
初看一脸懵逼,看懂直接跪下!原创
你好呀,我是歪歪。
我最近在 stackoverflow 上看到一段代码,怎么说呢。
就是初看一脸懵逼,看懂直接跪下!
我先带你看看 stackoverflow 上的这个问题是啥,然后引出这段代码:
https://stackoverflow.com/questions/15182496/why-does-this-code-using-random-strings-print-hello-world
问题特别简单,就一句话:
谁能给我解释一下:为什么这段代码使用随机字符串打印出了 hello world?

代码也很简单,我把它拿出来给你跑一下:
public class MainTest {
public static void main(String[] args) {
System.out.println(randomString(-229985452) + " " + randomString(-147909649));
}
public static String randomString(int i) {
Random ran = new Random(i);
StringBuilder ** = new StringBuilder();
while (true) {
int k = ran.nextInt(27);
if (k == 0)
break;
**.append((char) ('`' + k));
}
return **.toString();
}
}
上面的代码你也可以直接粘贴到你的运行环境中跑一下,看看是不是也输出的 hello world:
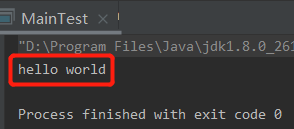
我就问你:即使代码都给你了,第一眼看到 hello world 的时候你懵不懵逼?

高赞回答
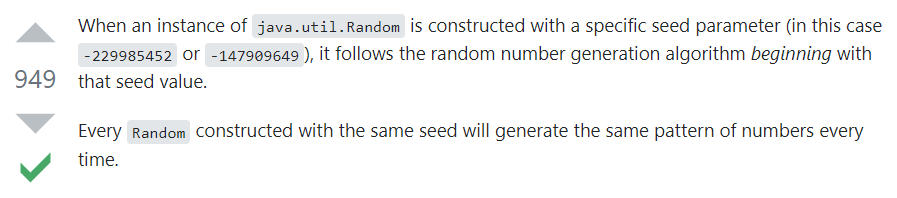
高赞回答也特别简单,就这么两句话。
我给你翻译一下,这个哥们说:
当我们调用 Random 的构造方法时,给定了一个“种子”(seed)参数。比如本例子中的:-229985452 或 -147909649。
那么 Random 将从指定的种子值开始生成随机数。
而每个用相同的种子构造的 Random 对象,都会按照产生相同的模式产生数字。
没看的太明白,对不对?
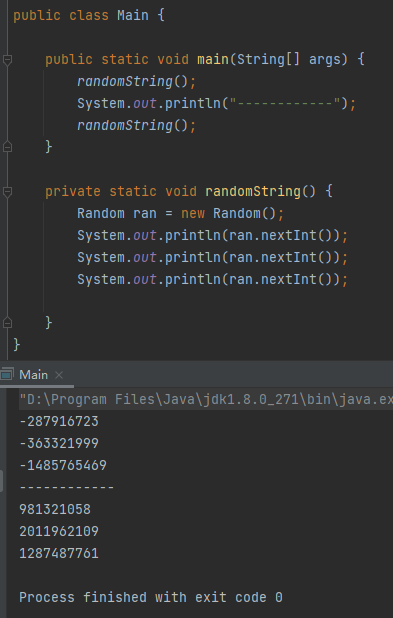
没关系,我给你上一段代码,你就能恍然大悟上面这一段说的是啥事:
public static void main(String[] args) {
randomString(-229985452);
System.out.println("------------");
randomString(-229985452);
}
private static void randomString(int i) {
Random ran = new Random(i);
System.out.println(ran.nextInt());
System.out.println(ran.nextInt());
System.out.println(ran.nextInt());
System.out.println(ran.nextInt());
System.out.println(ran.nextInt());
}
这段代码,在我的机器上运行结果是这样的:
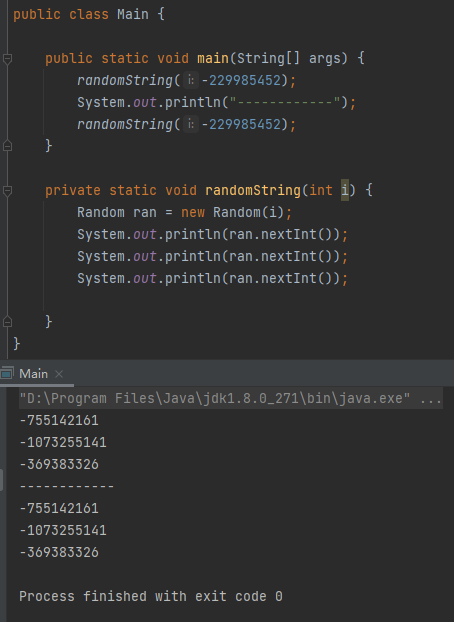
你拿过去跑,你的运行结果也一定是这样的。
这是为什么呢?
答案就在 Javadoc 上写着的:

如果用相同的种子创建了两个 Random 的实例,并且对每个实例进行了相同的方法调用序列,那么它们将生成并返回相同的数字序列。
在上面的代码中两个 -229985452 就是相同的种子,而三次 nextInt() 调用,就是相同的调用序列。
所以,他们生成并返回相同的、看起来是随机的数字。

而我们正常在程序里面的用法应该是这样的:
在 new Random() 的时候,不会去指定一个值。
我们都知道 Random 是一个伪随机算法,而构建的时候指定了 seed 参数的就是一个更加伪的伪随机算法了。
因为如果我可以推测出你的 seed 的话,或者你的 seed 泄露了,那么理论上我就可以推测出你随机数生成序列。
这个我已经在前面的代码中演示了。
再看看问题
在前面稍微解释了 “seed” 的关键之处之后,我们再回过头去品一品这个问题,大概就能看出点端倪了。
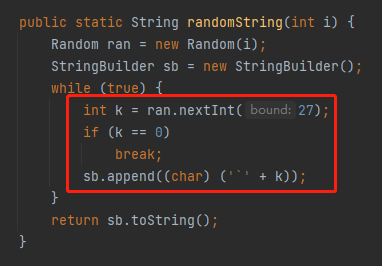
主要看这个循环里面的代码。
首先 nextInt(27) 就限定了,当前返回的数 k 一定是在 [0,27) 之间的一个数字。
如果返回 0,那么循环结束,如果不为零。则做一个类型转换。
接下来就是一个 char 类型的强制转换。
看到数字转 char 类型,就应该条件反射的想到 ascii 码:
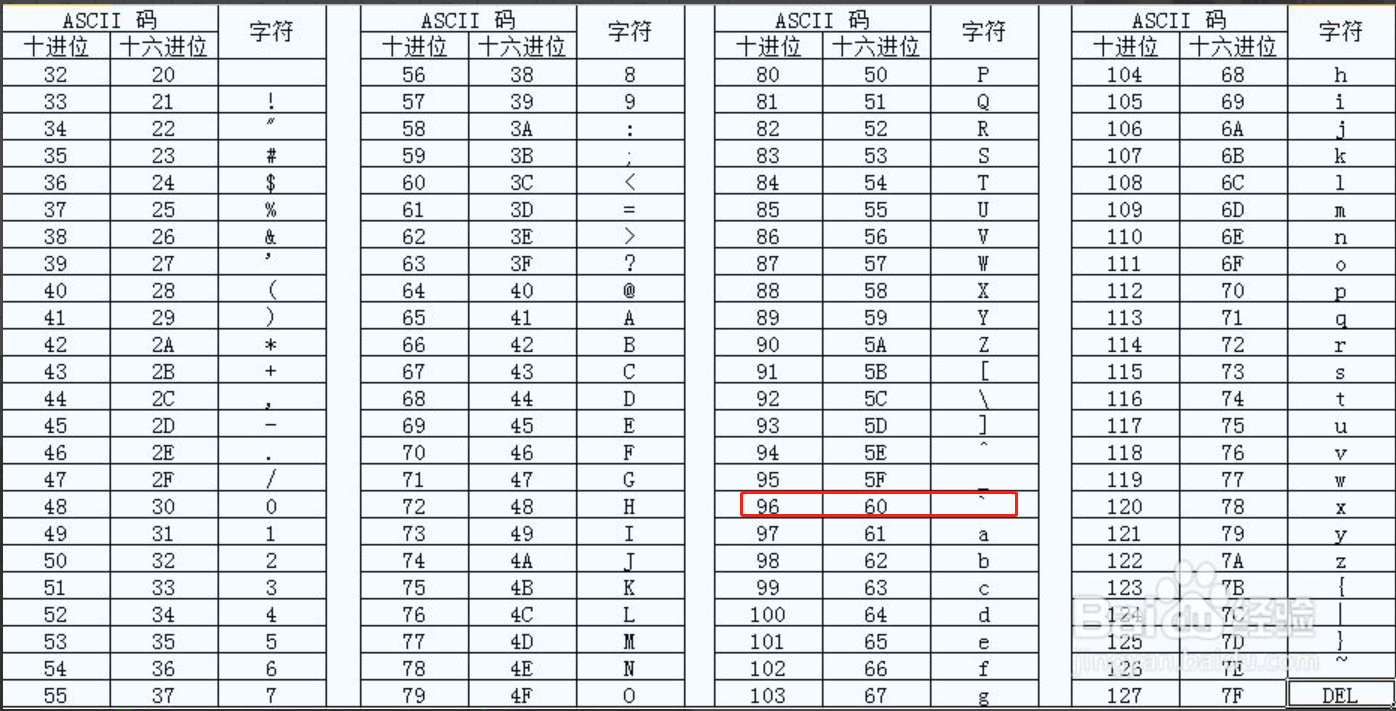
从 ascii 码 表中,我们可以到 “96” 就是这里的这个符号:
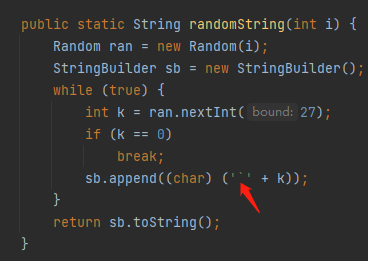
所以,下面这个代码的范围就是 [96+1,96+26]:
'`' + k
也就是 [97,122],即对应 ascii 码的 a-z。
所以,我带你再把上面的演示代码拆解一下。
首先 new Random(-229985452).nextInt(27) 的前五个返回是这样的:
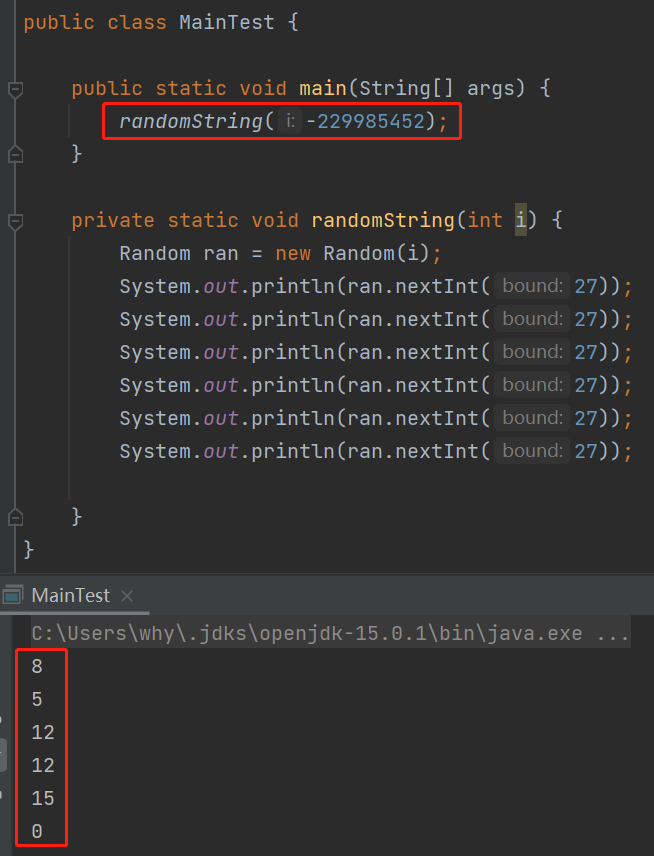
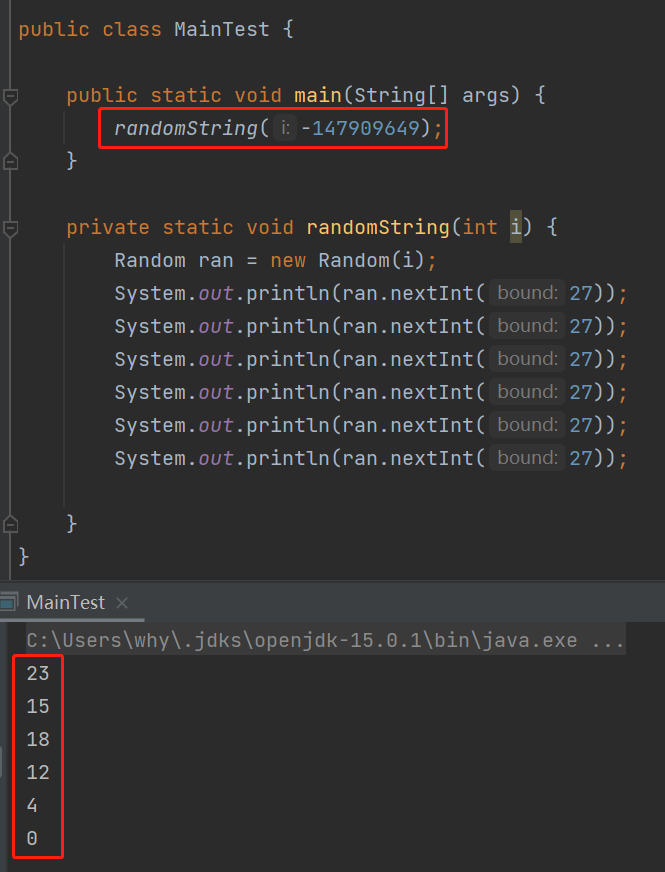
而 new Random(-147909649).nextInt(27) 的前五个返回是这样的:
所以,对照着 ascii 码表看,就能看出其对应的字母了:
8 + 96 = 104 --> h
5 + 96 = 101 --> e
12 + 96 = 108 --> l
12 + 96 = 108 --> l
15 + 96 = 111 --> o
23 + 96 = 119 --> w
15 + 96 = 111 --> o
18 + 96 = 114 --> r
12 + 96 = 108 --> l
4 + 96 = 100 --> d
现在,对于这一段谜一样的代码为什么输出了 “hello world” 的原因,心里是不是拨开云雾见青天,心里跟明镜儿似的。
看穿了,也就是一个小把戏而已。

然后这个问题下面还有个评论,让我看到了另外一种打开方式:
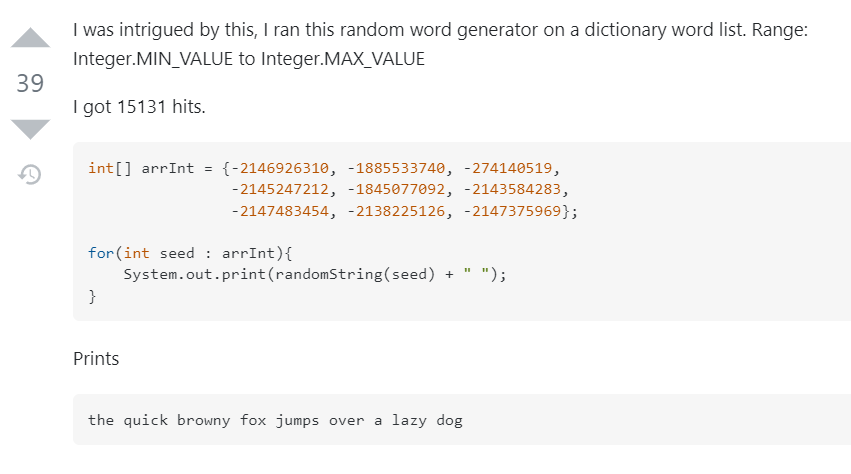
你能指定打印出 hello world,那么理论上我也能指定打出其他的单词。
比如这个老哥就打了一个短语:the quick browny fox jumps over a lazy dog.
如果从字面上直译过来,那么就是“敏捷的棕色狐狸跨过懒狗”,好像也是狗屁不通的样子。
但是,你知道的,我的 English 水平是比较 high 的,一眼就看出这个短语在这里肯定不简单。
于是查了一下:
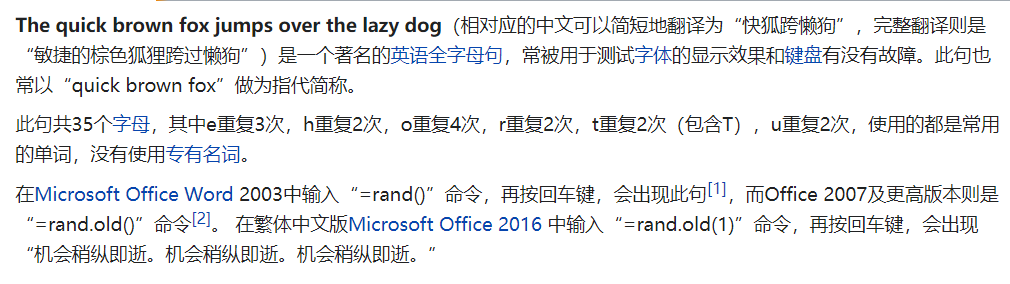
果然是有点故事的,属于 tricks in tricks。

你看学沙雕技术的时候还顺便丰富了自己的英语技能,一举多得,这一会还不得在文末给我点个赞、点个“在看”啥的?
看完这个老哥的 quick brown fox 示例之后,我又有一点新想法了。
既然它能把所有的字母都打出来,那我是不是也能把我想要的特定的短语也打出来呢?
比如 i am fine thank you and you 这样的东西。
而查找指定单词对应的 seed 这样的功能的代码,在这个问题的回答中,已经有“好事之人”帮我们写出来了。
我就直接粘过来,你也可以直接拿去就用:
public static long generateSeed(String goal, long start, long finish) {
char[] input = goal.toCharArray();
char[] pool = new char[input.length];
label:
for (long seed = start; seed < finish; seed++) {
Random random = new Random(seed);
for (int i = 0; i < input.length; i++)
pool[i] = (char) (random.nextInt(27) + '`');
if (random.nextInt(27) == 0) {
for (int i = 0; i < input.length; i++) {
if (input[i] != pool[i])
continue label;
}
return seed;
}
}
throw new NoSuchElementException("Sorry :/");
}
那么我要找前面提到的短语,就很简单了:
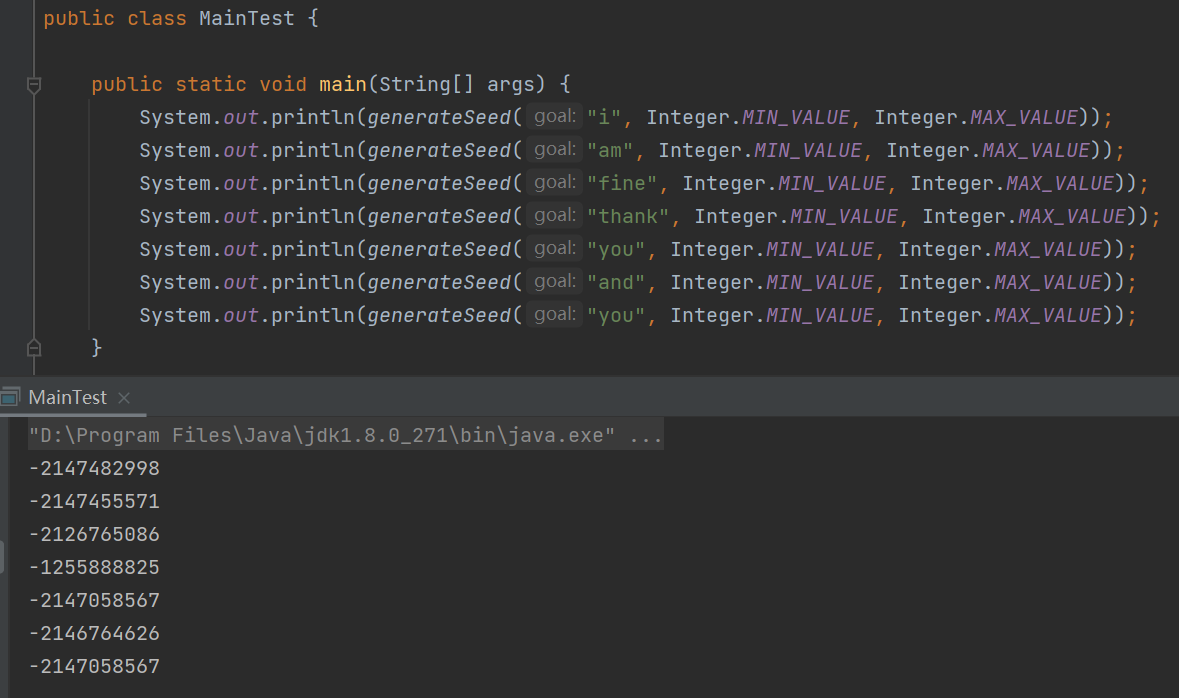
而且运行的时候我明显感觉到,在搜索“thank”这个单词的时候,花了很多时间。
为什么?
我给你讲一个故事啊,只有一句话,你肯定听过:
只要时间足够漫长,猴子都能敲出一部《莎士比亚》。
我们这里 generateSeed 方法,就相当于这个猴子。而 thank 这个单词,就是《莎士比亚》。
在 generateSeed 方法里面,通过 26 个字母不断的排列组合,总是能排列出 “thank” 的,只是时间长短而已。
单词越长,需要的时间就越长。
比如我来个 congratulations,这么长的单词,我从 00:05 分,跑了 23 个小时都还没跑出来:
 但是理论上来讲只要有足够长的时间,这个 seed 一定会被找到。
但是理论上来讲只要有足够长的时间,这个 seed 一定会被找到。
至此,你应该完全明白了为什么前面提到的那段代码,使用随机字符串的方式打印出了 hello world。

源码
你以为我要带你读源码?
不是的,我主要带你吃瓜。
首先,看一下的 Random 无参构造函数:
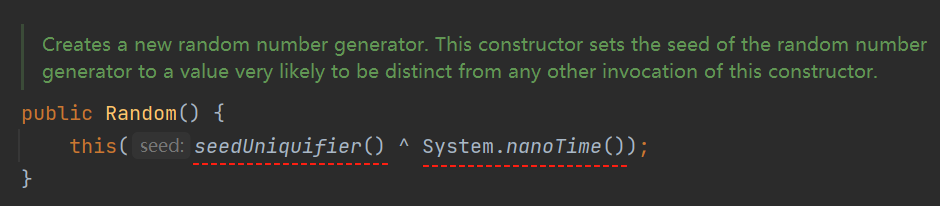
好家伙,原来也是套个了个“无参”的壳而已,实际上还是自己搞了一个 seed,然后调用了有参构造方法。
只是它构建的时候加入了“System.nanoTime()”这个变量,让 seed 看起来随机了一点而已。
等等,前面不是还有一个“seedUniquifier”方法吗?
这个方法是这样的:
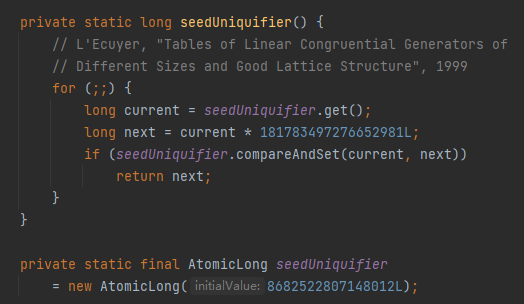
好家伙,看到第一眼的时候我头都大了,这里面有两个“魔法数”啊:
181783497276652981L
8682522807148012L
这玩意也看不懂啊?
遇事不决,stackoverflow。
一搜就能找到这个地方:
https://stackoverflow.com/questions/18092160/whats-with-181783497276652981-and-8682522807148012-in-random-java-7
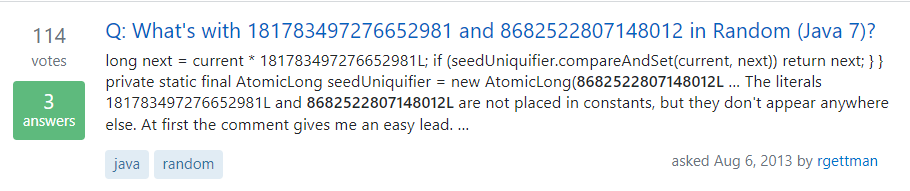
在这个问题里面,他说他对这两个数字也感到很懵逼,网上找了一圈,相关的资料非常的少。但是找到一个论文,里面提到了其中一个很接近的“魔数”:

论文中提到的数是这样的:
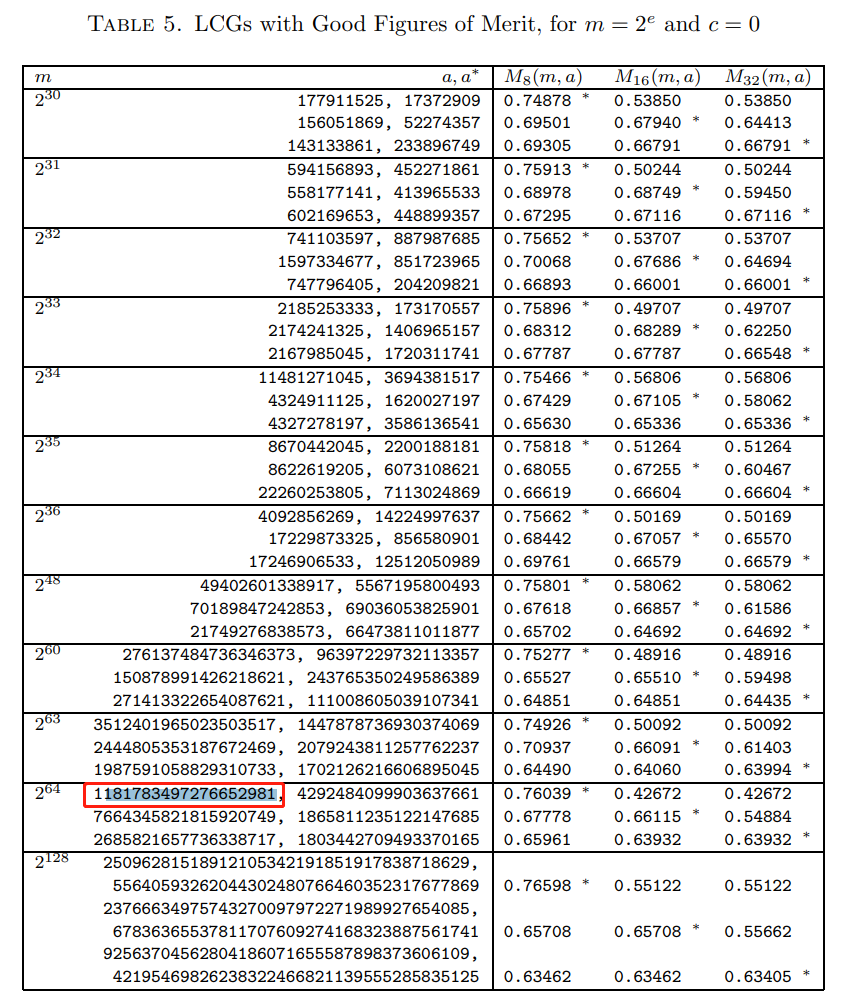
看到没有?
这 Java 源码中的数字前面少了一个“1”呀,咋回事呢,该不会是拷贝的时候弄错了吧?
下面的一个高赞回答是这样的:
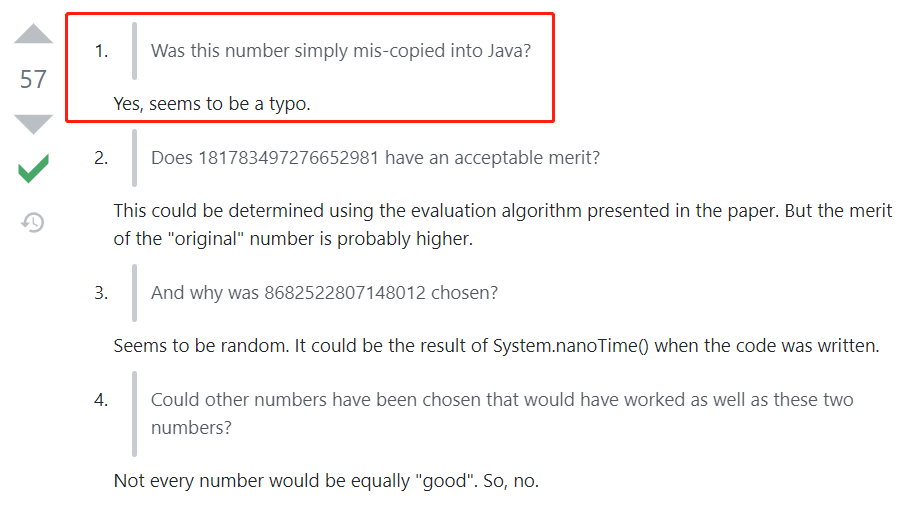
“看起来确实像是拷错了。”
有点意思,你要说这是写 Java 源码的老哥 copy 代码的时候手抖了,我就来劲了。

马上去 Java Bug 的页面上拿着那串数字搜一下,还真有意外收获:
https://bugs.openjdk.java.net/browse/JDK-8201634
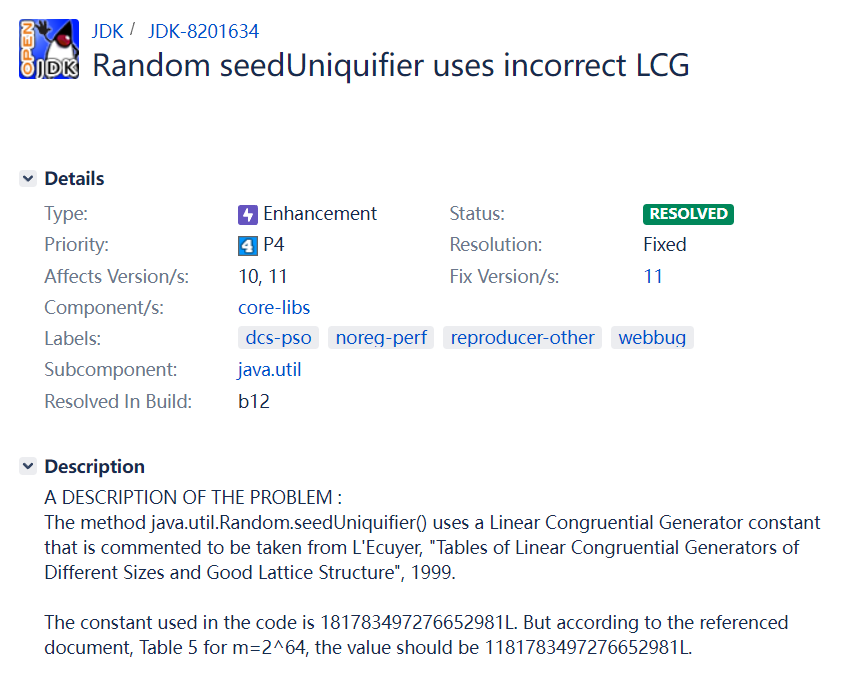
在这个 bug 的描述里面,他让我注意到了源码的这个地方:
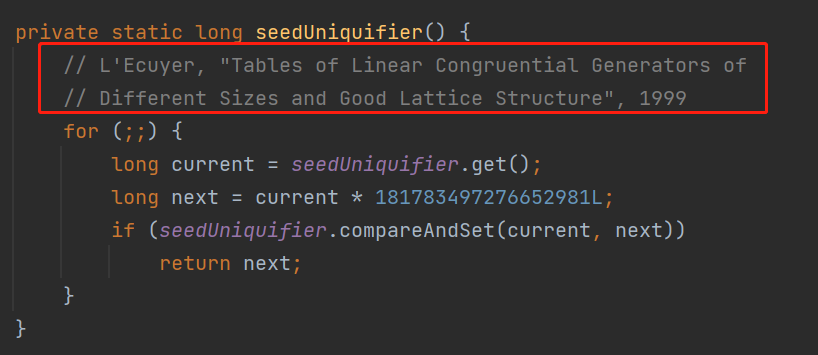
原来这个地方的注释代表着一个论文呀,那么这个论文里面肯定就藏着这个数的来源。
等等,我怎么感觉这个论文的名字有点像眼熟啊?
前面 stackoverflow 中提到的这个链接,点进去就是一个论文地址:

你看看这个论文的名称和 Java 这里的注释是不是说的一回事呀:
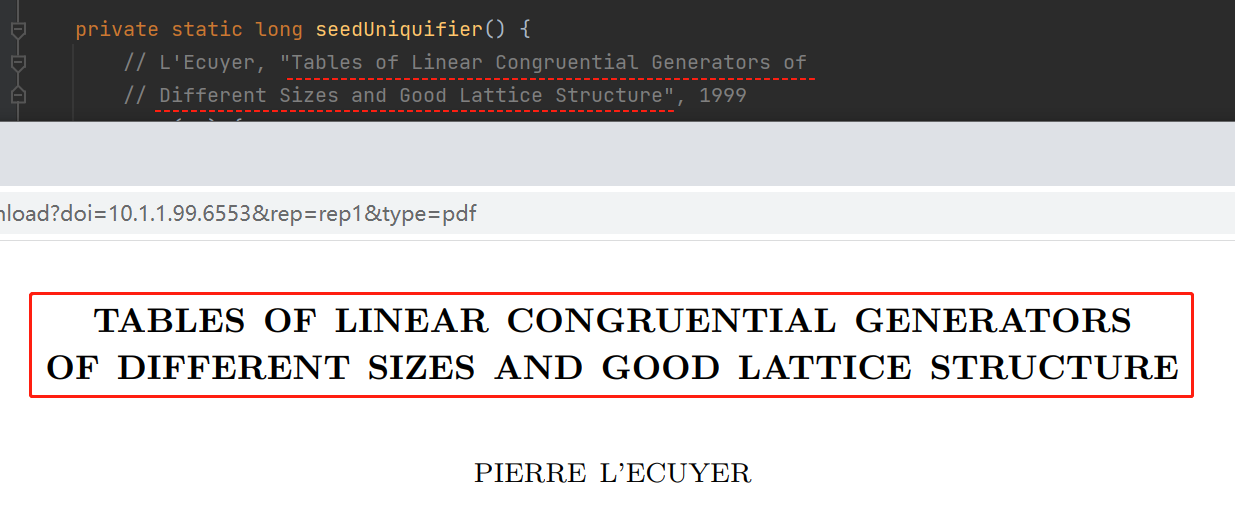
那必须是一回事啊,只是一个小写一个大写而已。
所以,到这里实锤了,确实是最开始写 Java 这块源码的老哥 copy 数字的时候手抖了,少 copy 了一个 “1”。
而且我甚至都能想象到当时写这部分源码的时候,那个老哥把“1181783497276652981”这个数字粘过来,发现:哎,这前面怎么有两个 1 啊,整重复了,删除了吧。
至于把这个“1”删除了之后,会带来什么问题呢?

反正这里关联了一个问题,说的是:并发调用 new Random() 的随机性不够大。
这我就没去研究了,有兴趣可以去看看,我只负责带你吃瓜。
所以,基于这个“瓜”,官方修改了一次这个代码:

刚好我这里有 JDK 15 和 JDK 8 版本的代码,我去看了一下,还真是差了一个 “1” :
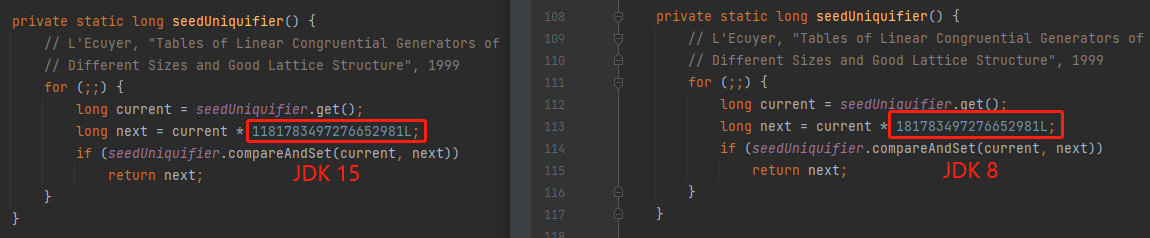
而且关于随机数,现在一般很少用 Random 了吧。
直接就是上 ThreadLocalRandom 了,它不香吗?
什么,你说不会?




