
Java 线程池中的线程复用是如何实现的?原创
前几天,技术群里有个群友问了一个关于线程池的问题,内容如图所示:
那么就来和大家探讨下这个问题,在线程池中,线程会从 workQueue 中读取任务来执行,最小的执行单位就是 Worker,Worker 实现了 Runnable 接口,重写了 run 方法,这个 run 方法是让每个线程去执行一个循环,在这个循环代码中,去判断是否有任务待执行,若有则直接去执行这个任务,因此线程数不会增加。

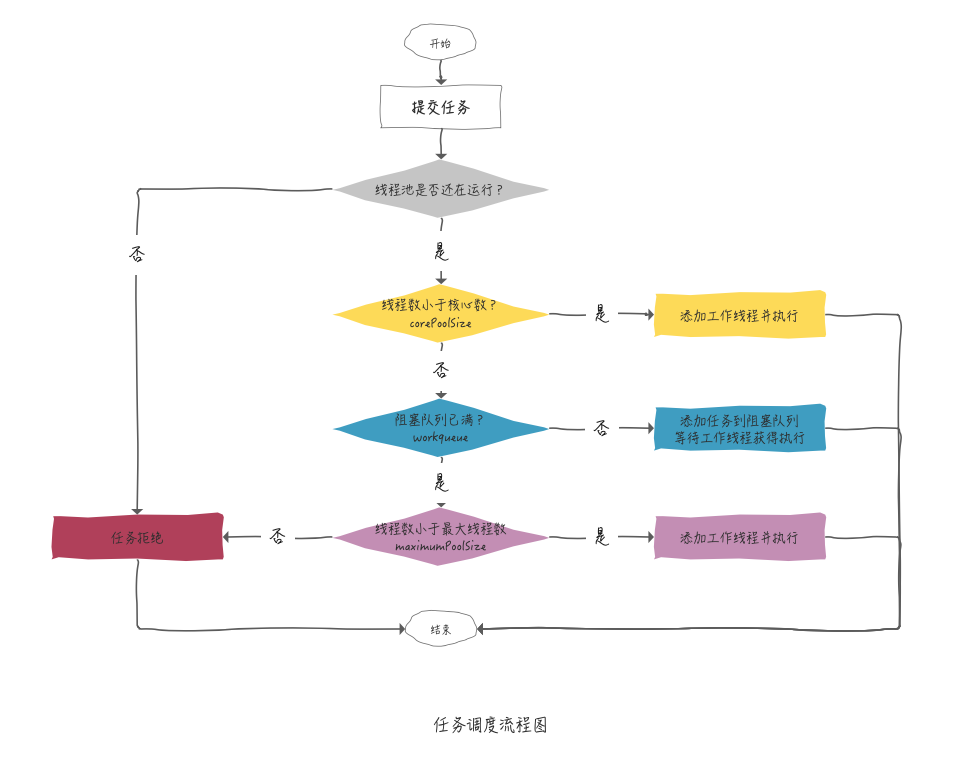
如下是线程池创建线程的整体流程图:
首先会判断线程池的状态,也就是是否在运行,若线程为非运行状态,则会拒绝。接下来会判断线程数是否小于核心线程数,若小于核心线程数,会新建工作线程并执行任务,随着任务的增多,线程数会慢慢增加至核心线程数,如果此时还有任务提交,就会判断阻塞队列 workQueue 是否已满,若没满,则会将任务放入到阻塞队列中,等待工作线程获得并执行,如果任务提交非常多,使得阻塞队达到上限,会去判断线程数是否小于最大线程数 maximumPoolSize,若小于最大线程数,线程池会添加工作线程并执行任务,如果仍然有大量任务提交,使得线程数等于最大线程数,如果此时还有任务提交,就会被拒绝。
现在我们对这个流程大致有所了解,那么让我们去看看源码是如何实现的吧!
线程池的任务提交从 submit 方法来说,submit 方法是 AbstractExecutorService 抽象类定义的,主要做了两件事情:
- 把 Runnable 和 Callable 都转化成 FutureTask
- 使用 execute 方法执行 FutureTask
execute 方法是 ThreadPoolExecutor 中的方法,源码如下:
public void execute(Runnable command) {
// 若任务为空,则抛 NPE,不能执行空任务
if (command == null) {
throw new NullPointerException();
}
int c = ctl.get();
// 若工作线程数小于核心线程数,则创建新的线程,并把当前任务 command 作为这个线程的第一个任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) {
return;
}
c = ctl.get();
}
/**
* 至此,有以下两种情况:
* 1.当前工作线程数大于等于核心线程数
* 2.新建线程失败
* 此时会尝试将任务添加到阻塞队列 workQueue
*/
// 若线程池处于 RUNNING 状态,将任务添加到阻塞队列 workQueue 中
if (isRunning(c) && workQueue.offer(command)) {
// 再次检查线程池标记
int recheck = ctl.get();
// 如果线程池已不处于 RUNNING 状态,那么移除已入队的任务,并且执行拒绝策略
if (!isRunning(recheck) && remove(command)) {
// 任务添加到阻塞队列失败,执行拒绝策略
reject(command);
}
// 如果线程池还是 RUNNING 的,并且线程数为 0,那么开启新的线程
else if (workerCountOf(recheck) == 0) {
addWorker(null, false);
}
}
/**
* 至此,有以下两种情况:
* 1.线程池处于非运行状态,线程池不再接受新的线程
* 2.线程处于运行状态,但是阻塞队列已满,无法加入到阻塞队列
* 此时会尝试以最大线程数为界创建新的工作线程
*/
else if (!addWorker(command, false)) {
// 任务进入线程池失败,执行拒绝策略
reject(command);
}
}
可以看到 execute 方法中的的核心方法为 addWorker,再去看 addWorker 方法之前,先看下 Worker 的初始化方法:
Worker(Runnable firstTask) {
// 每个任务的锁状态初始化为-1,这样工作线程在运行之前禁止中断
setState(-1);
this.firstTask = firstTask;
// 把 Worker 作为 thread 运行的任务
this.thread = getThreadFactory().newThread(this);
}
在 Worker 初始化时把当前 Worker 作为线程的构造器入参,接下来从 addWorker 方法中可以找到如下代码:
final Thread t = w.thread;
// 如果成功添加了 Worker,就可以启动 Worker 了
if (workerAdded) {
t.start();
workerStarted = true;
}
这块代码是添加 worker 成功,调用 start 方法启动线程,Thread t = w.thread; 此时的 w 是 Worker 的引用,那么t.start();实际上执行的就是 Worker 的 run 方法。
Worker 的 run 方法中调用了 runWorker 方法,简化后的 runWorker 源码如下:
final void runWorker(Worker w) {
Runnable task = w.firstTask;
while (task != null || (task = getTask()) != null) {
try {
task.run();
} finally {
task = null;
}
}
}
这个 while 循环有个 getTask 方法,getTask 的主要作用是阻塞从队列中拿任务出来,如果队列中有任务,那么就可以拿出来执行,如果队列中没有任务,这个线程会一直阻塞到有任务为止(或者超时阻塞),其中 getTask 方法的时序图如下:
其中线程复用的关键是 1.6 和 1.7 部分,这部分源码如下:
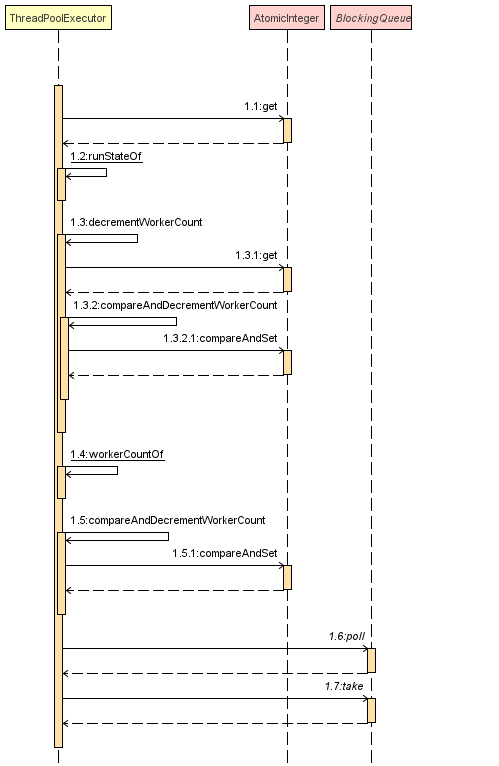
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
使用队列的 poll 或 take 方法从队列中拿数据,根据队列的特性,队列中有任务可以返回,队列中无任务会阻塞。
线程池的线程复用就是通过取 Worker 的 firstTask 或者通过 getTask 方法从 workQueue 中不停地取任务,并直接调用 Runnable 的 run 方法来执行任务,这样就保证了每个线程都始终在一个循环中,反复获取任务,然后执行任务,从而实现了线程的复用。
总结
本文主要从源码的角度解析了 Java 线程池中的线程复用是如何实现的。欢迎大家留言交流讨论。
更详细的源码解析可以点击链接查看:https://github.com/wupeixuan/JDKSourceCode1.8



