
java中WAITING状态的线程为啥还会消耗CPU原创
背景
刚刚过去的双十一, 公司订单量又翻了一倍. 就在老板坐在办公室里面偷偷笑的同时,坐在工位上的我们却是一直瑟瑟发抖. 面对zabbix里面时不时蹦出来的一条条CPU告警,默默地祈祷着不要出问题.
当然, 祈祷是解决不了问题的, 即使是开过光的服务器也不行. CPU告警了, 还得老老实实地去看为啥CPU飚起来了.
接下来就是CPU排查三部曲
1. top -Hp $pid 找到最耗CPU的线程.
2. 将最耗CPU的线程ID转成16进制
3. 打印jstack, 到jstack里面查这个线程在干嘛
当然 如果你线上环境有装arthas等工具的话, 直接thread -n就可以打印出最耗cpu的n个线程的堆栈,三个步骤一起帮你做了.
最后找到最耗cpu的线程堆栈如下:
"operate-api-1-thread-6" #1522 prio=5 os_prio=0 tid=0x00007f4b7006f800 nid=0x1b67c waiting on condition [0x00007f4ac8c4a000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000006c10828c8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
at ch.qos.logback.core.OutputStreamAppender.subAppend(OutputStreamAppender.java:210)
at ch.qos.logback.core.rolling.RollingFileAppender.subAppend(RollingFileAppender.java:235)
at ch.qos.logback.core.OutputStreamAppender.append(OutputStreamAppender.java:100)
at ch.qos.logback.core.UnsynchronizedAppenderBase.doAppend(UnsynchronizedAppenderBase.java:84)
at ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:51)
at ch.qos.logback.classic.Logger.appendLoopOnAppenders(Logger.java:270)
at ch.qos.logback.classic.Logger.callAppenders(Logger.java:257)
at ch.qos.logback.classic.Logger.buildLoggingEventAndAppend(Logger.java:421)
at ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus(Logger.java:383)
at ch.qos.logback.classic.Logger.info(Logger.java:579)
...
值得一提的是, 类似的线程还有800多个… 只是部分没有消耗CPU而已
问题
很明显, 这是因为logback打印日志太多了造成的(此时应有一个尴尬而不失礼貌的假笑).
当大家都纷纷转向讨论接下来如何优化logback和打日志的时候.
我却眉头一皱, 觉得事情并没有那么简单:
这个线程不是被LockSupport.park挂起了, 处于WAITING状态吗? 被挂起即代表放弃占用CPU了, 那为啥还会消耗CPU呢?
来看一下LockSupport.park的注释, 明确提到park的线程不会再被CPU调度了的:
/**
* Disables the current thread for thread scheduling purposes unless the
* permit is available.
*
* <p>If the permit is available then it is consumed and the call
* returns immediately; otherwise the current thread becomes disabled
* for thread scheduling purposes and lies dormant until one of three
* things happens:
*
*/
public static void park() {
UNSAFE.park(false, 0L);
}
实验见真知
带着这个疑问, 我在stackoverflow搜索了一波, 发现还有不少人有这个疑问
上面好几个问题内容有点多, 我也懒得翻译了, 直接总结结论:
- 处于waittig和blocked状态的线程都不会消耗CPU
- 线程频繁地挂起和唤醒需要消耗CPU, 而且代价颇大
但这是别人的结论, 到底是不是这样的呢. 下面我们结合visualvm来做一下实验.
有问题的代码
首先来看一段肯定会消耗100%CPU的代码:
package com.test;
public class TestCpu {
public static void main(String[] args) {
while(true){
}
}
}
visualvm显示CPU确实消耗了1个核, main线程也是占用了100%的CPU:
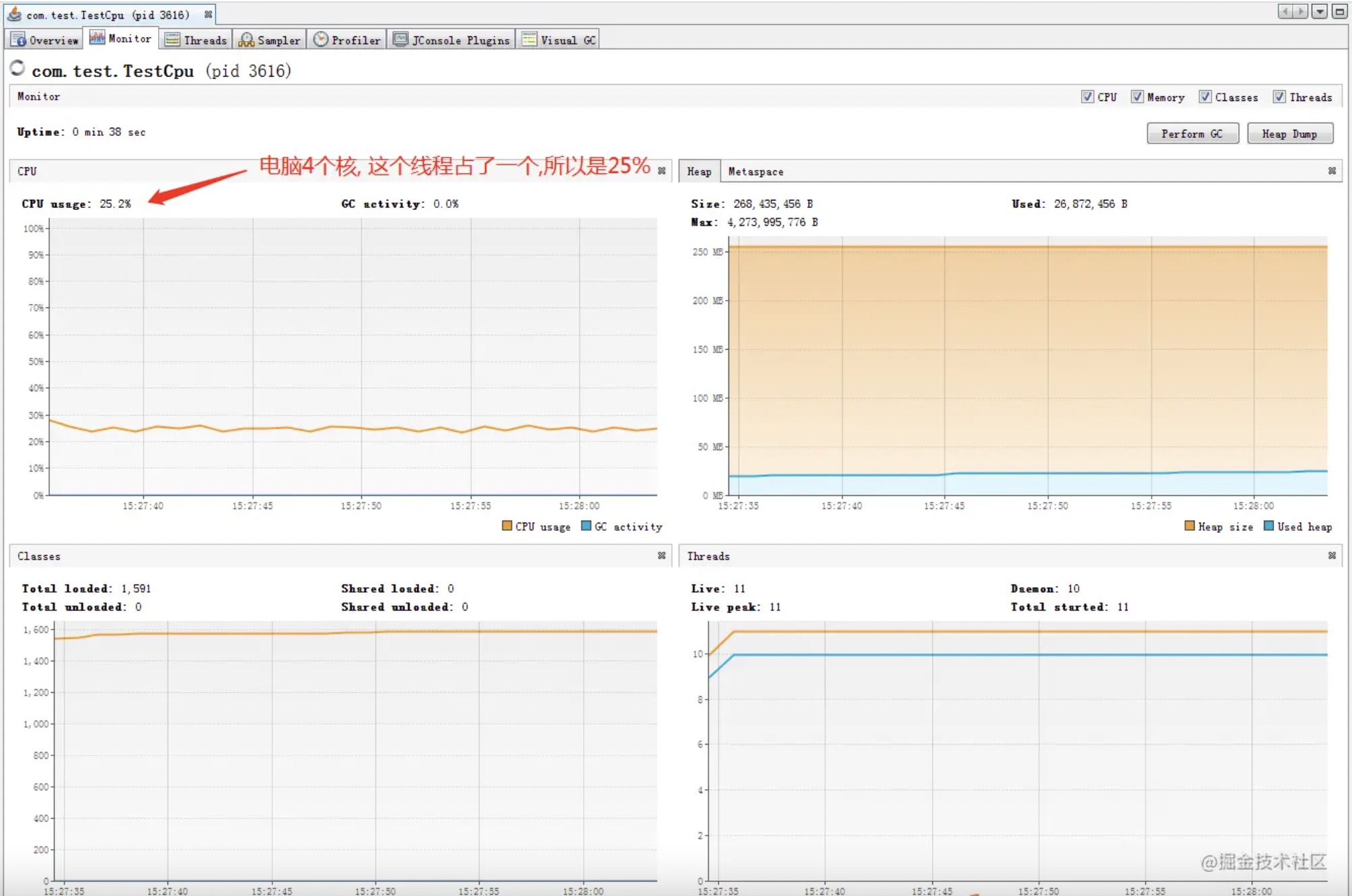
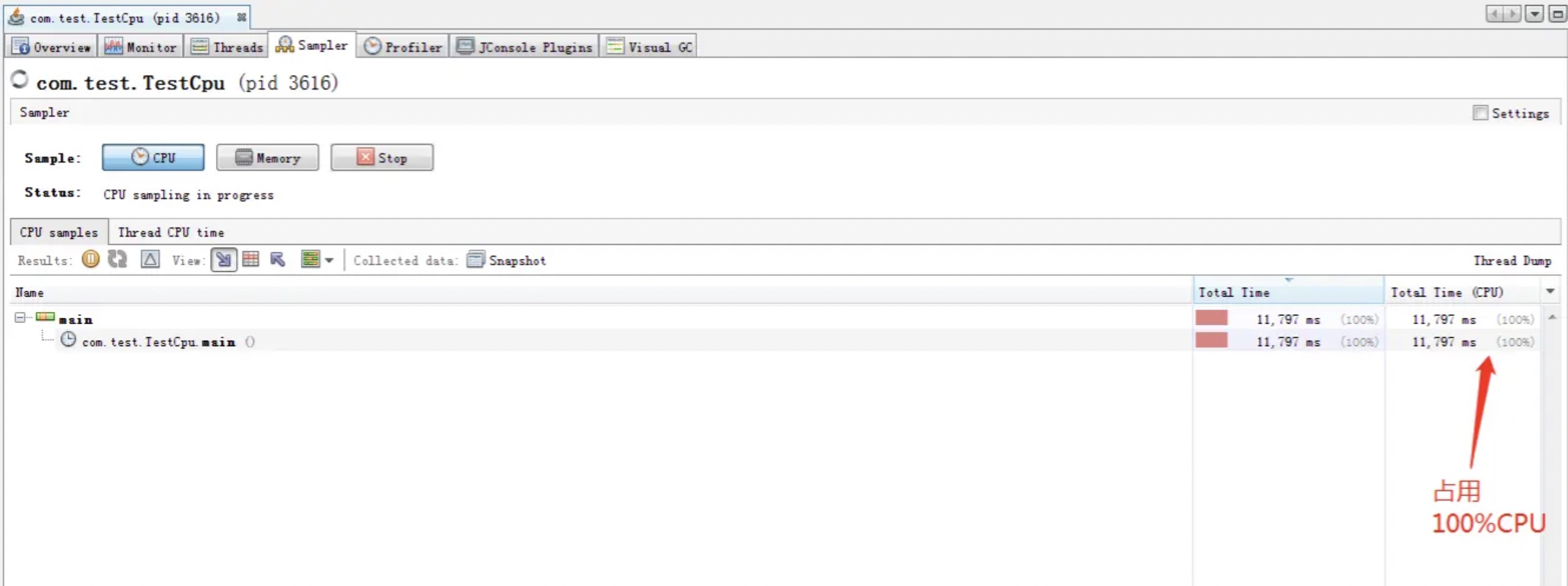
被park的线程
然后来看一下park的线程是否会消耗cpu
代码:
import java.util.concurrent.locks.LockSupport;
public class TestCpu {
public static void main(String[] args) {
while(true){
LockSupport.park();
}
}
}
visualvm显示一切波澜不惊,CPU毫无压力 :
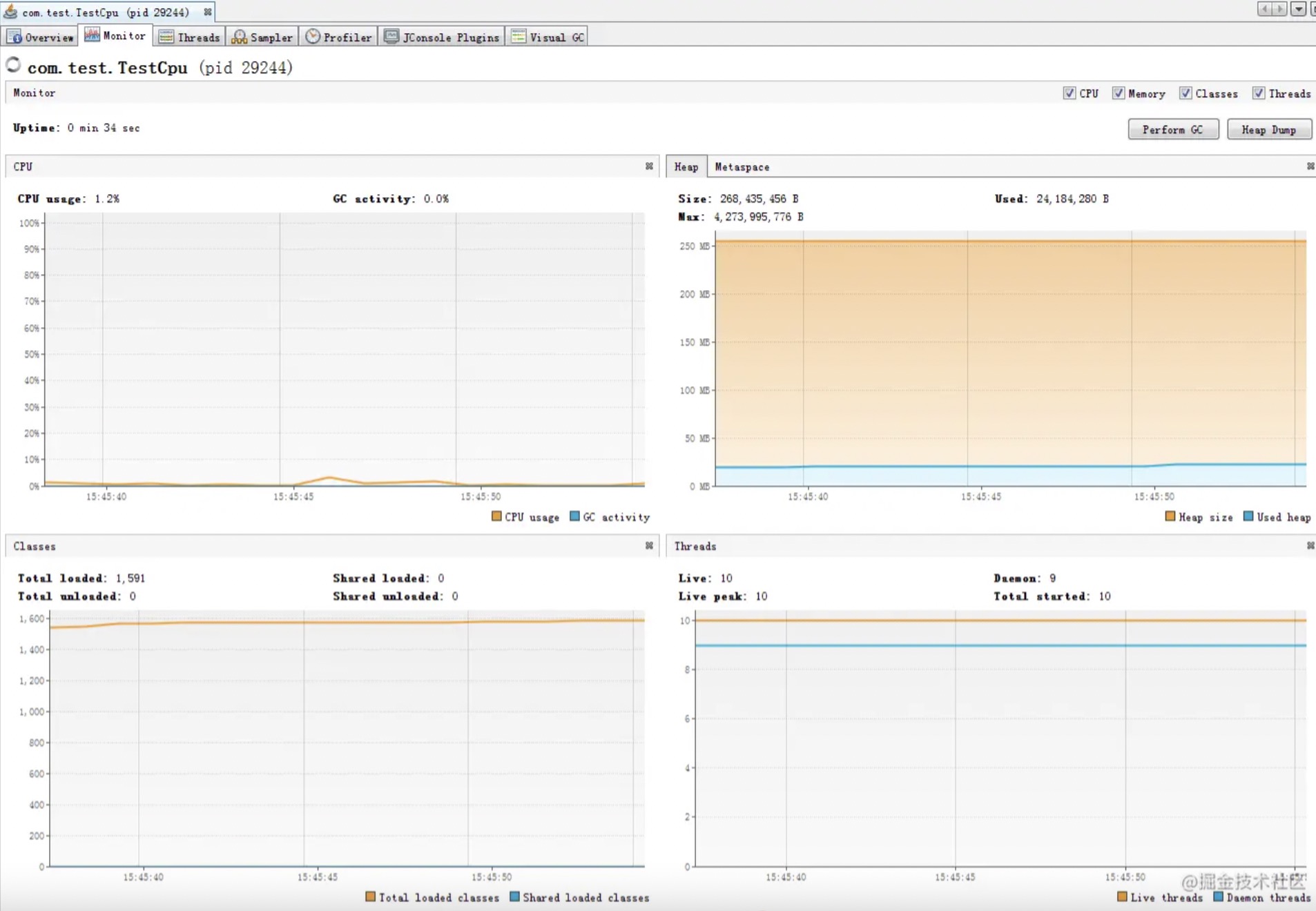
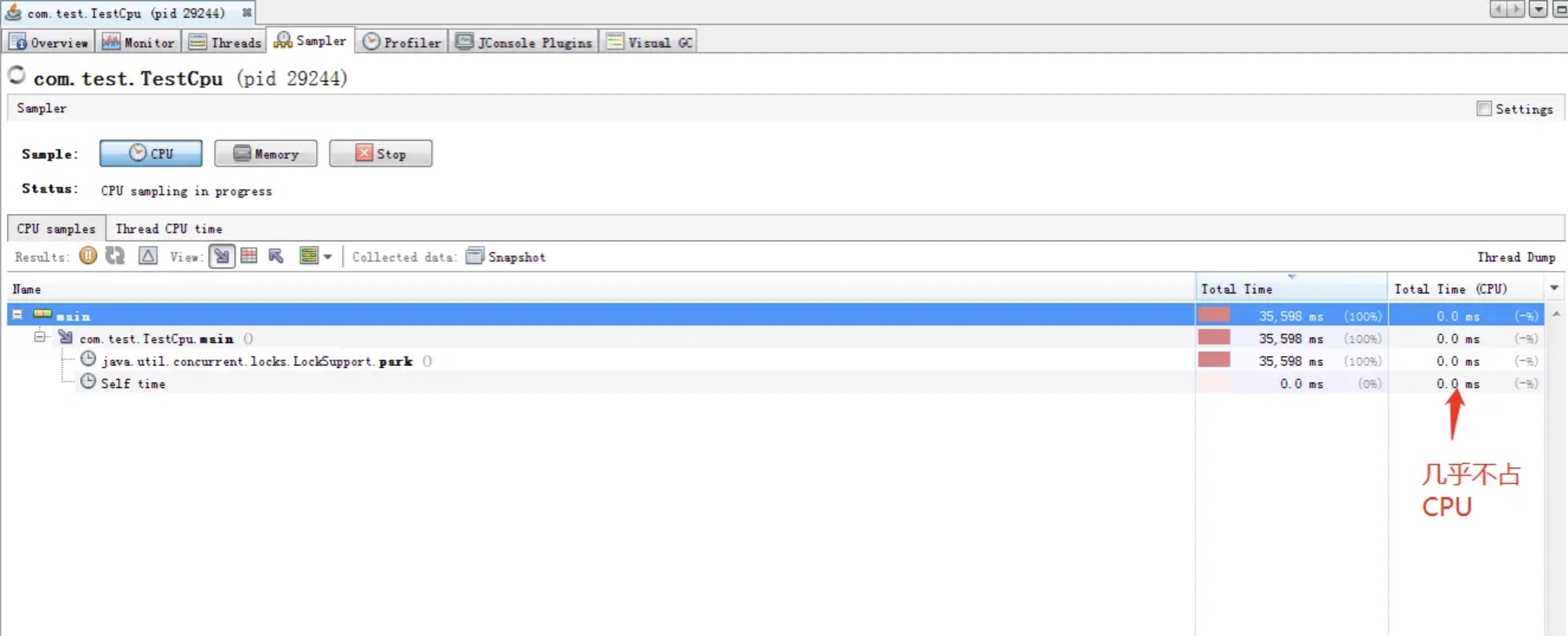
发生死锁的线程
再来看看blocked的线程是否消耗CPU. 而且我们这次玩大一点, 看看出现了死锁的话,会不会造成CPU飙高.(死锁就是两个线程互相block对方)
死锁代码如下:
package com.test;
public class DeadLock {
static Object lock1 = new Object();
static Object lock2 = new Object();
public static class Task1 implements Runnable {
@Override
public void run() {
synchronized (lock1) {
System.out.println(Thread.currentThread().getName() + " 获得了第一把锁!!");
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2) {
System.out.println(Thread.currentThread().getName() + " 获得了第二把锁!!");
}
}
}
}
public static class Task2 implements Runnable {
@Override
public void run() {
synchronized (lock2) {
System.out.println(Thread.currentThread().getName() + " 获得了第二把锁!!");
synchronized (lock1) {
System.out.println(Thread.currentThread().getName() + " 获得了第一把锁!!");
}
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(new Task1(), "task-1");
Thread thread2 = new Thread(new Task2(), "task-2");
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(Thread.currentThread().getName() + " 执行结束!");
}
}
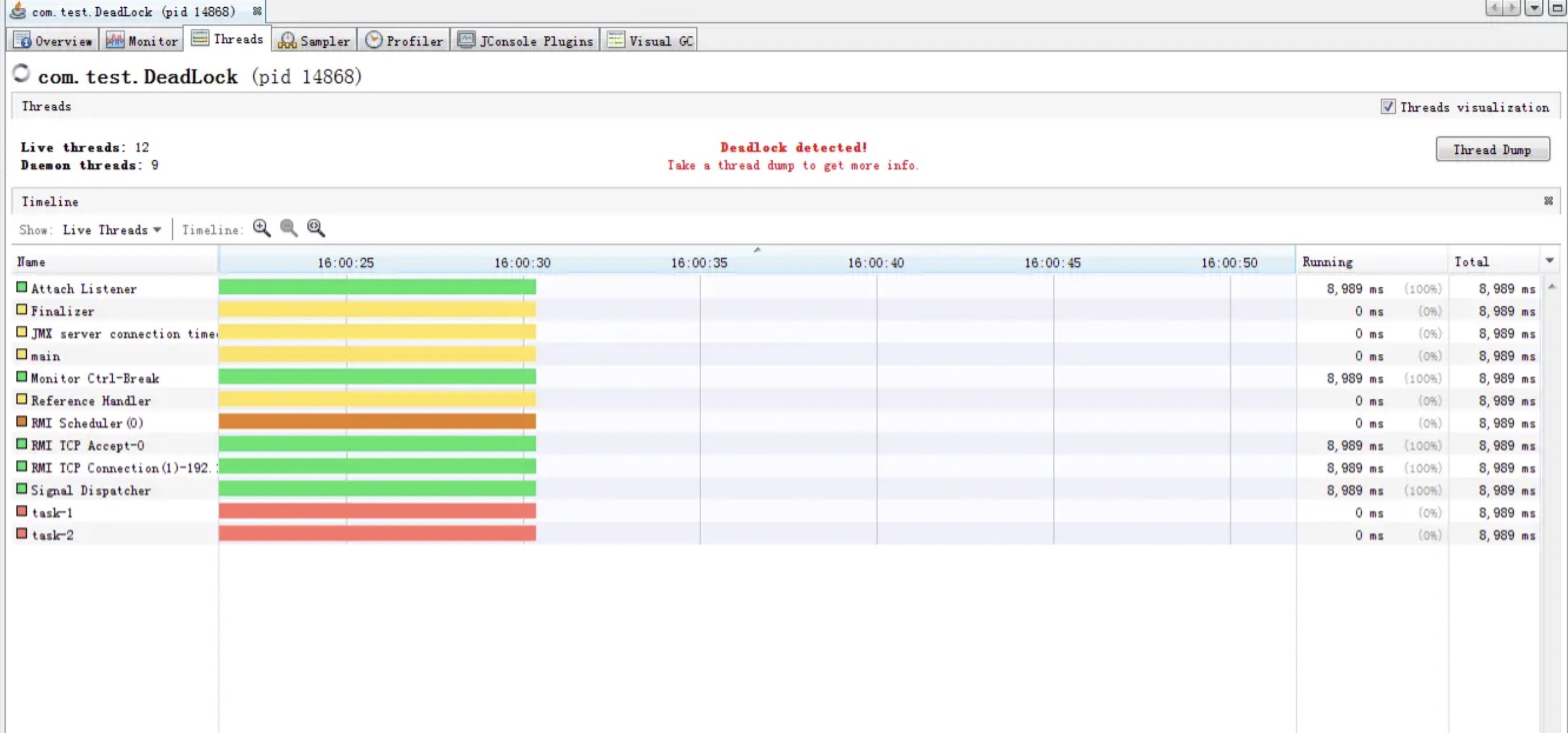
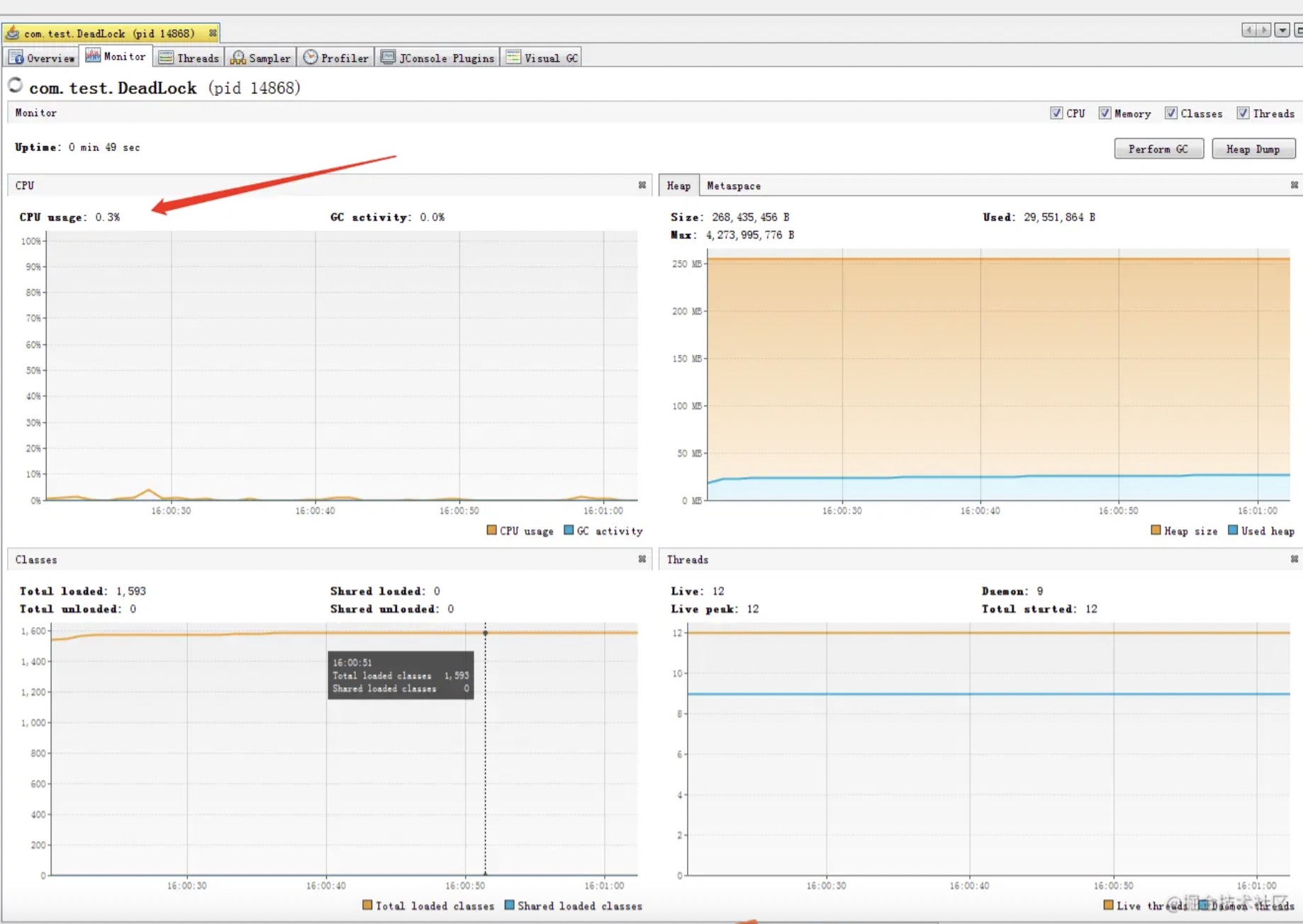
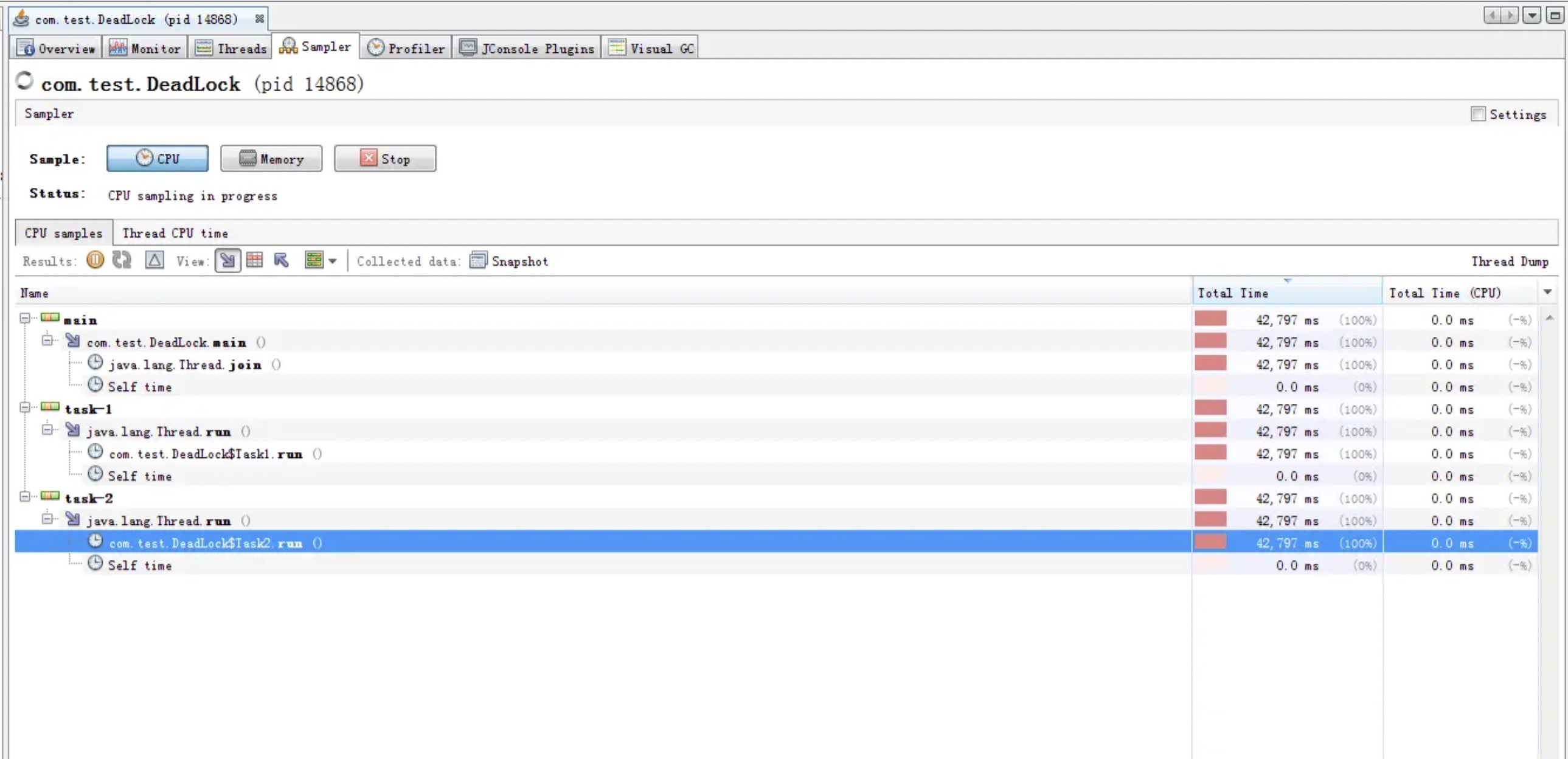
也是可以看到虽然visualVm能检测到了死锁, 但是整个JVM消耗的CPU并没有什么大的起伏的. 也就是说就算是出现了死锁,理论上也不会影响到系统CPU.
当然,虽然死锁不会影响到CPU, 但是一个系统的资源并不只有CPU这一种, 死锁的出现还是有可能导致某种资源的耗尽,而最终导致服务不可用, 所以死锁还是要避免的.
频繁切换线程上下文的场景
最后, 来看看大量线程切换是否会影响到JVM的CPU.
我们先生成数2000个线程, 利用jdk提供的LockSupport.park()不断挂起这些线程. 再使用LockSupport.unpark(t)不断地唤醒这些线程.
唤醒之后又立马挂起. 以此达到不断切换线程的目的.
代码如下:
package com.test;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.locks.LockSupport;
public class TestCpu {
public static void main(String[] args) {
int threadCount = 2000;
if(args.length > 0){
threadCount = Integer.parseInt(args[0].trim());
}
final List<Thread> list = new ArrayList<>(threadCount);
// 启动threadCount个线程, 不断地park/unpark, 来表示线程间的切换
for(int i =0; i<threadCount; i++){
Thread thread = new Thread(()->{
while(true){
LockSupport.park();
System.out.println(Thread.currentThread() +" was unpark");
}
});
thread.setName("cpuThread" + i);
list.add(thread);
thread.start();
}
// 随机地unpark某个线程
while(true){
int i = new Random().nextInt(threadCount);
Thread t = list.get(i);
if(t != null){
LockSupport.unpark(t);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
}
}
}
}
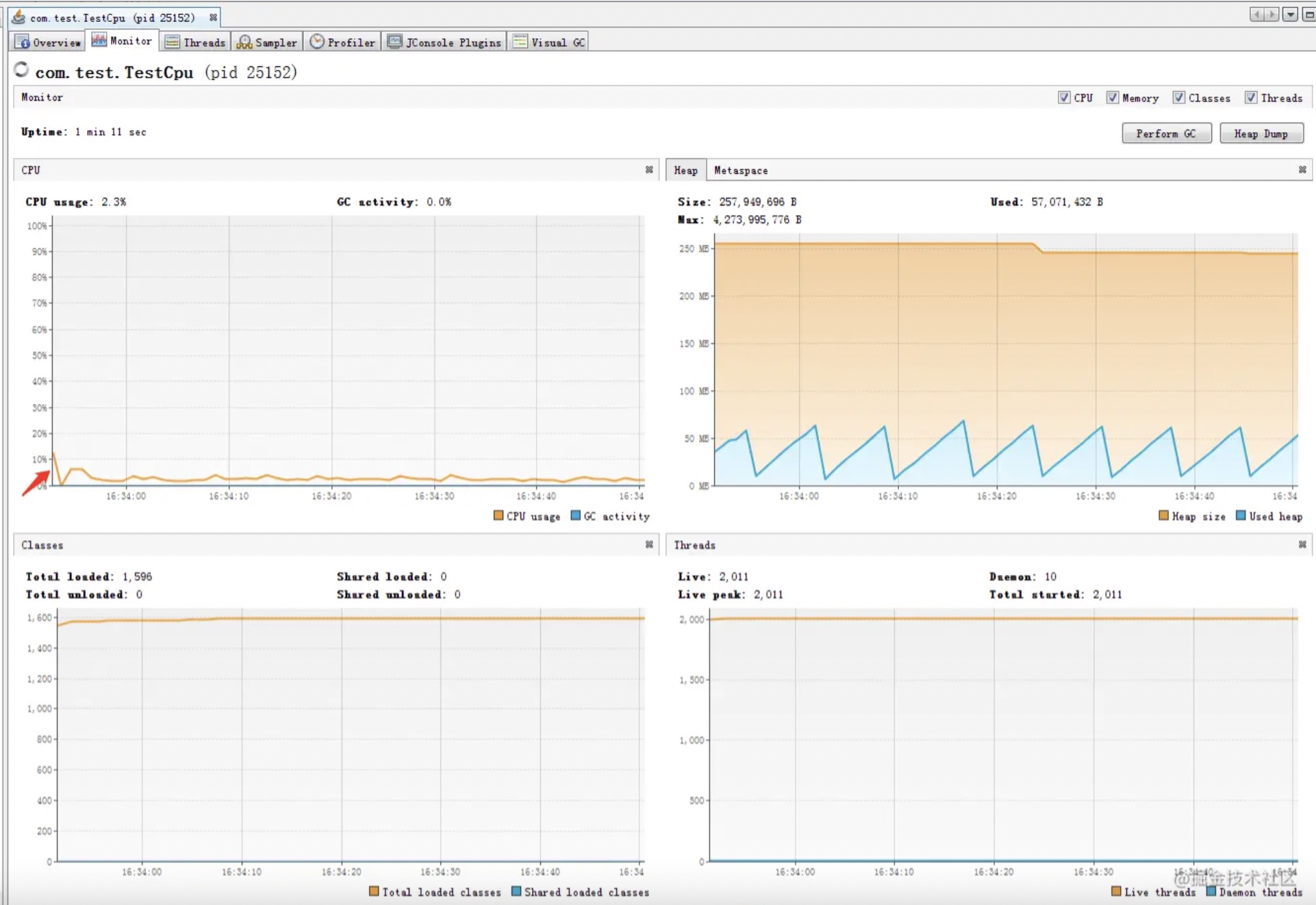
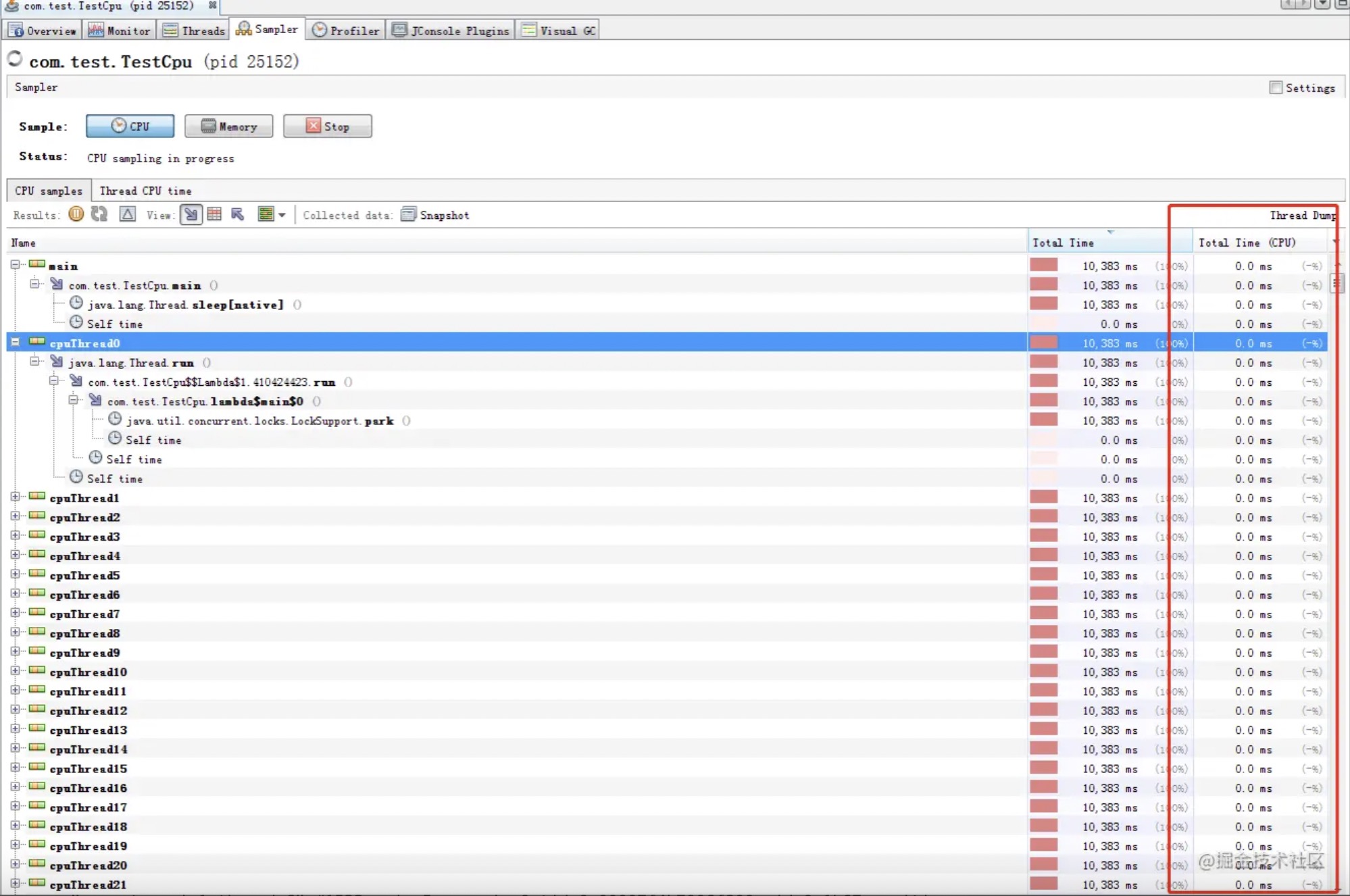
再观察visualVm, 发现整个JVM的CPU的确开始升高了, 但是具体到线程级别, 会发现每个线程都基本不耗CPU. 说明CPU不是这些线程本身消耗的.
而是系统在进行线程上下文切换时消耗的:
jvm的cpu情况:
每个线程的占用cpu情况:
分析和总结
再回到我们文章开头的线程堆栈(占用了15%的CPU):
"operate-api-1-thread-6" #1522 prio=5 os_prio=0 tid=0x00007f4b7006f800 nid=0x1b67c waiting on condition [0x00007f4ac8c4a000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000006c10828c8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:870)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(ReentrantLock.java:209)
at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
at ch.qos.logback.core.OutputStreamAppender.subAppend(OutputStreamAppender.java:210)
at ch.qos.logback.core.rolling.RollingFileAppender.subAppend(RollingFileAppender.java:235)
at ch.qos.logback.core.OutputStreamAppender.append(OutputStreamAppender.java:100)
at ch.qos.logback.core.UnsynchronizedAppenderBase.doAppend(UnsynchronizedAppenderBase.java:84)
at ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:51)
at ch.qos.logback.classic.Logger.appendLoopOnAppenders(Logger.java:270)
at ch.qos.logback.classic.Logger.callAppenders(Logger.java:257)
at ch.qos.logback.classic.Logger.buildLoggingEventAndAppend(Logger.java:421)
at ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus(Logger.java:383)
at ch.qos.logback.classic.Logger.info(Logger.java:579)
...
上面论证过了,WAITING状态的线程是不会消耗CPU的, 所以这里的CPU肯定不是挂起后消耗的, 而是挂起前消耗的.
那是哪段代码消耗的呢? 答案就在堆栈中的这段代码:
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(AbstractQueuedSynchronizer.java:1199)
众所周知, ReentrantLock的底层是使用AQS框架实现的. AQS大家可能都比较熟悉, 如果不熟悉的话这里可以大概描述一下AQS:
1. AQS有个临界变量state,当一个线程获取到state==0时, 表示这个线程进入了临界代码(获取到锁), 并原子地把这个变量值+1
2. 没能进入临界区(获取锁失败)的线程, 会利用CAS的方式添加到到CLH队列尾去, 并被LockSupport.park挂起.
3. 当线程释放锁的时候, 会唤醒head节点的下一个需要唤醒的线程(有些线程cancel了就不需要唤醒了)
4. 被唤醒的线程检查一下自己的前置节点是不是head节点(CLH队列的head节点就是之前拿到锁的线程节点)的下一个节点,
如果不是则继续挂起, 如果是的话, 与其他线程重新争夺临界变量,即重复第1步
CAS
在AQS的第2步中, 如果竞争锁失败的话, 是会使用CAS乐观锁的方式添加到队列尾的, 核心代码如下:
/**
* Inserts node into queue, initializing if necessary. See picture above.
* @param node the node to insert
* @return node's predecessor
*/
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
看上面的这段代码, 设想在极端情况下(并发量非常高的情况下), 每一次执行compareAndSetTail都失败(即返回false)的话,那么这段代码就相当是一个while(true)死循环.
在我们的实际案例中, 虽然不是极端情况, 但是并发量也是极高的(每一个线程每时每刻都在调用logback打日志), 所以在某些情况下, 个别线程会在这段代码自旋过久而长期占用CPU,最终导致CPU告警
CAS也是一种乐观锁, 所谓乐观就是认为竞争情况比较少出现. 所以CAS是不适合用于锁竞争严重的场景下的,锁竞争严重的场景更适合使用悲观锁, 那样线程被挂起了,会更加节省CPU
AQS中线程上下文切换
在实际的环境中, 如果临界区的代码执行时间比较短的话(logback写日志够短了吧), 上面AQS的第3,第4步也是会导致CLH队列的线程被频繁唤醒,而又由于抢占锁失败频繁地被挂起. 因此也会带来大量的上下文切换, 消耗系统的cpu资源.
从实验结果来看, 我觉得这个原因的可能性更高.
延伸思考
所谓cpu偏高就是指"cpu使用率"过高. 举例说1个核的机器,CPU使用100%, 8个核使用了800%,都表示cpu被用满了.那么1核的90%, 8核的700%都可以认为cpu使用率过高了.
cpu被用满的后果就是操作系统的其他任务无法抢占到CPU资源. 在window上的体现就是卡顿,鼠标移动非常不流畅.在服务器端的体现就是整个JVM无法接受新的请求, 当前的处理逻辑也无法进行而导致超时,对外的表现就是整个系统不可用.
CPU% = (1 - idleTime / sysTime) * 100
idleTime: CPU空闲时间
sysTime: CPU在用户态和内核态的使用时间之和
cpu是基于时间片调度的. 理论上不管一个线程处理时间有多长, 它能运行的时间也就是一个时间片的时间, 处理完后就得释放cpu. 然而它释放了CPU后, 还是会立马又去抢占cpu,而且抢到的概率是一样的. 所以从应用层面看, 有时还是可以看到这个线程是占用100%的
最后,从经验来看, 一个JVM系统的CPU偏高一般就是以下几个原因:
1.代码中存在死循环
2.JVM频繁GC
3.加密和解密的逻辑
4.正则表达式的处理
5.频繁地线程上下文切换
如果真的遇到了线上环境cpu偏高的问题, 不妨先从这几个角度进行分析.
最最最后, 给大家推荐一个工具, 可以线上分析jstack的一个网站, 非常的有用.
网站地址:
fastthread.io/
作者:NorthWard,著作权归作者所有。
链接:https://juejin.cn/post/6844904001067040781



