
去哪儿国内酒店稳定性治理实践之缓存治理原创
背景
2019 年 9 月,我们连续遇到几次与缓存相关的故障:
-
DBA 运维失误,导致我们存储在 redis 里的核心基础数据被清空。由于无法正常提供报价,出现 ATP(订单量骤降)故障,之后通过定时任务花费半个小时将数据写回 redis,故障恢复。
-
PC 端爬虫流量进入后端,应用的 redis 连接池被打满,大量同步的 redis 请求都等待 500ms 获取连接,导致应用的 tomcat 线程池被打满,服务被拖死,无法正常提供 PC 端业务,而 redis server 端当时还完全没压力。
类似与缓存相关的故障还有不少,这里就不一一列举了。在对故障进行 review 时,我们意识到有不少核心场景都使用了 redis 缓存作为核心依赖和存储,同时这些场景我们并没有对 redis 可能出现的问题进行预防和处理。
由于我们的核心业务重度依赖 redis,为了不让类似的故障重复上演,也希望在故障前做好准备和预防,我们对缓存进行了专项的治理。
治理方案
高可用治理:这项是最重要的,但是和 redis 本身的高可用部署是无关的,核心出发点是业务的高可用指标不应该完全依赖于使用的组件,组件出故障不代表业务也跟着故障。
首先,建议快速恢复。通常这种方案更适用于有基础数据集的,通过定时任务或者手动触发接口,在短时间内完成对数据的清洗,清洗时考虑优先恢复热点数据。这里的短时间,我们期望是能影响 ATP 的场景在 2min 内完成,对用户体验有影响的允许在 10min 内完成。
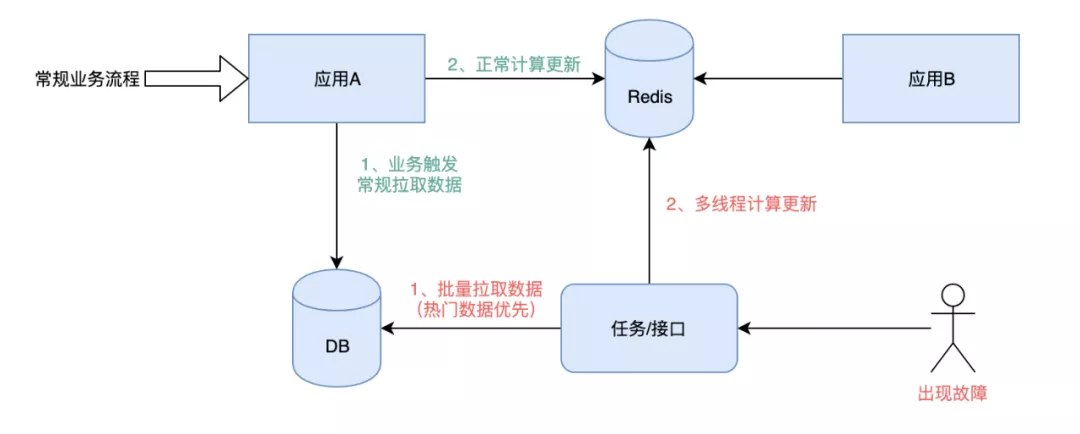
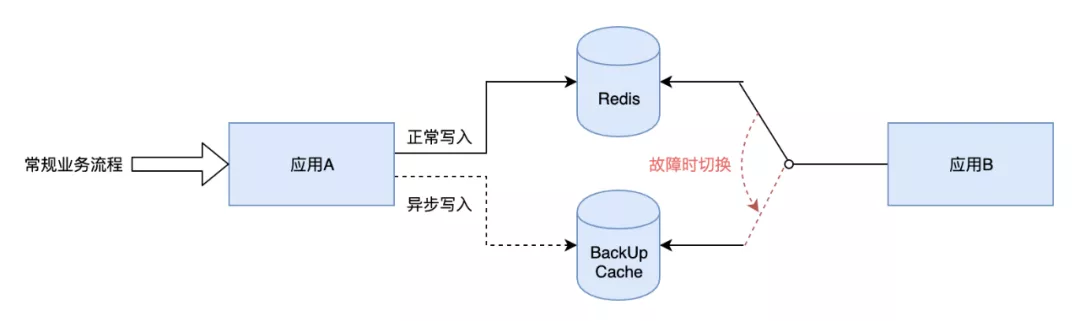
其次,考虑对核心数据做多副本。核心的业务场景可以考虑将数据缓存到 redis 不同 namespace 集群中或多个缓存组件中(redis+tair、redis+memory),这样挂掉一个时可以通过切换到备用的缓存来快速恢复。
之后,考虑手动降级。不走缓存,或替换为其他通道。这里优先考虑无损降级的方式,必要的时候可以考虑有损降级。
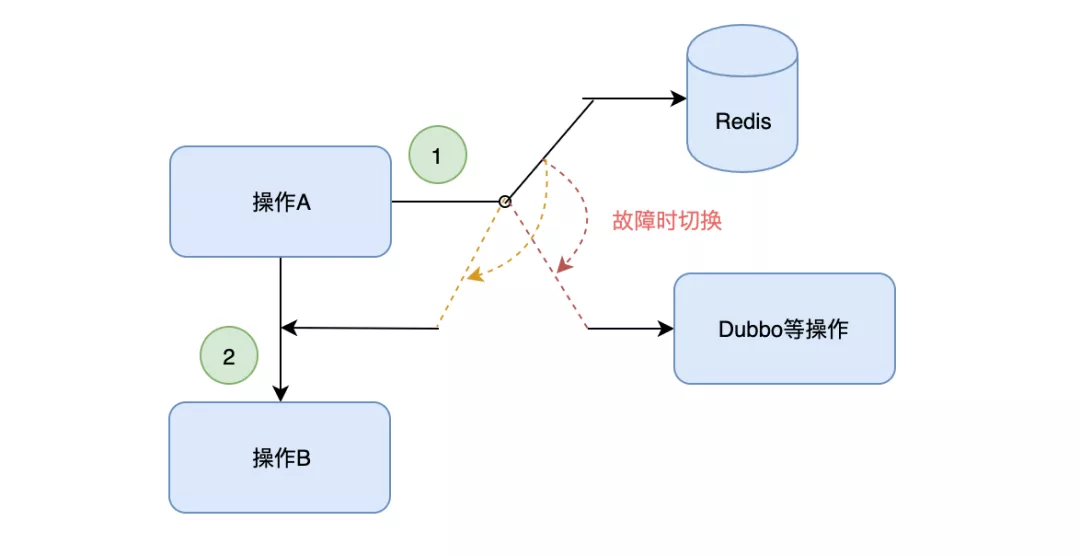
最后,我们还发现系统里存在”A 应用写,B、C 应用读“的情况,这种需要上下游一起沟通最终的方案,并且推荐使用快速恢复,使用方可根据需要做些额外的准备。
参数调优:这里主要指对 redis 使用配置的时间及线程数的优化。
根据监控我们发现:绝大部分场景下,通过 redis 读取和更新缓存的时间都是几毫秒左右(含连接时间)。实际中很多场景 redis 的使用都忽略了这些参数的合理配置,并且发现很多都是复制的某年的某个例子的几百毫秒。
针对这种情况,我们要求对应用里每个 redis 的配置都做好检查及合理化配置。
补充一些治理的细节
-
memcache 替换为 redis:redis 组件相比 memcache 好处就不多说了,主要是将缓存的运维统一都交给公司 DBA。
-
统一配置文件格式:目前很多系统线上有很多配置文件,找起来很麻烦,故障时要能快速找到对应的配置。
-
完善监控:保证每个业务场景对 redis 的调用量级和时间(含异常的量级和时间)都能在监控系统找到。
治理过程
-
梳理核心场景使用的缓存。主要整理涉及缓存的核心场景、故障时影响、数据量级等。
-
确定整体治理方案。先有了大致方案后,然后组内各个系统负责人一起 review 方案细节,将忽略的细节补充到整体方案中。这个和梳理可以并行,在梳理完成后确定最终的治理方案。
-
review 各个场景治理细节。开发、应用负责人、qa 负责人一起 review 每个场景的治理细节,并且明确标准。
-
按照每个场景讨论确定的治理方案进行开发、自测。过程中如果发现方案有问题,可讨论修改,按新方案执行。
-
开发过程中整理故障场景方案及应用维度的应急手册。
-
提测及测试。开发要再次跟 qa 说明治理的场景及方案,qa 根据整理的手册进行验证,同时在 beta 环境演练。
-
上线及制作监控面板。代码上线后,将相关监控按照应用维度制作监控面板,方便日常演练和故障时快速查看。
-
线上演练。在业务低峰时间段,对应急手册里的调整在线上进行验证,对有问题的点进行改进,并找时间继续演练,直至达到预期。
成果与总结
目前,组里大部分的 P1 系统都完成了缓存治理及演练,共花费 60 多个人日,过程中参与的开发人员对 redis 的很多细节做了深入学习,加深了对 redis 的理解。
缓存治理开始时的梳理加深了组内人员对系统的理解,产出的 wiki 对其他同学及新同学很有帮助。
缓存治理产出的监控面板,对日常巡检和故障时快速定位很有帮助。
缓存治理产出的应急手册,在面对实际故障时,能极大的减少故障持续的时间。
值得特别说明的是,近期基础数据组 DB 里酒店图片数据意外被脏写,间接导致我们 redis 里的数据被脏写(这部分数据是用户触发的)。在 DB 里数据恢复正常后,我们借助预留的降级手段,直接调整开关为调用 dubbo 接口获取基础服务 DB 里的图片数据,故障在操作后 1min 内恢复。
本文来自:Qunar技术沙龙 公众号,作者:郑吉敏,去哪儿国内酒店报价中心团队,主要负责报价相关系统开发及架构优化。。



