
隐藏了2年的Bug,终于连根拔起,悲观锁并没有那么简单原创
接手的新项目,接二连三的出现账不平的问题,作为程序员中比较执着的人,不解决誓不罢休。最终,经过两次,历时多日终于将其连根拔起。实属不易,特写篇文章记录一下。
文章中不仅会讲到使用悲观锁踩到的坑,以及本人是如何排查问题的,某些思路和方法或许能对大家有所帮助。
事情的起源
运营同事时不时就提出查账调账的需求,原因很简单,账不平,不查不行。如果你有过财务相关系统的工作经历,账务问题始终是最难攻克的。
虽然刚接手项目,虽然很多业务逻辑还不了解,但出现这样的技术挑战,还是要坚决攻克的。
其实,这类问题的原因很简单:热点账户。当很多服务或线程操作同一个用户的账户时,就会出现一个更新把另外一个更新覆盖掉的情况。
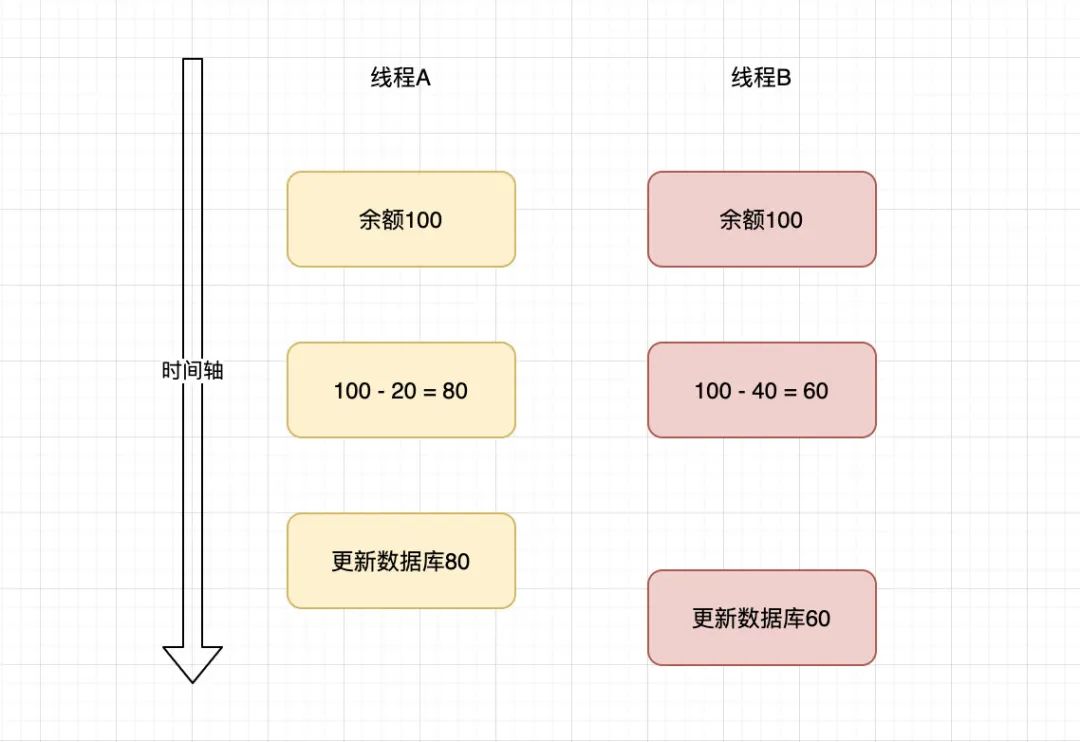
上图可轻易看出,当两个服务或线程同时查询数据库的一条数据(热点账户),然后内存中做修改,最后更新到数据库。如果出现并发情况,两个线程都读取了100,一个计算得80,一个计算得60,后更新的就有可能将前面的覆盖掉。
解决方案通常有:
-
单服务线程锁; -
集群分布式锁; -
集群数据库悲观锁;
项目中已采用了悲观锁,就基于来进行排查追踪原因。
何谓悲观锁
悲观锁是在对数据被的修改持悲观态度,在整个数据处理过程中会将数据锁定。
悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在应用层中实现了加锁机制,也无法保证外部系统不会修改数据)。
通常会使用select ... for update语句来实现对数据的枷锁。
for update仅适用于InnoDB,且必须在事务块(BEGIN/COMMIT)中才能生效。在进行事务操作时,通过“for update”语句,MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞。排他锁包含行锁、表锁。
如下示例展示了悲观锁的基本使用流程:
set autocommit=0;
//设置完autocommit后,执行正常业务。具体如下:
//0.开始事务
begin;/begin work;/start transaction; (三者选一就可以)
//1.查询出商品信息
select status from t_goods where id=1 for update;
//2.根据商品信息生成订单
insert into t_orders (id,goods_id) values (null,1);
//3.修改商品status为2
update t_goods set status=2;
//4.提交事务
commit;/commit work;
因为关闭了数据库自动提交,这里通过begin/commit来管理事务。
使用select…for update的方式通过数据库实现了悲观锁。其中,id为1的那条数据就被锁定,其它的事务必须等本次事务提交之后才能执行。这样就保证了在操作期间数据不会被其它事务修改。
原因初步分析
在了解了账不平的原因和悲观锁的基本原理之后,就可以进行问题的排查了。既然系统已经使用了悲观锁,竟然还会出现问题,那肯定是哪里漏掉了什么。
于是,排查了所有账户(account表)更新的地方,还真找到一处bug。
大多数地方都使用了悲观锁,先for update查询一下,然后计算新的余额,再进行更新数据库。但有一处竟然先查询到了计算了余额,然后再进行加锁,最后更新。
基本流程如下:
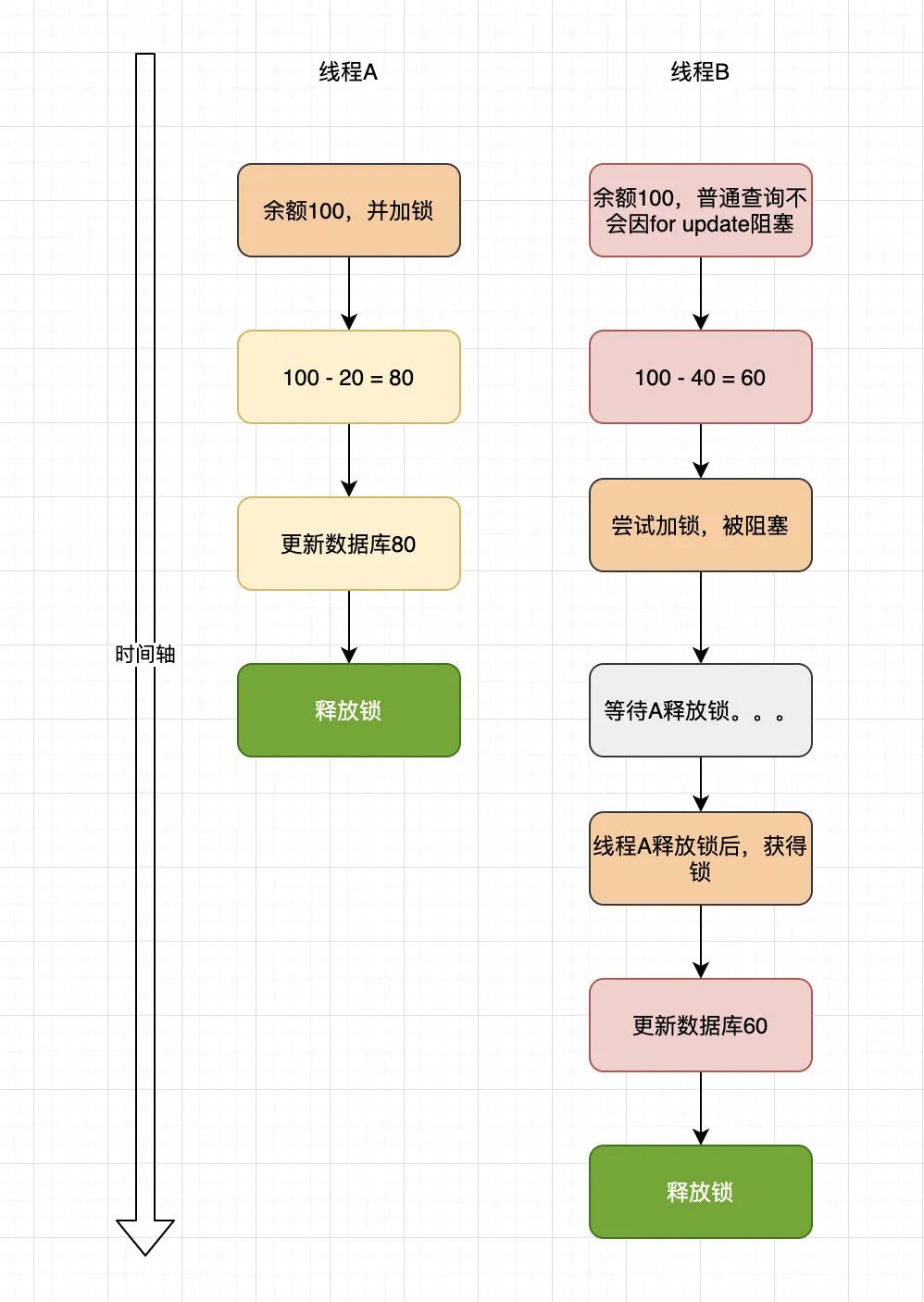
在上述情况中,虽然线程B进行了加锁处理,但由于计算新余额并未在锁中,导致虽然使用了悲观锁,但依旧存在问题。正确的使用方式就是将计算余额的逻辑放在锁中。
当然,如果线程B完全被遗忘加锁了,也会出现同样的问题。
在排查解决了上述bug,我开始嘚瑟了,以为彻底解决了账不平的问题。
一个月之后
结果一个月之后,运营同事又来找了,偶尔依旧会出现账不平的问题。刚开始我还以为是不是搞错了,历史的账不平导致现在最终的不平。但最终还是下定决心再排查一次。
第一天,把账不平的账户的账务流水、涉及到代码、日志全部捋一遍。这期间还遇到了很多小困难,最终注意克服。
困难一:数据查不动
账务记录表数据太多,上千万的数据,最初的设计者并没有创建索引。这就要了老命了,根据筛选条件根本查不出数据来。
这里就用到SQL优化的两个技能点:limit限制查询条数和高效的分页策略。
关于limit限制查询条件这一点很明显,不仅减少了结果集,而且在遇到符合条件的数据之后会立马返回。
高效的分页策略在列表页在查询数据经常遇到,为了避免一次性返回过多的数据影响接口性能,一般会对查询接口做分页处理。
在Mysql中分页一般用的limit关键字:
select id,name,age from user limit 10,20;
少量数据时,limit分页没啥问题。但如果表中数据量很多,就会出现性能问题。
比如分页参数变成了:
select id,name,age from user limit 1000000,20;
Mysql会查到1000020条数据,然后丢弃前面的1000000条,只查后面的20条数据,非常浪费资源。
优化sql:
select id,name,age from user where id > 1000000 limit 20;
当然还可以使用between优化分页:
select id,name,age
from user where id between 1000000 and 1000020;
值得庆幸的是那张表的ID是自增的,于是用了id大于的条件,只差了最近的交易记录,才勉强把数据查询出来。
困难二:日志过多
由于系统日志打的比较详细,一个项目每天大概几个G的日志。要在这中间查询到有用的日志,也是一个调整。
排查问题时,先使用了grep 命令找到出问题交易的账号日志:
grep 123 info.log
当大概定位的到日志输出时间了,再利用区间缩小日志范围:
grep '2021-11-17 19:23:23' info.log > temp.log
这里同样使用grep命令查找对应时间区间的日志,并将查找到日志输出到temp.log文件中,然后通过sz命令,下载到本地进行筛选分析。
这里大家可以善用grep命令。同时也要善用输出到新文件,这样比每次查几个G的内容方便多了。当然更方便的就是把筛选之后的日志下载本地,再次比对分析。
其他
关于代码筛选这块,没有什么诀窍,除了从头到位的捋一捋,没有别的好方法。不过这个过程善用IDE的搜索和“Find usages”功能即可。
日终收获
经过上述排查,最终在临下班时,定位到了问题的原因:一个线程将余额更新之后,另外一个线程将其覆盖了。在账务流水记录中存在了两笔紧邻,且计算前余额一样的记录。
得出结果之后,再排查其他的同类问题就方便多了,比如可采用group by来进行快速筛选:
select count(id) as num , balance from account group by balance having num > 1;
通过上述语句就可以快速查出有同样计算前余额的记录。当然,上述语句还可以添加条件和结果维度。
虽然找到的问题发生的地方,但并未完全找到问题的原因。
更深层次的Bug
本以为找到了问题发生的点,就能快速解决问题的,但的确小觑了这个Bug,又是一整天才排查出根本原因。
模拟高并发
找到出问题的代码,看了实现逻辑,没问题啊,也加了悲观锁,数据库事务也没失效,也没有同Service的方法调用。怎么就会出现问题呢?
既然肉眼看不出来,那就用程序跑。于是,写了一个单元测试,创建一个线程池,来调用对应加锁方法。结果,依旧没问题。
由于跑的是测试库,生产库用的是云服务,担心是数据库的差异,于是在Navicat验证了悲观锁是否生效:
START transaction ;
select * from account where id = 1 for update;
然后在另外一个查询窗口执行:
select * from account where id = 1 for update;
发现,数据库的锁的确是生效的,在没有执行commit操作之前,是查不到数据的。
僵局与希望
此时,完全陷入僵局。于是就开始大量搜索资料,多次阅读代码。
最终,在一篇写得很水,但给了一个Hibernate javadoc文档链接的文中,无意点了一下链接,获得了巨大的启发。
在javadoc看了一下session实现悲观锁的方法。项目中用了已经废弃的get方法:
get
@Deprecated
Object get(Class clazz,
Serializable id,
LockMode lockMode)**Deprecated.**LockMode parameter should be replaced with LockOptions
Return the persistent instance of the given entity class with the given identifier, or null if there is no such persistent instance. (If the instance is already associated with the session, return that instance. This method never returns an uninitialized instance.) Obtain the specified lock mode if the instance exists.
其中的“If the instance is already associated with the session, return that instance”让我眼前一亮。难道是缓存在作祟?
上面的重点是:如果session中已经存在这么个对象实例,会直接返回这个实例。
感觉回去看代码,还真是的,伪代码如下:
Account account = accountService.getAccount(type, userNo);
if(account == null){
//...
}
accountService.getAccountAndLock(account.getId());
// ...
上述代码首先值得肯定的有两点:第一,在加锁之前先查了一次对象,这样能避免因为对象不存在,锁住全表;第二,就是锁一条数据库记录时尽量采用id,精确定位到具体的记录,避免锁住其他记录或整张表。
那么,是不是因为前面的查询导致后面getAccountAndLock方法的实效呢?再来验证一下。
于是,在单元测试中添加了前面的查询,再次执行。哈哈,Bug终于复现了!
为了进一步证实,在底层的公共方法中添加了clear操作:
public T findAndLock(Class cls, String primaryKey) throws DataAccessException {
Session session = getHibernateTemplate().getSessionFactory().getCurrentSession();
// 添加验证是否缓存问题
session.clear();
Object object = session.load(cls, primaryKey, LockOptions.UPGRADE);
return (T) object;
}
再次执行单元测试,可正常加锁。至此,Bug定位完毕。
问题的解决
既然已经定位问题,解决起来就非常方便了。上面使用session.clear()只是为了验证,真实生产使用这种方法影响太大,而且是事后处理。
解决方案:将基于Hibernate的普通查询,改为基于原生SQL的查询。因为前面的普通查询只需要id,那么只用一条SQL查询ID即可,如果id为空,则不存在;如果id非空,则再进行下一步处理。
至此,问题完美解决。
小结
在解决上述问题的过程中,看似只是很简单的悲观锁,但在排查的过程中还用到和涉及到了大量的其他知识,比如@Transactional事务失效场景的排查、事务的隔离级别、Hibernate的多级缓存、Spring的事务管理、多线程、Linux操作、Navicat手动事务、SQL优化、单元测试、Javadoc查阅等。
所以,在解决问题之后,觉得十分有必要分享给大家。通过这个案例,你又学到了什么呢?
往期推荐
如果你觉得这篇文章不错,那么,下篇通常会更好。添加微信好友,可备注“加群”(微信号:zhuan2quan)。
和花一辈子都看不清的人,
注定是截然不同的搬砖生涯。







