
JDK14-ZGC调研初探原创
我在性能调优路上的打怪日记
背景
公司ElasticSearch准备进行升级,而ElasticSearch7以上则是已经在支持使用JDK11了,JDK11中最大的特点就是 ZGC,更快的垃圾回收,更爽的**,你懂的;所以,调研zgc的特性以及使用方式就迫在眉睫,再加上jdk14也已经刚出不久,所以则是直接以JDK14为基础,进行了相关的测试和参考了相关的文献后,写了该文章,今天闲来无事,发布到博客上,供大家需要时参考时使用。
前言
Open JDK11引入了ZGC的垃圾收集器,而在JDK12中引入了 Shenandoah 收集器:
背景:在《深入理解JAVA虚拟机》文章中有提到,Shenandoah更像是一个原有的G1收集器的升级版本,且由于该收集器是来自于外部团队所进行开发的,所以Oracle自身的JDK版本是已经对外宣布不支持该Shenandoah收集器,转而重推自己所开发的ZGC收集器;所以关于Shenandoah收集器则全面迁移到了OpenJDK上,这也是少见的免费版的JDK功能,多于商业版OracleJDK功能的一次;
由于ZGC是Oracle官方主推的GC收集器,且ZGC收集器的特性与Shenandoah实现过于相似,所以此处关于JDK14GC收集器的使用,则直接以ZGC为基础进行相关调研;
建议在了解ZGC收集器之前,先来了解下CMS与G1收集器?为什么?
因为:CMS的并发标记的四个阶段 与G1的回收阶段以及ZGC的回收阶段过程全部相同,所有的对象清理阶段都是 初始标记,并发标记,最终标记 & 垃圾清除;而G1与ZGC这些后续升级的收集器最大的变动,其实也就是优化上述的四个阶段;比如 G1优化了CMS最终标记阶段为了解决跨代引用而导致的全堆扫描问题,而ZGC在G1的基础上则更加彻底的优化了上述的回收过程;当然为了优化上述的过程,从内存结构的分配到一些算法的实现改动是很大的,但目的是一致的,减少标记时间,减少清理时间;
CMS的收集器是JDK1.8之前的经典收集器,JDK1.8以后大力推广G1的收集器效果,而在JDK14中则完全抛弃了CMS收集器,转而重推号称
无论运行在任何量级的堆上都可以达到最大GC停顿时间不会超过10ms的ZGC收集器,那么为什么ZGC可以做到如此优异的回收效果?ZGC的演变历史是什么?以及后续我们如何在Java进程如何使用ZGC?如何在服务端调试以及优化ZGC?带着这些问题向下看即可;
注意:CMS是标记清除算法,而G1与ZGC则是标记整理算法,所以G1和ZGC也不会存在CMS的碎片问题;
JVM参数使用
JVM调试相关
查看当前JVM的默认收集器:java -XX:+PrintCommandLineFlags -version
查看当前进程的Heap概要信息,GC使用的算法等信息(JDK14中不再支持jmap的-heap参数): jmap -heap PID
输出当前JVM进程的所有JVM参数的值:jinfo -flags PID
JDK GC配置比对
配置当前JDK8的服务开启G1收集器
-Xmx108M
-Xms108M
-XX:MaxMetaspaceSize=112M
-XX:MetaspaceSize=112M
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-XX:+ParallelRefProcEnabled
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintHeapAtGC
-Xloggc:C:\Arnold\workSpace\GC\gc.log
配置当前JDK14的服务开启ZGC收集器
-XX:+UnlockExperimentalVMOptions
-XX:+UseZGC
-Xmx100M
-Xlog:gc*:C:\Arnold\workSpace\GC\jdk14gc.log
ZGC收集器已经不再推荐之前老的日志配置方式,比如:-XX:+PrintGCDetails,-Xloggc: 等等,这些老的参数
已经不再推荐使用,并且部分参数已经不在支持了,后续关于gcLog的配置统一使用一个参数即可:-Xlog:gc: ;
JDK警告如下:
[0.051s][warning][gc] -Xloggc is deprecated. Will use -Xlog:gc:C:\Arnold\workSpace\GC\jdk14gc.log instead.
[0.052s][warning][gc] -XX:+PrintGCDetails is deprecated. Will use -Xlog:gc* instead.
-Xlog:gc*: 此处的* 表示输出当前gc日志的详细信息,如果是直接配置:-Xlog:gc: 输出的日志结果将是非明细版;
jinfo对比
使用Jinfo查看当前JDK8的默认进程所有JVM参数如下:
C:\Program Files\Java\jdk1.8.0_201\bin>jinfo -flags 55888
VM flags: -XX:CICompilerCount=3 -XX:CompressedClassSpaceSize=109051904 -XX:ConcGCThreads=1 -XX:G1HeapRegionSize=1048576 -XX:InitialHeapSize=113246208 -XX:MarkStackSize=4194304 -XX:MaxGCPauseMillis=100 -XX:MaxHeapSize=113246208 -XX:MaxMetaspaceSize=117440512 -XX:MaxNewSize=67108864 -XX:MetaspaceSize=117440512 -XX:MinHeapDeltaBytes=1048576 -XX:+ParallelRefProcEnabled -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:+UseG1GC -XX:-UseLargePagesIndividualAllocation
Command line: -Xmx108M -Xms108M -XX:MaxMetaspaceSize=112M -XX:MetaspaceSize=112M -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+ParallelRefProcEnabled -javaagent:C:\Program Files\JetBrains\IntelliJ IDEA 2018.3.2\lib\idea_rt.jar=57080:C:\Program Files\JetBrains\IntelliJ IDEA 2018.3.2\bin -Dfile.encoding=UTF-8
JDK14进程所对应的JVM参数如下:
C:\Apps\openjdk-14.0.1_windows-x64_bin\jdk-14.0.1\bin>jinfo -flags 12268
VM Flags:
-XX:CICompilerCount=3 -XX:InitialHeapSize=65011712 -XX:MaxHeapSize=104857600 -XX:MinHeapDeltaBytes=2097152 -XX:MinHeapSize=8388608 -XX:NonNMethodCodeHeapSize=5832780 -XX:NonProfiledCodeHeapSize=122912730 -XX:ProfiledCodeHeapSize=122912730 -XX:ReservedCodeCacheSize=251658240 -XX:+SegmentedCodeCache -XX:SoftMaxHeapSize=104857600 -XX:+UnlockExperimentalVMOptions -XX:-UseCompressedClassPointers -XX:-UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:-UseLargePagesIndividualAllocation -XX:+UseZG
Jstat对比各收集器运行信息及内存分布信息
JDK8 G1如下:
C:\Program Files\Java\jdk1.8.0_201\bin>jstat -gc 55888 1000 10
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
0.0 0.0 0.0 0.0 6144.0 2048.0 104448.0 0.0 4480.0 775.8 384.0 76.4 0 0.000 0 0.000 0.000
0.0 0.0 0.0 0.0 6144.0 2048.0 104448.0 0.0 4480.0 775.8 384.0 76.4 0 0.000 0 0.000 0.000
JDK14 ZGC如下:
C:\Apps\openjdk-14.0.1_windows-x64_bin\jdk-14.0.1\bin>jstat -gc 12268 1000 10
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT CGC CGCT GCT
- - - - - - 8192.0 0.0 0.0 0.0 0.0 0.0 - - - - 0 0.000 0.000
- - - - - - 8192.0 0.0 0.0 0.0 0.0 0.0 - - - - 0 0.000 0.000
根据上述ZGC输出可知:
ZGC已经不再存在:S0C,S1C,S0U,S1U,EC,EU 这些概念,且也已经不再存在YGC,FGC这些概念,转而变更为了CGC;
所以,目前版本的ZGC是没有分代收集的概念的,当然不排除后续是否会添加分代的概念进去,但目前是不存在分代收集的,
详情看下方关于ZGC的详细介绍;
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
GC日志比对
通过窥看GC的Log日志,基本就可以大概了解当前的gc收集器的一些特点和原理,此处只截取一些重要的信息:
G1
ZGC
ZGC init
ZGC初始化信息,可以看到有提示:NUMA Support: Disabled,Large Page Support: Disabled,还有当前运行的线程并发线程数,Min Capacity: 8M 初始化容量,Pre-touch: Disabled等信息,而这些信息都是在ZGC中相对比较重要的概念;
[0.040s][info][gc,init] Initializing The Z Garbage Collector
[0.041s][info][gc,init] Version: 14.0.1+7 (release)
[0.041s][info][gc,init] NUMA Support: Disabled
[0.041s][info][gc,init] CPUs: 4 total, 4 available
[0.042s][info][gc,init] Memory: 3892M
[0.042s][info][gc,init] Large Page Support: Disabled
[0.042s][info][gc,init] Medium Page Size: N/A
[0.042s][info][gc,init] Workers: 1 parallel, 1 concurrent
[0.044s][info][gc,init] Address Space Type: Contiguous/Unrestricted/Complete
[0.044s][info][gc,init] Address Space Size: 1600M x 3 = 4800M
[0.044s][info][gc,init] Min Capacity: 8M
[0.044s][info][gc,init] Initial Capacity: 62M
[0.044s][info][gc,init] Max Capacity: 100M
[0.044s][info][gc,init] Max Reserve: 2M
[0.044s][info][gc,init] Pre-touch: Disabled
[0.046s][info][gc,init] Uncommit: Enabled, Delay: 300s
[0.063s][info][gc,init] Runtime Workers: 1 parallel
好消息是:在ZGC的JVM参数中,也就只有这么几个参数是很重要的概念,ZGC的JVM参数并不复杂,所以可调优的空间以及可调优的参数也相对不多;
PS:感觉后续未来JDK的GC发展,也越来越是向简单实用的方向发展,你只需要简单的配置几个JVM参数以后,JVM自身内部就会做很多的处理,且性能极高;
并且不会再像CMS等GC那样需要有较为繁琐的配置,既要关注配置多大的比例触发CMS才能保证回收效率和空间使用的双向合理,又要关注碎片整理等问题;
而在未来,我觉得,未来的GC配置基本上是可以做到不用调优的,因为所有的调优操作,JVM内部都已经帮你做过了;甚至于说为什么未来的GC不需要再手动的过分调优?因为1、GC内部已经会做自适应调优,2、JDK就已经不会再对外抛给你这么多可调有的参数给你用了,也就是你想调优就基本也没有什么可调优空间了;
当然不调优不意味着就不需要再了解它了,因为至少目前来看,一些并发线程的数量配置,内存的大小,还是要开发者自己关注并适配的,如果真的GC回收很慢怎么办,那你还是要手动调优的。至少要做到,通过对ZGC的实现原理的了解 + 查看相关的ZGC的日志,要能够定位到,是什么原因导致的很慢?内存太少?数据太多?并发线程数太少?等等,只有定位到相关的问题后,才能有依据的修改对应的参数进行排查和优化
ZGC >>> Phases,Ref,heap
注意:我这里是直接拿的第一次垃圾回收的完整片段Copy过来的,所以可以看到下面的GC日志都是GC1,而对于GC0,和后续的所有GC日志,其实本质上都是相同的回收阶段和格式,所以直接看这一个片段即可;
1、开始GC回收Start
[1.432s][info][gc,start ] GC(1) Garbage Collection (Allocation Stall)
2、清除所有的对象软引用链接(这里实际上以及是涉及到ZGC的实现原理了,也就是后续下面一个标题ZGC的特点实现上那些比较概念化的东西,而这里的日志实际上就是最好的概念化的具体体现)
[1.433s][info][gc,ref ] GC(1) Clearing All SoftReferences
3、具体的回收阶段:
3.1.1、初始化标记阶段、与CMS和G1的初始化标记相同(就是标记我们GC ROOT所能引用到的对象),但是请注意,此处可以可以看到是:Pause Mark Start 也就说此处的初始化标记是STW的,这说明ZGC也并没有完全做到真正的并发执行,完全无用户线程停顿这样一个效果,但是可以看到,尽管是STW的,但是时间非常短暂,只有0.1毫秒,所以该STW阶段的耗时,基本可以忽略不计了;
[1.433s][info][gc,phases ] GC(1) Pause Mark Start 0.124ms
3.1.2、并发标记阶段:有没有觉得特别像CMS的回收特点?由于是并发标记所以此处并不是STW的,对用户线程无影响;但耗时较长
[1.436s][info][gc,phases ] GC(1) Concurrent Mark 3.394ms
3.1.3、初始化标记结束,也是当前已经看到的第二个STW的阶段了;但此处的耗时也是极短的;
[1.436s][info][gc,phases ] GC(1) Pause Mark End 0.018ms
3.1.4、并发的处理非强引用的关联对象
[1.437s][info][gc,phases ] GC(1) Concurrent Process Non-Strong References 0.417ms
3.1.5、由于ZGC所采用的管理单位是以Region为一个单位,所以此处所做的事情就是标记后续需要进行整理回收的Region集合,便于后续进行Region的整理回收;
[1.437s][info][gc,phases ] GC(1) Concurrent Reset Relocation Set 0.002ms
[1.437s][info][gc ] Allocation Stall (main) 4.599ms
[1.437s][info][gc ] Allocation Stall (Monitor Ctrl-Break) 4.022ms
[1.440s][info][gc,phases ] GC(1) Concurrent Select Relocation Set 2.786ms
第三次SWT的阶段:开始进行Region集合的移动
[1.441s][info][gc,phases ] GC(1) Pause Relocate Start 0.251ms
//TODO:
[1.443s][info][gc,phases ] GC(1) Concurrent Relocate 1.336ms
[1.444s][info][gc,load ] GC(1) Load: 0.00/0.00/0.00
[1.444s][info][gc,mmu ] GC(1) MMU: 2ms/73.4%, 5ms/89.3%, 10ms/94.1%, 20ms/95.2%, 50ms/98.1%, 100ms/98.7%
[1.444s][info][gc,marking ] GC(1) Mark: 1 stripe(s), 2 proactive flush(es), 1 terminate flush(es), 0 completion(s), 0 continuation(s)
[1.444s][info][gc,reloc ] GC(1) Relocation: Successful, 1M relocated
[1.444s][info][gc,nmethod ] GC(1) NMethods: 182 registered, 0 unregistered
[1.444s][info][gc,metaspace] GC(1) Metaspace: 6M used, 6M capacity, 6M committed, 8M reserved
[1.444s][info][gc,ref ] GC(1) Soft: 29 encountered, 25 discovered, 16 enqueued
[1.444s][info][gc,ref ] GC(1) Weak: 77 encountered, 63 discovered, 7 enqueued
[1.444s][info][gc,ref ] GC(1) Final: 0 encountered, 0 discovered, 0 enqueued
[1.444s][info][gc,ref ] GC(1) Phantom: 7 encountered, 5 discovered, 1 enqueued
[1.444s][info][gc,heap ] GC(1) Min Capacity: 8M(8%)
[1.444s][info][gc,heap ] GC(1) Max Capacity: 100M(100%)
[1.444s][info][gc,heap ] GC(1) Soft Max Capacity: 100M(100%)
[1.444s][info][gc,heap ] GC(1) Mark Start Mark End Relocate Start Relocate End High Low
[1.444s][info][gc,heap ] GC(1) Capacity: 100M (100%) 100M (100%) 100M (100%) 100M (100%) 100M (100%) 100M (100%)
[1.444s][info][gc,heap ] GC(1) Reserve: 2M (2%) 2M (2%) 2M (2%) 2M (2%) 2M (2%) 2M (2%)
[1.444s][info][gc,heap ] GC(1) Free: 0M (0%) 0M (0%) 86M (86%) 90M (90%) 90M (90%) 0M (0%)
[1.444s][info][gc,heap ] GC(1) Used: 98M (98%) 98M (98%) 12M (12%) 8M (8%) 98M (98%) 8M (8%)
[1.444s][info][gc,heap ] GC(1) Live: - 1M (1%) 1M (1%) 1M (1%) - -
[1.444s][info][gc,heap ] GC(1) Allocated: - 0M (0%) 6M (6%) 10M (10%) - -
[1.444s][info][gc,heap ] GC(1) Garbage: - 96M (97%) 6M (7%) 0M (1%) - -
[1.444s][info][gc,heap ] GC(1) Reclaimed: - - 90M (90%) 96M (96%) - -
[1.444s][info][gc ] GC(1) Garbage Collection (Allocation Stall) 98M(98%)->8M(8%)
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
G1特点
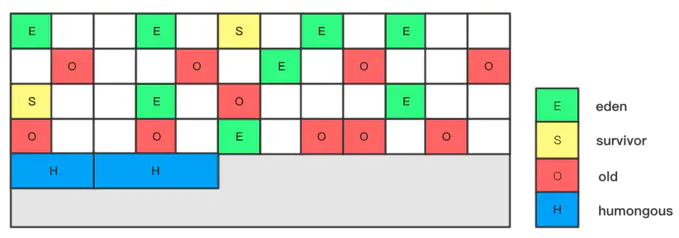
- G1采用内存划分多个大小相等的Region(默认512K)来进行对象的存储和划分,同时每个Region被标记成E、S、O、H,分别表示Eden、Survivor、Old、Humongous。其中E、S属于年轻代,O与H属于老年代,H表示巨型对象,当分配的对象大于等于Region的一半时就会被认为是巨型对象
-
Q:何时触发年轻代GC?
A:G1的GC回收仍然是分为两种,年轻代GC和年老代GC,年轻代Young GC的触发条件是:当Eden区不能够再分配新的对象时进行触发Young GC;触发的动作与其它的年轻代GC收集器相同,分别是:Eden区未被回收的对象会移动到Survivor区域,同时Survivor判断对象的晋升年龄,符合则晋升至Old; -
Q:何时触发年老代GC?
A:年老代回收在G1中被称作为Mixed GC(混合回收),回收所有年轻代的Region + 部分年老代的 Region;Mixed GC可以通过XX:InitiatingHeapOccupancyPercent参数来设置老年代占整个堆的比例,默认是45%,当达到这个比例时,则会触发Mixed GC; -
Q:Mixed GC为什么只会回收部分年老代?回收的判断依据是什么?
A:G1中可以通过指定-XX:MaxGCPauseMillis参数来指定G1的目标停顿时间,默认是200ms;当进行年老代的回收时,G1自身会有一个停顿预测模型,它会有选择的挑选部分Region,去尽量满足所设置的停顿时间,所以回收部分年老代的依据是根据所对应的目标停顿时间来进行分析后回收的; -
Full GC:当Mixed GC的回收速度,赶不上应用程序申请内存的速度,此时Mixed G1就会降低到Full GC,使用Serial GC收集器进行回收;
所以如果的确触发了Full GC,那么只能说明:- 当前机器的内存的确不足以支撑现有的并发了,也就是要加内存了,
- G1的目标停顿时间设置不合理,导致每次Mixed GC为了满足目标停顿时间的要求,每次都只能回收少量的内存,最终导致并发回收处理的过程中,新增对象导致内存空间耗尽所引发的Full GC;
- 调整对应的并发线程数量等可优化参数
G1相比CMS的提升
-
相比于CMS的纯分代回收的概念,G1所引入的Region内存块结构是一个本质的变化,基于Region来设计对象分配才能引起后续的所有变化;
-
跨代引用的问题:无论是CMS还是G1,都会出现新生代对象存在引用老年代对象,以及老年代对象存在引用新生代对象的问题,对于这种跨代引用的问题,CMS与G1的处理方式分别是什么?
- 在CMS中存在四个回收阶段,分别是初始标记(STW),并发标记,重标记(STW),并发清理。由于并发标记的过程中用户线程与GC线程是同时执行的,所以在并发标记的过程中就无法保证已经标记过的对象,在后续的用户线程的操作中,是否重新进行了新的引用;也就是当前并发标记阶段已经被标记为不可达的对象,可能存在被用户线程重新触发然后导致对象可达了;所以为了避免进行错误的对象回收,在并发标记后的重标记,则是进行最后一次可达性分析,且为了避免并发标记所会导致的用户线程问题,所以重标记过程中是STW的;由于存在跨代引用的问题,所以在CMS进行重标记的时候不能只是以老年代的对象为根,判断对象是否存在引用,因为还存在当前这个老年代对象被新生代对象引用的情况,所以CMS重标记阶段唯一的做法就是扫描全堆,由于是扫描全堆进行可达性分析,且此时的重标记阶段是STW的,所以此处在进行CMS回收时,将会异常耗时;(不过CMS中有提供重标记执行前先执行一下新生代的回收等操作,但尽管如此仍然不能解决全堆STW扫描而带来的耗时问题)
- G1采用pre-write barrier解决跨代问题。在并发标记阶段,当引用关系发生变化的时候,通过pre-write barrier函数会把这种这种变化记录并保存在一个队列里,在remark阶段会扫描这个队列,通过这种方式,旧的引用所指向的对象就会被标记上,其子孙也会被递归标记上,这样就不会漏标记任何对象从而解决Remark阶段全堆扫描的问题;
-
G1的停顿预测模型,根本性提升,,由于G1是采用Region内存块的方式进行设计,所以在触发Mixed GC后G1可以通过满足只回收一部分老年代的方式,来尽可能满足所设置的应用停顿时间,由于每次的Mixed GC的回收时间都可以控制在停顿时间之内,所以G1就很牛逼了;
ZGC特点:
ZGC为什么可以做到比G1更快的回收效果?
- 实现了并发标记 &并发清理 (G1由于是只回收部分Region且内部有自己的停顿预测模型,所以可以控制清理时的回收时间;但G1本质上在清理过程中还是并行清理的,而ZGC则做到了真正的并发清理,也就是清理过程中无需停止用户线程;)
- 动态Region,相比于G1每个Region都是512K的特点,在ZGC中Region分为小型Region(Small Region)容量固定2MB,用户存储小于256K的对象,中型Region(Medium Region)容量大小为32MB,用于存放大于256KB小于4MB的对象,大型Region,容量不固定,可以动态变化,但必须是2MB的整数倍;通过采用动态Region的方式可以更好的处理大对象的分配等问题;
3.支持Numa架构
4.ZGC目前是没有分代的,全堆扫描,所以也不用像G1那样需要维护一套Remember来跟踪跨代引用的问题(但其实理论上来说,如果ZGC实现了分代回收,那么其效率将会更高,毕竟在初始标记等阶段就不用再扫描全堆了,而其它的过程则又做到了并发处理,但也就意味着ZGC需要有一套自己更加便捷的跨代回收的方案,所以目前来看这是一种取舍了;不过官方回应是会在后续增加分代回收的功能的,只是目前还没有完美的解决方案)
通过CMS 以及 G1可以发现,对象的回收过程一般是:初始标记,并发标记,重标记,清理 这4个阶段,而G1通过停顿预测模型以及通过pre-write barrier解决跨代问题来以此优化了GC的回收效率;而ZGC则在G1之上,还解决了清理的问题,将其变更为了并发清理,这是一个很大的突破(清理过程中不再是STW的了),ZGC既然已经解决了并发标记和并发清理的问题,那么唯一还存在STW的过程则是初始标记阶段,而初始标记主要做的事情则是以Root为根对象做集合扫描:Java中Root根一般是虚拟机栈中的引用对象,方法区中静态属性引用的对象,JNI中引用的对象,方法区中的引用对象;所以GC初始化标记过程中则是与Java堆中的对象数量无关的,也就是说无论我们的Java堆是有1G的大小,还是有10G的大小,对我们在初始化标记时的影响是有限的,初始化标记时的耗时顶多会和当前JVM的线程的多少,线程栈的大小等进行变化,而和Java堆的对象数量则并没有任何关系;
所以,看到这里,我们就应该可以理解了为什么ZGC可以有胆量说,我们的GC回收过程中停顿时间绝对不会超过10ms的原因(注意:是停顿时间不会超过10ms,而不是整体回收时间不会超过10ms),因为从目前来看,真正会涉及到停顿时间的也只有,初始化标记过程,而初始化标记过程由于是和堆的大小以及数量是没有关系的,所以这也才是ZGC之所以可以对外宣传说,ZGC可以完全不受堆大大小限制,无论是运行在10G还是100G的堆上,ZGC都可以保证整个回收的停顿时间都不会超过10ms的原因;
当然,ZGC想要达到这样的效果,实现起来则肯定没有那么简单:
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
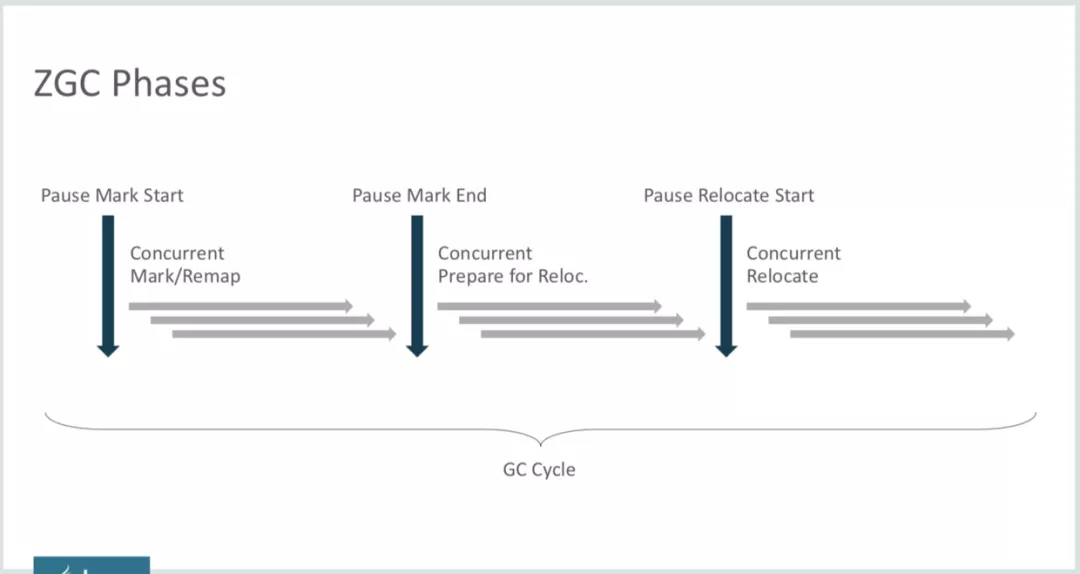
ZGC的垃圾回收过程:
- 初始标记(stw)
- 并发标记
2.1 并发标记后还会有一次短暂的stw暂停(Pause Mark End)详情看上述的ZGC日志分析; - 并发预备重分配
3.1 并发预备重分配后也还会有一次swt的暂停(Pause Relocate Start)详情看上述的ZGC日志分析 - 并发重分配
- 并发重映射
通过以上几个阶段可以得知,ZGC在实际的回收过程中,是有三次STW阶段的,但是由于都与Java堆的对象大小没有直接关系,所以stw的暂停时间也是极短的,整体下来仍然会满足ZGC的宣传口号,“不在意任何堆的大小都可以小于10ms”;
Q:ZGC是如何实现并发的清理对象的?
A:这里涉及到一些很重的概念,也就是ZGC的一些核心概念,GC屏障 以及 染色指针技术;(这部分内容很原理化,所以此处则不再文章中重复赘述,关于染色指针和GC屏障的原理直接参考文章后续的参考链接即可)
Q:为什么ZGC当前最大的管理堆内存不会超过4TB?
A:首先4TB的内存,其实对于目前的大多数场景都已经是足够了,毕竟还有分布式节点呢。。。所以ZGC可以直接管理4TB的内存且还保持10ms的停顿特性,这已经很强了;但是深究为什么ZGC只能管理不超过的4TB的内存?原因其实还是和ZGC内部所使用到的染色指针的技术相关(染色指针是一种直接将少量额外的信息存储在指针上的技术,目前在Linux下64位的操作系统中高18位是不能用来寻址的,但是剩余的46位却可以支持64T的空间,到目前为止我们几乎还用不到这么多内存。于是ZGC将46位中的高4位取出,用来存储4个标志位,剩余的42位可以支持4TB(2的42次幂)的内存,也就直接导致ZGC可以管理的内存不超过4TB)
ZGC的触发阶段
- rule_timer第一个策略,从行为表现上,我把它叫做是周期性GC,默认是不生效的,但是如果配置-XX:ZCollectionInterval=1(单位是秒),那么每隔1s,就会执行一次ZGC;
- rule_warmupJVM启动之后,如果一直没有发生过GC,那么会在堆内存使用超过10%、20%、30%时,分别触发一次GC,这样做是为了收集一些GC相关的数据,为后面的条件规则提供数据支撑。
- rule_allocation_rate根据对象分配速率决定是否GC。如果当前的可用堆内存,根据估计出来的对象最大分配速率,很快会被耗尽,则执行一次GC,这种策略一般在qps很高、对象分配很快时会被触发。
- rule_proactive这个策略是积极主动型的。如果能够接受因为GC引起的应用吞吐量下降,那么就触发GC,这个策略允许我们降低堆内存,并且在堆内存还有很多剩余空间时,执行引用处理,具体的条件是(1、自从上次GC之后,堆的使用量至少涨了10%; 2、
自从上次GC之后,已经过去5分钟没有发生GC)
ZGC 参数配置
ZGC现有的对外所提供的一些参数信息:
| General GC Options | ZGC Options | ZGC Dianostic Options (-XX:+UnlockDianosticVMOptions) |
|---|---|---|
| -XX:MinHeapSize, -Xms | -XX:ZAllocationSpikeTolerance | -XX:ZProactive |
| -XX:InitialHeapSize, -Xms | -XX:ZCollectionInterval | -XX:ZStatisticsForceTrace |
| -XX:MaxHeapSize, -Xmx | -XX:ZFragmentationLimit | -XX:ZStatisticsInterval |
| -XX:SoftMaxHeapSize | -XX:ZMarkStackSpaceLimit | -XX:ZVerifyForwarding |
| -XX:SoftRefLRUPolicyMSPerMB | -XX:ZPath | -XX:ZVerifyMarking |
| -XX:+UseNUMA | -XX:ZUncommit | -XX:ZVerifyObjects |
| -XX:ZUncommitDelay | -XX:ZVerifyRoots | |
| -XX:ZVerifyViews |
参数解释:
-XX:ConcGCThread:并发执行的GC线程数,默认JVM启动的时候会设置为当前CPU核数的12.5%(注意,是并发线程数,也就是意味着配置的越大,那么用户线程的吞吐量就会变低,因为GC的线程会和应用线程存在抢占CPU的情况)
-XX:ParallelGCThreads:GC ROOT的标记和移动时,也就是上述提到的3个STW的情况时,会使用该参数所配置的线程数来进行并行执行;(由于此参数所配置的线程数是STW期间并行执行的,所以相对来说多多益善喽,不要超过CPU核数就行,默认情况下如果不设置默认为当前CPU核数的60%)
-XX:ZUncommit:这个参数很有意思,将会打破我们之前对Xmx和Xms最好配置为相等的这个观念,以前在使用CMS,ParallelOld等GC时,默认情况下如果Xms和Xmx不一致,将会导致gc时的频繁扩张,直到触发到顶值也就是Xmx所配置的值;所以为了避免扩张,我们一般都会建议将Xmx和Xms配置为相同值;并且原有的JVM GC,即使GC后回收了很多的多余空间,JVM也不会把这部分空间归还给操作系统,也就是这部分内存尽管目前不会用到但也将一直被JVM所占据;但是现在不同了!配置开启当前Zuncommit参数后,默认情况下ZGC会把不再使用的内存归还给操作系统,这样对于特别在意内存占用情况的服务器或者说云服务器就特别有用了,内存资源的回收也就意味着云服务器的使用资源费率也将会降低;不过!!无论如何归还,最终JVM也会保留Xms参数所指定的内存大小;也就是说如果Xms和Xmx配置一致,则该参数就基本没用了;(合理的配置Xms的值将会特别有益于云服务器等)
-XX:ZUncommitDelay:默认300秒,这个参数表示不再使用的内存最多延迟多少时间后再归还给操作系统,配合上述参数使用;
-Xlog:gc*: 配置gc参数输出位置,gc* 表示输出detail gc日志详情;
-XX:+UnlockExperimentalVMOptions: 表示开启ZGC
-XX:+UseZGC:表示开启ZGC
-XX:+UseNUMAZGC:默认是开启支持NUMA的,不过,如果JVM探测到系统绑定的是CPU子集,就会自动禁用NUMA。我们可以通过参数-XX:+UseNUMA显示启动,或者通过参数-XX:-UseNUMA显示禁用。如果运行在NUMA服务器上,并且设置-XX:+UseNUMA,那对性能提升是显而易见的。
配置一个自用的ZGC参数
简单说明下,在ZGC的官网介绍上基准测试中的32和服务器,128G堆的情况下,配置的ConcGCThread是4,配置的ParallelGCThreads是20;
而这两个参数又恰恰是决定了ZGC回收并发&并行回收效率的很大一个变量,所以,我建议,在对自身应用服务的对象使用情况还不是很清晰的情况下,可以考虑使用默认的JVM值,也就是建议先不配置该值,避免弄巧成拙,如果后续gc的效率存在问题,则可以考虑观察堆对象的生命周期以及gc的日志来确定最优的配置方案;(注:官方对外给出的最大不会超过10ms的停顿时间,是在最优配置参数的情况下得到的结果,如果不合理的参数配置,导致gc回收停顿时间较长,那这个只能说是自身的问题的了、、、)
默认情况下直接配置如下的ZGC参数,其实就完事了:
-XX:+UnlockExperimentalVMOptions
-XX:+UseZGC
-XX:+UseNUMA
-Xms1g
-Xmx2g
-Xlog:gc*:C:\Arnold\workSpace\GC\jdk14gc.log
通过上述我们对ZGC的内部机制实现了解,就不会再出现直接环境上使用ZGC的回收器出现盲目慌乱的情况,毕竟了解他的机制和扩展过程,以及优化方式,就不会再存在任何好担心的情况了。
部分名词解释
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
STW
GC过程中常听到的STW的含义实际上:Stop-The-World 也就是说在GC线程的回收过程中是要暂用户的线程执行的,由于需要停止掉用户的线程执行,所以在此期间整个应用程序是处于停顿状态;
并行和并发的区别
上述在CMS以及G1和ZGC的部分内容说明中都提到了很多次的并行和并发的概念,此处做下相关解释:并行和并发实际上都是多个线程同时执行,但是在此处的JVM GC场景中,并行一般是指的多个GC线程同时进行执行,这个叫做并行;而对于多个GC线程和用户线程同时执行,则叫做并发;所以,G1的清理阶段是并行的(stw),而cms和zgc则做到了并发的清理;
动态年龄计算机制
JVM中Eden区对象晋升至Old区时会涉及到一个对象动态年龄计算的问题,默认情况下当累积的某个年龄的对象大小超过了survivor区的一半时,则会取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值;(不过由于当前的ZGC是没有分代的,所以也就没有了晋升的概念了 ,但仍然适合于g1及cms处理器)
官方压测对比回收效果
官方已经进行过具体的压测对比了,此处跳过直接列举部分网络资源。
停顿时间方面,ZGC是100%不超过10ms的
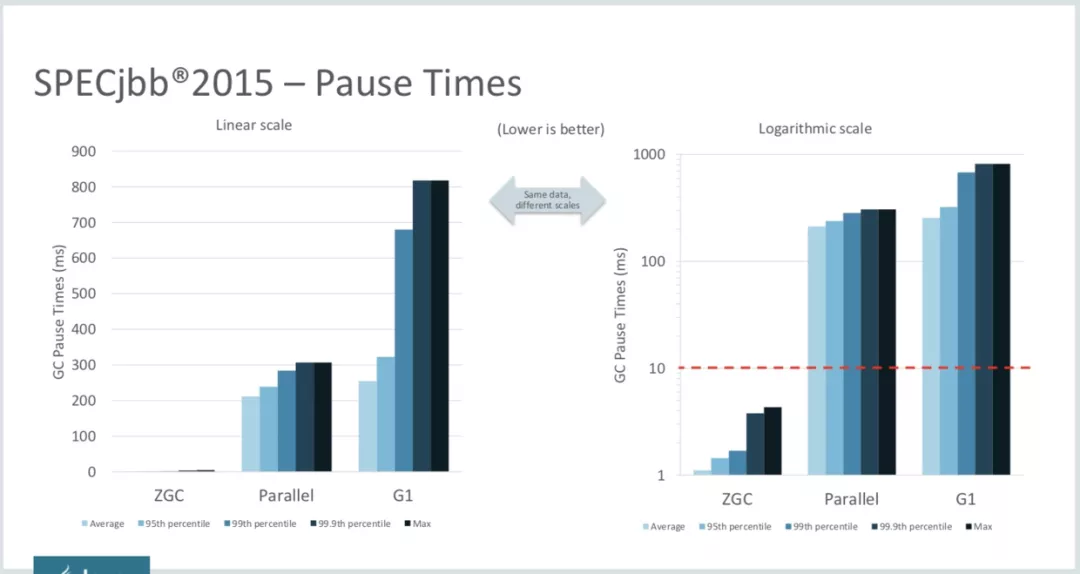
ZGC的垃圾回收方面,ZGC依然没有做到整个GC过程完全并发执行,依然有3个STW阶段,其他3个阶段都是并发执行阶段,对应的具体阶段,可以直接通过上面的日志分析就能得知
可参考外部链接
关于JDK14的新特性说明: https://zhuanlan.zhihu.com/p/98389056
关于ZGC的解读: https://www.zhihu.com/topic/20208311/hot
关于G1收集器解读:https://www.jianshu.com/p/548c67aa1bc0
HeapDump中关于ZGC的文章:https://heapdump.cn/search/all?keyword=zgc
注
g1日志及zgc日志注释说明待补充完善;



