
一、前言
Java性能优化之影响性能的那些细节 - 续来了。打算把这个标题整个系列文章,后面慢慢积累慢慢写。这是第一篇入口。这次内容主要来源于《Java程序性能优化实战》这本书,算是一份读书笔记,感兴趣的小伙伴可以阅读下这本书。
二、List接口
先来看下这几个List的类图:
ArrayList
Vector
LinkedList
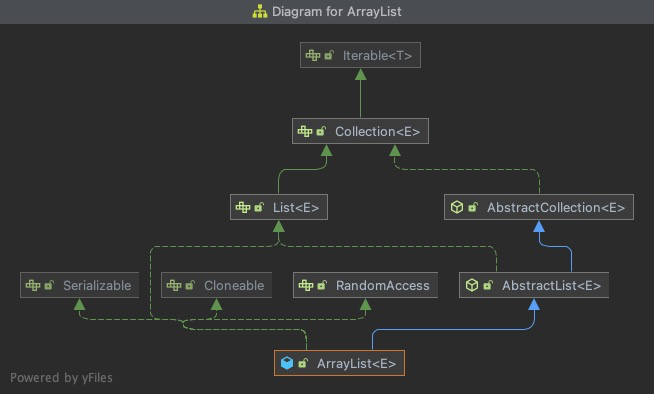
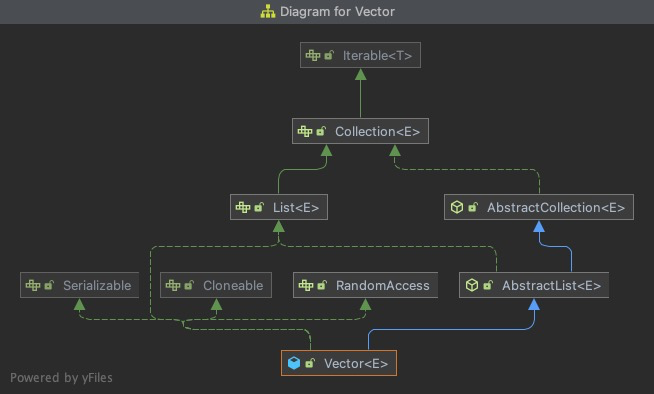

ArrayList、Vector以及LinkedList3种List均来自AbstractList的实现,而AbstractList直接实现了List接口,并扩展自AbstractCollection。
1. ArrayList和Vector
ArrayList和Vector基本差不多,所以就把这两放一块了。这两个实现类几乎使用了相同的算法,它们的 唯一区别 可以认为是对多线程的支持。ArrayList没有对任何一个方法做线程同步,因此不是线程安全的; Vector中的绝大部分方法都做了线程同步,是一种线程安全的实现方式;
ArrayList和Vector使用了数组。可以认为ArrayList或者Vector封装了对内部数组的操作,例如向数组中添加、删除、插入新的元素或者数组的扩展和重定义。(对于ArrayList和Vector的一些优化方式其实都是基于数组的来的,因此一般情况同样适用于底层使用数组的其他情况)
ArrayList的当前容量足够大【默认初始化长度为10】,add()操作的效率就非常高,ArrayList扩容【默认扩容原本的1.5倍】过程中会进行大量的数组复制操作,相对来说频繁的扩容会有性能影响;扩容的核心源码如下:
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 这里用位运算来实现的。相当于newCapacity = oldCapacity + (oldCapacity / 2)
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}从源码中我们又能get一个细节:代码中的整数乘除使用位运算实现,可以大大提高计算效率。
- 从尾部删除元素时效率很高,从头部删除元素时相当费时,原因是每次删除后都要进行数组的重组;
- 插入操作都会进行一次数组复制【除尾端插入情况】,而这个操作在增加元素到
List尾端的时候是不存在的。大量的数组重组操作会导致系统性能低下,并且插入的元素在List中的位置越靠前,数组重组的开销也越大;
- 尽量直接访问内部元素,而不要调用对应的接口。因为函数调用是需要消耗系统资源的,而直接访问元素会更高效,比如直接使用List数组下标索引,而不用get接口。
2. LinkedList
LinkedList使用了循环双向链表数据结构。与基于数组的List相比,这是两种截然不同的实现技术,这也决定了它们将适用于完全不同的工作场景。LinkedList链表由一系列表项连接而成。一个表项包含3部分,即元素内容、前驱表项和后驱表项。
- 无论
LinkedList是否为空,链表内都有一个header表项,它既表示链表的开始,也表示链表的结尾。循环链表 示意图如下:
LinkedList对堆内存和GC要求较高,原因是每次添加元素都要new Entry(),及每次都要封装数据,因为必须设置前指针和后指针,才能加入到链表中;
LinkedList从头、尾删除元素时效率相差无几级,但是从List中间删除元素时性能非常糟糕,原因是每次都要遍历半个链表;
(下面是前一篇文章中提到过的关于LinkedList的注意点)- 使用ListIterator(forEach,利用指针遍历)遍历LinkedList【链表特性】;
- 避免任何接受或返回列表中元素索引的LinkedList方法【类似获取index的操作】,性能很差,遍历列表实现;

三、Map接口
先来看下这几个Map的类图:
HashMap
LinkedHashMap
TreeMap

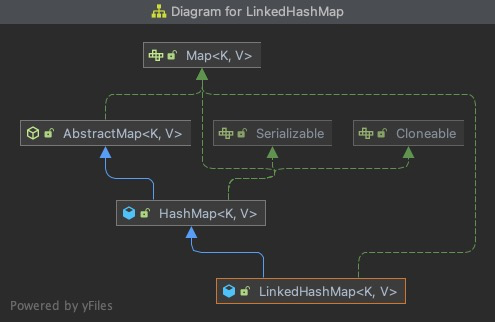

这3个Map都是实现Map接口,继承AbstractMap类。HashMap和LinkedHashMap直接继承AbstractMap类,而LinkedHashMap继承了HashMap。
1. HashMap
HashMap的性能在一定程度上取决于hashCode()的实现。一个好的hashCode()算法,可以尽可能减少冲突,从而提高HashMap的访问速度。另外,一个较大的负载因子意味着使用较少的内存空间,而空间越小,越可能引起Hash冲突。
HashMap初始化默认数组大小16,在创建的时候指定大小【默认使用达到75%进行自动扩容,每次扩容为原来的2倍,最大长度2^30】,参数必须是2的指数幂(不是的话强行转换);扩容部分源码如下:
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 这里也是用的位运算,相当于乘2
newThr = oldThr << 1; // double threshold
}HashMap扩容大体流程(jdk8):
i. new一个新的数组
ii. 借助二进制的高低位指针进行数据迁移(最高位是0则坐标不变,最高位是1则坐标为原位置+新数组长度,如果是树结构有额外的逻辑)【这里不过多的解释HashMap的扩容机制】;
iii. 链表长度大于8,且hash table长度大于等于64,则会将链表转红黑树(一般情况不使用红黑树,优先扩容) ;
2. LinkedHashMap
LinkedHashMap可以保持元素输入时的顺序;底层使用循环链表,在内部实现中,LinkedHashMap通过继承HashMap.Entry类,实现了LinkedHashMap.Entry,为HashMap.Entry增加了before和after属性,用于记录某一表项的前驱和后继。
- 一些注意点参照
LinkedList(链表)
3. TreeMap
TreeMap,实现了SortedMap接口,这意味着它可以对元素进行排序,然而TreeMap的性能却略微低于HashMap;
TreeMap的内部实现是基于红黑树的。红黑树是一种平衡查找树,它的统计性能要优于平衡二叉树。它具有良好的最坏情况运行时间,可以在O(logn)时间内做查找、插入和删除操作。
- 如果需要对
Map中的数据进行排序,可以使用TreeMap,而不用自己再去实现很多代码,而且性能不一定很高;
四、关于List的测试demo
package com.allen.list;
import org.junit.Test;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Vector;
/**
* 1、ArrayList,Vector:尾部添加元素性能高,头部插入元素每次插入都会涉及元素的复制和移动,性能较低
* 2、LinkedList:每次添加元素都要new Entry(),对堆内存和GC要求较高【-Xmx512M -Xms512M 使用这个参数对测试结果有一定影响】
*/
public class TestList {
private static final int CIRCLE1 = 50000;
protected List list;
protected void testAddTail(String funcname){
Object obj=new Object();
long starttime=System.currentTimeMillis();
for(int i=0;i<CIRCLE1;i++){
list.add(obj);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
protected void testDelTail(String funcname){
Object obj=new Object();
for(int i=0;i<CIRCLE1;i++){
list.add(obj);
}
long starttime=System.currentTimeMillis();
while(list.size()>0){
list.remove(list.size()-1);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
protected void testDelFirst(String funcname){
Object obj=new Object();
for(int i=0;i<CIRCLE1;i++){
list.add(obj);
}
long starttime=System.currentTimeMillis();
while(list.size()>0){
list.remove(0);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
protected void testDelMiddle(String funcname){
Object obj=new Object();
for(int i=0;i<CIRCLE1;i++){
list.add(obj);
}
long starttime=System.currentTimeMillis();
while(list.size()>0){
list.remove(list.size()>>1);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
protected void testAddFirst(String funcname){
Object obj=new Object();
long starttime=System.currentTimeMillis();
for(int i=0;i<CIRCLE1;i++){
list.add(0, obj);
}
long endtime=System.currentTimeMillis();
System.out.println(funcname+": "+(endtime-starttime));
}
// 测试ArrayList尾部添加
@Test
public void testAddTailArrayList() {
list=new ArrayList();
testAddTail("testAddTailArrayList");
}
//@Test
public void testAddTailVector() {
list=new Vector();
testAddTail("testAddTailVector");
}
// 测试LinkedList尾部添加
@Test
public void testAddTailLinkedList() {
list=new LinkedList();
testAddTail("testAddTailLinkedList");
}
// 测试ArrayList头部添加
@Test
public void testAddFirstArrayList() {
list=new ArrayList();
testAddFirst("testAddFirstArrayList");
}
// @Test
public void testAddFirstVector() {
list=new Vector();
testAddFirst("testAddFirstVector");
}
// 测试LinkedList头部添加
@Test
public void testAddFirstLinkedList() {
list=new LinkedList();
testAddFirst("testAddFirstLinkedList");
}
// 测试ArrayList尾部删除
@Test
public void testDeleteTailArrayList() {
list=new ArrayList();
testDelTail("testDeleteTailArrayList");
}
// @Test
public void testDeleteTailVector() {
list=new Vector();
testDelTail("testDeleteTailVector");
}
// 测试LinkedList尾部删除
@Test
public void testDeleteTailLinkedList() {
list=new LinkedList();
testDelTail("testDeleteTailLinkedList");
}
// 测试ArrayList头部删除
@Test
public void testDeleteFirstArrayList() {
list=new ArrayList();
testDelFirst("testDeleteFirstArrayList");
}
// @Test
public void testDeleteFirstVector() {
list=new Vector();
testDelFirst("testDeleteFirstVector");
}
// 测试LinkedList头部删除
@Test
public void testDeleteFirstLinkedList() {
list=new LinkedList();
testDelFirst("testDeleteFirstLinkedList");
}
// 测试LinkedList中间删除
@Test
public void testDeleteMiddleLinkedList() {
list=new LinkedList();
testDelMiddle("testDeleteMiddleLinkedList");
}
// 测试ArrayList中间删除
@Test
public void testDeleteMiddleArrayList() {
list=new ArrayList();
testDelMiddle("testDeleteMiddleArrayList");
}
}



