
深入汇编指令理解Java关键字volatile原创
volatile是什么
volatile关键字是Java提供的一种轻量级同步机制。它能够保证可见性和有序性,但是不能保证原子性
可见性
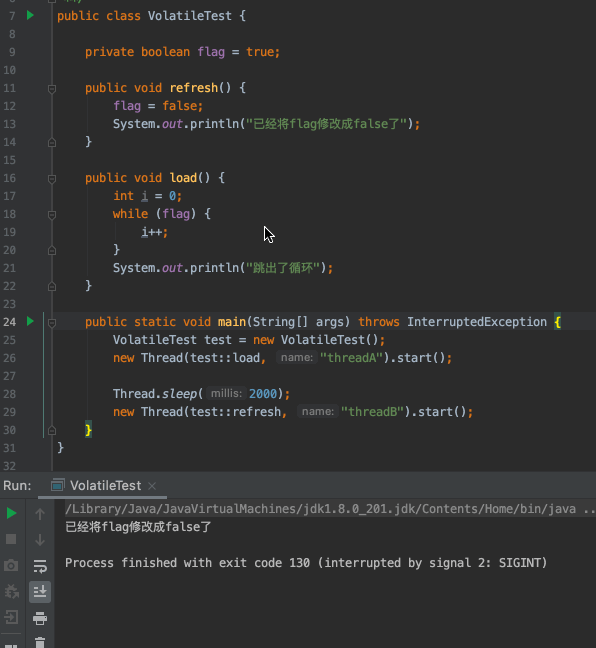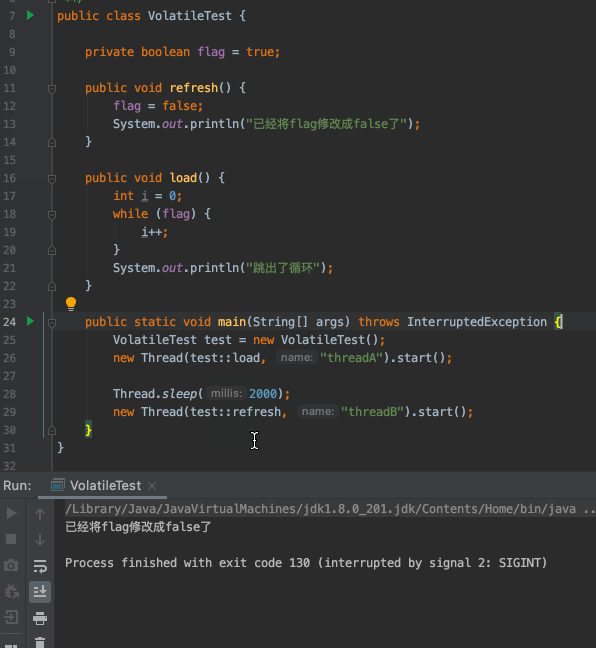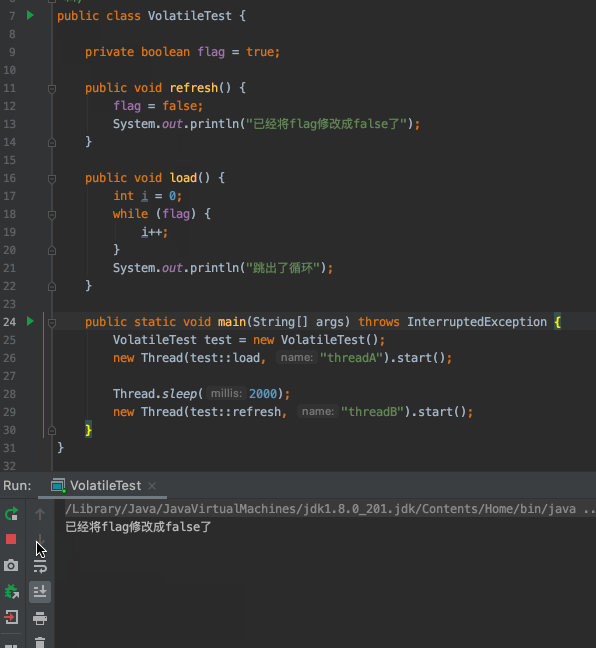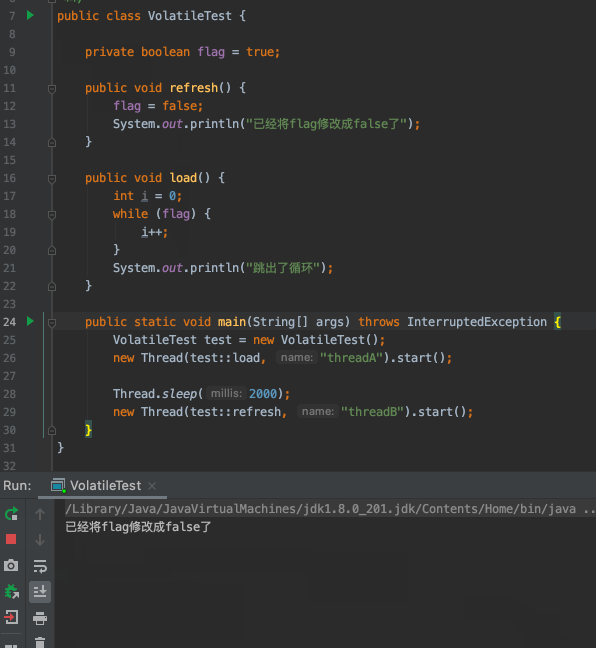
对于volatile的可见性,先看看这段代码的执行
<div align = “center”>
</div>
flag默认为true- 创建一个线程A去判断
flag是否为true,如果为true循环执行i++操作 - 两秒后,创建另一个线程B将
flag修改为false - 线程A没有感知到
flag已经被修改成false了,不能跳出循环
这相当于啥呢?相当于你的女神和你说,你好好努力,年薪百万了就嫁给你,你听了之后,努力赚钱。3年之后,你年薪百万了,回去找你女神,结果发现你女神结婚了,她结婚的消息根本没有告诉你!难不难受?
<div align = “center”>

</div>
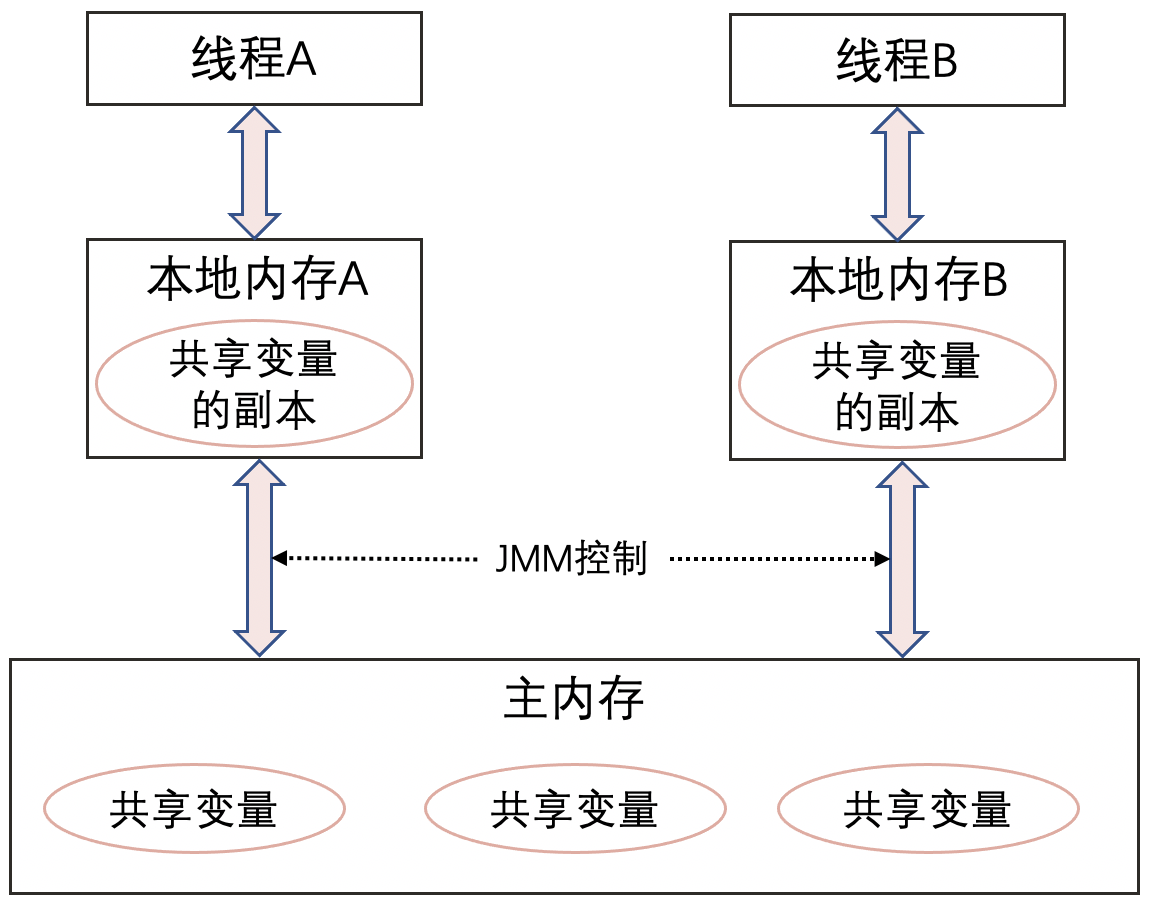
女神结婚可以不告诉你,可是Java代码中的属性都是存在内存中,一个线程的修改为什么另一个线程为什么不可见呢?这就不得不提到Java中的内存模型了,Java中的内存模型,简称JMM,JMM定义了线程和主内存之间的抽象关系,定义了线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本地内存中存储了该线程以读/写共享变量的副本,它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
注意!JMM是一个屏蔽了不同操作系统架构的差异的抽象概念,只是一组Java规范。
<div align = “center”>
</div>
了解了JMM,现在我们再回顾一下文章开头的那段代码,为什么线程B修改了flag线程A看到的还是原来的值呢?
<div align = “center”>
</div>
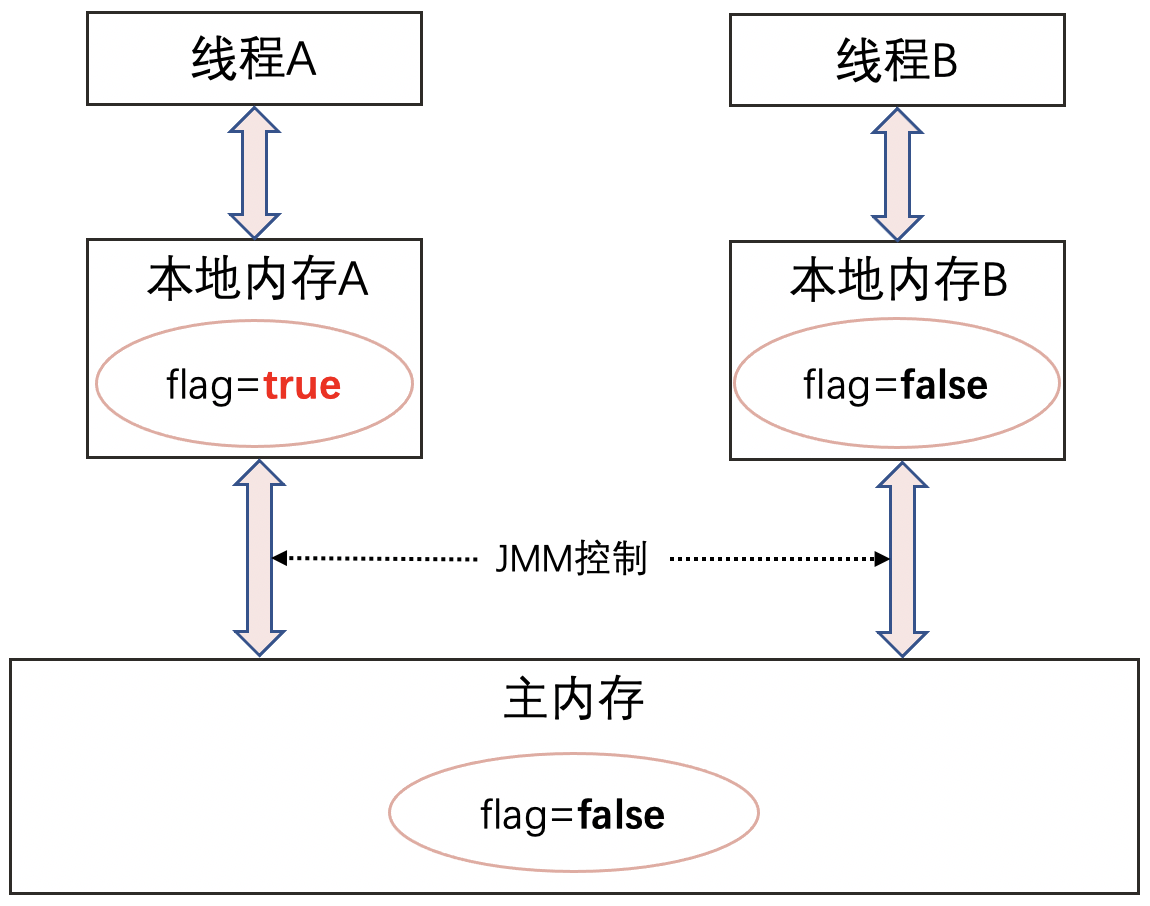
- 因为线程A复制了一份刚开始的
flage=true到本地内存,之后线程A使用的flag都是这个复制到本地内存的flag。 - 线程B修改了
flag之后,将flag的值刷新到主内存,此时主内存的flag值变成了false。 - 线程A是不知道线程B修改了
flag,一直用的是本地内存的flag = true。
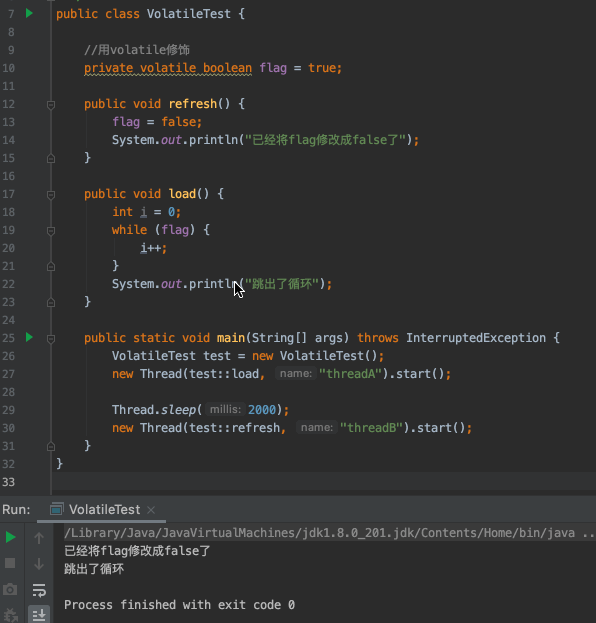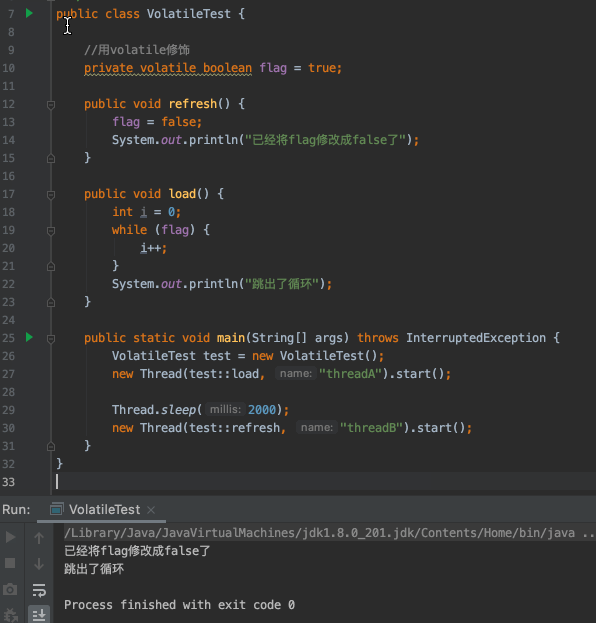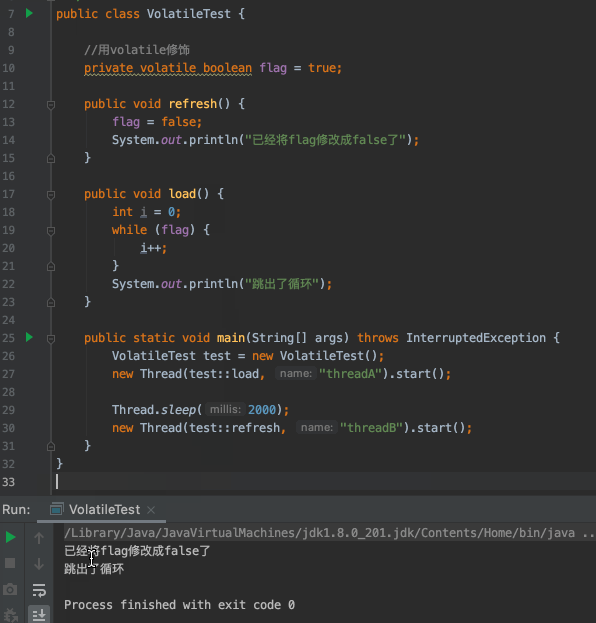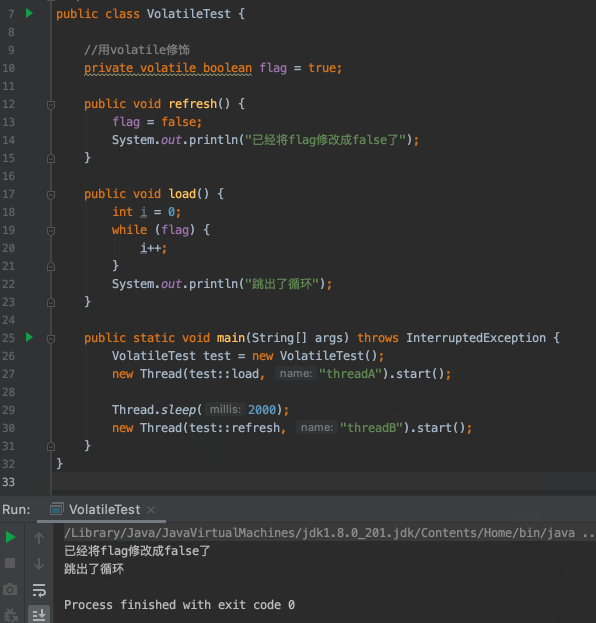
那么,如何才能让线程A知道flag被修改了呢?或者说怎么让线程A本地内存中缓存的flag无效,实现线程间可见呢?用volatile修饰flag就可以做到:
<div align = “center”>
</div>
我们可以看到,用volatile修饰flag之后,线程B修改flag之后线程A是能感知到的,说明了volatile保证了线程同步之间的可见性。
重排序
在阐述volatile有序性之前,需要先补充一些关于重排序的知识。
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。
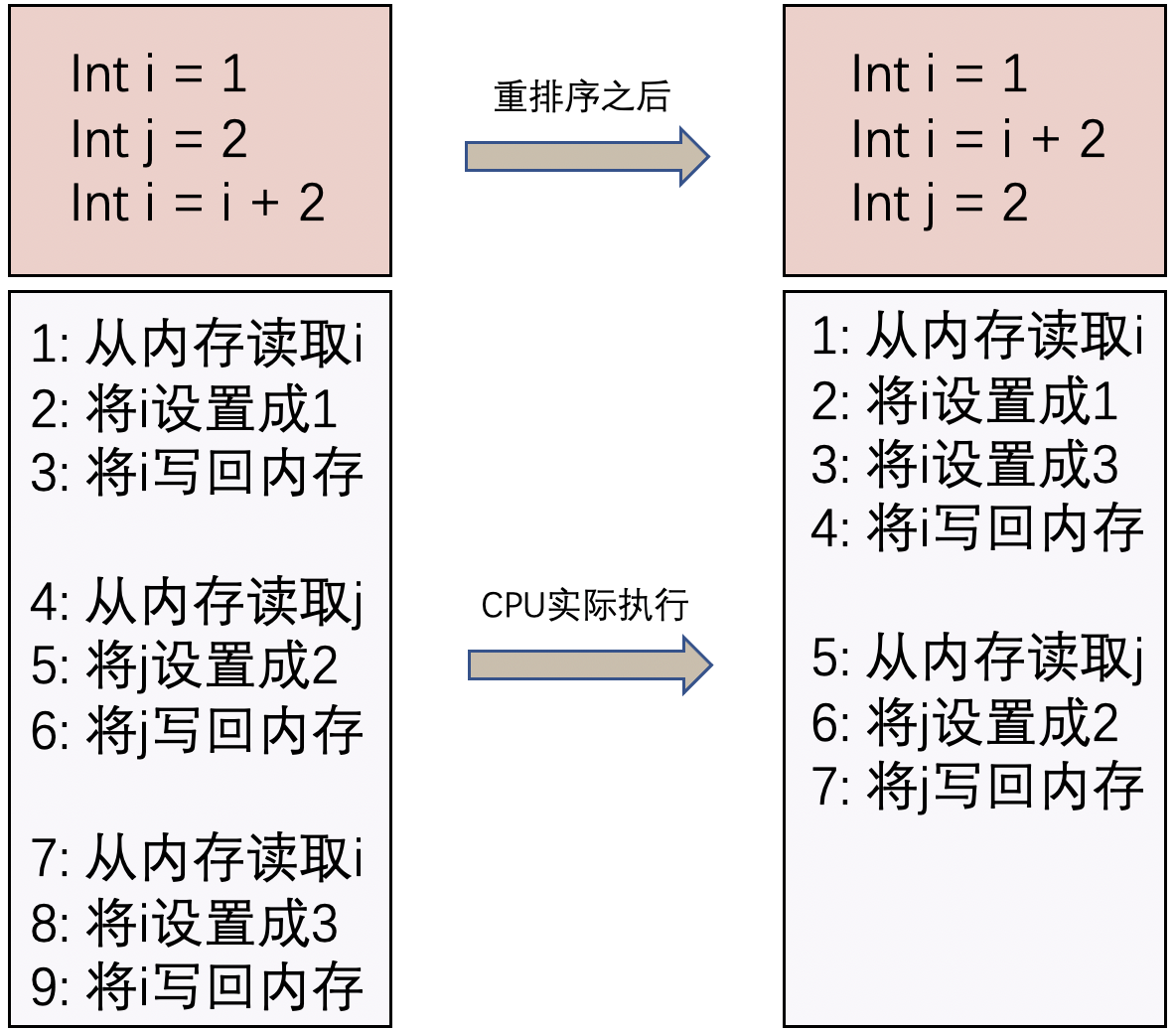
为什么要有重排序呢?简单来说,就是为了提升执行效率。为什么能提升执行效率呢?我们看下面这个例子:
<div align = “center”>
</div>
可以看到重排序之后CPU实际执行省略了一个读取和写回的操作,也就间接的提升了执行效率。
有一点必须强调的是,上图的例子只是为了让读者更好的理解为什么重排序能提升执行效率,实际上Java里面的重排序并不是基于代码级别的,从代码到CPU执行之间还有很多个阶段,CPU底层还有一些优化,实际上的执行流程可能并不是上图的说的那样。不必过于纠结于此。
重排序可以提高程序的运行效率,但是必须遵循as-if-serial语义。as-if-serial语义是什么呢?简单来说,就是不管你怎么重排序,你必须保证不管怎么重排序,单线程下程序的执行结果不能被改变。
有序性
上面我们已经介绍了Java有重排序情况,现在我们再来聊一聊volatile的有序性。
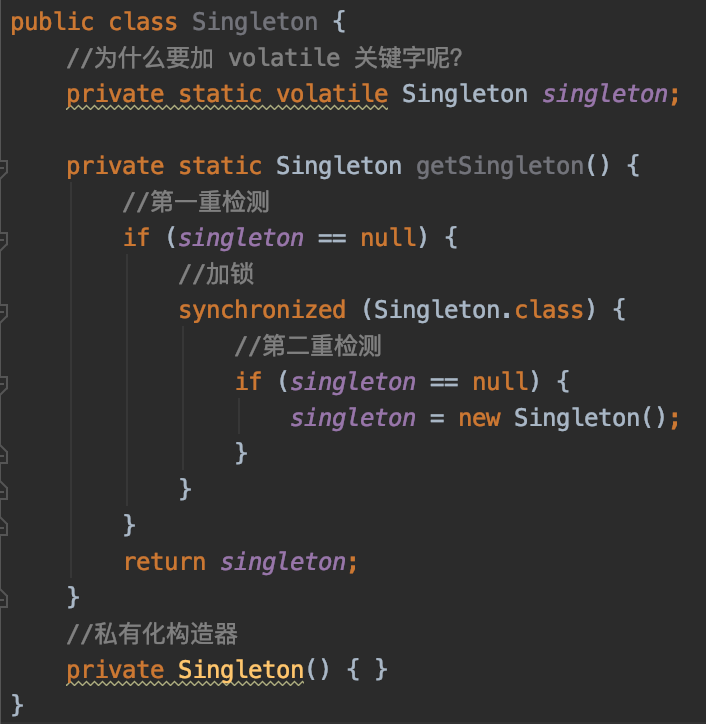
先看一个经典的面试题:为什么DDL(double check lock)单例模式需要加volatile关键字?
<div align = “center”>
</div>
因为singleton = new Singleton()不是一个原子操作,大概要经过这几个步骤:
- 分配一块内存空间
- 调用构造器,初始化实例
singleton指向分配的内存空间
实际执行的时候,可能发生重排序,导致实际执行步骤是这样的:
- 申请一块内存空间
singleton指向分配的内存空间- 调用构造器,初始化实例
在singleton指向分配的内存空间之后,singleton就不为空了。但是在没有调用构造器初始化实例之前,这个对象还处于半初始化状态,在这个状态下,实例的属性都还是默认属性,这个时候如果有另一个线程调用getSingleton()方法时,会拿到这个半初始化的对象,导致出错。
而加volatile修饰之后,就会禁止重排序,这样就能保证在对象初始化完了之后才把singleton指向分配的内存空间,杜绝了一些不可控错误的产生。volatile提供了happens-before保证,对volatile变量的写入happens-before所有其他线程后续对的读操作。
原理
从上面的DDL单例用例来看,在并发情况下,重排序的存在会导致一些未知的错误。而加上volatile之后会防止重排序,那volatile是如何禁止重排序呢?
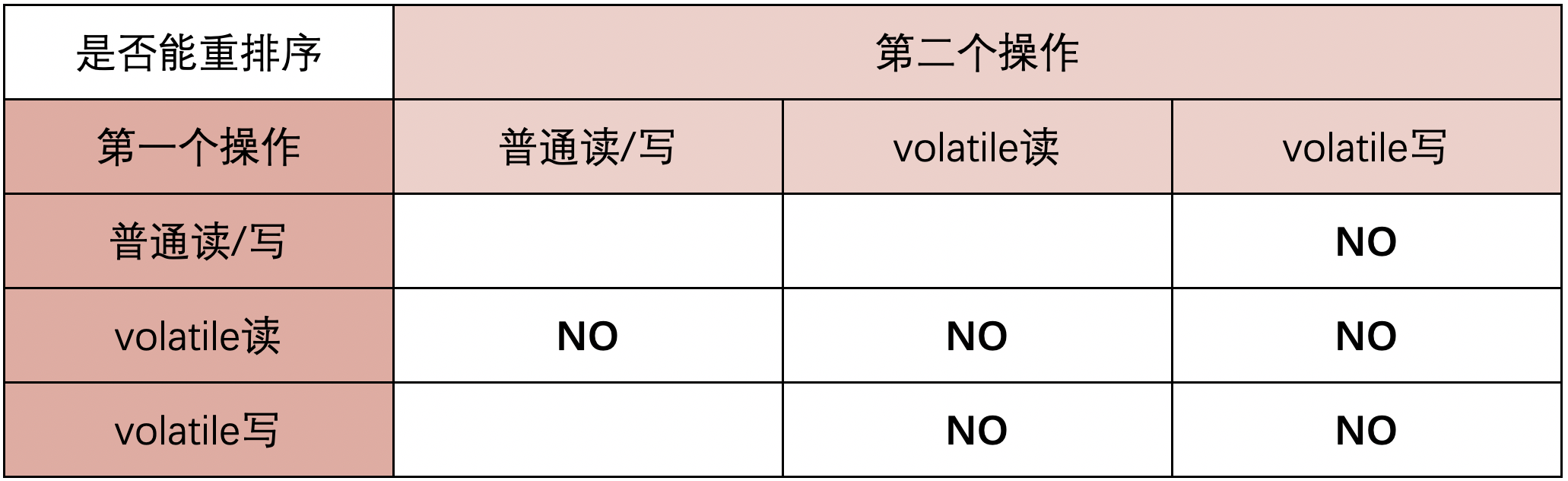
为了实现volatile的内存语义,JMM会限制特定类型的编译器和处理器重排序,JMM会针对编译器制定volatile重排序规则表:
<div align = “center”>
</div>
总结来说就是:
- 第二个操作是volatile写,不管第一个操作是什么都不会重排序
- 第一个操作是volatile读,不管第二个操作是什么都不会重排序
- 第一个操作是volatile写,第二个操作是volatile读,也不会发生重排序
如何保证这些操作不会发送重排序呢?就是通过插入内存屏障保证的,JMM层面的内存屏障分为读(load)屏障和写(Store)屏障,排列组合就有了四种屏障。对于volatile操作,JMM内存屏障插入策略:
- 在每个volatile写操作的前面插入一个StoreStore屏障
- 在每个volatile写操作的后面插入一个StoreLoad屏障
- 在每个volatile读操作的后面插入一个LoadLoad屏障
- 在每个volatile读操作的后面插入一个LoadStore屏障
<div align = “center”>

</div>
上面的屏障都是JMM规范级别的,意思是,按照这个规范写JDK能保证volatile修饰的内存区域的操作不会发送重排序。
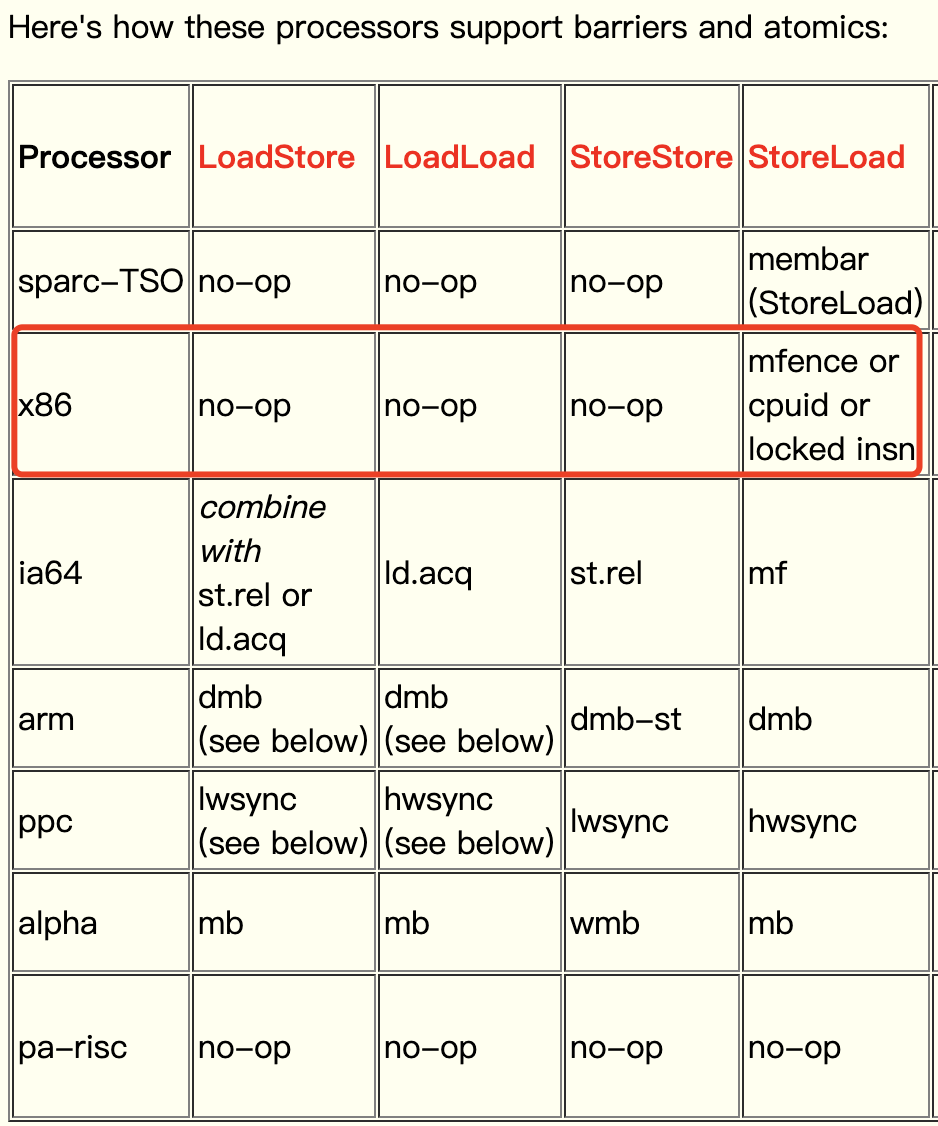
在硬件层面上,也提供了一系列的内存屏障来提供一致性的能力。拿X86平台来说,主要提供了这几种内存屏障指令:
- lfence指令:在lfence指令前的读操作当必须在lfence指令后的读操作前完成,类似于读屏障
- sfence指令:在sfence指令前的写操作当必须在sfence指令后的写操作前完成,类似于写屏障
- mfence指令: 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成,类似读写屏障。
JMM规范需要加这么多内存屏障,但实际情况并不需要加这么多内存屏障。以我们常见的X86处理器为例,X86处理器不会对读-读、读-写和写-写操作做重排序,会省略掉这3种操作类型对应的内存屏障,仅会对写-读操作做重排序。所以volatile写-读操作只需要在volatile写后插入StoreLoad屏障。在《The JSR-133 Cookbook for Compiler Writers》中,也很明确的指出了这一点:
<div align = “center”>
</div>
而在x86处理器中,有三种方法可以实现实现StoreLoad屏障的效果,分别为:
- mfence指令:上文提到过,能实现全能型屏障,具备lfence和sfence的能力。
- cpuid指令:cpuid操作码是一个面向x86架构的处理器补充指令,它的名称派生自CPU识别,作用是允许软件发现处理器的详细信息。
- lock指令前缀:总线锁。lock前缀只能加在一些特殊的指令前面。
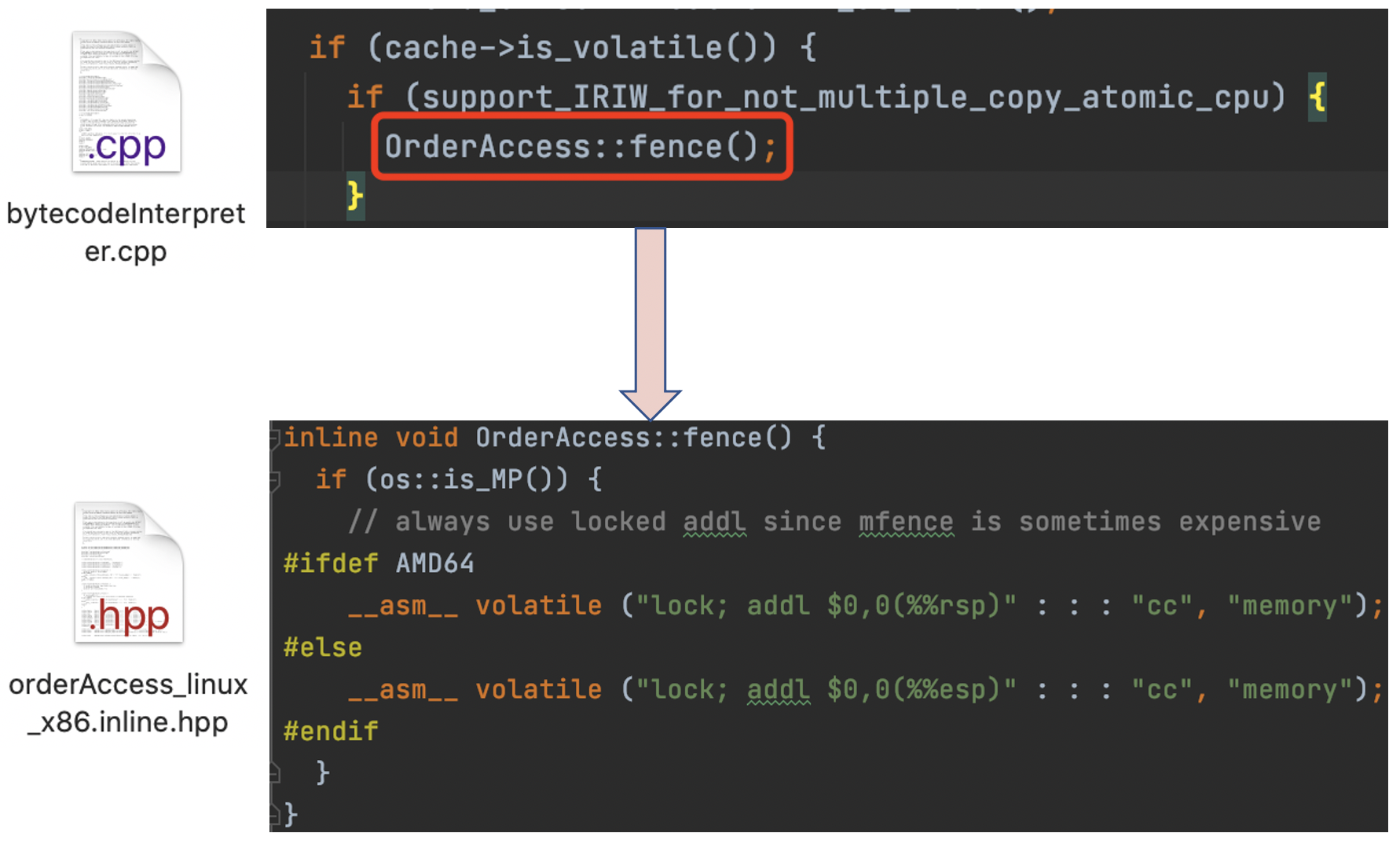
实际上HotSpot关于volatile的实现就是使用的lock指令,只在volatile标记的地方加上带lock前缀指令操作,并没有参照JMM规范的屏障设计而使用对应的mfence指令。
加上-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XcompJVM参数再次执行main方法,在打印的汇编码中,我们也可以看到有一个lock addl $0x0,(%rsp)的操作。
<div align = “center”>

</div>
在源码中也可以得到验证:
<div align = “center”>
</div>
lock addl $0x0,(%rsp)后面的addl $0x0,(%rsp)其实是一个空操作。add是加的意思,0x0是16进制的0,rsp是一种类型寄存器,合起来就是把寄存器的值加0,加0是不是等于什么都没有做?这段汇编码仅仅是lock指令的一个载体而已。其实上文也有提到过,lock前缀只能加在一些特殊的指令前面,add就是其中一个指令。
至于Hotspot为什么要使用lock指令而不是mfence指令,按照我的理解,其实就是省事,实现起来简单。因为lock功能过于强大,不需要有太多的考虑。而且lock指令优先锁缓存行,在性能上,lock指令也没有想象中的那么差,mfence指令更没有想象中的好。所以,使用lock是一个性价比非常高的一个选择。而且,lock也有对可见性的语义说明。
在《IA-32架构软件开发人员手册》的指令表中找到lock:
<div align = “center”>

</div>
我不打算在这里深入阐述lock指令的实现原理和细节,这很容易陷入堆砌技术术语中,而且也超出了本文的范围,有兴趣的可以去看看《IA-32架构软件开发人员手册》。
我们只需要知道lock的这几个作用就可以了:
- 确保后续指令执行的原子性。在Pentium及之前的处理器中,带有lock前缀的指令在执行期间会锁住总线,使得其它处理器暂时无法通过总线访问内存,很显然,这个开销很大。在新的处理器中,Intel使用缓存锁定来保证指令执行的原子性,缓存锁定将大大降低lock前缀指令的执行开销。
- 禁止该指令与前面和后面的读写指令重排序。
- 把写缓冲区的所有数据刷新到内存中。
总结来说,就是lock指令既保证了可见性也保证了原子性。
重要的事情再说一遍,是lock指令既保证了可见性也保证了原子性,和什么缓冲一致性协议啊,MESI什么的没有一点关系。
为了不让你把缓存一致性协议和JMM混淆,在前面的文章中,我特意没有提到过缓存一致性协议,因为这两者本不是一个维度的东西,存在的意义也不一样,这一部分,我们下次再聊。
总结
全文重点是围绕volatile的可见性和有序性展开的,其中花了不少的部分篇幅描述了一些计算机底层的概念,对于读者来说可能过于无趣,但如果你能认真看完,我相信你或多或少也会有一点收获。
不去深究,volatile只是一个普通的关键字。深入探讨,你会发现volatile是一个非常重要的知识点。volatile能将软件和硬件结合起来,想要彻底弄懂,需要深入到计算机的最底层。但如果你做到了。你对Java的认知一定会有进一步的提升。
只把眼光放在Java语言,似乎显得非常局限。发散到其他语言,C语言,C++里面也都有volatile关键字。我没有看过C语言,C++里面volatile关键字是如何实现的,但我相信底层的原理一定是相通的。
写在最后
本着对每一篇发出去的文章负责的原则,文中涉及知识理论,我都会尽量在官方文档和权威书籍找到并加以验证。但即使这样,我也不能保证文中每个点都是正确的,如果你发现错误之处,欢迎指出,我会对其修正。
创作不易,你的正反馈对我来说非常重要!点个赞,点个再看,点个关注甚至评论区发送一条666都是对我最大的支持!
我是CoderW,一个普通的程序员。
谢谢你的阅读,我们下期再见!
参考资料
- JSR-133: http://gee.cs.oswego.edu/dl/jmm/cookbook.html
- 《Java并发编程的艺术》
- 《深入理解Java虚拟机》第三版
- 《IA-32+架构软件开发人员手册》



