
一次 RocketMQ 顺序消费延迟的问题定位原创
问题背景与现象
昨晚收到了应用报警,发现线上某个业务消费消息延迟了 54s 多(从消息发送到MQ 到被消费的间隔):
2021-06-30T23:12:46.756 message processing is incredibly delayed! (Current delay time: 54725, incredible delay count in 10 seconds: 5677)
查看 RocketMQ 的监控,发现确实发生了比较多的消息积压: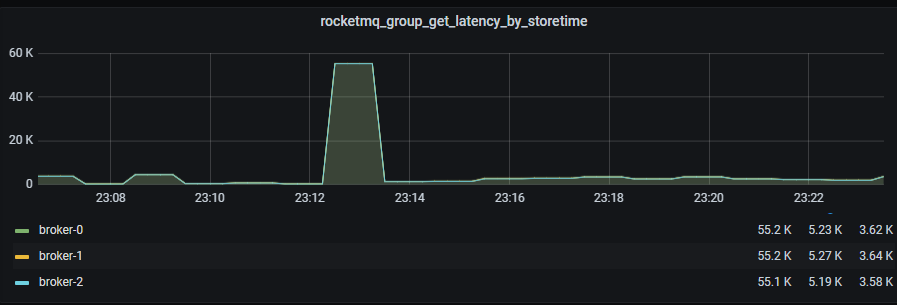
从 RocketMQ-Console 上面查看 Topic 的消费者: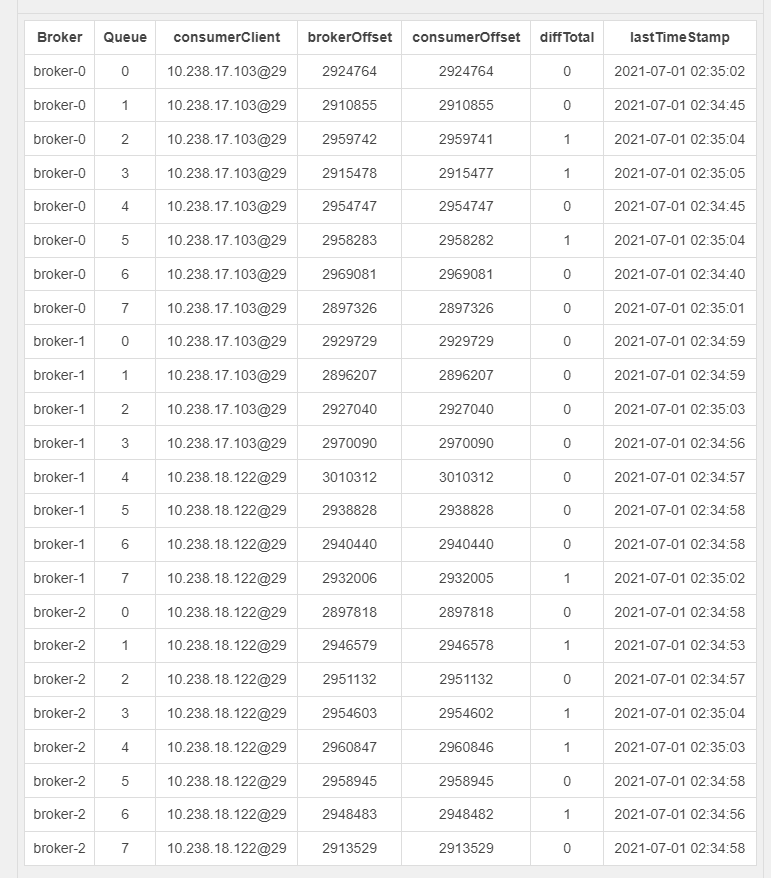
这个 Topic,业务要求是需要有序的。所以在发送的时候,指定了业务 Key,并且消费的时候,使用的是顺序消费模式。
我们使用了 RocketMQ 集群,有三个 Broker,对于这个 Topic,每个 Broker 上面都有 8 个 ReadQueue 和 WriteQueue。这里简单提一下 ReadQueue 和 WriteQueue 的意思:
在 RocketMQ 中,消息发送时使用 WriteQueue 个数返回路由信息,而消息消费时按照 ReadQueue 个数返回路由信息。在物理文件层面,只有 WriteQueue 才会创建文件。举个例子:设置 WriteQueueNum = 8,ReadQueueNum = 4,会创建 8 个文件夹,代表 0 1 2 3 4 5 6 7 这 8 个队列,但在消息消费时,路由信息只返回 4,在具体拉取消息时,就只会消费0 1 2 3 这 4 个队列中的消息,4 5 6 7 压根就没有被消费。反过来,如果设置 WriteQueueNum = 4,ReadQueueNum = 8,在生产消息时只会往0 1 2 3中生产消息,消费消息时则会从0 1 2 3 4 5 6 7 所有的队列中消费,当然 4 5 6 7中压根就没有消息 ,假设消费是 Group 消费,Group 中有两个消费者,事实上只有第一个消费者在真正的消费消息(0 1 2 3),第二个消费者压根就消费不到消息(4 5 6 7)。一般我们都会设置这两个值相同,只有在需要缩容 topic 的队列数量的时候,才会设置他们不同。
问题分析
首先联想到的是,是否是消费线程卡住了呢?线程卡住一般因为:
1.发生了 Stop-the-wolrd:
2.GC 导致
3.其他 safepoint 原因导致(例如 jstack,定时进入 safepoint 等等,参考我的这篇文章JVM相关 - JVM相关 - SafePoint 与 Stop The World 全解)
4.线程处理消息时间过长,可能有锁获取不到,可能卡在某些 IO
采集当时的 JFR(关于 JFR,请参考我的另一系列JFR全解),发现:
1.在这个时间段并没有发生停滞时间很长的 GC 以及其他 Stop-the-world 的 safepoint 事件:
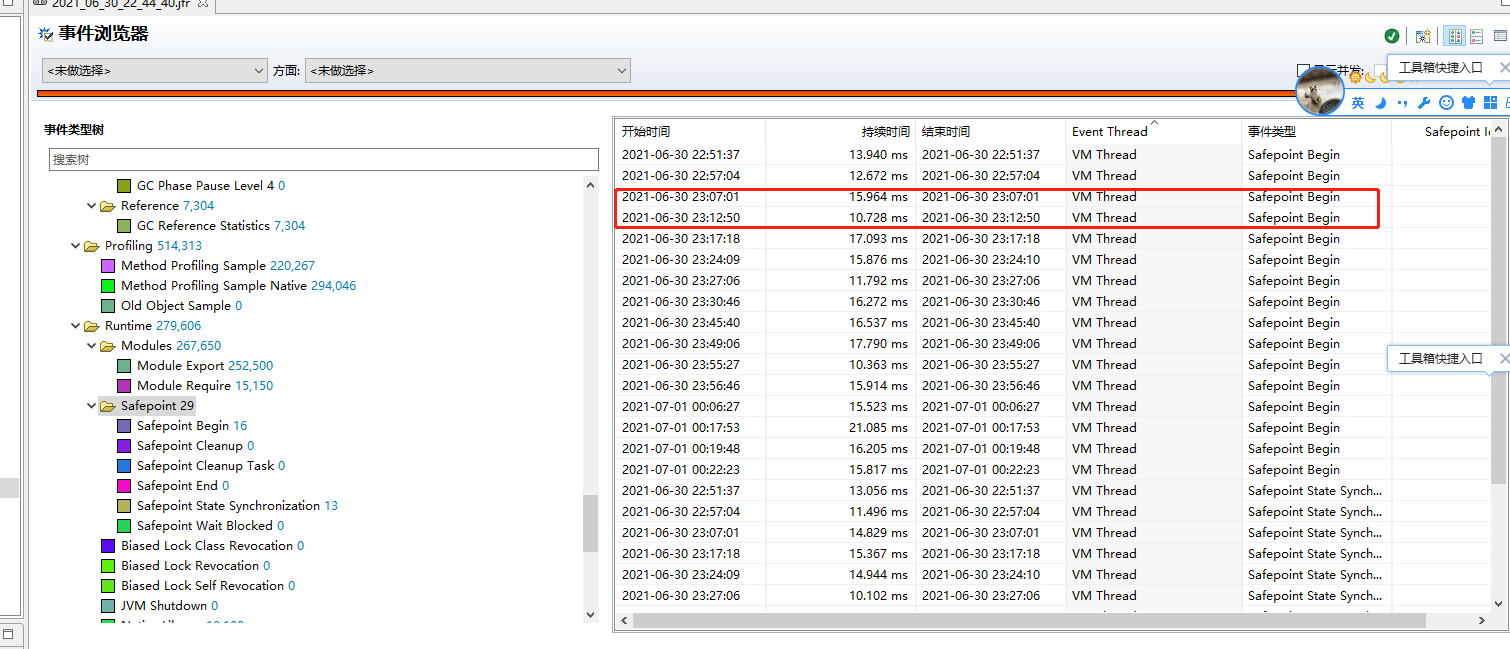
在这段时间,线程是 park 的,并且堆栈显示是消费线程并没有消息可以消费: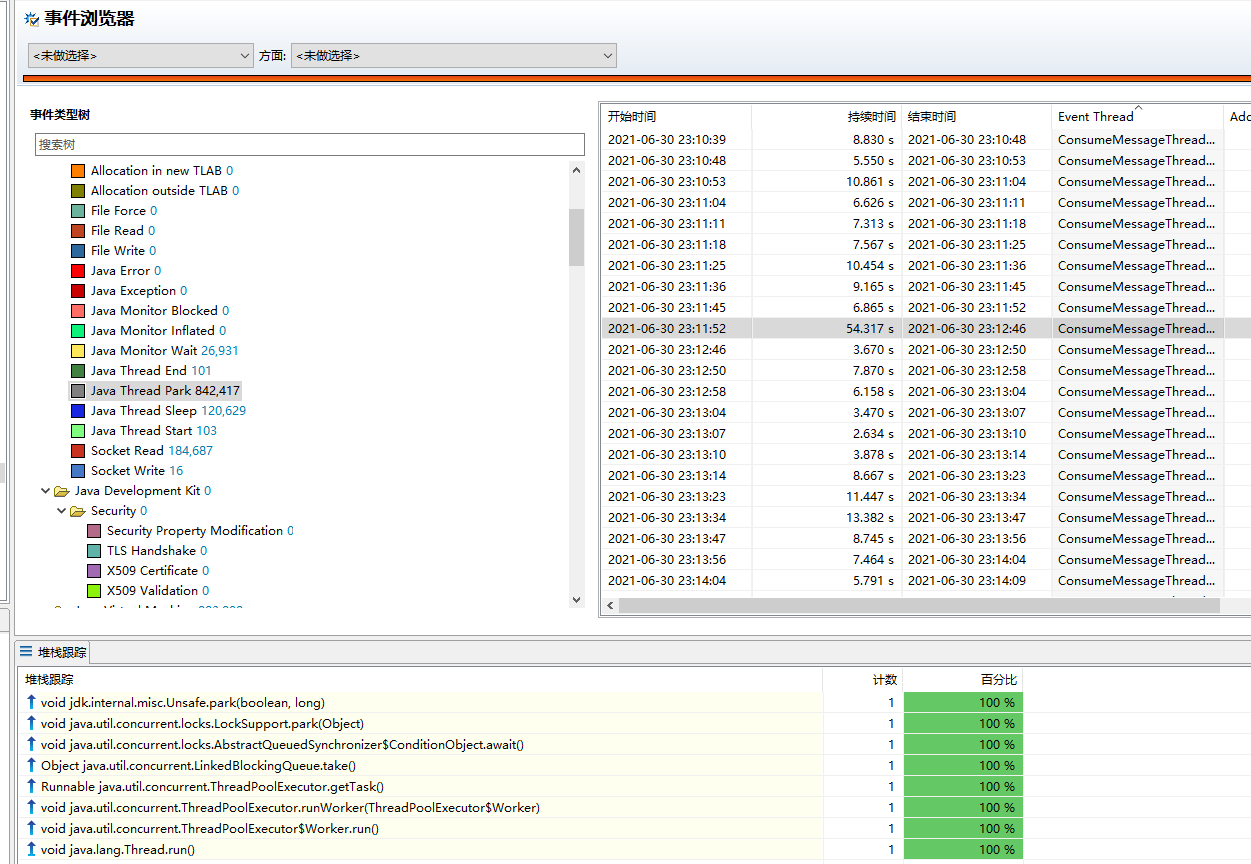
既然应用并没有什么问题,我们来看看 RocketMQ 是否有什么问题。一般的 RocketMQ Broker 的日志我们关心:
1.消息持久化的时间消耗统计,如果这里发生异常,我们需要调优 Java MMAP 相关的参数,请参考:
2.消息持久化异常,查看 storeerr.log
3.锁异常,查看 lock.log
那究竟应该去看哪一个 broker 呢?之前提到了,发送到这个 Topic 是指定了 hashKey 的,通过消息的 hashKey 我们可以定位到是哪个 broker:
int hashCode = "我们的hashKey".hashCode();
log.info("{}", Math.abs(hashCode % 24));
我们找到了消息的 hashKey,通过上面的代码,结果是 20,也就是队列 20,通过前面的描述,我们知道每个 broker 是 8 个队列,20 对应的就是 broker-2 上面的队列,也就是 broker-2 queueId = 5 这个队列。我们来查看 broker-2 上面的日志定位问题。
我们发现 lock.log 里面有异常,如下所示,类似的有很多条,并且持续了 54s 左右,和线程 park 时间比较吻合,也和消息延迟比较吻合:
2021-07-01 07:11:47 WARN AdminBrokerThread_10 - tryLockBatch, message queue locked by other client. Group: 消费group OtherClientId: 10.238.18.6@29 NewClientId: 10.238.18.122@29 MessageQueue [topic=消息topic, brokerName=broker-2, queueId=5]
这个日志的意思是,10.238.18.122@29 这个实例尝试锁住 queueId = 5 失败,因为 10.238.18.6@29 正在持有这个锁。那么为什么会发生这种情况呢?
RocketMQ 多队列顺序消费的原理
RocketMQ 想要实现多队列顺序消费,首先需要指定 hashKey,通过 hashKey 消息会被放入特定的队列,消费者消费这个队列的时候,如果指定了顺序消费,是单线程消费的,这样就保证了同一队列内有序。
那么是如何保证每个队列是单线程消费的呢?每个 Broker 维护一个:
- private final ConcurrentMap<String/* group */, ConcurrentHashMap<MessageQueue, LockEntry>> mqLockTable =
- new ConcurrentHashMap<String, ConcurrentHashMap<MessageQueue, LockEntry>>(1024);
他是一个 ConcurrentMap<消费组名称, ConcurrentHashMap<消息队列, 锁对象>>。锁对象 LockEntry 包括:
RebalanceLockManager.java
- //读取 rocketmq.broker.rebalance.lockMaxLiveTime 这个环境变量,默认 60s
- private final static long REBALANCE_LOCK_MAX_LIVE_TIME = Long.parseLong(System.getProperty(
- "rocketmq.broker.rebalance.lockMaxLiveTime", "60000"));
- static class LockEntry {
- //RocketMQ 客户端唯一 id
- private String clientId;
- private volatile long lastUpdateTimestamp = System.currentTimeMillis();
- //省略getter setter
- public boolean isLocked(final String clientId) {
- boolean eq = this.clientId.equals(clientId);
- return eq && !this.isExpired();
- }
- public boolean isExpired() {
- // 在 REBALANCE_LOCK_MAX_LIVE_TIME 这么长时间后过期
- boolean expired =
- (System.currentTimeMillis() - this.lastUpdateTimestamp) > REBALANCE_LOCK_MAX_LIVE_TIME;
- return expired;
- }
- }
RocketMQ 客户端发送LOCK_BATCH_MQ 请求到 Broker 上面,Broker 会将客户端请求封装成为 LockEntry 并尝试更新这个 Map,如果更新成功就是获取到了锁,如果失败则没有获取这个锁。Broker 的详细更新逻辑是(感兴趣可以查看,也可以直接跳过,不影响理解,后面有便于理解的图片):
- public boolean tryLock(final String group, final MessageQueue mq, final String clientId) {
- //判断没有已经锁住
- if (!this.isLocked(group, mq, clientId)) {
- try {
- //获取锁,这个锁是实例内的,因为每个 broker 维护自己的队列锁表,并不共享
- this.lock.lockInterruptibly();
- try {
- //尝试获取,判断是否存在,存在就判断是否过期
- ConcurrentHashMap<MessageQueue, LockEntry> groupValue = this.mqLockTable.get(group);
- if (null == groupValue) {
- groupValue = new ConcurrentHashMap<>(32);
- this.mqLockTable.put(group, groupValue);
- }
- LockEntry lockEntry = groupValue.get(mq);
- if (null == lockEntry) {
- lockEntry = new LockEntry();
- lockEntry.setClientId(clientId);
- groupValue.put(mq, lockEntry);
- log.info("tryLock, message queue not locked, I got it. Group: {} NewClientId: {} {}",
- group,
- clientId,
- mq);
- }
- if (lockEntry.isLocked(clientId)) {
- lockEntry.setLastUpdateTimestamp(System.currentTimeMillis());
- return true;
- }
- String oldClientId = lockEntry.getClientId();
- if (lockEntry.isExpired()) {
- lockEntry.setClientId(clientId);
- lockEntry.setLastUpdateTimestamp(System.currentTimeMillis());
- log.warn(
- "tryLock, message queue lock expired, I got it. Group: {} OldClientId: {} NewClientId: {} {}",
- group,
- oldClientId,
- clientId,
- mq);
- return true;
- }
- //这里就是我们刚刚看到的日志
- log.warn(
- "tryLock, message queue locked by other client. Group: {} OtherClientId: {} NewClientId: {} {}",
- group,
- oldClientId,
- clientId,
- mq);
- return false;
- } finally {
- this.lock.unlock();
- }
- } catch (InterruptedException e) {
- log.error("putMessage exception", e);
- }
- } else {
- }
- return true;
- }
- //判断是否是已经锁住了
- private boolean isLocked(final String group, final MessageQueue mq, final String clientId) {
- //通过消费组名称获取
- ConcurrentHashMap<MessageQueue, LockEntry> groupValue = this.mqLockTable.get(group);
- //如果不为 null
- if (groupValue != null) {
- //尝试获取 lockEntry,看是否存在
- LockEntry lockEntry = groupValue.get(mq);
- if (lockEntry != null) {
- //如果存在,判断是否过期
- boolean locked = lockEntry.isLocked(clientId);
- if (locked) {
- lockEntry.setLastUpdateTimestamp(System.currentTimeMillis());
- }
- return locked;
- }
- }
- return false;
- }
每个 MQ 客户端,会定时发送LOCK_BATCH_MQ请求,并且在本地维护获取到锁的所有队列:
ProcessQueue.java
//定时发送 **LOCK_BATCH_MQ** 间隔
public final static long REBALANCE_LOCK_INTERVAL = Long.parseLong(System.getProperty("rocketmq.client.rebalance.lockInterval", "20000"));
ConsumeMessageOrderlyService.java
- if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())) {
- this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
- public void run() {
- ConsumeMessageOrderlyService.this.lockMQPeriodically();
- }
- }, 1000 * 1, ProcessQueue.REBALANCE_LOCK_INTERVAL, TimeUnit.MILLISECONDS);
- }
流程图如下所示:
ConsumeMessageOrderlyService 在关闭的时候,会 unlock 所有的队列:
- public void shutdown() {
- this.stopped = true;
- this.scheduledExecutorService.shutdown();
- this.consumeExecutor.shutdown();
- if (MessageModel.CLUSTERING.equals(this.defaultMQPushConsumerImpl.messageModel())) {
- this.unlockAllMQ();
- }
- }
问题出现原因
我们这里客户端定时发送 LOCK_BATCH_MQ 间隔是默认的 20s, Broker 端锁过期的时间也是默认的 60s。
我们的集群容器编排使用了 k8s,并且有实例迁移的功能。在集群压力大的时候,自动扩容新的 Node (可以理解为虚拟机)并将创建新的服务实例部署上去。集群某些服务压力小的时候,某些服务实例会缩容下去,这时候就不需要那么多 Node 了,就会回收一部分 Node,但是被回收的 Node 上面还有不能缩容的服务实例,这时候就需要将这些服务实例迁移到其他 Node 上面。这里我们的业务实例就是发生了这个情况。
在问题出现的时候,发生了迁移,老的实例被关闭,但是没有等待 ConsumeMessageOrderlyService#shutdown 的执行,导致锁没有被主动释放,而是等待 60s 的锁过期时间后,新的实例才拿到队列锁开始消费。
问题解决
1.在下个版本,加入针对 RocketMQ 客户端的优雅关闭逻辑
2.所有服务实例(RocketMQ 客户端)配置 rocketmq.client.rebalance.lockInterval 缩短心跳时间(5s),RocketMQ Broker 配置 rocketmq.broker.rebalance.lockMaxLiveTime 缩短过期时间(例如 15s),但是保持过期时间是心跳时间的 3 倍(集群中的 3 倍设计公理)



