
Prometheus时序数据库-数据的插入原创
前言
在之前的文章里,笔者详细的阐述了Prometheus时序数据库在内存和磁盘中的存储结构。有了前面的铺垫,笔者就可以在本篇文章阐述下数据的插入过程。
监控数据的插入
在这里,笔者并不会去讨论Promtheus向各个Endpoint抓取数据的过程。而是仅仅围绕着数据是如何插入Prometheus的过程做下阐述。对应方法:
func (a *headAppender) Add(lset labels.Labels, t int64, v float64) (uint64, error) {
......
// 如果lset对应的series没有,则建一个。同时把新建的series放入倒排Posting映射里面
s, created := a.head.getOrCreate(lset.Hash(), lset)
if created { // 如果新创建了一个,则将新建的也放到a.series里面
a.series = append(a.series, record.RefSeries{
Ref: s.ref,
Labels: lset,
})
}
return s.ref, a.AddFast(s.ref, t, v)
}
我们就以下面的add函数调用为例:
app.Add(labels.FromStrings("foo", "bar"), 0, 0)
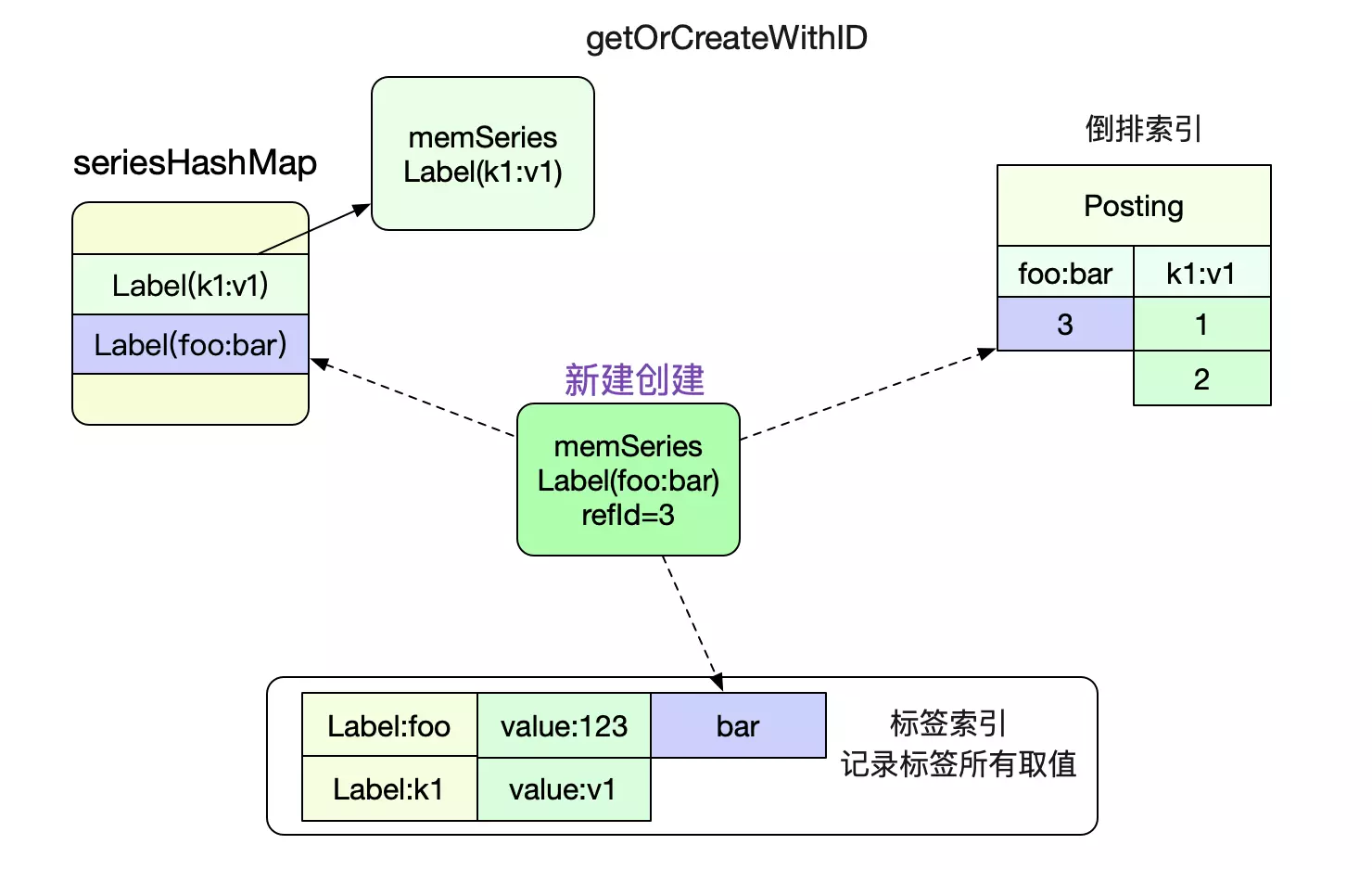
首先是getOrCreate,顾名思义,不存在则创建一个。创建的过程包含了seriesHashMap/Postings(倒排索引)/LabelIndex的维护。如下图所示:
然后是AddFast方法
func (a *headAppender) AddFast(ref uint64, t int64, v float64) error{
// 拿出对应的memSeries
s := a.head.series.getByID(ref)
......
// 设置为等待提交状态
s.pendingCommit=true
......
// 为了事务概念,放入temp存储,等待真正commit时候再写入memSeries
a.samples = append(a.samples, record.RefSample{Ref: ref,T: t,V: v,})
//
}
Prometheus在add数据点的时候并没有直接add到memSeries(也就是query所用到的结构体里),而是加入到一个临时的samples切片里面。同时还将这个数据点对应的memSeries同步增加到另一个sampleSeries里面。
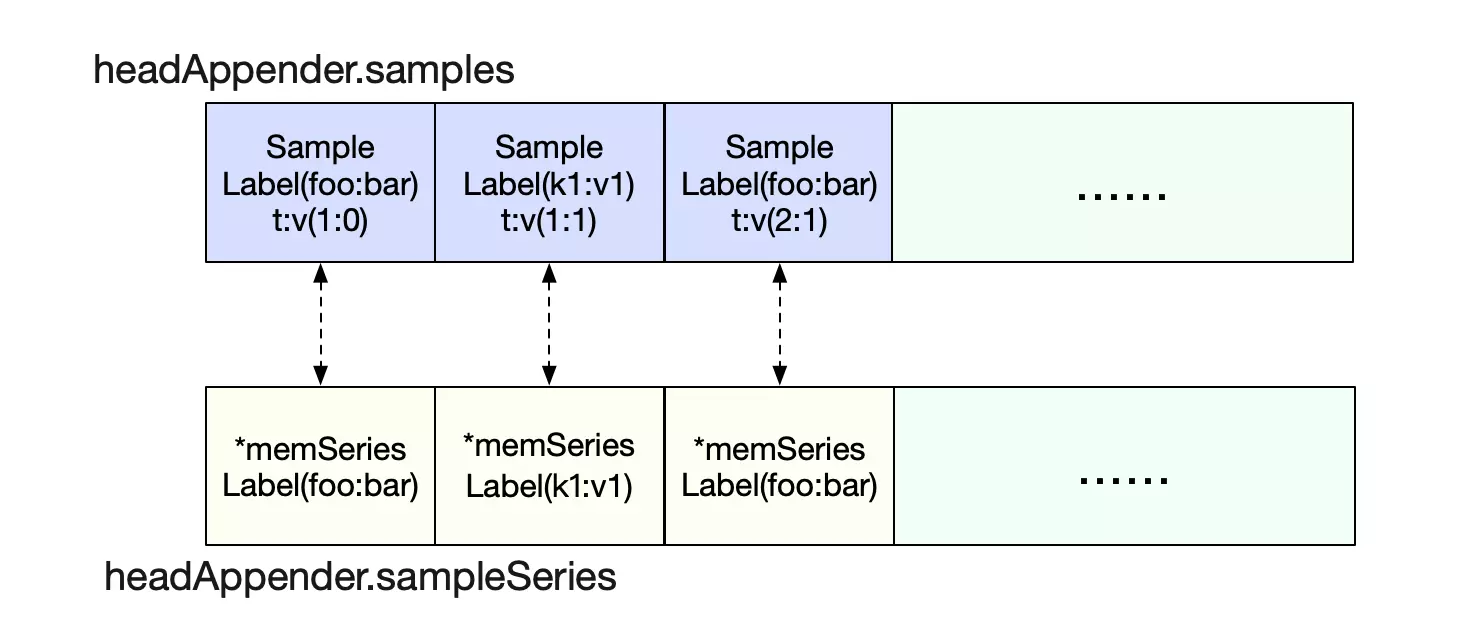
事务可见性
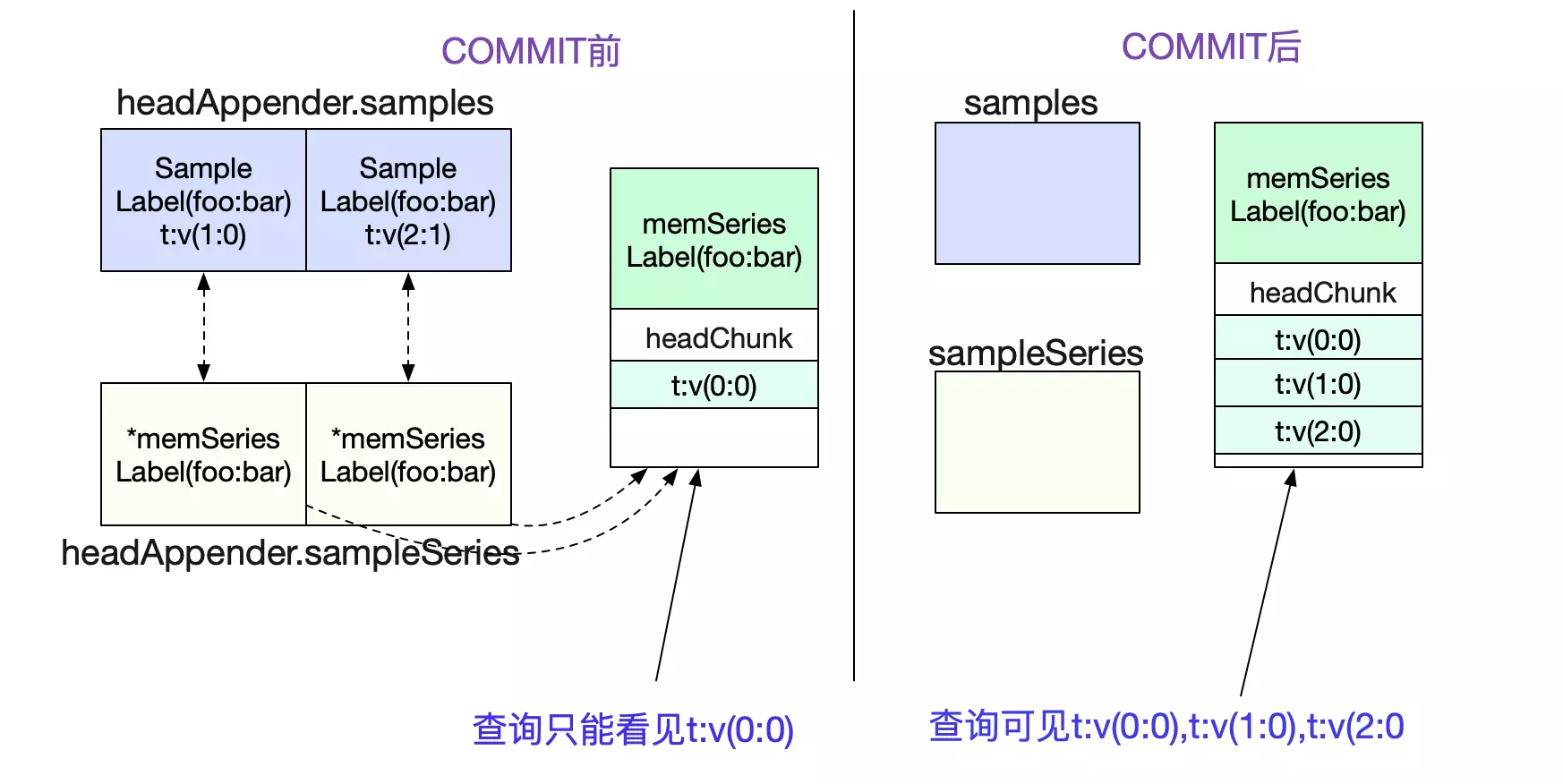
为什么要这么做呢?就是为了实现commit语义,只有commit过后数据才可见(能被查询到)。否则,无法见到这些数据。而commit的动作主要就是WAL(Write Ahead Log)以及将headerAppender.samples数据写到其对应的memSeries中。这样,查询就可见这些数据了,如下图所示:
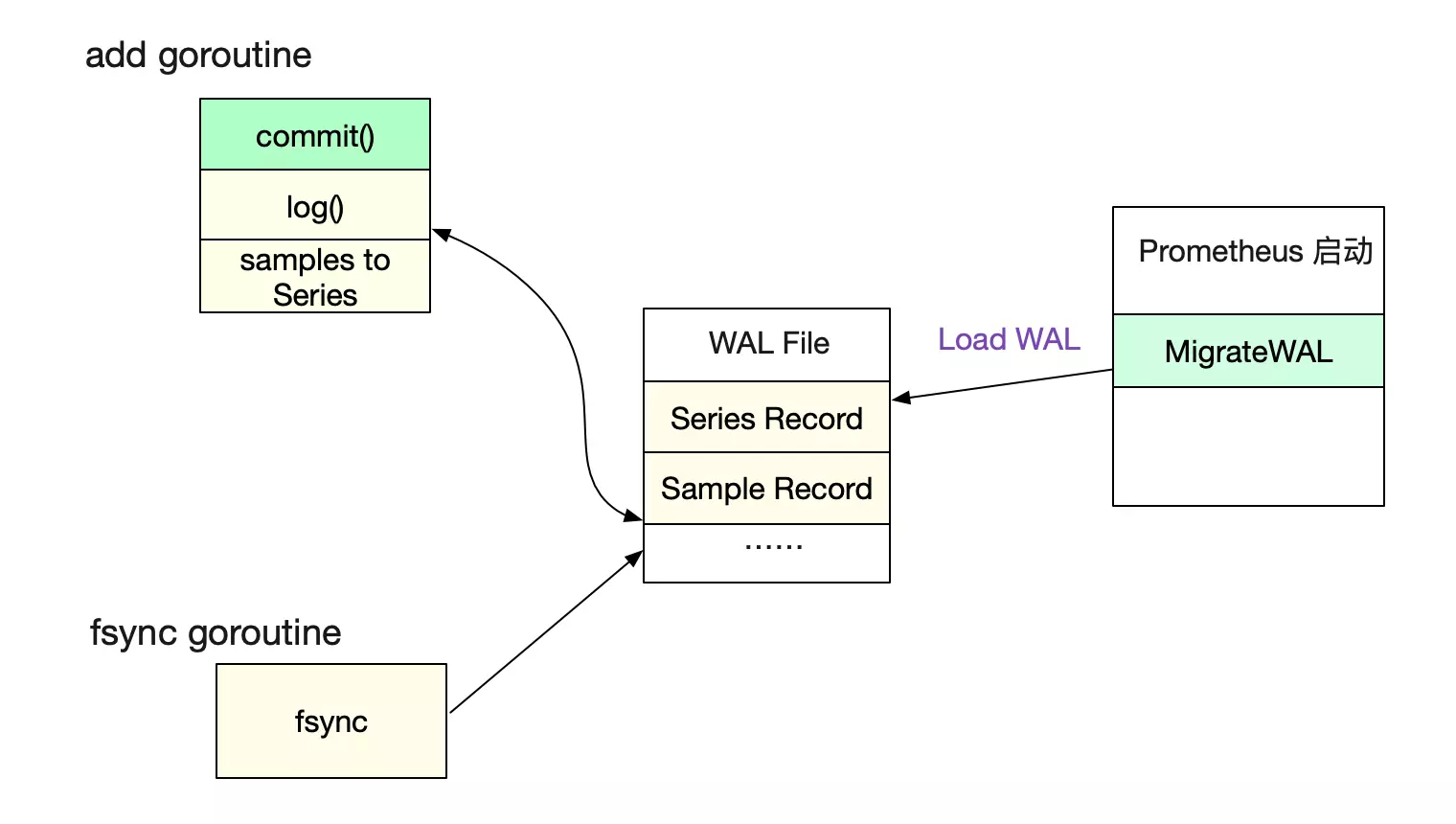
WAL
由于Prometheus最近的数据是保存在内存里面的,未防止服务器宕机丢失数据。其在commit之前先写了日志WAL。等服务重启的时候,再从WAL日志里面获取信息并重放。
为了性能,Prometheus了另一个goroutine去做文件的sync操作,所以并不能保证WAL不丢。进而也不能保证监控数据完全不丢。这点也是监控业务的特性决定的。
写入代码为:
commit()
|=>
func (a *headAppender) log() error {
......
// 往WAL写入对应的series信息
if len(a.series) > 0 {
rec = enc.Series(a.series, buf)
buf = rec[:0]
if err := a.head.wal.Log(rec); err != nil {
return errors.Wrap(err, "log series")
}
}
......
// 往WAL写入真正的samples
if len(a.samples) > 0 {
rec = enc.Samples(a.samples, buf)
buf = rec[:0]
if err := a.head.wal.Log(rec); err != nil {
return errors.Wrap(err, "log samples")
}
}
}
对应的WAL日志格式为:
Series records
┌────────────────────────────────────────────┐
│ type = 1 <1b> │
├────────────────────────────────────────────┤
│ ┌─────────┬──────────────────────────────┐ │
│ │ id <8b> │ n = len(labels) <uvarint> │ │
│ ├─────────┴────────────┬─────────────────┤ │
│ │ len(str_1) <uvarint> │ str_1 <bytes> │ │
│ ├──────────────────────┴─────────────────┤ │
│ │ ... │ │
│ ├───────────────────────┬────────────────┤ │
│ │ len(str_2n) <uvarint> │ str_2n <bytes> │ │
│ └───────────────────────┴────────────────┘ │
│ . . . │
└────────────────────────────────────────────┘
Sample records
┌──────────────────────────────────────────────────────────────────┐
│ type = 2 <1b> │
├──────────────────────────────────────────────────────────────────┤
│ ┌────────────────────┬───────────────────────────┐ │
│ │ id <8b> │ timestamp <8b> │ │
│ └────────────────────┴───────────────────────────┘ │
│ ┌────────────────────┬───────────────────────────┬─────────────┐ │
│ │ id_delta <uvarint> │ timestamp_delta <uvarint> │ value <8b> │ │
│ └────────────────────┴───────────────────────────┴─────────────┘ │
│ . . . │
└──────────────────────────────────────────────────────────────────┘
见Prometheus WAL.md
落盘存储
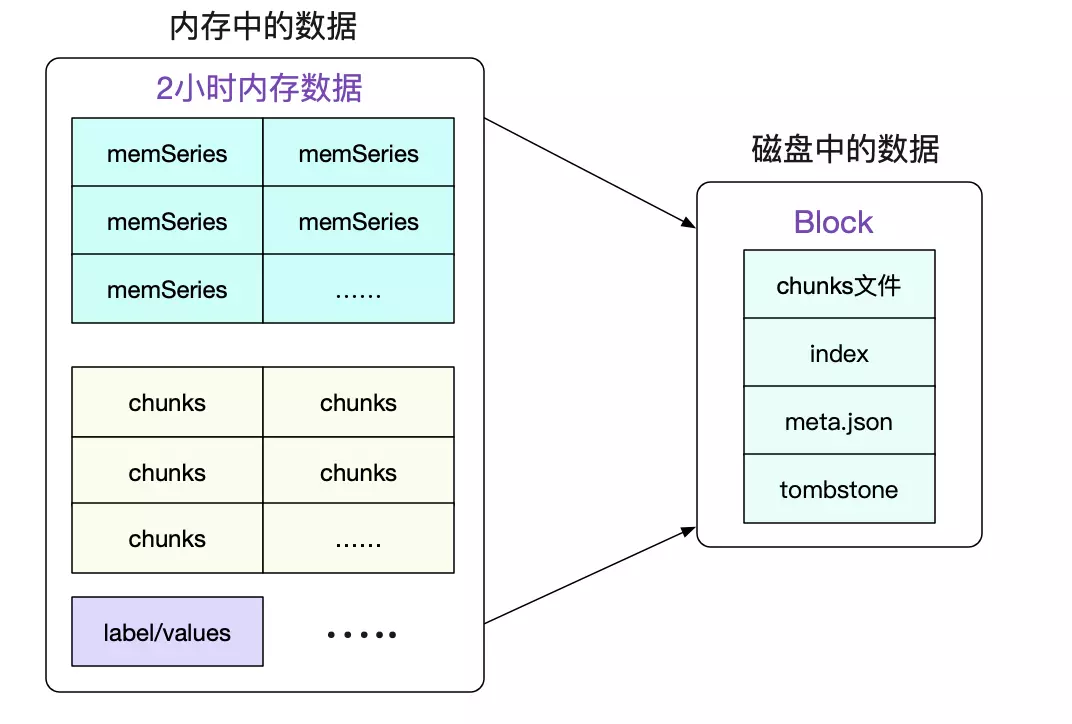
之前描述的所有数据都是写到内存里面。最终落地是通过compator routine将每两个小时的数据打包到一个Blocks里面。
具体可见笔者之前的文章《Prometheus时序数据库-磁盘中的存储结构》
总结
在这篇文章里,笔者详细描述了Prometheus数据的插入过程。在下一篇文章里面,笔者会继续阐述Prometheus数据的查询过程。
感谢大家观看本次分享,欢迎大家进行留言、评论哦~
相关阅读


