
记一次 Netty PR 的提交原创
有一个热心网友丁师傅提了一个问题,问为什么 netty 源码中,有这样一段代码
public final class InternalThreadLocalMap
extends UnpaddedInternalThreadLocalMap {
// ArrayList-related thread-locals
private ArrayList<Object> arrayList;
// ...
private BitSet cleanerFlags;
/** @deprecated These padding fields will be removed in the future. */
public long rp1, rp2, rp3, rp4, rp5, rp6, rp7, rp8, rp9;
}
为什么这里需要 9 个 long 型的 padding 来做 cache-line 的填充,为什么不是 8 个或者更少的用 7 个,比如大名鼎鼎的 Disruptor,它的缓存行填充方式如下
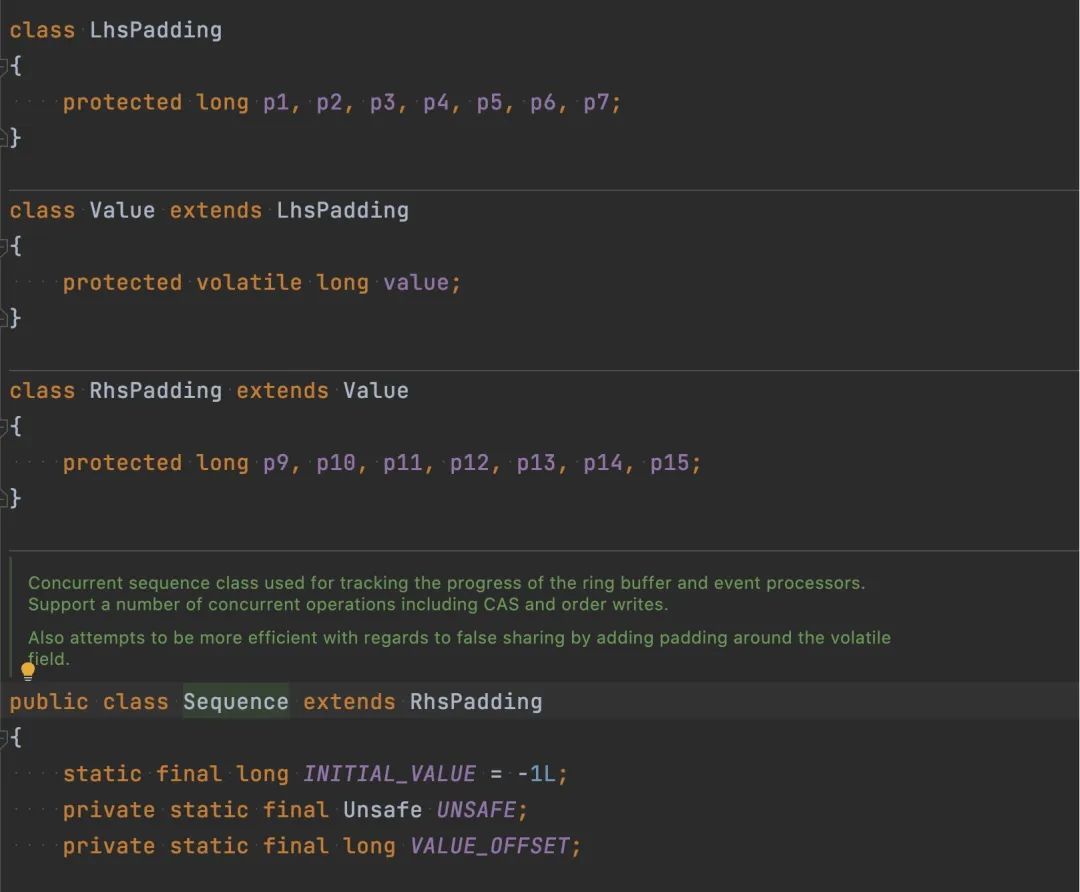
用了 7 个 long 去保护 value 这个值独占缓存行,这个稍后会讲到。
于是做了一下简单的研究,发现是 netty 在迭代的过程中一个小瑕疵,于是做了一次 PR 的提交,过了几天就被合并了,PR 地址如下:https://github.com/netty/netty/pull/12309
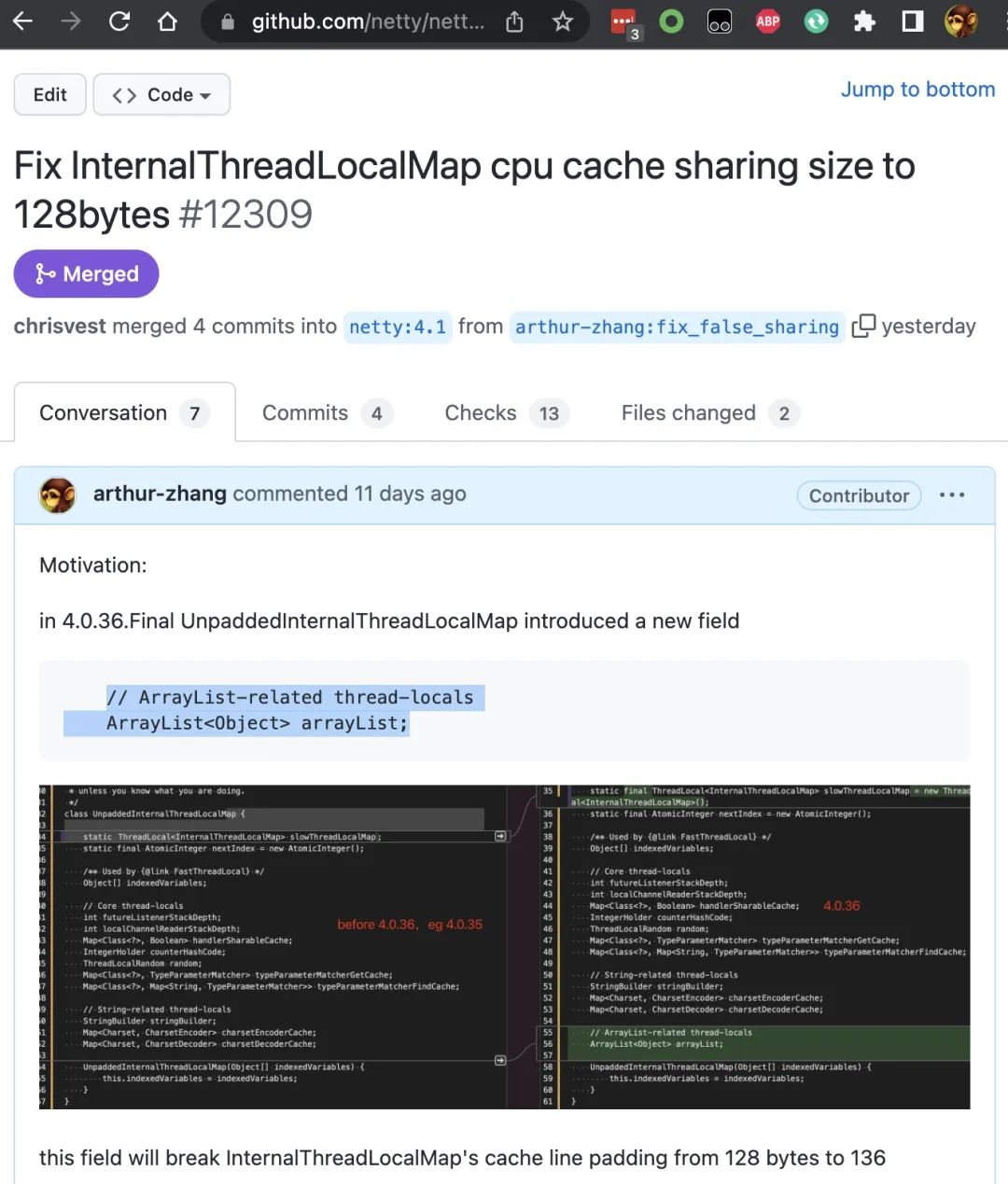
改动的地方就删了一个变量,混到一个 netty PR。

InternalThreadLocalMap 用 9 个 long 型在早期的版本里的目的是填充整个对象的大小达到 128 字节,以便充分利用缓存行。4.0.36 版本之前的 InternalThreadLocalMap 类占用的大小如下。
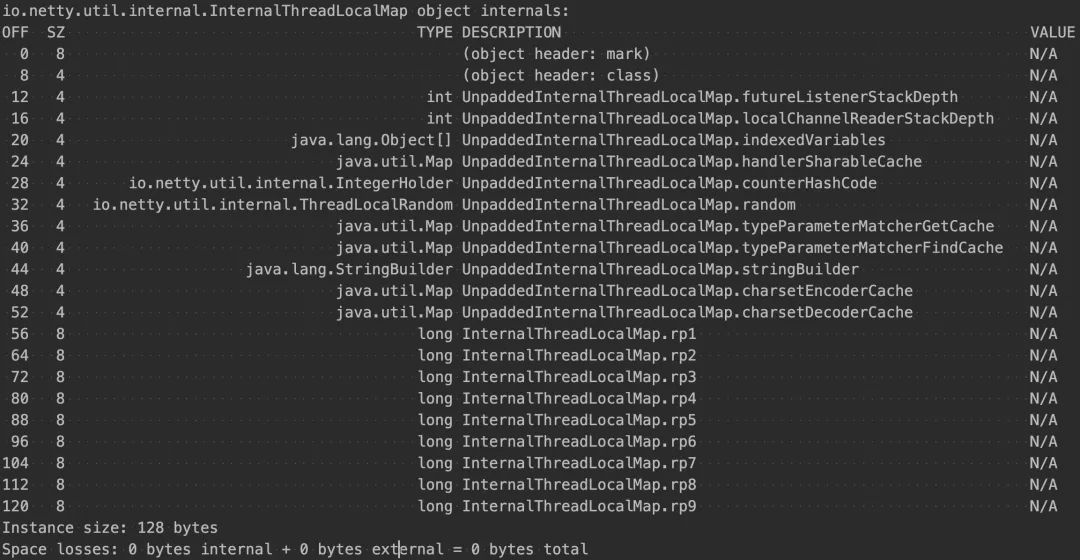
但是在迭代的过程中在 4.0.36 版本中,引入了一个新的变量 arrayList
class UnpaddedInternalThreadLocalMap {
// ...
// 4.0.36 版本新增
// ArrayList-related thread-locals
ArrayList<Object> arrayList;
}
public final class InternalThreadLocalMap
extends UnpaddedInternalThreadLocalMap {
}
之前的 InternalThreadLocalMap 的类对象对象已经到了 128 字节,但是在 4.0.36 版本又新增了这个 arrayList 变量,但是没有相应的调整填充 rp* long 型字段的个数,导致新的 InternalThreadLocalMap 类变量大小达到了 136 字节。
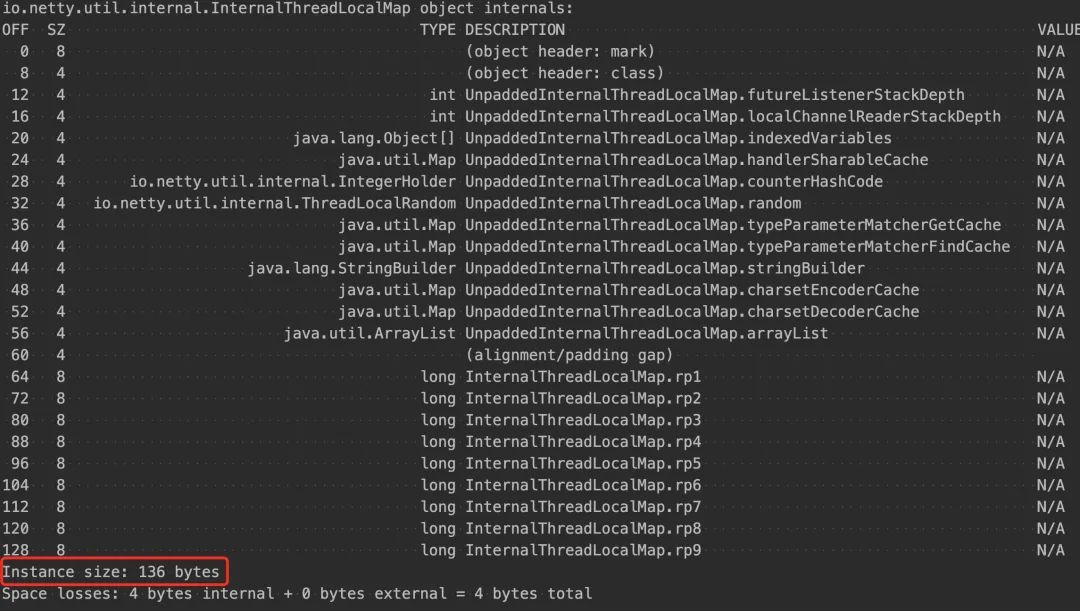
其实达到 136 字节也没什么问题,只是有点浪费。
到这里,Netty 这个问题的介绍就到这里了。
接下来我们先来看看什么是缓存行,什么是伪共享。
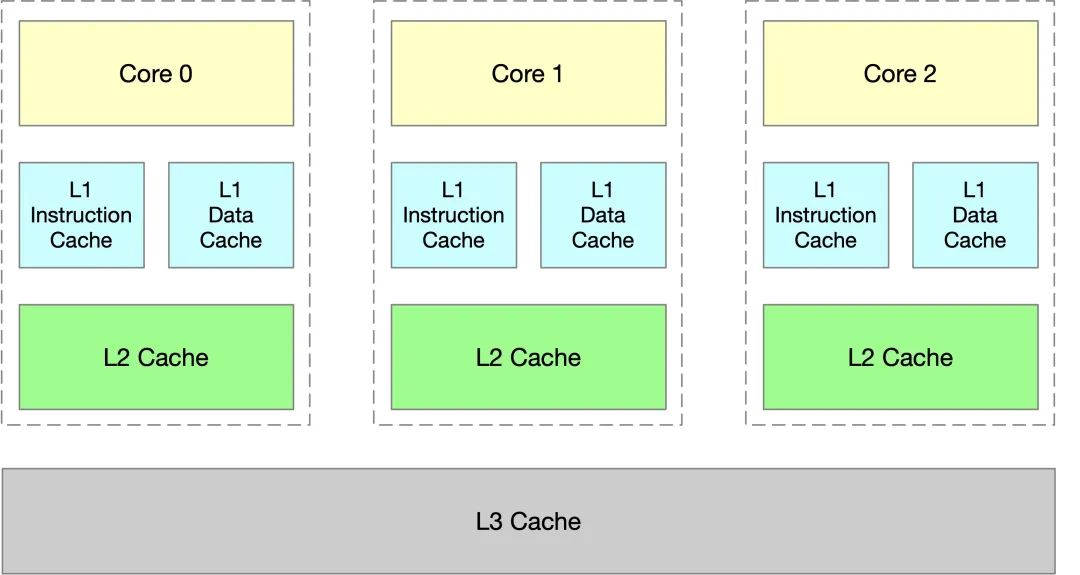
CPU 多级缓存
CPU 缓存通常分为**缓存:
-
L1 缓存:分成两种,一种是指令缓存,一种是数据缓存 -
L1 和 L2 缓存在每一个 CPU 核中 -
L3 则是所有 CPU 核心共享的内存
不同的缓存在访问速度上有非常大的区别:
| 时钟周期 | 需要时间 | |
|---|---|---|
| 寄存器 | 1 cycle | <1ns |
| L1 | 3~4 cycles | ~1ns |
| L2 | 12 cycles | ~3ns |
| L3 | 38 cycles | ~12ns |
| RAM | 100+ cycles | ~65ns |
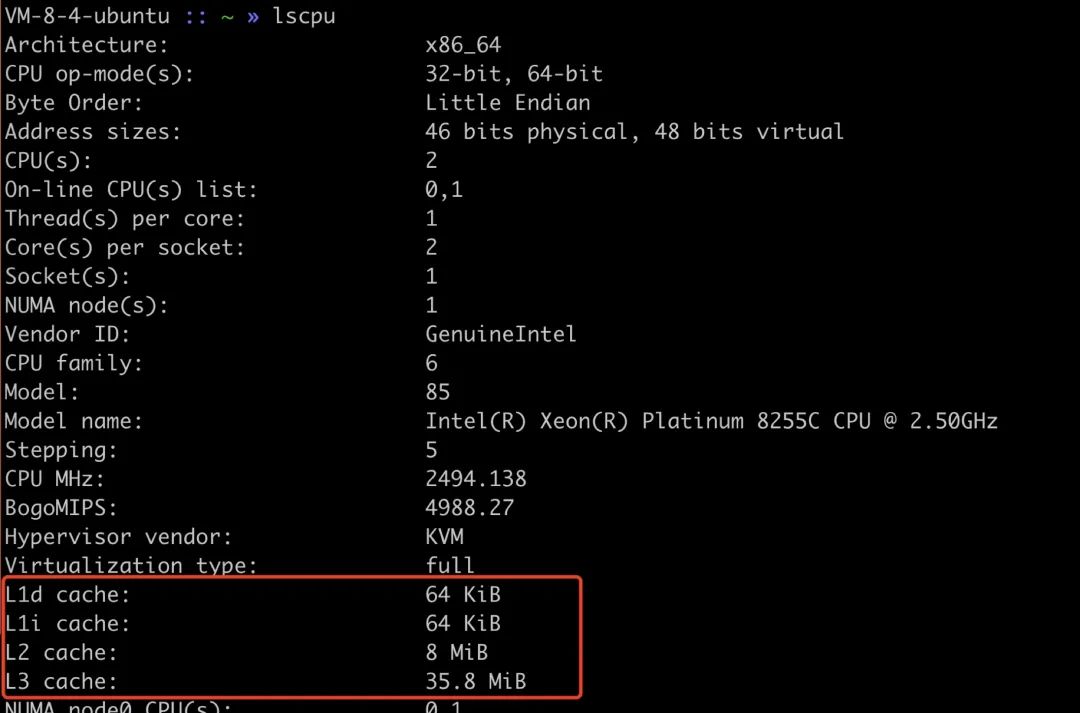
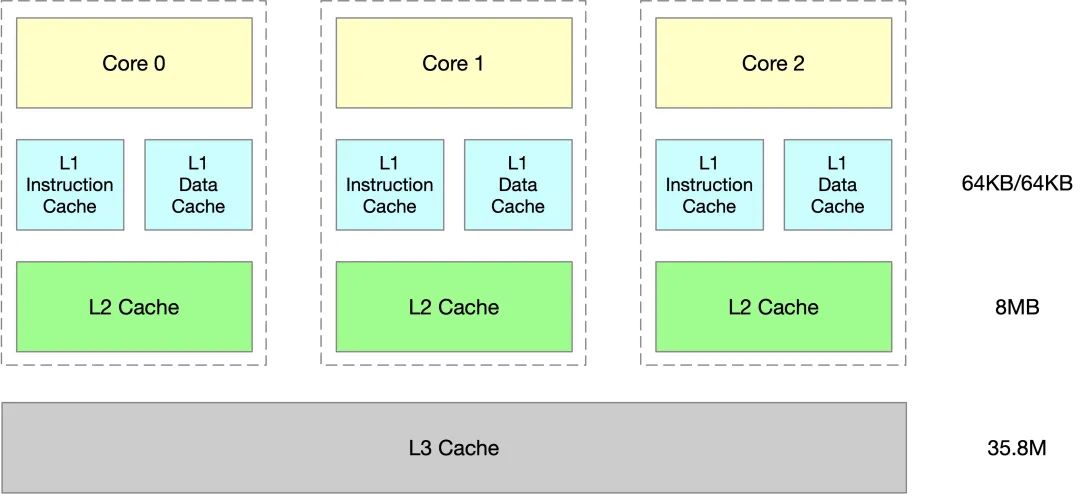
可以通过 lscpu 来查看 CPU cache 的大小
如下所示:
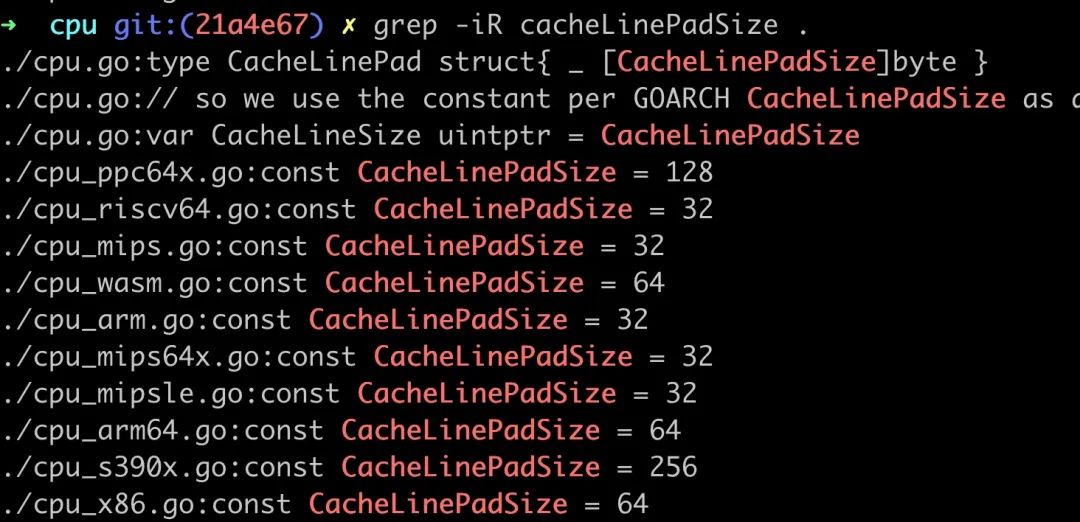
在支持多平台的编程语言里,也有类似的逻辑,以 Go 为例,src/internal/cpu,
什么是 CPU 缓存⾏(CPU Cache Line)
缓存⾏英文的解释就是“The minimum amount of cache which can be loaded or stored to memory”,缓存⼀次载⼊及写⼊数据的⼤⼩,通常为 64 字节,可以通过命令来查看。
$ cat /sys/devices/system/cpu/cpu0/cache/index1/coherency_line_size ↵
64
接下来做一个实验,有一个 2048 * 2048 的二维数组,我们 for 循环遍历所有的数据,通过对比先遍历行和先遍历列的方式,看看两者的耗时。
#define N 2048
int main(int argc, char **argv) {
int slowMode = atoi(argv[1]);
char arr[N][N];
clock_t start, end;
if (slowMode) {
start = clock();
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
arr[j][i] = 0;
}
}
end = clock();
printf("arr[j][i] mode, time: %ld\n", timediff(start, end));
} else {
start = clock();
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
arr[i][j] = 0;
}
}
end = clock();
printf("arr[i][j] mode, time: %ld\n", timediff(start, end));
}
}
结果如下
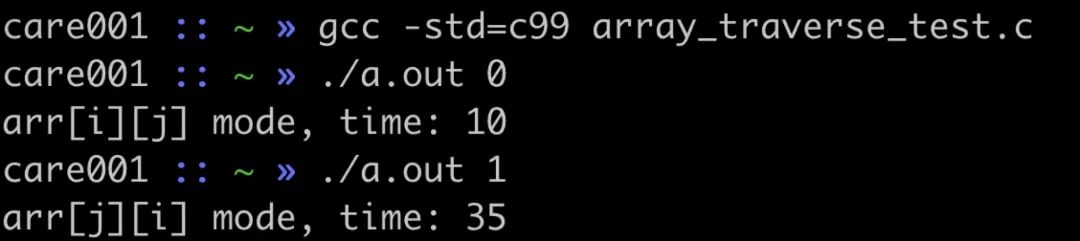
可以看到先遍历列的方式时间多了很多。
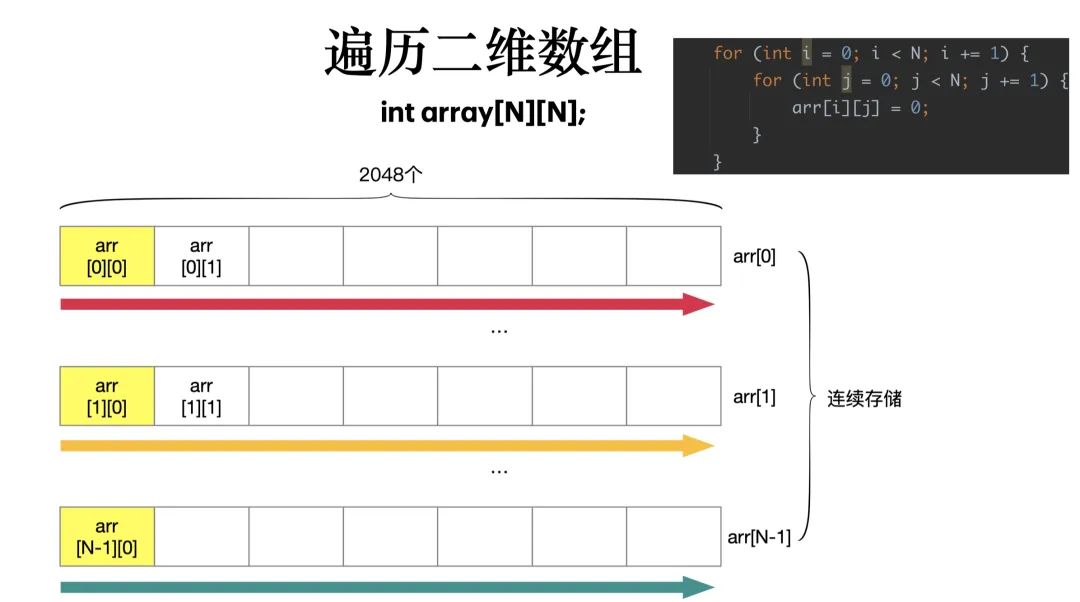
行遍历的方式如下:
列遍历的方式如下:
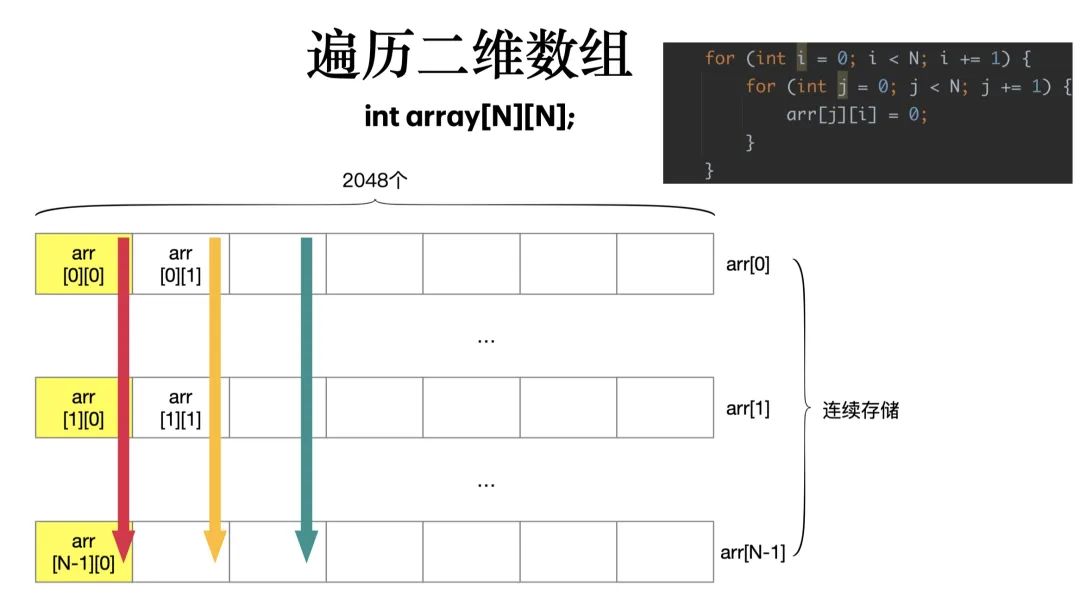
CPU Cache 加载内存里面的数据,不是一个一个字段加载的,而是加载一整个缓存行大小的数据,在本例中,用行遍历时,读取二维数组某一行的第一个数据时,会加载接下来的 64 字节的数据,在访问第二个数据时,就可以直接用 cache 中获取,速度自然快了很多。
ps:其实压根没什么二维数组,都是一维数组,都是下标和指针的 trick 而已。
cache line 在 Nginx 上的应用
CPU 缓存⾏的使用在很多高性能中间件都有应用,比如 Nginx 就有这样的配置项

伪共享(false sharing)
当多线程修改看似互相独⽴的变量时,如果这些变量共享同⼀个缓存⾏,就会在⽆意中影响彼此的性能,这就是伪共享,被称为并发编程⽆声的性能杀⼿。
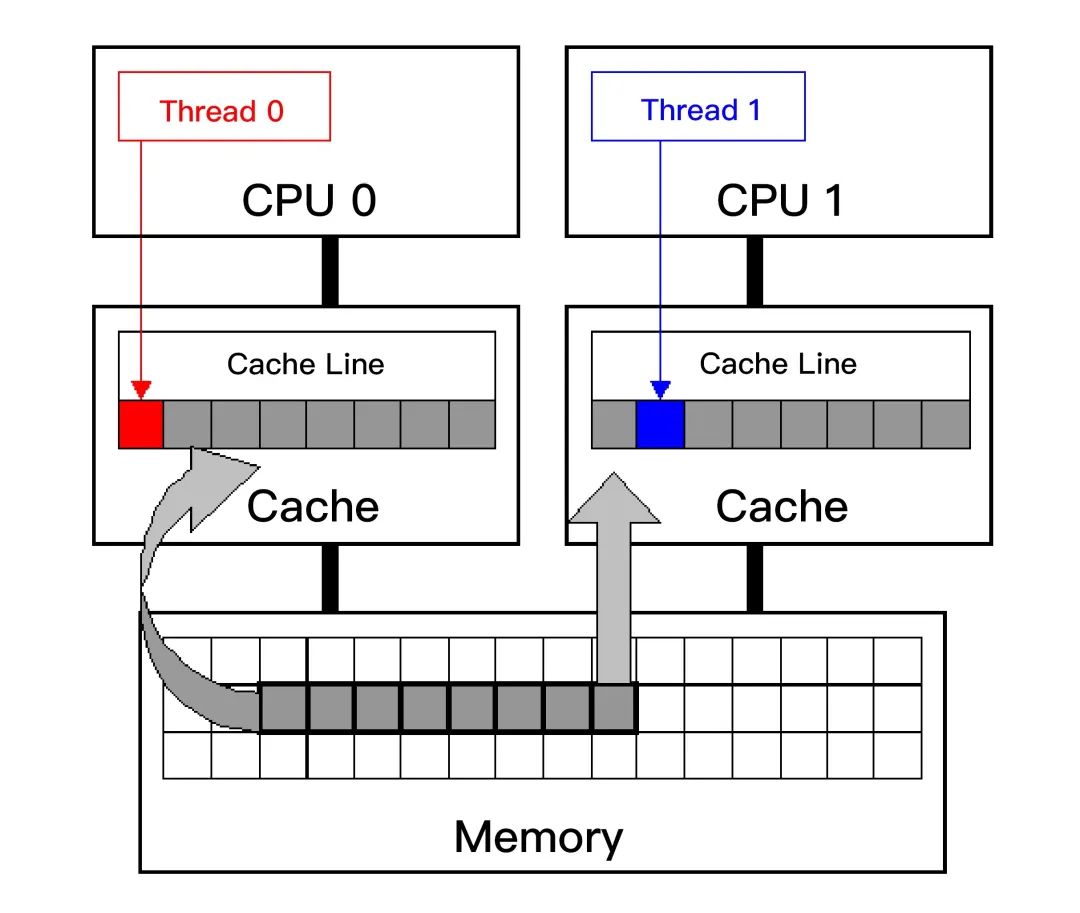
比如我们有这样一个结构体 Point 变量,当然用 java 等其它语言的 class 也是可以的。
struct Point {
long x;
long y;
} point;
有两个线程,一个在不停修改 x,一个在不停读取 y,会造成什么情况呢?
前面我们介绍过,CPU 加载内存中的数据,是按缓存行来加载,在修改 x 时,加载 x 的同时也会把 y 也加载到当前核心中的缓存行中,更新完 x 以后,包含 x 的缓存行就失效了,在第二个线程读取 y 时,发现这个缓存行已经失效,就要从内存中重新加载。
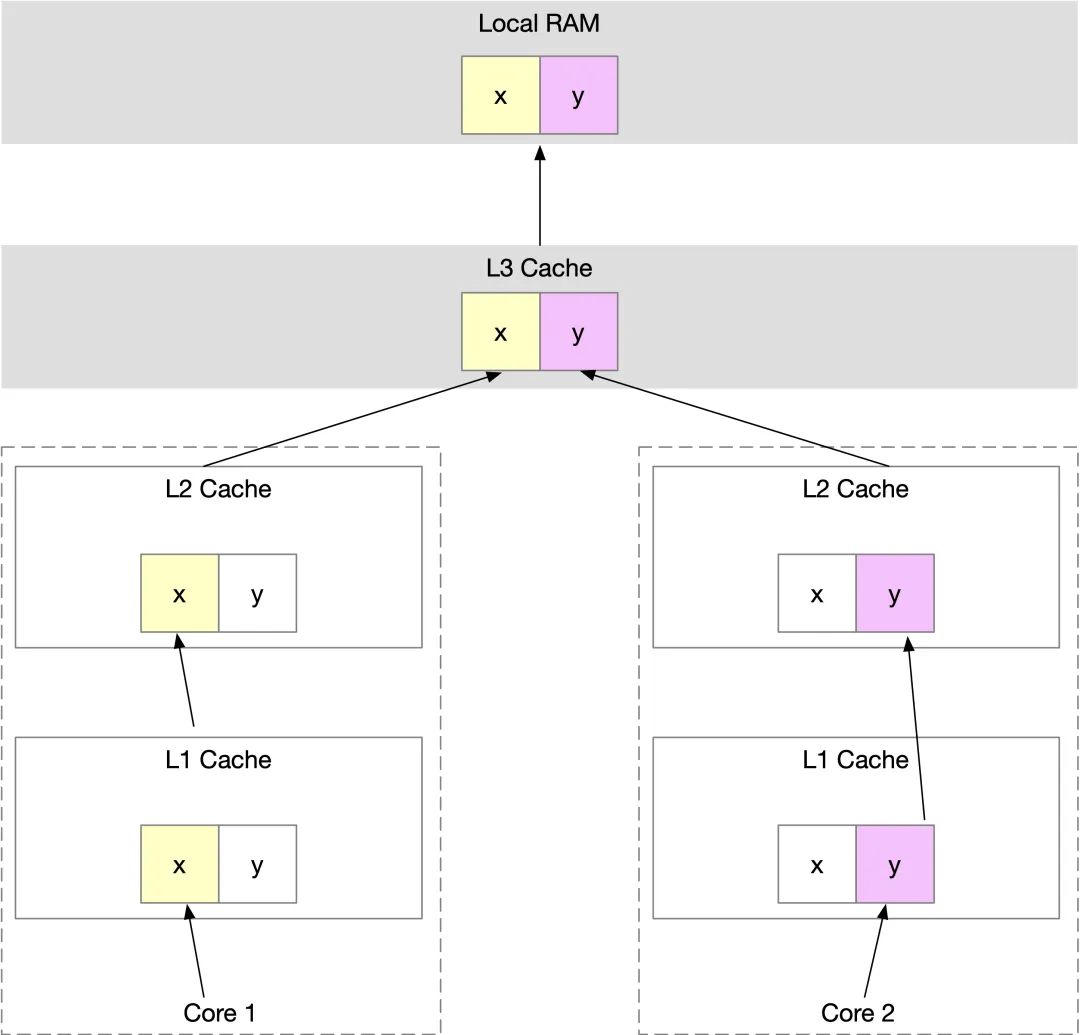
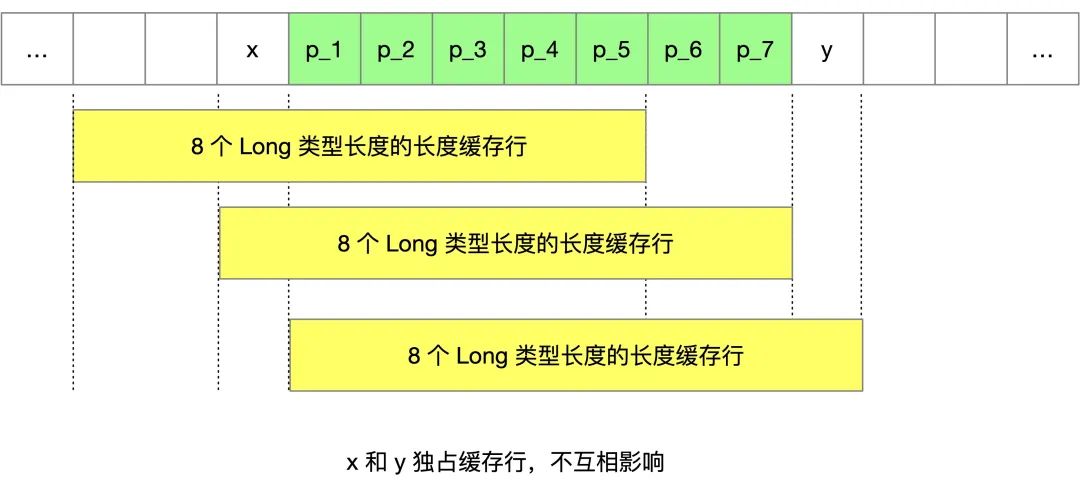
一个优化的方式,就是空间换时间,增大元素的间隔使得由不同线程存取的元素位于不同的缓存行上,以空间换时间,增加 7 个 long 型变量。
struct Point {
long x;
#ifdef ENABLE
long p_1;
long p_2;
long p_3;
long p_4;
long p_5;
long p_6;
long p_7;
#endif
long y;
} point;
目的就是让 x 和 y 独占缓存行,不互相影响。
CPU 缓存在 Disruptor 中的应用
Java SDK 的 ArrayBlockingQueue,其内部维护了 4 个成员变量,分别是队列数组 items、出队索引 takeIndex、入队索引 putIndex 以及队列中的元素总数 count。
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** The queued items */
final Object[] items;
/** items index for next take, poll, peek or remove */
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
/** Number of elements in the queue */
int count;
}
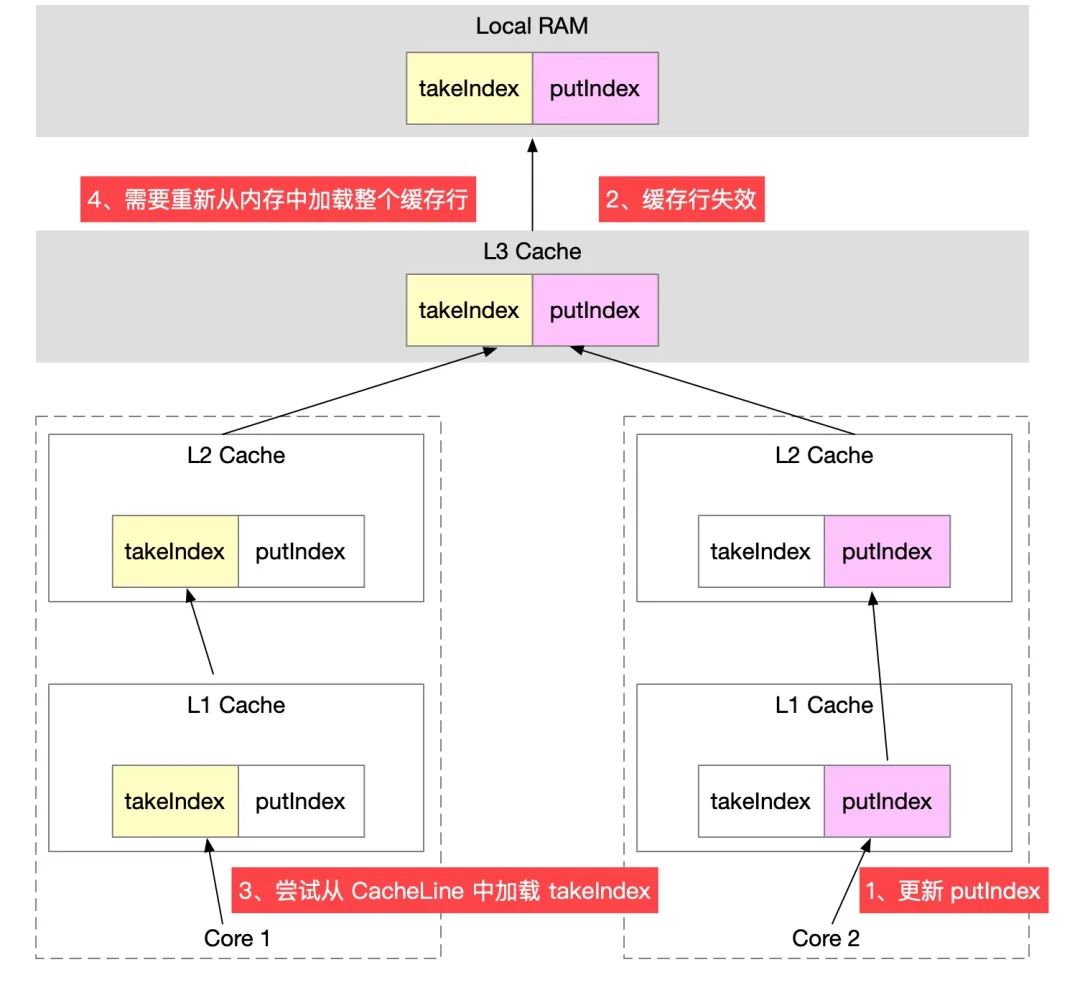
当 CPU 从内存中加载 takeIndex 时,会把 putIndex、count 等都加载到缓存行。假设一个线程执行入队操作,修改 putIndex,导致缓存行失效,另外一个线程执行出队操作,读取 takeIndex,由于前面的线程修改了 putIndex 导致缓存行失效,读取 takeIndex 只能重新从内存中读取。
从这里可以看到,入队压根就不会修改 takeIndex,但是由于修改了 putIndex,而 takeIndex 和 putIndex 共享的是一个缓存行,导致无法利用 CPU cache,导致伪共享的发生。
Disruptor 则使用字段填充的方式来避免伪共享
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding
{
}
通过继承的方式,在 value 前后都填充了 7 个 long 型的变量,让 value 独占缓存行,这样其它的变量修改不会影响到频繁读写的 value 值。

后记
高性能编程的水还是挺深的,不懂一点底层原理都看不懂很多代码为什么要那么写。



