
30万行的框架代码,这样给Dubbo加扩展原创
本文首发于公众号【看点代码再上班】,建议关注公众号,及时阅读最新文章。
大家好,我是tin,这是我的第18篇原创文章

Dubbo已是一个很大的项目,2.7.15版本中光Java代码已累积到了30万行。
Dubbo在国内微服务界的名气不用我说大家应该都知道,它有很多的突出的设计点,其中,扩展机制就是一个。
今天结合实例讲一讲如何给Dubbo加扩展,先上一个目录:
一、Dubbo的扩展机制
1. 开闭原则
我们应该都听说过一个非常重要的设计原则——开闭原则。在大项目编程设计中,这个原则显得尤其重要。从定义来理解,开闭原则表示:
Software entities like classes,modules and functions should be open for extension but closed for modifications.(一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。)
用大白话来说就是,你可以往一个系统里面加代码功能,但是不修改系统原代码逻辑。

在基本的六大原则中,开闭是最基础的原则同时也是其他几大原则的指导基石。如果用Java语言来描述,开闭原则是抽象类,其他几大原则是具体的实现类。
开闭原则在面向对象设计领域中的地位就类似于牛顿第一定律在力学、勾股定律在几何学、质能方程在狭义相对论中的地位,其地位无人能及。
2. Dubbo扩展
Dubbo的扩展机制正是应用了这种设计原则思想,它设计定义了很多的接口(也叫扩展点),以及定义了一整套加载机制(SPI机制)和接口契约。
当需要对扩展点进行扩展的时候,只需新增扩展点的实现类以及配置指定配置文件即可。
在Dubbo官网上可以看到已定义的SPI扩展有非常多:

由此也可见扩展对Dubbo的重要性。Dubbo采用的这种扩展结构对于Dubbo来说有两大好处:
-
作为框架的维护者,在添加一个新功能时,只需要添加一些新代码,而不用大量的修改现有的代码,即符合开闭原则。
-
作为框架的使用者,在添加一个新功能时,不需要去修改框架的源码,在自己的工程中添加代码即可。
二、从扩展点到@SPI注解
1. 扩展点
要深入理解Dubbo的扩展机制,需要先理解两个概念:
-
扩展点,也是一个Java接口,可以通过 SPI 机制查找并加载扩展实现的接口(又称“扩展接口”)。比如上图《SPI扩展实现》中的协议扩展接口org.apache.dubbo.rpc.Protocol,它就是一个扩展点。
-
扩展,扩展点的实现类。比如InjvmProtocol实现了Protocol,它就是一个扩展。
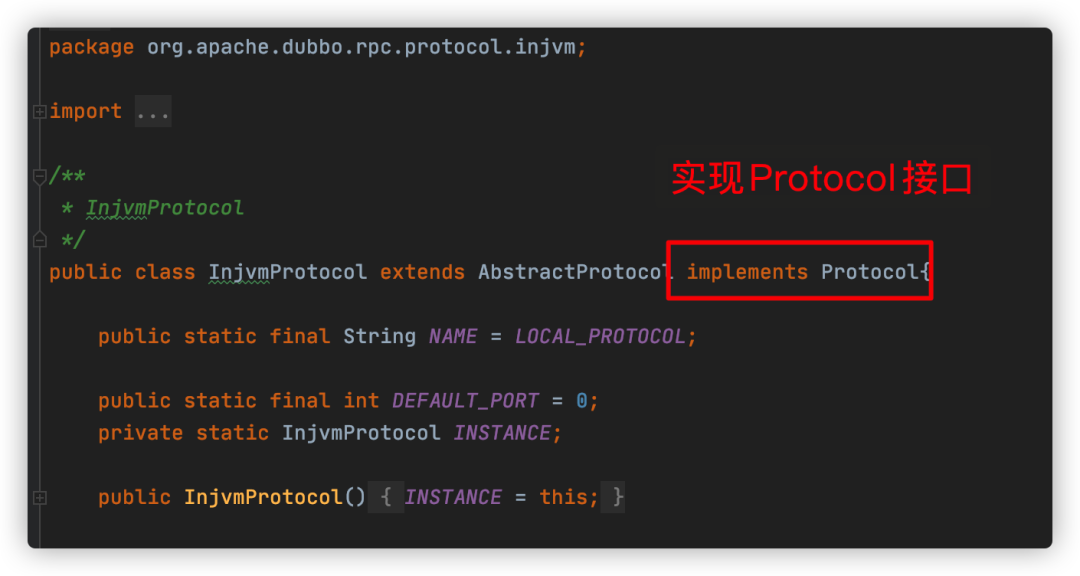
和Java SPI类似,Dubbo扩展也需要在指定的META-INF目录下配置config文件,当服务启动的时候,Dubbo则从相应路径目录加载并实例化扩展。
Dubbo 按照 SPI 配置文件的用途,将其分成了三类目录:
-
META-INF/services/ 目录:兼容 JDK SPI。
-
META-INF/dubbo/ 目录:存放用户自定义的 SPI 配置文件。
-
META-INF/dubbo/internal/ 目录:存放 Dubbo 框架内部使用的 SPI 配置文件。
就拿协议扩展点来说:org.apache.dubbo.rpc.Protocol
它的扩展实现InjvmProtocol是在dubbo-rpc-injvm包内实现的,在该包的META-INF/dubbo/internal/ 目录下有对应的扩展配置。
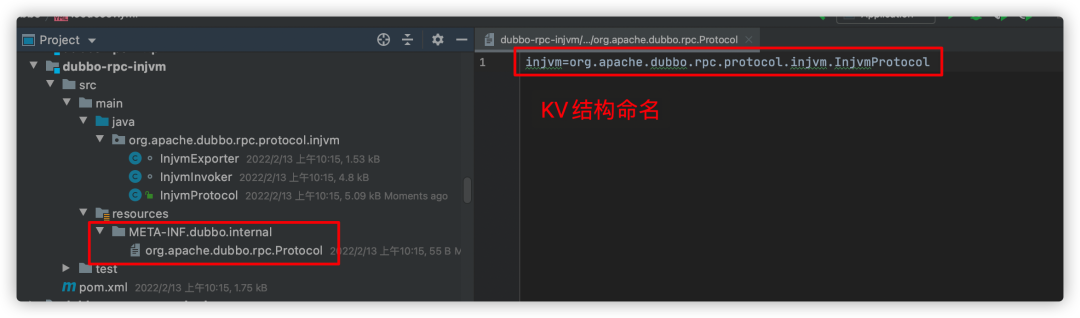
配置命名形如 KV 的格式:
injvm=org.apache.dubbo.rpc.protocol.dubbo.InjvmProtocol
其中 key 被称为扩展名(也就是 ExtensionName),当我们在为一个接口查找具体实现类时,可以指定扩展名来选择相应的扩展实现。
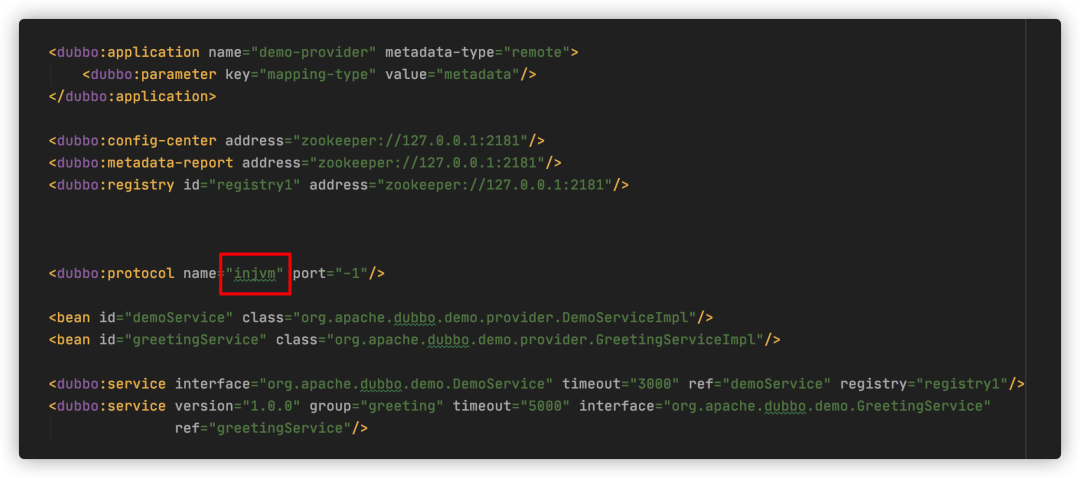
就例如,这里扩展名为 injvm,我们在xml文件配置服务Provider的时候,就可以指定protocol name为injvm,表示服务接口将使用injvm协议。
2. @SPI注解
@SPI注解作用于扩展点上,表明该接口是一个扩展点,可以被Dubbo的ExtensionLoader加载。前文中的 org.apache.dubbo.rpc.Protocol 接口就是一个扩展点:
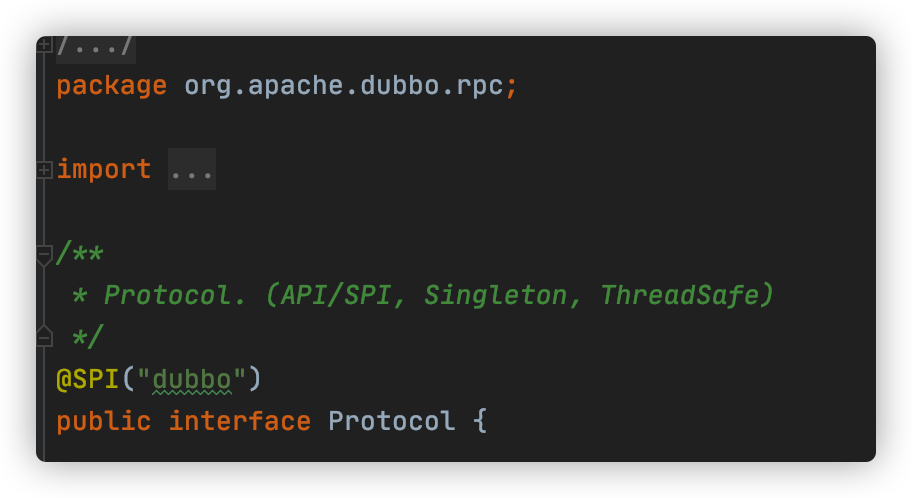
@SPI 注解有一个 value 属性值,用于指定默认的扩展名称。
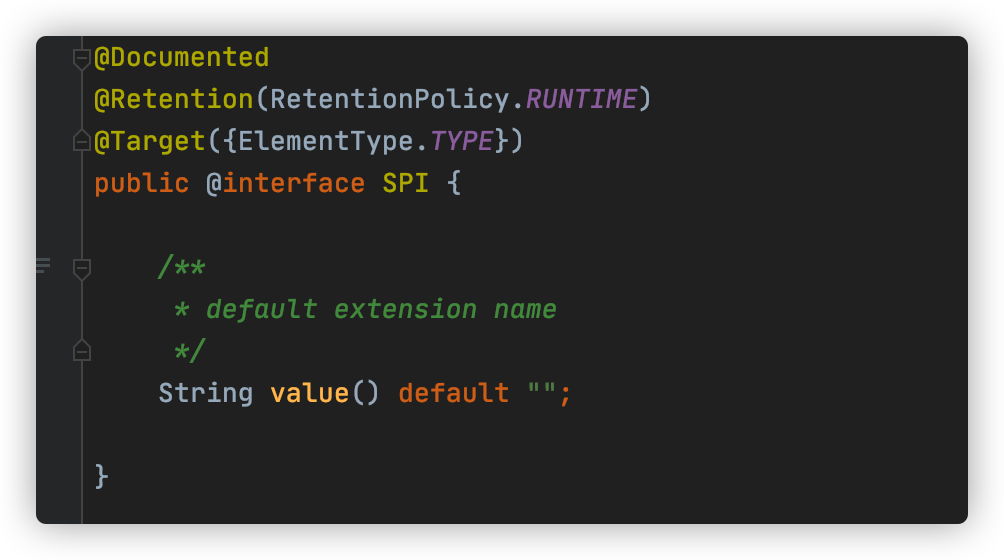
上文Protocol扩展点声明中表示,在通过 Dubbo SPI 加载 Protocol 接口实现时,如果没有明确指定扩展名,则默认使用dubbo作为该扩展点的实现,所以,我们的Dubbo服务接口默认是使用dubbo协议的。
3. ExtensionLoader扩展加载类
作用类似于Java SPI的java.util.ServiceLoader,负责扩展的加载和生命周期维护。
我们要看Dubbo扩展的源码的话,ExtensionLoader类是非常关键的类,SPI相关的核心逻辑都在这个类中。
ExtensionLoader位于 dubbo-common 模块的 extension 包中:
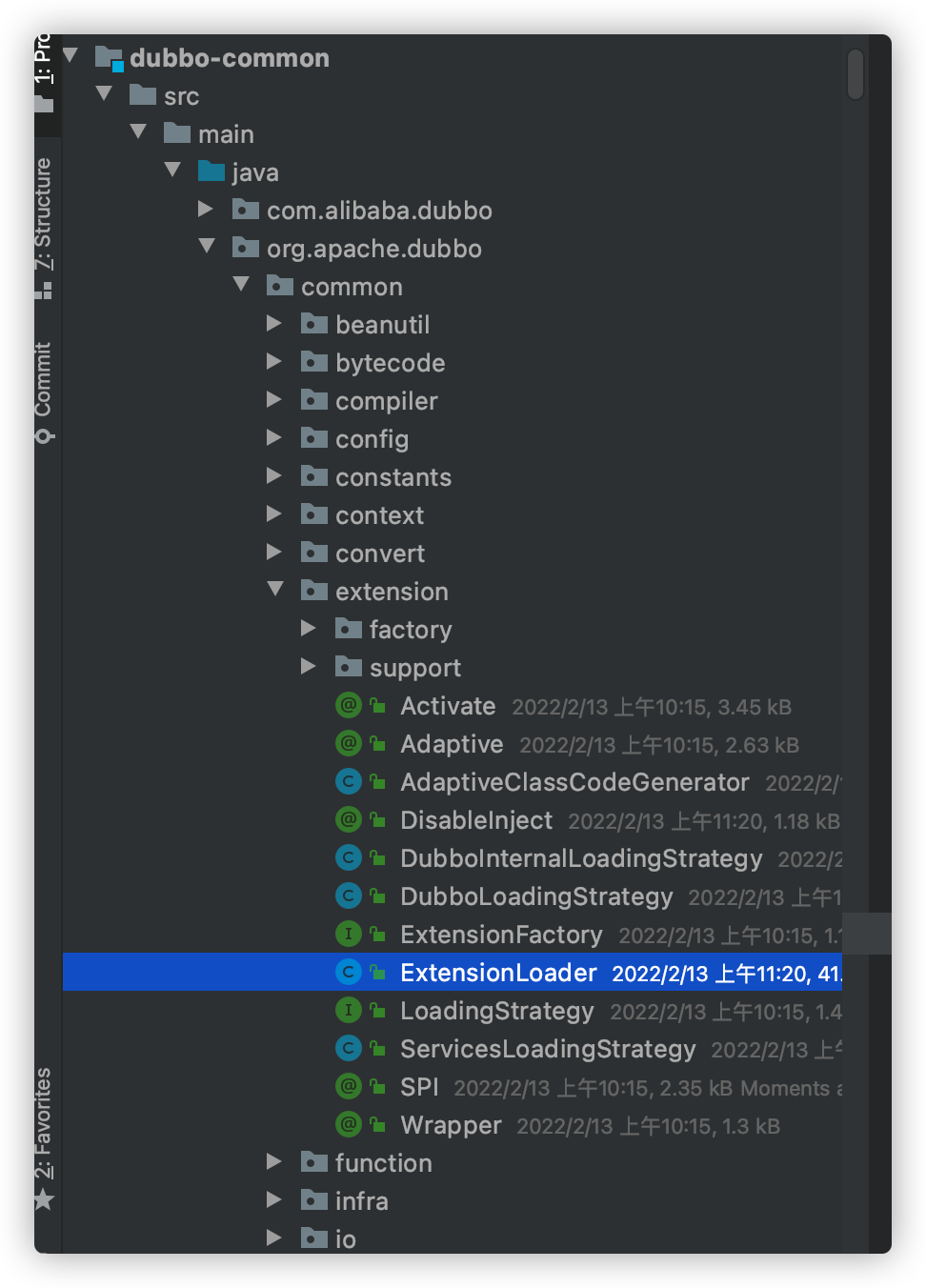
它有一个获取指定扩展点的扩展加载器的方法getExtensionLoader:
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
if (type == null) {
throw new IllegalArgumentException("Extension type == null");
}
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");
}
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type (" + type +
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");
}
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}
和一个获取指定扩展名的扩展的方法getExtension:
public T getExtension(String name) {
return getExtension(name, true);
}
所以,一般使用方式如下:
Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getExtension("injvm");
三、自定义一个扩展
1. 包结构
Dubbo支持多种序列化方式,比如hessian、kryo、pb等。看源码包dubbo-serialization可以看到不同的序列化方式实现原理:
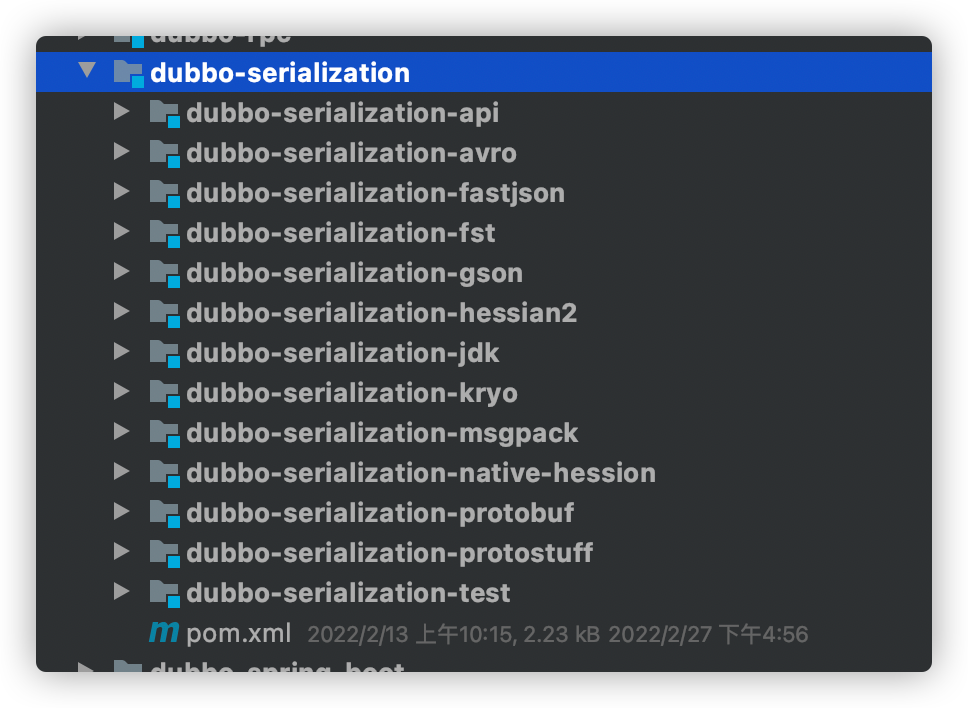
今天,我不去说每个序列化方式的实现细节,只是通过引入jackson包实现给Dubbo新增一种序列化方式。
首先,我的包结构如下:

dubbo-demo-consumer:定义Dubbo消费者客户端
dubbo-demo-facade:定义接口
dubbo-demo-provider:定义Dubbo提供者客户端
dubbo-demo-serialization:jackson序列化扩展
重点在dubbo-demo-serialization包,这个包是序列化扩展实现的关键。
2. 实现Serialization扩展点
Dubbo已经定义好序列化策略的扩展点Serialization(从@SPI注解可以看出是一个SPI扩展点)
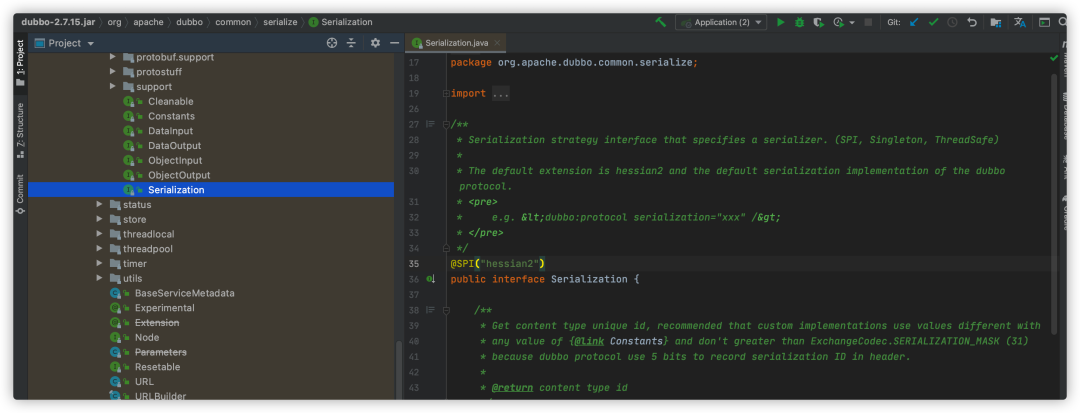
首先,引入jackson序列化工具依赖包:
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.0</version>
</dependency>
我定义了JacksonSerialization扩展实现,如下:
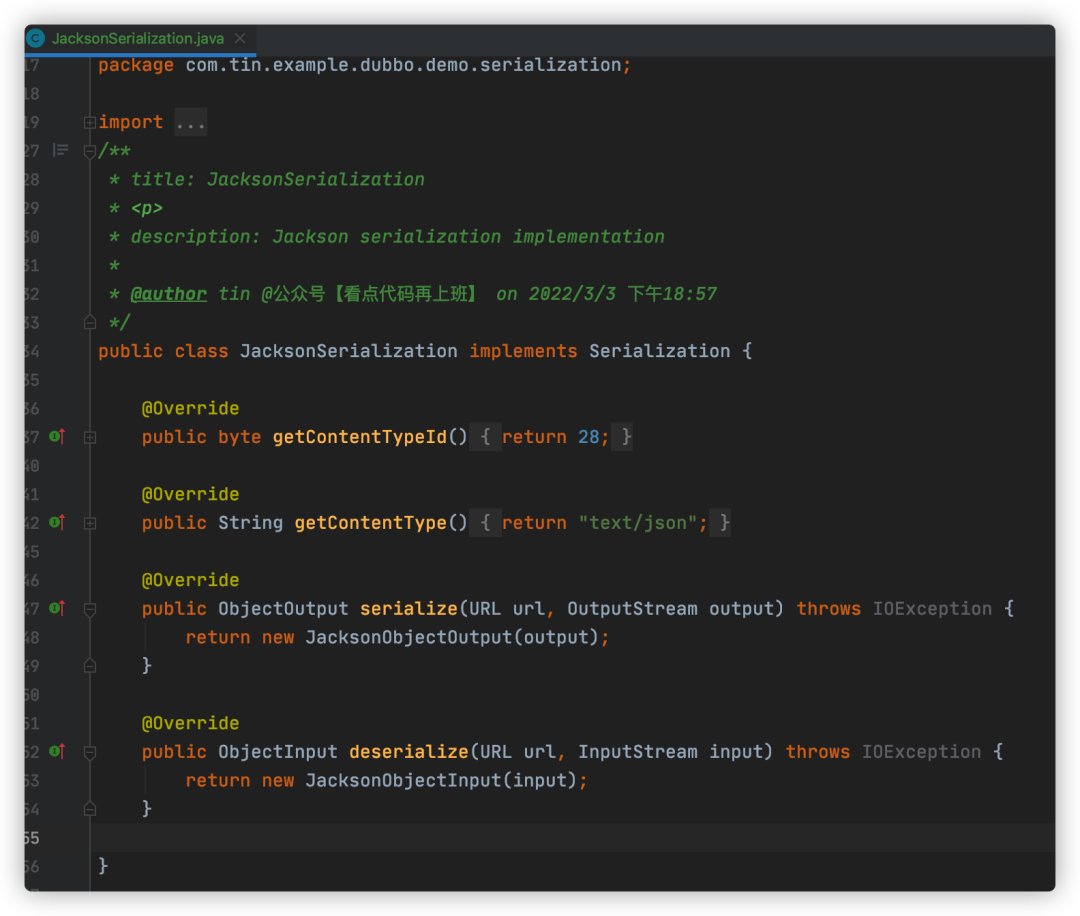
3. META-INF目录下配置扩展信息
根据Dubbo扩展实现的原理,Dubbo会从这个目录加载扩展,我把key定义为jackson,如下:

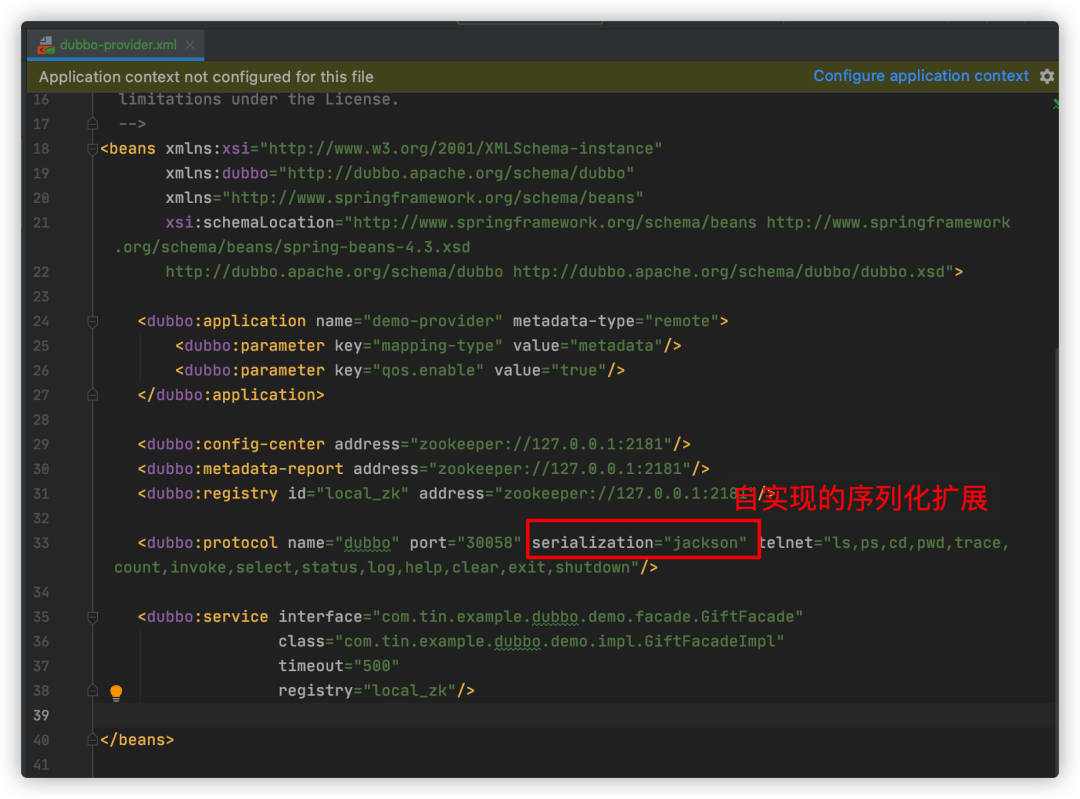
4. 配置使用自实现的Jackson协议
我们可以在provider配置文件内指定我们的服务采用哪种序列化方式,比如采用xml文件方式可以指定dubbo:protocol标签中的serialization属性:
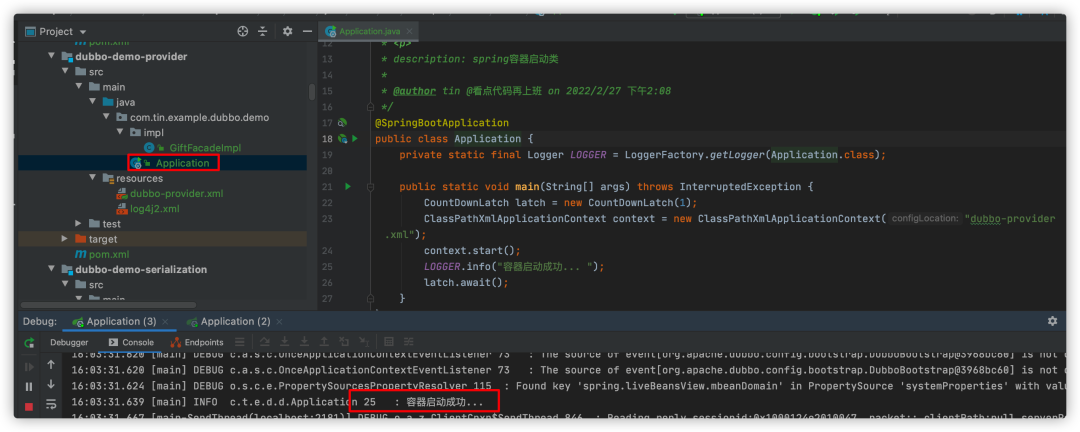
5. 启动客户端,完成Dubbo服务的jackson序列化
首先启动provider
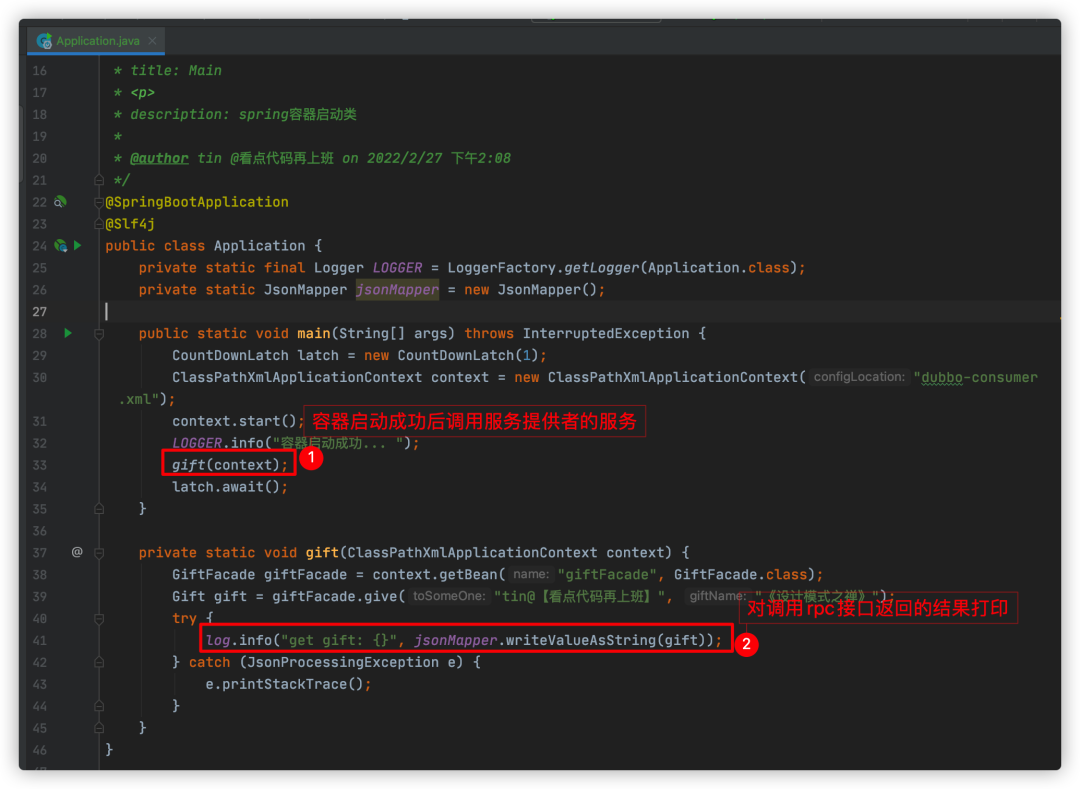
其次启动consumer
查看provider控制台日志打印信息
可以看到jason序列化扩展打印的相关read/write日志:
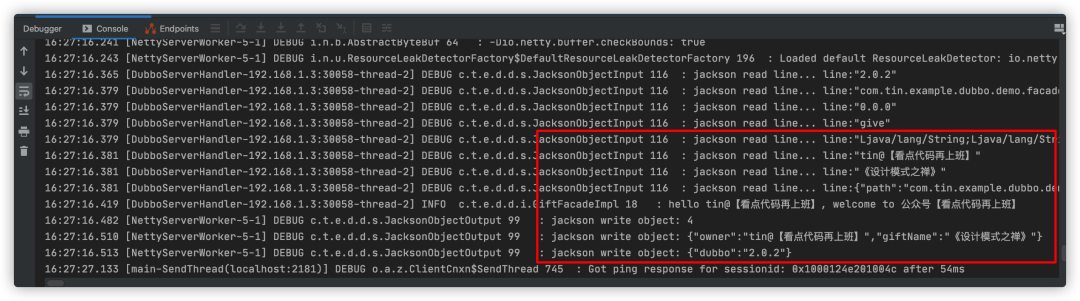
查看consumer控制台日志打印信息
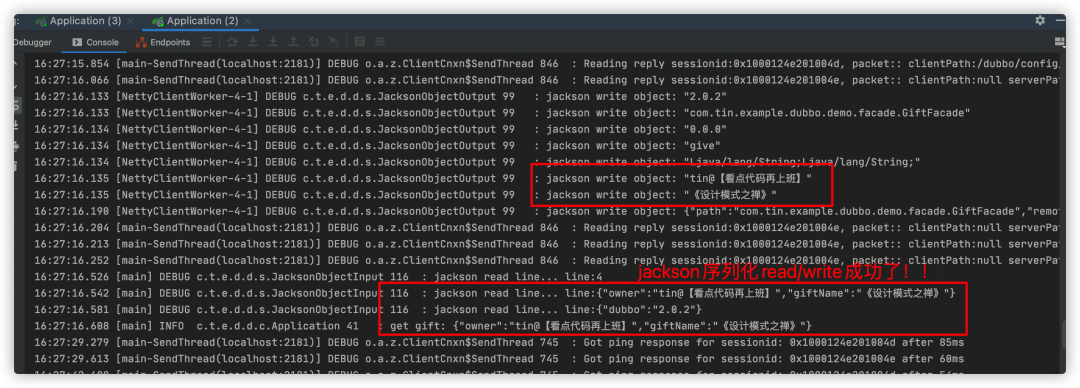
新增的序列化扩展运行成功了!源码在这里,有兴趣的朋友可下载自运行:
四、结语
我是tin,一个在努力让自己变得更优秀的普通工程师。自己阅历有限、学识浅薄,如有发现文章不妥之处,非常欢迎加我提出,我一定细心推敲并加以修改。
坚持创作不容易,你的正反馈是我坚持输出的最强大动力,谢谢!

最后附上原文链接!⏬⏬⏬
https://mp.weixin.qq.com/s?__biz=MzIwMDEzOTYzNA……



