
Prometheus时序数据库-报警的计算原创
前言
在前面的文章中,笔者详细的阐述了Prometheus的数据插入存储查询等过程。但作为一个监控神器,报警计算功能是必不可少的。自然的Prometheus也提供了灵活强大的报警规则可以让我们自由去发挥。在本篇文章里,笔者就带读者去看下Prometheus内部是怎么处理报警规则的。
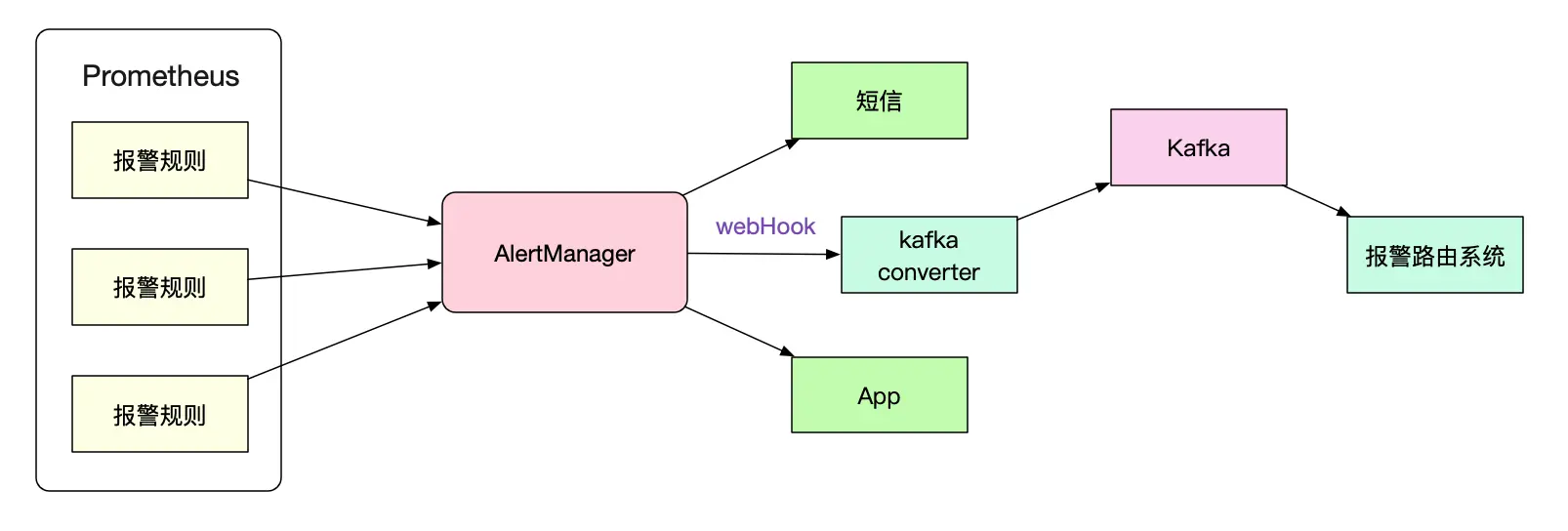
报警架构
Prometheus只负责进行报警计算,而具体的报警触发则由AlertManager完成。如果我们不想改动AlertManager以完成自定义的路由规则,还可以通过webhook外接到另一个系统(例如,一个转换到kafka的程序)。
在本篇文章里,笔者并不会去设计alertManager,而是专注于Prometheus本身报警规则的计算逻辑。
一个最简单的报警规则
rules:
alert: HTTPRequestRateLow
expr: http_requests < 100
for: 60s
labels:
severity: warning
annotations:
description: "http request rate low"
这上面的规则即是http请求数量<100从持续1min,则我们开始报警,报警级别为warning
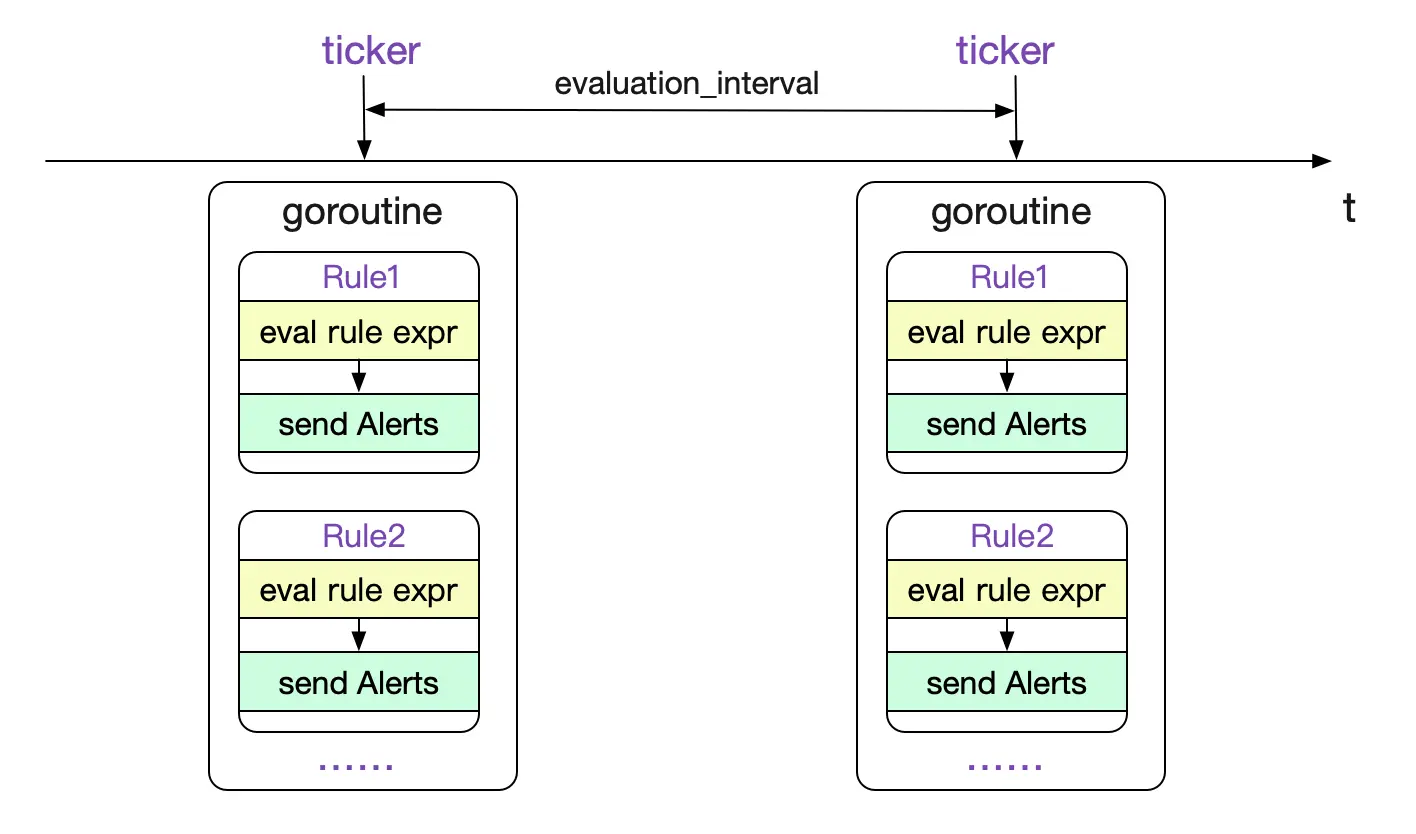
什么时候触发这个计算
在加载完规则之后,Prometheus按照evaluation_interval这个全局配置去不停的计算Rules。代码逻辑如下所示:
rules/manager.go
func (g *Group) run(ctx context.Context) {
iter := func() {
......
g.Eval(ctx,evalTimestamp)
......
}
// g.interval = evaluation_interval
tick := time.NewTicker(g.interval)
defer tick.Stop()
......
for {
......
case <-tick.C:
......
iter()
}
}
而g.Eval的调用为:
func (g *Group) Eval(ctx context.Context, ts time.Time) {
// 对所有的rule
for i, rule := range g.rules {
......
// 先计算出是否有符合rule的数据
vector, err := rule.Eval(ctx, ts, g.opts.QueryFunc, g.opts.ExternalURL)
......
// 然后发送
ar.sendAlerts(ctx, ts, g.opts.ResendDelay, g.interval, g.opts.NotifyFunc)
}
......
}
整个过程如下图所示:
对单个rule的计算
我们可以看到,最重要的就是rule.Eval这个函数。代码如下所示:
func (r *AlertingRule) Eval(ctx context.Context, ts time.Time, query QueryFunc, externalURL *url.URL) (promql.Vector, error) {
// 最终调用了NewInstantQuery
res, err = query(ctx,r.vector.String(),ts)
......
// 报警组装逻辑
......
// active 报警状态变迁
}
这个Eval包含了报警的计算/组装/发送的所有逻辑。我们先聚焦于最重要的计算逻辑。也就是其中的query。其实,这个query是对NewInstantQuery的一个简单封装。
func EngineQueryFunc(engine *promql.Engine, q storage.Queryable) QueryFunc {
return func(ctx context.Context, qs string, t time.Time) (promql.Vector, error) {
q, err := engine.NewInstantQuery(q, qs, t)
......
res := q.Exec(ctx)
}
}
也就是说它执行了一个瞬时向量的查询。而其查询的表达式按照我们之前给出的报警规则,即是
**http_requests < 100 **
既然要计算表达式,那么第一步,肯定是将其构造成一颗AST。其树形结构如下图所示:
解析出左节点是个VectorSelect而且知道了其lablelMatcher是
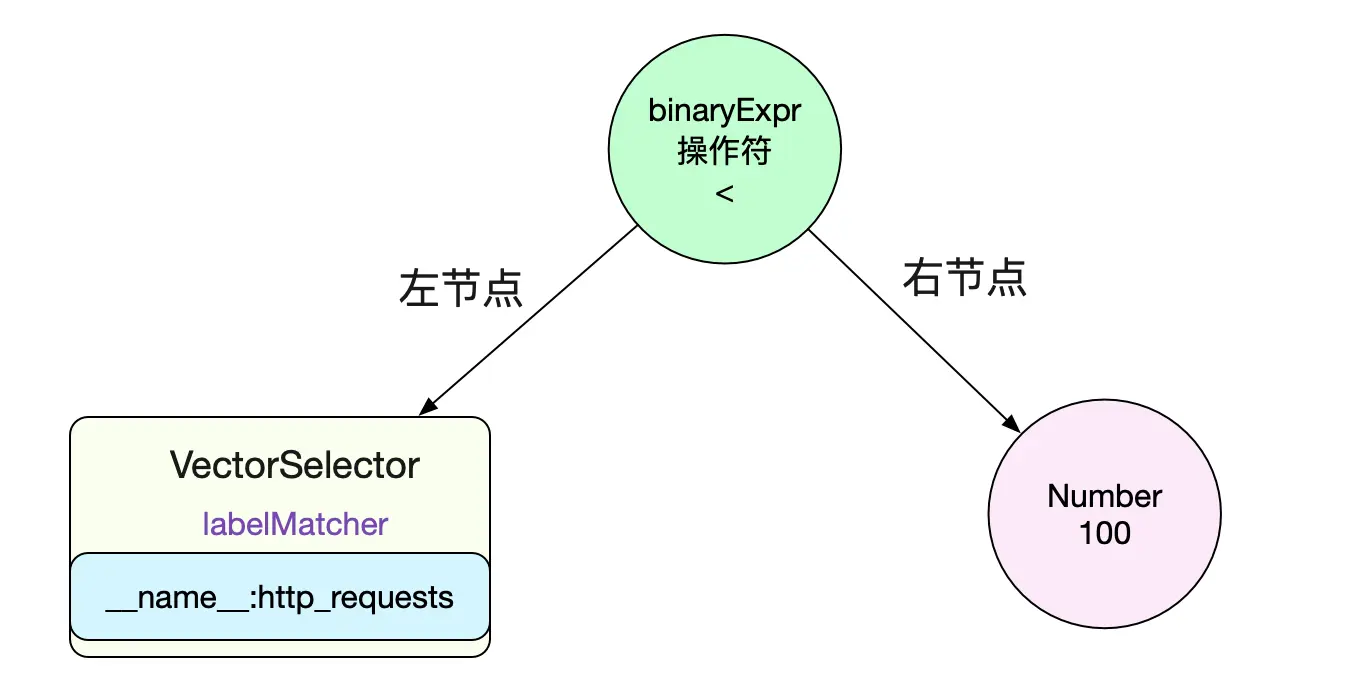
__name__:http_requests
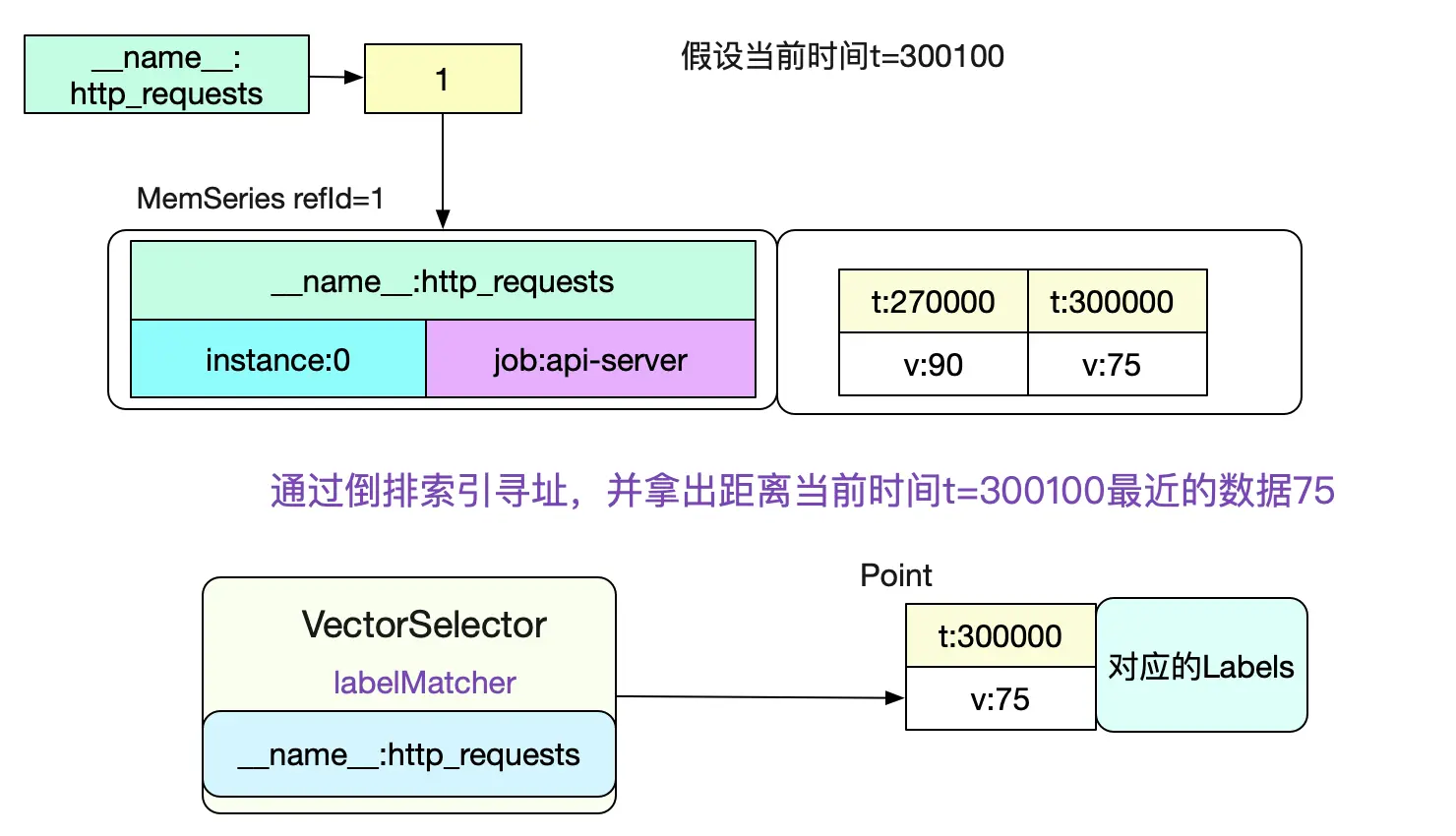
那么我们就可以左节点VectorSelector进行求值。直接利用倒排索引在head中查询即可(因为instant query的是当前时间,所以肯定在内存中)。
想知道具体的计算流程,可以见笔者之前的博客《Prometheus时序数据库-数据的查询》 计算出左节点的数据之后,我们就可以和右节点进行比较以计算出最终结果了。具体代码为:
func (ev *evaluator) eval(expr Expr) Value {
......
case *BinaryExpr:
......
case lt == ValueTypeVector && rt == ValueTypeScalar:
return ev.rangeEval(func(v []Value, enh *EvalNodeHelper) Vector {
return ev.VectorscalarBinop(e.Op, v[0].(Vector), Scalar{V: v[1].(Vector)[0].Point.V}, false, e.ReturnBool, enh)
}, e.LHS, e.RHS)
.......
}
最后调用的函数即为:
```func (ev *evaluator) VectorBinop(op ItemType, lhs, rhs Vector, matching *VectorMatching, returnBool bool, enh *EvalNodeHelper) Vector {
// 对左节点计算出来的所有的数据sample
for _, lhsSample := range lhs {
......
// 由于左边lv = 75 < 右边rv = 100,且op为less
/**
vectorElemBinop(){
case LESS
return lhs, lhs < rhs
}
**/
// 这边得到的结果value=75,keep = true
value, keep := vectorElemBinop(op, lv, rv)
......
if keep {
......
// 这边就讲75放到了输出里面,也就是说我们最后的计算确实得到了数据。
enh.out = append(enh.out.sample)
}
}
}
如下图所示:
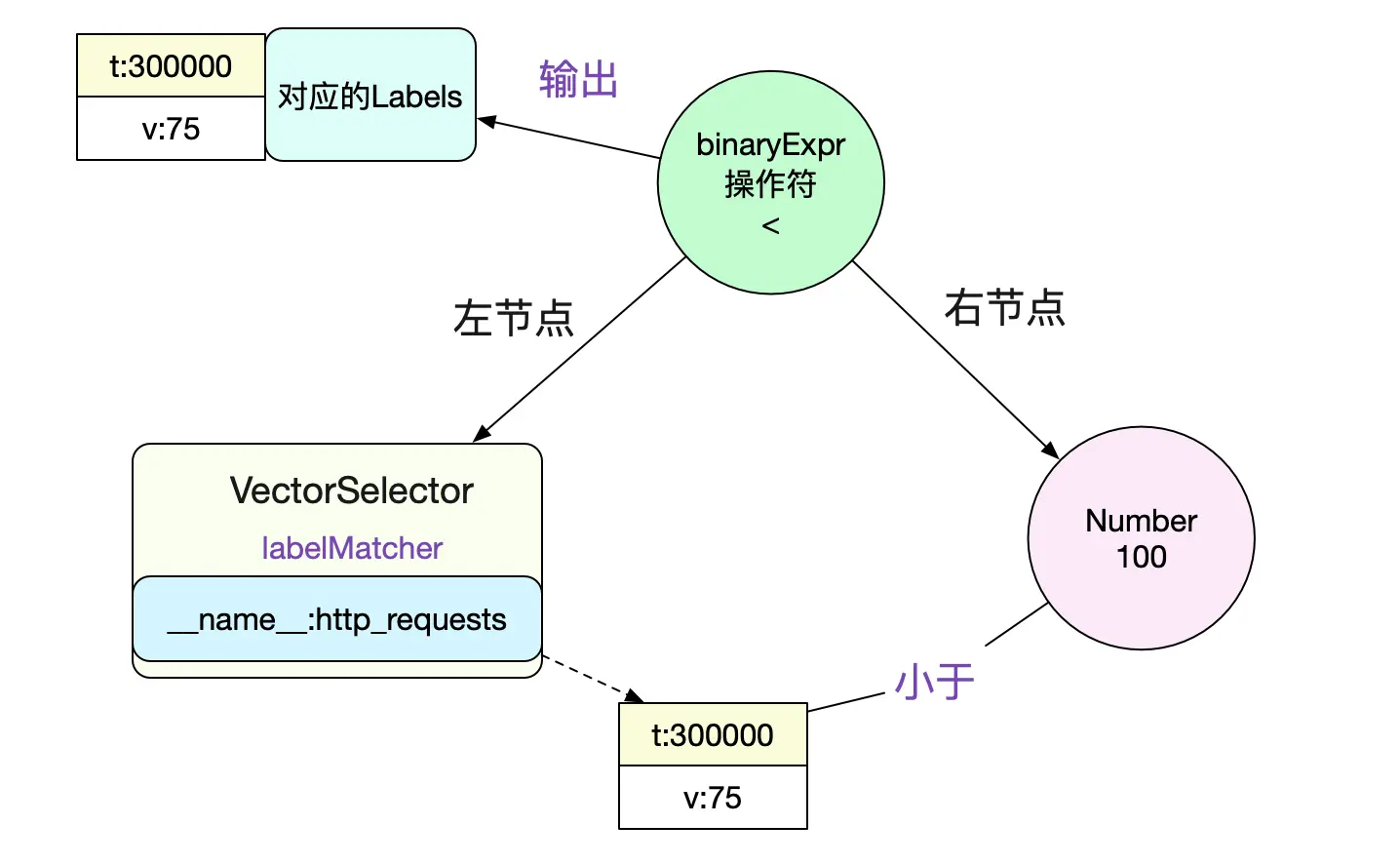
最后我们的expr输出即为
sample {
Point {t:0,V:75}
Metric {__name__:http_requests,instance:0,job:api-server}
}
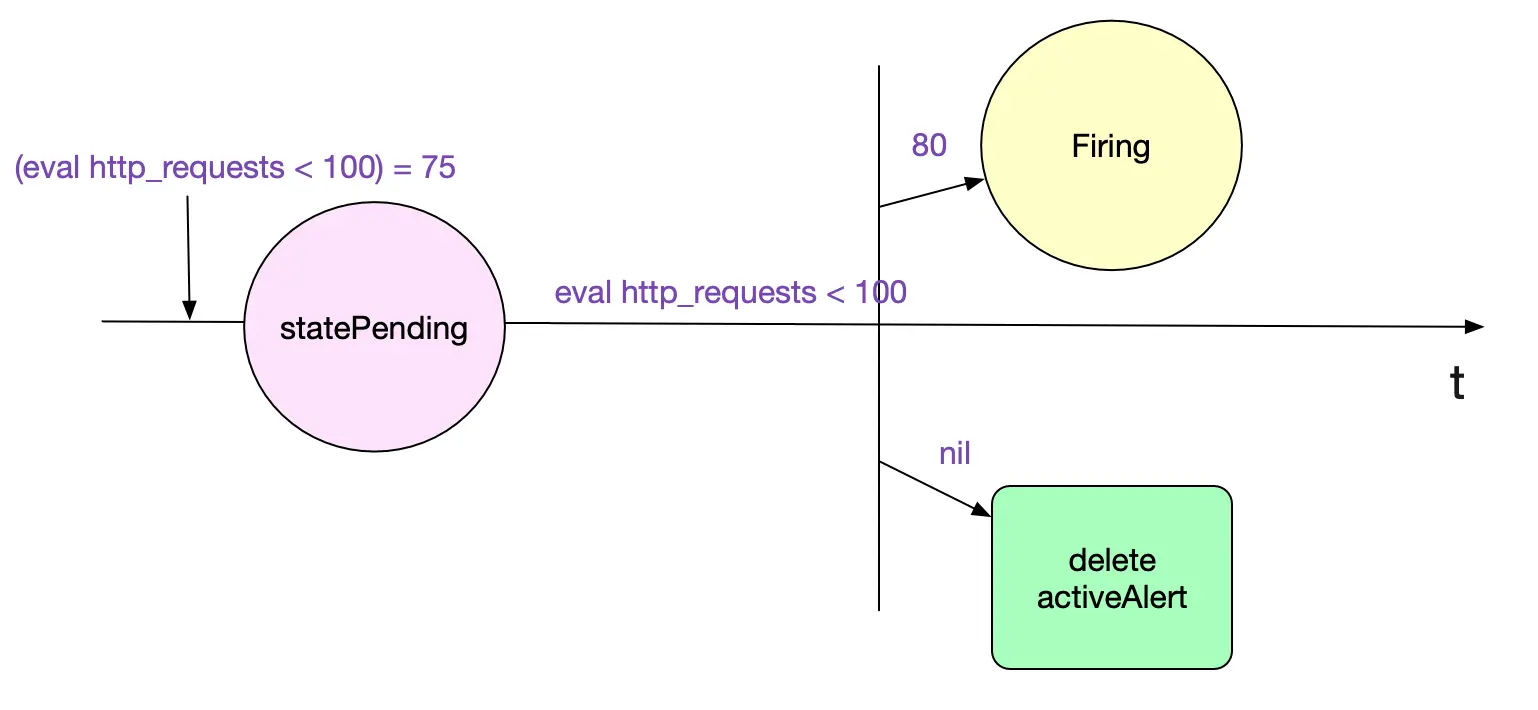
报警状态变迁
计算过程讲完了,笔者还稍微讲一下报警的状态变迁,也就是最开始报警规则中的rule中的for,也即报警持续for(规则中为1min),我们才真正报警。为了实现这种功能,这就需要一个状态机了。笔者这里只阐述下从Pending(报警出现)->firing(真正发送)的逻辑。
在之前的Eval方法里面,有下面这段
for _, smpl := range res {
......
if alert, ok := r.active[h]; ok && alert.State != StateInactive {
alert.Value = smpl.V
alert.Annotations = annotations
continue
}
// 如果这个告警不在active map里面,则将其放入
// 注意,这里的hash依旧没有拉链法,有极小概率hash冲突
r.active[h] = &Alert{
Labels: lbs,
Annotations: annotations,
ActiveAt: ts,
State: StatePending,
Value: smpl.V,
}
}
......
// 报警状态的变迁逻辑
for fp, a := range r.active {
// 如果当前r.active的告警已经不在刚刚计算的result里面了 if _, ok := resultFPs[fp]; !ok {
// 如果状态是Pending待发送
if a.State == StatePending || (!a.ResolvedAt.IsZero() && ts.Sub(a.ResolvedAt) > resolvedRetention) {
delete(r.active, fp)
}
......
continue
}
// 对于已有的Active报警,如果其Active的时间>r.holdDuration,也就是for指定的
if a.State == StatePending && ts.Sub(a.ActiveAt) >= r.holdDuration {
// 我们将报警置为需要发送
a.State = StateFiring
a.FiredAt = ts
}
......
}
}
上面代码逻辑如下图所示:
总结
Prometheus作为一个监控神器,给我们提供了各种各样的遍历。其强大的报警计算功能就是其中之一。了解其中告警的计算原理,才能让我们更好的运用它。
相关阅读


