
在被线上大量日志输出导致性能瓶颈毒打了很多次之后总结出的经验原创
由于线上业务量级比较大(日请求上亿,日活用户几十万),同时业务涉及逻辑很复杂,线上日志级别我们采用的是 info 级别,导致线上日志量非常庞大,经常遇到因为日志写入太慢导致的性能瓶颈(各微服务每小时日志量加在一起约小 1000G)。下面将我们做的日志性能提升与精简日志的规范列出,供大家参考。我们使用的日志框架是 Log4j2
1. 使用 Log4j2 异步日志
首先,推荐日志量大的时候,采用异步日志进行日志输出。好处是在 RingBuffer 满之前,调用日志 api 打印日志的时候不会阻塞。坏处是增加日志丢失的可能性,例如在进程异常退出的时候(例如 kill -9),在 RingBuffer 中的还没输出到文件的日志事件就会丢失。
这里简单说一下 Log4j2 异步日志的原理:Log4j2 异步日志基于高性能数据结构 Disruptor,Disruptor 是一个环形 buffer,做了很多性能优化(具体原理可以参考我的另一系列:高并发数据结构(disruptor)),Log4j2 对此的应用如下所示:
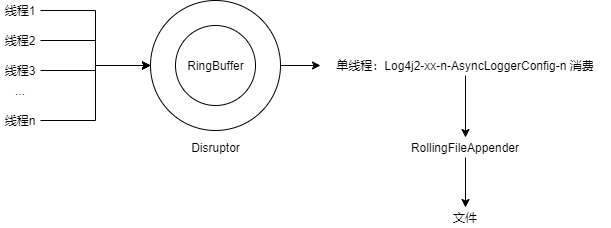
简单来说,多线程通过 log4j2 的门面类 org.apache.logging.log4j.Logger 进行日志输出,被封装成为一个 org.apache.logging.log4j.core.LogEvent,放入到 Disruptor 的环形 buffer 中。在消费端有一个单线程消费这些 LogEvent 写入对应的 Appender,假设我们这里只有一个 Appender,其配置是将所有日志输出到一个文件:
<RollingFile name="file" append="true"
filePattern="./app.log-%d{yyyy.MM.dd.HH}" immediateFlush="false">
<PatternLayout pattern="${logFormat}"/>
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true"/>
</Policies>
<DirectWriteRolloverStrategy maxFiles="72"/>
</RollingFile>
异步日志 logger 配置为(配置 includeLocation 为 false,避免每次打印日志需要获取调用堆栈的性能损耗,这个我们后面会提到),这里的日志级别是 info:
<Asyncroot level="info" includeLocation="false">
<appender-ref ref="file"/>
</Asyncroot>
log4j component 额外配置为:
log4j2.component.properties:
# 当没有日志的时候,打印日志的单线程通过 SLEEP 等待日志事件到来。这样 CPU 占用较少的同时,也能在日志到来时唤醒打印日志的单线程延迟较低,这个后面会详细分析
# 我们还进一步将其中的 Thread.yield() 修改为了 Thread.spinWait()
AsyncLoggerConfig.WaitStrategy=SLEEP
2. 关闭 includeLocation,在日志内容中加入标志位置的标记
日志中我们可能会需要输出当前输出的日志对应代码中的哪一类的哪一方法的哪一行,这个需要在运行时获取堆栈。获取堆栈,无论是在 Java 9 之前通过 Thorwable.getStackTrace(),还是通过 Java 9 之后的 StackWalker,获取当前代码堆栈,都是一个非常消耗 CPU 性能的操作。在大量输出日志的时候,会成为严重的性能瓶颈,其原因是:
1.获取堆栈属于从 Java 代码运行,切换到 JVM 代码运行,是 JNI 调用。这个切换是有性能损耗的。
2.Java 9 之前通过新建异常获取堆栈,Java 9 之后通过 Stackwalker 获取。这两种方式,截止目前 Java 17 版本,都在高并发情况下,有严重的性能问题,会吃掉大量 CPU。主要是底层 JVM 符号与常量池优化的问题。
所以,我们在日志中不打印所在类方法。但是可以自己在日志中添加类名方法名用于快速定位问题代码。一般 IDE 中会有这种模本辅助,例如我在 IDEA 中就自定义了这个快捷模板:
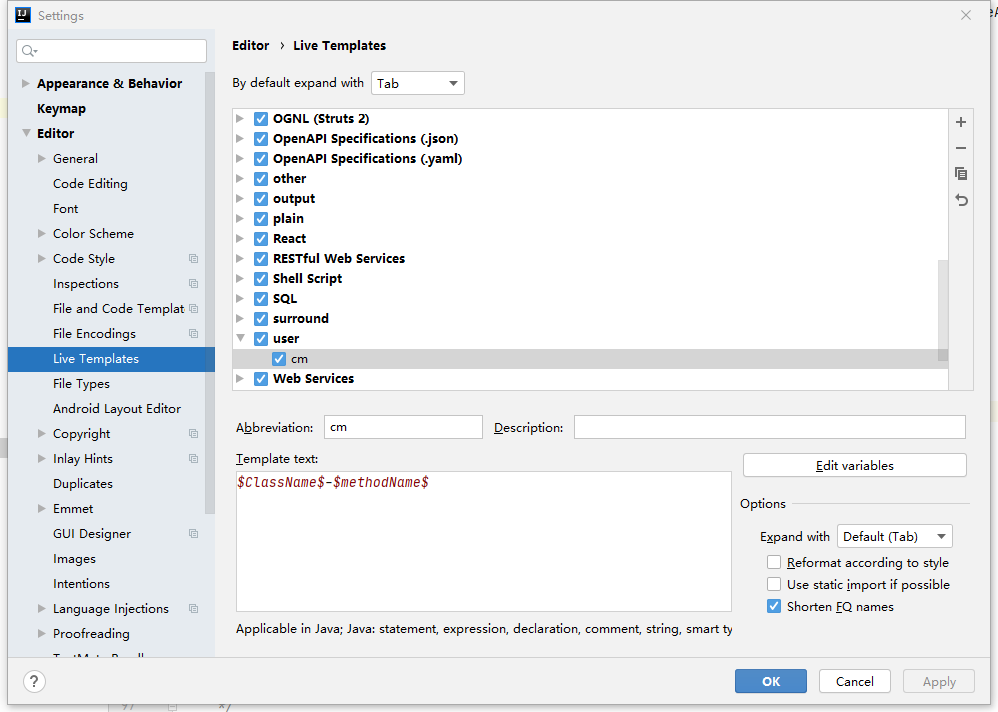
快捷键 cm 之后按 tab 就会变成 类名-方法名 的字符串。
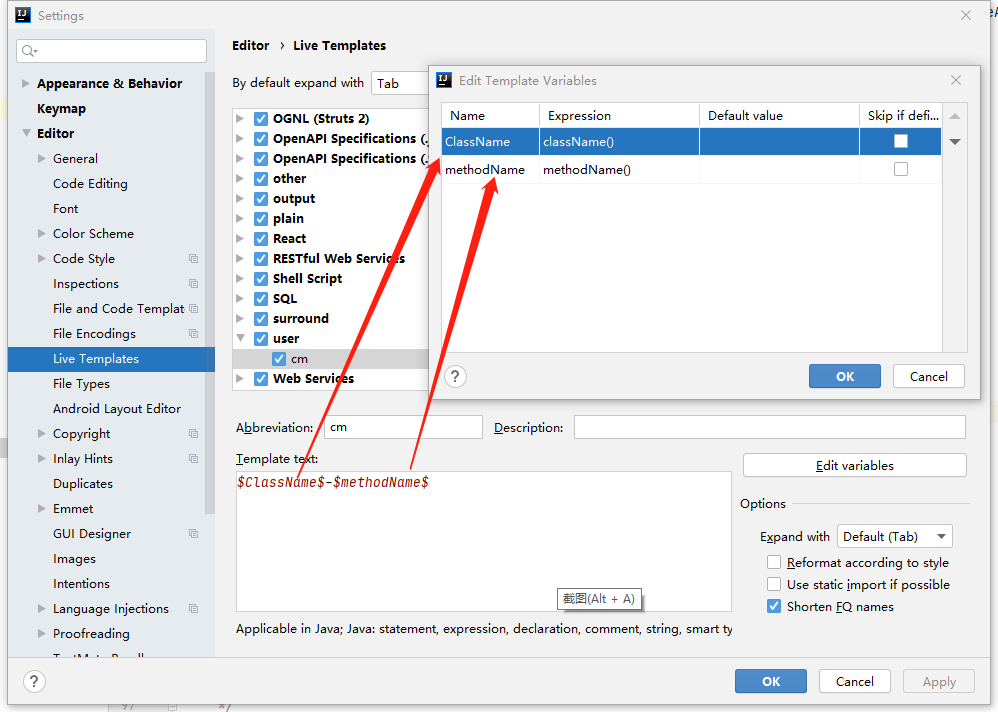
3. 配置 Disruptor 的等待策略为 SLEEP,但是最好能将其中的 Thread.yield 修改为 Thread.onSpinWait (这个修改仅针对 x86 机器部署)
Disruptor 的消费者做的事情其实就是不断检查是否有消息到来,其实就是某个状态位是否就绪,就绪后读取消息进行消费。至于如何不断检查,这个就是等待策略。Disruptor 中有很多等待策略,熟悉多处理器编程的对于等待策略肯定不会陌生,在这里可以简单理解为当任务没有到来时,线程应该如何等待并且让出 CPU 资源才能在任务到来时尽量快的开始工作。在 Log4j2 中,异步日志基于 Disruptor,同时使用 AsyncLoggerConfig.WaitStrategy 这个环境变量对于 Disruptor 的等待策略进行配置,目前最新版本的 Log4j2 中可以配置:
switch (strategyUp) {
case "SLEEP":
final long sleepTimeNs =
parseAdditionalLongProperty(propertyName, "SleepTimeNs", 100L);
final String key = getFullPropertyKey(propertyName, "Retries");
final int retries =
PropertiesUtil.getProperties().getIntegerProperty(key, 200);
return new SleepingWaitStrategy(retries, sleepTimeNs);
case "YIELD":
return new YieldingWaitStrategy();
case "BLOCK":
return new BlockingWaitStrategy();
case "BUSYSPIN":
return new BusySpinWaitStrategy();
case "TIMEOUT":
return new TimeoutBlockingWaitStrategy(timeoutMillis, TimeUnit.MILLISECONDS);
default:
return new TimeoutBlockingWaitStrategy(timeoutMillis, TimeUnit.MILLISECONDS);
}
我们这里使用其中策略最为均衡的 SleepingWaitStrategy。在当前的大多数应用中,线程的个数都远大于 CPU 的个数,甚至是 RUNNABLE 的线程个数都远大于 CPU 个数,使用基于 Wait 的 BusySpinWaitStrategy 会导致业务闲时突然来业务高峰的时候,日志消费线程唤醒的不够及时(CPU 一直被大量的 RUNNABLE 业务线程抢占)。如果使用比较激进的 BusySpinWaitStrategy(一直调用 Thread.onSpinWait())或者 YieldingWaitStrategy(先 SPIN 之后一直调用 Thread.yield()),则闲时也会有较高的 CPU 占用。我们期望的是一种递进的等待策略,例如:
1.在一定次数内,不断 SPIN,应对日志量特别多的时候,减少线程切换消耗。
2.在超过一定次数之后,开始不断的调用 Thread.onSpinWait() 或者 Thread.yield(),使当前线程让出 CPU 资源,应对间断性的日志高峰。
3.在第二步达到一定次数后,使用 Wait,或者 Thread.sleep() 这样的函数阻塞当前线程,应对日志低峰的时候,减少 CPU 消耗。
SleepingWaitStrategy 就是这样一个策略,第二步采用的是 Thread.yield(),第三步采用的是 Thread.sleep()。同时,我们修改其中的 Thread.yield() 为 Thread.onSpinWait(),原因是:我们部署到的环境是 x86 的机器,在 x86 的环境下 Thread.onSpinWait() 在被调用一定次数后,C1 编译器就会将其替换成使用 PAUSE 这个 x86 指令实现。参考 JVM 源码:
x86.ad
instruct onspinwait() %{
match(OnSpinWait);
ins_cost(200);
format %{
$$template
$$emit$$"pause\t! membar_onspinwait"
%}
ins_encode %{
__ pause();
%}
ins_pipe(pipe_slow);
%}
我们知道,CPU 并不会总直接操作内存,而是以缓存行读取后,缓存在 CPU 高速缓存上。但是对于这种不断检查检查某个状态位是否就绪的代码,不断读取 CPU 高速缓存,会在当前 CPU 从总线收到这个 CPU 高速缓存已经失效之前,都认为这个状态为没有变化。在业务忙时,总线可能非常繁忙,导致 SleepingWaitStrategy 的第二步一直检查不到状态位的更新导致进入第三步。
PAUSE 指令(参考:www.felixcloutier.com/x86/pause) 是针对这种等待策略实现而产生的一个特殊指令,它会告诉处理器所执行的代码序列是一个不断检查某个状态位是否就绪的代码(即 spin-wait loop),这样的话,然后 CPU 分支预测就会据这个提示而避开内存序列冲突,CPU 就不会将这块读取的内存进行缓存,也就是说对 spin-wait loop 不做缓存,不做指令
重新排序等动作。从而提高 spin-wait loop 的执行效率。
这个指令使得针对 spin-wait loop 这种场景,Thread.onSpinWait()的效率要比 Thread.yield() 的效率要高。所以,我们修改 SleepingWaitStrategy 的 Thread.yield() 为 Thread.onSpinWait()。
4. 自定义异常格式化插件,减少在异常集中发生的时候,因为打印异常栈日志量过大导致进一步的性能问题
其实 JVM 有参数 -XX:+OmitStackTraceInFastThrow 可以在某一个异常抛出过多次数时,自动省略异常堆栈。但是这个坏处在于:
1.对于某个新异常,赶上流量高峰突然输出很多异常,还是会有很多日志打印出来。
2.对于一个已经启动很久的进程,比如在 1 月 1 日抛出了很多 A 异常,在 3 月 1 日又抛出 A 异常却没有异常栈,这样很难寻找这个异常栈在哪里。
由于我们项目中使用了各种框架,有的使用了异步框架,导致异常栈会非常非常长(有的甚至有 1000 行),所以其实最符合我们需求的是:
1.每次异常都输出异常栈
2.但是异常栈只包括我们关心的包,其他的包都被省略
但是 Log4j2 官方只是提供了黑名单包的配置,也就是哪些包的异常栈被省略掉:

其实我们需要就是将这个黑名单变成白名单。于是,针对这种情况,我们根据官方源码,将其中的黑名单的判断取反,从黑名单变成了白名单。并创建自定义异常格式化插件:
import org.apache.logging.log4j.core.LogEvent;
import org.apache.logging.log4j.core.config.Configuration;
import org.apache.logging.log4j.core.config.plugins.Plugin;
import org.apache.logging.log4j.core.impl.CustomizedThrowableProxyRenderer;
import org.apache.logging.log4j.core.impl.ThrowableProxy;
import org.apache.logging.log4j.core.pattern.ConverterKeys;
import org.apache.logging.log4j.core.pattern.PatternConverter;
import org.apache.logging.log4j.core.pattern.ThrowablePatternConverter;
@Plugin(name = "CustomizedThrowablePatternConverter", category = PatternConverter.CATEGORY)
//配置 key 是 %cusEx 或者 %cusThrowable 或者 %cusException
@ConverterKeys({ "cusEx", "cusThrowable", "cusException" })
public class CustomizedThrowablePatternConverter extends ThrowablePatternConverter {
public static CustomizedThrowablePatternConverter newInstance(final Configuration config, final String[] options) {
return new CustomizedThrowablePatternConverter(config, options);
}
private CustomizedThrowablePatternConverter(final Configuration config, final String[] options) {
super("CustomizedThrowable", "throwable", options, config);
}
@Override
public void format(final LogEvent event, final StringBuilder toAppendTo) {
final ThrowableProxy proxy = event.getThrownProxy();
final Throwable throwable = event.getThrown();
if ((throwable != null || proxy != null) && options.anyLines()) {
if (proxy == null) {
super.format(event, toAppendTo);
return;
}
final int len = toAppendTo.length();
if (len > 0 && !Character.isWhitespace(toAppendTo.charAt(len - 1))) {
toAppendTo.append(' ');
}
//这里的 CustomizedThrowableProxyRenderer 其实就是将 log4j2 的 ThrowableProxyRenderer 代码复制一份,之后将其中的黑名单判断取反,变成白名单
CustomizedThrowableProxyRenderer.formatExtendedStackTraceTo(proxy, toAppendTo, options.getIgnorePackages(),
options.getTextRenderer(), getSuffix(event), options.getSeparator());
}
}
}
之后通过 layout %cusEx{filters(java, com.mycompany)},这样异常栈就只会输出这些包开头的异常堆栈,这里是 java 和 com.mycompany 开头的,输出的堆栈类似于:
... suppressed 27 lines
at com.mycompany.spring.cloud.parent.web.common.undertow.jfr.JFRTracingFilter.doFilter(JFRTracingFilter.java:40) ~[spring-cloud-parent-web-common-2020.0.3-SNAPSHOT.jar!/:2020.0.3-SNAPSHOT]
at com.mycompany.spring.cloud.parent.web.common.undertow.jfr.LazyJFRTracingFilter.doFilter(LazyJFRTracingFilter.java:23) ~[spring-cloud-parent-web-common-2020.0.3-SNAPSHOT.jar!/:2020.0.3-SNAPSHOT]
... suppressed 46 lines
Caused by: com.alibaba.fastjson.JSONException: write javaBean error, fastjson version 1.2.75, class com.hopegaming.factsCenter.query.revo.controller.frontend.share.matches.MatchController$EventVO, fieldName : data
... suppressed 8 lines
... 74 more
Caused by: java.lang.NullPointerException
at com.mycompany.OrderController.postOrder(OrderController.java:103) ~[classes!/:2020.0.3-SNAPSHOT]
... suppressed 13 lines
... 74 more
5. 监控 RingBuffer 的使用率大小,如果使用率超过一定比例并且持续一段时间,证明应用写日志过忙,需要进行动态扩容,并且暂时将流量从这个实例切走一部分
log4j2 disruptor 的 RingBuffer 既然是一个环形 Buffer,它的容量是有限的,我们这里没有修改它的大小,走的是默认配置,查看其源码:
AsyncLoggerConfigDisruptor.java
public synchronized void start() {
//省略其他代码
ringBufferSize = DisruptorUtil.calculateRingBufferSize("AsyncLoggerConfig.RingBufferSize");
disruptor = new Disruptor<>(factory, ringBufferSize, threadFactory, ProducerType.MULTI, waitStrategy);
}
private static final int RINGBUFFER_MIN_SIZE = 128;
private static final int RINGBUFFER_DEFAULT_SIZE = 256 * 1024;
private static final int RINGBUFFER_NO_GC_DEFAULT_SIZE = 4 * 1024;
static int calculateRingBufferSize(final String propertyName) {
//是否启用了 ThreadLocal,如果是则为 4 kB,不是则为 256 kB
int ringBufferSize = Constants.ENABLE_THREADLOCALS ? RINGBUFFER_NO_GC_DEFAULT_SIZE : RINGBUFFER_DEFAULT_SIZE;
//读取系统变量,以及 log4j2.component.properties 文件获取 propertyName(这里是 AsyncLoggerConfig.RingBufferSize) 这个配置
final String userPreferredRBSize = PropertiesUtil.getProperties().getStringProperty(propertyName,
String.valueOf(ringBufferSize));
try {
int size = Integer.parseInt(userPreferredRBSize);
//如果小于 128 字节则按照 128 字节设置
if (size < RINGBUFFER_MIN_SIZE) {
size = RINGBUFFER_MIN_SIZE;
LOGGER.warn("Invalid RingBufferSize {}, using minimum size {}.", userPreferredRBSize,
RINGBUFFER_MIN_SIZE);
}
ringBufferSize = size;
} catch (final Exception ex) {
LOGGER.warn("Invalid RingBufferSize {}, using default size {}.", userPreferredRBSize, ringBufferSize);
}
//取最近的 2 的 n 次方,因为对于 2 的 n 次方取余等于对于 2^n-1 取与运算,这样更快
return Integers.ceilingNextPowerOfTwo(ringBufferSize);
}
如果启用了 ThreadLocal 这种方式生成 LogEvent,每次不新生成的 LogEvent 用之前的,用 ThreadLocal 存储的,这样避免了创建新的 LogEvent。但是考虑下面这种情况:
logger.info("{}", someObj);
这样会造成强引用,导致如果线程没有新的日志,这个 someObj 一直不能回收。所以针对 Web 应用,log4j2 默认是不启用 ThreadLocal 的 方式生成 LogEvent:
Constants.java
public static final boolean IS_WEB_APP = PropertiesUtil.getProperties().getBooleanProperty(
"log4j2.is.webapp", isClassAvailable("javax.servlet.Servlet"));
public static final boolean ENABLE_THREADLOCALS = !IS_WEB_APP && PropertiesUtil.getProperties().getBooleanProperty(
"log4j2.enable.threadlocals", true);
由此,可以看出,我们的 RingBuffer 的大小为 256 kB。
RingBuffer 满了 log4j2 会发生什么?当 RingBuffer 满了,如果在 log4j2.component.properties 配置了 AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull=false,则会 Wait(其实是 park) 在 Disruptor 的 produce 方法上,等待消费出下一个可以生产的环形 buffer 槽;默认这个配置为 true,即所有生产日志的线程尝试获取全局中的同一个锁(private final Object queueFullEnqueueLock = new Object();):
DisruptorUtil.java
static final boolean ASYNC_CONFIG_SYNCHRONIZE_ENQUEUE_WHEN_QUEUE_FULL = PropertiesUtil.getProperties()
.getBooleanProperty("AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull", true);
private boolean synchronizeEnqueueWhenQueueFull() {
return DisruptorUtil.ASYNC_CONFIG_SYNCHRONIZE_ENQUEUE_WHEN_QUEUE_FULL
// Background thread must never block
&& backgroundThreadId != Thread.currentThread().getId();
}
private final Object queueFullEnqueueLock = new Object();
private void enqueue(final LogEvent logEvent, final AsyncLoggerConfig asyncLoggerConfig) {
//如果 AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull=true,默认就是 true
if (synchronizeEnqueueWhenQueueFull()) {
synchronized (queueFullEnqueueLock) {
disruptor.getRingBuffer().publishEvent(translator, logEvent, asyncLoggerConfig);
}
} else {
//如果 AsyncLoggerConfig.SynchronizeEnqueueWhenQueueFull=false
disruptor.getRingBuffer().publishEvent(translator, logEvent, asyncLoggerConfig);
}
}
默认配置的时候,异常堆栈和我们 JFR 中看到的一样,举个例子:
"Thread-0" #27 [13136] prio=5 os_prio=0 cpu=0.00ms elapsed=141.08s tid=0x0000022d6f2fbcc0 nid=0x3350 waiting for monitor entry [0x000000399bcfe000]
java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor.enqueue(AsyncLoggerConfigDisruptor.java:375)
- waiting to lock <merged>(a java.lang.Object)
at org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor.enqueueEvent(AsyncLoggerConfigDisruptor.java:330)
at org.apache.logging.log4j.core.async.AsyncLoggerConfig.logInBackgroundThread(AsyncLoggerConfig.java:159)
at org.apache.logging.log4j.core.async.EventRoute$1.logMessage(EventRoute.java:46)
at org.apache.logging.log4j.core.async.AsyncLoggerConfig.handleQueueFull(AsyncLoggerConfig.java:149)
at org.apache.logging.log4j.core.async.AsyncLoggerConfig.logToAsyncDelegate(AsyncLoggerConfig.java:136)
at org.apache.logging.log4j.core.async.AsyncLoggerConfig.log(AsyncLoggerConfig.java:116)
at org.apache.logging.log4j.core.config.LoggerConfig.log(LoggerConfig.java:460)
at org.apache.logging.log4j.core.config.AwaitCompletionReliabilityStrategy.log(AwaitCompletionReliabilityStrategy.java:82)
at org.apache.logging.log4j.core.Logger.log(Logger.java:162)
at org.apache.logging.log4j.spi.AbstractLogger.tryLogMessage(AbstractLogger.java:2190)
at org.apache.logging.log4j.spi.AbstractLogger.logMessageTrackRecursion(AbstractLogger.java:2144)
at org.apache.logging.log4j.spi.AbstractLogger.logMessageSafely(AbstractLogger.java:2127)
at org.apache.logging.log4j.spi.AbstractLogger.logMessage(AbstractLogger.java:2003)
at org.apache.logging.log4j.spi.AbstractLogger.logIfEnabled(AbstractLogger.java:1975)
at org.apache.logging.log4j.spi.AbstractLogger.info(AbstractLogger.java:1312)
省略业务方法堆栈
配置为 false 的时候,堆栈是这个样子的:
"Thread-0" #27 [18152] prio=5 os_prio=0 cpu=0.00ms elapsed=5.68s tid=0x000002c1fa120e00 nid=0x46e8 runnable [0x000000eda8efe000]
java.lang.Thread.State: TIMED_WAITING (parking)
at jdk.internal.misc.Unsafe.park(java.base@17-loom/Native Method)
at java.util.concurrent.locks.LockSupport.parkNanos(java.base@17-loom/LockSupport.java:410)
at com.lmax.disruptor.MultiProducerSequencer.next(MultiProducerSequencer.java:136)
at com.lmax.disruptor.MultiProducerSequencer.next(MultiProducerSequencer.java:105)
at com.lmax.disruptor.RingBuffer.publishEvent(RingBuffer.java:524)
at org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor.enqueue(AsyncLoggerConfigDisruptor.java:379)
at org.apache.logging.log4j.core.async.AsyncLoggerConfigDisruptor.enqueueEvent(AsyncLoggerConfigDisruptor.java:330)
at org.apache.logging.log4j.core.async.AsyncLoggerConfig.logInBackgroundThread(AsyncLoggerConfig.java:159)
at org.apache.logging.log4j.core.async.EventRoute$1.logMessage(EventRoute.java:46)
at org.apache.logging.log4j.core.async.AsyncLoggerConfig.handleQueueFull(AsyncLoggerConfig.java:149)
at org.apache.logging.log4j.core.async.AsyncLoggerConfig.logToAsyncDelegate(AsyncLoggerConfig.java:136)
at org.apache.logging.log4j.core.async.AsyncLoggerConfig.log(AsyncLoggerConfig.java:116)
at org.apache.logging.log4j.core.config.LoggerConfig.log(LoggerConfig.java:460)
at org.apache.logging.log4j.core.config.AwaitCompletionReliabilityStrategy.log(AwaitCompletionReliabilityStrategy.java:82)
at org.apache.logging.log4j.core.Logger.log(Logger.java:162)
at org.apache.logging.log4j.spi.AbstractLogger.tryLogMessage(AbstractLogger.java:2190)
at org.apache.logging.log4j.spi.AbstractLogger.logMessageTrackRecursion(AbstractLogger.java:2144)
at org.apache.logging.log4j.spi.AbstractLogger.logMessageSafely(AbstractLogger.java:2127)
at org.apache.logging.log4j.spi.AbstractLogger.logMessage(AbstractLogger.java:2003)
at org.apache.logging.log4j.spi.AbstractLogger.logIfEnabled(AbstractLogger.java:1975)
at org.apache.logging.log4j.spi.AbstractLogger.info(AbstractLogger.java:1312)
对于这种情况,我们需要监控。
首先想到的是进程外部采集系统指标监控:现在服务都提倡上云,并实现云原生服务。对于云服务,存储日志很可能使用 NFS(Network File System),例如 AWS 的 EFS。这种 NFS 一动都可以动态的控制 IO 最大承载,但是服务的增长是很难预估完美的,并且高并发业务流量基本都是一瞬间到达,仅通过 IO 定时采集很难评估到真正的流量尖峰(例如 IO 定时采集是 5s 一次,但是在某一秒内突然到达很多流量,导致进程内大多线程阻塞,这之后采集 IO 看到 IO 压力貌似不大的样子)。并且,由于线程的阻塞,导致可能我们看到的 CPU 占用貌似也不高的样子。所以,外部定时采集指标,很难真正定位到日志流量问题。
然后我们考虑进程自己监控,暴露接口给外部监控定时检查,例如 K8s 的 pod 健康检查等等。在进程的日志写入压力过大的时候,新扩容一个实例;启动完成后,在注册中心将这个日志压力大的进程的状态设置为暂时下线(例如 Eureka 置为 OUT_OF_SERVICE,Nacos 置为 PAUSED),让流量转发到其他实例。待日志压力小之后,再修改状态为 UP,继续服务。
Log4j2 对于每一个 AsyncLogger 配置,都会创建一个独立的 RingBuffer,例如下面的 Log4j2 配置:
<!--省略了除了 loggers 以外的其他配置-->
<loggers>
<!--default logger -->
<Asyncroot level="info" includeLocation="true">
<appender-ref ref="console"/>
</Asyncroot>
<AsyncLogger name="RocketmqClient" level="error" additivity="false" includeLocation="true">
<appender-ref ref="console"/>
</AsyncLogger>
<AsyncLogger name="com.alibaba.druid.pool.DruidDataSourceStatLoggerImpl" level="error" additivity="false" includeLocation="true">
<appender-ref ref="console"/>
</AsyncLogger>
<AsyncLogger name="org.mybatis" level="error" additivity="false" includeLocation="true">
<appender-ref ref="console"/>
</AsyncLogger>
</loggers>
这个配置包含 4 个 AsyncLogger,对于每个 AsyncLogger 都会创建一个 RingBuffer。Log4j2 也考虑到了监控 AsyncLogger 这种情况,所以将 AsyncLogger 的监控暴露成为一个 MBean(JMX Managed Bean)。
相关源码如下:
Server.java
private static void registerLoggerConfigs(final LoggerContext ctx, final MBeanServer mbs, final Executor executor)
throws InstanceAlreadyExistsException, MBeanRegistrationException, NotCompliantMBeanException {
//获取 log4j2.xml 配置中的 loggers 标签下的所有配置值
final Map<String, LoggerConfig> map = ctx.getConfiguration().getLoggers();
//遍历每个 key,其实就是 logger 的 name
for (final String name : map.keySet()) {
final LoggerConfig cfg = map.get(name);
final LoggerConfigAdmin mbean = new LoggerConfigAdmin(ctx, cfg);
//对于每个 logger 注册一个 LoggerConfigAdmin
register(mbs, mbean, mbean.getObjectName());
//如果是异步日志配置,则注册一个 RingBufferAdmin
if (cfg instanceof AsyncLoggerConfig) {
final AsyncLoggerConfig async = (AsyncLoggerConfig) cfg;
final RingBufferAdmin rbmbean = async.createRingBufferAdmin(ctx.getName());
register(mbs, rbmbean, rbmbean.getObjectName());
}
}
}
创建的 MBean 的类源码:RingBufferAdmin.java
public class RingBufferAdmin implements RingBufferAdminMBean {
private final RingBuffer<?> ringBuffer;
private final ObjectName objectName;
//... 省略其他我们不关心的代码
public static final String DOMAIN = "org.apache.logging.log4j2";
String PATTERN_ASYNC_LOGGER_CONFIG = DOMAIN + ":type=%s,component=Loggers,name=%s,subtype=RingBuffer";
//创建 RingBufferAdmin,名称格式符合 Mbean 的名称格式
public static RingBufferAdmin forAsyncLoggerConfig(final RingBuffer<?> ringBuffer,
final String contextName, final String configName) {
final String ctxName = Server.escape(contextName);
//对于 RootLogger,这里 cfgName 为空字符串
final String cfgName = Server.escape(configName);
final String name = String.format(PATTERN_ASYNC_LOGGER_CONFIG, ctxName, cfgName);
return new RingBufferAdmin(ringBuffer, name);
}
//获取 RingBuffer 的大小
@Override
public long getBufferSize() {
return ringBuffer == null ? 0 : ringBuffer.getBufferSize();
}
//获取 RingBuffer 剩余的大小
@Override
public long getRemainingCapacity() {
return ringBuffer == null ? 0 : ringBuffer.remainingCapacity();
}
public ObjectName getObjectName() {
return objectName;
}
}
我们可以通过 JConsole 查看对应的 MBean:
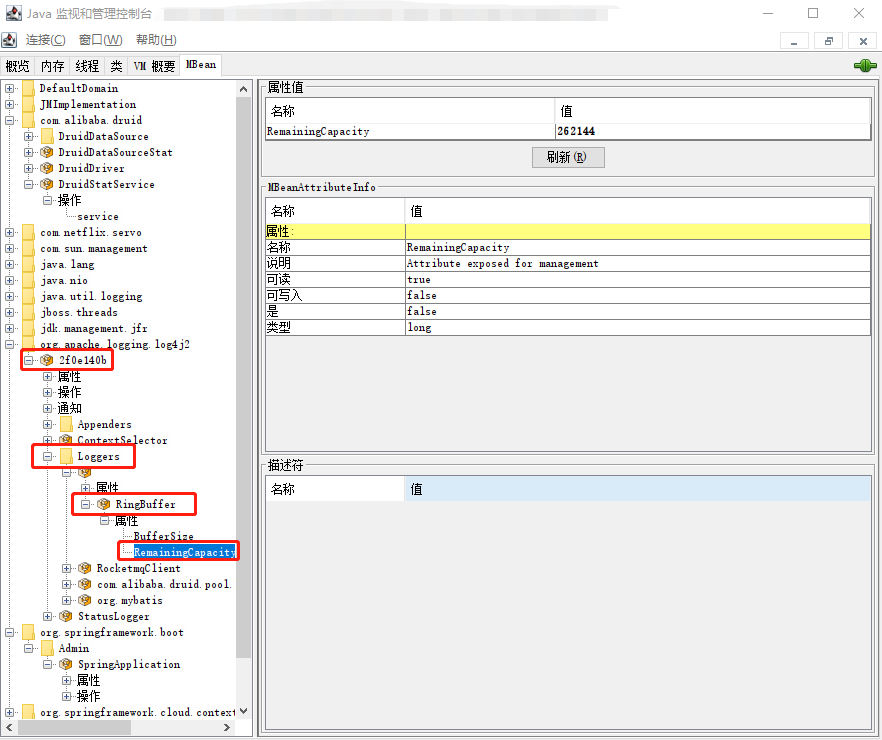
其中 2f0e140b 为 LoggerContext 的 name。
我们的微服务项目中使用了 spring boot,并且集成了 prometheus。我们可以通过将 Log4j2 RingBuffer 大小作为指标暴露到 prometheus 中,通过如下代码:
import io.micrometer.core.instrument.Gauge;
import io.micrometer.prometheus.PrometheusMeterRegistry;
import lombok.extern.log4j.Log4j2;
import org.apache.commons.lang3.StringUtils;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.core.LoggerContext;
import org.apache.logging.log4j.core.jmx.RingBufferAdminMBean;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.actuate.autoconfigure.metrics.export.ConditionalOnEnabledMetricsExport;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.event.ContextRefreshedEvent;
import org.springframework.context.event.EventListener;
import javax.annotation.PostConstruct;
import javax.management.ObjectName;
import java.lang.management.ManagementFactory;
@Log4j2
@Configuration(proxyBeanMethods = false)
//需要在引入了 prometheus 并且 actuator 暴露了 prometheus 端口的情况下才加载
@ConditionalOnEnabledMetricsExport("prometheus")
public class Log4j2Configuration {
@Autowired
private ObjectProvider<PrometheusMeterRegistry> meterRegistry;
//只初始化一次
private volatile boolean isInitialized = false;
//需要在 ApplicationContext 刷新之后进行注册
//在加载 ApplicationContext 之前,日志配置就已经初始化好了
//但是 prometheus 的相关 Bean 加载比较复杂,并且随着版本更迭改动比较多,所以就直接偷懒,在整个 ApplicationContext 刷新之后再注册
// ApplicationContext 可能 refresh 多次,例如调用 /actuator/refresh,还有就是多 ApplicationContext 的场景
// 这里为了简单,通过一个简单的 isInitialized 判断是否是第一次初始化,保证只初始化一次
@EventListener(ContextRefreshedEvent.class)
public synchronized void init() {
if (!isInitialized) {
//通过 LogManager 获取 LoggerContext,从而获取配置
LoggerContext loggerContext = (LoggerContext) LogManager.getContext(false);
org.apache.logging.log4j.core.config.Configuration configuration = loggerContext.getConfiguration();
//获取 LoggerContext 的名称,因为 Mbean 的名称包含这个
String ctxName = loggerContext.getName();
configuration.getLoggers().keySet().forEach(k -> {
try {
//针对 RootLogger,它的 cfgName 是空字符串,为了显示好看,我们在 prometheus 中将它命名为 root
String cfgName = StringUtils.isBlank(k) ? "" : k;
String gaugeName = StringUtils.isBlank(k) ? "root" : k;
Gauge.builder(gaugeName + "_logger_ring_buffer_remaining_capacity", () ->
{
try {
return (Number) ManagementFactory.getPlatformMBeanServer()
.getAttribute(new ObjectName(
//按照 Log4j2 源码中的命名方式组装名称
String.format(RingBufferAdminMBean.PATTERN_ASYNC_LOGGER_CONFIG, ctxName, cfgName)
//获取剩余大小,注意这个是严格区分大小写的
), "RemainingCapacity");
} catch (Exception e) {
log.error("get {} ring buffer remaining size error", k, e);
}
return -1;
}).register(meterRegistry.getIfAvailable());
} catch (Exception e) {
log.error("Log4j2Configuration-init error: {}", e.getMessage(), e);
}
});
isInitialized = true;
}
}
}
增加这个代码之后,请求 /actuator/prometheus 之后,可以看到对应的返回:
//省略其他的
# HELP root_logger_ring_buffer_remaining_capacity
# TYPE root_logger_ring_buffer_remaining_capacity gauge
root_logger_ring_buffer_remaining_capacity 262144.0
# HELP org_mybatis_logger_ring_buffer_remaining_capacity
# TYPE org_mybatis_logger_ring_buffer_remaining_capacity gauge
org_mybatis_logger_ring_buffer_remaining_capacity 262144.0
# HELP com_alibaba_druid_pool_DruidDataSourceStatLoggerImpl_logger_ring_buffer_remaining_capacity
# TYPE com_alibaba_druid_pool_DruidDataSourceStatLoggerImpl_logger_ring_buffer_remaining_capacity gauge
com_alibaba_druid_pool_DruidDataSourceStatLoggerImpl_logger_ring_buffer_remaining_capacity 262144.0
# HELP RocketmqClient_logger_ring_buffer_remaining_capacity
# TYPE RocketmqClient_logger_ring_buffer_remaining_capacity gauge
RocketmqClient_logger_ring_buffer_remaining_capacity 262144.0
这样,当这个值为 0 持续一段时间后(就代表 RingBuffer 满了,日志生成速度已经远大于消费写入 Appender 的速度了),我们就认为这个应用日志负载过高了。
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer



