
近期业务大量突增微服务性能优化总结-3.针对 x86 云环境改进异步日志等待策略原创
最近,业务增长的很迅猛,对于我们后台这块也是一个不小的挑战,这次遇到的核心业务接口的性能瓶颈,并不是单独的一个问题导致的,而是几个问题揉在一起:我们解决一个之后,发上线,之后发现还有另一个的性能瓶颈问题。这也是我经验不足,导致没能一下子定位解决;而我又对我们后台整个团队有着固执的自尊,不想通过大量水平扩容这种方式挺过压力高峰,导致线上连续几晚都出现了不同程度的问题,肯定对于我们的业务增长是有影响的。这也是我不成熟和要反思的地方。这系列文章主要记录下我们针对这次业务增长,对于我们后台微服务系统做的通用技术优化,针对业务流程和缓存的优化由于只适用于我们的业务,这里就不再赘述了。本系列会分为如下几篇:
1.改进客户端负载均衡算法
2.开发日志输出异常堆栈的过滤插件
3.针对 x86 云环境改进异步日志等待策略
4.增加对于同步微服务的 HTTP 请求等待队列的监控以及云上部署,需要小心达到实例网络流量上限导致的请求响应缓慢
5.针对系统关键业务增加必要的侵入式监控
针对 x86 云环境改进异步日志等待策略
由于线上业务量级比较大(日请求上亿,日活用户几十万),同时业务涉及逻辑很复杂,线上日志级别我们采用的是 info 级别,导致线上日志量非常庞大,所以我们很早就使用了 Log4j2 异步日志。Log4j2 异步日志基于 Disruptor,其中的等待策略,本次优化前,我们选用的是 BLOCK。
Log4j2 异步日志的等待策略
Disruptor 的消费者做的事情其实就是不断检查是否有消息到来,其实就是某个状态位是否就绪,就绪后读取消息进行消费。至于如何不断检查,这个就是等待策略。Disruptor 中有很多等待策略,熟悉多处理器编程的对于等待策略肯定不会陌生,在这里可以简单理解为当任务没有到来时,线程应该如何等待并且让出 CPU 资源才能在任务到来时尽量快的开始工作。在 Log4j2 中,异步日志基于 Disruptor,同时使用 AsyncLoggerConfig.WaitStrategy 这个环境变量对于 Disruptor 的等待策略进行配置,目前最新版本的 Log4j2 中可以配置:
switch (strategyUp) {
case "SLEEP":
final long sleepTimeNs =
parseAdditionalLongProperty(propertyName, "SleepTimeNs", 100L);
final String key = getFullPropertyKey(propertyName, "Retries");
final int retries =
PropertiesUtil.getProperties().getIntegerProperty(key, 200);
return new SleepingWaitStrategy(retries, sleepTimeNs);
case "YIELD":
return new YieldingWaitStrategy();
case "BLOCK":
return new BlockingWaitStrategy();
case "BUSYSPIN":
return new BusySpinWaitStrategy();
case "TIMEOUT":
return new TimeoutBlockingWaitStrategy(timeoutMillis, TimeUnit.MILLISECONDS);
default:
return new TimeoutBlockingWaitStrategy(timeoutMillis, TimeUnit.MILLISECONDS);
}
本来,我们使用的是基于 Wait/Notify 的 BlockingWaitStrategy。但是这种策略导致业务量突增的时候,日志写入线程在一段时间内一直未能被唤醒,导致 RingBuffer 中积压了很多日志事件。
为何日志写入线程未能被唤醒
首先简单说一下一些硬件基础。CPU 不是直接从内存中读取数据,中间有好几层 CPU 缓存。当前大多是多 CPU 架构,单机中使用 MESI 缓存一致性协议,当一个处理器访问另一个处理器已经装载入高速缓存的主存地址的时候,就会发生共享(sharing,或者称为争用 contention)。需要考虑缓存一致性的问题,因为如果一个处理器要更新共享的缓存行,则另一个处理器的副本需要作废以免读取到过期的值。
MESI 缓存一致性协议,缓存行存在以下四种状态:
- Modified:缓存行被修改,最终一定会被写回入主存,在此之前其他处理器不能再缓存这个缓存行。
- Exclusive:缓存行还未被修改,但是其他的处理器不能将这个缓存行载入缓存
- Shared:缓存行未被修改,其他处理器可以加载这个缓存行到缓存
- Invalid:缓存行中没有有意义的数据
举例:假设处理器和主存由总线连接,如图所示:
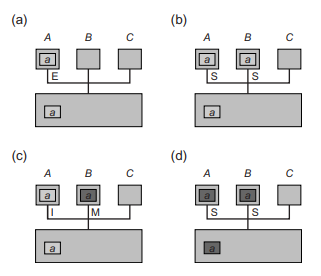
a) 处理器 A 从地址 a 读取数据,将数据存入他的高速缓存并置为 Exclusive
b) 处理器 B 从地址 a 读取数据,处理器 A 检测到地址冲突,响应缓存中 a 地址的数据,之后, 地址 a 的数据被 A 和 B 以 Shared 状态装入缓存
c) 处理器 B 对于 a 进行写操作,状态修改为 Modified,并广播提醒 A(所有其他已经将该数据装入缓存的处理器),状态置为 Invalid。
d) 随后 A 还需要访问 a,它会广播这个请求,B 将修改过的数据发到 A 和主存上,并且置两个副本状态为 Shared。
然后我们来看 Log4j2 异步日志的原理:Log4j2 异步日志基于高性能数据结构 Disruptor,Disruptor 是一个环形 buffer,做了很多性能优化(具体原理可以参考我的另一系列:高并发数据结构(disruptor)),Log4j2 对此的应用如下所示:
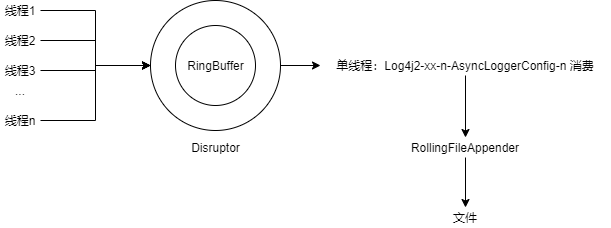
在消费端,只有一个单线程进行消费。当没有日志到来时,线程需要等待,如何等待就是上面提到的等待策略。那么如何判断就绪呢?其实这个线程就是不断的检查一个状态位是否就绪,这里就是检查 RingBuffer 的生产 offset 是否大于当前消费到的值,如果大于则代表有新消息需要消费。对于这种不断检查一个状态位的代码,被称为 spin-wait loop。
那么为何业务高峰的时候,这个单线程唤醒的慢呢?主要原因是,业务量突增时,通常伴随着大量远大于 CPU 数量的线程进入 Runnable 状态,同时伴随着大量的 CPU 计算以及缓存行更新和失效,这会引起很大的总线流量,导致 Notify 信号被日志消费单线程感知受到影响的同时,日志消费单线程进入 Runnable 同时占有 CPU 资源进行运行也会受到影响。在这期间,可能活跃的业务线程占用较久的 CPU 时间,导致生产了很多日志事件进入 RingBuffer。
改用 SleepingWaitStrategy
我们这里改用其中策略最为均衡的 SleepingWaitStrategy。在当前的大多数应用中,线程的个数都远大于 CPU 的个数,甚至是 RUNNABLE 的线程个数都远大于 CPU 个数,使用基于 Wait 的 BusySpinWaitStrategy 会导致业务闲时突然来业务高峰的时候,日志消费线程唤醒的不够及时(CPU 一直被大量的 RUNNABLE 业务线程抢占)。如果使用比较激进的 BusySpinWaitStrategy(一直调用 Thread.onSpinWait())或者 YieldingWaitStrategy(先 SPIN 之后一直调用 Thread.yield()),则闲时也会有较高的 CPU 占用。我们期望的是一种递进的等待策略,例如:
1.在一定次数内,不断 SPIN,应对日志量特别多的时候,减少线程切换消耗。
2.在超过一定次数之后,开始不断的调用 Thread.onSpinWait() 或者 Thread.yield(),使当前线程让出 CPU 资源,应对间断性的日志高峰。
3.在第二步达到一定次数后,使用 Wait,或者 Thread.sleep() 这样的函数阻塞当前线程,应对日志低峰的时候,减少 CPU 消耗。
SleepingWaitStrategy 就是这样一个策略,第二步采用的是 Thread.yield(),第三步采用的是 Thread.sleep()。
public final class SleepingWaitStrategy implements WaitStrategy
{
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException
{
long availableSequence;
int counter = retries;
while ((availableSequence = dependentSequence.get()) < sequence)
{
counter = applyWaitMethod(barrier, counter);
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking()
{
}
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException
{
barrier.checkAlert();
//大于 100 的时候,spin
//默认 counter 从 200 开始
if (counter > 100)
{
--counter;
}
//在 0~ 100 之间
else if (counter > 0)
{
--counter;
Thread.yield();
}
//最后,使用 sleep
else
{
LockSupport.parkNanos(sleepTimeNs);
}
return counter;
}
}
将其中的 Thread.yield 改为 Thread.onSpinWait
我们发现,使用 SleepingWaitStrategy 之后,通过我们自定义的 JFR 事件发现,在业务低峰到业务突增的时候,线程总是在 Thread.yield() 的时候有日志事件到来。但是每次线程执行 Thread.yield() 的时间间隔还是有点长,并且有日志事件到来了但是还是能观察到再过几个 Thread.yield() 之后,线程才发现有日志过来的情况。
所以,我们修改其中的 Thread.yield() 为 Thread.onSpinWait(),原因是:我们部署到的环境是 x86 的机器,在 x86 的环境下 Thread.onSpinWait() 在被调用一定次数后,C1 编译器就会将其替换成使用 PAUSE 这个 x86 指令实现。参考 JVM 源码:
x86.ad
instruct onspinwait() %{
match(OnSpinWait);
ins_cost(200);
format %{
$$template
$$emit$$"pause\t! membar_onspinwait"
%}
ins_encode %{
__ pause();
%}
ins_pipe(pipe_slow);
%}
我们知道,CPU 并不会总直接操作内存,而是以缓存行读取后,缓存在 CPU 高速缓存上。但是对于这种不断检查检查某个状态位是否就绪的代码,不断读取 CPU 高速缓存,会在当前 CPU 从总线收到这个 CPU 高速缓存已经失效之前,都认为这个状态为没有变化。在业务忙时,总线可能非常繁忙,导致 SleepingWaitStrategy 的第二步一直检查不到状态位的更新导致进入第三步。
PAUSE 指令(参考:www.felixcloutier.com/x86/pause)是针对这种等待策略实现而产生的一个特殊指令,这样的话,然后 CPU 分支预测就会据这个提示而避开内存序列冲突,CPU 就不会将这块读取的内存进行缓存,也就是说对 spin-wait loop 不做缓存,不做指令重新排序等动作。从而提高 spin-wait loop 的执行效率。
这个指令使得针对 spin-wait loop 这种场景,Thread.onSpinWait()的效率要比 Thread.yield() 的效率要高。所以,我们修改 SleepingWaitStrategy 的 Thread.yield() 为 Thread.onSpinWait()。



