
Java多线程——并发测试原创
编写并发程序时候,可以采取和串行程序相同的编程方式。
唯一的难点在于,并发程序存在不确定性,这种不确定性会令程序出错的地方远比串行程序多,出现的方式也没有固定规则。那么如何在测试中,尽可能的暴露出这些问题,并且了解其性能瓶颈,本篇针对这些问题来做个简要总结。
并发测试分类
测试流程
并发测试和串行测试有相同的部分,比如都需要线测试其在串行情况下的正确性,这个是保证后续测试的基础。
当然了,正确性测试和我们的串行测试方没有什么不同,都是在保证其程序在单线程情况下执行和串行执行有相同的结果,这个我们不再陈述。
一般的并发测试,我们按照以下流程来进行。
分类
并发测试大致可以分为两类:安全性测试与活跃性测试。
安全性测试我们可以定义为“不发生任何错误的行为”,也可以理解为保持一致性。比如i++操作,但单线程情况下,循环20次,i=20,可是在多线程情况下,如果总共循环20次,结果不为20,那么这个结果就是错误的,说明出现了错误的线程安全问题。
我们在测试这种问题的时候,必须要增加一个”test point”保证其原子性同时又不影响程序的正确性。以此为判断条件执行测试代码,关于“test point”如何做,我们后续再讨论。
活跃性测试定义为“某个良好的行为终究会发生”,也可以为理解为程序运行有必然的结果,不会出现因某个方法阻塞,而运行缓慢,或者是发生了线程死锁,导致一直等待的状态等。
与活跃性测试相关的是性能测试。主要有以下几个方面进行衡量:吞吐量,响应性,可伸缩性。
吞吐量:一组并发任务中已完成任务所占的比例。或者说是一定时间内完成任务的数量。
响应性:请求从发出到完成之间的时间。
可伸缩性:在增加更多资源(CPU,IO,内存),吞吐量的提升情况。
安全性测试
安全性测试,如前面所说是“不发生任何错误的行为”,也是要对其数据竞争可能引发的错误进行测试。这也是我们需要找到一个功能中并发的的“test point”,并对其额外的构造一些测试。而且这些测试最好不需要任何同步机制。
我们通过一个例子来进行说明。
采用ArrayBlockingQueue,我们知道这个列表是采用一个有界的阻塞队列来实现的生产-消费模式的。如果对其测试并发问题的,重要的就是对put和take方法进行测试,一种有效的方法就是检查被放入队列中和出队列中的各个元素是否相等。
如果出现数据安全性的问题,那么必然入队列的值和出队列的值没有发生对应,结果也不尽相同。比如多线程情况下,我们把所有入列元素和出列元素的校检和进行比较,如果二者相等,那么表明测试成功。
为了保证其能够测试到所有要点,需要对入队的值进行随机生成,令每次测试得到的结果不尽相同。另外为了保证其公平性,要保证所有的线程一起开始运算,防止先进行的程序进行串行运算。
public class PutTakeTest {
protected static final ExecutorService pool = Executors.newCachedThreadPool();
//栅栏,通过它可以实现让一组线程等待至某个状态之后再全部同时执行
protected CyclicBarrier barrier;
protected final ArrayBlockingQueue<Integer> bb;
protected final int nTrials, nPairs;
//入列总和
protected final AtomicInteger putSum = new AtomicInteger(0);
//出列总和
protected final AtomicInteger takeSum = new AtomicInteger(0);
public static void main(String[] args) throws Exception {
new PutTakeTest(10, 10, 100000).test(); // 10个承载因子,10个线程,运行100000
pool.shutdown();
}
public PutTakeTest(int capacity, int npairs, int ntrials) {
this.bb = new ArrayBlockingQueue<Integer>(capacity);
this.nTrials = ntrials;
this.nPairs = npairs;
this.barrier = new CyclicBarrier(npairs * 2 + 1);
}
void test() {
try {
for (int i = 0; i < nPairs; i++) {
pool.execute(new Producer());
pool.execute(new Consumer());
}
barrier.await(); // 等待所有的线程就绪
barrier.await(); // 等待所有的线程执行完成
System.out.println("result,put==take :"+(putSum.get()==takeSum.get()));
} catch (Exception e) {
throw new RuntimeException(e);
}
}
static int xorShift(int y) {
y ^= (y << 6);
y ^= (y >>> 21);
y ^= (y << 7);
return y;
}
//生产者
class Producer implements Runnable {
public void run() {
try {
int seed = (this.hashCode() ^ (int) System.nanoTime());
int sum = 0;
barrier.await();
for (int i = nTrials; i > 0; --i) {
bb.put(seed);
sum += seed;
seed = xorShift(seed);
}
putSum.getAndAdd(sum);
barrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
//消费者
class Consumer implements Runnable {
public void run() {
try {
barrier.await();
int sum = 0;
for (int i = nTrials; i > 0; --i) {
sum += bb.take();
}
takeSum.getAndAdd(sum);
barrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
}
以上程序中,我们增加putSum和takeSum变量,用来统计put和take数据的校检和。同时采用CyclicBarrier(回环栅栏)令所有的线程同一时间从相同的位置开始执行。每个线程的入列数据,为了保证其唯一性,都生成一个唯一的seed,在下列代码执行出,必然是多线程竞争的地方。
for (int i = nTrials; i > 0; --i) {
bb.put(seed);
sum += seed;
seed = xorShift(seed);
}
如果此处出现线程安全问题,那么最终take出来的数据和put的数据必然是不相同的,最终putSum和takeSum的值必然不同,相反则相同。
由于并发代码中大多数错误都是一些低概率的事件,因此在测试的时候,还是需要反复测试多次,以提高发现错误的概率。
性能测试
性能测试通常是功能测试的延伸。虽然性能测试与功能测试之间会有重叠之处,但它们的目标是不同的。
首先性能测试需要反映出被测试对象在应用程序中的实际用法以及它的吞吐量。另外需要根据经验值来调整各种不同的限值,比如线程数,并发数等,从而令程序更好的在系统上运行。
我们对上述的PutTakeTest进行扩展,增加以下功能:
1、为了保证时间精确性,增加一个运行一组操作的运行时间。
采用BarrierTimer来维护单组运行时间,它implements Runnable,在计数达到栅栏(CyclicBarrier)一组的数量之后,会调用一次该回调,设置结束时间。
我们用它来记录,一组的总时间。有总时间了,单次操作的时间就可以计算出来了。如此我们就可以计算出单个测试的吞吐量。
吞吐量=1ms/单次操作的时间=每秒可以执行的次数。
以下是基于栅栏的计时器。
public class BarrierTimer implements Runnable{
private boolean started;
private long startTime, endTime;
public synchronized void run() {
long t = System.nanoTime();
if (!started) {
started = true;
startTime = t;
} else
endTime = t;
}
public synchronized void clear() {
started = false;
}
public synchronized long getTime() {
return endTime - startTime;
}
}
2、性能测试需要针对不同参数组合进行测试。
通过不同参数来进行组合测试,以此来获得在不同参数下的吞吐率,以及不同线程数量下的可伸缩性。在putTakeTest里面,我们只只针对安全性测试。
我们看加强版本的TimedPutTakeTest,这里我们把ArrayBlockingQueue的容量分别设置为1、10、100、1000,令其在线程数量分别为1、2、4、8、16、32、64、128的情况下,看其链表的吞吐率。
public static void main(String[] args) throws Exception {
int tpt = 100000; // trials per thread
for (int cap = 1; cap <= 1000; cap *= 10) {
System.out.println("Capacity: " + cap);
for (int pairs = 1; pairs <= 128; pairs *= 2) {
TimedPutTakeTest t = new TimedPutTakeTest(cap, pairs, tpt);
System.out.print("Pairs: " + pairs + "\t");
t.test();
System.out.print("\t");
Thread.sleep(1000);
t.test();
System.out.println();
Thread.sleep(1000);
}
}
PutTakeTest.pool.shutdown();
}
以下是我们针对ArrayBlockingQueue的性能测试结果,我的电脑硬件环境是:
CPU: i7 4核8线程
memory: 16G
硬盘: SSD110G
jdk 环境
java version “1.8.0_45"
Java HotSpot™ 64-Bit Server VM (build 25.45-b02, mixed mode)
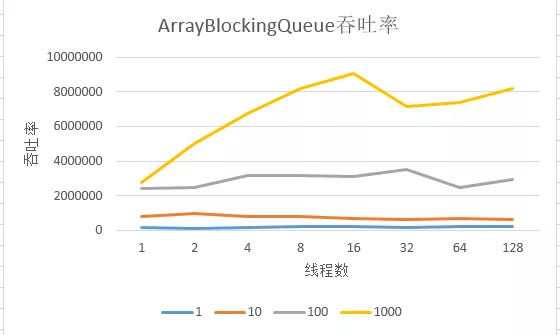
从上面可以看到以下几点情况
-
在ArrayBlockingQueue的缓存容量在1的情况下,无论线性并发数为多少,都不能显著的提升其吞吐率。这是因为每个线程在阻塞等待另外线程执行任务。
-
当尝试把缓存容量提升至10、100、1000的时候,吞吐率都得到了极大的提高,特别是在1000的时候,最高可达到900w次/s。
-
当线程增加到16个的时候,吞吐率会达到顶峰,然后再增加线程吞吐率不生反而下降,当然没有很大的下降,这是因为,当线程增多的时候,大部分时间耗费在阻塞和解除阻塞上面了。
其他阻塞队列的比较
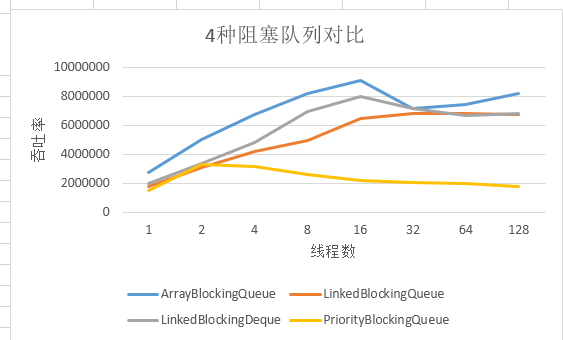
以下是针对ArrayBlockingQueue、LinkedBlockingQueue、LinkedBlockingDeQue、PriorityBlockingQueue几种阻塞队列进行的横向测评。硬件环境还是和上述相同。jdk还是采用1.8的API。
每个队列的缓存容量是1000。然后分别在1、2、4、8、16、32、64、128的线程并发下,查看其吞吐率。
从上述数据中,我们可以看到:
-
ArrayBlockingQueue在jdk1.8的优化下性能高于LinkedBlockingQueue,虽然两者差别不是太大,这个是1.6之前,LinkedBlockingQueue是要优于ArrayBlockingQueue的。
-
PriorityBlockingQueue在达到290w的吞吐高峰之后,性能开始持续的下降,这是因为优先队列需要不断的优化优先列表,而需要一定的排序时间。
以上测试的主要目的是,测试生产者和消费者在通过有界put和take传送数据时,那些约束条件将对整个吞吐量产生影响。所以会忽略了许多实际的因素。另外由于jit的动态编译,会直接将编译后的代码直接编译为机器代码。
所以以上测试需要经过预热处理,运行更多的次数,以保证所有的代码都是编译完成之后,才统计测试的运行时间。
最后
测试并发程序的正确性可能会特别困难的,因为并发程序的许多故障都是一些低概率的事情,并且它们对执行时序、负载情况以及其他难以重现的条件比较敏感。
要想尽可能的发现这些错误,就需要我们做更多的工作来进行分析测试,期待今天的介绍能够帮助大家开阔一些思路。
本文作者:大码侯
关注个人成长和游戏研发,致力于推进国内游戏技术社区的进步。



