
近期业务大量突增微服务性能优化总结-4.增加对于同步微服务的 HTTP 请求等待队列的监控原创
最近,业务增长的很迅猛,对于我们后台这块也是一个不小的挑战,这次遇到的核心业务接口的性能瓶颈,并不是单独的一个问题导致的,而是几个问题揉在一起:我们解决一个之后,发上线,之后发现还有另一个的性能瓶颈问题。这也是我经验不足,导致没能一下子定位解决;而我又对我们后台整个团队有着固执的自尊,不想通过大量水平扩容这种方式挺过压力高峰,导致线上连续几晚都出现了不同程度的问题,肯定对于我们的业务增长是有影响的。这也是我不成熟和要反思的地方。这系列文章主要记录下我们针对这次业务增长,对于我们后台微服务系统做的通用技术优化,针对业务流程和缓存的优化由于只适用于我们的业务,这里就不再赘述了。本系列会分为如下几篇:
1.改进客户端负载均衡算法
2.开发日志输出异常堆栈的过滤插件
3.针对 x86 云环境改进异步日志等待策略
4.增加对于同步微服务的 HTTP 请求等待队列的监控以及云上部署,需要小心达到实例网络流量上限导致的请求响应缓慢
5.针对系统关键业务增加必要的侵入式监控
增加对于同步微服务的 HTTP 请求等待队列的监控
相对于基于 spring-webflux 的异步微服务,基于 spring-webmvc 的同步微服务没有很好的处理客户端有请求超时配置的情况。当客户端请求超时时,客户端会直接返回超时异常,但是调用的服务端任务,在基于 spring-webmvc 的同步微服务并没有被取消,基于 spring-webflux 的异步微服务是会被取消的。目前,还没有很好的办法在同步环境中可以取消这些已经超时的任务。
我们的基于 spring-webmvc 的同步微服务,HTTP 容器使用的是 Undertow。在 spring-boot 环境下,我们可以配置处理 HTTP 请求的线程池大小:
server:
undertow:
# 以下的配置会影响buffer,这些buffer会用于服务器连接的IO操作
# 如果每次需要 ByteBuffer 的时候都去申请,对于堆内存的 ByteBuffer 需要走 JVM 内存分配流程(TLAB -> 堆),对于直接内存则需要走系统调用,这样效率是很低下的。
# 所以,一般都会引入内存池。在这里就是 `BufferPool`。
# 目前,UnderTow 中只有一种 `DefaultByteBufferPool`,其他的实现目前没有用。
# 这个 DefaultByteBufferPool 相对于 netty 的 ByteBufArena 来说,非常简单,类似于 JVM TLAB 的机制
# 对于 bufferSize,最好和你系统的 TCP Socket Buffer 配置一样
# `/proc/sys/net/ipv4/tcp_rmem` (对于读取)
# `/proc/sys/net/ipv4/tcp_wmem` (对于写入)
# 在内存大于 128 MB 时,bufferSize 为 16 KB 减去 20 字节,这 20 字节用于协议头
buffer-size: 16364
# 是否分配的直接内存(NIO直接分配的堆外内存),这里开启,所以java启动参数需要配置下直接内存大小,减少不必要的GC
# 在内存大于 128 MB 时,默认就是使用直接内存的
directBuffers: true
threads:
# 设置IO线程数, 它主要执行非阻塞的任务,它们会负责多个连接, 默认设置每个CPU核心一个读线程和一个写线程
io: 4
# 阻塞任务线程池, 当执行类似servlet请求阻塞IO操作, undertow会从这个线程池中取得线程
# 它的值设置取决于系统线程执行任务的阻塞系数,默认值是IO线程数*8
worker: 128
其背后的线程池,是 jboss 的线程池:org.jboss.threads.EnhancedQueueExecutor,spring-boot 目前不能通过配置修改这个线程池的队列大小,默认队列大小是 Integer.MAX
我们需要监控这个线程池的队列大小,并针对这个指标做一些操作:
- 当这个任务持续增多的时候,就代表这时候请求处理跟不上请求到来的速率了,需要报警。
- 当累积到一定数量时,需要将这个实例暂时从注册中心取下,并扩容。
- 待这个队列消费完之后,重新上线。
- 当超过一定时间还是没有消费完的话,将这个实例重启。
添加同步微服务 HTTP 请求等待队列监控
幸运的是,org.jboss.threads.EnhancedQueueExecutor 本身通过 JMX 暴露了 HTTP servlet 请求的线程池的各项指标:
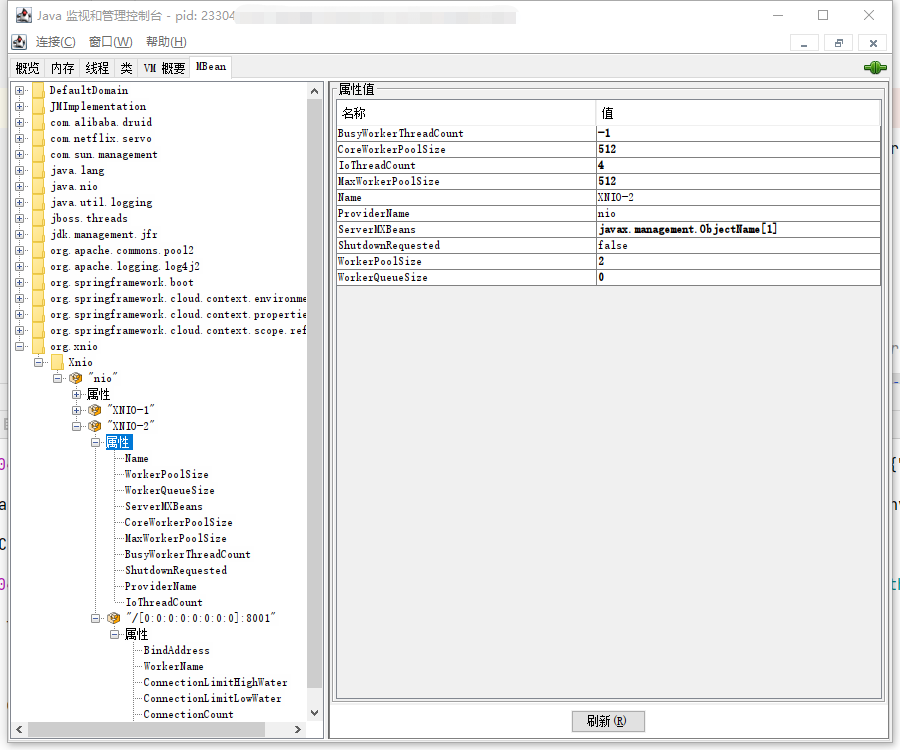
我们的项目中,使用两种监控:
- prometheus + grafana 微服务指标监控,这个主要用于报警以及快速定位问题根源
- JFR 监控,这个主要用于详细定位单实例问题
对于 HTTP 请求等待队列监控,我们应该通过 prometheus 接口向 grafana 暴露,采集指标并完善响应操作。
暴露 prometheus 接口指标的代码是:
@Log4j2
@Configuration(proxyBeanMethods = false)
//需要在引入了 prometheus 并且 actuator 暴露了 prometheus 端口的情况下才加载
@ConditionalOnEnabledMetricsExport("prometheus")
public class UndertowXNIOConfiguration {
@Autowired
private ObjectProvider<PrometheusMeterRegistry> meterRegistry;
//只初始化一次
private volatile boolean isInitialized = false;
//需要在 ApplicationContext 刷新之后进行注册
//在加载 ApplicationContext 之前,日志配置就已经初始化好了
//但是 prometheus 的相关 Bean 加载比较复杂,并且随着版本更迭改动比较多,所以就直接偷懒,在整个 ApplicationContext 刷新之后再注册
// ApplicationContext 可能 refresh 多次,例如调用 /actuator/refresh,还有就是多 ApplicationContext 的场景
// 这里为了简单,通过一个简单的 isInitialized 判断是否是第一次初始化,保证只初始化一次
@EventListener(ContextRefreshedEvent.class)
public synchronized void init() {
if (!isInitialized) {
Gauge.builder("http_servlet_queue_size", () ->
{
try {
return (Integer) ManagementFactory.getPlatformMBeanServer()
.getAttribute(new ObjectName("org.xnio:type=Xnio,provider=\"nio\",worker=\"XNIO-2\""), "WorkerQueueSize");
} catch (Exception e) {
log.error("get http_servlet_queue_size error", e);
}
return -1;
}).register(meterRegistry.getIfAvailable());
isInitialized = true;
}
}
}
之后,调用 /actuator/prometheus 我们就能看到对应的指标:
# HELP http_servlet_queue_size
# TYPE http_servlet_queue_size gauge
http_servlet_queue_size 0.0
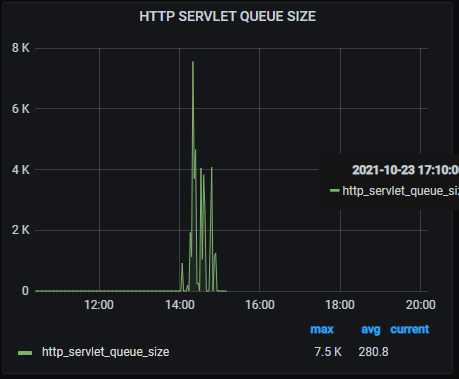
当发生队列堆积时,我们能快速的报警,并且直观地从 grafana 监控上发现:
对于公有云部署,关注网络限制的监控
现在的公有云,都会针对物理机资源进行虚拟化,对于网络网卡资源,也是会虚拟化的。以 AWS 为例,其网络资源的虚拟化实现即 ENA(Elastic Network Adapter)。它会对以下几个指标进行监控并限制:
-
带宽:每个虚拟机实例(AWS 中为每个 EC2 实例),都具有流量出的最大带宽以及流量入的最大带宽。这个统计使用一种网络 I/O 积分机制,根据平均带宽使用率分配网络带宽,最后的效果是允许短时间内超过额定带宽,但是不能持续超过。
-
每秒数据包 (PPS,Packet Per Second) 个数:每个虚拟机实例(AWS 中为每个 EC2 实例)都限制 PPS 大小
-
连接数:建立连接的个数是有限的
-
链接本地服务访问流量:一般在公有云,每个虚拟机实例 (AWS 中为每个 EC2 实例)访问 DNS,元数据服务器等,都会限制流量
同时,成熟的公有云,这些指标一般都会对用户提供展示分析界面,例如 AWS 的 CloudWatch 中,就提供了以下几个指标的监控:
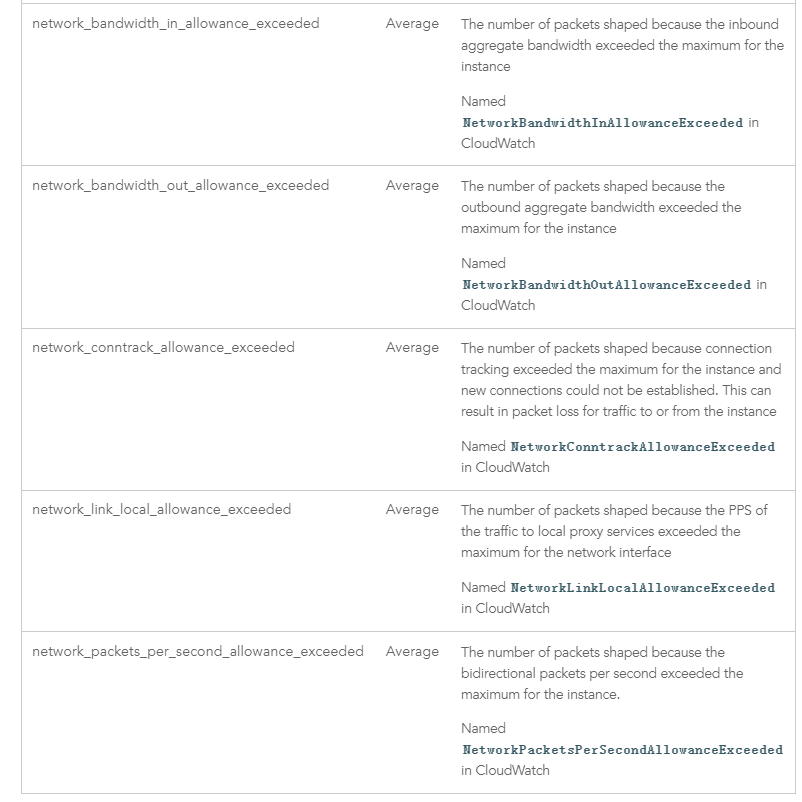
在业务流量突增时,我们通过 JFR 发现访问 Redis 有性能瓶颈,但是 Redis 本身的监控显示他并没有遇到性能瓶颈。这时候就需要查看是否因为网络流量限制导致其除了问题,在我们出问题的时间段,我们发现 NetworkBandwidthOutAllowanceExceeded 事件显著提高了很多:

对于这种问题,就得需要考虑垂直扩容(提升实例配置)与水平扩容(多实例负载均衡)了,或者减少网络流量(增加压缩等)



