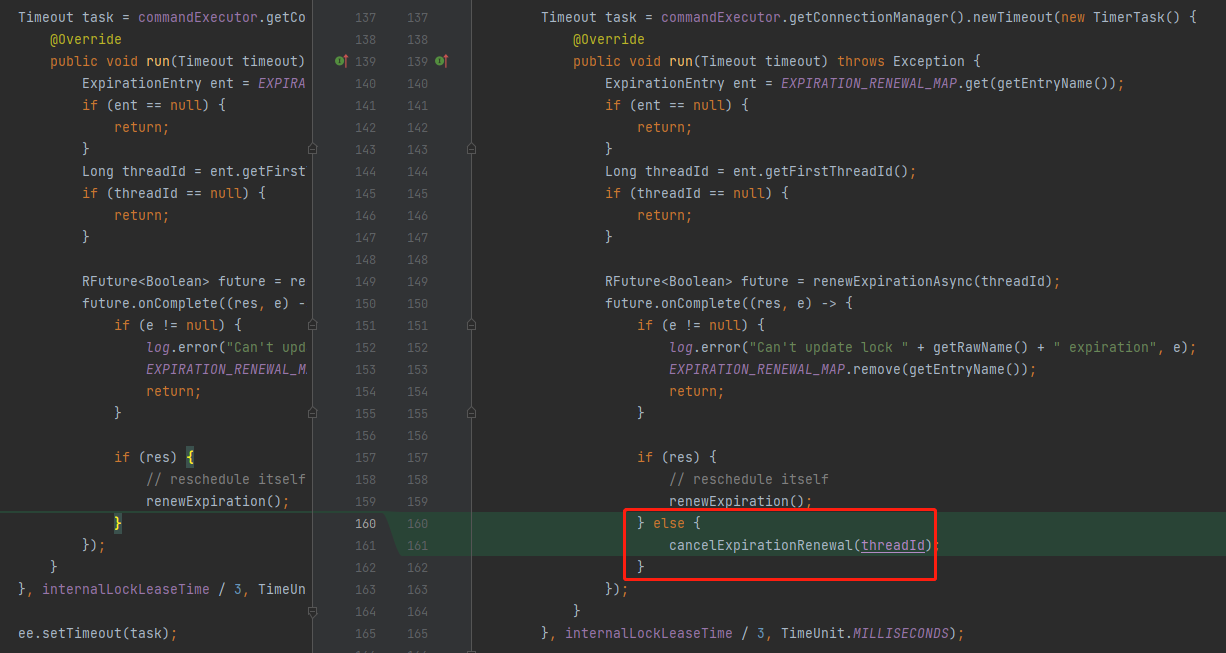
在看门狗这里,如果看门狗续命失败,说明锁不存在了,即 res 返回为 false,那么也主动执行一下 cancelExpirationRenewal 方法,方便为后面的加锁成功的线程让路,以免耽误别人开启看门狗机制。
这样就能有双重保障了,在 unlock 和看门狗里面都会触发 cancelExpirationRenewal 的逻辑,而且这两个逻辑也并不会冲突。

另外,我提醒一下,最终提交的代码是这样的,两个方法入参是不一样的:

为什么从 threadId 修改为 null 呢?
留个思考题吧,就是从重入的角度考虑的,可以自己去研究一下,很简单的。
看门狗导致死锁的BUG
这个 BUG 解释起来就很简单了。
看看这个 issue:
https://github.com/redisson/redisson/issues/1966
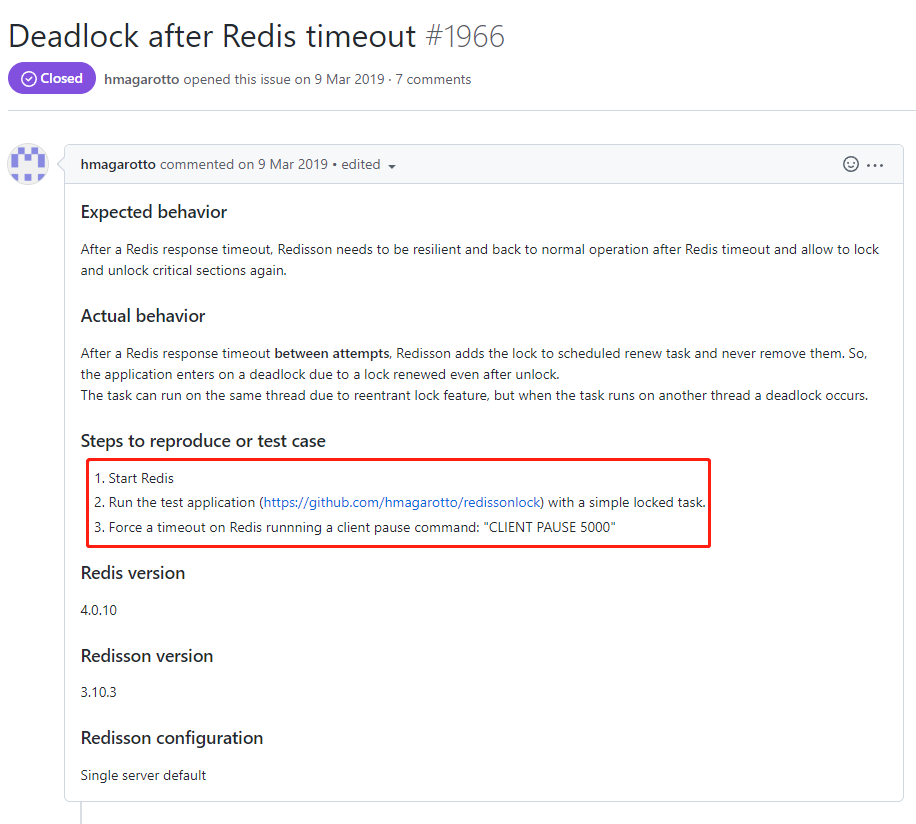
在这里把复现的步骤都写的清清楚楚的。
测试程序是这样的,通过定时任务 1s 触发一次,但是任务会执行 2s,这样就会导致锁的重入:
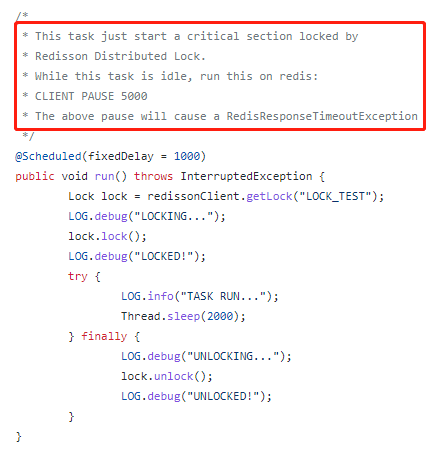
他这里提到一个命令:
CLIENT PAUSE 5000
主要还是模拟 Redis 处理请求超时的情况,就是让 Redis 假死 5s,这样程序发过来的请求就会超时。
这样,重入的逻辑就会发生混乱。
看一下这个 bug 修复的对应的关键代码之一:
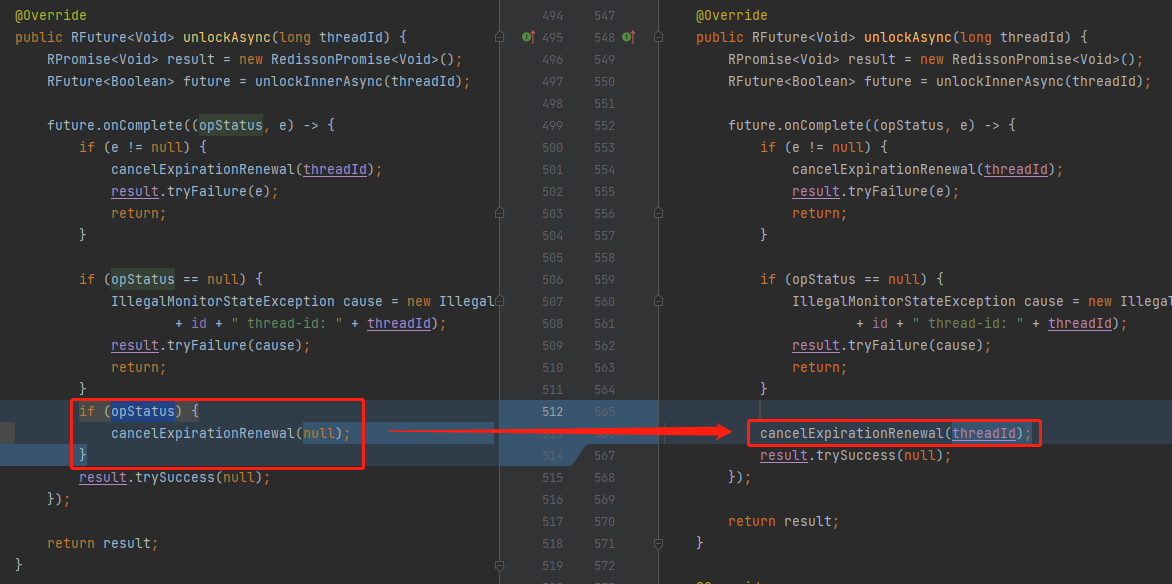
不管 opStatus 返回为 false 还是 true,都执行 cancelExpirationRenewal 逻辑。
问题的解决之道,还是在于对 MAP 的操作。
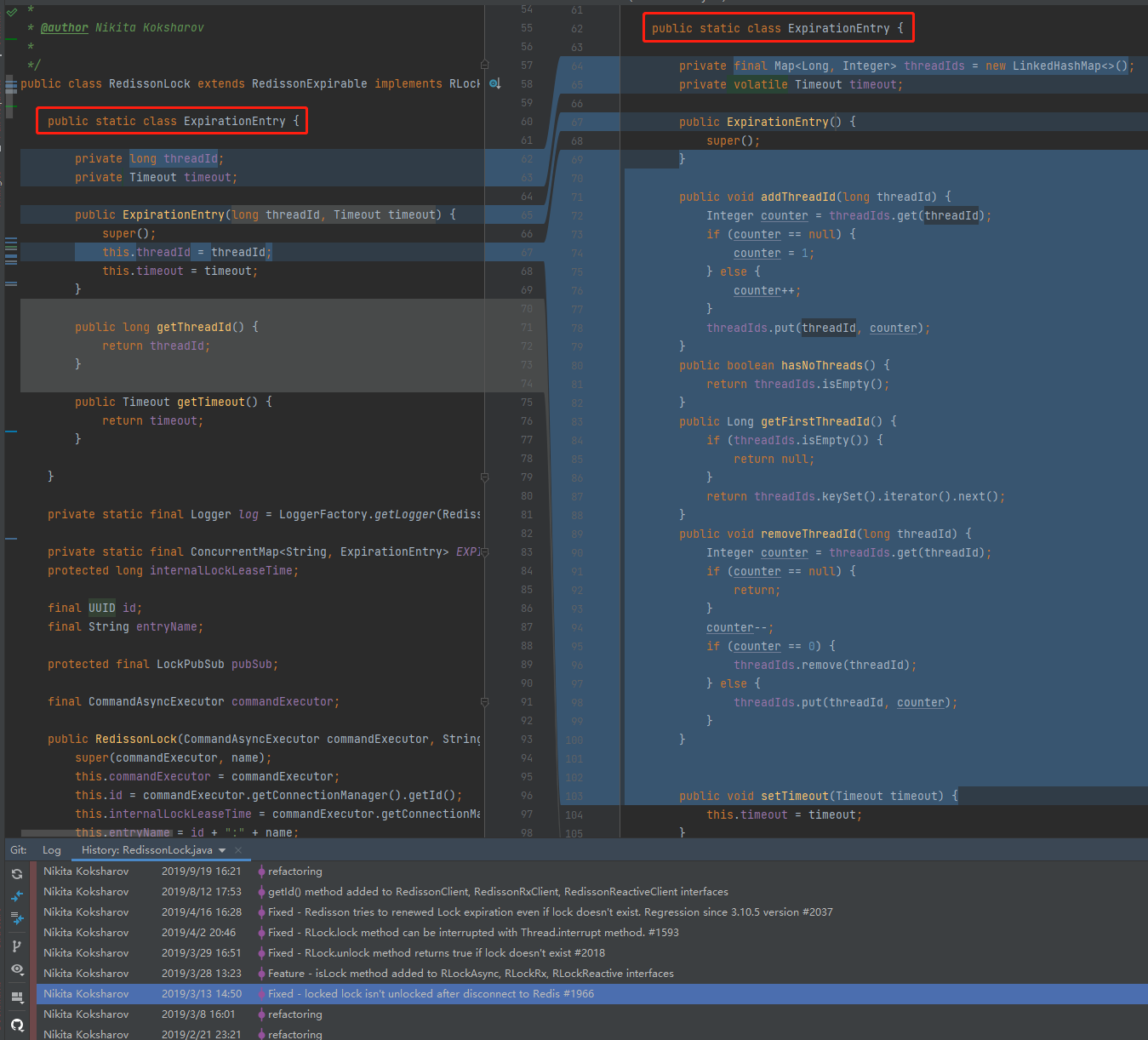
另外,多提一句。
也是在这次提交中,把维护重入的逻辑封装到了 ExpirationEntry 这个对象里面,比起之前的写法优雅了很多,有兴趣的可以把源码拉下来进行一下对比,感受一下什么叫做优雅的重构:
线程中断
在写文章的时候,我还发现一个有意思的,但对于 Redisson 无解的 bug。
就是这里:
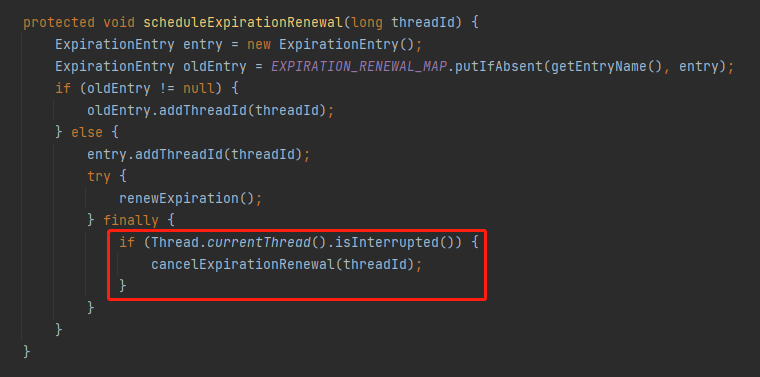
我第一眼看到这一段代码就很奇怪,这样奇怪的写法,背后肯定是有故事的。
这背后对应的故事,藏在这个 issue 里面:
https://github.com/redisson/redisson/issues/2714
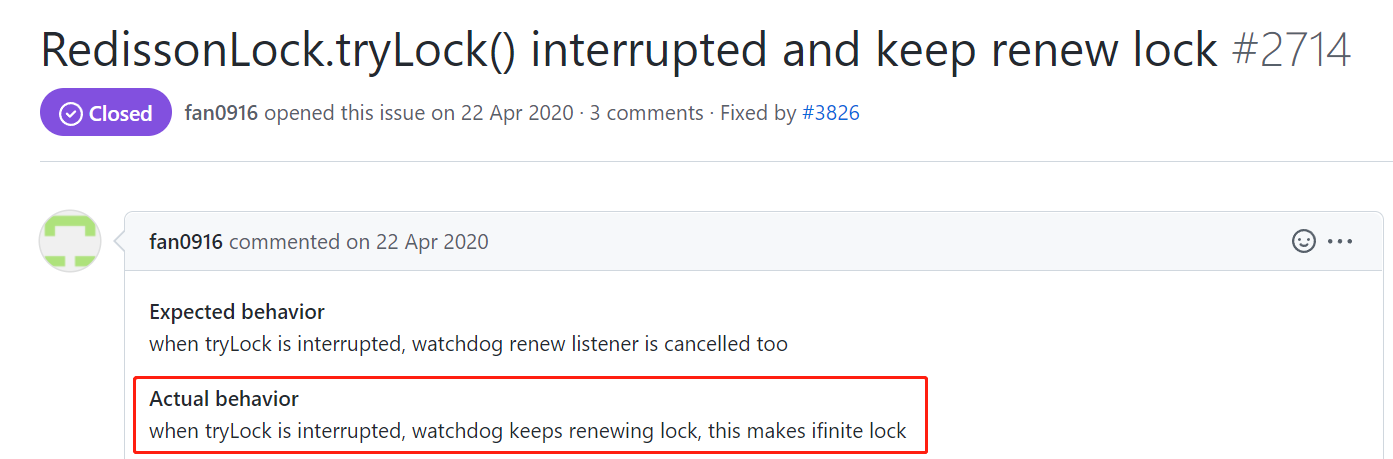
翻译过来,说的是当 tryLock 方法被中断时,看门狗还是会不断地更新锁,这就造成了无限锁,也就是死锁。
我们看一下对应的测试用例:
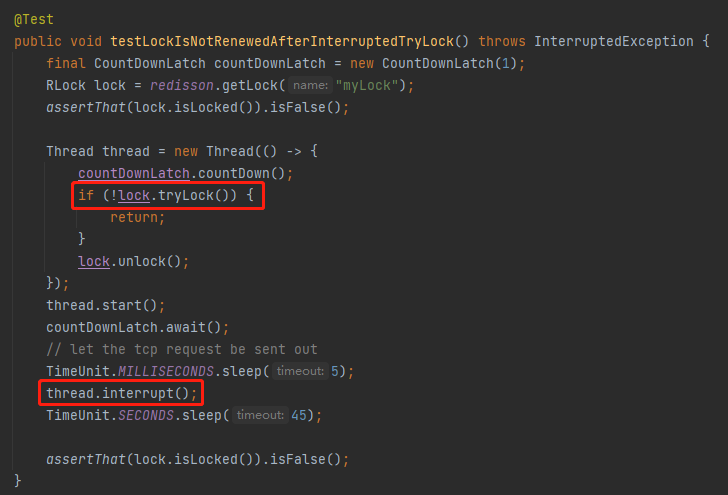
开启了一个子线程,在子线程里面执行了 tryLock 的方法,然后主线程里面调用了子线程的 interrupt 方法。
你说这个时候子线程应该怎么办?
按理来说,线程被中断了,是不是看门狗也不应该工作呢?
是的,所以这样的代码就出现了:
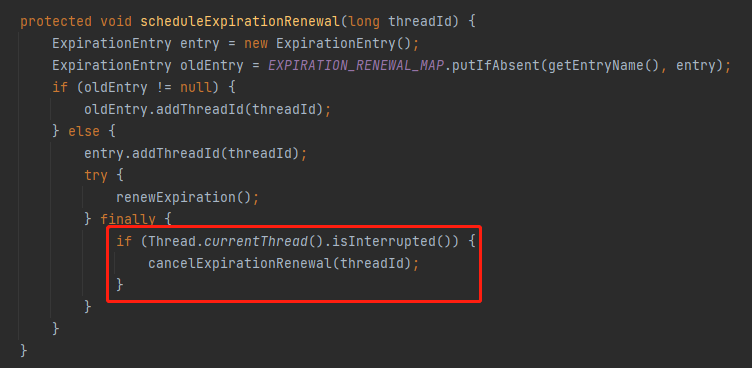
但是,你细品,这几行代码并没有完全解决看门狗的问题。只能在一定概率上解决第一次调用后 renewExpiration 方法后,还没来得及启动定时任务之前的这一小段时间。
所以,测试案例里面的 sleep 时间,只有 5ms:
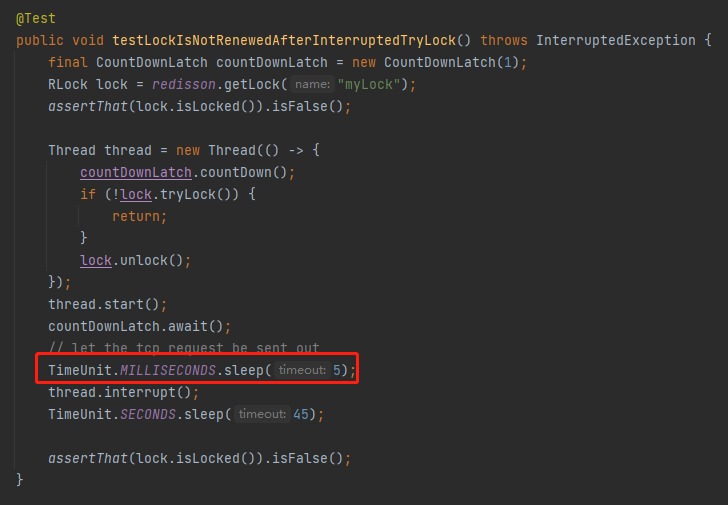
这时间要是再长一点,就会触发看门狗机制。
一旦触发看门狗机制,触发 renewExpiration 方法的线程就会变成定时任务的线程。
你外面的子线程 interrupt 了,和我定时任务的线程有什么关系?
比如,我把这几行代码移动到这里:
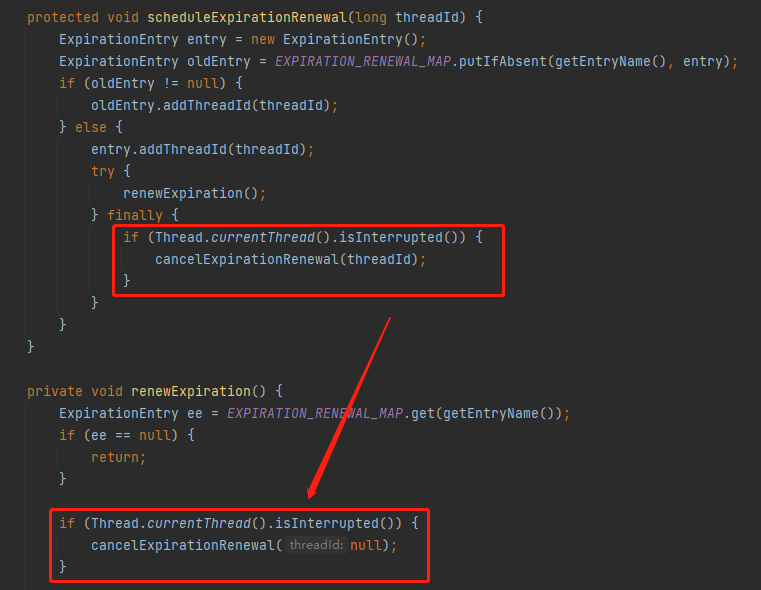
其实没有任何卵用:
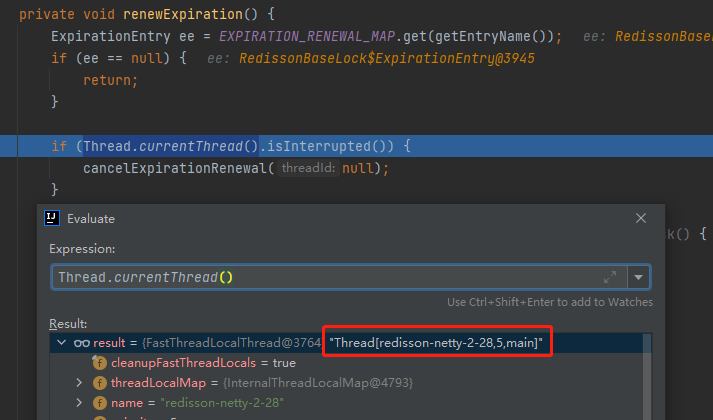
因为线程变了。
对于这个问题,官方的回答是这样的:
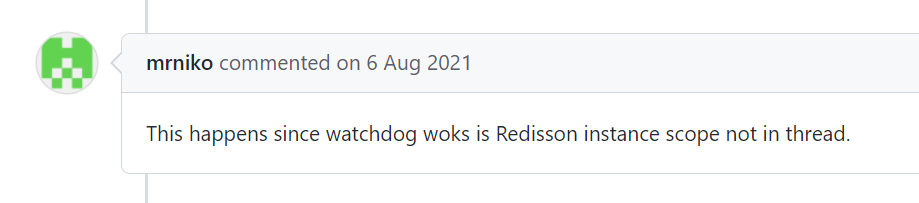
大概意思就是说:嗯,你说的很有道理,但是 Redisson 的看门狗工作范围是整个实例,而不是某个指定的线程。
意外收获
最后,再来一个意外收获:

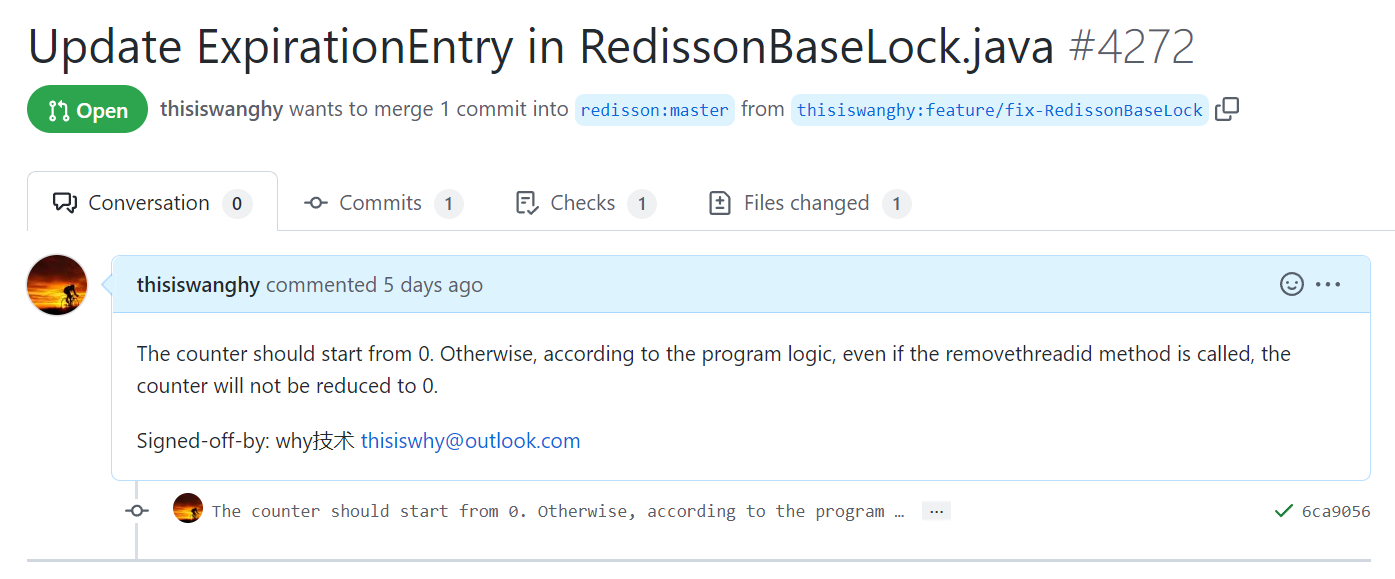
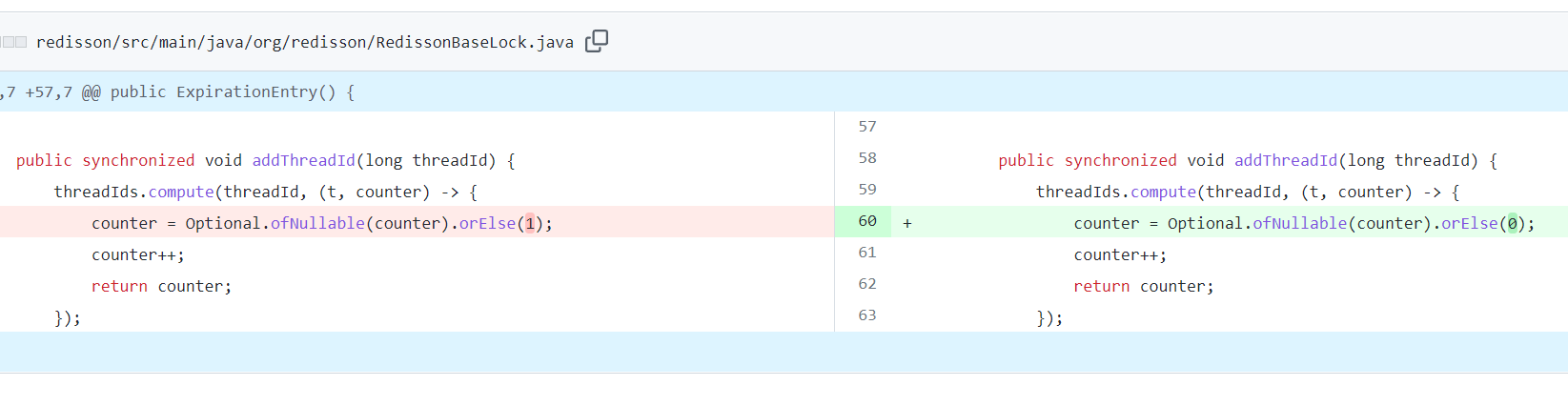
你看 addThreadId 这个方法重构了一次。
但是这次重构就出现问题了。
原来的逻辑是当 counter 是 null 的时候,初始化为 1。不为 null 的时候,就执行 counter++,即重入。
重构之后的逻辑是当 counter 是 null 的时候,先初始化为 1,然后紧接着执行 counter++。
那岂不是 counter 直接就变成了 2,和原来的逻辑不一样了?
是的,不一样了。
搞的我 Debug 的时候一脸懵逼,后来才发现这个地方出现问题了。

那就不好意思了,意外收获,混个 pr 吧: