
g1源码之fullGC算法详解原创
关于g1的gc源码系列解析就剩下fullGC了,其实关于fullGC的源码方面并不是很难,相对于youngGC和mixed GC和并发标记来说,相对好阅读一些,网上也有一些文章是讲述fullGC的源码,但是多多少少有些部分讲述的不太清楚,或者干脆写错,所以笔者从自己的视角出发,来学习fullGC的源码,话不多说,我们直接开始。
一.full gc触发的时机
国际惯例,我们先从full gc的触发时机开始看起,读过笔者之前博客的朋友应该都熟悉这个套路,学习源码都需要先找到入口,而gc算法的入口其实就是其触发的时机。
关于full gc触发的时机其实是内存申请失败,晋升失败,疏散失败,元空间gc,调用system.gc时会触发full gc,相关调用关系如下:
//(大对象或内存)申请失败
//年轻代对象晋升老年代的疏散(即回收)失败
//其他原因的疏散(即回收)失败
G1CollectedHeap::mem_allocate
--VM_G1CollectForAllocation::doit()
----G1CollectedHeap::satisfy_failed_allocation()
------G1CollectedHeap::do_collection()
//入参是GC触发原因:
//other = system.gc
//collect_as_vm_thread = metadata_gc
G1CollectedHeap::collect(GCCause::Cause cause)
--VM_G1CollectFull::doit()
----G1CollectedHeap::do_full_collection()
------ G1CollectedHeap::do_collection()
//看过笔者之前的文章的朋友可以看到VM_G1CollectForAllocation和VM_G1CollectFull是gc时候的任务类
//方法调用到这层时已经进入stw了,有兴趣的朋友可以翻一翻笔者往期博客,有关于stw的实现讲解,这里就先不论述
我们可以看到,最终调用的都是G1CollectedHeap::do_collection()这个方法去执行full gc的逻辑,下面我们来逐步拆解full gc的过程。
二.full gc前准备
G1CollectedHeap::do_collection()从方法名我们就可以看出这是关于gc的方法,但是这个方法再gc前还会做一些准备工作,我们直接来看下:
//参数分别是:
//1.是否是明确的gc即为false则表示gc应最少满足回收word_size的大小,为true则表示system.gc或整个堆回收
//2.是否清除所有软引用
//3.要申请的空间大小
bool G1CollectedHeap::do_collection(bool explicit_gc,
bool clear_all_soft_refs,
size_t word_size) {
//检查是否正在执行
if (GC_locker::check_active_before_gc()) {
return false;
}
//声明一些gc计时器
STWGCTimer* gc_timer = G1MarkSweep::gc_timer();
gc_timer->register_gc_start();
SerialOldTracer* gc_tracer = G1MarkSweep::gc_tracer();
gc_tracer->report_gc_start(gc_cause(), gc_timer->gc_start());
SvcGCMarker sgcm(SvcGCMarker::FULL);
ResourceMark rm;
//gc前打印相关日志
print_heap_before_gc();
trace_heap_before_gc(gc_tracer);
//元空间之前的使用量
size_t metadata_prev_used = MetaspaceAux::allocated_used_bytes();
HRSPhaseSetter x(HRSPhaseFullGC);
verify_region_sets_optional();
const bool do_clear_all_soft_refs = clear_all_soft_refs ||
collector_policy()->should_clear_all_soft_refs();
//声明清理所有软引用闭包
ClearedAllSoftRefs casr(do_clear_all_soft_refs, collector_policy());
{
IsGCActiveMark x;
// 一些时间计算
assert(gc_cause() != GCCause::_java_lang_system_gc || explicit_gc, "invariant");
gclog_or_tty->date_stamp(G1Log::fine() && PrintGCDateStamps);
//追踪cpu时间
TraceCPUTime tcpu(G1Log::finer(), true, gclog_or_tty);
{
//gc时间追踪器
GCTraceTime t(GCCauseString("Full GC", gc_cause()), G1Log::fine(), true, NULL);
TraceCollectorStats tcs(g1mm()->full_collection_counters());
TraceMemoryManagerStats tms(true /* fullGC */, gc_cause());
double start = os::elapsedTime();
//记录full gc开始
g1_policy()->record_full_collection_start();
//这里是为了以后更换新的日志框架时留的口子
wait_while_free_regions_coming();
//这里是终止并发标记的根区域扫描
_cm->root_regions()->abort();
_cm->root_regions()->wait_until_scan_finished();
//将second_free_list(不为空的话)加入到free_list中
append_secondary_free_list_if_not_empty_with_lock();
//这个方法是gc前的准备工作,主要是用虚拟数组填充tlab中,方便退回tlab
gc_prologue(true);
//增加统计
increment_total_collections(true /* full gc */);
increment_old_marking_cycles_started();
//gc前验证
verify_before_gc();
//在full gc前生成一些dump信息
pre_full_gc_dump(gc_timer);
//禁用并发标记引用发现器(用于并发处理非强引用)并清空相关发现列表
ref_processor_cm()->disable_discovery();
ref_processor_cm()->abandon_partial_discovery();
ref_processor_cm()->verify_no_references_recorded();
//终止并发标记
concurrent_mark()->abort();
//释放young region正在使用的region
release_mutator_alloc_region();
//取消正在使用的老年代region
abandon_gc_alloc_regions();
//清理记忆集合
g1_rem_set()->cleanupHRRS();
_hr_printer.start_gc(true /* full */, (size_t) total_collections());
//清除回收集合,和incremental回收集合,再gc结束后重建
abandon_collection_set(g1_policy()->inc_cset_head());
g1_policy()->clear_incremental_cset();
g1_policy()->stop_incremental_cset_building();
//清空region sets 包括old_sets, young_list和free_list
tear_down_region_sets(false /* free_list_only */);
//修改gcs_are_young标记
g1_policy()->set_gcs_are_young(true);
ReferenceProcessorMTDiscoveryMutator stw_rp_disc_ser(ref_processor_stw(), false);
ReferenceProcessorIsAliveMutator stw_rp_is_alive_null(ref_processor_stw(), NULL);
//开启stw引用发现器,用于处理非强引用
ref_processor_stw()->enable_discovery(true /*verify_disabled*/, true /*verify_no_refs*/);
ref_processor_stw()->setup_policy(do_clear_all_soft_refs);
// 开始回收工作
{
HandleMark hm;
G1MarkSweep::invoke_at_safepoint(ref_processor_stw(), do_clear_all_soft_refs);
}
//gc 结束收尾工作,先忽略一会我们在分析
.....
}
我们看到在真正的gc开始之前是做了很多准备工作的,包括创建gc时间统计器,开启stw引用发现器,关闭cm引用发现器,填充并退回tlab,终止并发标记,取消正在使用的old region和年轻代region,清理记忆集合,清理回收集合等等,这里笔者就不一一展开分析,其主要逻辑也比较简单,有兴趣的读者可以自行查找阅读。而真正包含full gc算法逻辑的方法是:G1MarkSweep::invoke_at_safepoint().
三.full gc算法详解
在看full gc主要算法源码之前,我们要明确一点,full gc使用的是标记压缩清除算法,关于这点有很多同学只了解这个概念,并不清除具体是如何实现的,比如压缩后指针怎么调整,如何进行压缩,标记前锁状态怎么处理等等,接下来笔者会将其慢慢拆解分析,我们先看刚刚提到G1MarkSweep::invoke_at_safepoint()方法:
void G1MarkSweep::invoke_at_safepoint(ReferenceProcessor* rp,
bool clear_all_softrefs) {
SharedHeap* sh = SharedHeap::heap();
//安装软引用处理策略,rp即前面提到的stw引用发现器,用于处理非强引用
GenMarkSweep::_ref_processor = rp;
rp->setup_policy(clear_all_softrefs);
//当gc时,java方法的字节码地址可能会移动,
//我们必须刷新所有的bcp,或者将其转换为bic,防止其gc结束后指向错误的位置
//这里关于bcp和bic(感兴趣的朋友可以自行查看,本文我们不继续深究,先略过):
//当执行 Java 方法时,程序计数器存放 Java 字节码的地址。
//实现上可能有两种形式,一种是相对该方法字节码开始处的偏移量,叫做 bytecode index(简称 bci)。
//另一种是该 Java 字节码指令在内存的地址,叫做 bytecode pointer(简称 bcp)。
CodeCache::gc_prologue();
Threads::gc_prologue();
bool marked_for_unloading = false;
//申请保存markword(对象头中的markword)的栈,用于保存非偏向锁的锁的markword的栈之后会用到
allocate_stacks();
//保存偏向锁的markword
BiasedLocking::preserve_marks();
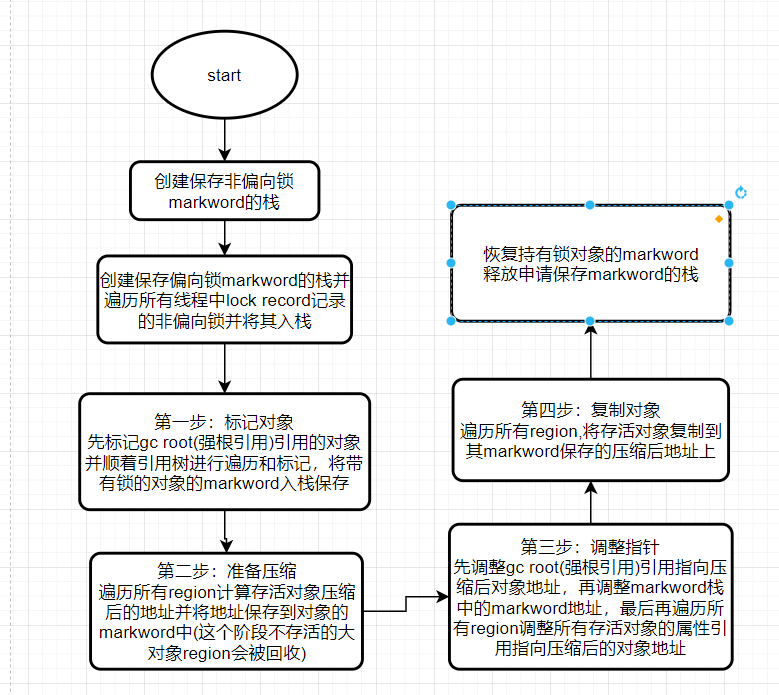
//第一步:标记标记对象
mark_sweep_phase1(marked_for_unloading, clear_all_softrefs);
//第二步:准备压缩,即计算压缩后的地址
mark_sweep_phase2();
//第三步:调整指针
mark_sweep_phase3();
//第四步:复制对象
mark_sweep_phase4();
//恢复之前_preserved_marks里保存的markword
GenMarkSweep::restore_marks();
//恢复偏向锁
BiasedLocking::restore_marks();
//释放之前申请的用于保存markword的栈
GenMarkSweep::deallocate_stacks();
Threads::gc_epilogue();
CodeCache::gc_epilogue();
JvmtiExport::gc_epilogue();
// 清空引用扫描器
GenMarkSweep::_ref_processor = NULL;
}
就像笔者之前说到的,这里的代码逻辑是比较明显的,相对好阅读一些,在进行gc算法之前调用了BiasedLocking::preserve_marks() 方法保存偏向锁,笔者在这里解释下为什么要先保存偏向锁:
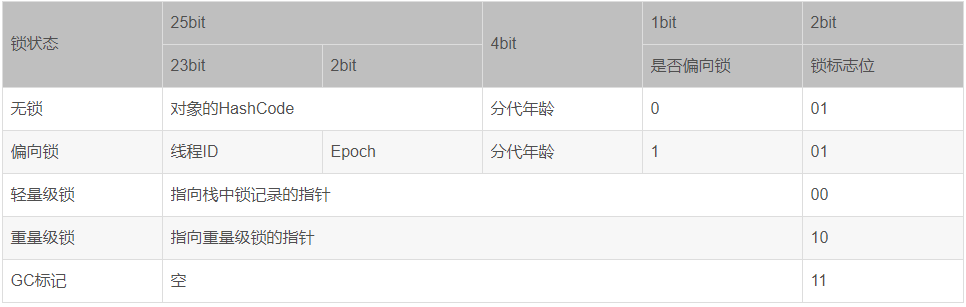
如上图在g1中对象的锁标记位都在markword(对象头中的markword)中,而gc标记也在markword(对象头中的markword)中,并且两者在相同的位置,所以要想标记对象,我们就需要保存锁标记,等gc结束后再进行恢复。
其实不止是偏向锁,其他锁也会被保存,之后我们就可以看到,我们先看下保存偏向锁的方法:
void BiasedLocking::preserve_marks() {
//判断偏向锁jvm参数
if (!UseBiasedLocking)
return;
//创建保存偏向锁的mark 和oop的栈
//注:和之前非偏向锁的栈不是一个栈,两者是分开保存的
_preserved_mark_stack = new (ResourceObj::C_HEAP, mtInternal) GrowableArray<markOop>(10, true);
_preserved_oop_stack = new (ResourceObj::C_HEAP, mtInternal) GrowableArray<Handle>(10, true);
//遍历所有线程
ResourceMark rm;
Thread* cur = Thread::current();
for (JavaThread* thread = Threads::first(); thread != NULL; thread = thread->next()) {
//获取最后一个栈帧
if (thread->has_last_Java_frame()) {
RegisterMap rm(thread);
//遍历栈帧
for (javaVFrame* vf = thread->last_java_vframe(&rm); vf != NULL; vf = vf->java_sender()) {
//获取栈帧中的monitors
//这里应该是从lock record中获取记录
GrowableArray<MonitorInfo*> *monitors = vf->monitors();
if (monitors != NULL) {
int len = monitors->length();
//遍历monitors
for (int i = len - 1; i >= 0; i--) {
MonitorInfo* mon_info = monitors->at(i);
if (mon_info->owner_is_scalar_replaced()) continue;
oop owner = mon_info->owner();
if (owner != NULL) {
markOop mark = owner->mark();
//如果是偏向锁则保存mark和oop
if (mark->has_bias_pattern()) {
_preserved_oop_stack->push(Handle(cur, owner));
_preserved_mark_stack->push(mark);
}
}
}
}
}
}
}
}
在处理偏向锁的保存时,jvm使用的时遍历所有线程栈中栈帧的lock record,如果lock record中记录的是一个偏向锁,则将markword和对象分开保存在栈中。
注:lock record是用于线程栈帧中记录锁信息,这里涉及到synchronized的具体实现,非本文重点,笔者就不过多论述。
之后真正的g1标记压缩清除算法开始了,我们先看第一步:标记对象:
//标记对——递归遍历所有的对象并标记
void G1MarkSweep::mark_sweep_phase1(bool& marked_for_unloading,
bool clear_all_softrefs) {
GCTraceTime tm("phase 1", G1Log::fine() && Verbose, true, gc_timer());
//打印日志
GenMarkSweep::trace(" 1");
SharedHeap* sh = SharedHeap::heap();
//这里清除遍历ClassLoader的标记,后面遍历的时候还会开启
ClassLoaderDataGraph::clear_claimed_marks();
//熟悉的方法,在youngGC中出现过,扫描强根并标记
//笔者就不展开,我们直接看闭包遍历方法即GenMarkSweep::follow_root_closure的遍历方法
sh->process_strong_roots(true, // activate StrongRootsScope
false, // not scavenging.
SharedHeap::SO_SystemClasses,
&GenMarkSweep::follow_root_closure,
&GenMarkSweep::follow_code_root_closure,
&GenMarkSweep::follow_klass_closure);
//GenMarkSweep::ref_processor()返回的是之前提到的stw引用发现器,用于处理非强引用
ReferenceProcessor* rp = GenMarkSweep::ref_processor();
//装载是否清理软引用的策略
rp->setup_policy(clear_all_softrefs);
//发现引用并处理
const ReferenceProcessorStats& stats =
rp->process_discovered_references(&GenMarkSweep::is_alive,
&GenMarkSweep::keep_alive,
&GenMarkSweep::follow_stack_closure,
NULL,
gc_timer());
gc_tracer()->report_gc_reference_stats(stats);
//卸载类和清除系统字典
bool purged_class = SystemDictionary::do_unloading(&GenMarkSweep::is_alive);
//卸载native方法
CodeCache::do_unloading(&GenMarkSweep::is_alive, purged_class);
//从子类/兄弟类/接口实现类列表中删除死类
Klass::clean_weak_klass_links(&GenMarkSweep::is_alive);
//清理没引用的字符串
StringTable::unlink(&GenMarkSweep::is_alive);
//清理没引用的符号
SymbolTable::unlink();
//跳过一些验证
....
//在gc之后报告对象数量
gc_tracer()->report_object_count_after_gc(&GenMarkSweep::is_alive);
}
//GenMarkSweep::follow_root_closure闭包最后调用这个方法遍历处理
template <class T> inline void MarkSweep::follow_root(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
//如果gc root引用的对象没有被标记则进行标记
if (!obj->mark()->is_marked()) {
mark_object(obj);
//这个方法会迭代标记对象属性引用的对象
//并将其加入正在标记栈
obj->follow_contents();
}
}
//这个方法会顺着引用链路遍历下去并标记
//具体实现是不断从标记栈中取出对象取出并遍历其属性引用的对象之后将新对象并加入标记栈,直到栈为空
follow_stack();
}
//我们看看标记的方法
inline void MarkSweep::mark_object(oop obj) {
//获取gc前的markword
markOop mark = obj->mark();
//创建标记markword即锁标记位是刚刚提到的11的markword并替换对象的markword
obj->set_mark(markOopDesc::prototype()->set_marked());
//把一些对象的原markword保存下来
//因为锁的标记位和full gc的标记位是同两位
//如果用于锁就不能标记了,所以保存之后恢复
if (mark->must_be_preserved(obj)) {
preserve_mark(obj, mark);
}
}
//看下判断是否保存markword的方法
//最后调用这个方法
inline bool markOopDesc::must_be_preserved_with_bias(oop obj_containing_mark) const {
//偏向锁和对象是分开保存的,偏向锁已经保存过了,所以这里返回false
if (has_bias_pattern()) {
return false;
}
//如果klass被锁的对象在gc结束后被恢复时会使用klass的markword,所以这里返回true将其原markword保存
//即防止被锁的class对象干扰到普通对象
markOop prototype_header = prototype_for_object(obj_containing_mark);
if (prototype_header->has_bias_pattern()) {
return true;
}
//有锁返回true, 需要保存markword
return (!is_unlocked() || !has_no_hash());
}
至此,full gc第一步结束了,现在所有的对象已经被标记即markword锁标记位为11,所有的偏向锁和非偏向锁的markword也被保存到相应的栈中。
然后我们看第二步:准备压缩(计算压缩后的对象地址):
//现在所有的对象已经被标记,计算新的对象地址
void G1MarkSweep::mark_sweep_phase2() {
G1CollectedHeap* g1h = G1CollectedHeap::heap();
GCTraceTime tm("phase 2", G1Log::fine() && Verbose, true, gc_timer());
GenMarkSweep::trace("2");
//这里可以理解为找到第一个region,非humongus region
//将其当作压缩空间,在之后会用到,这里的压缩空间会记录存活对象压缩后的位置
HeapRegion* r = g1h->region_at(0);
CompactibleSpace* sp = r;
if (r->isHumongous() && oop(r->bottom())->is_gc_marked()) {
sp = r->next_compaction_space();
}
//创建用于准备压缩的遍历闭包
G1PrepareCompactClosure blk(sp);
g1h->heap_region_iterate(&blk);
//这个方法主要是更新大对象region集合,会将回收的大对象region加入代理集合等待之后回收
blk.update_sets();
}
//我们看看准备压缩的闭包遍历方法
bool doHeapRegion(HeapRegion* hr) {
//大对象region处理
if (hr->isHumongous()) {
//大对象region只处理开始的region
if (hr->startsHumongous()) {
oop obj = oop(hr->bottom());
//如果被标记则将指向自己的指针保存到对象的markword中
if (obj->is_gc_marked()) {
obj->forward_to(obj);
} else {
//如果没被标记则释放region
free_humongous_region(hr);
}
} else {
assert(hr->continuesHumongous(), "Invalid humongous.");
}
} else {
//一般region处理
//其他的准备压缩,计算存活对象压缩后的指针位置并存到对象的markword中
//这个方法最后会调用准备压缩宏方法,我们一起来看看
//参数是之前传入的压缩空间的封装类
hr->prepare_for_compaction(&_cp);
//清理卡表
_mrbs->clear(MemRegion(hr->compaction_top(), hr->end()));
}
return false;
}
我们来看下最后调用的准备压缩宏方法:
//准备压缩region的宏
//计算每个对象压缩后的位置
#define SCAN_AND_FORWARD(cp,scan_limit,block_is_obj,block_size) {
//这个表示当前要压缩到的位置的游标
//先初始化到region底部bottom
HeapWord* compact_top;
set_compaction_top(bottom());
//初始化压缩空间,这里是g1所以space不为Null跳过
//这里的压缩空间其实是普通的region,和当前遍历处理的region不一定是一个region
if (cp->space == NULL) {
assert(cp->gen != NULL, "need a generation");
assert(cp->threshold == NULL, "just checking");
assert(cp->gen->first_compaction_space() == this, "just checking");
cp->space = cp->gen->first_compaction_space();
compact_top = cp->space->bottom();
cp->space->set_compaction_top(compact_top);
cp->threshold = cp->space->initialize_threshold();
} else {
compact_top = cp->space->compaction_top();
}
//这里会获取fullGC调用次数来判断是否跳过在存活对象区域中间的死亡区域
//其意义是可以避免频繁压缩,减少性能消耗
uint invocations = MarkSweep::total_invocations();
bool skip_dead = ((invocations % MarkSweepAlwaysCompactCount) != 0);
//如果允许跳过死亡区域,则计算可跳过的死亡区域大小
size_t allowed_deadspace = 0;
if (skip_dead) {
const size_t ratio = allowed_dead_ratio();
allowed_deadspace = (capacity() * ratio / 100) / HeapWordSize;
}
HeapWord* q = bottom();
//scan_limit()是传入的第二个参数(闭包)实际上返回的是top,即region已经使用的区域大小
HeapWord* t = scan_limit();
//这个代表最后的存活对象的游标,先设置为bottom
HeapWord* end_of_live= q;
//第一个垃圾对象游标,先设置为end即region尾部
HeapWord* first_dead = end();
LiveRange* liveRange = NULL;
_first_dead = first_dead;
const intx interval = PrefetchScanIntervalInBytes;
//遍历直到top位置,q即当前游标指向的对象
while (q < t) {
//判断是否是对象且被标记,即表示存活
if (block_is_obj(q) && oop(q)->is_gc_marked()) {
Prefetch::write(q, interval);
//获取对象的大小
size_t size = block_size(q);
//计算对象压缩后的地址,并将指针存到对象的markword中
//一会我们分析下这个forward()方法
compact_top = cp->space->forward(oop(q), size, cp, compact_top);
//移动q游标和最后一个存活对象游标
q += size;
end_of_live = q;
} else {
//不存活的对象处理
HeapWord* end = q;
//这个循环是判断后面是不是连续的不存活对象,方便直接跳过
do {
Prefetch::write(end, interval);
end += block_size(end);
} while (end < t && (!block_is_obj(end) || !oop(end)->is_gc_marked()));
//根据allowed_deadspace判断是否允许跳过不存活的对象,意义是避免经常压缩
if (allowed_deadspace > 0 && q == compact_top) {
size_t sz = pointer_delta(end, q);
//填充deadspace,填充成功就把这段当作存活对象
if (insert_deadspace(allowed_deadspace, q, sz)) {
compact_top = cp->space->forward(oop(q), sz, cp, compact_top);
q = end;
end_of_live = end;
continue;
}
}
if (liveRange) {
liveRange->set_end(q);
}
//这里有点难以理解,代码运行到这里
//end是这个垃圾区域后的存活对象指针,将存活的对象地址放到垃圾区域开始对象的markword中
//在第三步调整指针的时候可以直接跳过这片垃圾区域
liveRange = (LiveRange*)q;
liveRange->set_start(end);
liveRange->set_end(end);
//修改第一个不存活的对象标记的位置
if (q < first_dead) {
first_dead = q;
}
q = end;
}
}
//遍历结束
if (liveRange != NULL) {
liveRange->set_end(q);
}
_end_of_live = end_of_live;
//如果最后一个存活对象位置小于第一个死亡对象的位置,则修改死亡对象的位置到最后存活对象的位置
//若遍历所有使用区域后,无逻辑上的死亡对象,则调整first_dead
if (end_of_live < first_dead) {
first_dead = end_of_live;
}
_first_dead = first_dead;
//保存压缩位置游标
cp->space->set_compaction_top(compact_top);
}
这段代码读起来有点繁琐,主要做了两件事:
1.处理first_dead和end_of_live游标
2.计算存活对象压缩后的指针并保存
第一件事就是笔者画个图来展示下所有region处理完成后两个游标的状态,便于大家直观理解下:
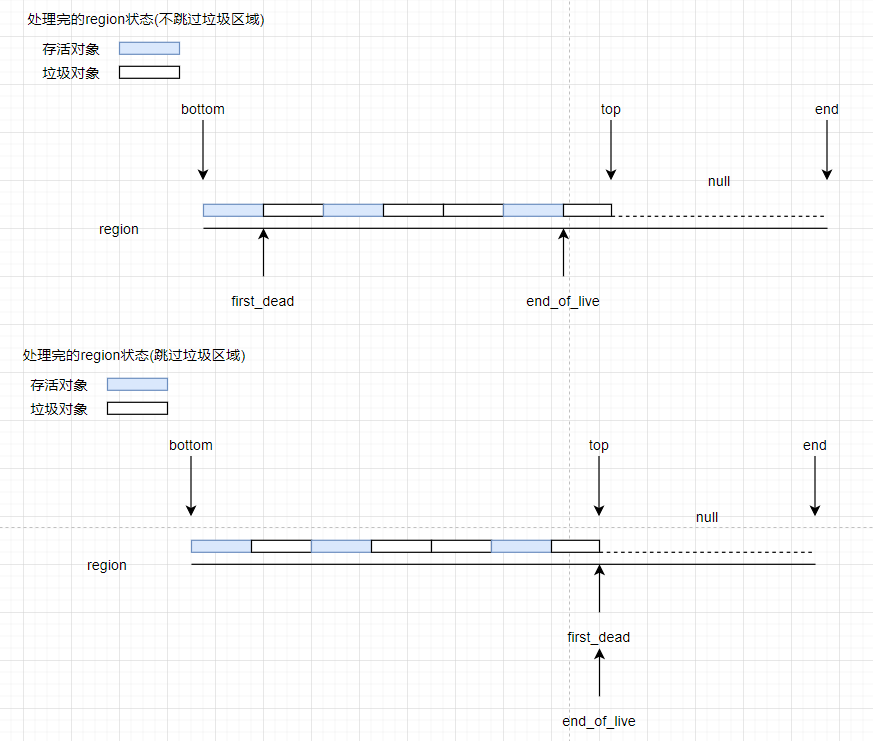
第二件事是在之前提到的forward()方法实现的,我们来一起看看:
HeapWord* CompactibleSpace::forward(oop q, size_t size,
CompactPoint* cp, HeapWord* compact_top) {
//计算当前还可使用的压缩的最大空间,即end - compact_top
size_t compaction_max_size = pointer_delta(end(), compact_top);
//判断需要的对象大小是否不大于可压缩的最大空间,如果大于则切换下一个region
while (size > compaction_max_size) {
cp->space->set_compaction_top(compact_top);
//获取下一段压缩空间,这里的space->调用的是CompactibleSpace派生类
//HeapRegion重写的方法返回的是下一个非大对象region
cp->space = cp->space->next_compaction_space();
// g1 space不为空这里跳过
if (cp->space == NULL) {
cp->gen = GenCollectedHeap::heap()->prev_gen(cp->gen);
assert(cp->gen != NULL, "compaction must succeed");
cp->space = cp->gen->first_compaction_space();
assert(cp->space != NULL, "generation must have a first compaction space");
}
compact_top = cp->space->bottom();
cp->space->set_compaction_top(compact_top);
cp->threshold = cp->space->initialize_threshold();
compaction_max_size = pointer_delta(cp->space->end(), compact_top);
}
//如果当前对象和计算的压缩位置不一样,则将压缩位置的指针保存到对象的markword中
if ((HeapWord*)q != compact_top) {
//这个方法是将压缩后的指针存储在对象的markword中
//这里其实是把压缩后的地址封装成markword替换掉原对象的markword
//等到第四步进行copy的时候直接取markword的地址即是计算压缩后的地址
q->forward_to(oop(compact_top));
} else {
//如果计算后的位置不变,即不需要移动,初始化对象markword,并将其原来位置的指针保存到markword中
q->init_mark();
}
//增加压缩位置
compact_top += size;
if (compact_top > cp->threshold)
cp->threshold =
cp->space->cross_threshold(compact_top - size, compact_top);
return compact_top;
}
到这里所有的对象都已经被处理,存活对象被压缩后的地址被封装成了markword,且已经替换了存活对象原本的markword,等待之后进行copy的时候直接取用即可。
接下来我们来看第三步:调整指针:
//调整指针
void G1MarkSweep::mark_sweep_phase3() {
G1CollectedHeap* g1h = G1CollectedHeap::heap();
GCTraceTime tm("phase 3", G1Log::fine() && Verbose, true, gc_timer());
GenMarkSweep::trace("3");
SharedHeap* sh = SharedHeap::heap();
//这里清除遍历ClassLoader的标记,后面遍历的时候还会开启
ClassLoaderDataGraph::clear_claimed_marks();
//遍历所有根对象,调整指针到新地址,用GenMarkSweep::adjust_pointer_closure闭包遍历调整指针
sh->process_strong_roots(true, // activate StrongRootsScope
false, // not scavenging.
SharedHeap::SO_AllClasses,
&GenMarkSweep::adjust_pointer_closure,
NULL, // do not touch code cache here
&GenMarkSweep::adjust_klass_closure);
//调整弱引用的指针,用GenMarkSweep::adjust_pointer_closure闭包遍历调整指针
g1h->ref_processor_stw()->weak_oops_do(&GenMarkSweep::adjust_pointer_closure);
//调整弱引用根的指针,用GenMarkSweep::adjust_pointer_closure闭包遍历调整指针
g1h->g1_process_weak_roots(&GenMarkSweep::adjust_pointer_closure);
//调整之前保存的非偏向锁的markword的指针
GenMarkSweep::adjust_marks();
//遍历所有region调整指针的闭包
G1AdjustPointersClosure blk;
g1h->heap_region_iterate(&blk);
}
//这里我们看几个调整指针的方式
//1.GenMarkSweep::adjust_pointer_closure闭包
//2.GenMarkSweep::adjust_marks()
//这两个方式最后会调用这个方法去调整指针
template <class T> inline void MarkSweep::adjust_pointer(T* p) {
//获取指针指向的对象,即解引用
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
//从对象markword中获取刚刚保存的计算压缩后对象的地址
oop new_obj = oop(obj->mark()->decode_pointer());
if (new_obj != NULL) {
//将指针指向新的地址
oopDesc::encode_store_heap_oop_not_null(p, new_obj);
}
}
}
//3.G1AdjustPointersClosure的闭包
//遍历所有region调整指针的闭包
bool doHeapRegion(HeapRegion* r) {
//大对象region
if (r->isHumongous()) {
if (r->startsHumongous()) {
oop obj = oop(r->bottom());
obj->adjust_pointers();
}
} else {
//普通region
r->adjust_pointers();
}
return false;
}
第三种调整指针的方式 G1AdjustPointersClosure闭包这里我们再单独拿出来讲下,最后会调用一个调整指针的方法宏,我们一起来看下:
//调整指针的宏
#define SCAN_AND_ADJUST_POINTERS(adjust_obj_size) {
HeapWord* q = bottom();
HeapWord* t = _end_of_live; /* Established by "prepare_for_compaction". */
if (q < t && _first_dead > q &&
!oop(q)->is_gc_marked()) {
//因为有些存活的对象初始化markword了,即没有移动位置,所以这里会处理第一个对象没被标记的情况
HeapWord* end = _first_dead;
//end为first_dead,如果first_dead大于q则证明第一个对象其实是存活的只不过不需要调整指针
//遍历后面的对象
while (q < end) {
//这个方法会获取对象所有属性的引用,并调整引用指向新的地址(原引用对象压缩后的地址)
//最后还是会调用MarkSweep::adjust_pointer方法
size_t size = oop(q)->adjust_pointers();
size = adjust_obj_size(size);
q += size;
}
//若first_dead等于t即end_of_live则表示存活对象是连续的
if (_first_dead == t) {
q = t;
} else {
//这里可以理解成读取之前写的LiveRange,跳过连续的垃圾区域
q = (HeapWord*)oop(_first_dead)->mark()->decode_pointer();
}
}
const intx interval = PrefetchScanIntervalInBytes;
while (q < t) {
/* prefetch beyond q */
Prefetch::write(q, interval);
//存活对象,调整指针
if (oop(q)->is_gc_marked()) {
size_t size = oop(q)->adjust_pointers();
size = adjust_obj_size(size);
q += size;
} else {
//这里可以理解成读取之前写的LiveRange,跳过连续的垃圾区域,将q赋值为连续垃圾区域后的存活对象
q = (HeapWord*) oop(q)->mark()->decode_pointer();
}
}
}
至此,所有的根引用已经指向了新的地址,所有的被标记过存活的对象的属性引用也指向了新的地址,这里的新的地址是指之前引用的对象压缩后的而地址。
然后我们来看下第四步:复制对象:
//第四步:复制对象
//现在所有的指针都被调整过了,需要移动对象了
void G1MarkSweep::mark_sweep_phase4() {
G1CollectedHeap* g1h = G1CollectedHeap::heap();
GCTraceTime tm("phase 4", G1Log::fine() && Verbose, true, gc_timer());
GenMarkSweep::trace("4");
//压缩复制对象的闭包
G1SpaceCompactClosure blk;
g1h->heap_region_iterate(&blk);
}
//直接看闭包主要处理方法
bool doHeapRegion(HeapRegion* hr) {
//大对象region
if (hr->isHumongous()) {
if (hr->startsHumongous()) {
oop obj = oop(hr->bottom());
if (obj->is_gc_marked()) {
//如果是存活的则初始化其markword
obj->init_mark();
} else {
//垃圾对象则不处理,因为在第二步时已经被回收
}
hr->reset_during_compaction();
}
} else {
//普通region,我们看下普通对象如何处理
hr->compact();
}
return false;
}
普通对象一样是使用了宏方法,我们一起看下:
//压缩空间方法宏
//复制所有存活的对象到他们新的空间
#define SCAN_AND_COMPACT(obj_size) {
HeapWord* q = bottom();
HeapWord* const t = _end_of_live;
debug_only(HeapWord* prev_q = NULL);
//第一个对象如果没被标记和第三步一样,先处理其第一个对象可能没有移动位置的情况
if (q < t && _first_dead > q &&
!oop(q)->is_gc_marked()) {
//如果first_dead = end_of_live,则设置q到end_of_live
//这里代表整齐的region不需要复制和压缩
if (_first_dead == t) {
q = t;
} else {
//否则将q移动到first_dead连续死亡区域之后
q = (HeapWord*) oop(_first_dead)->mark()->decode_pointer();
}
}
const intx scan_interval = PrefetchScanIntervalInBytes;
const intx copy_interval = PrefetchCopyIntervalInBytes;
//遍历
while (q < t) {
//如果没被标记则跳过连续垃圾区域,类似liveRange
if (!oop(q)->is_gc_marked()) {
q = (HeapWord*) oop(q)->mark()->decode_pointer();
} else {
//否则表示对象存活
Prefetch::read(q, scan_interval);
size_t size = obj_size(q);
//获取需要copy到目的地的地址
HeapWord* compaction_top = (HeapWord*)oop(q)->forwardee();
Prefetch::write(compaction_top, copy_interval);
//复制对象并重置markword
//将对象直接复制到之前计算的位置,覆盖垃圾区域
Copy::aligned_conjoint_words(q, compaction_top, size);
oop(compaction_top)->init_mark();
q += size;
}
}
//记录压缩之前是否是空的
bool was_empty = used_region().is_empty();
//压缩后重置region相关属性包括top和存活字节数等等
reset_after_compaction();
//压缩处理后如果是空的且压缩前不是空的则清理
if (used_region().is_empty()) {
if (!was_empty) clear(SpaceDecorator::Mangle);
} else {
if (ZapUnusedHeapArea) mangle_unused_area();
}
}
现在所有的存活对象已经整齐的排列在新的region中,之前region的相关属性也进行了重置,整个full gc的标记压缩清除阶段结束了,我们回顾一下主要的流程:
四.full gc收尾
整个full gc过程差不多结束了,当然还有一些收尾工作,我们一起来看下:
//一切的开始do_collection方法
bool G1CollectedHeap::do_collection(bool explicit_gc,
bool clear_all_soft_refs,
size_t word_size) {
//full gc前期工作,前面已经讲述过了
.....
//full gc
{
HandleMark hm; // Discard invalid handles created during gc
G1MarkSweep::invoke_at_safepoint(ref_processor_stw(), do_clear_all_soft_refs);
}
//我们看看收尾工作
//重建region集合,并将空的region加入free_list
rebuild_region_sets(false /* free_list_only */);
//将一些发现列表中没被删除的被发现引用入列
ref_processor_stw()->enqueue_discovered_references();
//跟踪内存使用
MemoryService::track_memory_usage();
//验证stw引用发现器没有引用记录
ref_processor_stw()->verify_no_references_recorded();
//删除已卸载类加载器的元空间,并清理loader_data图
ClassLoaderDataGraph::purge();
MetaspaceAux::verify_metrics();
//验证cm引用发现器没有引用记录
ref_processor_cm()->verify_no_references_recorded();
reset_gc_time_stamp();
//因为有些对象已经移动,所以我们要清除所有记忆集合和card,稍后我们将重建记忆集合
clear_rsets_post_compaction();
check_gc_time_stamps();
//如果有必要的话调整堆大小
resize_if_necessary_after_full_collection(explicit_gc ? 0 : word_size);
......
//重置热卡缓存
G1HotCardCache* hot_card_cache = _cg1r->hot_card_cache();
if (hot_card_cache->use_cache()) {
hot_card_cache->reset_card_counts();
hot_card_cache->reset_hot_cache();
}
//重建所有记忆集合,根据策略并发执行或单线程执行
if (G1CollectedHeap::use_parallel_gc_threads()) {
uint n_workers =
AdaptiveSizePolicy::calc_active_workers(workers()->total_workers(),
workers()->active_workers(),
Threads::number_of_non_daemon_threads());
workers()->set_active_workers(n_workers);
set_par_threads(n_workers);
ParRebuildRSTask rebuild_rs_task(this);
set_par_threads(workers()->active_workers());
workers()->run_task(&rebuild_rs_task);
set_par_threads(0);
reset_heap_region_claim_values();
} else {
RebuildRSOutOfRegionClosure rebuild_rs(this);
heap_region_iterate(&rebuild_rs);
}
//重新注册编译后的java方法代码(因为之前卸载了)
rebuild_strong_code_roots();
//计算元空间的新大小
if (true) { // FIXME
MetaspaceGC::compute_new_size();
}
//抛弃脏卡队列中的信息
JavaThread::dirty_card_queue_set().abandon_logs();
//重置young_list信息
_young_list->reset_sampled_info();
//增加旧标记(指full gc和并发标记)周期记录
increment_old_marking_cycles_completed(false /* concurrent */);
//验证hrs 和region set
_hrs.verify_optional();
verify_region_sets_optional();
verify_after_gc();
g1_policy()->start_incremental_cset_building();
//清理cset_fast_test
clear_cset_fast_test();
//重新初始化年轻代使用区域
init_mutator_alloc_region();
double end = os::elapsedTime();
//记录full gc结束(这个方法会设置开启youngGC标记表示full gc结束后开启youngGC和重置一些参数)
g1_policy()->record_full_collection_end();
if (G1Log::fine()) {
g1_policy()->print_heap_transition();
}
//更新内存大小(包括元空间)
g1mm()->update_sizes();
gc_epilogue(true);
}
//后面是打印一些日志
if (G1Log::finer()) {
g1_policy()->print_detailed_heap_transition(true /* full */);
}
print_heap_after_gc();
trace_heap_after_gc(gc_tracer);
post_full_gc_dump(gc_timer);
gc_timer->register_gc_end();
gc_tracer->report_gc_end(gc_timer->gc_end(), gc_timer->time_partitions());
}
return true;
}
至此整个full gc的流程结束了。
五.总结
通过对full gc的源码阅读,笔者对full gc的整个处理流程有了更深一步的了解,许多之前不清楚或者比较模糊的概念也有了清晰的认识。比如:元空间不够时也会触发full gc,markword的锁标记位和gc标记位是同样位置,那么在gc结束后怎么恢复之前的锁状态,标记压缩清理的压缩时引用怎么处理,压缩空间在哪里如何压缩等等。这些都是full gc算法的细节内幕,只有真正通过源码的学习才能有完整的答案,不过相信读者们看完本篇博客,心里应该会对这些问题有了答案。



