
为什么 JVM 叫做基于栈的 RISC 虚拟机转载
其实这个问题比较简单,但我今天写这篇文章的主要目的是让大家看一下分析这个问题的逻辑,并且如何更好地从一手资料里寻找这些问题的答案。

上图是《深入理解 Java 虚拟机》一书中的截图。其实,说 JVM 是基于栈的虚拟机,指的是 JVM 所支持的指令集架构 ISA 是基于栈的,即字节码是基于栈的指令集架构。
有了指令集架构这层抽象,我们就无需关心其背后的实现是虚拟机还是物理机,甚至假如实际的执行是基于寄存器实现的,但指令集架构里是基于栈的,我们也可以说这套指令集架构是基于栈的。
------
指令集架构就是 ISA,Instruction Set Architecture。
我们通常使用的 Intel x86 CPU 的 ISA 可以查阅 Intel 手册第二部分。
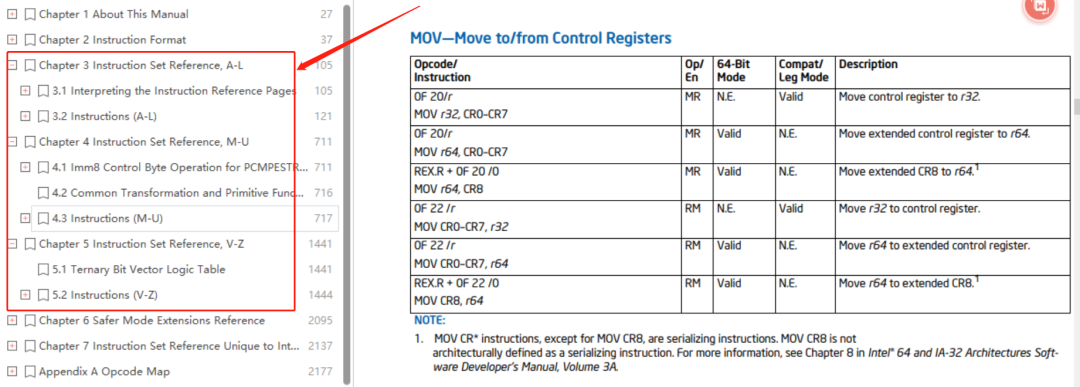
这里按照首字母排序分成了三个部分进行逐一讲解,一共有几千条指令,所以是属于 CISC 复杂指令集架构。
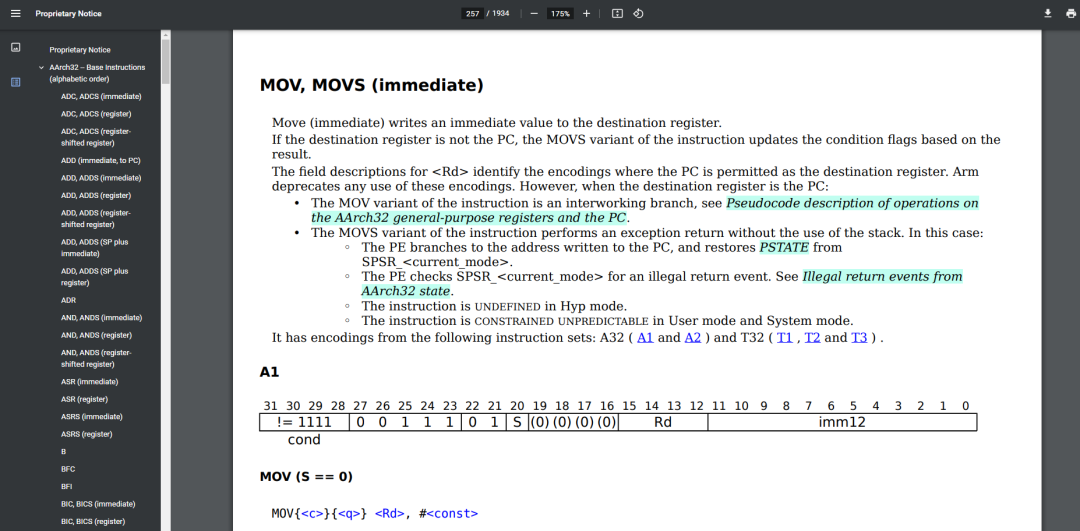
与之相对的精简指令集架构 RISC 的典型实现是 ARM,ARM 本身的指令集架构又分很多种,其中 A32 ISA 可以从官网下载到,指令数量仅有几百条,且指令长度均为 32 位,方便了指令译码与流水线优化。
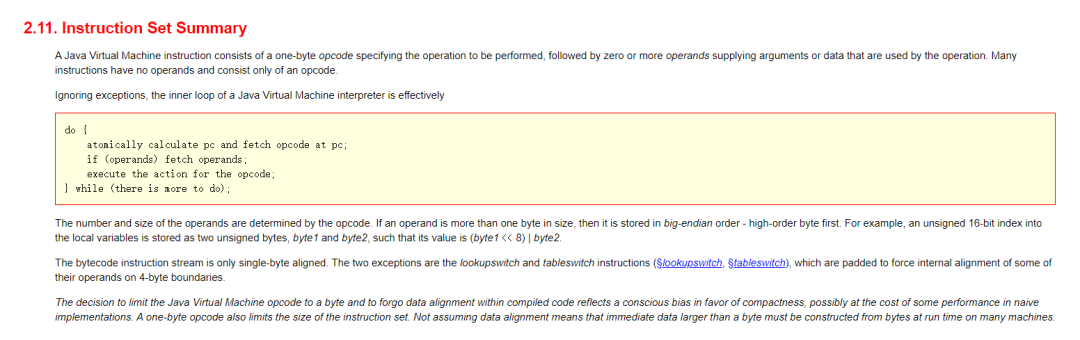
而对于 JVM 这台虚拟计算机来说,字节码就是它的 ISA,它的官方手册就是:
Java Language and Virtual Machine Specifications
在 2.11 小节中给出了 ISA 的概述。
在后面的 Chapter 6 中列出了每一条字节码指令的详细说明和用法。
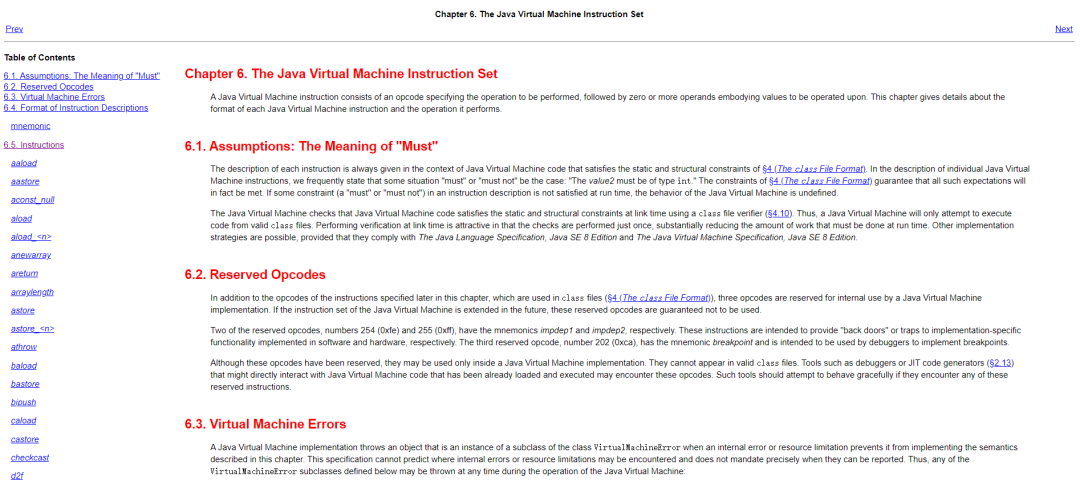
可以注意到,指令的数量非常少,且大部分是零地址指令,即指令长度大部分是固定的 1 字节,所以也是典型的 RISC 指令集架构。
------
字节码指令一共有多少个呢?看下 OpenJDK 源码里的 bytecodes.hpp,共 203 条指令。
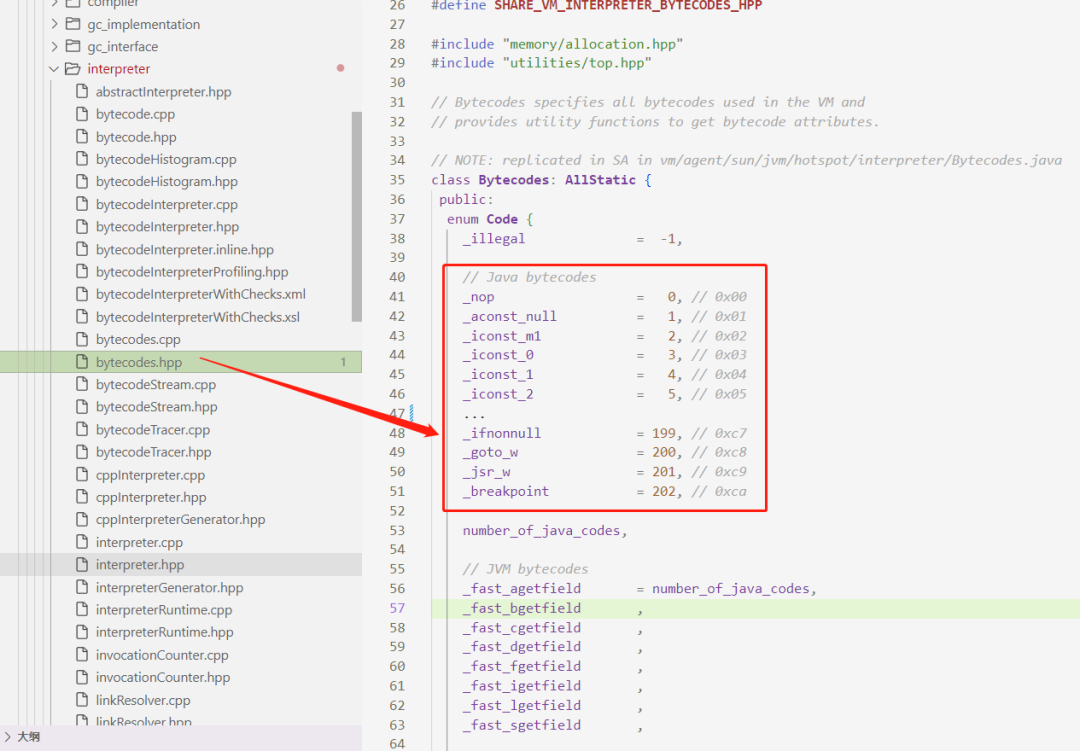
而且,还有很多比如 iconst_0 iconst_1 iconst2 ... 这样的,在官方文档中是都归为一类的,所以实际上的指令数量更少,可以放心地把它归为精简指令集的类别里。
好了,我们现在解释清楚了,JVM 为什么是 RISC 指令集架构的虚拟机了。回顾一下我们的思考方式。
Intel x86 --> Intel 手册 --> CISC
ARM -> ARM A32 手册 --> RISC
JVM -> JVM 手册 --> RISC
嗯,完美,接下来我们讨论,为什么 JVM 是基于栈的虚拟机?
------
有两个关键点,一,基于栈说的是 ISA 是基于栈的,即字节码是基于栈的。二,既然说了基于栈,那与之相对的是什么呢?
我们两个问题一块来解释。
我们用 c 语言写一段简单的 1+1 程序。
int add() {
int a = 1;
int b = a + 1;
return b;
}
它编译成 Intel x86 汇编是这样的。
add:
pushl %ebp
movl %esp,%ebp
subl $8,%esp
movl $1,-4(%ebp)
movl -4(%ebp),%edx
incl %edx
movl %edx,-8(%ebp)
movl -8(%ebp),%eax
jmp .L1
.L1:
leave
ret
可以看出这里的 edx 寄存器就是作为计算 b 的结果的关键部件,所以 x86 ISA 是基于寄存器的。
如果我们用 java 语言编写这段程序。
public int add() {
int a = 1;
int b = a + 1;
return b;
}
那么编译成给 JVM 看的 ISA 即字节码是这样的。
public int add();
Code:
0: iconst_1
1: istore_1
2: iload_1
3: iconst_1
4: iadd
5: istore_2
6: iload_2
7: ireturn
这里面的 iload_1 iconst_1 和 iadd 都是使用操作数栈,所以字节码是基于栈的 ISA。
这就把第二个问题讲清楚了,不需要其他多余的解释。
------
那具体的一条字节码指令在 CPU 中究竟是如何执行的呢?也是用栈来完成操作的么?
我们看其中一条指令 iconst_1
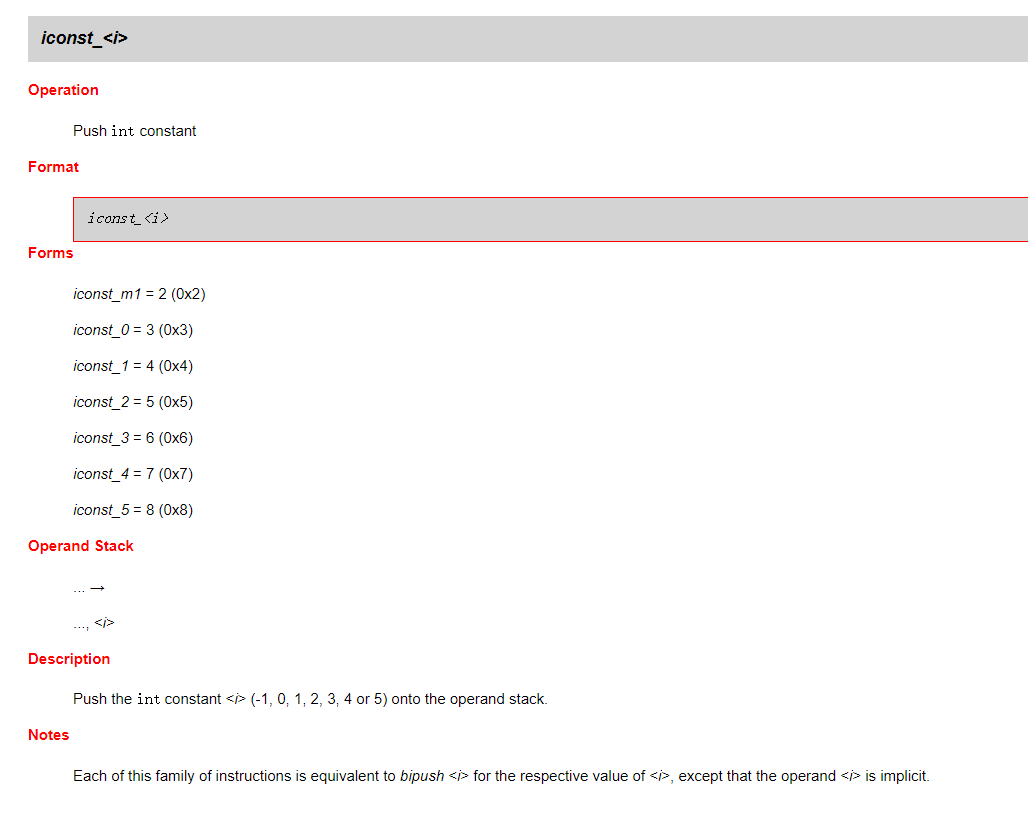
根据 JVM 手册上的说明,该指令表示将 1 放入操作数栈顶。如果落实到 Intel x86 CPU 上也是使用栈来完成的操作,应该大概是
pushl $1
这种样子。
那实际上这条字节码指令在 Intel x86 上对应的指令是什么呢?
这里有两种不同的方式,第一种是比较古老的字节码解释器,通过纯软件来模拟字节码的行为,效率很低。
比如 iconst_1 会通过宏定义 SET_STACK_INT 来执行
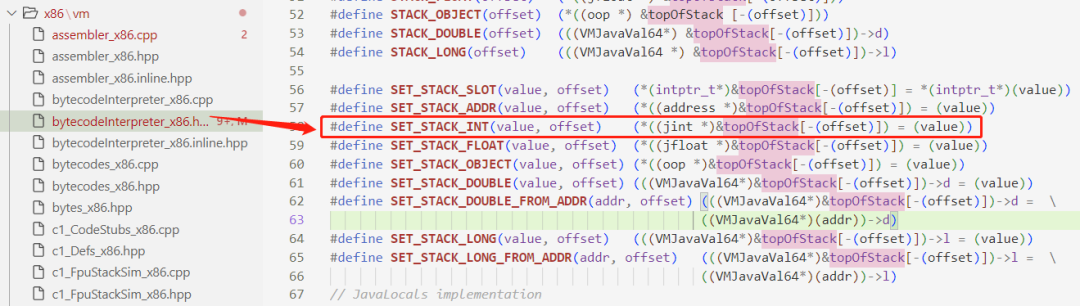
可以看到,实际上就是把数字 1 放入 topOfStack 数组中,这个数组就代表软件层面实现的 "操作数栈" 这个含义。
当然这种字节码解释器现在已经不用了,因为效率低下。那么第二种实现方式就是模板解释器,即将每一个字节码指令和一个模板函数绑定,这个模板函数里会直接生成对应的机器码。
我们仍然使用 iconst_1 这个字节码来看。
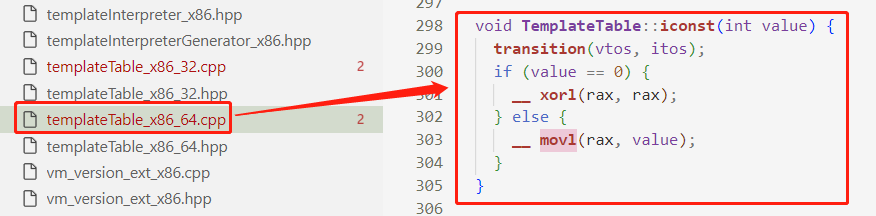
我们看到,iconst_1 会执行到 templateTable 里面的函数,这里我们看 Intel x86 64 位机的实现,所以是 templateTable_x86_64.cpp 里。
如果立即数 value 为 0,也就是 iconst_0 指令将会生成 xorl 的机器码,即简单对寄存器进行清零操作。如果不为 0,那么将会生成 movl 的机器码。
继续往里跟进,会发现最终就是使用 emit_int 函数直接往内存地址处写二进制数值,这些数值就表示机器码了。
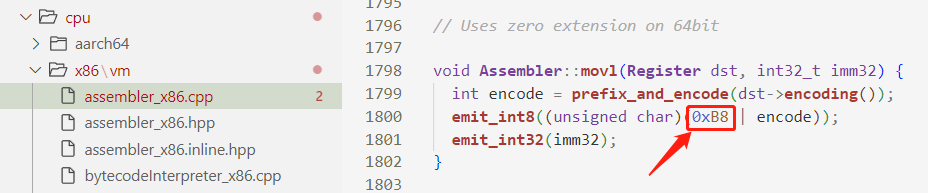
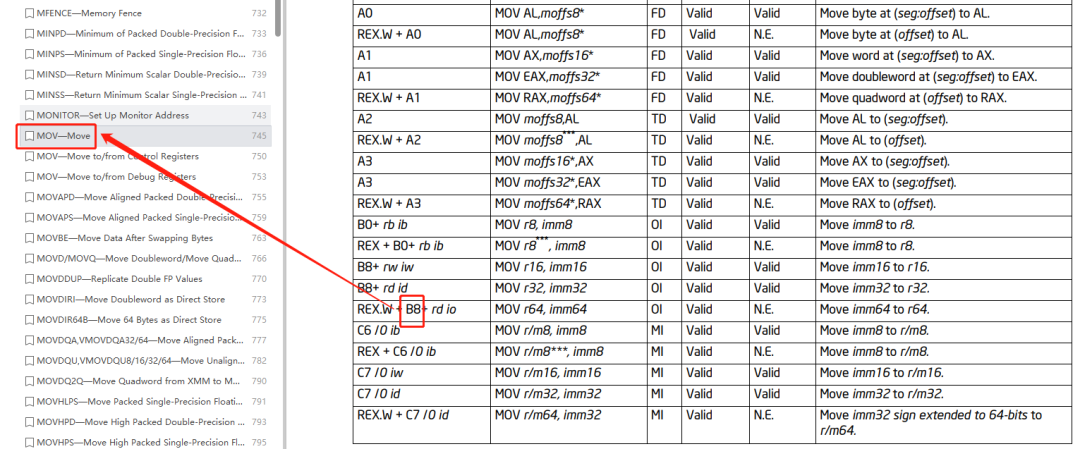
这里的 0xB8 是 x86 指令中的 Opcode 操作码,在 Intel 手册中可以看到,就是 mov 指令相关操作码的值。
在第一种字节码解释器中,iconst 会使用内存进行实现,可以理解为在软件层面真正实现了一个 "栈" 结构,即具体实现也是基于栈的。
但在模板解释器中,最终翻译成 x86 实现后仅仅只是寄存器操作,没有通过内存,即具体实现是基于寄存器的。
所以,虽然字节码这个 ISA 是基于栈来实现的,但具体再底层的实现是基于什么的,是不影响字节码是基于栈实现这个事实。
------
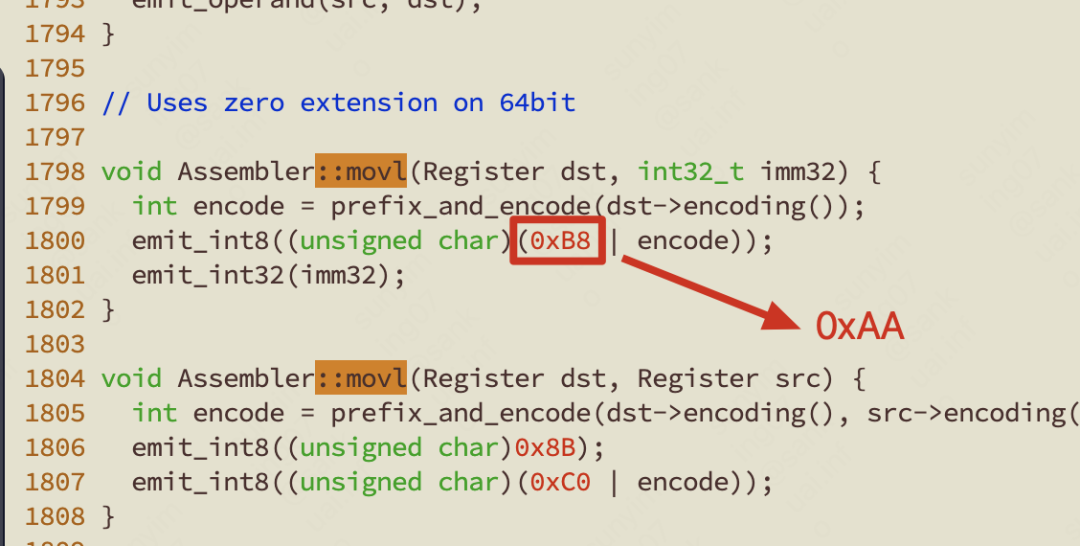
这时候我想搞怪一下,假如我把最终写入机器的这个机器码值给改了,那岂不是虚拟机就崩溃了?
我把刚刚那里的 0xB8 改成 0xAA,随便改个值,这么底层的位置,肯定会导致上面整座大厦都崩溃了。
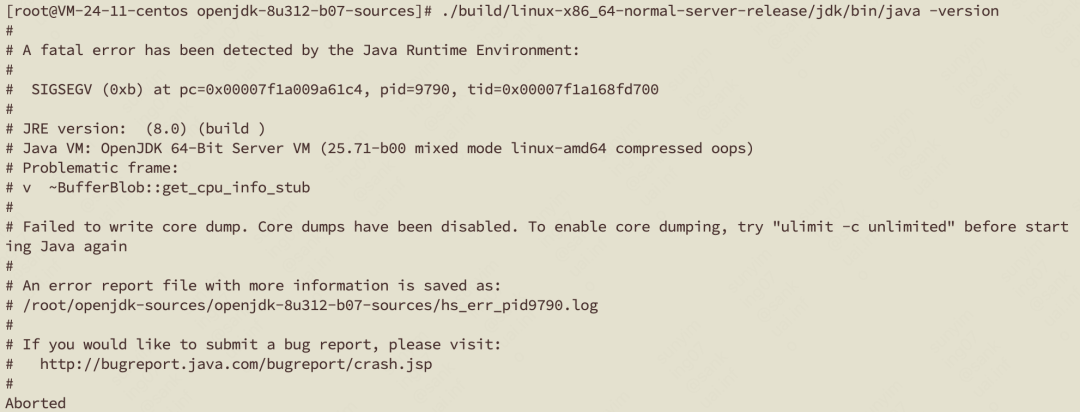
重新编译 openjdk,最终输出下 java -version,果然 crash 了。
------
OK,全部问题就解释清楚了。我们通过对不同指令集的具体实现对比,分析出字节码是 RISC 指令集的一种。我们又通过字节码的官方手册,分析出字节码是基于栈实现的。
最后我们又通过剖析字节码再底层的执行引擎,分析出用软件实现一个基于栈的指令集,只要上层表现上是基于栈的,那么底层实现上可以很灵活。
这也体现了分层的好处,Java 程序员们只需要知道操作数栈,并且通过操作数栈来理解字节码的执行原理就可以了,而且这样理解对于 Java 语言层面,也算是十分 "底层" 了。
最最最后,我们又搞怪了一下,把 JVM 搞 crash 了,也因此验证了我们的结论。
本文的知识点不难,读过 JVM 相关原理的同学应该对这些概念已经熟悉了,但如何通过 一手资料 + 源码 + 分析推理 + 搞怪 的方式把这一切串联起来,是我想表达给大家的,希望在这一点上你有所启发。



