
Java如何绑定线程到指定CPU上?原创
不知道你是啥感觉,但是我第一次看到这个问题的时候,我是懵逼的。
而且它还是一个面试题。
我懵逼倒不是因为我不知道答案,而是恰好我之前在非常机缘巧合的情况下知道了答案。
我感觉非常的冷门,作为一个考察候选者的知识点出现在面试环节中不太合适,除非是候选者主动提起做过这样的优化。
而且怕就怕面试官也是恰巧在某个书上或者博客中知道这个东西,稍微的看了一下,以为自己学到了绝世武功,然后拿出去考别人。
这样不合适。
说回这个题目。
正常来说,其实应该是属于考察操作系统的知识点范畴。
但是面试官呢又特定的加了“在 Java 中如何实现”。
那我们就聊聊这个问题。
Java线程
在聊如何绑定之前,先铺垫一个相关的背景知识:Java线程的实现。
其实我们都知道 Thread 类的大部分方法都是 native 方法:

在 Java 中一个方法被声明为 native 方法,绝大部分情况下说明这个方法没有或者不能使用平台无关的手段来实现。
说明需要操作的是很底层的东西了,已经脱离了 Java 语言层面的范畴。
抛开 Java 语言这个大前提,实现线程主要是有三种方式:
1.使用内核线程实现(1:1实现)
2.使用用户线程实现(1:N实现)
3.使用用户线程加轻量级进程混合实现(N:M实现)
这三种实现方案,在《深入理解Java虚拟机》的 12.4 小节有详细的描述,有兴趣的同学可以去仔细的翻阅一下。
总之,你要知道的是虽然有这三种不同的线程模型,但是 Java 作为上层应用,其实是感知不到这三种模型之间的区别的。
JVM 规范里面也没有规定,必须使用哪一种模型。
因为操作系统支持是怎样的线程模型,很大程度上决定了运行在上面的 Java 虚拟机的线程怎样去映射,但是这一点在不同的平台上很难达成一致。
所以JVM 规范里面没有、也不好去规定 Java 线程需要使用哪种线程模型来实现。
同时关于本文要讨论的话题,我在知乎上也找到了类似的问题:
https://www.zhihu.com/question/64072646/answer/216184631
这里面有一个R大的回答,大家可以看看一下。
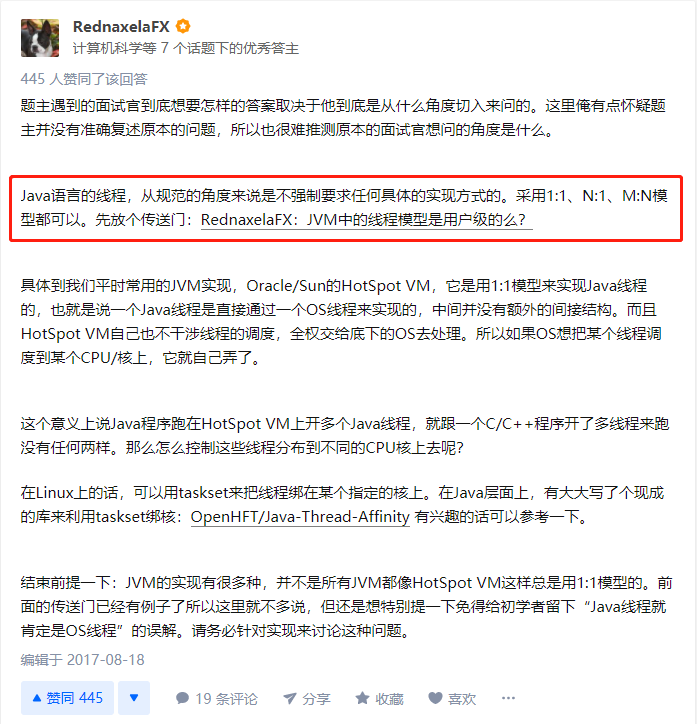
他也是先从线程模型的角度铺垫了一下。
我这里主要说一下使用内核线程实现(1:1实现)的这个模型。
因为我们用的最多的 HotSpot 虚拟机,就是采用 1:1 模型来实现 Java 线程的。
这是个啥意思呢?
说人话就是一个 Java 线程是直接映射为一个操作系统原生线程的,中间没有额外的间接结构。HotSpot 虚拟机也不干涉线程的调度,这事全权交给底下的操作系统去做。
顶多就是设置一个线程优先级,操作系统来调度的时候给个建议。
但是何时挂起、唤醒、分配时间片、让那个处理器核心去执行等等这些关于线程生命周期、执行的东西都是操作系统干的。
这话不是我说的,是R大和周佬都说过这样的话。
https://www.zhihu.com/question/64072646/answer/216184631
.png)
关于 1:1 的线程模型,大家记住书上的这幅图就行:
LWP:Light Weight Process 轻量级进程 KLT:Kernal-Level Thread 内核线程 UT:User Thread 用户线程
.png)
内核线程就是直接由操作系统内核支持的线程,这种线程由内核来完成线程切换,内核通过操纵调度器对线程进行调度,并负责将线程的任务映射到各个处理器上。
然后你看上面的图片,KLT 线程上面都有一个 LWP 与之对应。
啥是 LWP 呢?
程序一般来说不会直接使用内核线程,而是使用内核线程的一种高级接口,即轻量级进程(LWP),轻量级进程就是我们通常意义上说的线程。
然后大家记住书上的下面这段话,可以说是 Java 多线程实现的基石理论之一:
由于内核线程的支持,每个轻量级进程都成为一个独立的调度单元,即使其中某一个轻量级进程在系统调用中被阻塞了,也不会影响整个进程继续工作。
但是,轻量级进程也具有它的局限性。
首先,由于是基于内核线程实现的,所以各种线程操作,如创建、析构及同步,都需要进行系统调用。而系统调用的代价相对较高,需要在用户态(User Mode)和内核态(Kernel Mode)中来回切换。
其次,每个轻量级进程都需要一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的。
好的,终于铺垫完成了。
前面说了这么多,其实就是为了表达一个观点:
不论从什么角度来说,绑定线程到某个 CPU 上去执行都像是操作系统层面干的事儿。Java 作为高级开发语言,肯定是直接干不了的。需要更加底层的开发语言,Java 通过 JNA 技术去调用。
在R大的回答中也提到了解决方案:
在Linux上的话,可以用taskset来把线程绑在某个指定的核上。 在Java层面上,有大大写了个现成的库来利用taskset绑核:OpenHFT/Java-Thread-Affinity 有兴趣的话可以参考一下。
Java-Thread-Affinity
这个开源项目其实就是面试题的答案。
https://github.com/OpenHFT/Java-Thread-Affinity
项目里面有个问答,解答了如何使用它去做绑核的操作:
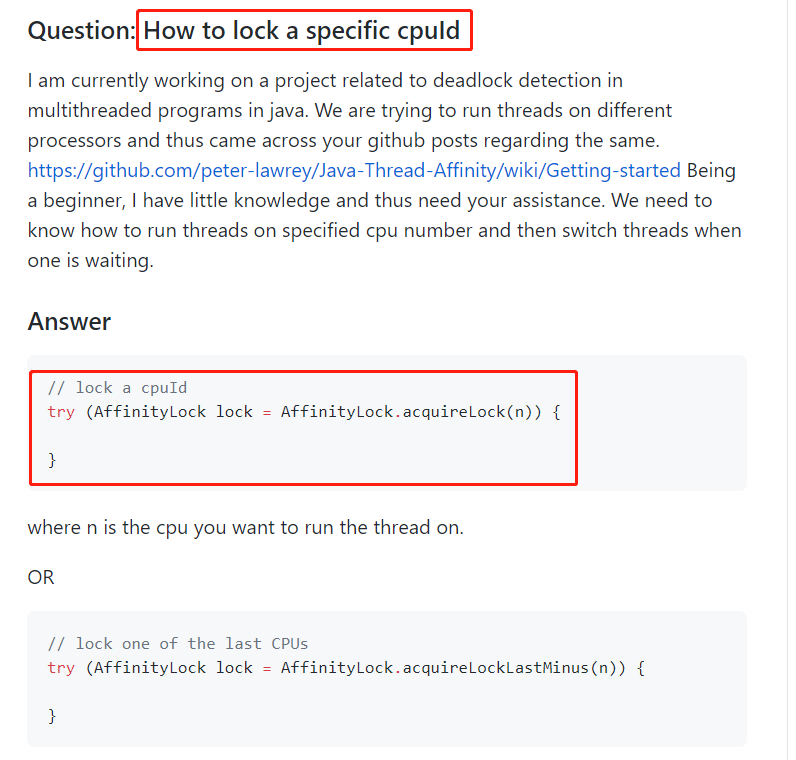
话不多说,直接上效果演示吧。
先把依赖搞到项目里面去:
<dependency>
<groupId>net.openhft</groupId>
<artifactId>affinity</artifactId>
<version>3.2.3</version>
</dependency>
然后来个 main 方法:
public static void main(String[] args) {
try (AffinityLock affinityLock = AffinityLock.acquireLock(5)) {
// do some work while locked to a CPU.
while(true) {}
}
}
按照 git 上的描述,我在方法里面写了一个死循环,为的是更好的演示效果。
上面的意思就是我要在第 5 个 CPU 线程执行死循环,把 CPU 利用率打到 100%。
来看一下效果。
这是没有程序启动之前:
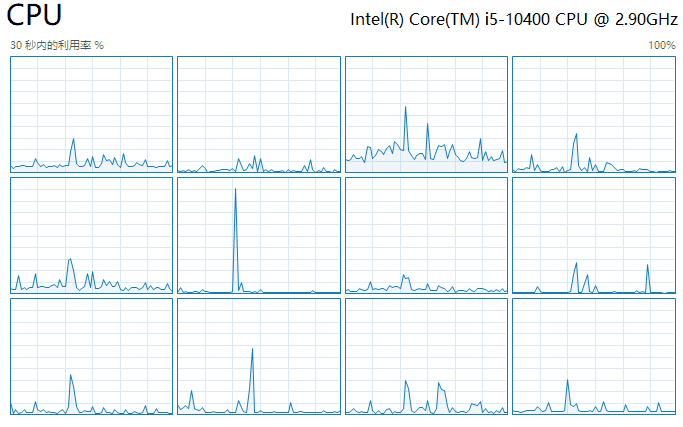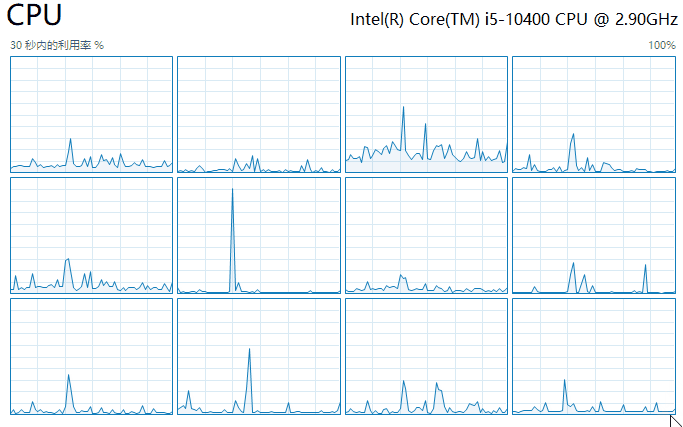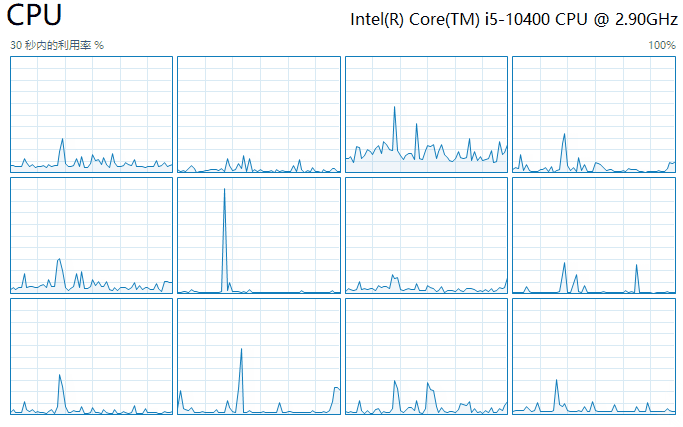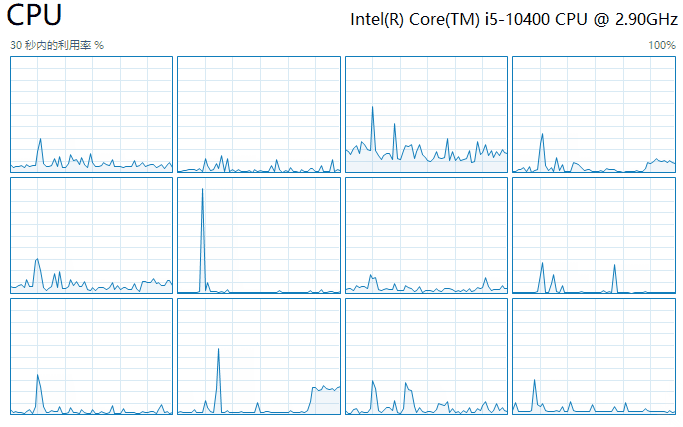
这是启动起来之后:
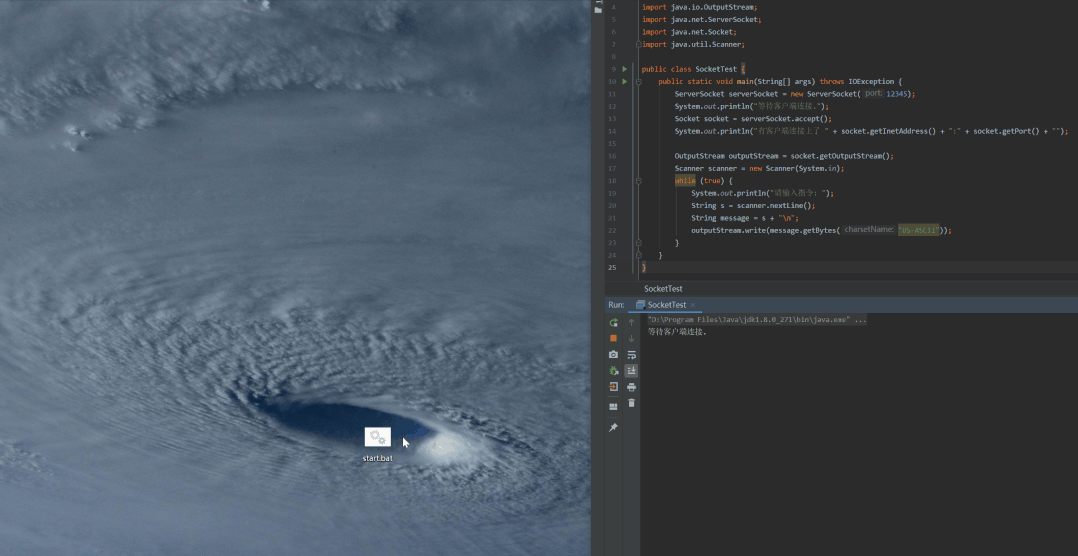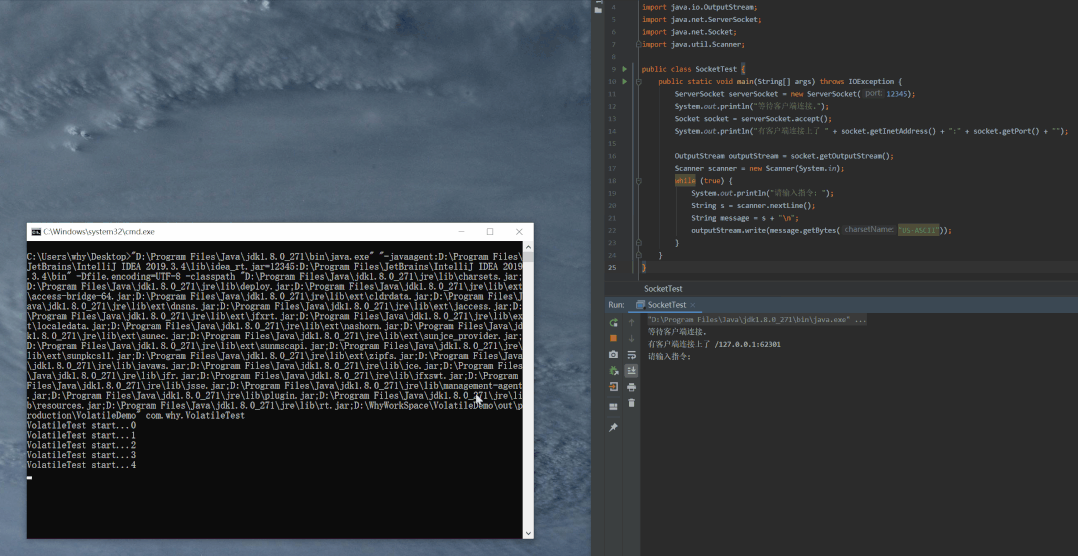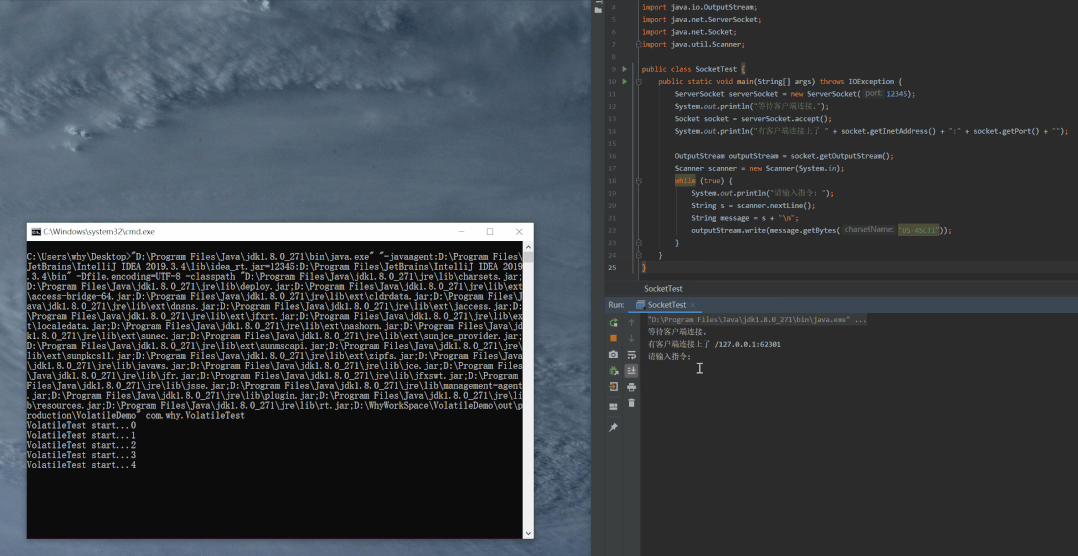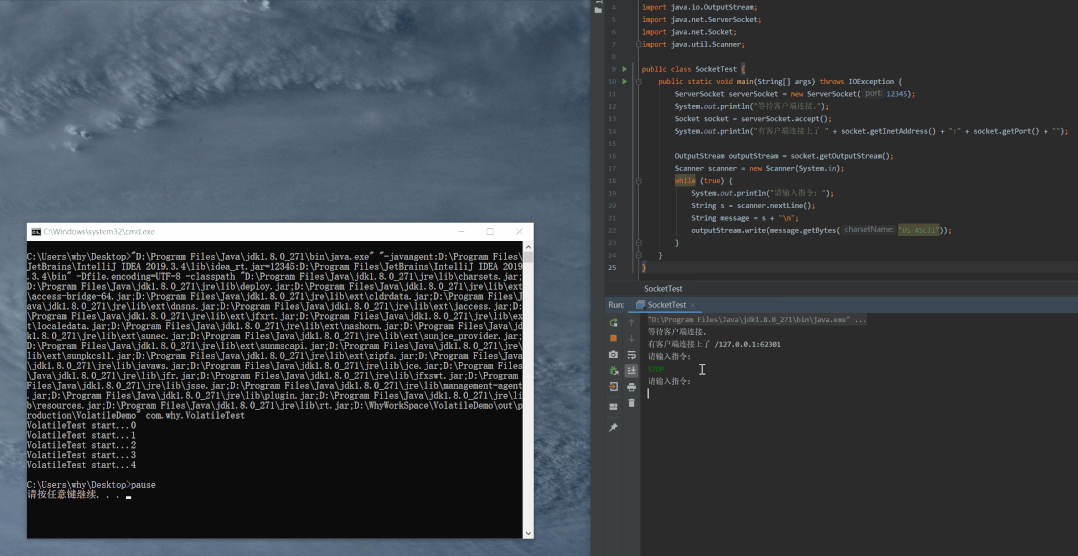
立竿见影,CUP 5 马上就被打满了。
同时还有两行日志输出,我截出来给你看一下:

另外,说明一下这个项目对应的 Maven 版本还是有好多个的:
在我的机器上,如果用高于 3.2.3 的版本就会出现这样的异常信息:

感觉是版本冲突了,反正没去深究,如果你也想跑一下,我就提醒一下而已。
效果我们现在是看到了,可以说这个项目非常的溜,可以实现把线程绑定到指定核心上去。
该功能也是有实际应用场景的,属于一直非常极致的性能优化手段吧。
绑定核心之后就可以更好的利用缓存以及减少线程的上下文切换。

说到这就不得不提起我第一次知道“绑核”这个骚操作的场景了。
那是举行于 2018 年的首届数据库性能大赛,或者更加出名一点的名字叫做天池大赛。
那一届比赛,我去打了个酱油,成绩非常拉胯就不提了。
但是我去仔细的看了前几名的赛后分享,大家的思路都是大同小异的。
我又不得不小声的叨叨一句:那一届比赛打到最后已经变成了开发语言层面上、参数配置上的差距了。C++ 天然优势,所以可以看到排在前面的清一色的 C++ 选手。
很多支队伍都提到了一个小细节,那就是绑核。
而我第一次知道这个开源项目,就是通过这篇文章《PolarDB数据库性能大赛Java选手分享》
.png)
当时把他的参赛代码拉下来看了一下,对于绑核操作有了一个基础认识,但是其实也没有深究实现。
只是这样写就对了,就能绑上就完事了。
再后来,我看 disruptor 这个框架的时候,看到它有一个这样的等待策略:
com.lmax.disruptor.BusySpinWaitStrategy
这个策略上有这样的一个注释:

It is best used when threads can be bound to specific CPU cores.
如果你要用这个策略,最好是线程可以被绑定到特定的 CPU 核心上。
就这样,奇怪的知识又被唤醒了。
我知道怎么绑定啊,Java-Thread-Affinity 这个开源项目就做了。
于是问题就变成了:它是怎么做呢?

怎么做的
具体怎么做的,只写几个关键的点,简单的分析一下,大家有兴趣的可以把源码拉下看。
首先第一个点:JNA 对于 Java-Thread-Affinity 非常重要:

可以说其实 Java-Thread-Affinity 就是套了个 Java 皮,这种应该让操作系统来做的事,其实编写更加底层的 C++ 或者 C 语言来实现的。
所以这个项目实质上是基于 JNA 调用了 DLL 文件,从而实现绑核的需求。
具体对应的代码是这样的:
net.openhft.affinity.Affinity
首先在这个类的静态代码块判断操作系统的类型:
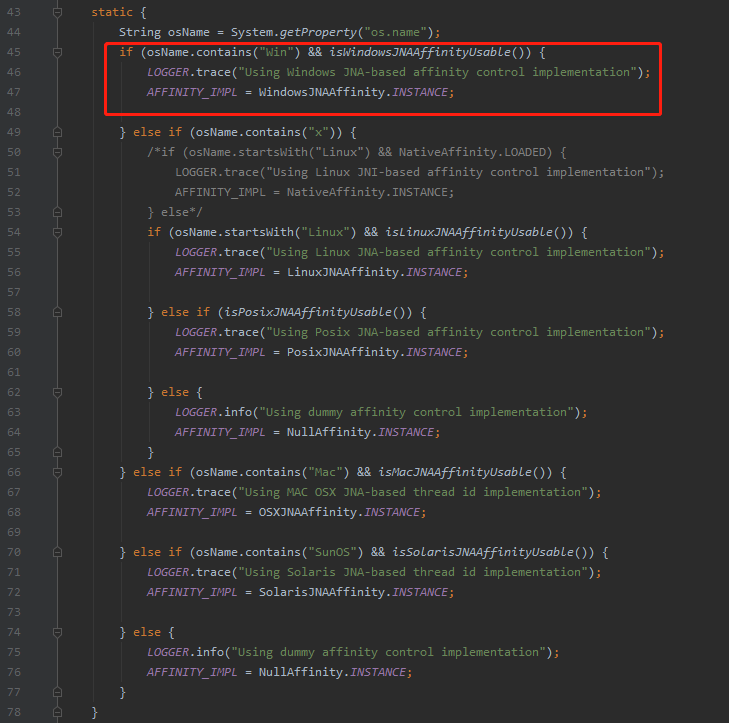
我这里是 win 操作系统。
net.openhft.affinity.IAffinity
是一个接口,有各个平台的线程亲和性实现:
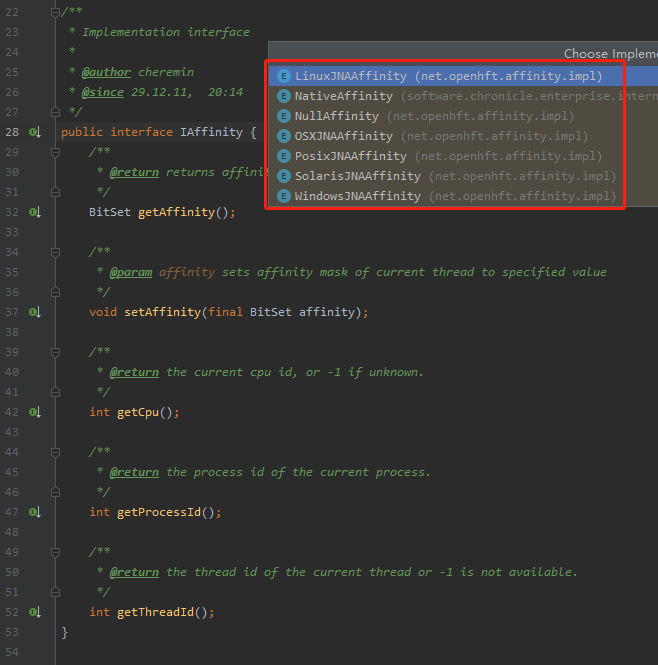
比如,在实现类 WindowsJNAAffinity 里面,你可以看到在它的静态代码块里面调用了这样的逻辑:
net.openhft.affinity.impl.WindowsJNAAffinity.CLibrary
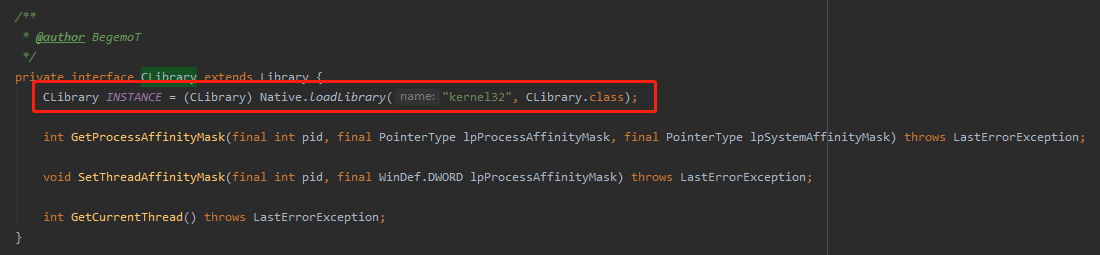
这里就是通过前面说的,通过 JNA 调用 kernel32.dll 文件。
在 windows 平台上能使用该功能的一些的基石就是在此。
第二个点:怎么绑定到指定核心上?
在其核心类里面有这样的一个方法:
net.openhft.affinity.AffinityLock#acquireLock(int)
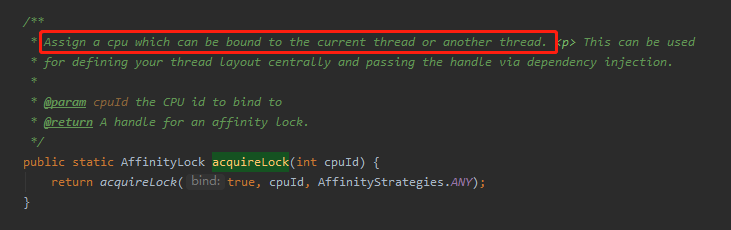
这里的入参,就是第几个 CPU 的意思,记得 CPU 编号是从 0 开始。
但 0 不建议使用:
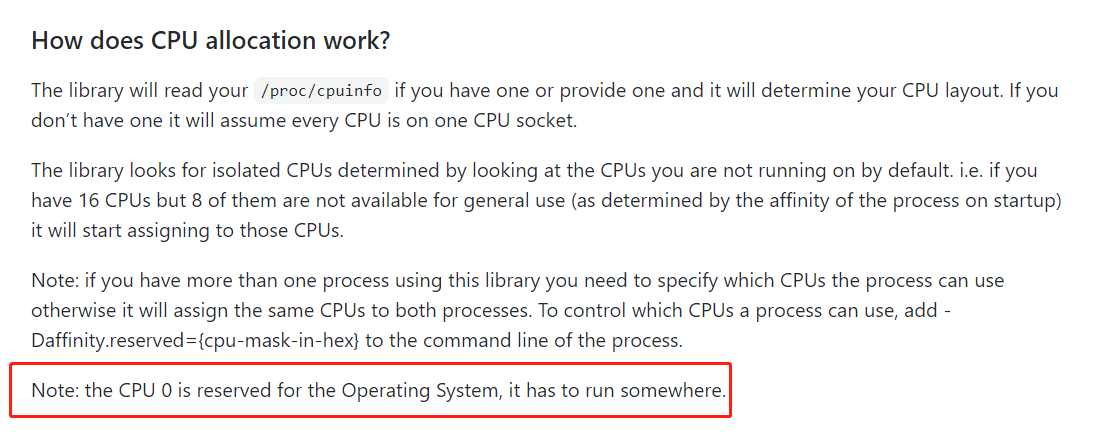
所以程序里面也控制了不能绑定到 0 号 CPU 上。
最终会走到这个方法中:
net.openhft.affinity.AffinityLock#bind(boolean)
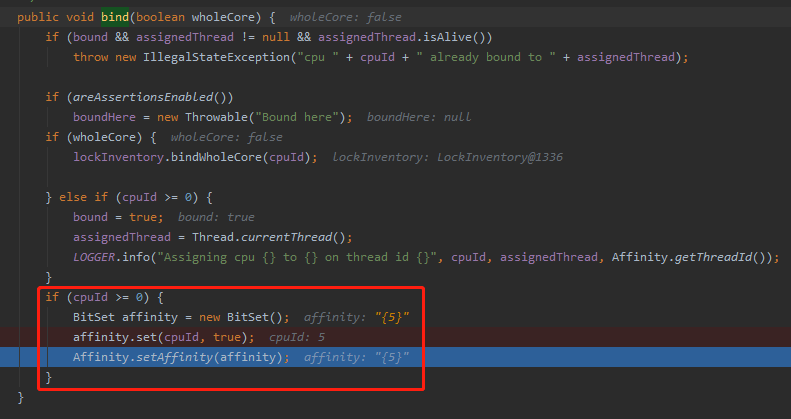
这里采用的是 BitSet,想绑定到第几个 CPU 就把第几个 CPU 的位置设置为 true。
在 win 平台上会调用这个方法:
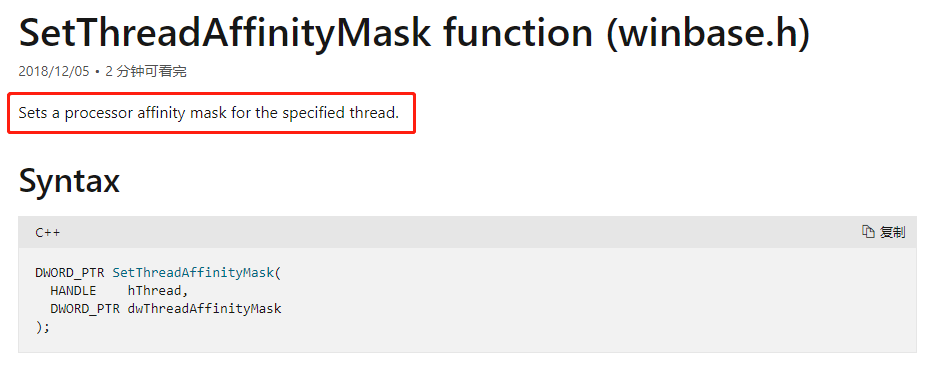
net.openhft.affinity.impl.WindowsJNAAffinity.CLibrary#SetThreadAffinityMask
这个方法,就是限制线程在哪个 CPU 上运行的 API。
https://docs.microsoft.com/zh-cn/windows/win32/api/winbase/nf-winbase-setthreadaffinitymask?redirectedfrom=MSDN
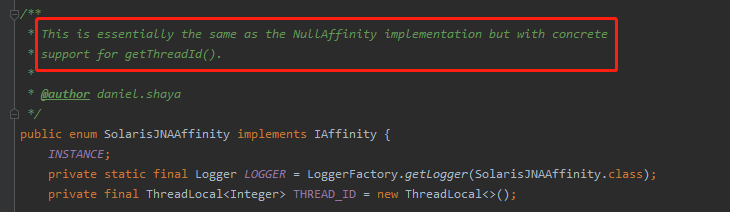
第三个点:Solaris 平台怎么实现的?
因为我们知道,在 Solaris 平台上的 HotSpot 虚拟机,同时支持 1:1 和 N:M 的线程模型。

那么按理来说得提供两套绑定方案,于是我点进去一看,好家伙:
大道至简,直接来一个不实现。
第四个点:有谁用了?
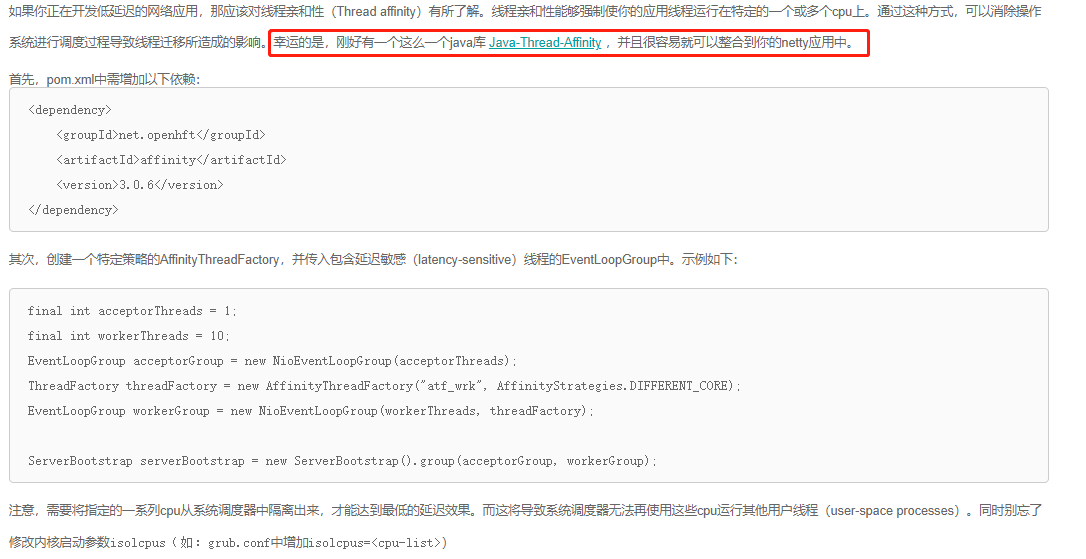
Netty 里面用到了这个库:
https://ifeve.com/thread-affinity/
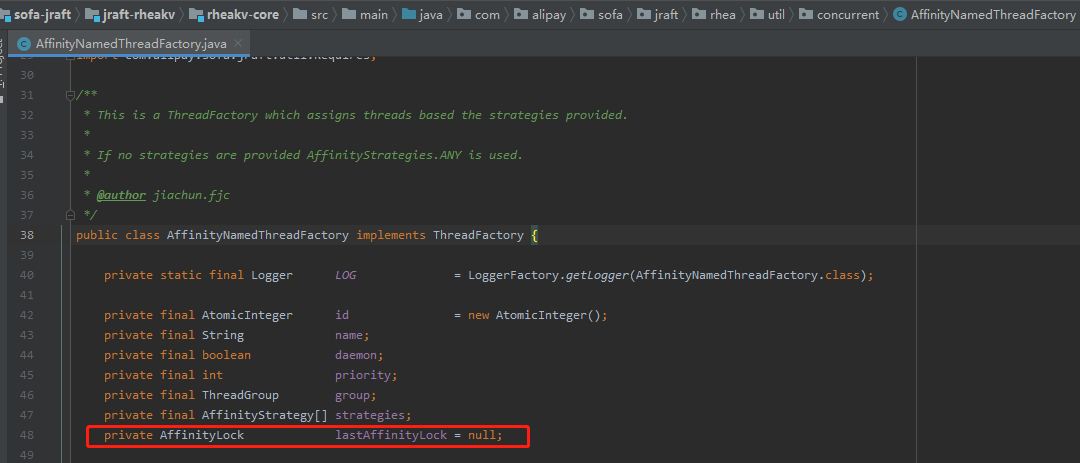
SOFAJRaft 里面也依赖了这个包:
https://github.com/sofastack/sofa-jraft/blob/master/README_zh_CN.md

然后我前面说到的比赛中也有这样的使用场景,在知乎也看到了这样的一个场景:

好了,文章写到这里也就可以收尾了。
你再想想这个面试题,如果面试官想要的真的是这个回答,你说合适吗?

而且你说你问这干啥,自己家啥业务场景啊,掂量掂量,需要优化到这个级别?
难道是高频交易?
人招进来后,可能线程池都看不到几个,你说是吧?

好了,手动保命,收工。
请自行脑补表情包:战术后仰.gif



