
一文深度分析Java内存模型原创
0x01 内存模型产生的历史背景
曾经,计算机的世界远没有现在复杂,那时候的cpu只有单核,我们写的程序也只会在单核上按代码顺序依次执行,根本不用考虑太多。
后来,随着技术的发展,cpu的执行速度和内存的读写速度差异越来越大,人们很快发现,如果还是按照代码顺序依次执行的话,cpu会花费大量时间来等待内存操作的完成,这造成了cpu的巨大浪费。
为了弥补cpu和内存之间的速度差异,计算机世界的工程师们在cpu和内存之间引入了缓存,虽然该方法极大的缓解了这一问题,但追求极致的工程师们觉得这还不够,他们又想到了一个点子,就是通过合理调整内存的读写顺序来进一步缓解这个问题。
比如,在编译时,我们可以把不必要的内存读写去掉,把相关连的内存读写尽量放到一起,充分利用缓存。
比如,在运行时,我们可以对内存提前读,或延迟写,这样使cpu不用总等待内存操作的完成,充分利用cpu资源,避免计算能力的浪费。
这一想法的实施带来了性能的巨大提升,但同时,它也带来了一个问题,就是内存读写的乱序,比如原本代码中是先写后读,但在实际执行时却是先读后写,怎么办呢?
为了避免内存乱序给上层开发带来困扰,这些工程师们又想到了可以通过分析代码中的语义,把有依赖关系,有顺序要求的代码保持原有顺序,把剩余的没有依赖关系的代码再进行性能优化,乱序执行,通过这样的方式,就可以屏蔽底层的乱序行为,使代码的执行看起来还是和其编写顺序一样,完美。
之后,计算机的性能就是在硬件的飞速发展及软件执行方式的深入优化下,野蛮生长了很长一段时间,同样一段代码,即使什么都不改,每隔一段时间还是会有执行速度上的成倍提升,这就是著名的摩尔定律时代。
但万事皆有终结,随着硬件上遇到的物理瓶颈越来越多,软件上对执行方式的优化已接近极限,单纯通过单核来提升性能的方式显示是已经走不通了,此时,计算机世界已经来到了一个十字路口,前方的路如何走,已经成为困扰所有人的一个问题。
既然单核遇到了瓶颈,为什么不发展多核呢?
不知道谁想到了这个点子,一下引爆了整个计算机行业,是啊,单核不行了我们可以发展多核嘛,自此,整个计算机行业都开始向多核转变,也由此进入到了多核的大航海时代。
2005年,时任intel主席的Paul Otellini宣布,将所有的未来产品都转向多核,并预测这将是历史性的拐点。
事实也确实如此,到现在,我们用的所有的cpu基本都是多核。
多核时代的到来虽然重启了计算机世界新一轮的发展,但也带来了一个非常严峻的问题,那就是多核时代如何承接单核时代的历史馈赠。
上面我们提到,在单核时代,为了追求代码的极致性能,我们在编译时和运行时都对内存操作做了各种乱序处理,虽然已经通过一定的方式,让这种乱序不影响到上层开发,对上层逻辑透明,但这种方式只对单核有效,进入到多核时代,单核运行不可见的乱序,在多核情况下都可见了,且此种乱序已经严重影响到了多核代码的正确编写。
怎么办呢?移除乱序优化,让代码还是按照原来的顺序方式执行?
那这样会造成巨大的性能损失,此种情况下由单核进化到多核的意义也就不大了,那怎么办呢?
谁说代码就一定要顺序执行的?谁说乱序就一定不能对上层可见的?我们可以好好看下我们写的代码,其实很多时候,我们并不介意乱序执行,我们介意的只是某些关键位置上代码的乱序执行。
比如,一个线程先对n个普通变量进行写操作,再对一个特殊的,用于标志写完成的变量进行写操作,此种情况下,我们并不关心前n次写操作是否乱序,我们只要能确保前n次写和最后一次写之间是有序的就可以了,这样,当其他线程要读那前n次写时,只要先读最后那次写,检查其值是否表示前n次已经写完成,如果是,我们就可以放心的读那前n次写了。
默认乱序执行,在关键节点保证有序,这种方式不仅使单核时代的各种乱序优化依然有效,也使多核情况下的乱序行为有了一定的规范。
基于此,各种硬件平台提供了自己的方式给上层开发,约定好只要按我给出的方式编写代码,即使是在多核情况下,该保证有序的地方也一定会保证有序。
这套在多核情况下,依然可以让开发者指定哪些代码保证有序执行的规则,就叫做内存模型。
0x02 内存模型的定义
内存模型的英文是memory model,或者更精确的来说是memory consistency model,它其实就是一套方法或规则,用于描述如何在多核乱序的情况下,通过一定的方式,来保证指定代码的有序执行。
它是介于硬件和软件之间,以一种协议的形式存在的。
对硬件来说,它描述的是硬件对外的行为规范,对软件来说,它描述的是编写多线程代码的一套规则。
总之,内存模型就相当于是在多核时代下,硬件的使用说明书,只要按照说明书来编写多线程程序,那不管底层如何乱序,如何优化,都不会影响你代码的正确性。
0x03 Java的雄心壮志
上文我们提到,内存模型描述的是在多核情况下,硬件的一套行为规范,也就是说,只要硬件支持多核,就必须提供一套自己的内存模型。
这就衍生出了一个问题,就是不同硬件上的内存模型差异很大,完全不兼容。
比如应用于桌面和服务器领域的x86平台用的是x86 tso内存模型。
比如应用于手机和平板等移动设备领域的arm平台用的是weakly-ordered内存模型。
比如最近几年大火的riscv平台用的是risc-v weak memory ordering内存模型。
不同硬件平台的内存模型,描述的指令乱序情况,及禁止乱序的方式都完全不一样,它们只适用于自己平台的指令集,或者说只适用于自己平台的汇编语言。
不过由于汇编语言本身就不具有跨平台性,所以这样做也无可厚非,甚至某种程度上来说,只能这样做,基于这样的事实,大家在各自的硬件平台,按照对应的内存模型规范,编写着自己的汇编代码,相安无事又其乐融融的享受着多核带来的红利。
如果只是写汇编代码的话,因为大家对其没有什么跨平台的预期,所以也沒啥太大的意见,但对于追求跨平台的c/c++等高级语言来说,这个就有点不一样了,由于其语言层面并没有对多线程进行内置支持,所以当用其写的多线程代码时,可能在一个平台上是正确的,但到了另一个平台就错误的。
这种局面终于在Java身上得到了改善。
1991年,James Gosling在Sun Microsystems发起了Java语言项目。
1996年,Sun Microsystems对外发布了Java 1.0版本。
由于Java的目标是write once, run anywhere,所以它不仅创造性的提出了字节码中间层,让字节码运行在虚拟机上,而不是直接运行在物理硬件上,它还在语言层面内置了对多线程的跨平台支持,也为此提出了Java语言的内存模型,这样,当我们用Java写多线程项目时,只要按照Java的内存模型规范来编写代码,Java虚拟机就能保证我们的代码在所有平台上都是正确执行的。
在语言层面支持多线程在现在看来不算什么,但在那个年代,这也算是一项大胆的创举了,它也成为了首个主流编程语言中,内置支持多线程编码的语言。
但事与愿违,Java的先行者们大大低估了这项工作的复杂程度,以至于第一版的Java内存模型有很多严重的问题,严重到一般人很难使用Java来编写正确的多线程代码。
经过了很长一段时间的诟病,Java的设计者们终于决定重新修订Java的内存模型,这就是著名的JSR 133计划,该计划在2001年发起,经过了长达3年的激烈讨论,终于在2004年完成,并与Java 5.0一起对外发布。
至此,Java终于在语言层面正确的对线程跨平台进行了内置支持,并且也对各种硬件平台的内存模型进行了合理的抽象,形成一套自己的内存模型。
0x04 Java内存模型的影响
在Java从语言层面提炼出跨平台的内存模型获得巨大成功之后,c和c++纷纷开始效仿借鉴,在Java内存模型的基础上,总结并改进出了适合自己语言的内存模型,并在c11和c++11标准中对外发布。
自此之后的很多新兴的编程语言,都会内置对多线程的支持,且都会有自己的一套内存模型。
0x05 Java内存模型规范
完整的Java内存模型是很复杂的,要不然JSR 133也不会花费三年时间才定下来,但如果我们只是想写正确的多线程程序,它又非常简单。
它的核心要义其实就一句话:
If a program is correctly synchronized, then all executions of the program will appear to be sequentially consistent.
为了追求语义上的精确,上面的话我直接引自Java Language Specification(JLS)。
它的大意就是说,如果我们的程序是正确同步的,则该程序在执行时,不管底层如何乱序,它都会表现的像按代码编写顺序那样依次执行。
这里我们要注意三点,一是correctly synchronized,二是appear to be,三是sequentially consistent。
首先,sequentially consistent指的是顺序执行,它给我们两个保证,一是有序性,即代码的执行顺序就像代码本身写的一样,没有乱序发生,如果是多线程在执行多段代码,那总的执行顺序就是多段代码之间的穿插执行。
二是可见性,即一行代码执行完毕后,比如写内存,下一行代码对上一行代码的执行结果立即可见,比如读到上一行代码写的值。
其实sequentially consistent本质上就是我们正常人理解的代码执行顺序,顺序执行、没有乱序、读写立即可见、多线程代码段穿插执行。
上面那句话要注意的第二点是appear to be,即它只是让我们看起来像在以sequentially consistent的方式在执行,但真实的执行顺序很有可能还是在乱序,只是我们感知不到而已。
这个非常类似于单核时代的代码执行,它也是让我们感觉代码是在以sequentially consistent的方式在执行,但底层其实是各种乱序的。
上面那句话中,最后一点我们需要注意的就是correctly synchronized,即正确同步的,那什么叫正确同步的呢,这个在JLS里也给了官方定义:
A program is correctly synchronized if and only if all sequentially consistent executions are free of data races.
它的大意是说,如果一个程序用各种假定的顺序执行方式来执行其代码时,都没有发现数据竞争,那它就是correctly synchronized。
这里需要注意的是所有的sequentially consistent的执行,因为程序中一般都存在大量的逻辑分支,一次执行只会走分支的一个方向,假定我们把程序中的所有分支的所有方向都按代码顺序方式模拟执行了一遍,还是没有发现数据竞争,那这个程序就是correctly synchronized的。
为了方便记忆,我们把上面两句话合并并精简一下,大意为,如果我们的程序没有data race,那它在被执行时,其执行顺序我们就可以认为是代码的编写顺序。
那何为data race呢,继续看官方定义:
When a program contains two conflicting accesses that are not ordered by a happens-before relationship, it is said to contain a data race.
根据该定义我们可知,如果两个accesses是conflicting的,且没有被happens-before规则约束,则称之为data race。
继续来看下什么是conflicting accesses:
Two accesses to (reads of or writes to) the same variable are said to be conflicting if at least one of the accesses is a write.
其大意是说,对同一变量的两个访问操作,如果有一个是写操纵,则这两个访问操作被成为conflicting的。
到这里,Java内存模型的核心要义就快浮出水面了,我们把上面四句官方定义再合并精简下,它说的其实就是:
如果程序中存在对同一变量的多个访问操作,且至少有一个是写操作,则这些访问操作被称为是conflicting操作,如果这些conflicting操作没有被happens-before规则约束,则这些操作被称为data race,有data race的程序就不是correctly synchronized,运行时也就无法保证sequentially consistent特性,没有data race的程序就是correctly synchronized,运行时可保证sequentially consistent特性。
那也就是说,我们现在只要知道什么是happens-before规则,然后用这个规则约束程序中的所有conflicting操作,那我们最终的程序就是correctly synchronized,它在运行时让我们感知到的顺序就是代码的编写顺序。
下面我们来看下什么是happens-before规则,为了精确定义,我们还是直接引用官方文档:
Two actions can be ordered by a happens-before relationship. If one action happens-before another, then the first is visible to and ordered before the second.
If we have two actions x and y, we write hb(x, y) to indicate that x happens-before y.
If x and y are actions of the same thread and x comes before y in program order, then hb(x, y).
If an action x synchronizes-with a following action y, then we also have hb(x, y).
If hb(x, y) and hb(y, z), then hb(x, z).
第一句话是说,如果两个行为之间有happens-before顺序,则第一个行为一定发生在第二个行为之前,且第一个行为的结果对第二个行为可见。
理解这句话非常重要,它告诉我们,有happens-before关系的两个行为之间,是能保证有序性和可见性的,或者说我们也可以理解为,它们之间不会发生乱序。
第二句话是说用hb(x, y)形式表示x发生在y之前。
第三句话是说,同一线程中,如果x的出现顺序是在y之前,则x发生在y之前。
第四句话是说,如果x synchronizes-with y,则我们说x发生在y之前。
第五句话是说,happens-before规则有传递性,这点非常重要,它也是经常被忽视的一点。
从上面的这段话我们可以知道,happens-before规则由两部分组成,一部分是program order,即单线程中代码的编写顺序,另一部分是synchronizes-with,即多线程中的各种同步原语。
也就是说,在单线程中,代码编写的前后顺序之间有happens-before关系,在多线程中,有synchronizes-with关联的代码之间也有happens-before关系。
program order非常好理解,这里我们就不再说了,下面我们来重点看下synchronizes-with,还是直接引自JLS:
An unlock action on monitor m synchronizes-with all subsequent lock actions on m (where "subsequent" is defined according to the synchronization order).
A write to a volatile variable v synchronizes-with all subsequent reads of v by any thread (where "subsequent" is defined according to the synchronization order).
An action that starts a thread synchronizes-with the first action in the thread it starts.
The write of the default value (zero, false, or null) to each variable synchronizes-with the first action in every thread.
The final action in a thread T1 synchronizes-with any action in another thread T2 that detects that T1 has terminated.
T2 may accomplish this by calling T1.isAlive() or T1.join().
If thread T1 interrupts thread T2, the interrupt by T1 synchronizes-with any point where any other thread (including T2) determines that T2 has been interrupted (by having an InterruptedException thrown or by invoking Thread.interrupted or Thread.isInterrupted).
因为synchronizes-with规则比较多,我们就不逐行翻译了,它们讲的都是Java中的同步原语的一些使用,比如我们常用的synchronized关键字,volatile关键字等。
知道这些关系后,我们再来总结下,happens-before规则包括两种,一种是program order,是定义单线程内各种操作的顺序,另一种是synchronizes-with,是定义多线程之间操作的顺序。
到现在为止,我们就清晰的知道如何写一个correctly synchronized的程序了,找到所有的conflicting操作,然后用上述happens-before规则进行约束,那该程序就是correctly synchronized的了。
correctly synchronized的程序虽然不能保证我们代码逻辑上的正确性,但因为其提供的sequentially consistent特性,我们至少可以很容易的,且有根据的分析我们的代码是否正确了。
如果不是correctly synchronized的程序,也就没有sequentially consistent特性,那在运行时,很多地方的代码都可能是乱序的,我们也就无从分析代码的正确性了。
好,如果你只是想写正确的多线程程序,Java内存模型理解到这个程度已经算是可以了,但如果你想了解更多细节,可以继续往下看。
在JLS规范的第17章 Threads and Locks 里完整定义了Java内存模型的各种规则,上面引用的各种官方定义也都是从这里来的。
该章中最难理解的,或者说根本无法理解的其实是其causality语义,那什么是causality呢?
上文中我们讲的都是如何正确的写一个correctly synchronized的程序,以便我们能在程序执行时得到sequentially consistent保证。
那如果我们写的程序不是correctly synchronzed,或者说代码里有各种data race,会发生什么呢,结果会是什么样子呢?
如果读过类似于c/c++标准规范文档的同学一定知道,如果是在那里定义非correctly synchronized的执行结果,那一定是undefined,即未定义,任何情况都可能发生。
也就是说,类似于c/c++规范里,它们只定义正确行为,如果你不按照正确行为写,那后果自负。
但是Java既然是以安全著称的语言,它是没法容忍所有后果都自负的,即使我们写的程序不是correctly synchronzed的。
所以causality定义的是,即使我们写的程序不是correctly synchronzed的,那有些极端的结果也是不能发生的,这样保证了即使出现了坏的结果,也不至于坏到我们接受不了的程度。
限于篇幅及复杂度的原因,causality相关的东西我们就不展开讲了,如果真对这些感兴趣,可以看本文结尾的参考资料,或私聊我单独讨论。
Java内存模型中还有一部分是讲final关键字的,因为这个是独立的,且在JLS中讲的比较清楚,这里就不再展开讲了,还是像上面说的,有问题可以私聊我,我们一起讨论。
0x06 实战看看

假设方法f1, f2分别被两个线程执行,且f1的线程先获得锁,则f2中r1, r2读到的值分别是什么?
我们上面讲happens-before中的synchronizes-with规则时提到过,unlock操作发生在同一个monitor上后续的lock操作之前,对比上面的代码我们可知,操作4发生在操作5之前。
又根据happens-before中的program order规则我们可知,操作3发生在操作4之前,操作5发生在操作6之前。
上面我们还提到过,happens-before规则不仅保证有序性,还保证可见性,即happens-before之前的操作对happens-before之后的操作可见。
综上可知r1的值一定是1。
r1的值为1这个结果,即使不用happens-before规则论证,对于绝大部分学过java的人来说也是很好理解的,那r2的值是多少呢?
对,也一定是1。
同样根据happens-before中的program order规则可知,方法f1中的happens-before顺序是 1 -> 2 -> 3 -> 4,方法f2中的happens-before顺序是 5 -> 6 -> 7 -> 8。
又根据happens-before中的synchronizes-with规则可知,操作4发生在操作5之前。
我们上面还提到过,happens-before规则是有传递性的,所以方法f1和f2整个happens-before顺序为 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8,又因为happens-before规则保证可见性,所以操作1中写入的值,在操作8中一定可见,所以r2的值一定是1。
这里我重点想要强调的是,操作1对操作8可见,这个也是很多人会忽视的。
我们在学synchronized关键字时,讲的最多的就是它的原子性,我获得了锁别人就没法获得,所以在获得锁期间的操作都是单线程的,都是原子的,但是却很少有人会去讲它的有序性和可见性。
synchronized关键字的解锁操作,是发生在后续的加锁操作之前的,它们之间是有happens-before关系的,所以synchronized解锁之前的操作,对synchronized加锁之后的操作是有序并可见的。
这里的操作不仅包括synchronized里的操作,还包括对应的synchronized之前或之后的操作。
由这个例子我们也可以看到,在单线程中通过program order定义happens-before关系,在跨线程中通过synchronizes-with定义happens-before关系,两个结合,就建立起了一条完整的,跨线程的happens-before关系,从而也就能确立了跨线程之间操作的的有序性及可见性。
好,我们还是用上面的代码,假设方法f2的线程先获得锁,方法f1的线程后获得锁,那r1和r2的值分别是什么?
同样根据我们上面讨论过的happens-before规则可知,操作7是发生在操作2之前的,操作1和操作8之间没有任何happens-before关系,所以,r1的值一定是0,而r2的值无法确定。
其实这个程序就是典型的没有correctly synchronized的程序,因为操作1和操作8这两个conflicting操作,并没有被happens-before规则约束,所以该程序出现了data race,所以该程序不是correctly synchronized,这是我们平时要避免的情况。
我们再看一个例子:

假设方法f1,f2分别被两个线程独立执行,那r1,r2的值分别是多少?
先说答案,r1的值一定是1,r2的值无法确定。
为什么呢?
首先,根据happens-before中的program order规则,操作1,2,3之间是顺序执行,操作4,5,6之间也是顺序执行,又根据happens-before中synchronizes-with规则的,volatile的写操作发生在后续的volatile读操作之前,所以可知,3和4之间也有happens-before关系。
那按这样来看的话,r1,r2的值都应该是1啊,因为3,4之间建立了跨线程的执行顺序,而各自线程中又按照代码的顺序执行,为什么r1就一定是1,r2就无法确定呢?
这又是一个典型的对volatile理解深度的问题。
对volatile的理解深度可分为三层:
第一层是绝大部分资料都会告诉你的,volatile能保证跨线程间的可见性,这是最基础的理解。
第二层的理解就比较少的资料会提到,就是有序性,可能有些资料只是提到了有序性,但又没有说明谁和谁有序。
volatile保证的有序性其实是在跨线程之间建立了一条happens-before规则,即volatile的写操作发生在后续的volatile读操作之前,它只建立了这一条有序关系,而volatile之前或之后的有序关系,比如上面例子中的操作1,2和操作5,6是通过program order建立的。
所以说volatile保证的有序是帮助串联起跨线程之间操作的有序。
这就是第二层的理解,能说到这层且能说明白的资料其实已经比较少了,至于能说到第三层的就更少了。
在说第三层的理解之前,我们再来看下volatile建立的happens-before规则是,volatile的写操作是发生在后续的读操作之前。
理解第三层的关键,是你如何理解 后续的 这三个字。
何为后续?在代码中我们只有读到了volatile的写操作的那个值,我们才能确定这些读操作是写操作的后续操作,比如上面代码的操作4中,只有我们读到了true,我们才能确定这次读是上面volatile写的后续操作,这样我们才能确立volatile给我们保证的happens-before顺序。
这也是为什么r1一定能读到1,而r2值无法确定的原因,因为操作6虽然发生在操作4之后,但如果操作4没有读到true,则操作3和操作4之间的happens-before关系还是没法建立的,也就是说,操作2和操作6之间的happens-before关系无法确立。
理解到这一层,才算是真正理解volatile。
再来看一个例子:

这次还是假设方法f1,f2分别被两个线程执行,且f1先执行,f2后执行,那f2返回的值一定是1吗?
不一定,因为要想保证可见性,必须要确立happens-before关系,而跨线程的happens-before关系的确立只有上面我们提到的那几种,比如解锁和后续的加锁操作,比如volatile写和后续的volatile读操作,比如有关线程启动或终止的一些操作等。
但我们看上面的方法,虽然f1有synchronized的解锁操作,但f2并没有对应的加锁操作,所以f1和f2的线程之间没有任何happens-before规则,也就无法保证它们之间读写的可见性。
再来看一个例子:

这次还是假设f1,f2被两个不同线程执行,且f1先执行,f2后执行,那f2返回值一定是1吗?
不一定,因为虽然它们都有加解锁操作,但它们是对不同的锁,只有是对同样的锁的加解锁之间才有happens-before关系,才能保证可见性。
虽然我还想写更多的例子让大家来了解java的内存模型,但限于篇幅原因,就写的到这里吧,其实万变不离其宗,只要掌握了java内存模型的核心要义,那所有的例子你都能正确的解答出来。
我们再来重新梳理下java内存模型的核心要义:
要想写正确的多线程代码,我们必须要保证我们的代码是correctly synchronized,也就是说,是没有data race的。
而data race的产生,是因为我们没有用happens-before规则限制代码中的conflicting操作,即那些对同一变量存在多个访问,且其中至少有一个操作是写操作的那些操作。
也就是说,如果我们对所有conflicting操作都用happens-before规则限制,那我们的程序就是correctly synchronized的了,也就能保证运行时的sequentially consistent特性。
happens-before规则由两部分组成,一部分是program order规则,即单线程中代码的字面顺序,另一部分是synchronizes-with规则,即各种同步操作,比如synchronized关键字,volatile关键字,线程的启动关闭操作等。
想写正确的多线程代码,你只需要记住这些就好了。
当然,内存模型中还有对final关键字正确使用的说明,这个因为是独立出来的一部分,且比较好理解,这里就不再讲了。
好,实战部分的内容就这些。
0x07 Java内存模型的底层实现
原本这篇文章我还想详细说下Java内存模型在各硬件平台上是怎么实现的,但没想到写到这里都已经这么多字了,所以,有关实现的部分,我们还是改天令起一篇文章再写。
如果对实现部分感兴趣的同学可以关注我的公众号:卯时卯刻,后者搜ytcode,有关实现部分的文章会首发在我的公众号里。
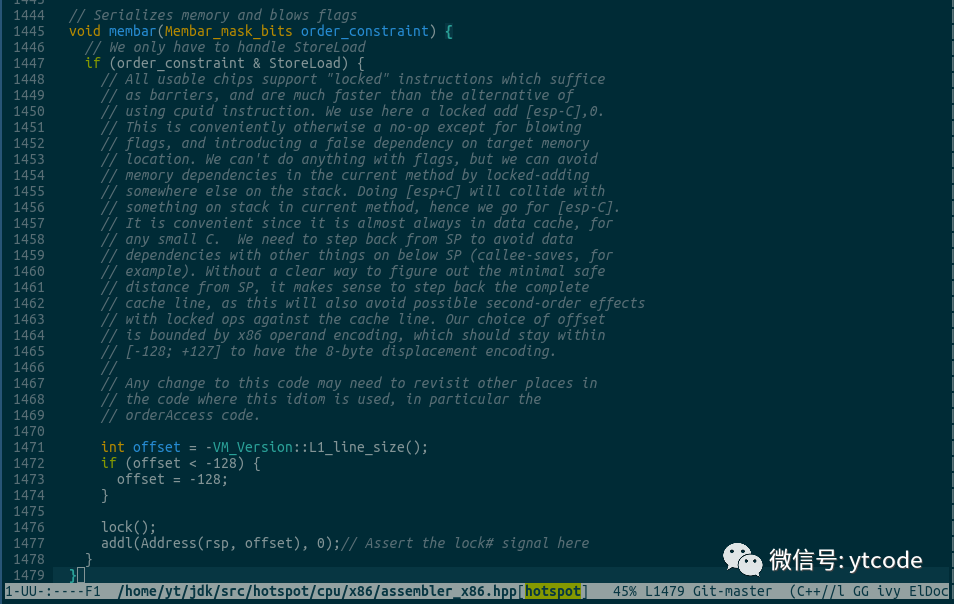
但为了满足一下大家的好奇心,我简单提一下,在x86平台上,volatile的读操作没有任何消耗,volatile的写操作使用的是 lock 汇编指令,相关代码为:
0x08 文章总结
文章开始我们说到,内存模型的出现,是因为单核到多核,或者说是,单线程到多线程时代过渡时,我们需要一种方式,来解决多线程内存读写乱序的问题,而内存模型正是一套这样的规则,它定义了用什么样的方式,可以保证多线程间相关代码不会有乱序发生,即保证了相关代码的有序性和可见性。
而又由于硬件平台有非常多的种类,比如x86, arm, riscv等,每种平台都有自己的一套内存模型,这对于我们编写跨平台的代码来说,非常麻烦。
为了实现write once, run anywhere的宏图大志,Java作为当时的主流编程语言,第一个尝试去从语言层面,抽象出对各物理平台都适用的一套内存模型。
虽然过程非常坎坷,第一次的尝试失败了,第二次的尝试花了三年时间才最终定稿,但Java最终还是实现了自己的目标,首次实现了语言层面上的内存模型。
这对后续的编程语言产生了深远的影响,现在看看那些新兴的编程语言,每种都内置对多线程的跨平台支持,每种都有自己的内存模型规范。
壮哉 Java!
0x09 参考资料
[1] Java Language Specification 第17章 Threads and Locks
https://docs.oracle.com/javase/specs/index.html
[2] JSR 133
http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf
[3] http://rsim.cs.uiuc.edu/Pubs/popl05.pdf
[4] https://gpetri.github.io/publis/jmm-vamp07.pdf
[5] http://groups.inf.ed.ac.uk/request/jmmexamples.pdf
本文作者:wangyuntao
希望本文对你有所帮助,可以的话也帮忙点个赞。
另外也欢迎关注我公众号:卯时卯刻(ID:ytcode),主要是结合实际,讲一些linux内核相关的知识。



