
Prometheus时序数据库-数据的抓取原创
前言
在之前的文章里,笔者详细的阐述了数据的存储/写入以及查询过程。那么Prometheus又是怎么去主动获得数据的呢?这个问题,笔者将在本篇文章详细阐述。
Pull模式
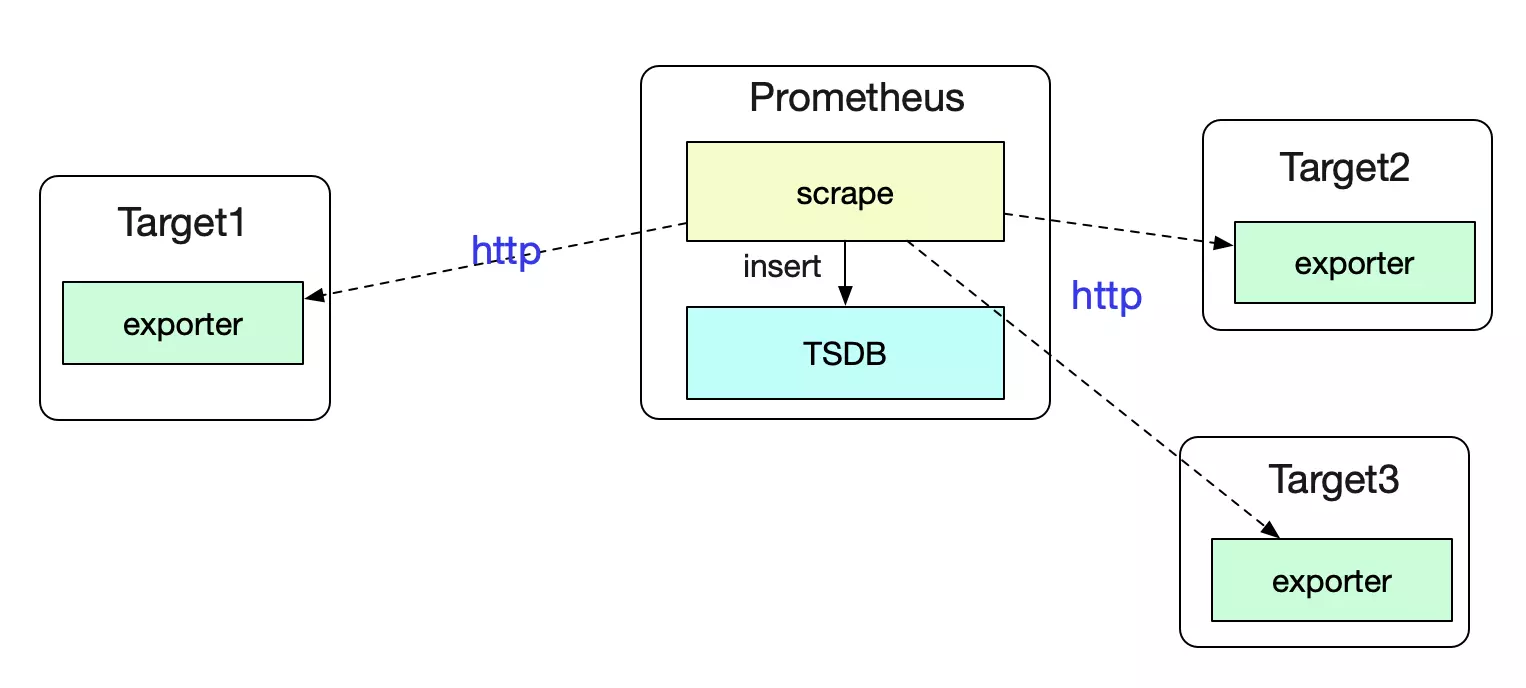
Prometheus是通过pull从各个Target(目标)Exporter中去获取数据。
作为一个成熟的监控系统,自然可以对这些Target进行自动发现。下面,笔者就阐述下Prometheus自动发现的过程。
配置的加载
首先,我们需要告诉Prometheus要通过什么样的方式去自动获取Targets。这就是我们的scrape_configs。
scrape_configs
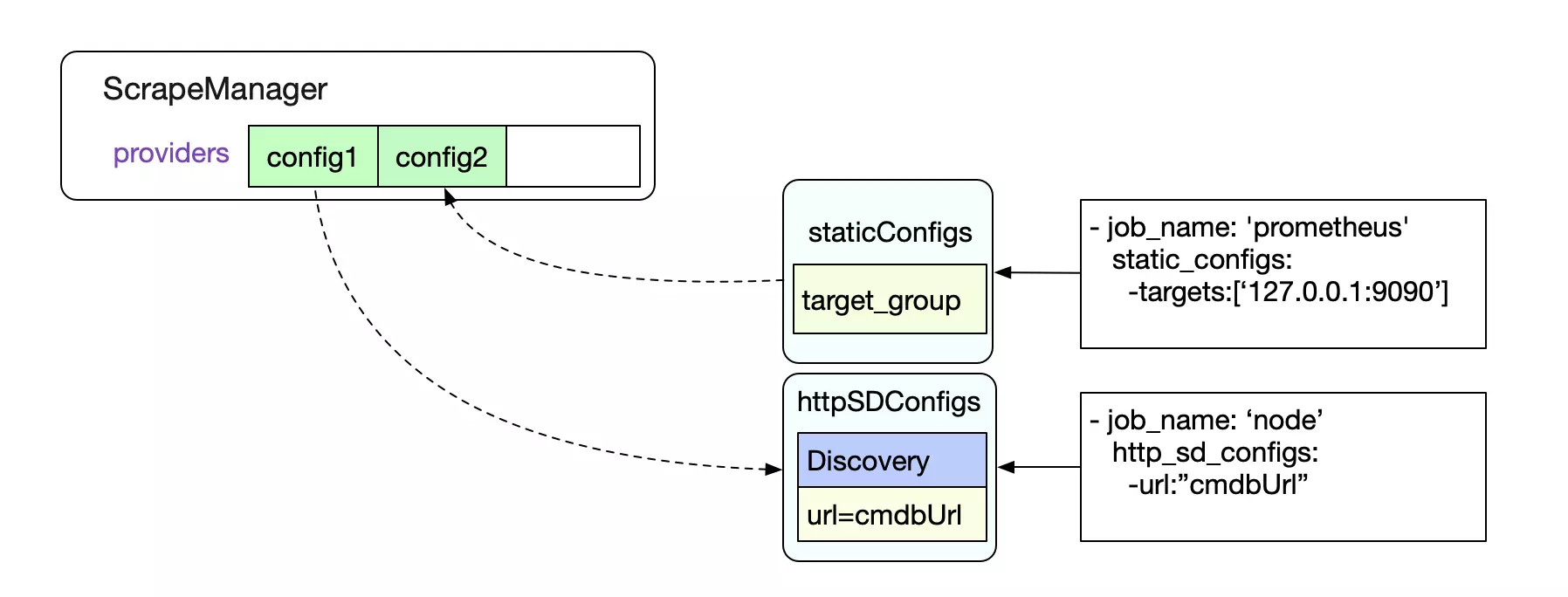
先给出一个scrape_configs的例子:
prometheus.yml
global:
scrape_interval: 60s
scrape_timeout: 40s
......
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['127.0.0.1:9090']
- job_name: 'node'
http_sd_configs:
- url:"http://cmdbIp:8080/queryAll'
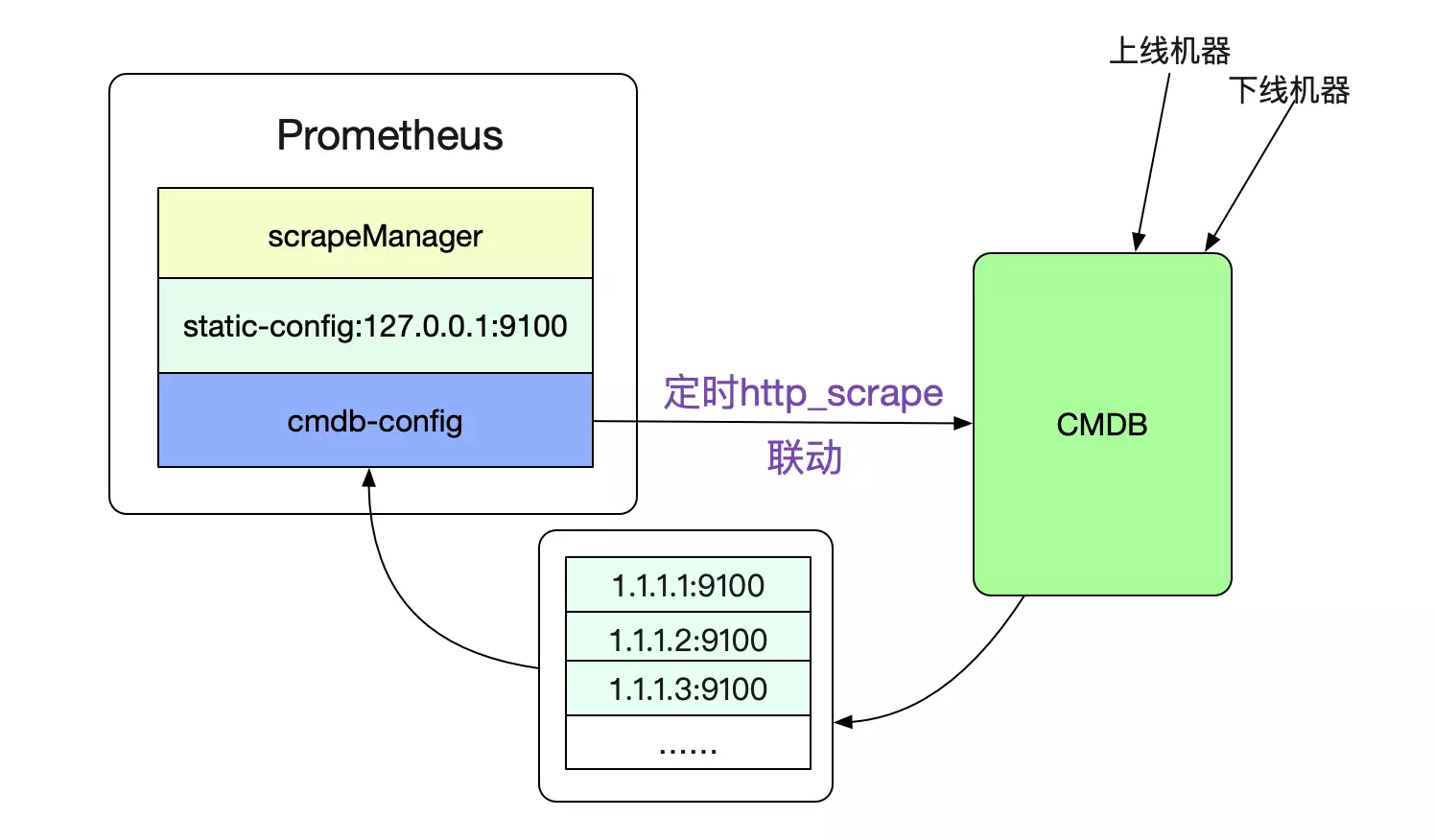
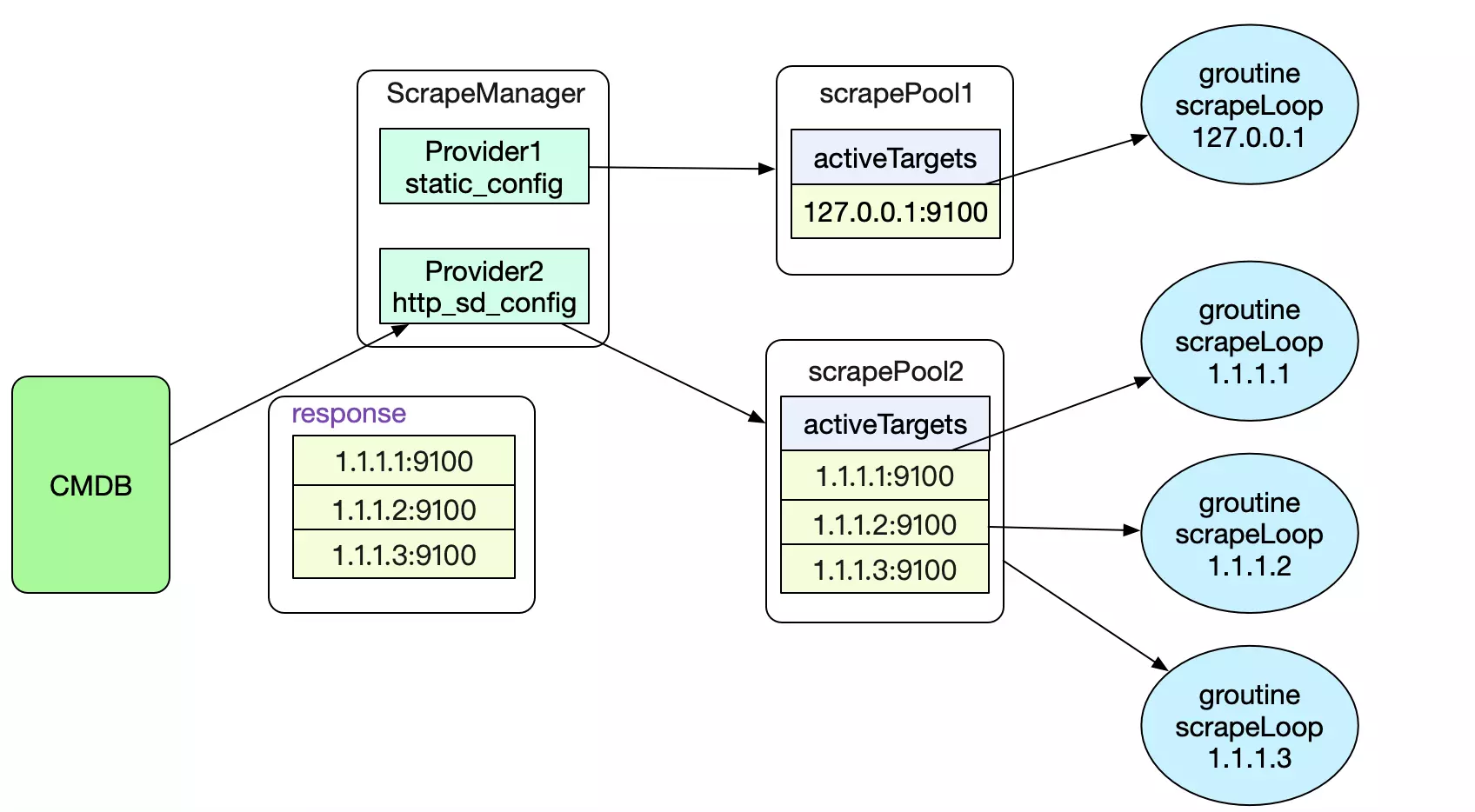
这个yml文件里面,定义了两个job,分别为抓取127.0.0.1:9100这个监控Prometheus自身的job。第二个为我们自定义的http_sd_confgis,向我们的cmdb获取数据。这样,Prometheus就可以和我们本身的运维基础设施联动了。
好了,为了能够完成这样的自发现功能,我们首先要解析出scrape_configs中的元数据。
scrape_configs的元数据解析
这样的元配置数据信息肯定是在启动的时候就已经加载好了。所以我们去观察main.go。
main.go
func main() {
// 对scrape_configs配置建立providers,providers会提供最终所有的Target
func(cfg *config.Config) error {
c := make(map[string]sd_config.ServiceDiscoveryConfig)
for _, v := range cfg.ScrapeConfigs {
c[v.JobName] = v.ServiceDiscoveryConfig
}
return discoveryManagerScrape.ApplyConfig(c)
},
}
上面的匿名函数中,将读取到的scrape_configs和其job名建立映射,然后调用discoveryManagerScrape.ApplyConfig去建立providers(Targets的提供者)。我们观察下代码:
discoveryManagerScrape.ApplyConfig
func (m *Manager) ApplyConfig(cfg map[string]sd_config.ServiceDiscoveryConfig) error {
......
// 为每个scrape_config都建立一个provider并注册
for name, scfg := range cfg {
failedCount += m.registerProviders(scfg, name)
discoveredTargets.WithLabelValues(m.name, name).Set(0)
}
// 启动所有的providers,也就启动了不停的抓取过程
for _, prov := range m.providers {
m.startProvider(m.ctx, prov)
}
}
其中注册过程如下,根据不同的scrapeConfigs类型生成不同的provider,然后放到一个scrapeManager的成员providers切片里面。
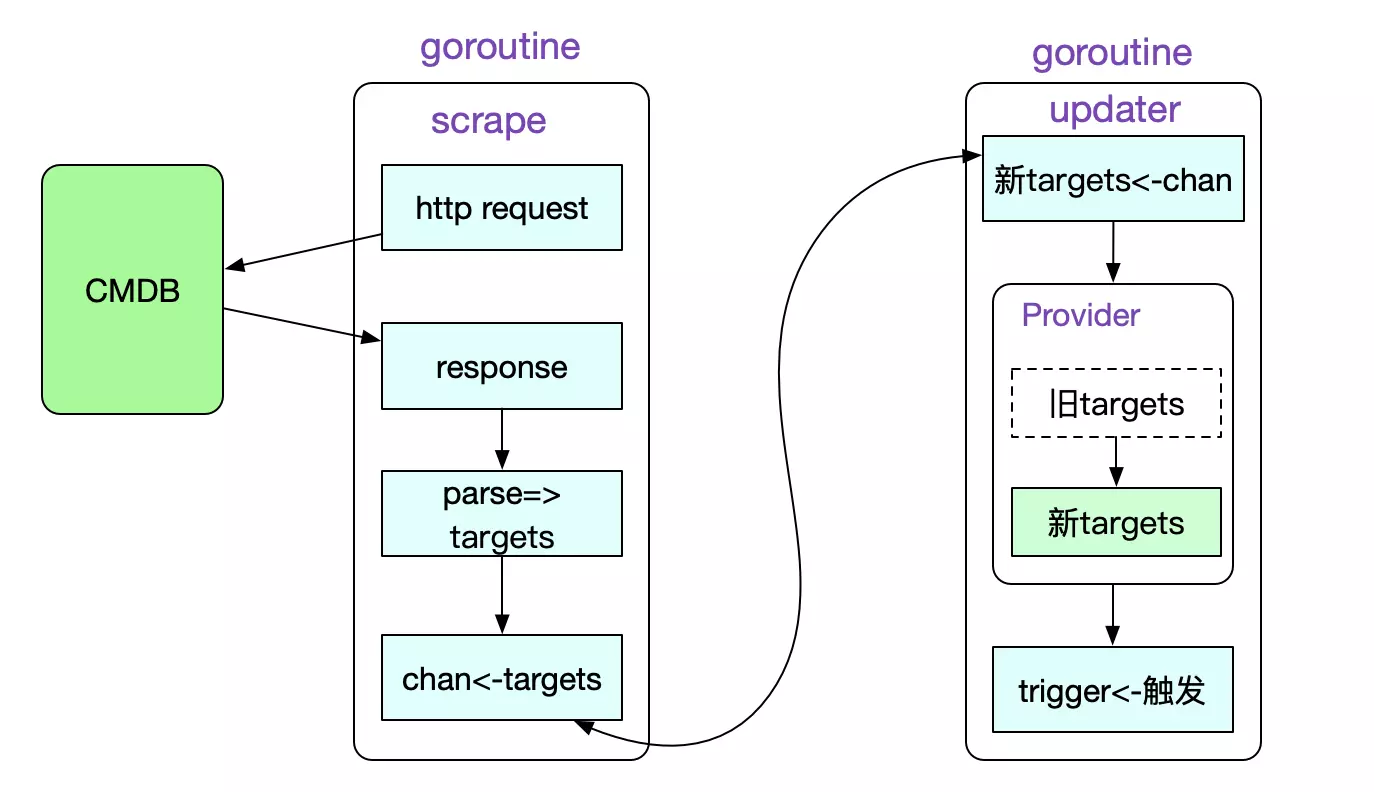
在我们解析出所有的provider之后,就可以启动provider来进行不停抓取所有Target的过程了。注意这里只是监控目标的抓取,并非抓取真正的数据。
func (m *Manager) startProvider(ctx context.Context, p *provider) {
......
// 抓取最新Targets的goroutine
go p.d.Run(ctx, updates)
// 将Prometheus现有Targets集合替换为新Targets(刚抓取到的)的携程
go m.updater(ctx, p, updates)
}
Prometheus对每个provider分了两个goroutine来进行更新Targets(监控对象)集合的操作,第一个是不同的获取最新Targets的goroutine。在抓取到之后,会由updater goroutine来热更新当前抓取目标。更新完目标targets后,再触发triggerSend chan。
这样做,虽然将逻辑变复杂了,但很好的将scrape的过程与更新target的过程隔离了开来。
防止更新过于频繁
为了防止更新过于频繁,Prometheus通过一个ticker去限制更新频率。
manager.go
func (m *Manager) sender(){
ticker := time.NewTicker(m.updatert)
defer ticker.Stop()
......
for {
.....
select {
......
case <-ticker.C:
......
case <-m.triggerSend
......
case m.synch <- m.allGroups
......
}
}
}
如代码中所见,只有在ticker每秒触发后才会去检测triggerSend信号,这样就不会频繁的触发重建scrape targets逻辑了。代码中,我们最终将allGroups,也就是m.targets(刚刚更新过的)的所有数据全部取出送入到m.synch
通过m.synch触发更新manger.targetSets,最后触发reloader信号,如下代码所示:

scrape/manager.go
func (m *Manager) Run(tsets <-chan map[string][]*targetgroup.Group) error {
go m.reloader()
for {
select {
case ts := <-tsets:
m.updateTsets(ts)
select {
case m.triggerReload <- struct{}{}:
default:
}
case <-m.graceShut:
return nil
}
}
}
reloader操作
好了,终于到我们的reloader操作了,也就是真正改变Prometheus抓取目标动作的地方。 首先,我们对每一个provider(及其底下的subs)建立一个scrapePool,并对每个target建立一个goroutine去exporter定时抓取数据。
func (sp *scrapePool) sync(targets []*Target) {
// 这段hash代码会有问题,hash出来不是唯一的
for _, t := range targets {
......
// 为每一个target建立一个goroutine
go l.run(interval, timeout, nil)
......
}
......
// Stop and remove old targets and scraper loops.
for hash := range sp.activeTargets {
if _, ok := uniqueTargets[hash]; !ok {
......
l.stop()
.....
}
......
}
......
}
由于我们这边是reloader逻辑,所以Prometheus还会去比对这次的target集合和之前的target集合的差异。如果有新的,则新建goroutine去scrap,如果老集合中有的元素已经过期了,则stop对应的goroutine。
值得注意的是,这边Prometheus直接用hash代替targets去判断是否存在,而hash并不能和target一一对应,所以这边是有些问题的!需要拉链法进一步去判断。
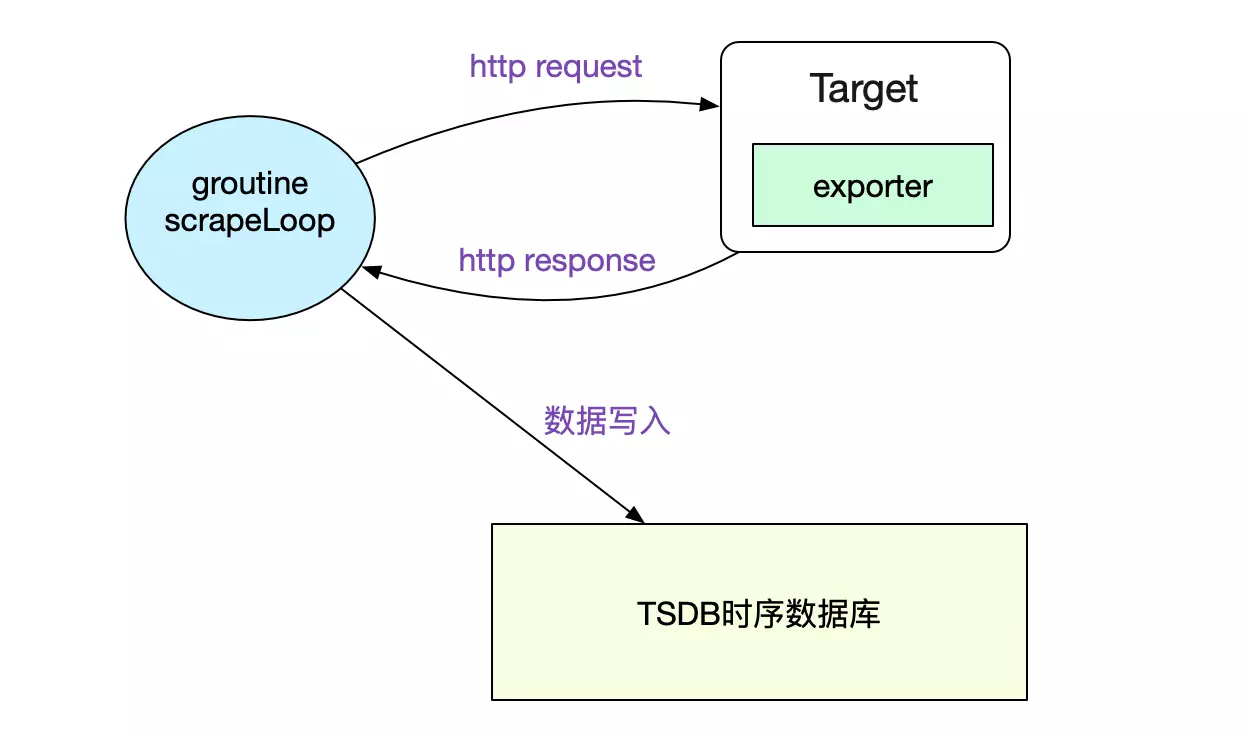
抓取单个Target的实际数据
我们通过scrapeLoop去定时从不同的Target获取数据并写入到TSDB(时序数据库里面)。
scrape.go
func (sl *scrapeLoop) run(interval, timeout time.Duration, errc chan<- error) {
......
mainLoop:
......
// 发起http请求,并获取结果
contentType, scrapeErr := sl.scraper.scrape(scrapeCtx, buf)
......
// 解析http Response,并写入OpenTSDB
sl.append(b, contentType, start)
......
}
解析http Response并插入TSDB的函数为:
scrape.go
func (sl *scrapeLoop) append(b []byte, contentType string, ts time.Time) {
......
loop:
for {
var et textparse.Entry
// 解析parse
......
// 解析后的数据写入TSDB
app.AddFast(ce.lset, ce.ref, t, v);
}
......
// 没有错误的话,再提交
if err := app.Commit(); err != nil {
return total, added, seriesAdded, err
}
......
}
通过TSDB事务的概念,Prometheus使得我们的数据写入是原子的,即不会出现只看到部分数据的现象。至于事务的实现,可以见笔者之前的博客《Prometheus时序数据库-数据的插入》。
总结
Prometehus提供了非常灵活的接口供其和我们自身的运维基础设施进行联动。在实际应用过程中,我们只需要实现对应的discovery逻辑即可。在本篇文章里面,笔者详细阐述了Promtheus的自动发现以及数据抓取过程,希望对读者有所帮助!
相关阅读

