
一、前言
最近遇到了个log4j2写日志导致线程阻塞的问题(多亏了开发小哥日志打的多,不然就没有下面这一系列骚操作)。

大致描述下当时的情况(内网限制,没法把现场东西拿出来,只能口述了):
log4j2配置情况: 同时配置了3个RollingRandomAccessFile,分别针对SQL语句、INFO日志、ERROR日志,大致的配置如下:
<RollingRandomAccessFile name="RandomAccessFile" fileName="${FILE_PATH}/async-log4j2.log" append="false"
filePattern="${FILE_PATH}/rollings/async-testLog4j2-%d{yyyy-MM-dd}_%i.log.gz">
<PatternLayout>
<Pattern>${LOG_PATTERN}</Pattern>
</PatternLayout>
<ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY"/>
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true" />
<SizeBasedTriggeringPolicy size="450MB"/>
</Policies>
<DefaultRolloverStrategy max="15" compressionLevel="0"/>
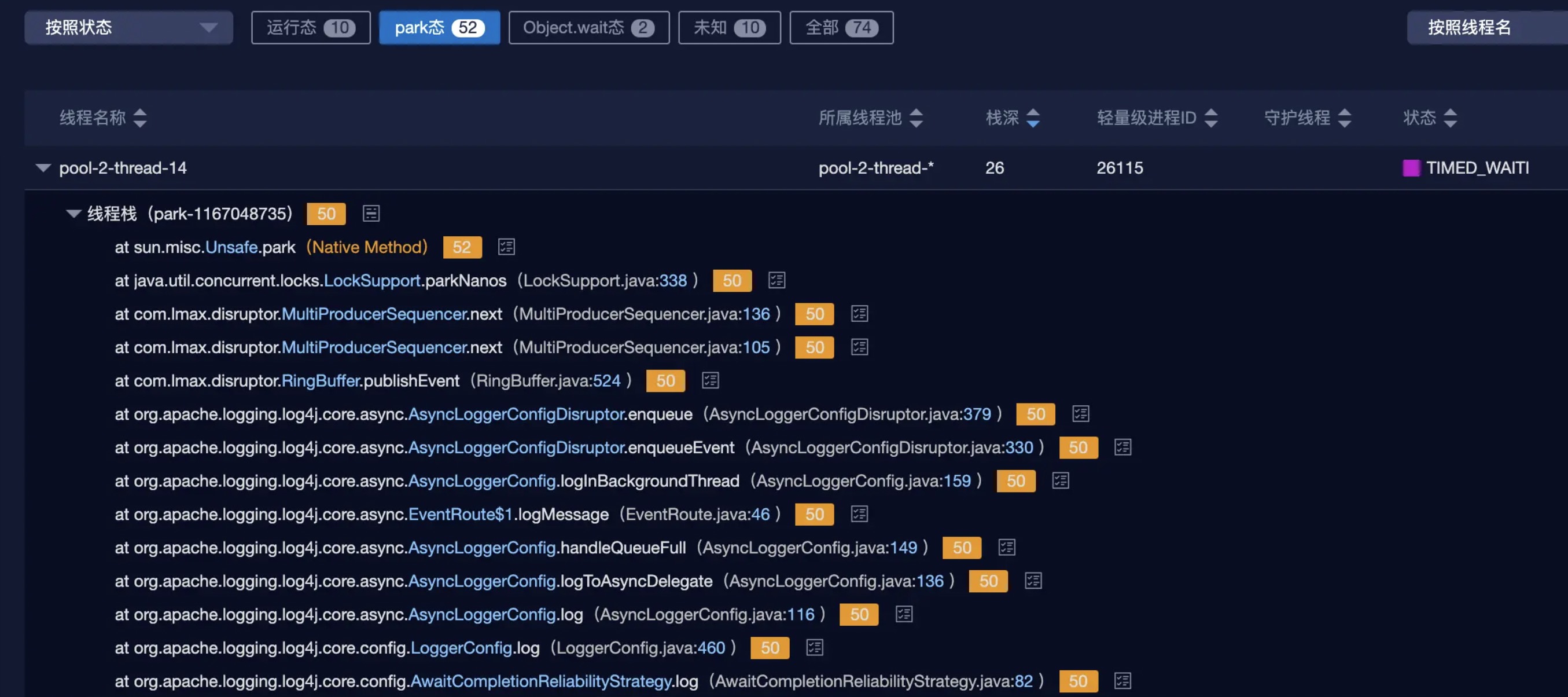
</RollingRandomAccessFile>问题描述: 1、32C的机器压缩日志占用30%+的资源;2、tomcat主线程全部50%+都是park状态,线程状态大致如下;
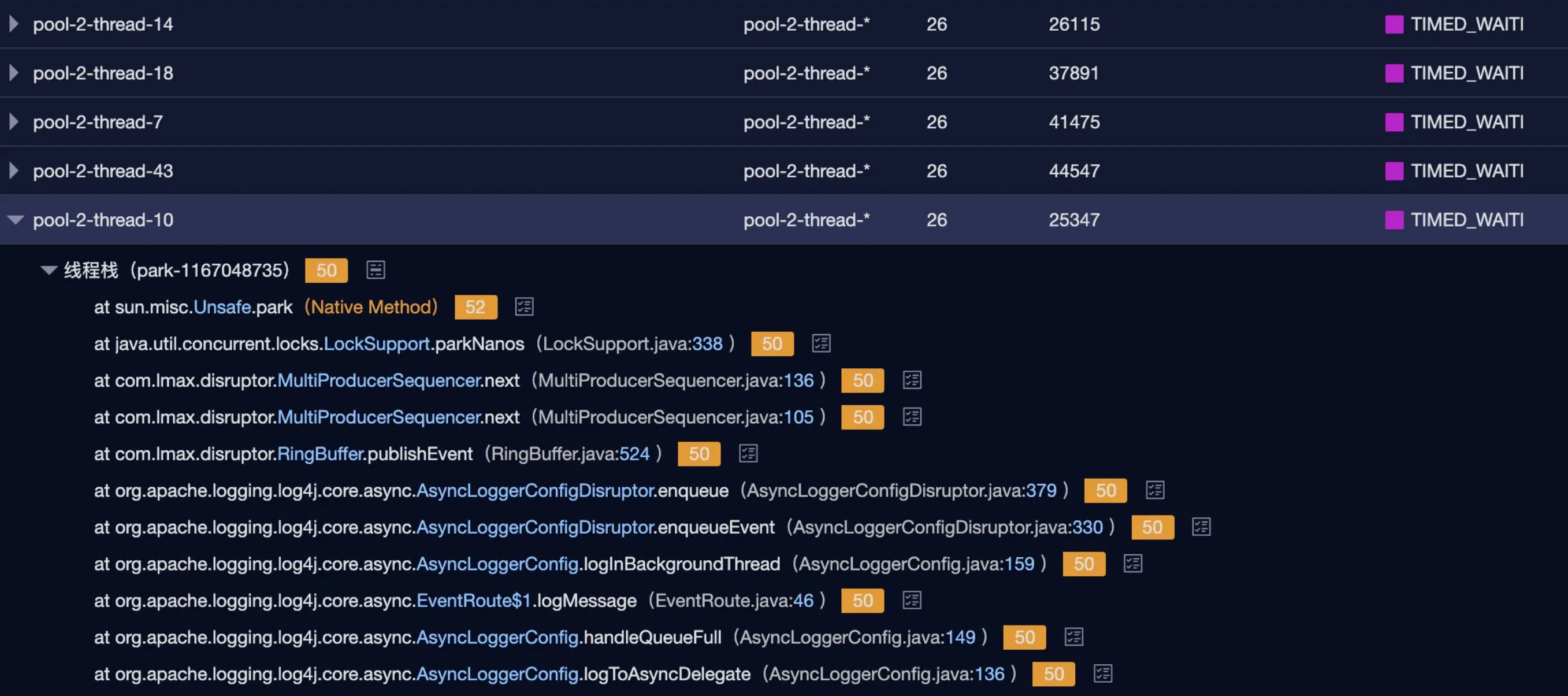
当时针对log4j2给的优化建议是: 1、配置immediateFlush=false 2、将filePattern对应的gz后缀去掉(因为对应的compressionLevel=0,根本不压缩),是否就不会调用JDK的Deflater进行压缩。【猜测,也是后面还原现场的原因之一,想亲自验证一下】
二、本地复现&部分源码学习
问题复现的过程也是蛮艰辛的,遇到各种问题。下面记录的是我本地复现时遇到的问题以及解决办法,附带一些log4j2基于disruptor的部分源码学习,篇幅可能会稍长。

环境:Macbook Pro x86(16C32G)、jdk1.8、log4j-core 2.12.1、log4j-api 2.12.1、disruptor 3.4.2
测试代码(启动50线程不间断地写日志【现场系统涉及200个Tomcat线程】):
public class TestLog4j {
private static Logger logger = LogManager.getLogger(TestLog4j.class);
private final ThreadPoolExecutor executor;
public TestLog4j() {
this.executor = new ThreadPoolExecutor(50, 50,
60, TimeUnit.SECONDS,
new ArrayBlockingQueue(1000),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
}
public void testLog() {
for (int i = 0; i < this.executor.getCorePoolSize(); i++) {
this.executor.execute(() -> {
while (true) {
logger.info("测试日志--麻利麻利哄快阻塞--麻利麻利哄快阻塞--麻利麻利哄快阻塞--麻利麻利哄快阻塞" +
"--麻利麻利哄快阻塞--麻利麻利哄快阻塞--麻利麻利哄快阻塞--麻利麻利哄快阻塞--麻利麻利哄快阻塞" +
"--麻利麻利哄快阻塞--麻利麻利哄快阻塞--麻利麻利哄快阻塞--麻利麻利哄快阻塞--麻利麻利哄快阻塞");
}
});
}
}
public static void main(String[] args) {
new TestLog4j().testLog();
}
}部分log4j2.xml配置(将备份的压缩日志大小改小至100M,备份文件数量增加至100):
<appenders>
<RollingRandomAccessFile name="RandomAccessFile" fileName="${FILE_PATH}/async-log4j2.log" append="false"
filePattern="${FILE_PATH}/rollings/async-testLog4j2-%d{yyyy-MM-dd}_%i.log.gz">
<PatternLayout>
<Pattern>${LOG_PATTERN}</Pattern>
</PatternLayout>
<ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY"/>
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true" />
<SizeBasedTriggeringPolicy size="100MB"/>
</Policies>
<DefaultRolloverStrategy max="100" compressionLevel="0"/>
</RollingRandomAccessFile>
</appenders>
<loggers>
<!--disruptor异步日志-->
<AsyncLogger name="DisruptorLogger" level="info" includeLocation="false">
<AppenderRef ref="RandomAccessFile"/>
</AsyncLogger>
<Asyncroot level="info" includeLocation="false">
<appender-ref ref="RandomAccessFile"/>
</Asyncroot>
</loggers>(一)线程阻塞-Blocked
一切准备就绪,点击运行,jps+jstack+jmap,一片自信满满。打开thread dump的那一刻,我就懵了,一片红红的blocked,此时应上问号脸。线程情况是这样的:
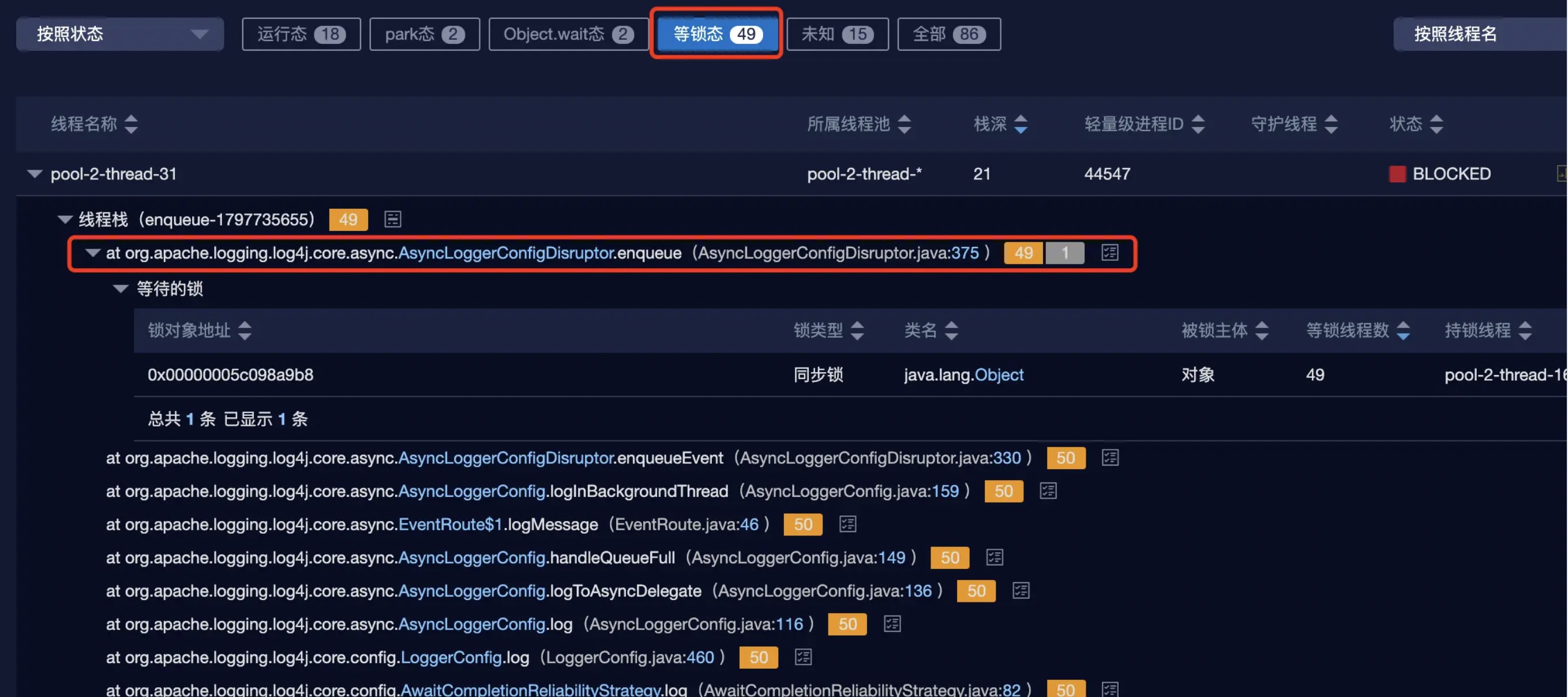
感觉和预期差的有点大啊,看样子是在往disruptor的RingBuffer里写日志的时候就blocked了,可以对比一下之前线程的线程情况,是没有blocked的。内存dump中好像发现了不一样的:
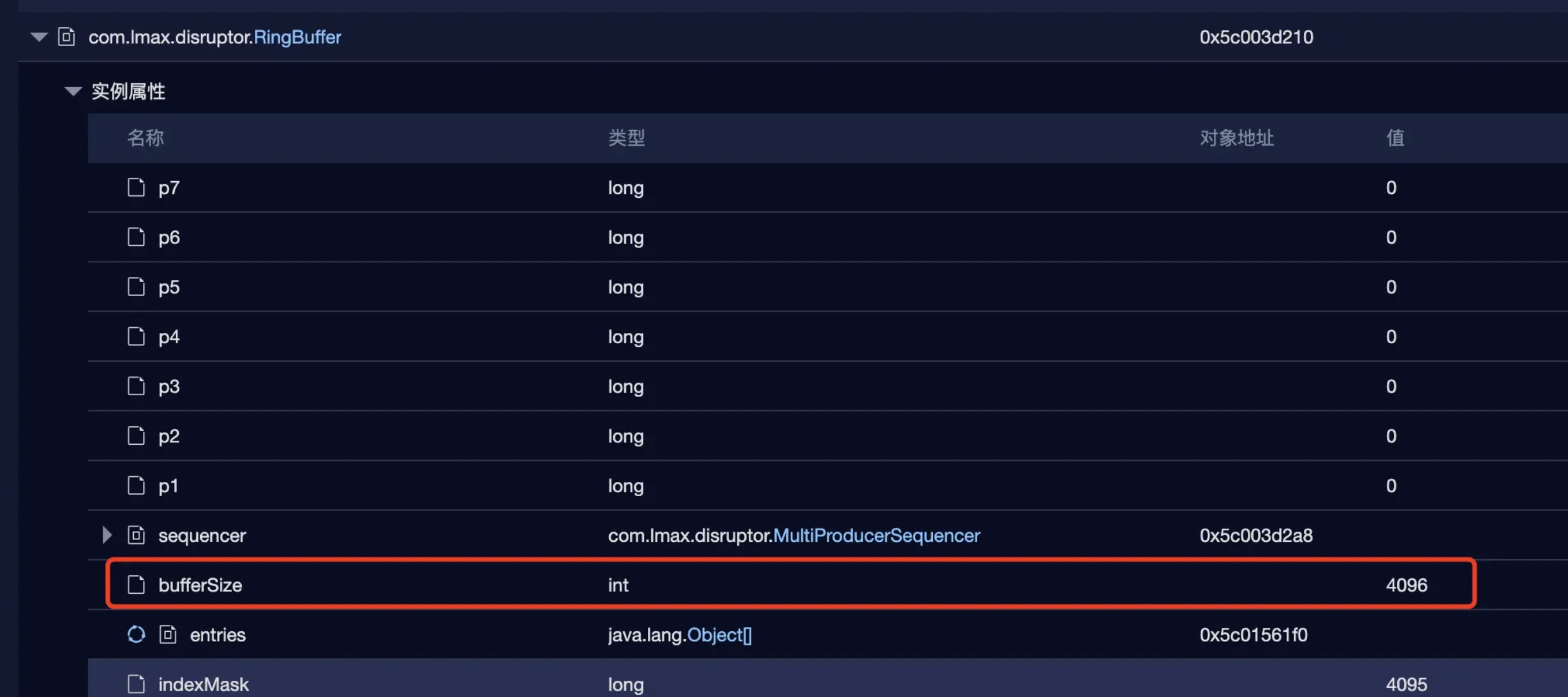
RingBuffer只有4096,印象里没有设置的话默认是256*1024。
(1)RingBuffer大小
org.apache.logging.log4j.core.async包下的DisruptorUtil类里定义了很多Disruptor相关的配置属性。
其中有三个RingBuffer size的静态属性,还有一个获取RingBufferSize的方法calculateRingBufferSize。
// DisruptorUtil类
private static final int RINGBUFFER_MIN_SIZE = 128;
private static final int RINGBUFFER_DEFAULT_SIZE = 256 * 1024;
private static final int RINGBUFFER_NO_GC_DEFAULT_SIZE = 4 * 1024;
static int calculateRingBufferSize(final String propertyName) {
// 如果ENABLE_THREADLOCALS为true,则使用RINGBUFFER_NO_GC_DEFAULT_SIZE即4096大小的size
int ringBufferSize = Constants.ENABLE_THREADLOCALS ? RINGBUFFER_NO_GC_DEFAULT_SIZE : RINGBUFFER_DEFAULT_SIZE;
// 获取配置文件中自定配置大小,如果没有返回上面ringBufferSize
final String userPreferredRBSize = PropertiesUtil.getProperties().getStringProperty(propertyName,
String.valueOf(ringBufferSize));
try {
int size = Integer.parseInt(userPreferredRBSize);
// 自定义配置大小小于128,则将size重新赋值为128
if (size < RINGBUFFER_MIN_SIZE) {
size = RINGBUFFER_MIN_SIZE;
LOGGER.warn("Invalid RingBufferSize {}, using minimum size {}.", userPreferredRBSize,
RINGBUFFER_MIN_SIZE);
}
// 自定义配置大小重新赋值给ringBufferSize
ringBufferSize = size;
} catch (final Exception ex) {
LOGGER.warn("Invalid RingBufferSize {}, using default size {}.", userPreferredRBSize, ringBufferSize);
}
return Integers.ceilingNextPowerOfTwo(ringBufferSize);
}然后看下Constants.ENABLE_THREADLOCALS就真相大白了:
/**
* {@code true} if we think we are running in a web container, based on the boolean value of system property
* "log4j2.is.webapp", or (if this system property is not set) whether the {@code javax.servlet.Servlet} class
* is present in the classpath.
*/
public static final boolean IS_WEB_APP = PropertiesUtil.getProperties().getBooleanProperty(
"log4j2.is.webapp", isClassAvailable("javax.servlet.Servlet"));
/**
* Kill switch for object pooling in ThreadLocals that enables much of the LOG4J2-1270 no-GC behaviour.
* <p>
* {@code True} for non-{@link #IS_WEB_APP web apps}, disable by setting system property
* "log4j2.enable.threadlocals" to "false".
* </p>
*/
public static final boolean ENABLE_THREADLOCALS = !IS_WEB_APP && PropertiesUtil.getProperties().getBooleanProperty(
"log4j2.enable.threadlocals", true);大致意思就是,如果应用不是web应用【判断是否存在javax.servlet.Servlet这个类】,就默认使用threadlocals这种模式,即我本地程序的RingBuffer就被设置成了4096。
注释中也提到,可以设置jvm运行时参数,不使用threadlocals这种模式,可以这么设置:-Dlog4j2.enable.threadlocals=false
-
Garbage-free logging
- 大部分日志框架,包括log4j会在正常日志输出的时候创建临时对象( log event objects, Strings, char arrays, byte arrays...),这会增加GC的压力;
- 从Log4j2.6开始,log4j默认使用Garbage-free这种模式。threadlocals是Garbage-free的其中一种实现,在
ThreadLocal基础上,会重用对象(例如log event objects); - 但是在web应用中,threadlocals这种模式很容易导致
ThreadLocal的内存泄漏,所以在web应用中,不会使用threadlocals模式; -
一些不完全Garbage-free的功能,不依赖
ThreadLocal,会将log events对象转换成text,继而将text直接编码成bytes存入可重用的ByteBuffer,而不需要创建零时的Strings, char arrays and byte arrays等对象。- 上述功能默认开始(
log4j2.enableDirectEncoders默认为true),在多线程环境下,日志性能可能会不太理想,因为在使用共享buffer的时候是同步操作。所以考虑性能的话,建议使用异步日志。
- 上述功能默认开始(
参考:https://logging.apache.org/log4j/2.x/manual/garbagefree.html,Garbage-free Logging
(2)阻塞的核心方法enqueue
主要的阻塞点org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor的enqueue方法
private void enqueue(final LogEvent logEvent, final AsyncLoggerConfig asyncLoggerConfig) {
// 如果synchronizeEnqueueWhenQueueFull为true,进入阻塞方法
if (synchronizeEnqueueWhenQueueFull()) {
synchronized (queueFullEnqueueLock) {
disruptor.getRingBuffer().publishEvent(translator, logEvent, asyncLoggerConfig);
}
} else {
disruptor.getRingBuffer().publishEvent(translator, logEvent, asyncLoggerConfig);
}
}
private boolean synchronizeEnqueueWhenQueueFull() {
return DisruptorUtil.ASYNC_CONFIG_SYNCHRONIZE_ENQUEUE_WHEN_QUEUE_FULL
// Background thread must never block
&& backgroundThreadId != Thread.currentThread().getId();
}DisruptorUtil中关于SYNCHRONIZE_ENQUEUE_WHEN_QUEUE_FULL的两个静态属性:
// 默认都是true
static final boolean ASYNC_LOGGER_SYNCHRONIZE_ENQUEUE_WHEN_QUEUE_FULL = PropertiesUtil.getProperties()
.getBooleanProperty("AsyncLogger.SynchronizeEnqueueWhenQueueFull", true);
static final boolean ASYNC_CONFIG_SYNCHRONIZE_ENQUEUE_WHEN_QUEUE_FULL = PropertiesUtil.getProperties()
.getBooleanProperty("AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull", true);从源码可以看到,默认enqueue方法就是走阻塞的分支代码。如果要设置成非阻塞的运行方式,需要手动配置参数,方法如下:
新建log4j2.component.properties文件,添加如下配置:
【其他可配置参数详见:https://logging.apache.org/log4j/2.x/manual/configuration.html#SystemProperties】
# 适用<root> and <logger>加
# Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector配置的异步日志
# 作用于org.apache.logging.log4j.core.async.AsyncLoggerDisruptor
AsyncLogger.SynchronizeEnqueueWhenQueueFull=false
# 适用<asyncRoot> & <asyncLogger>配置的异步日志
# 作用于org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor
AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull=false-
note:
- 异步日志配置方式不同的话,会使用不同的处理类(
AsyncLoggerConfigDisruptor|AsyncLoggerDisruptor),因此配置参数得相匹配; -
将
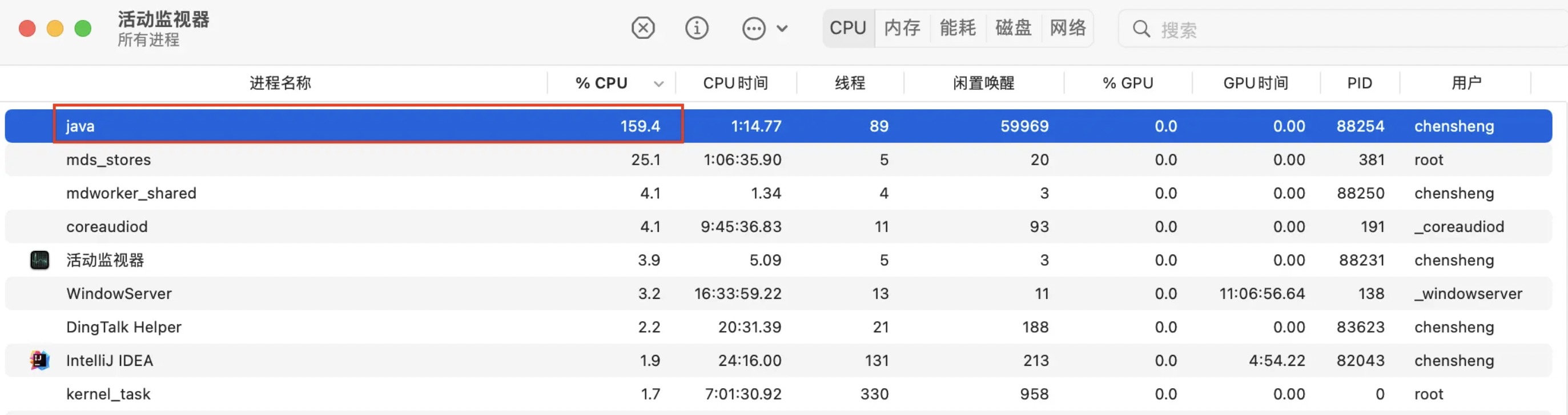
SynchronizeEnqueueWhenQueueFull设置成false,会导致CPU使用率飙升,这个应该也是默认为true的原因。可以看下面本地实验的结果,差不多是10倍的差距。【官方文档中是不建议设置成false的,除非绑定CPU核。】- true时的CPU使用「159%」:
- false时的CPU使用「1565%」:
- true时的CPU使用「159%」:
- 异步日志配置方式不同的话,会使用不同的处理类(

CPU高的主要原因:
在enqueue方法处没有阻塞的情况下,所有的线程都会进入到MultiProducerSequencer的next方法。这个方法是获取RingBuffer的可写区间的,方法中有个while死循环不断的做CAS操作。在LockSupport.parkNanos(1)处原作者这边也给了疑问:要不要沿用WaitStrategy的等待策略。
@Override
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
long current;
long next;
do
{
current = cursor.get();
next = current + n;
long wrapPoint = next - bufferSize;
long cachedGatingSequence = gatingSequenceCache.get();
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
if (wrapPoint > gatingSequence)
{
LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy?
continue;
}
gatingSequenceCache.set(gatingSequence);
}
else if (cursor.compareAndSet(current, next))
{
break;
}
}
while (true);
return next;
}至此,基本还原现场的情况:
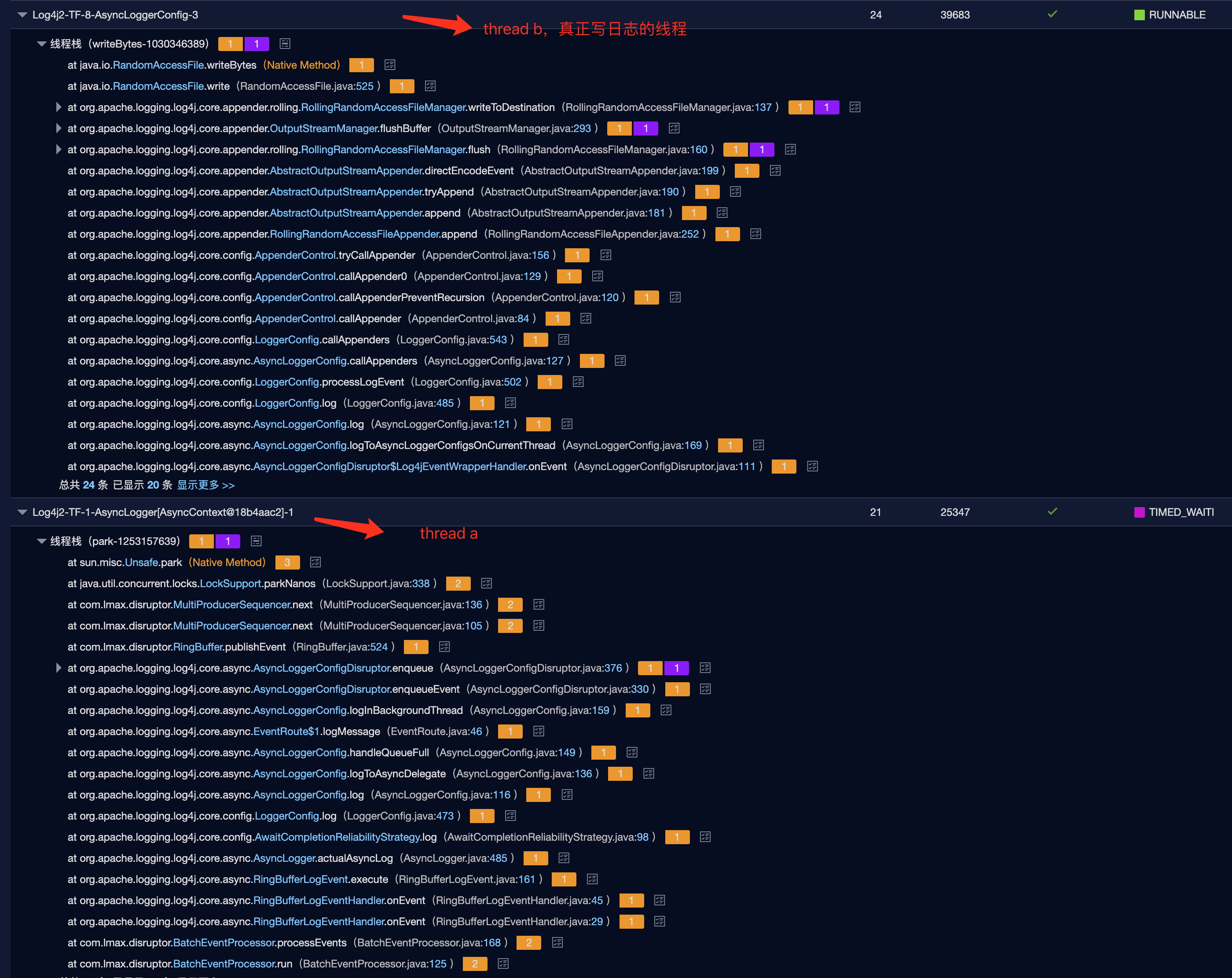
(3)异步日志重复配置的问题
这是个人的好奇之举。当即使用了Log4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector,又在log4j2.xml中配置了<asyncRoot>标签,日志对象将会多一次中间传递:app -> RingBuffer-1 -> thread a -> RingBuffer-2 -> thread b -> disk。
这会带来不必要的性能损耗。
看下这种情况的线程dump就了然了:
(二)日志压缩
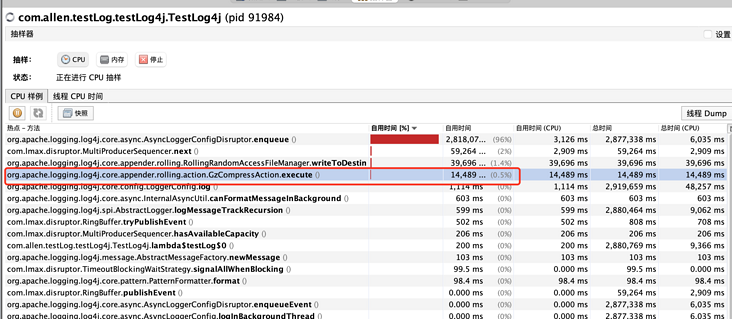
尝试去掉gz后缀名,优化压缩的资源消耗问题。
- 修改前,CPU采样情况,在资源占用前列可以明显看到压缩的相关方法:
- 去掉gz后缀和压缩级别参数,已经找不到压缩相关的方法了:
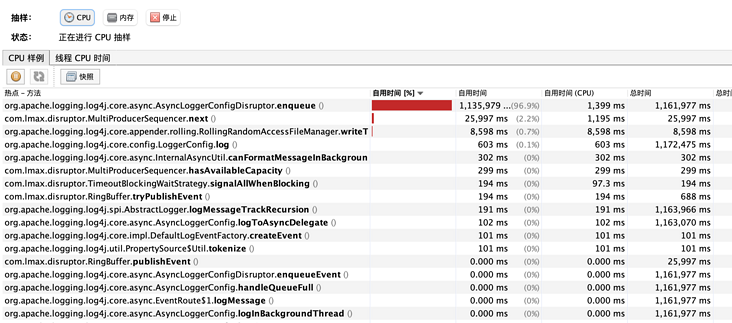
验证了之前的猜想,RollingFile其实就是根据文件后缀来判断是否进行压缩的。
(三)消费线程(IO线程)的WaitStrategy
即log4j2.asyncLoggerWaitStrategy | log4j2.asyncLoggerConfigWaitStrategy 这两配置,主要用来配置等待日志事件的I/O线程的策略。
官方文档中给出了4种策略:Block, Timeout「默认」, Sleep, Yield。
但是源码中其实有5种:
// org.apache.logging.log4j.core.async.DisruptorUtil
static WaitStrategy createWaitStrategy(final String propertyName, final long timeoutMillis) {
final String strategy = PropertiesUtil.getProperties().getStringProperty(propertyName, "TIMEOUT");
LOGGER.trace("property {}={}", propertyName, strategy);
final String strategyUp = strategy.toUpperCase(Locale.ROOT); // TODO Refactor into Strings.toRootUpperCase(String)
switch (strategyUp) { // TODO Define a DisruptorWaitStrategy enum?
case "SLEEP":
return new SleepingWaitStrategy();
case "YIELD":
return new YieldingWaitStrategy();
case "BLOCK":
return new BlockingWaitStrategy();
case "BUSYSPIN":
return new BusySpinWaitStrategy();
case "TIMEOUT":
return new TimeoutBlockingWaitStrategy(timeoutMillis, TimeUnit.MILLISECONDS);
default:
return new TimeoutBlockingWaitStrategy(timeoutMillis, TimeUnit.MILLISECONDS);
}
}多了一个BusySpinWaitStrategy策略「JDK9才真正适用,9以下就是简单的死循环」
这里不一一介绍,主要是disruptor相关的内容「详细内容可以参考这片文章,写的还可以:https://blog.csdn.net/boling_...」,结合log4j2说几点:
- 默认的
TimeoutBlockingWaitStrategy和BlockingWaitStrategy策略都是基于ReentrantLock实现的,由于底层是基于AQS,在运行过程中会创建AQS的Node对象,不符合Garbage-free的思想; SLEEP是Garbage-free的,且官方文档提到,相较于BLOCK适用于资源受限的环境,SLEEP平衡了性能和CPU资源两方面因素。
三、总结
关于log4j2的性能优化,总结以下几点「后面有补充会添加到这里」
1.配置滚动日志的时候,若不需要压缩日志,filePattern的文件名不要以gz结尾;
2.使用Disruptor异步日志的时候,不要同时使用Log4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector和<asyncRoot>;
3.给RollingRandomAccessFile配置immediateFlush="false"属性,这样让I/O线程批量刷盘(这里其实涉及到native方法调用的性能问题);
4.可以结合资源情况是否要配置SynchronizeEnqueueWhenQueueFull为false;
5.结合实际情况是否要更改I/O线程的WaitStrategy;
6.若日志可以丢弃,可以配置丢弃策略,配置log4j2.asyncQueueFullPolicy=Discard,log4j2.discardThreshold=INFO「默认」,当队列满时,INFO, DEBUG和TRACE级别的日志会被丢弃;



